1、大数据概述
1.1 大数据基本概念
- 数据量大
-
1.2 大数据设计到的技术
数据采集
- 数据存储
- 数据处理 /分析/挖掘
-
1.3 大数据带来的技术挑战
对现有数据库管理技术的挑战
- 经典数据库技术没有考虑数据的多类别(json,parquet,etc)
-
1.3.1 大数据带来的其他挑战
数据隐私
- 数据源复杂性
2、初识Hadoop
2.1、Hadoop概述
Hadoop 是Apache开源的分布式存储+分布式计算的平台
能干什么?
- 大型数据仓库
- PB级别数据的存储、处理、分析、统计等业务
-
2.2、Hdoop 核心组件
2.2.1、分布式文件系统HDFS
源自于Google发表于2003年10月的GFS论文
- HDFS是GFS的开源实现
- HDFS特点:拓展性&容错性&海量数据存储
- 将文件切分成指定大小的数据块,并以多副本的方式存储在多个机器
-
2.2.2、资源调度系统YARN
YARN:Yet Another Resource Negotiator
- 负责整个集群资源的管理和调度
- YARN特点:拓展性&容错性&多框架资源统一调度
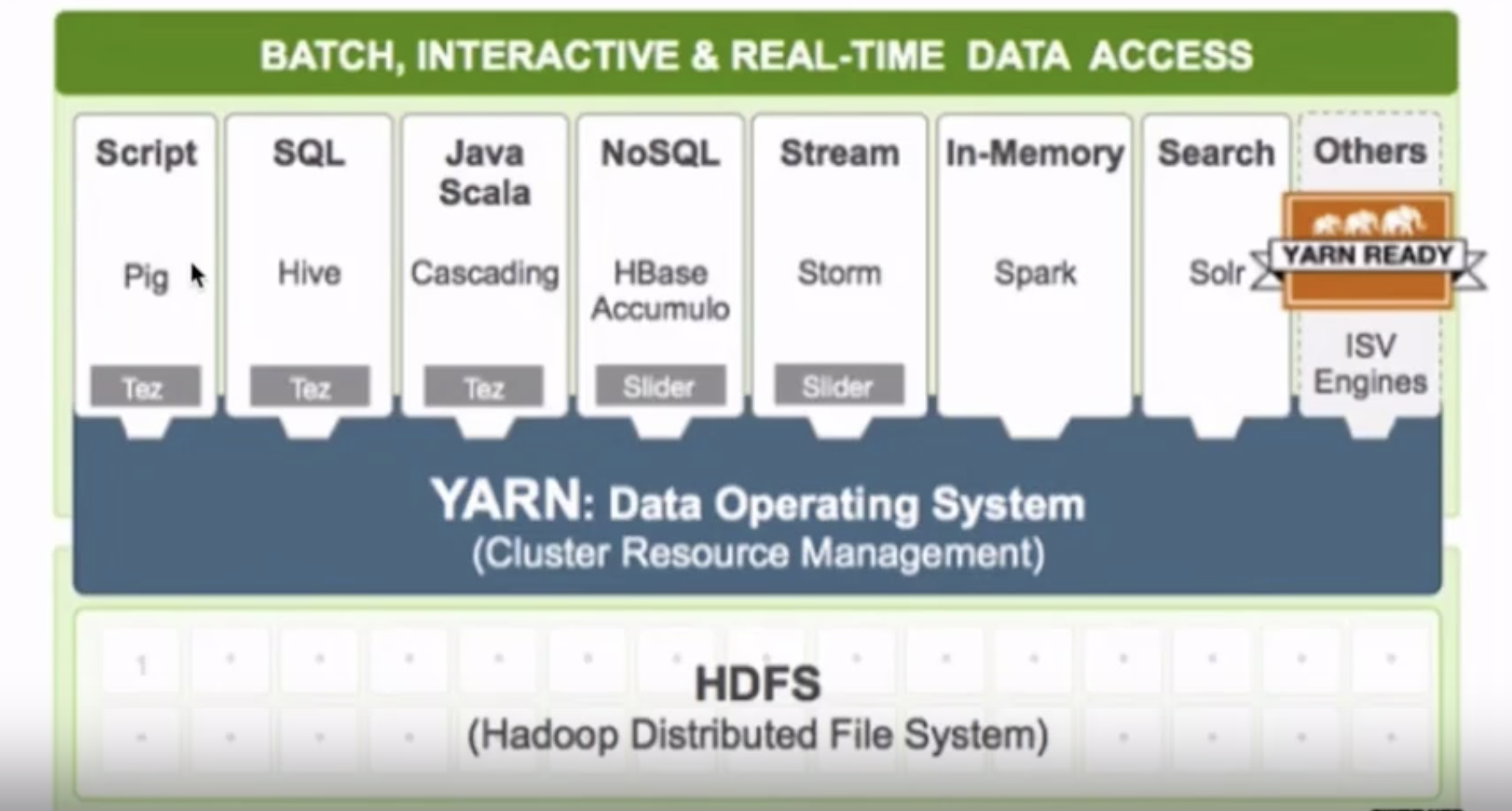
2.2.3、分布式计算框架MapReduce
- Google 2004年12月发表的MapReduce论文
- Hadoop的MapReduce是Google MapReduce的开源实现
-
2.3、Hadoop优势
高可靠性
- 数据存储:数据库多副本
- 数据计算:重新调度作业计算
- 高拓展性
- 存储/计算资源不够时,可以横向线性拓展机器
- 一个集群中可以包含数以千计的节点
- 其他优势
- 存储在廉价机器上,降低成本
- 成熟的生态圈
2.4、Hadoop发展史
https://www.infoq.cn/article/hadoop-ten-years-interpretation-and-development-forecast
2.5、Hadoop生态系统
2.5.1 狭义的Hadoop VS 广义的Hadoop
- 狭义的Hadoop:是一个适合大数据分布式存储(HDFS)、分布式计算(MapReduce)和资源调度(YARN)的平台
广义的Hadoop:指的是Hadoop的生态系统,Hadoop生态系统是一个很庞大的概念,Hadoop是其中最重要最基础的一个部分;生态系统总的每一个子系统只解决某一个特定的问题域(甚至可能很窄),不搞统一型的一个全能系统,而是小而精的多个小系统。
2.6、Hadoop发行版本的选择
Apache Hadoop
- CDH: Cloudera Distributed Hadoop
- HDP: Hortonwords Data Platform
3、分布式文件系统HDFS(重点)
3.1、HDFS概述及设计目标
- 什么是HDFS
- Hadoop实现了一个分布式文件系统(Hadoop Distributed File System)
- 源于2003年Google的GFS论文
- 设计目标是什么
- 非常巨大的分布式文件系统
- 运行在普通的廉价的硬件上
- 易拓展、为用户提供性能不错的文件存储服务
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
3.2、HDFS架构
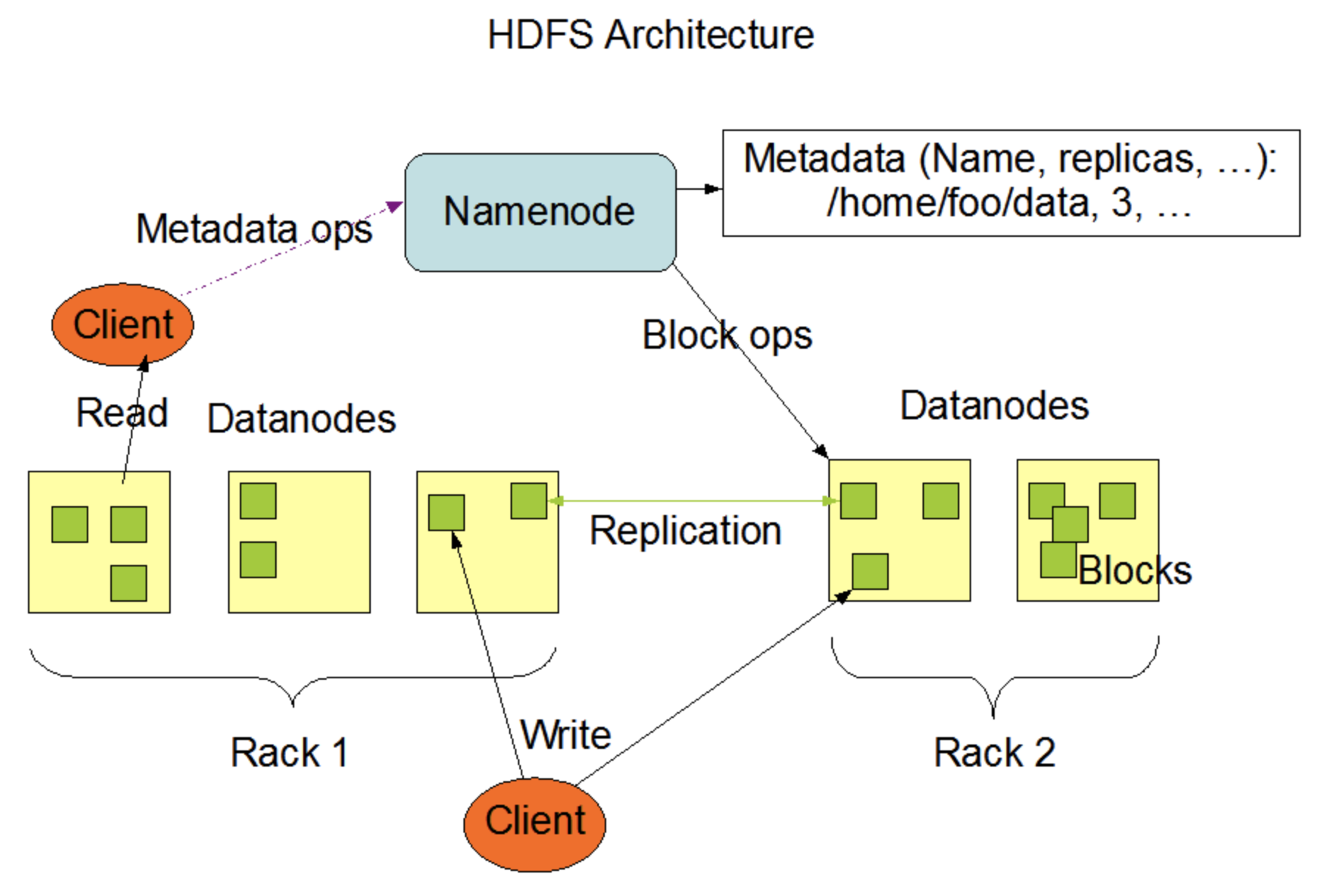
HDFS架构:
1、Master(NameNode/NM) 带 N个Slaves(DataNode/DN)
HDFS/YARN/HBase
2、一个文件会被拆分成多个Block
blocksize: 128M
130M ==>2个Block: 128M和2M
NN:
1)负责客户端请求得响应
2)负责元数据(文件的名称、副本系数、Block存放的的DN)的管理·
DN:
1)存储用户的文件对应的数据块(Block)
2)要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况
3.3、HDFS副本机制
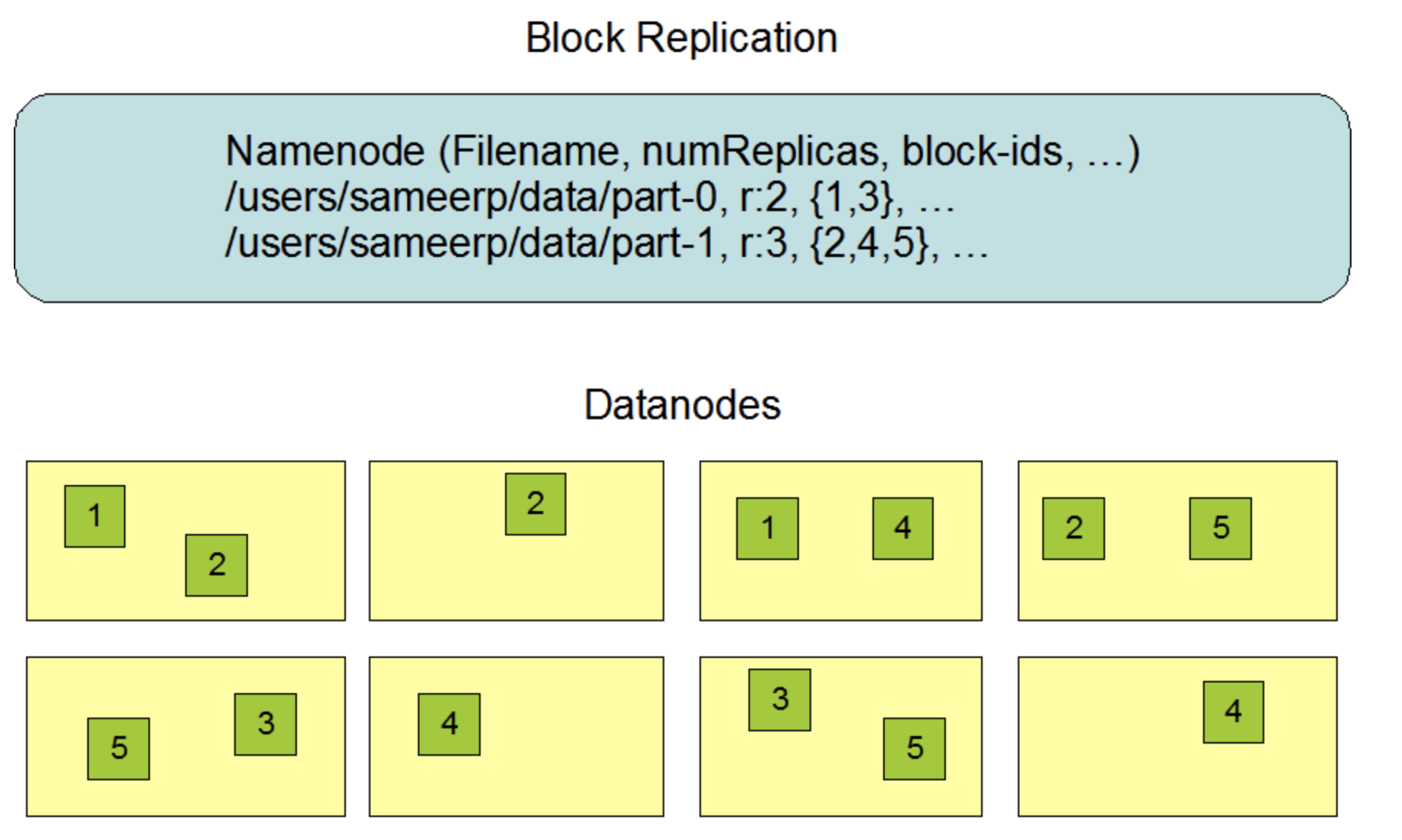
为什么hdfs需要副本机制?
- 在上个问题的时候,我说过我们需要的是大量相对廉价的计算机,那么宕机就是一种必然事件,我们需要让数据避免丢失,就只有采取冗余数据存储,而具体的实现就是副本机制
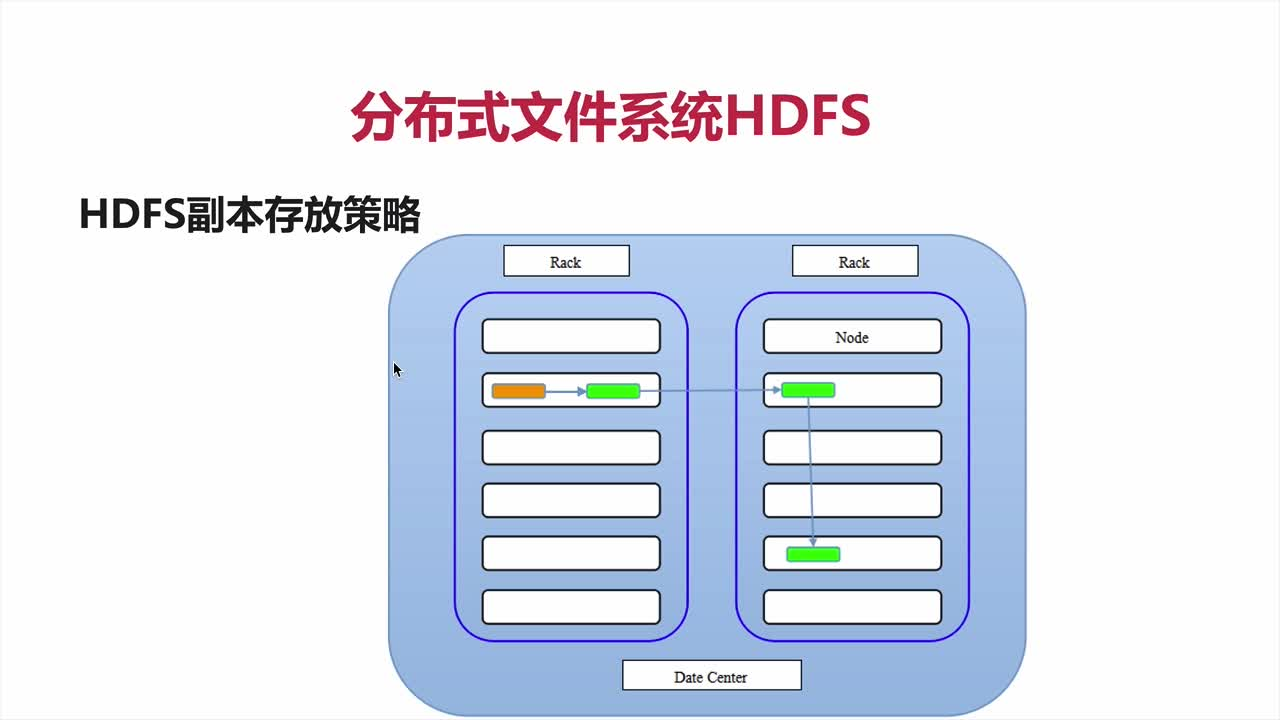
HDFS副本存放策略:
- 1、默认每个Block有三个副本
- 2、第一个副本存放在客户端请所在的Rack(机架)
- 3、第二个副本优先存放在不同Rack
- 4、第三个副本优先存放在第二个副本相同的Rack上
- 5、仅有一个Rack时,随机在不同节点上存放副本
副本机制的作用:
https://www.jianshu.com/p/a0f170436cbe
- 请求namenode,告知block大小和存储份数(如3个)
- namenode返回3个由近及远排序过的datanode给客户端
- client以流水线的形式向datanode1上传数据,datanode1会将数据转发到datanode2,datanode2接收同时会转发到datanode3。
- 每个datanode接受完数据后会告知namenode
- namenode告知client当前block完成
- client重复如上步骤开始下一个block的传输
client 告知namenode所有block传输完成,namenode告知所有数据存储完成
3.5、HDFS 写流程(面试常考)
client向namenode请求文件名的元数据信息
- namenode反馈由远及近排序后的datanode集合。每个block存放的datanode位置
- client从最近的datanode上下载每一个block
容错:
namenode是唯一的,一旦namenode挂了,整个集群就挂了
datanode每三秒发一个心跳给namenode
10分钟没收到某个datanode的心跳就认为该datanode已经挂了3.6、HDFS 的优缺点
优点:
- 数据冗余,硬件容错
- 处理流式数据访问(一次写入,多次读取)
- 适合大文件存储
- 可构建在廉价机器上
缺点:
- 无法处理低延迟的数据访问
- 不适合小文件存储(元数据多对NameNode压力大,MapReduce过程中会起很多进程去取数据,占用资源)
4、分布式资源调度YARN(重点)
4.1、YARN产生背景
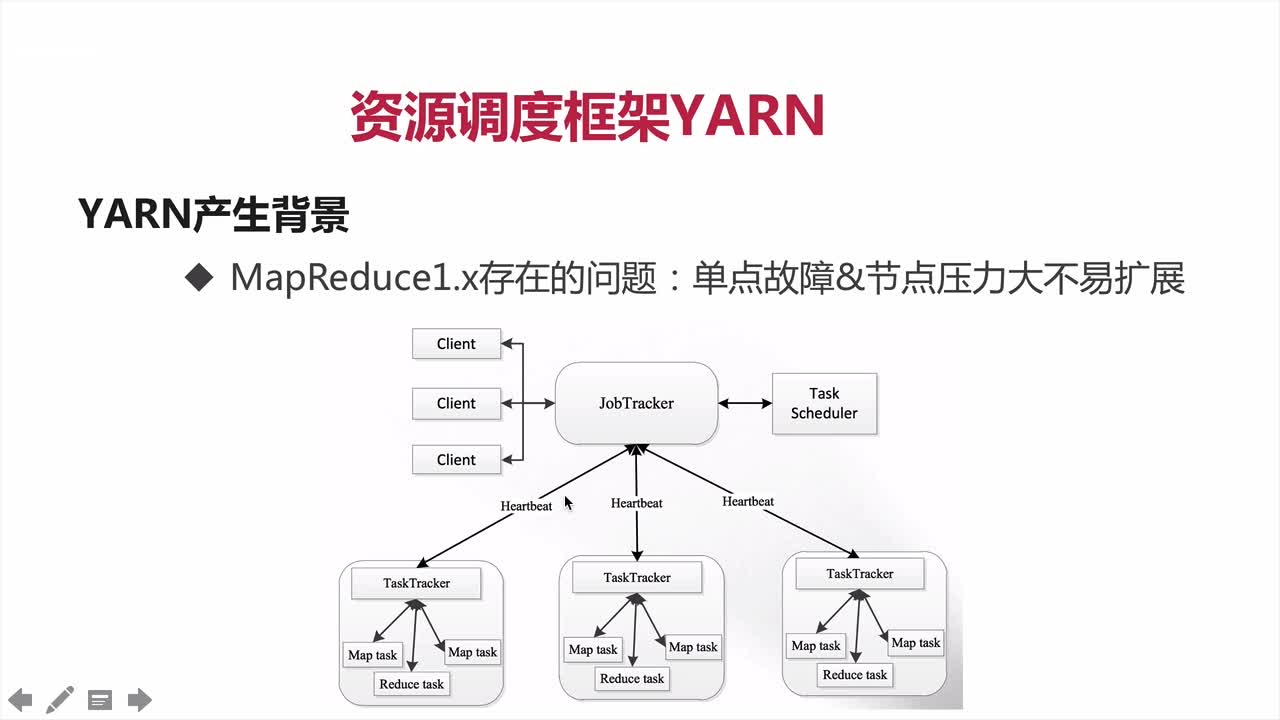
Hadoop1.X时:
MapReduce:Master/Slave架构,1个JobTracker带多个TaskTracker
Job Tracker: 负责资源管理和作业调度,压力很大
TaskTracker:
定期向JT汇报本节点的健康情况、资源使用情况、作业执行情况
接收来自JT的启动命令:启动、杀死进程
MR1.X存在的问题:
- Yet Another Resource Negotiator
- 通用的资源管理系统
- 为上层应用提供统一的管理和调度
4.3、YARN架构
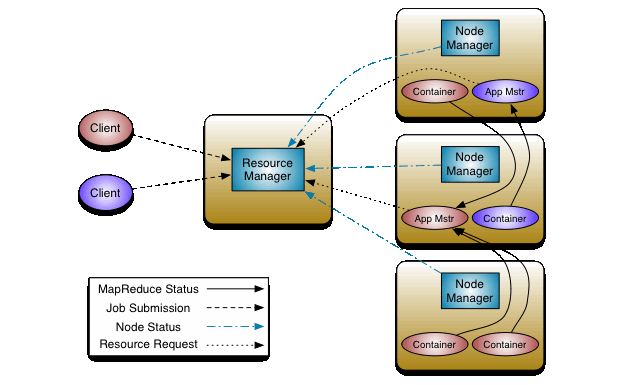
- ResouceManager : RM
- 整个集群同一时间提供服务的RM只有一个
- 处理客户端的请求(提交一个作业、杀死一个作业)
- 监控NM,一旦某个NM挂了,那么需要告诉AM该NM上运行的任务应该如何处理(重启)
- NodeManager: NM
- 多个NM,负责自身节点资源管理和使用
- 定时向RM汇报健康和资源情况
- 接收并处理RM的命令(启动container等)
- 处理来自AM的命令
- ApplicationMaster: AM
- 每个应用程序对应一个AM
- 为应用程序向RM申请资源core memory,分配给task
- 需要和NM通信:启动/停止task运行 ,task运行在container里
- Container
- 封装了CPU、Memory等资源的容器
Client
- 提交作业
- 查看作业的进度
- kill作业
4.4、YARN执行流程
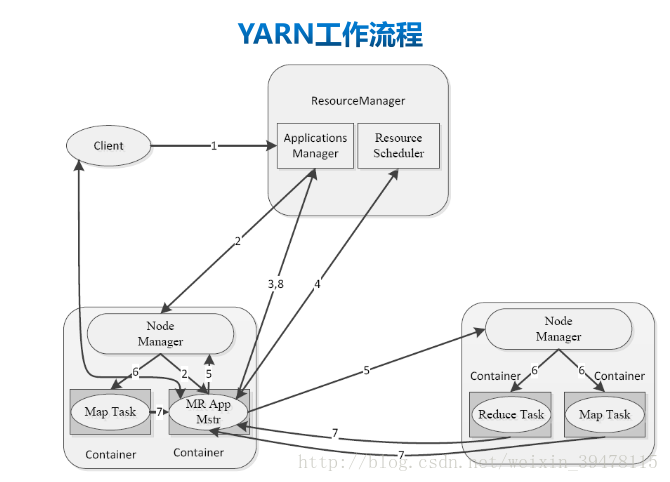
服务功能
ResouceManager:
1、处理客户端的请求
2、启动和监控ApplicationMaster
3、监控nodemanager
4、资源的分配和调度
Nodemanager
1、处理单个节点的资源管理
2、处理来自ResouceManager的命令
3、处理来自ApplicationMaster的命令
ApplicationMaser
1、为应用程序申请资源,并分配给内部任务
2、任务的监控和容错
Container
对多任务运行环境的抽象,包括CPU、内存等多维度资源以及环境变量、启动命令等任务运行的相关环境运行流程
1、客户端向RM中提交程序
2、RM向NM中分配一个container,并在该container中启动AM
3、AM向RM注册,这样用户可以直接通过RM査看应用程序的运行状态(然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束)
4、AM采用轮询的方式通过RPC协议向RM申请和领取资源,资源的协调通过异步完成
5、AM申请到资源后,便与对应的NM通信,要求它启动任务
6、NM为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务
7、各个任务通过某个RPC协议向AM汇报自己的状态和进度,以让AM随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务5、分布式计算计算框架MapReduce(重点)
5.1、MapReduce概述
Google的MapReduce论文
- Hadoop MapReduce 是Google MapReduce的开源实现版本
- 海量数据离线处理&易开发&易运行
- 无法进行实时流计算
5.2、MapReduce编程模型
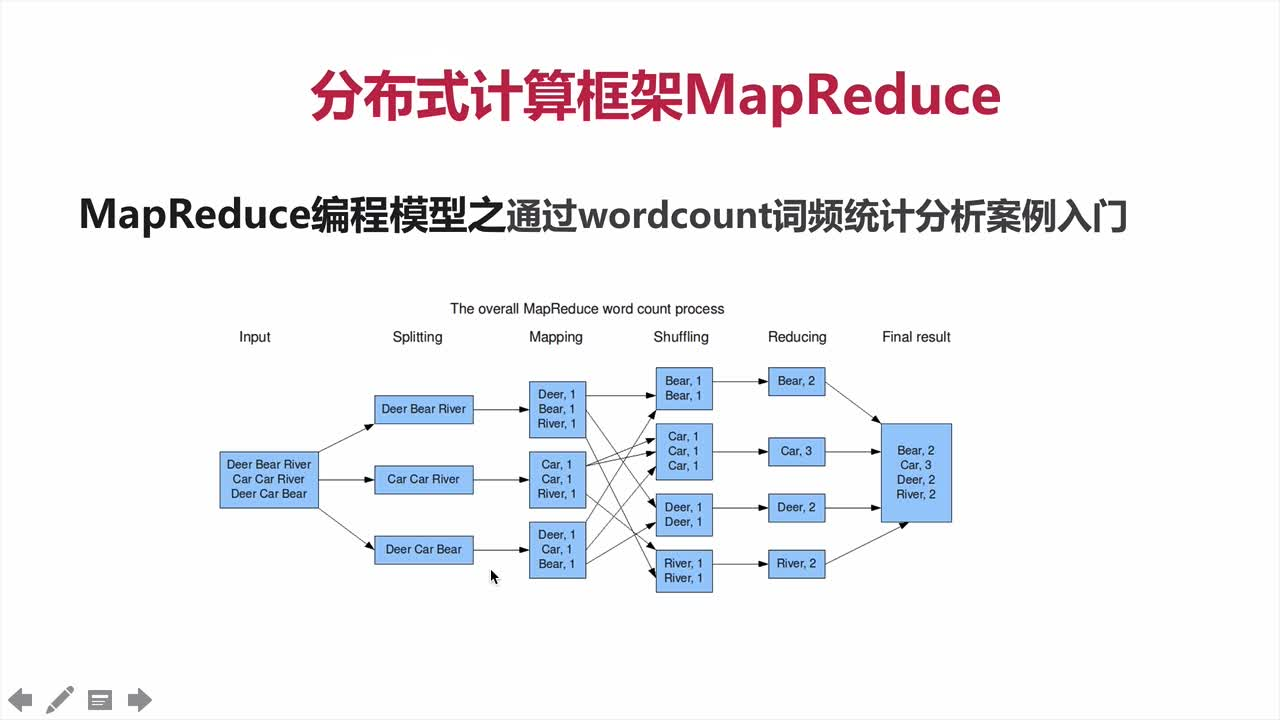
数据输入 —> 数据拆分 —> 统计计算 —> 分类顺序排列 —> 合并 —>汇总结果
**
5.2.1、MR执行步骤
- 准备map处理的输入数据
- Mapper处理
- Shuffle
- Reduce处理
- 结果输出
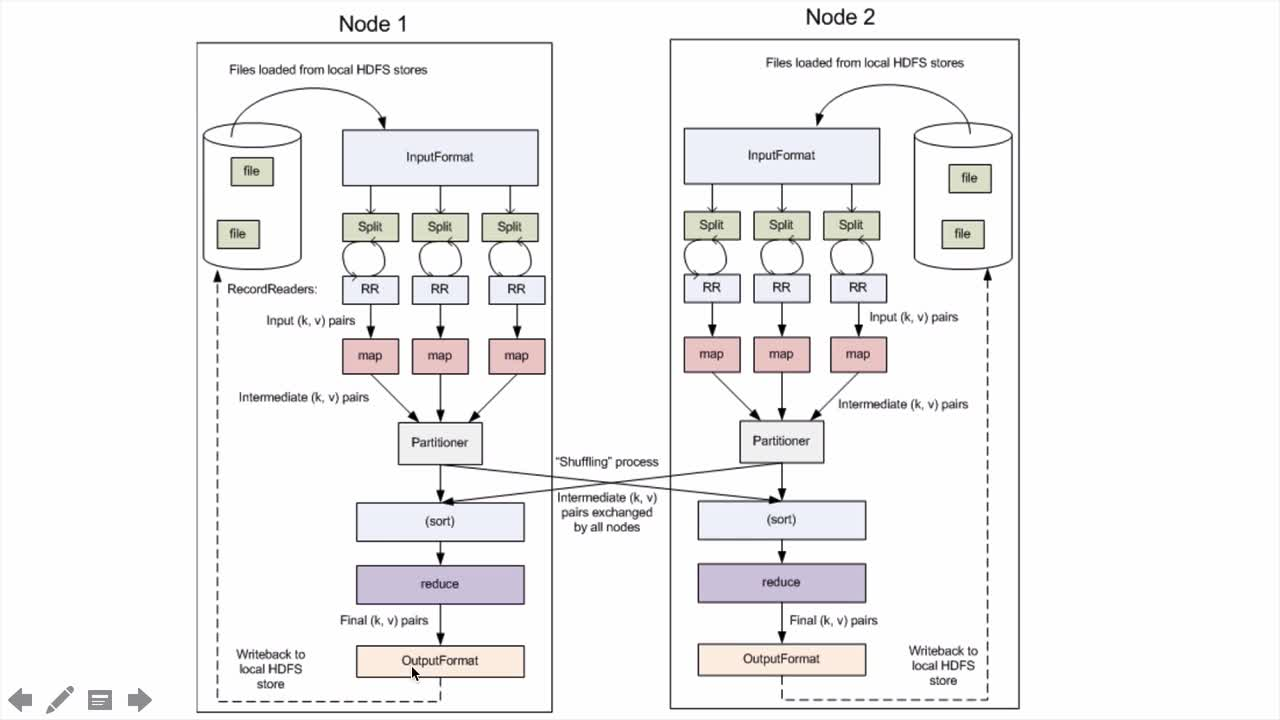
5.2.2、MR核心概念
- Split: 交由MapReduce作业来处理的数据块,是MapReduce中最小的计算单元。默认情况下,与HDFS中BLOCKSIZE一一对应。一个split交给一个map处理
- InputFormat:
将输入数据分片:InputSplit[] getSplits()
处理文本格式的数据:TextInputFormat - OutputFormat: 对应InputFormat
- Combiner
- Partitioner
-
5.3、MapReduce架构
5.3.1、MapReduce 1.x架构
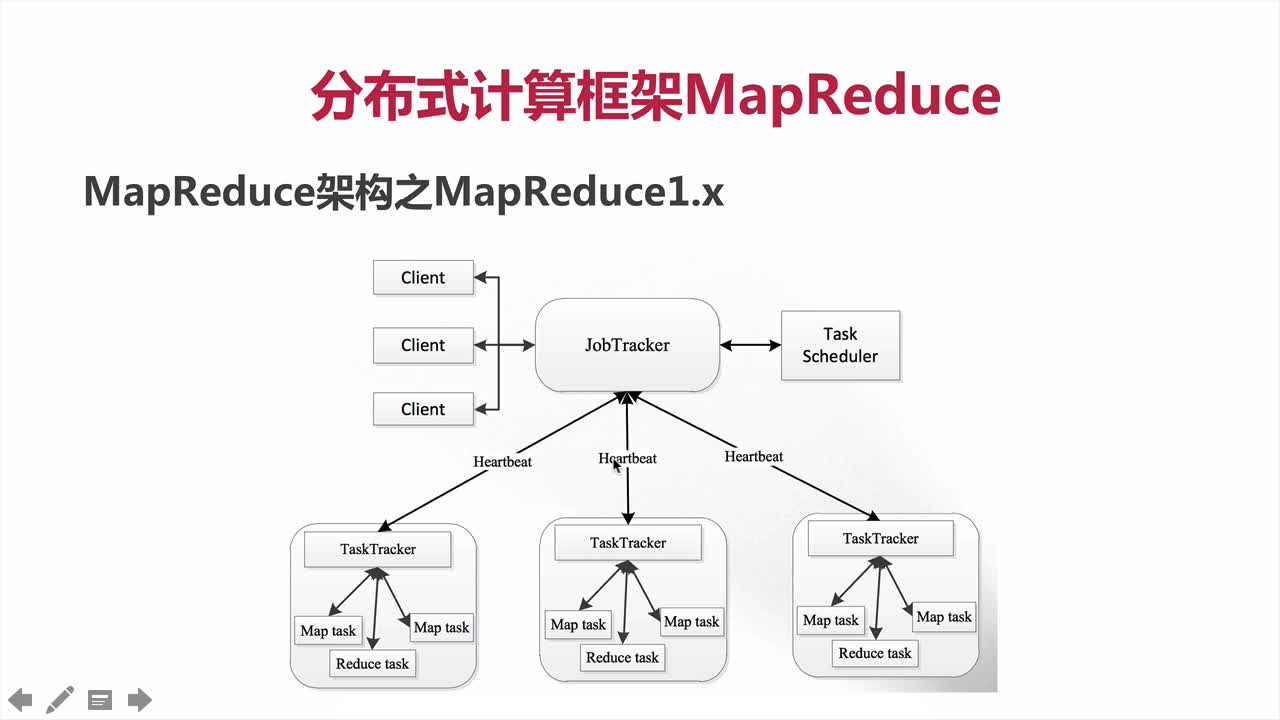
JobTracker:JT
- 作业的管理者
- 将作业分解成一堆的任务:Task(MapTask 、ReduceTask)
- 将任务分配给TaskTracker运行
- 作业的控制、容错机制
- 在一定的时间间隔内,没有收到TT的心跳,TT挂了,TT上运行的任务会指派到其他的TT上执行
- TaskTracker: TT
- 任务的执行者
- 在TT上执行Task
- 与JT进行交互:执行、启动、终止、发心跳
- MapTask
- 自己开发的Map任务交由该Task执行
- 解析每天记录数据,交由map的方法来处理
- 将map结果写到本地磁盘(如果只有map没有Reduce作业直接写到HDFS)
- ReduceTask
- 将MapTask输入的数据进行读取
- 按照数据进行分组,传给我们自己写的Reduce方法处理
- 输出结果写到HDFS
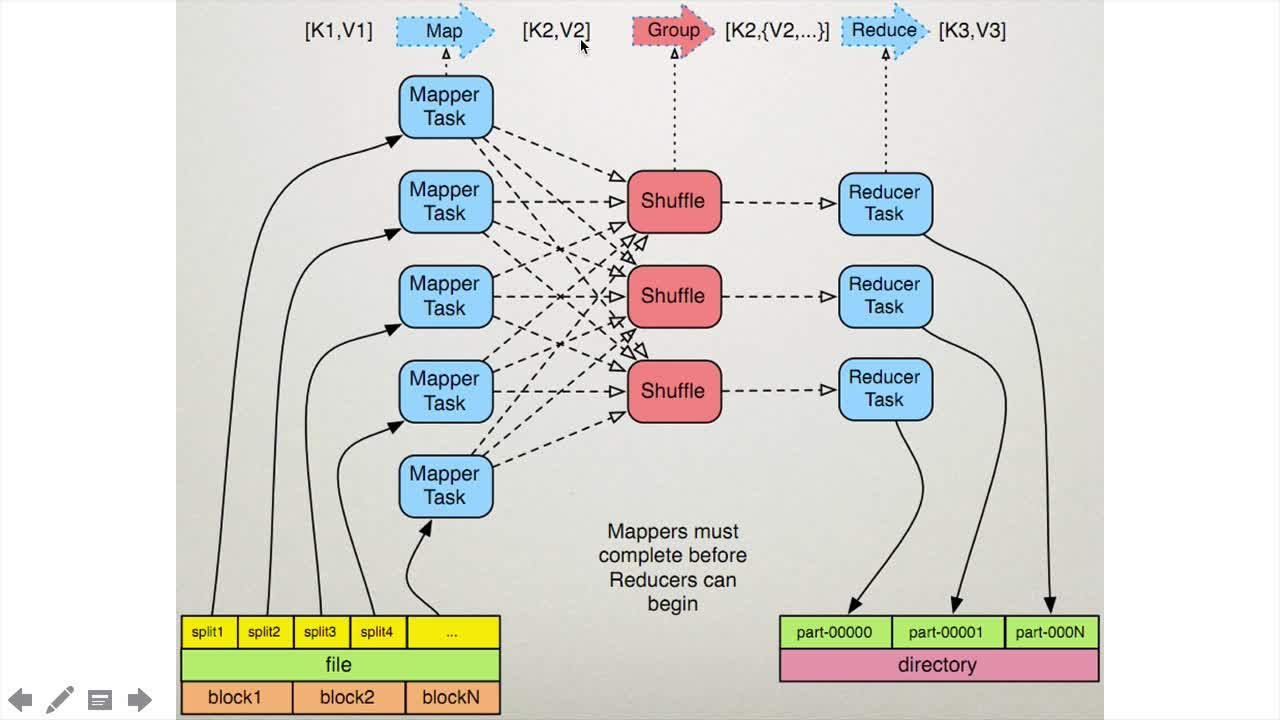
注:总是最后一步才把数据写入到HDFS
5.3.2、MapReduce 2.x架构
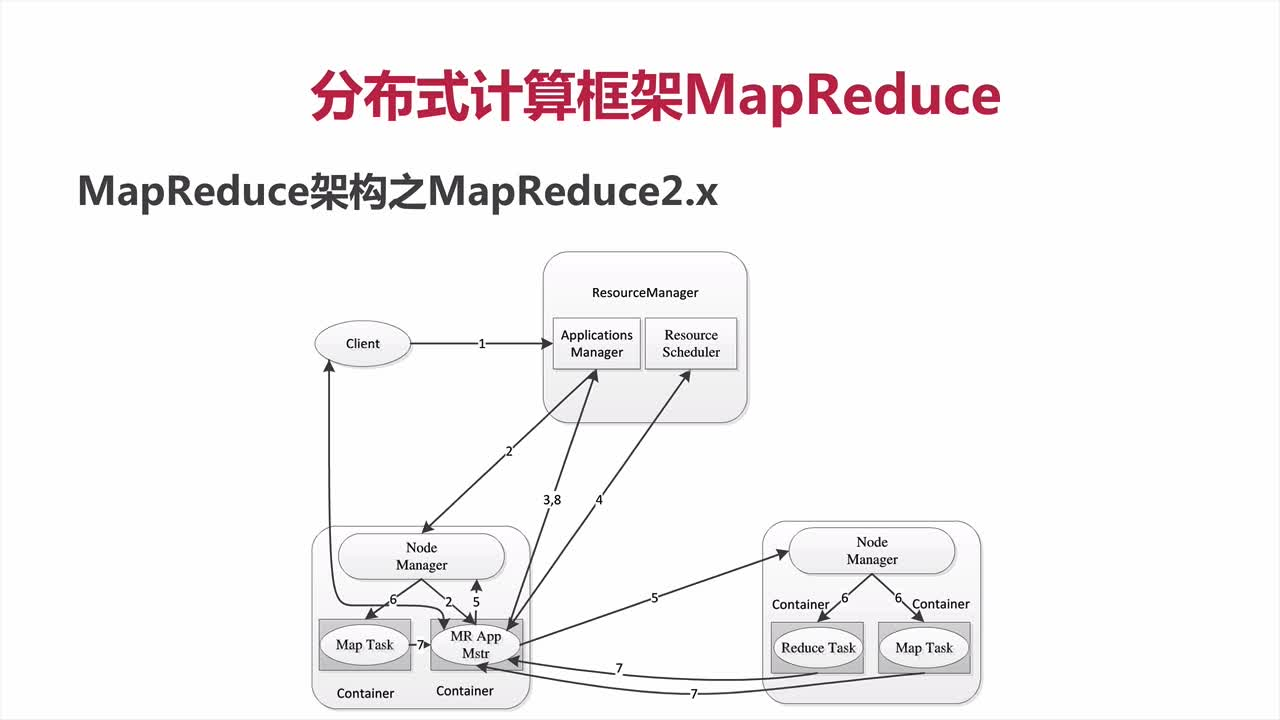
同YARN执行流程

若有收获,就点个赞吧
0 人点赞
