前言
来到BOOS直聘
搜索python
打开控制台,查看请求发现,页面数据不是动态加载
所以直接复制当前页面链接进行爬取,经过多次的爬取之后

。。。。。。。

失策失策,以前爬取别的网站从没有这么严格的反爬虫机制,没到到翻车了。。

偷偷告诉大家一个小技巧:虽然被禁止访问了,但登录后就又可以访问了,嘿嘿!可惜我当时不知道,事后才发现,可惜。
现在这样只能使用IP代理了
使用 IP代理 参考以下文章
Python爬虫避坑IP代理教程避坑(reuqests和selenium的ip代理)
建立boos数据库
boos建表语句
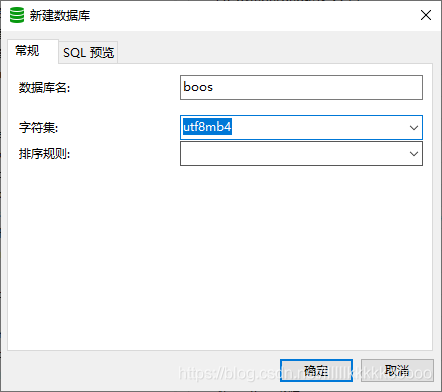
CREATE TABLE `boos` (`id` int(11) NOT NULL AUTO_INCREMENT,`title` varchar(100) DEFAULT NULL,`company` varchar(100) DEFAULT NULL,`price` varchar(100) DEFAULT NULL,`education` varchar(100) DEFAULT NULL,`text` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci,`introduce` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci,`address` varchar(100) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=99 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
完整代码及注释分析
import requestsfrom bs4 import BeautifulSoupimport timeimport pymysql#控制爬取页数num = 2#插入语句sql = "insert into boos(id,title, company, price, education, text, introduce ,address) values(null,%s,%s,%s,%s,%s,%s,%s)"#请求头headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",#爬取boos直聘cookie必不可少,参考图1"cookie": "_uab_collina=159575841104312945170807; __zp__pub__=; __c=1595890401; lastCity=100010000; JSESSIONID=""; _bl_uid=vLkaCdRI5j77gqrsIh0gbF4mC44z; sid=sem_pz_bdpc_dasou_title; __g=sem_pz_bdpc_dasou_title; __l=l=%2Fwww.zhipin.com%2F&r=https%3A%2F%2Fwww.google.com%2F&friend_source=0&g=%2Fwww.zhipin.com%2F%3Fsid%3Dsem_pz_bdpc_dasou_title&friend_source=0; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1595893052,1595903578,1595903959,1595906815; t=EPTZCBdCrM30pa4h; wt=EPTZCBdCrM30pa4h; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1595913530; __a=50500966.1595758411.1595862833.1595890401.177.4.124.36; __zp_stoken__=67beaGmFLZg0RXnJQY3cBIzMicU9jYzIZF1VdYXwsKBQkPCwGb0tdGEcsOHITTCwFWi49AjoIYy5BJTgsdSFCBVEoc1kTdgEWRSMQRTg3IBNgSQ5DPHsvDSFNcwokCHtOGBd4fT93SAUJYTk%3D"}#IP代理proxy = {'https': '61.178.118.86:8080'}#爬取数据def Crawling(cur,conn,response):#引入全局变量global numglobal sql# 使用lxml XML解析器data_list = BeautifulSoup(response.text, "lxml")#拿到所有的li标签然后遍历,参考图2#由于li没有class什么的,我们找到搜索li的父标签定位,再找下面的所有lili_list = data_list.find(class_="job-list").find_all("li")#遍历for data in li_list:bs = BeautifulSoup(str(data), "lxml")#职位,参考图3title = bs.find("a")["title"].strip()url = "https://www.zhipin.com/" + bs.find("a")['href']# 公司,图4company = bs.find(class_="company-text").find(class_="name").text# 公司福利 图5education = bs.find(class_="info-desc").text# 薪资 图6price = bs.find(class_="red").text# print(title+"--"+company+"--"+price+"--"+education)# # 请求详情页,进行数据爬取time.sleep(1)page_source = requests.get(url=url, headers=headers)page_source.encoding = "utf-8"page_bs = BeautifulSoup(str(page_source.text), "lxml")# 岗位职责,图7text = page_bs.find(class_="text").text.strip()#print(text)#print("+"*100)# 公司介绍,参考图8#有的公司没有介绍,爬取的时候会异常,我们呢处理异常,没有的时候直接给无介绍try:#因为这里的class值也是text,由于find的特性只会返回匹配到的第一个值,所以我们选择定位他的父标签,再找它introduce = page_bs.find(class_="job-sec company-info").find(class_="text").text.strip()except:introduce = "无介绍"# 工作地址,图9#有的公司地址后带有502,我们把它替换成空串address = page_bs.find(class_="location-address").text.replace("502","")#执行sql,提交事务cur.execute(sql, (title, company, price, education, text, introduce, address))conn.commit()#多页爬取if num < 4:#链接分析,图10next_url = "https://www.zhipin.com/c100010000/?query=python&page="+str(num)+"&ka=page-"+str(num)num += 1next_data = requests.get(url=next_url,headers=headers,proxies=proxy)next_data.encoding = "utf-8"#爬取Crawling(cur,conn,next_data)else:return cur,conn#初始化mysql连接def init_mysql():dbparams = {'host': '127.0.0.1','port': 3306,'user': '数据库账号','password': '数据库密码','database': 'boos', #数据库名'charset': 'utf8'}conn = pymysql.connect(**dbparams)cur = conn.cursor()return cur,conn#关闭数据库连接def close(cur,conn):cur.close()conn.close()#起始if __name__ == "__main__":#print("="*40)#防止请求频繁,关闭多余链接,可参考博主的文章requests.DEFAULT_RETRIES = 5s = requests.session()s.keep_alive = False#请求链接,只需更改url即可爬取自己想爬取的数据start_url = "https://www.zhipin.com/c100010000/?query=python&page=1&ka=page-1"response = requests.get(url=start_url, headers=headers,proxies=proxy)time.sleep(2)response.encoding = "utf-8"# print("="*40)#查看请求状态码,200为成功print(response.status_code)cur,conn = init_mysql()#爬取数据cur,conn = Crawling(cur,conn,response)#关闭数据库连接close(cur,conn)
图片辅助分析
图1
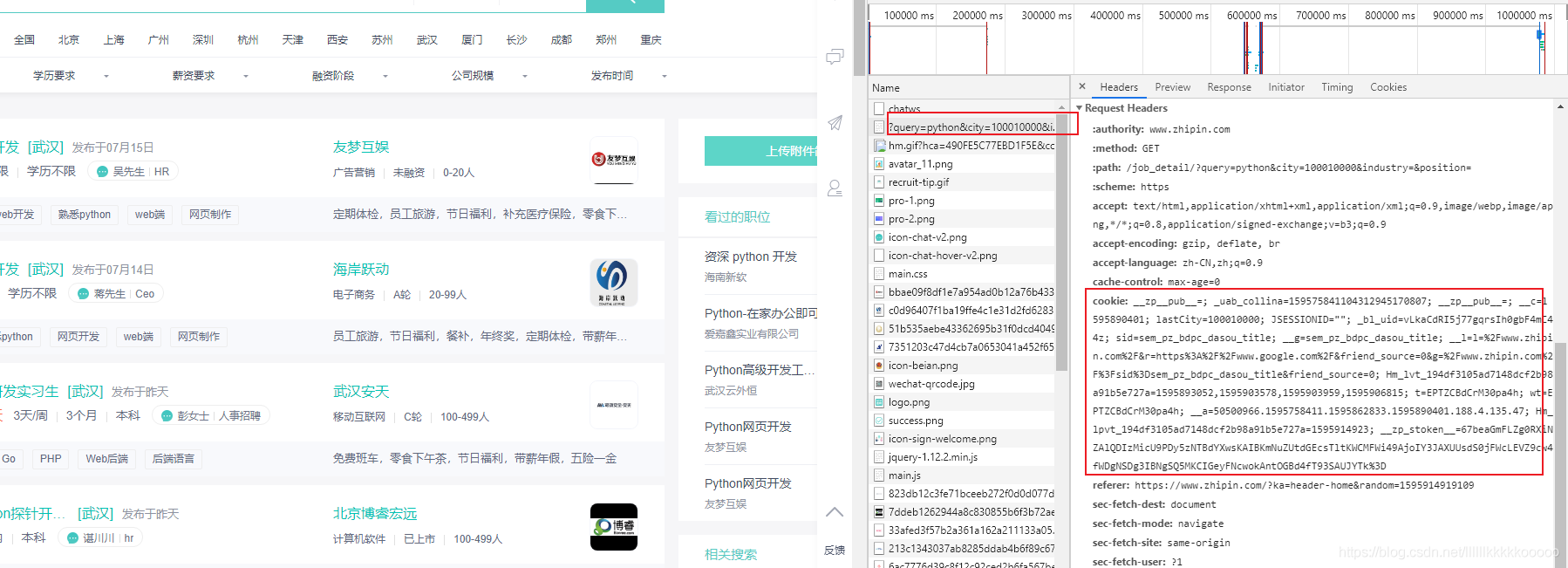
图2
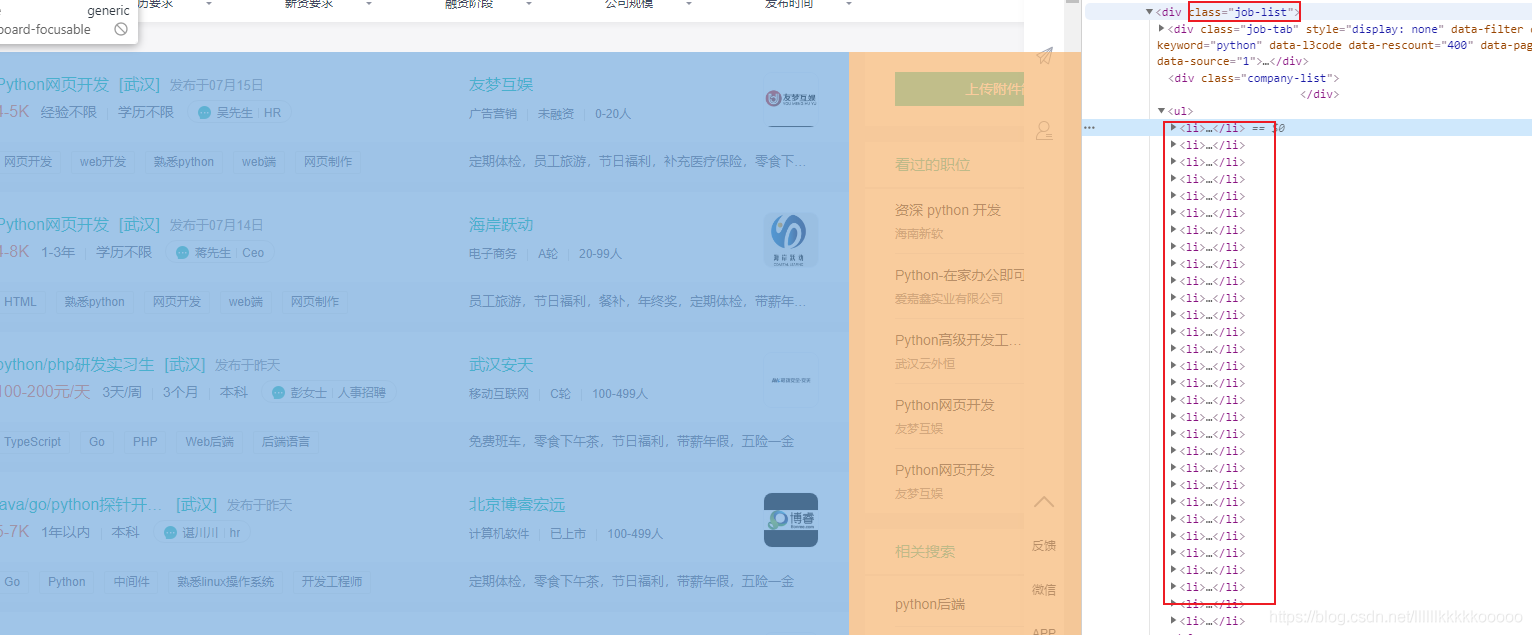
图3
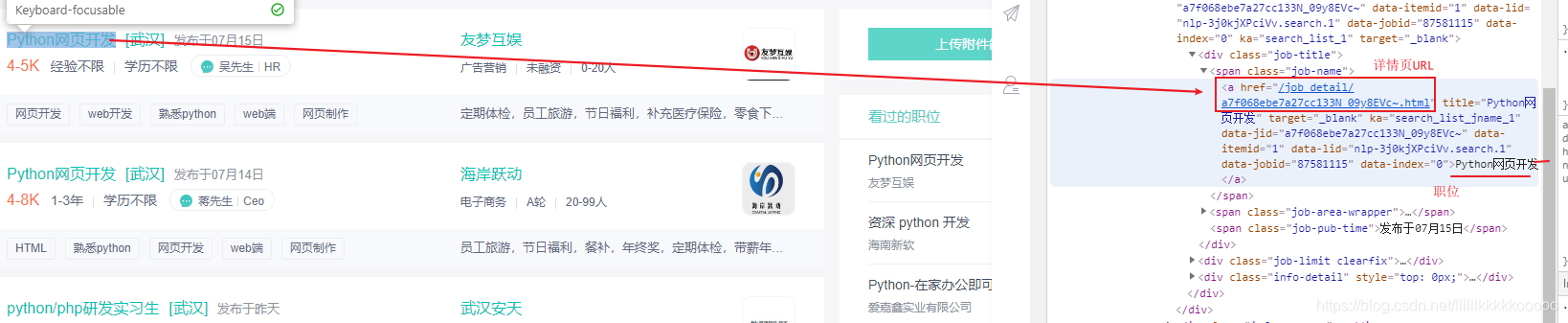
图4
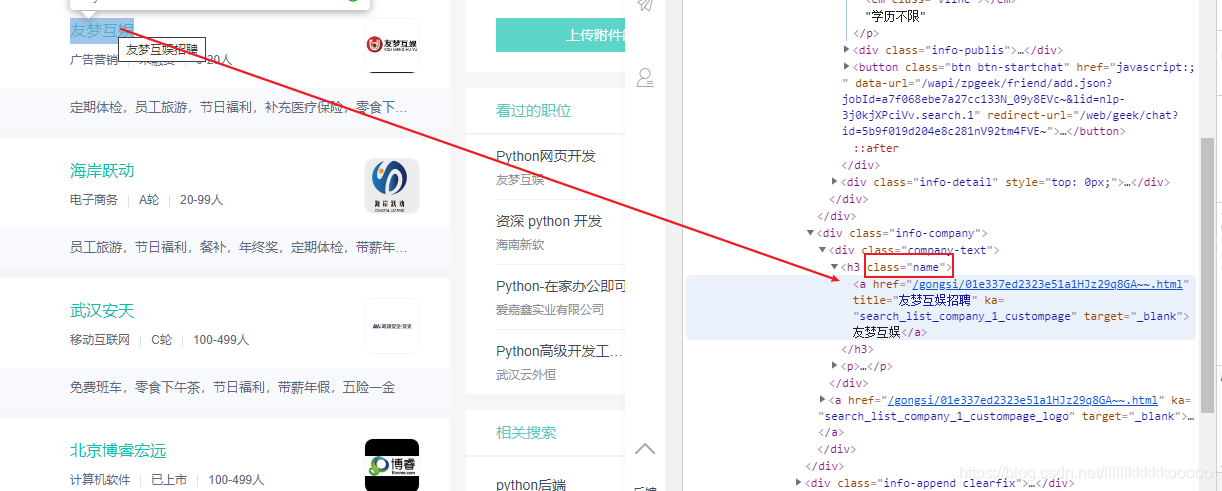
图5
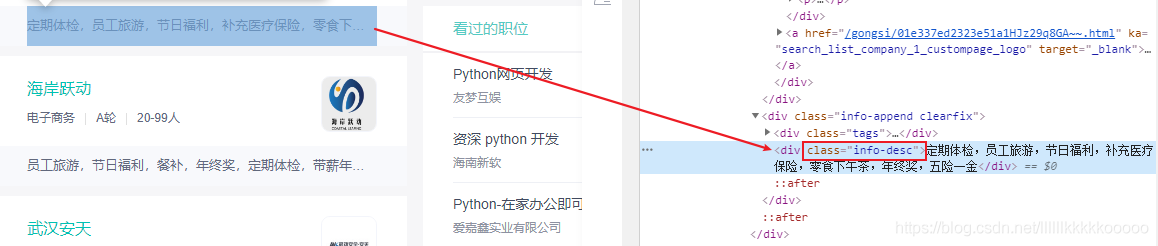
图6

图7
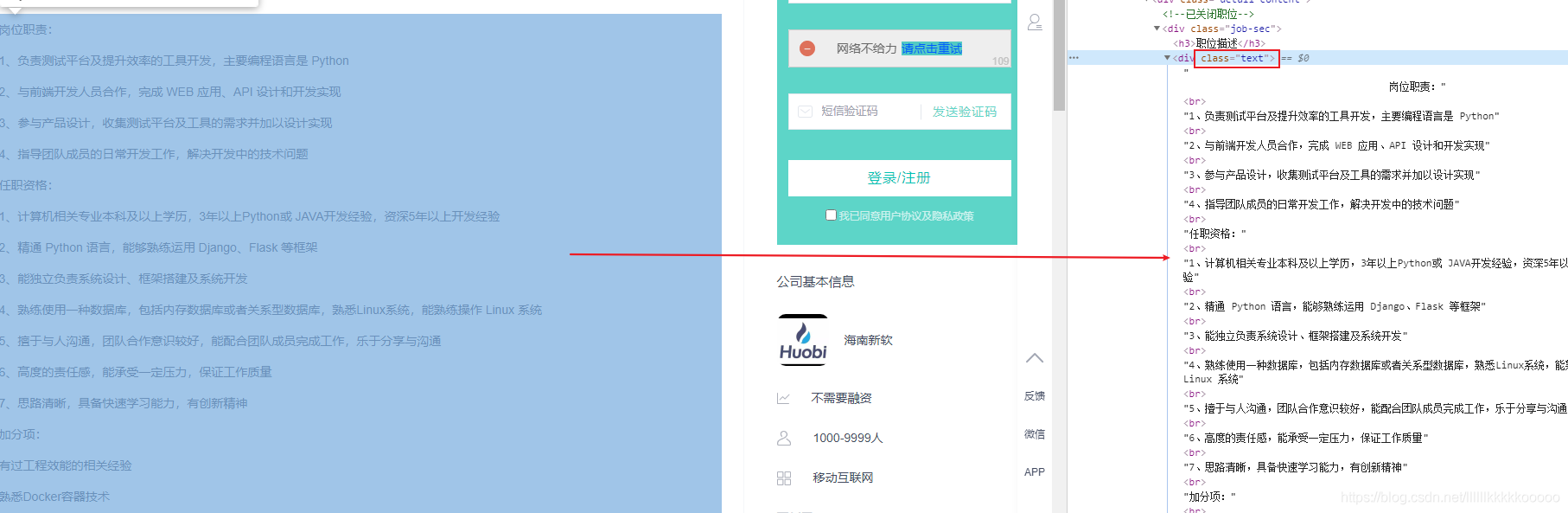
图8

图9

图10

运行结果
'NoneType' object has no attribute 'find_all'
BOOS直聘的反爬虫机制确实厉害,如果报以上错误,可以通过更换cookie或者更换代理IP来解决
实在不行,那就用不用代理ip了,还是用本机的,小技巧在上面已经教给大家了。
觉得博主写的不错的读者大大们,可以点赞关注和收藏哦,谢谢各位!

若有收获,就点个赞吧
0 人点赞
