一、Gulp的基本使用
在项目的根目录安装Gulp的开发依赖
根目录下创建gulpfile.js作为项目入口文件,用于编写需要gulp自动执行的构建任务
接着使用gulp提供的命令行cli来运行构建任务
$ yarn init --yes// 初始化package.json$ yarn add gulp --dev// 安装gulp$ code gulpfile.js// 创建gulpfile入口文件,定义需要执行的任务--------------------- 分割线 ---------------------// gulpfile.js// 导出的函数都会作为 gulp 任务// exports.foo = () => {// console.log('foo task working~')// }$ yarn gulp foo// gulp 的任务函数都是异步的// 可以通过调用回调函数标识任务完成exports.foo = done => {console.log('foo task working~')done() // 标识任务执行完成}// default 是默认任务// 在运行是可以省略任务名参数exports.default = done => {console.log('default task working~')done()}// v4.0 之前需要通过 gulp.task() 方法注册任务const gulp = require('gulp')gulp.task('bar', done => {console.log('bar task working~')done()})
二、Gulp创建组合任务
并行任务和串行任务
const { series, parallel } = require('gulp')const task1 = done => {setTimeout(() => {console.log('task1 working~')done()}, 1000)}const task2 = done => {setTimeout(() => {console.log('task2 working~')done()}, 1000)}const task3 = done => {setTimeout(() => {console.log('task3 working~')done()}, 1000)}// 让多个任务按照顺序依次执行exports.foo = series(task1, task2, task3)// 让多个任务同时执行exports.bar = parallel(task1, task2, task3)
三、Gulp异步任务的三种方式
gulp中的任务都是异步任务,也就是我们在JS当中经常提到的异步函数, 当我们去调用异步函数时,我们是无法明确知道调用是否完成的,都是通过函数内部通过回调或者事件的方式通知外部这个函数执行完成,那么在异步任务中我们也面临如何通知Gulp完成情况这样一个问题。
可以通过回调,promise,async、await,stream
const fs = require('fs')exports.callback = done => {console.log('callback task')done()}exports.callback_error = done => {console.log('callback task')done(new Error('task failed'))}exports.promise = () => {console.log('promise task')return Promise.resolve()}exports.promise_error = () => {console.log('promise task')return Promise.reject(new Error('task failed'))}const timeout = time => {return new Promise(resolve => {setTimeout(resolve, time)})}exports.async = async () => {await timeout(1000)console.log('async task')}//任务函数当中返回一个stream对象exports.stream = () => {const read = fs.createReadStream('yarn.lock')// 创建一个读取文件的文件流const write = fs.createWriteStream('a.txt')// 创建一个写入文件的文件流read.pipe(write)// read读取到的内容导入到write,相当于复制return read}// exports.stream = done => {// const read = fs.createReadStream('yarn.lock')// const write = fs.createWriteStream('a.txt')// read.pipe(write)// read.on('end', () => {// done()// })// }
四、Gulp构建过程核心工作原理
构建过程大多数情况下都是将文件读出来然后进行转换再写入到另一个位置,以前我们手动操作,如今可以通过代码自动执行
简单来讲,Gulp就是基于流的构建系统,为什么构建系统使用的是文件流的方式,这是因为Gulp为了实现构建管道的概念,这样在使用扩展插件的时候就可以有统一方式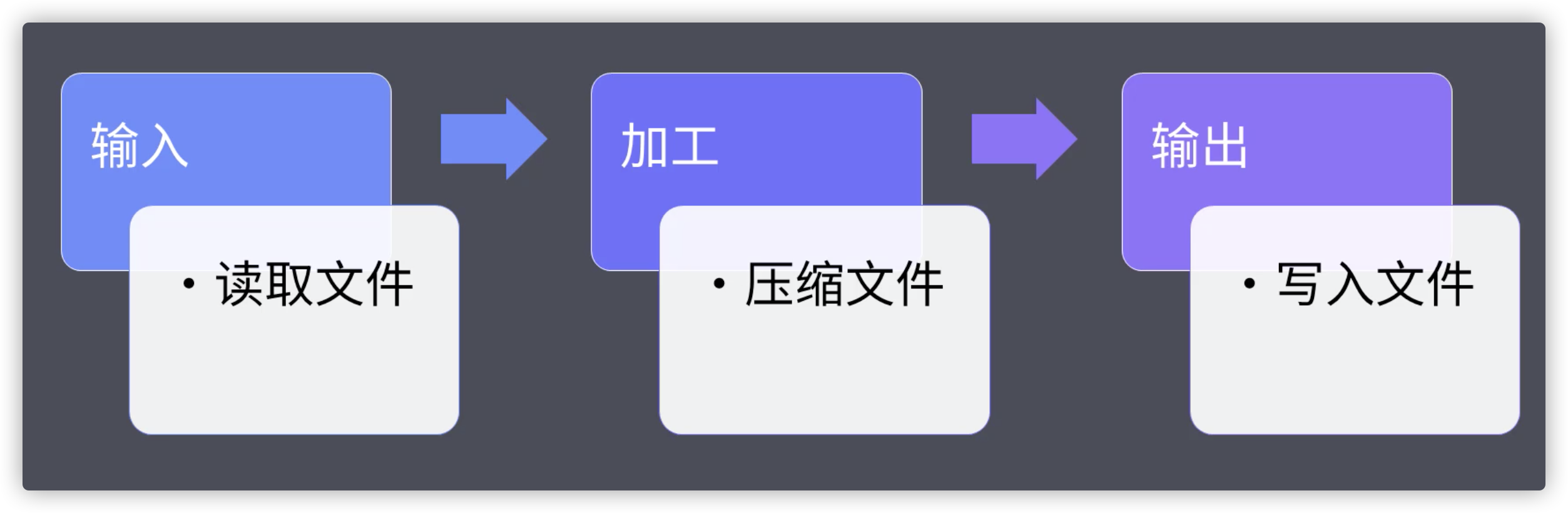
以下代码是通过底层Node的API来实现基于文件流的构建过程
const fs = require('fs')const { Transform } = require('stream')exports.default = () => {// 文件读取流const readStream = fs.createReadStream('normalize.css')// 文件写入流const writeStream = fs.createWriteStream('normalize.min.css')// 文件转换流const transformStream = new Transform({// 核心转换过程transform: (chunk, encoding, callback) => {// 通过chunk => 读取流中读取到的内容(Buffer)const input = chunk.toString()// 取得的是字节数组用toString转化为字符串const output = input.replace(/\s+/g, '').replace(/\/\*.+?\*\//g, '')// 再对转换得来的字符串替换掉空白字符和注释callback(null, output)// callback函数是错误优先的回调函数,没有错误第一个参数传入null}})return readStream.pipe(transformStream) // 转换.pipe(writeStream) // 写入}
五、Gulp文件操作API+插件的使用
通过Gulp创建构建任务的流程如下:
- 先通过src方法创建一个读取流
- 再借助于插件提供的转换流来实现文件加工
- 最后通过dist方法创建一个写入流,从而写入到目标文件
const { src, dest } = require('gulp')// 载入需要的方法const cleanCSS = require('gulp-clean-css')// CSS压缩插件的安装// yarn add gulp-clean-css --devconst rename = require('gulp-rename')// 压缩插件安装// yarn add gulp-rename --devexports.default = () => {return src('src/*.css')// src方法创建读取流,入参是指定读取的文件路径.pipe(cleanCSS())// 导入到压缩转换流当中.pipe(rename({ extname: '.min.css' }))// 导入到重命名扩展名转换流当中.pipe(dest('dist'))// 导入到dest创建的写入流,指定写入的目标目录}
// 插件的安装命令行// CSS压缩插件yard add glup-clean-css --dev// 指定文件重命名的扩展名插件yarn add glup-rename --dev
六、基于Gulp完成的网页应用自动化构建工作流案例
02-01-03-13-zce-gulp-extract├─ .gitignore├─ LICENSE├─ package.json├─ pages.config.js├─ public // 该目录是开发网页应用程序当中不需要加工直接拷贝到最终生成的文件夹当中的文件│ └─ favicon.ico├─ README.md└─ src // 该目录是开发阶段编写代码的目录,该目录下的文件都会被构建或者说都会经过转换最终放到我们生成的文件夹当中├─ about.html├─ assets│ ├─ fonts│ │ ├─ pages.eot│ │ ├─ pages.svg│ │ ├─ pages.ttf│ │ └─ pages.woff│ ├─ images // 开发过程中用的图片和字体文件需要自动的被压缩,图片中存在二进制的信息,在我们的生产环境中没有必要│ │ ├─ brands.svg│ │ └─ logo.png│ ├─ scripts // 完成网页脚本的时候通过ES6的方式去编写,在转换的过程中自动转化为Es5的方式│ │ └─ main.js│ └─ styles // 通过sass的方式编写样式│ ├─ demo.scss│ ├─ main.scss│ ├─ _icons.scss│ └─ _variables.scss├─ features.html├─ index.html // html文件是通过模板的方式去编写的,我们可以使用布局页和部分页的概念├─ layouts│ └─ basic.html└─ partials├─ footer.html├─ header.html└─ tags.html
第一步安装Gulp
$ yarn add gulp --dev
第二步样式编译
创建gulpfile.js文件并在改文件中定义任务
先定义一个名为style的私有任务也称之为私有函数,我们可以通过module.export选择性的导出函数
内部需要将通过return来让gulp获知流的状态
借着安装sass
安装的指令为
$ yarn add gulp-sass --dev
首先要注意的是使用src指定读取路径时要传入第二个参数来确保转换后文件路径的完整性
其次是指定要处理的文件目录下的sass文件名若是以下划线开头的话会被默认视为被主文件所依赖的文件将不会被编译转换
另外直接使用sass的话,转换得到的css样式文件的收尾大括号将会与我们日常的开发习惯不太一样是半展开的,我们可以在sass()中写入outputStyle:’expented’,使得转换得到的css是全展开的
const {src,dest} = require('gulp')const sass = require('gulp-sass')const style = () => {return src('src/assets/styles/*.scss', {base: 'src'}).pipe(sass({outputStyle:'expented'})).pipe(dest('dist'))}module.exports = {style}
第三步脚本编译
定义脚本编译任务
要关注有以下几点:
指定读取路径看情况使用通配符
设置基准路径保留原始目录结构
通过dest设定dist的导出编译后的文件目录路径
指定好输入输出后在进行相应的脚本编译模块的安装以及使用
$ yarn add gulp-babel --dev
值得注意的是单独安装gulp-babel只是唤起babel/core这个模块的转换过程
它并不像sass一样自动安装node-sass核心转换模块,我们需要手动安装babel的核心转换模块
而且还要注意的是Babel只是ES的一个转换平台,平台是不做任何事情的,具体的转换时通过Babel中的插件来实现的,这里的preset就是一个插件的集合
所以在使用Babel转换的时候必须要指定插件版本
$ yarn add @babel/core @babel/preset-env --dev// 这里我们还加入了@babel/preset-env,这使得我们将会对Es的所有新特性进行转换
最终的配置如下
const { src, dest } = require("gulp");const babel = require("gulp-babel");const script = () => {return src("src/assets/scripts/*.js", { base: "src" }).pipe(babel({ presets: ["@babel/preset-env"] })).pipe(dest("dist"));};module.exports = {script,};
第四部模板文件编译
这里说的模板文件指的就是HTML文件
为了把页面当中重用的地方抽象出来,我们可以使用模板引擎swig
$ yarn add gulp-swig --dev
安装了该插件过后,我们就可以正常载入该插件
这里我们要注意的是,该目录下有的多个子目录中都存在我们需要处理的html的话,我么需要使用通配符进行匹配
并且要为模板文件中的可变更数据提供数据
const { src, dest } = require("gulp");const swig = require("gulp-swig");const page = () => {return src('src/*.html', { base: 'src' }).pipe(plugins.swig({ data, defaults: { cache: false } })) // 防止模板缓存导致页面不能及时更新.pipe(dest('dist'))}module.exports = {page,};
最后我们使用前面提到的组合任务来将目前使用到的几个编译插件整合起来一起运行,这里因为三者没有关联可以同时运行,所以我们使用parallel
$ yarn gulp compile
const compile = parallel(style, script, page)module.exports = {compile};
第五步图片和字体文件转换
$ yarn add gulp-imagemin --dev
const imagemin = require('gulp-imagemin')const image = () => {return src('src/assets/images/**', { base: 'src' }).pipe(plugins.imagemin()).pipe(dest('dist'))}const font = () => {return src('src/assets/fonts/**', { base: 'src' }).pipe(plugins.imagemin()).pipe(dest('dist'))}module.exports = {image,font};
第六步其他文件及文件清除
const extra = () => {return src('public/**', { base: 'public' }).pipe(dest('dist'))}const build = parallel(compile,extra)module.exports = {build};
我们这里再次使用组合的方式来合并src目录下与非src目录下的拷贝构建
*额外操作,自动清除dist目录下的所有文件
使用的模块不是gulp的插件,他只是可以在gulp构建项目中使用
$ yarn add del --dev
为什么可以使用这个非gulp插件呢
原因在于我们在使用gulp去定义任务的时候
gulp的任务并不是一定需要通过src去检索文件流最终pipe到dist当中
我们也可以通过自己写代码去实现这个构建过程
例如这个del模块就可以帮助我们自动去删除指定的文件,而且他是一个promise方法
gulp任务是支持promise模式的
我们可以这样操作
const { src, dest, parallel, series, watch } = require('gulp')const del = require('del')const clean = () => {return del(['dist'])}const build = series(clean,parallel(compile,extra))
del方法返回的是一个Promise,所以clean任务完成过后会自动的标记完成
clean任务要放在build之前
使用series来确保clean先执行在运行build任务
第七步自动加载插件
$ yarn add gulp-load-plugins --dev
通过手动require的方式载入插件的话,会很麻烦,这里我们使用gulp-load-plugins这个依赖
const loadPlugins = require('gulp-load-plugins')
这里导出的是一个方法loadPlugins,它返回一个plugins的对象,所有的插件都会成为这个对象的属性,命名的方式是将’glup-‘删除
第八步热更新开发服务器
使用热更新开发服务器进行开发调试,我们可以通过gulp去启动和管理开发服务器
后续可以去配合构建任务在代码修改过后自动去编译和自动去刷新浏览器页面,这样可以大大提高开发的效率,可以有效减少开发阶段的重复操作
首先我们需要去安装一个browser-sync的模块
$ yarn add browser-sync --dev
该模块会提供一个开发服务器
相比我们以往使用的普通服务器,browser-syn具有更强大的功能,支持代码修改过后自动热更新到浏览器刷新页面
该模块和del模块类似,它不属于gulp插件,我们只是通过gulp去管理它,所以我们需要单独去引入这个模块
该模块提供了一个方法去创建服务器,我们需要定义一个任务去启动它
在启动的任务中需要先使用init去初始化配置
接着设置server来配置网站的根目录
const browserSync = require('browser-sync')const bs = browserSync.create()const serve = () => {watch('src/assets/styles/*.scss', style)watch('src/assets/scripts/*.js', script)watch('src/*.html', page)// watch('src/assets/images/**', image)// watch('src/assets/fonts/**', font)// watch('public/**', extra)watch(['src/assets/images/**','src/assets/fonts/**','public/**'], bs.reload)bs.init({notify: false,// 关闭链接提示port: 2080,// 指定端口// open: false,// 关闭自动打开浏览器的行为// files: 'dist/**',// 指定检测的目录server: {baseDir: ['temp', 'src', 'public'],routes: {'/node_modules': 'node_modules'// 左侧是匹配前缀,右侧是指定目录}// routes会优先于baseDir}})}
在编译的过程当中我们没有去处理node_modules的拷贝,我们只对自己编写的源代码进行了编译
通过添加特殊的路由来对下划线node_modules的网页请求指定到同一个目录文件下
第九步监事变化以及构建优化
在src目录下源代码修改过后自动的去编译
这里我们需要用到gulp提供的第二个API watch
watch会自动监测文件路径的通配符,再根据文件的变化,再去决定是否需要重新执行某个任务
watch接收两个参数,第一个就是gulp也就是通配符,监视产生构建任务的路径
第二个参数指定的是对应的任务函数
指的注意的是,在运行sever命令之前,我们应该先去执行build,原因是得先通过build先生成dist目录
「这里可能回应为swig模板迎请缓存的机制导致页面不会变化,此时需要额外将swig选项中的cache设置为false」
除了对html、js以及sass文件的监测在开发调试时是有意义的,其他的监测编译操作会添加成本
第十步useref文件引用处理
useref会自动处理html中的构建注释,实现引用文件的压缩合并
$ yarn add gulp-useref --dev
第十一步文件压缩
$ yarn add gulp-htmlmin gulp-uglify gulp-clean-css --dev$ yarn add gulp-if --dev
读取流中存在不同类型的操作需要使用gulp-if,判断类型执行指定转换流
读写同步会导致冲突产生
*htlmin({collapseWhitespace:true})折叠html所有的空白字符
const useref = () => {return src('temp/*.html', { base: 'temp' }).pipe(plugins.useref({ searchPath: ['temp', '.'] }))// html js css.pipe(plugins.if(/\.js$/, plugins.uglify())).pipe(plugins.if(/\.css$/, plugins.cleanCss())).pipe(plugins.if(/\.html$/, plugins.htmlmin({collapseWhitespace: true,// 折叠HTML所有的空白字符minifyCSS: true,// 引用文件的CSS压缩minifyJS: true// 引用文件的JS压缩}))).pipe(dest('dist'))}
先执行compare在执行useref,否则的话注释已被删除
第十二步重新规划构建过程
useref打破了构建的目录结构
会被useref影响到的操作目录,我们可以使用临时目录来处理

若有收获,就点个赞吧
0 人点赞
