最近回顾了一下数据仓库的理论知识,遂整理成一份知识点大纲,方便后续复习。
主要参考:
1、木东居士分享的文章
2、阿里巴巴大数据之路
3、穆晨的博客
4、工作中的实践
此文本意是供自己学习使用,有些地方是自己工作中的真实情况,可能不一定合适于每一个人。如果感兴趣,可以跟着大纲自己梳理一遍,会大有裨益。
1、定义
什么是数据仓库?
数据仓库是一个面向
- 主题的(Subject Oriented)
- 集成的(Integrate)
- 相对稳定的(Non-Volatile)
- 反映历史变化(Time Variant)的数据集合
2、离线数据同步
- 《阿里巴巴大数据之路》第4章
- Hive表数据存储格式ORC、parquet
- 数据偏移
- 数据同步工具 Datax和Sqoop
根据updatetime增量数据合并全量表的几种方式
《阿里巴巴大数据之路》第8章
- ER建模(实体关系建模)
- 数据库和数据仓库的区别
规范化和反规范化
《阿里巴巴大数据之路》第9章
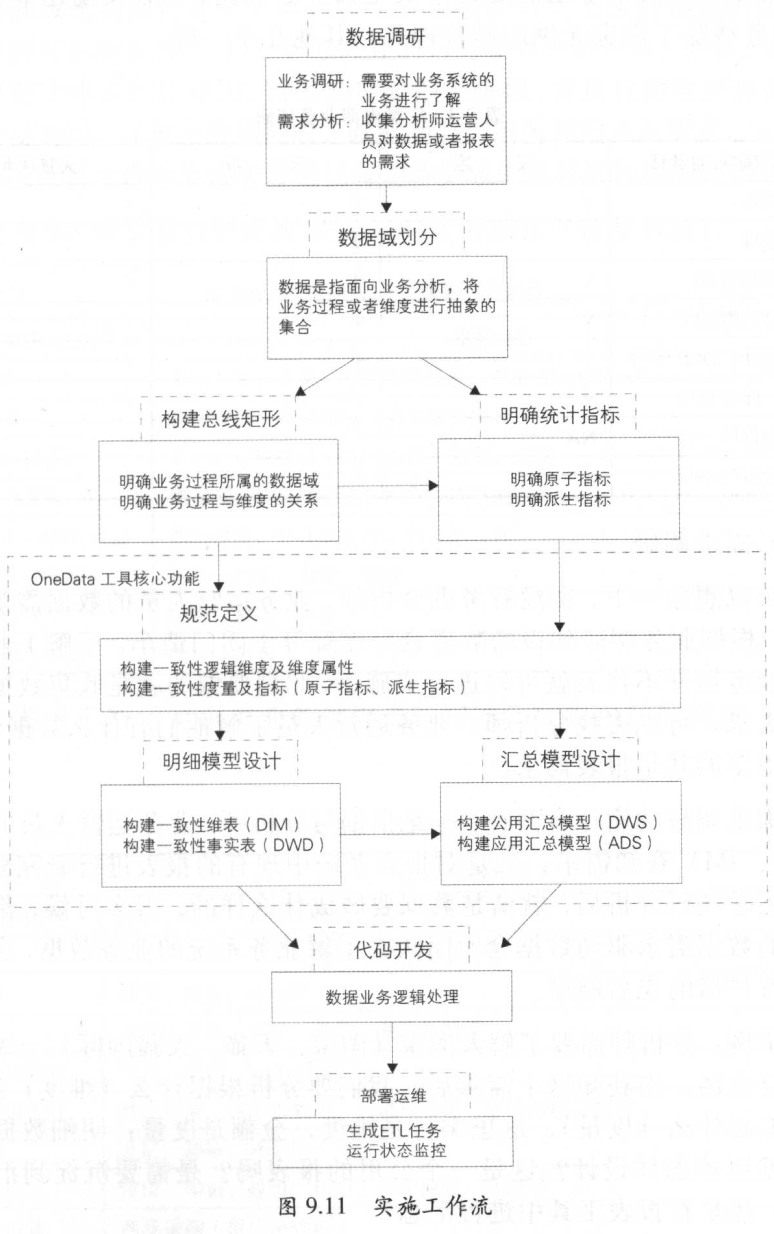
- 数仓关键名词定义
- 数据域、度量、指标(原子指标/派生指标)、维度、维度属性
- 数仓分层
- https://www.yuque.com/data-tea-room/data-in-action/data-layer
- 结合自己工作的数仓和理论的数仓分层进行对应分析
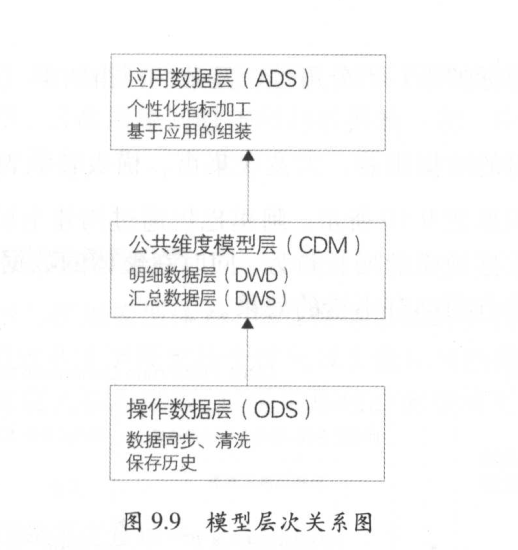
开发实施流程
《阿里巴巴大数据之路》第10章
- 维度和维度属性的基本概念
- 维度建模的过程

- 在确定维度属性的时候要求:
- 1、尽可能丰富
- 2、尽量通用
- 3、连续值一般不是维度属性,但是可以拆分成维度属性
- 层次结构的处理方式
- 结合数据立方体理解上卷和下钻
- OLAP中进行反规范化处理,将维度的属性层次合并到单个为表中
- 维度整合与拆分
缓慢变化维
《阿里巴巴大数据之路》第11章
- 事务事实表
- 单事务事实表
- 多事务事实表
- 周期快照事实表
- 例子:如用户累计登陆次数,当前VIP等级,最高VIP等级等快照事实
- 基本可以基于事务事实表计算得来
- 累计快照事实表
- 记录事实的变化工程
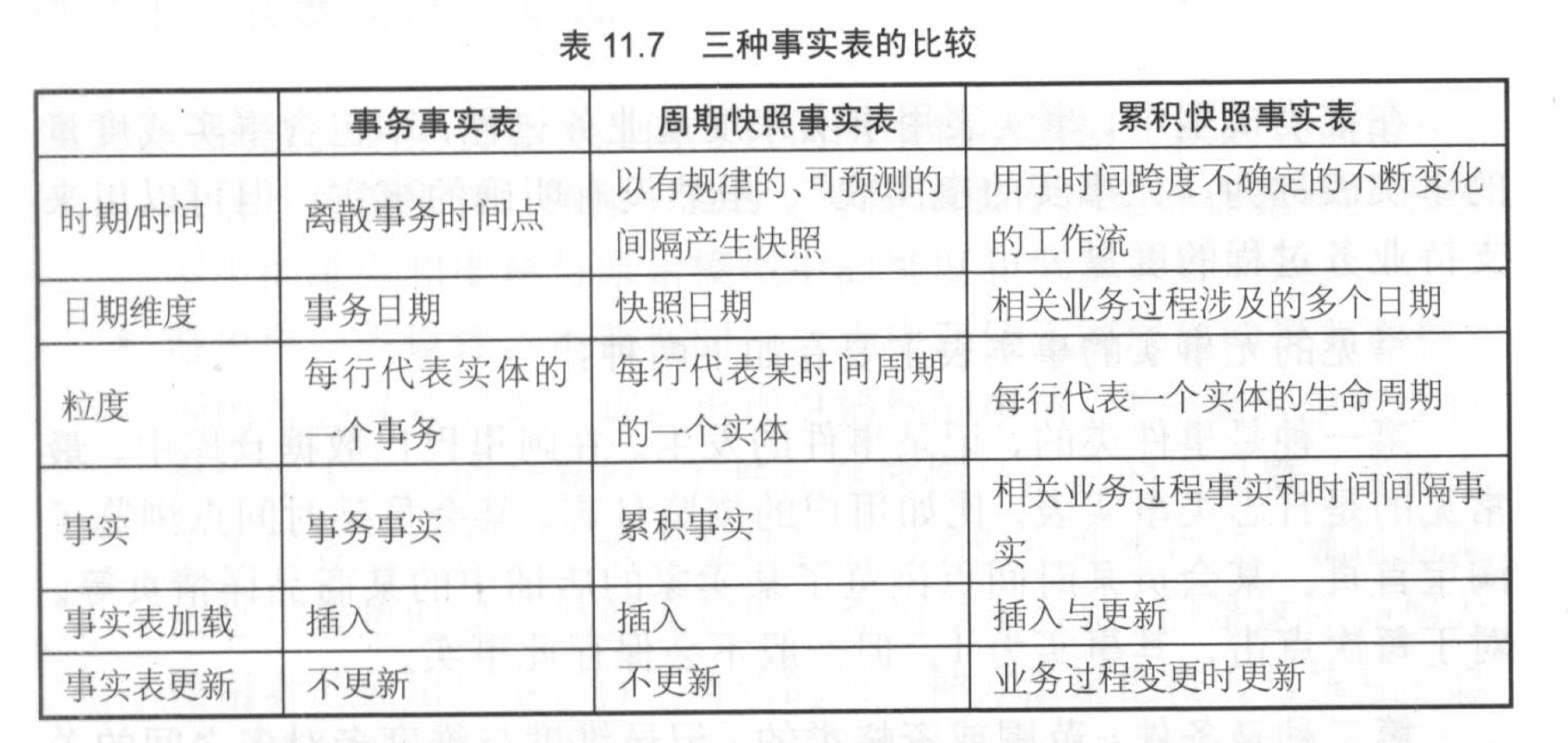
事实表设计方法
《阿里巴巴大数据之路》第12章
- Hive元数据表的基本使用参考http://lxw1234.com/archives/2015/07/378.htm
- 查询所有数据库
- 查询是内部表还是外部表
- 查询表格式
- 查询数仓所有表个数(分区表个数、非分区表个数)
- 统计所有表行数
- 统计表对应的HDFS里存储文件个数
- 获取表的上一次更新时间
- 小文件合并
- 使用
Alter table xxx concatenate进行小文件合并 - 使用spark 进行事后合并 https://stackoverflow.com/questions/39187622/how-do-you-control-the-size-of-the-output-file
- 使用
- 统计数仓表行数
- Hive insert overwrite 会自动统计(hive.stats.autogather=true)
- 有些操作不能触发自动统计,使用
ANALYZE TABLE XXX COMPUTE STATISTICS进行写流程后统计
- 使用Hive元数据进行简单监控
- 表命名规范检查
- 小文件个数合理性检查
- 表行数掉零监测
公司系统元数据:
《阿里巴巴大数据之路》第15章
- 美团数据质量监控 https://tech.meituan.com/2018/03/21/mtdp-dataman.html
- 木东居士:No.22 漫谈数据质量监控
- 数据质量保障
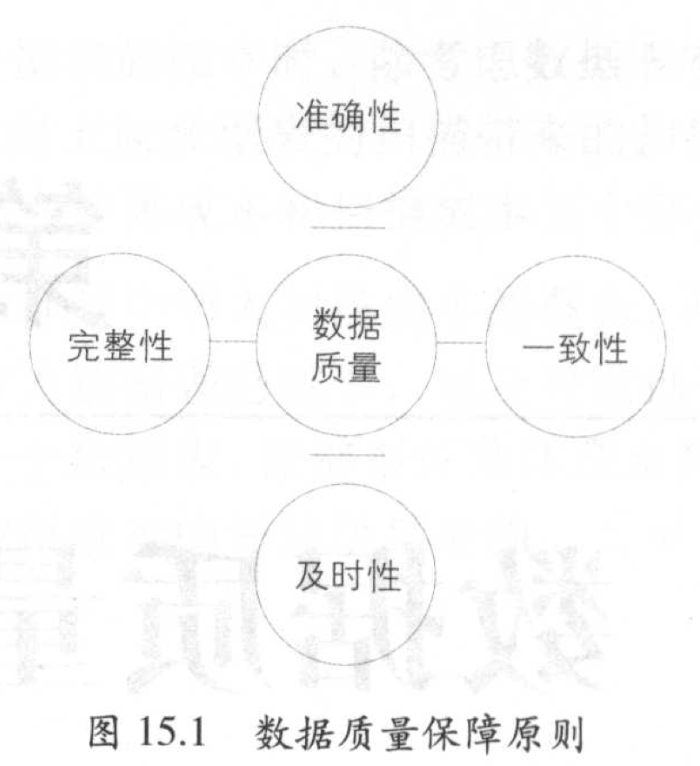
- 血缘关系
- SQL语法解析:Antlr4
- Hive的LineageInfo
业务库表变更发现
- 业务库删除数据发现https://www.yuque.com/calvin.zhang/log/issue-20190320
- 增量数据更新进行规范化,updatetime一定要更新
9、优化
数据倾斜
- 木东居士:No.23 聊一聊数据倾斜那些坑https://mp.weixin.qq.com/s/1URilIgOcFBtnUbYIp5JUA
- 数据倾斜 https://blog.csdn.net/lbfjava/article/details/76408852
spark性能优化
木东居士的所有文章建议看一遍
- 穆晨的博客里关于数据库和数据仓库的所有文章建议看一遍
- 《阿里巴巴大数据之路》这本书里涉及到的第3、4、8、9、10、11、12、15章建议看一遍
- 文章应当结合自己的工作内容进行总结

若有收获,就点个赞吧
0 人点赞
