花了几天时间,基于python入门了一下Spark,了解了Spark Core,Spark SQL,Spark Streaming等相关包的基础操作,此文作为读书笔记供自己参考。
PySpark
https://github.com/apache/spark
1、SparkCore
1.1、什么是RDD
A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable,partitioned collection of elements that can be operated on in parallel.
弹性分布式数据集,spark的最基本抽象。代表的是一个不可变的、可分区的集合元素能进行并行计算
abstract class RDD[T: ClassTag](@transient private var _sc: SparkContext,@transient private var deps: Seq[Dependency[_]]) extends Serializable with Logging {
- 1)RDD是一个抽象类
- 2)带泛型的,可支持多种数据类型:String、object
1.2、RDD 特性
Internally, each RDD is characterized by five main properties:
- A list of partitions
- 一系列的分区/分片
- A function for computing each split/partitions
- 一个作用于RDD的函数本质上会作用于RDD内部的每一个分区
rdd.map(_+1)
- 一个作用于RDD的函数本质上会作用于RDD内部的每一个分区
- A list of dependencies on other RDDs
- 会依赖一些列的其他的RDD
rdd1 ==> rdd2 ==> rdd3 ==> rdd4
- 会依赖一些列的其他的RDD
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- 指定 key-value RDD 的 分区方法(Partitioner:分区器)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
- 数据在哪优先把作业调度到数据所在的节点进行计算:移动数据不如移动计算(减少IO)
1.3、RDD 特性在源码中的体现
// 特性二def compute(split: Partition, context: TaskContext): Iterator[T]// 特性一protected def getPartitions: Array[Partition]// 特性三protected def getDependencies: Seq[Dependency[_]] = deps// 特性五protected def getPreferredLocations(split: Partition): Seq[String] = Nil// 特性四val partitioner: Option[Partitioner] = None
1.4、图解RDD
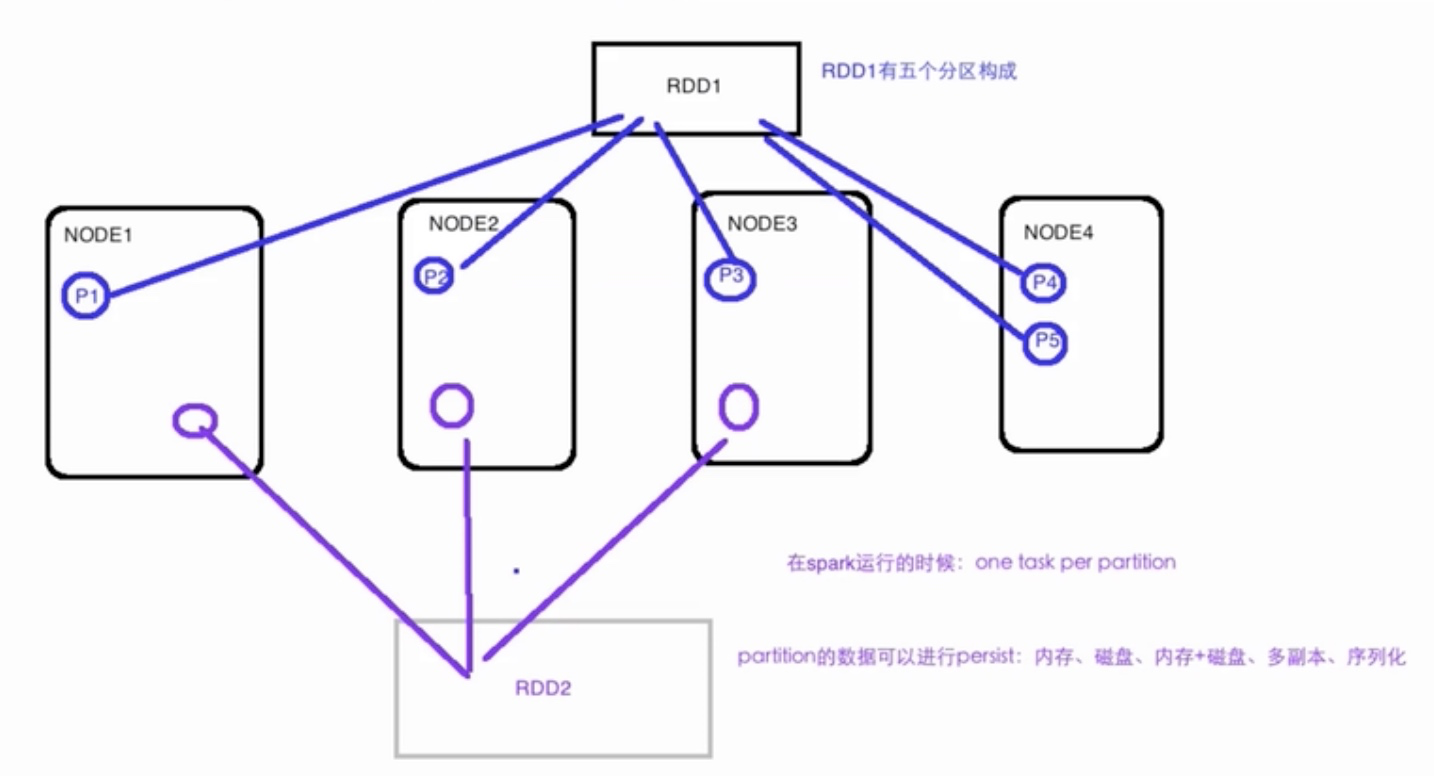
1.5、SparkContext & SparkConf
创建 SparkContext
- 连接到spark“集群”:local/standalone/yarn/mesos
- 指定master 和 appName
- 通过SparkContext创建RDD和广播变量到集群
在创建 SparkContext 之前,需要创建一个 SparkConf
1.6、本地开发环境
本地开发不需要集群,安装完成之后直接开发
1、安装
pip install pyspark
2、编码
from pyspark import SparkConffrom pyspark import SparkContextconf = SparkConf().setAppName("spark_01").setMaster("local[2]")sc = SparkContext(conf=conf)rdd = sc.parallelize(range(1, 6))print(rdd.collect())sc.stop()
3、提交
./bin/spark-submit --master "local[1]" --name "pysubmit" /Users/calvin/pyspark_project/spark_01.py
打印输出如下:
2019-03-27 19:04:29 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable2019-03-27 19:04:30 INFO SparkContext:54 - Running Spark version 2.4.02019-03-27 19:04:30 INFO SparkContext:54 - Submitted application: spark_012019-03-27 19:04:30 INFO SecurityManager:54 - Changing view acls to: calvin2019-03-27 19:04:30 INFO SecurityManager:54 - Changing modify acls to: calvin2019-03-27 19:04:30 INFO SecurityManager:54 - Changing view acls groups to:2019-03-27 19:04:30 INFO SecurityManager:54 - Changing modify acls groups to:2019-03-27 19:04:30 INFO SecurityManager:54 - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(calvin); groups with view permissions: Set(); users with modify permissions: Set(calvin); groups with modify permissions: Set()2019-03-27 19:04:30 INFO Utils:54 - Successfully started service 'sparkDriver' on port 56645.2019-03-27 19:04:30 INFO SparkEnv:54 - Registering MapOutputTracker2019-03-27 19:04:30 INFO SparkEnv:54 - Registering BlockManagerMaster2019-03-27 19:04:30 INFO BlockManagerMasterEndpoint:54 - Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information2019-03-27 19:04:30 INFO BlockManagerMasterEndpoint:54 - BlockManagerMasterEndpoint up2019-03-27 19:04:30 INFO DiskBlockManager:54 - Created local directory at /private/var/folders/4l/zdr5yt953pl36zwtl7dk9kfr0000gn/T/blockmgr-3f8bcb35-ea31-40e2-86fe-61f894c147172019-03-27 19:04:30 INFO MemoryStore:54 - MemoryStore started with capacity 366.3 MB2019-03-27 19:04:30 INFO SparkEnv:54 - Registering OutputCommitCoordinator2019-03-27 19:04:30 INFO log:192 - Logging initialized @2403ms2019-03-27 19:04:30 INFO Server:351 - jetty-9.3.z-SNAPSHOT, build timestamp: unknown, git hash: unknown2019-03-27 19:04:30 INFO Server:419 - Started @2493ms2019-03-27 19:04:30 WARN Utils:66 - Service 'SparkUI' could not bind on port 4040. Attempting port 4041.2019-03-27 19:04:30 WARN Utils:66 - Service 'SparkUI' could not bind on port 4041. Attempting port 4042.2019-03-27 19:04:30 INFO AbstractConnector:278 - Started ServerConnector@663f2e4{HTTP/1.1,[http/1.1]}{0.0.0.0:4042}2019-03-27 19:04:30 INFO Utils:54 - Successfully started service 'SparkUI' on port 4042.2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@e3fbafe{/jobs,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@6c2383f3{/jobs/json,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@8c7afcf{/jobs/job,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@32ac61e7{/jobs/job/json,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@42e0405a{/stages,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@776c261e{/stages/json,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@3a9ad1e6{/stages/stage,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@3d80dc1d{/stages/stage/json,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@51792faa{/stages/pool,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@7b5b49fa{/stages/pool/json,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@275320e{/storage,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@392e7669{/storage/json,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@21321a99{/storage/rdd,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@783dc{/storage/rdd/json,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@2bc93490{/environment,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@619e82be{/environment/json,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@5049bac6{/executors,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@6cecca70{/executors/json,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@e630ec9{/executors/threadDump,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@1b7df6c9{/executors/threadDump/json,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@6fff0ea{/static,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@1d5b2088{/,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@1939ec14{/api,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@332ff00f{/jobs/job/kill,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@62bba62a{/stages/stage/kill,null,AVAILABLE,@Spark}2019-03-27 19:04:30 INFO SparkUI:54 - Bound SparkUI to 0.0.0.0, and started at http://192.168.1.100:40422019-03-27 19:04:30 INFO Executor:54 - Starting executor ID driver on host localhost2019-03-27 19:04:31 INFO Utils:54 - Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 56646.2019-03-27 19:04:31 INFO NettyBlockTransferService:54 - Server created on 192.168.1.100:566462019-03-27 19:04:31 INFO BlockManager:54 - Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy2019-03-27 19:04:31 INFO BlockManagerMaster:54 - Registering BlockManager BlockManagerId(driver, 192.168.1.100, 56646, None)2019-03-27 19:04:31 INFO BlockManagerMasterEndpoint:54 - Registering block manager 192.168.1.100:56646 with 366.3 MB RAM, BlockManagerId(driver, 192.168.1.100, 56646, None)2019-03-27 19:04:31 INFO BlockManagerMaster:54 - Registered BlockManager BlockManagerId(driver, 192.168.1.100, 56646, None)2019-03-27 19:04:31 INFO BlockManager:54 - Initialized BlockManager: BlockManagerId(driver, 192.168.1.100, 56646, None)2019-03-27 19:04:31 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@1c98b669{/metrics/json,null,AVAILABLE,@Spark}2019-03-27 19:04:31 INFO SparkContext:54 - Starting job: collect at /Users/calvin/pyspark_project/spark_01.py:122019-03-27 19:04:31 INFO DAGScheduler:54 - Got job 0 (collect at /Users/calvin/pyspark_project/spark_01.py:12) with 2 output partitions2019-03-27 19:04:31 INFO DAGScheduler:54 - Final stage: ResultStage 0 (collect at /Users/calvin/pyspark_project/spark_01.py:12)2019-03-27 19:04:31 INFO DAGScheduler:54 - Parents of final stage: List()2019-03-27 19:04:31 INFO DAGScheduler:54 - Missing parents: List()2019-03-27 19:04:31 INFO DAGScheduler:54 - Submitting ResultStage 0 (PythonRDD[1] at collect at /Users/calvin/pyspark_project/spark_01.py:12), which has no missing parents2019-03-27 19:04:31 INFO MemoryStore:54 - Block broadcast_0 stored as values in memory (estimated size 4.3 KB, free 366.3 MB)2019-03-27 19:04:31 INFO MemoryStore:54 - Block broadcast_0_piece0 stored as bytes in memory (estimated size 2.9 KB, free 366.3 MB)2019-03-27 19:04:31 INFO BlockManagerInfo:54 - Added broadcast_0_piece0 in memory on 192.168.1.100:56646 (size: 2.9 KB, free: 366.3 MB)2019-03-27 19:04:31 INFO SparkContext:54 - Created broadcast 0 from broadcast at DAGScheduler.scala:11612019-03-27 19:04:31 INFO DAGScheduler:54 - Submitting 2 missing tasks from ResultStage 0 (PythonRDD[1] at collect at /Users/calvin/pyspark_project/spark_01.py:12) (first 15 tasks are for partitions Vector(0, 1))2019-03-27 19:04:31 INFO TaskSchedulerImpl:54 - Adding task set 0.0 with 2 tasks2019-03-27 19:04:31 INFO TaskSetManager:54 - Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 7852 bytes)2019-03-27 19:04:31 INFO TaskSetManager:54 - Starting task 1.0 in stage 0.0 (TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL, 7852 bytes)2019-03-27 19:04:31 INFO Executor:54 - Running task 1.0 in stage 0.0 (TID 1)2019-03-27 19:04:31 INFO Executor:54 - Running task 0.0 in stage 0.0 (TID 0)2019-03-27 19:04:32 INFO PythonRunner:54 - Times: total = 390, boot = 383, init = 7, finish = 02019-03-27 19:04:32 INFO PythonRunner:54 - Times: total = 390, boot = 378, init = 12, finish = 02019-03-27 19:04:32 INFO Executor:54 - Finished task 0.0 in stage 0.0 (TID 0). 1437 bytes result sent to driver2019-03-27 19:04:32 INFO Executor:54 - Finished task 1.0 in stage 0.0 (TID 1). 1440 bytes result sent to driver2019-03-27 19:04:32 INFO TaskSetManager:54 - Finished task 0.0 in stage 0.0 (TID 0) in 489 ms on localhost (executor driver) (1/2)2019-03-27 19:04:32 INFO TaskSetManager:54 - Finished task 1.0 in stage 0.0 (TID 1) in 470 ms on localhost (executor driver) (2/2)2019-03-27 19:04:32 INFO TaskSchedulerImpl:54 - Removed TaskSet 0.0, whose tasks have all completed, from pool2019-03-27 19:04:32 INFO PythonAccumulatorV2:54 - Connected to AccumulatorServer at host: 127.0.0.1 port: 566472019-03-27 19:04:32 INFO DAGScheduler:54 - ResultStage 0 (collect at /Users/calvin/pyspark_project/spark_01.py:12) finished in 0.702 s2019-03-27 19:04:32 INFO DAGScheduler:54 - Job 0 finished: collect at /Users/calvin/pyspark_project/spark_01.py:12, took 0.763967 s[1, 2, 3, 4, 5]2019-03-27 19:04:32 INFO AbstractConnector:318 - Stopped Spark@663f2e4{HTTP/1.1,[http/1.1]}{0.0.0.0:4042}2019-03-27 19:04:32 INFO SparkUI:54 - Stopped Spark web UI at http://192.168.1.100:40422019-03-27 19:04:32 INFO MapOutputTrackerMasterEndpoint:54 - MapOutputTrackerMasterEndpoint stopped!2019-03-27 19:04:32 INFO MemoryStore:54 - MemoryStore cleared2019-03-27 19:04:32 INFO BlockManager:54 - BlockManager stopped2019-03-27 19:04:32 INFO BlockManagerMaster:54 - BlockManagerMaster stopped2019-03-27 19:04:32 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint:54 - OutputCommitCoordinator stopped!2019-03-27 19:04:32 INFO SparkContext:54 - Successfully stopped SparkContext2019-03-27 19:04:33 INFO ShutdownHookManager:54 - Shutdown hook called2019-03-27 19:04:33 INFO ShutdownHookManager:54 - Deleting directory /private/var/folders/4l/zdr5yt953pl36zwtl7dk9kfr0000gn/T/spark-ff2cab87-726c-494d-adb6-8fedde89aaef2019-03-27 19:04:33 INFO ShutdownHookManager:54 - Deleting directory /private/var/folders/4l/zdr5yt953pl36zwtl7dk9kfr0000gn/T/spark-a4cd4f93-ffbb-48cd-8356-f3dbd62ef1d4/pyspark-3ebf0ccb-c270-4348-a94b-1c78773dd4ca2019-03-27 19:04:33 INFO ShutdownHookManager:54 - Deleting directory /private/var/folders/4l/zdr5yt953pl36zwtl7dk9kfr0000gn/T/spark-a4cd4f93-ffbb-48cd-8356-f3dbd62ef1d4
2、Spark Core 核心RDD常用算子编程详解
2.1、RDD 常用操作
RDDs support two types of operations: transformations, which create a new dataset from an existing one, and actions, which return a value to the driver program after running a computation on the dataset.
- 转换:从已经存在的RDD中生成新的RDD
- 动作:对RDD进行计算返回结果
- map 是一个转换
- collect 是一个动作
- 所有的transformations都是lazy的,遇到action之后才会进行计算并返回结果
- action才会触发计算
2.2、Transformation算子
- map 和 filter
def my_filter():data = [1, 2, 3, 4, 5]rdd1 = sc.parallelize(data)map_rdd = rdd1.map(lambda x: x * 2)filter_rdd = map_rdd.filter(lambda x: x > 5)print(filter_rdd.collect())print(sc.parallelize(data).map(lambda x: x * 2).filter(lambda x: x > 5).collect())
- flap_map
def my_flat_map():data = ["hello spark", "hello world", "hello world"]rdd = sc.parallelize(data)print(rdd.flatMap(lambda line: line.split(" ")).collect())print(rdd.flatMap(lambda line: line.split(" ")).map(lambda x: (x, 1)).collect())
- group by key
def my_group_by():data = ["hello spark", "hello world", "hello world"]rdd = sc.parallelize(data)group_rdd = rdd.flatMap(lambda line: line.split(" ")).map(lambda x: (x, 1)).groupByKey()print(group_rdd.map(lambda x: {x[0]: sum(x[1])}).collect())
使用groupbykey方式的world count
def word_count():rdd = sc.textFile("readme.md")flat_map_rdd = rdd.flatMap(lambda line: line.split(" "))res_rdd = flat_map_rdd.map(lambda x: (x, 1)).groupByKey().map(lambda x: {x[0]: sum(x[1])})print(res_rdd.collect())
- my reduce by key
def my_reduce_by():data = ["hello spark", "hello world", "hello world"]rdd = sc.parallelize(data)map_rdd = rdd.flatMap(lambda line: line.split(" ")).map(lambda x: (x, 1))reduce_rdd = map_rdd.reduceByKey(lambda x, y: x + y)# sort by key,sort by value 可以使用两次map,将value转换到key上去reduce_rdd = reduce_rdd.map(lambda x: (x[1], x[0])).sortByKey(ascending=False).map(lambda x: (x[1], x[0]))print(reduce_rdd.collect())
- my union
def my_union():a = sc.parallelize([[1, 2, 3], [3, 4, 5]])b = sc.parallelize([[3, 4, 5], [1, 2, 3]])union_rdd = a.union(b).flatMap(lambda x: list(x))print(union_rdd.collect())
- distinct
def my_distinct():a = sc.parallelize([[1, 2, 3], [3, 4, 5]])b = sc.parallelize([[3, 4, 5], [1, 2, 3]])union_rdd = a.union(b).flatMap(lambda x: list(x))distinct_rdd = union_rdd.distinct()print(distinct_rdd.map(lambda x: (x, 1)).sortByKey().map(lambda x: x[0]).collect())
- join
def my_join():x = sc.parallelize([("a", 1), ("b", 4)])y = sc.parallelize([("a", 2), ("a", 3)])print(x.join(y).collect())print(x.leftOuterJoin(y).collect())print(x.fullOuterJoin(y).collect())
2.3、Action算子
def my_action():data = list(range(1, 11))rdd = sc.parallelize(data)print(rdd.collect())print(rdd.max(), rdd.min())print(rdd.take(3))print(rdd.reduce(lambda x, y: x + y))rdd.foreach(lambda x: print(x))
2.4、Spark RDD 实战
- 词频统计
- topN
- 平均数
3、Spark运行模式
3.1、local
pyspark最简单,使用 pip install pyspark 就能在本地进行测试开发
3.2、standalone
http://spark.apache.org/docs/latest/spark-standalone.html
3.3、yarn
http://spark.apache.org/docs/latest/running-on-yarn.html
4、Spark Core 进阶(面试关键)
4.1、Spark核心概念
http://spark.apache.org/docs/latest/cluster-overview.html

4.2、Spark运行架构及注意事项(非常重要)
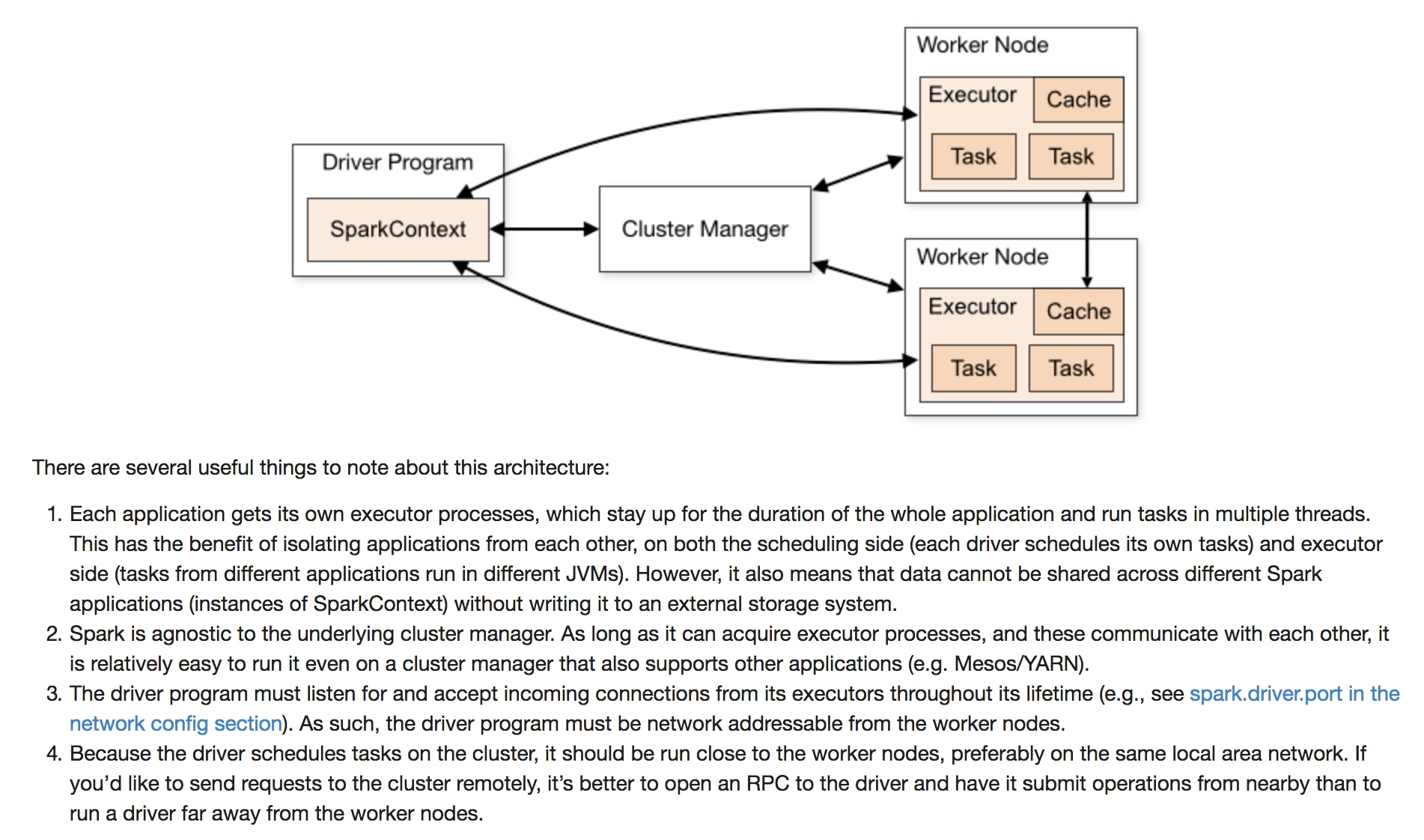
4.3、Spark和Hadoop重要概念区分
Hadoop
- 一个MR程序 = 一个Job
- 一个Job = 1 到 N 个Task(Map/Reduce)
- 一个Task对应一个进程
- Task运行时开启进程,Task执行完毕时销毁进程,对多个Task来说,开销比较大的(即使你能通过JVM共享)
Spark
- Application = Driver(main方法,创建SparkContext) + Executors
- 一个Application = 0到N 个Job
- 一个Job = 一个Action
- 一个Job = 1到N个Stage
- 一个Stage = 1到N个Task
- 一个Task对应一个线程,多个Task可以以并行的方式在一个Executor中
4.4、Spark Cache
http://spark.apache.org/docs/latest/rdd-programming-guide.html#rdd-persistence
- cache和transformations一样是lazy 没有遇到action是不会提交作业到spark上运行
- cache本质上是执行persis(),指定storageLevel=StorageLevel.Memory_Only
- 如果一个rdd在后续的操作中会被用到,建议使用Cache
- 不缓存的场景,有多少次action就会读取多少次disk上的数据,缓存能减少io
- 使用LRU算法进行缓存删除
4.4、Spark Lineage
transformations产生的RDD里的partition和之前的RDD里的partition能进行一一对应,如果其中一个partition发生了数据丢失能很方便从源partition进行计算恢复数据
4.4、Spark Dependency
- 窄依赖:父rdd的分区至多被子rdd用一次,map,filter,union,join with inputs co-partition
- 宽依赖:一个父RDD的的数据被多个子RDD使用,groupBuKey on non-partitioned data,join with inputs not co-partition
shuffle操作是一个非常昂贵的操作
- 所有的宽依赖对应的 ByKey和join操作都会产生shuffle
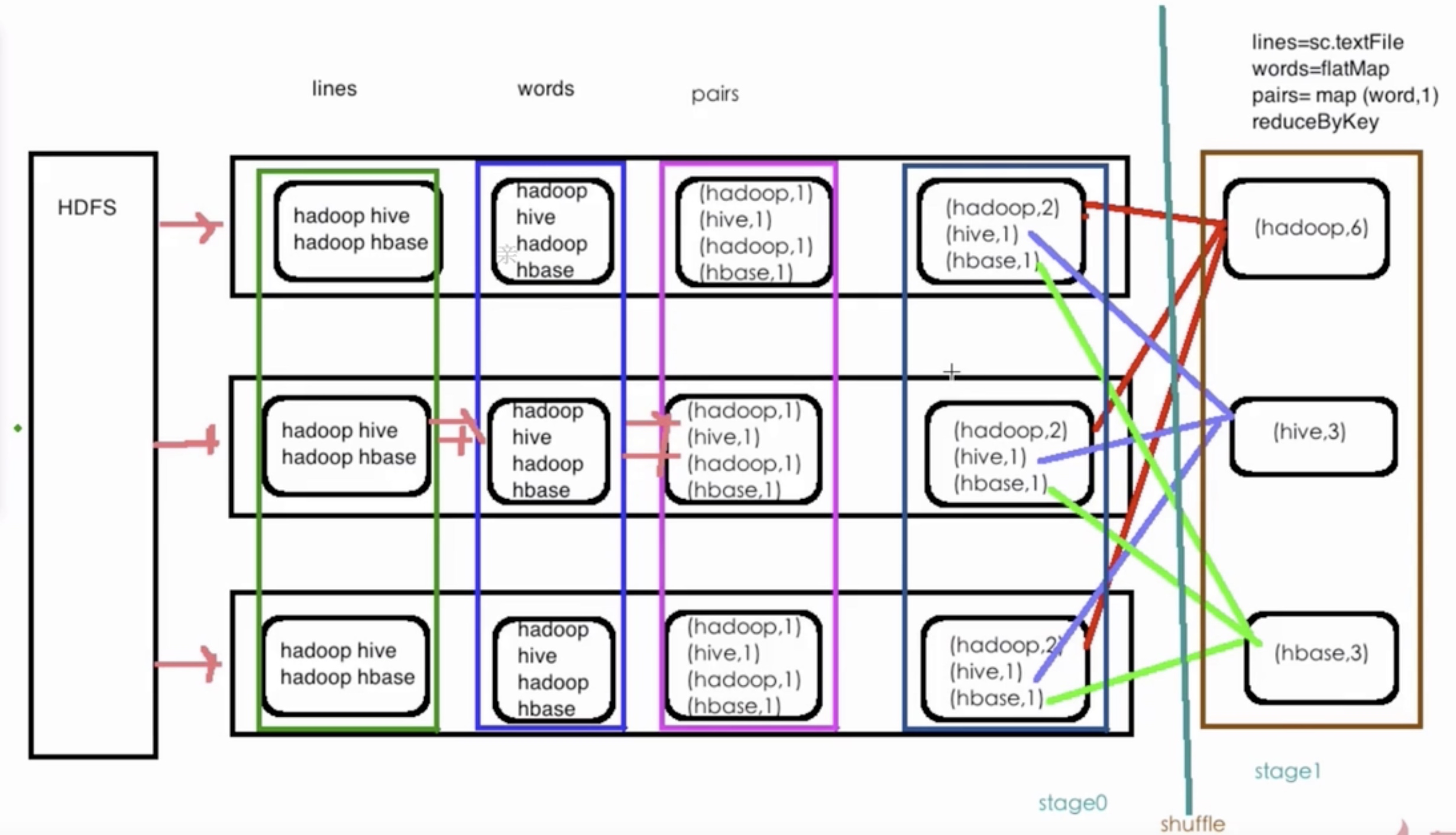
5、Spark优化
http://spark.apache.org/docs/latest/tuning.html
5.1、序列化
http://spark.apache.org/docs/latest/tuning.html#serialized-rdd-storage
5.2、内存管理
- 执行内存:shuffle, joins, sorts, aggregations
- 存储内存:persist, cache
两者公用一个内存范围,执行内存不够的时候回进行内存剔除,但是存储内存可以设置一个最小阈值
需要掌握的:
- 内存管理的百分比
- 如何知道一个对象占用多少内存?
- 1)创建一个RDD放到缓存里去,webUI里可以看
- 2)使用SizeEstimator’s estimate方法
- 太大的RDD存储的时候可使用序列化,时间换空间
http://spark.apache.org/docs/latest/tuning.html#memory-management-overview
http://spark.apache.org/docs/latest/configuration.html#memory-management
5.3、广播变量
广播变量会将变量直接缓存在每一个机器上,而不用每次分发task的时候都copy一个副本
http://spark.apache.org/docs/latest/tuning.html#broadcasting-large-variables
对大的RDD进行广播,tasks larger than about 20 KB are probably worth optimizing.
5.4、数据本地性
http://spark.apache.org/docs/latest/tuning.html#data-locality
数据节点和计算节点不在一起的时候,需要移动计算而不是移动数据
数据和代码距离从最近到最远:
- 在同一个JVM,最好的
- 在同一个节点,数据需要在两个进程之间传输
- 数据能快速访问到,没有本地性可言
- 数据在相同的机架
- 网络上的其他数据
http://spark.apache.org/docs/latest/configuration.html#scheduling
默认的本地化spark.locality.wait = 3s,如果集群的本地化较差,可以适当调大参数
6、Spark SQL
6.1、Spark SQL 架构
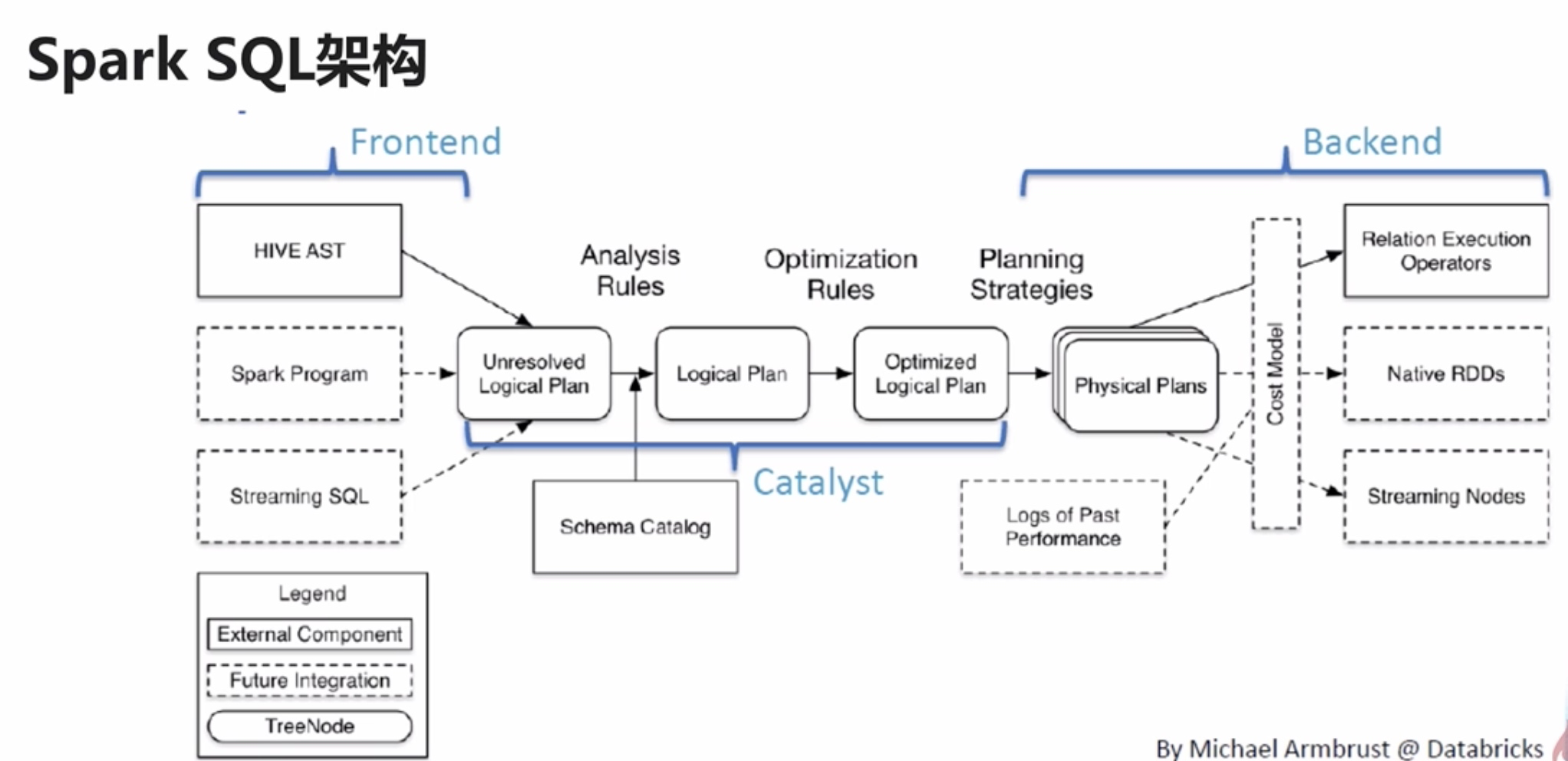
- 前端:负责数据输入
- Catalyst:接收前端的输入,对执行计划进行解析和优化。几乎所有的Spark优化都是在Catalyst中进行
- 后端:对物理计划进行优化,生成Spark作业
6.2、DataFrame
因为已经会了pandas DataFrame,两年前自己也使用Spark SQL 做过报表,所以这一章节学起来非常的快
主要看
http://spark.apache.org/docs/latest/sql-getting-started.html#running-sql-queries-programmatically
练习源码
from pyspark import Rowfrom pyspark.sql import SparkSessionimport pandas as pd# basicfrom pyspark.sql.types import StructField, StringType, IntegerType, StructType
从json中生成df
def json_df(_spark):# from jsondf = _spark.read.json("resource/people.json")df.show()
从pandas DataFrame 中生成df
def pdf_to_df(_spark):data_list = [{"name": "Michael"}, {"name": "Andy", "age": 30}, {"name": "Justin", "age": 19}]df = _spark.createDataFrame(pd.DataFrame(data_list))df.show()
rdd 和 df 互相转换
def rdd_to_df(_spark):sc = _spark.sparkContextlines = sc.textFile("resource/people.txt")parts = lines.map(lambda x: x.split(","))parts_row = parts.map(lambda x: Row(name=x[0], age=int(x[1])))df = _spark.createDataFrame(parts_row)df.createOrReplaceTempView("schema_people")_spark.sql("select * from schema_people").show()df.printSchema()df_teenager = _spark.sql("select * from schema_people where age > 13 and age <= 19")df_teenager.show()rdd_df = df.rdd.map(lambda x: "name={}".format(x.name))print(rdd_df.collect())
指定schema
def specify_schema(_spark):sc = _spark.sparkContextlines = sc.textFile("resource/people.txt")parts = lines.map(lambda x: x.split(","))people = parts.map(lambda x: (x[0], int(x[1])))# 官方代码schema_string = "name age"fields = [StructField(field_name, StringType(), True) for field_name in schema_string.split()]schema = StructType(fields)df = _spark.createDataFrame(people, schema)df.show()df.printSchema()# 手写schema,主要如果需要执行类型为int,需要rdd中的数据已经为int类型,否则会报错schema = StructType([StructField("name", StringType(), True), StructField("age", IntegerType(), True)])df = _spark.createDataFrame(people, schema)df.show()df.printSchema()df["age"] = df["age"].astype(StringType())df.schemadf.printSchema()
7、Spark Streaming
http://spark.apache.org/docs/latest/streaming-programming-guide.html
7.1、Spark Streaming 概述
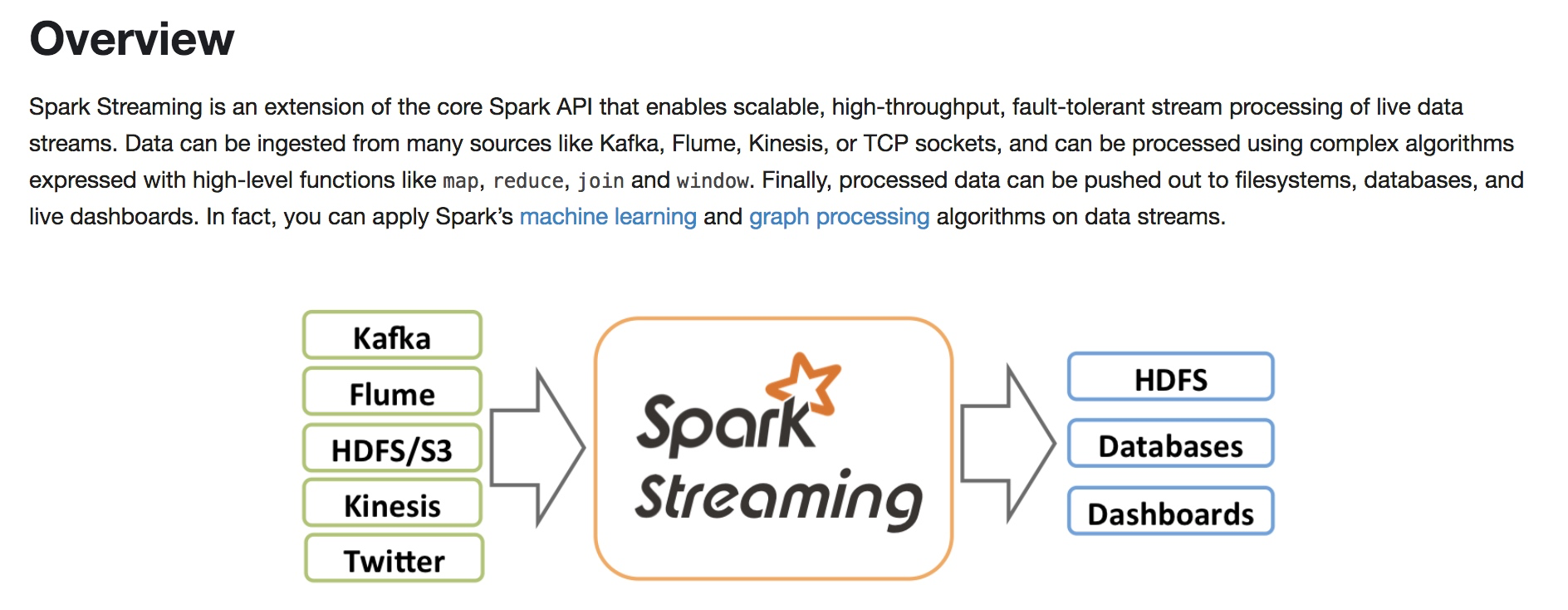
Spark Streaming 是
- 基于core Spark API
- 可伸缩
- 高吞吐
- 可容错
- 支持众多的数据源
- 可以使用Spark中的 high-level 函数如 map 、 reduce 、 join 、 window 表达的复杂的算法
- 可以输出到文件系统、数据库、实时看板
- 可使用在 Streaming中使用Spark的机器学习库和图形算法库处理数据
- 的一个实时数据流处理的Spark拓展
Spark Streaming 的工作流程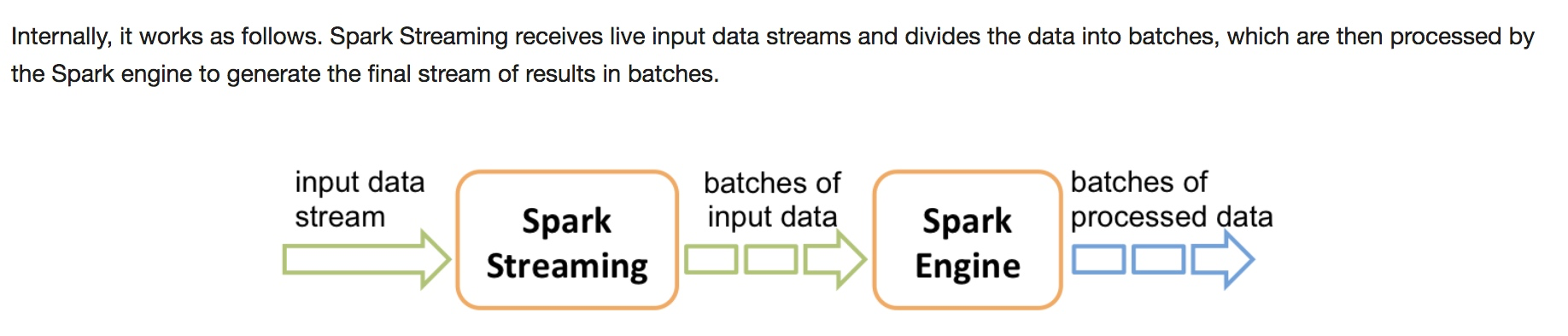
- 接收数据
- 把数据拆分成
batches batches被Spark Engine处理- 产生结果
batches - Spark Core的核心概念是RDD,Spark Streaming的核心概念是 DStream(discretized stream)
- DStreams 可以从Kafka, Flume, Kinesis等外部流创建,也可以从其他的DStreams创建
- DStreams本质上是一系列的 RDD
7.2、常用实时流处理对比
| 应用 | 特性 |
|---|---|
| Storm | 真正的实时流处理 |
| Spark Streaming | mini batch 操作,微批处理,使用Spark一栈式解决 |
| Flink | 实时流处理(DataStream),支持基于实时流的批处理(DataSet) |
| Kafka Stream | 分析处理Kafka中的数据 |
7.3、DStream
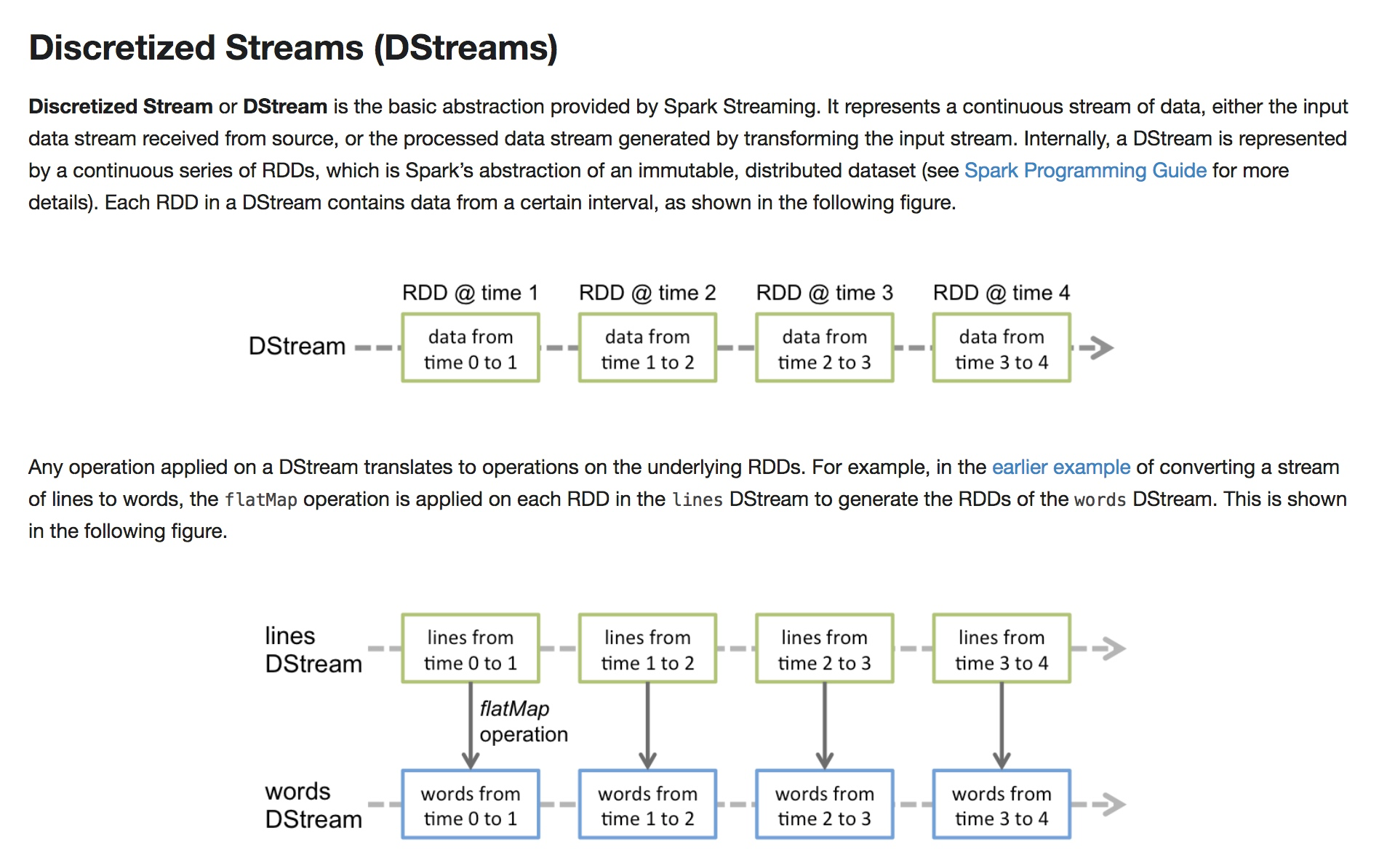
- 是连续的流数据的抽象结构
- 输入输出都是流数据
- 本质上是一系列的RDD
- 每个RDD都是固定的时间间隔获取到的数据
- 应用在DStream上的操作,都是应用在RDD上的
8、Structured Streaming
是基于Spark SQL engin的一种流式计算引擎。Structured Streaming 之于 Spark SQL,相当于 Spark Streaming 之于 Spark RDD。
9、总结
入门知识就看到这里了,具体的一些问题可以单独细细讨论,每一个环节都值得深入了解。

若有收获,就点个赞吧
0 人点赞
