URL
- 统一资源定位符(Uniform Resource Locator),它是WWW的统一资源定位标志,WWW上每一信息资源都有统一且在唯一的地址,就是网络地址。
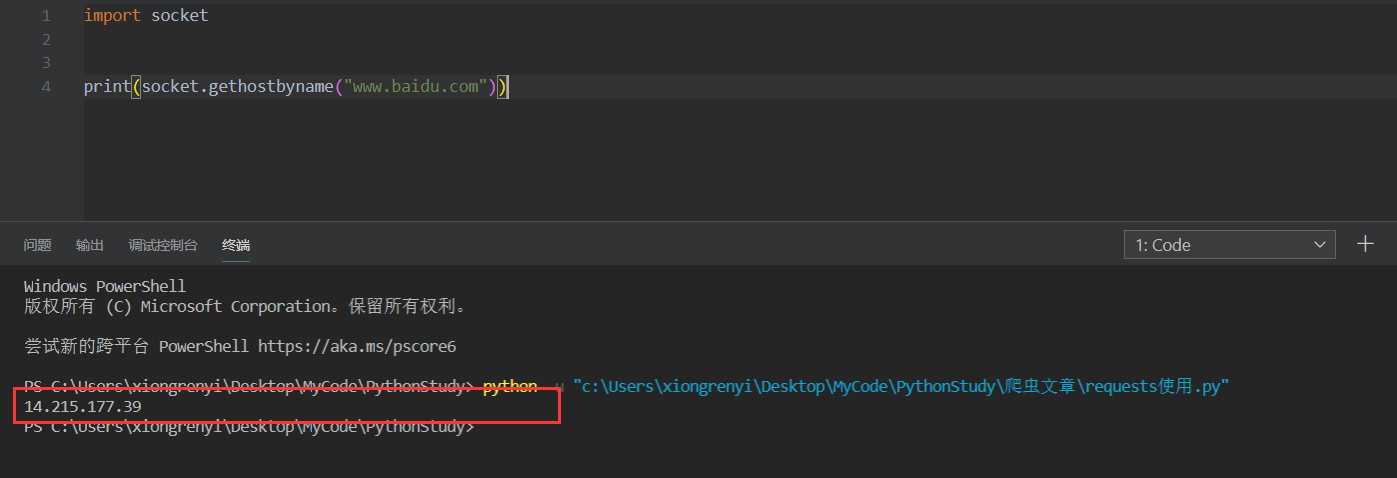
- 其实url就是IP地址,因为IP地址都是xxx.xxx.xxx.xxx这种形式,不太好使用,所以使用另一种方式来表达,如下所示可以将baidu网址转为IP地址
requests
requests是专门用来模拟浏览器,对服务器进行请求的模块,封装了get、post、put等方法来实现。其实再底层一些便是socket来做处理。
导入模块
- import requests
get请求
- get请求:对服务器带有参数发送请求获取数据,但是携带的参数不超过256bytes。
- reuquests.get(url)
post请求:对服务发送带有表单的数据发送请求获取数据,理论上post传递的数据没有大小限制。一般需要密码登录,验证码等都是post请求。
- form_data = “”
- requests.post(url,data=form_data)
开发者工具及参数
- 鼠标右键 ,检查,如果是谷歌可以F12,其他的也有快捷键
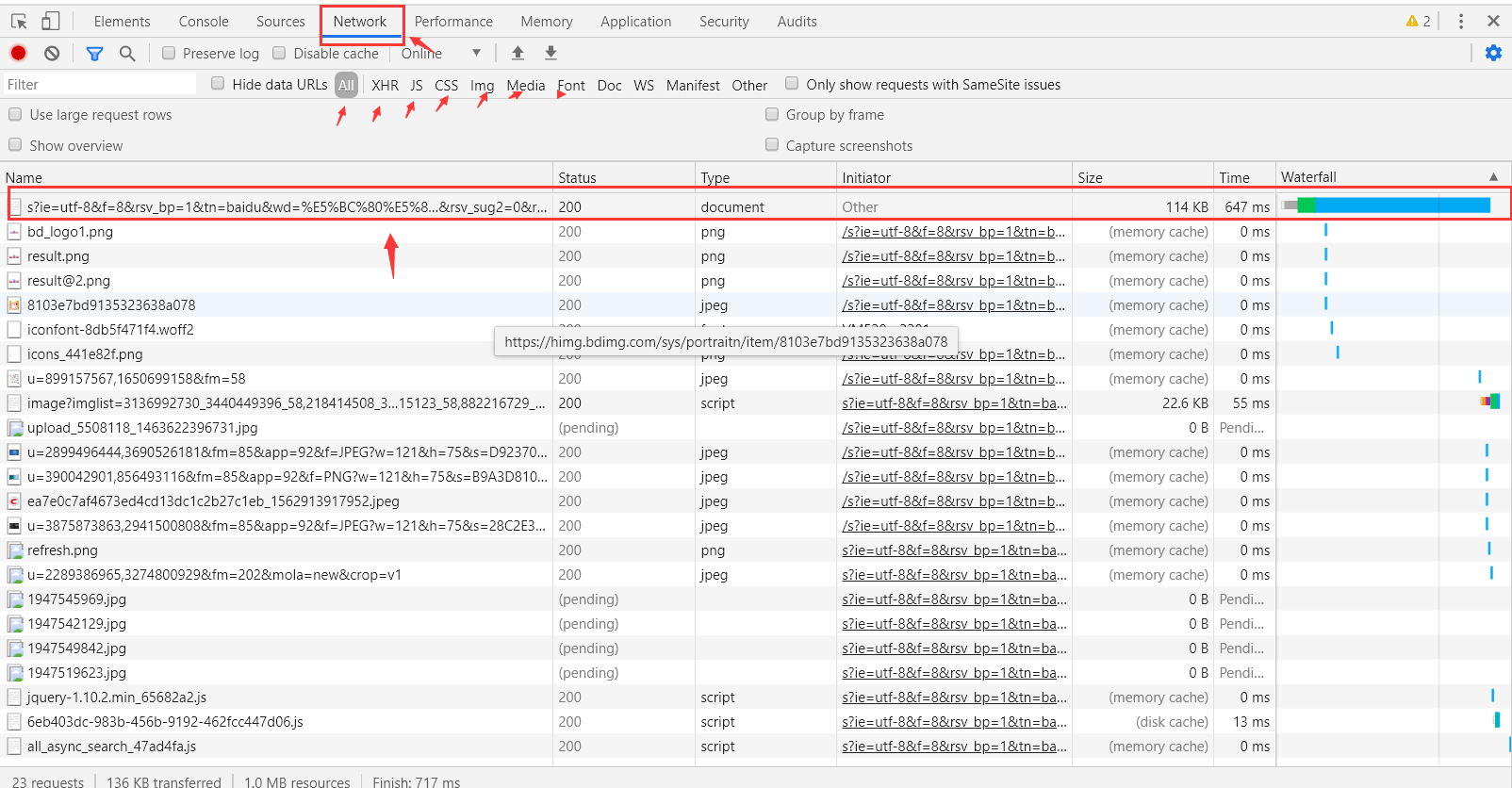
2.点击network
- network下面便是浏览器返回的一些数据包
- xhr、js、css、img等文件
general
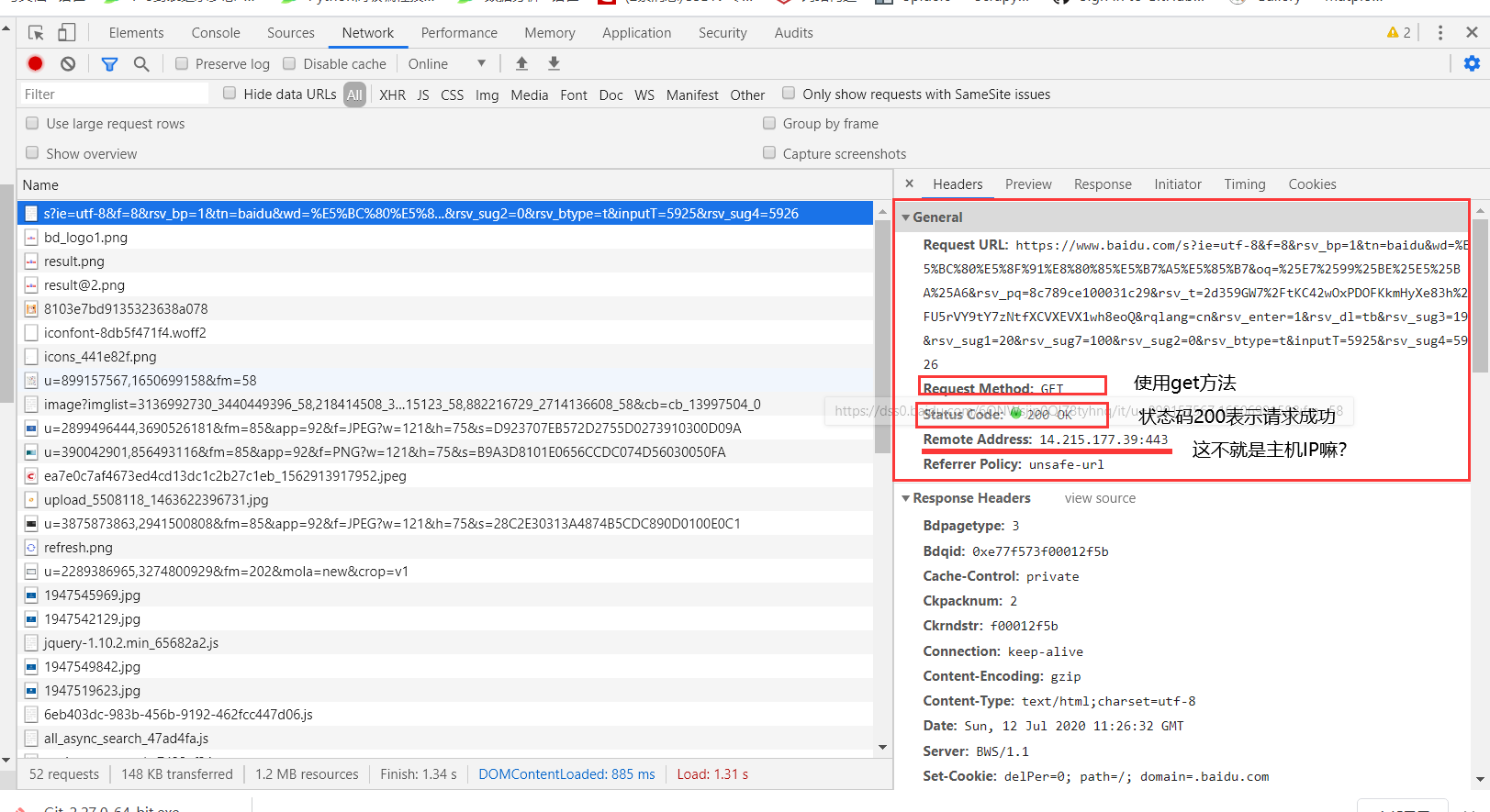
- 可以查看基本信息
- request method 表示请求方法
- status code 表示服务器响应状态
- remote address 表示服务器主机地址
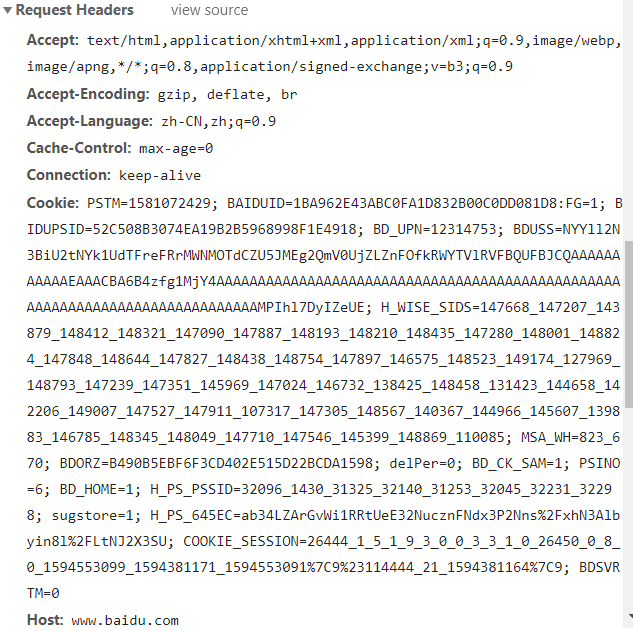
请求头
包含了发送给服务器的信息,服务器根据这些来判断是否返回数据,返回什么样的数据,既然是模拟浏览器对服务器进行请求,请求头的参数就是必不可少的。其中服务器最常用的反爬就是使用user-agent、referer、cookie等。
- Accept 请求的数据返回类型
- Accept-Encoding 返回数据的编码格式
- Accept-Language 返回数据的语言
- Connection 是否保持连接
- cookie** **用户信息
- 保存于本地,用于下次访问时验证客户信息,如果已经登录,下次就浏览器可以直接使用cookie进行的登录,不需要人为的数据账号密码。
- Host 主机名
- Referer** **防盗链
- 访问服务器时,会发送给服务器上一次访问的地址
- User-Agent ** **用户代理,主要根据这个判断是浏览器访问的服务器,还是别的程序访问的服务器
一个简单的爬虫
import requestsurl = "https://www.baidu.com"# 请求头 以字典形式传递headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36"}response = requests.get(url, headers=headers)# text返回字符串文档print(response.text)
可以看到返回的是一个HTML文档: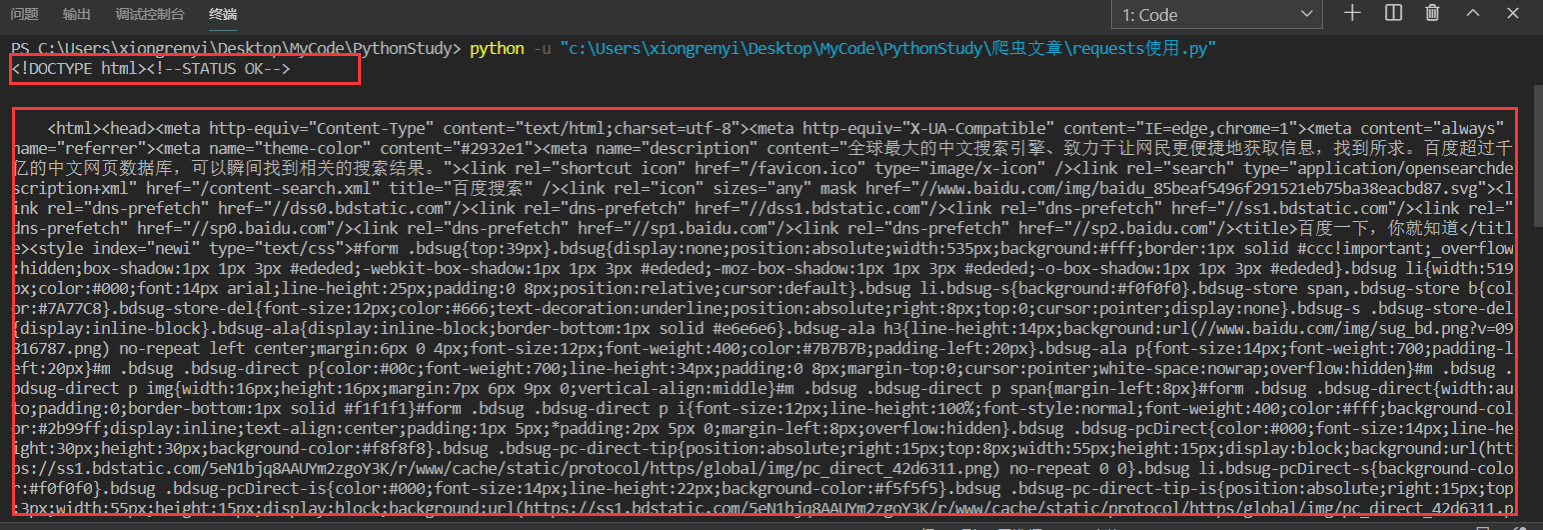

若有收获,就点个赞吧
0 人点赞
