- 一、 数据类型
- 如果把切片赋给新变量,则是一个新的列表
- 逻辑处理
- 二、 文件操作
- 默认 只读 编码utf-8
- mode:
- 打开xls文件
- 打开表的两种方式
- 访问单元格的两种方式
- 遍历一行或者一列所有单元格
- 修改单元格的值
- 存储xls文件
- 文件绝对路径
- 获取当前文件上级目录
- 判断路径是否存在
- 判断是否文件夹
- 拼合路径和文件名
- 创建目录
- 文件列表
- 删除文件或者目录
- 复制、移动文件
- 因为默认参数会维护一块固定内存区域,当默认参数是可变类型时,会出现一些坑
- 比如:
- a=3, b=[1,2,1,3] v3与v1的内存地址一样,也就是说默认参数会维护一块固定的内存区域,只要没有传参数,就会到这个区域取值
- 举例
- 得到一个元组,每个单元含序号num(从n开始)和value(为列表的元素)
- 四 项目开发规范
- 五 面向对象
- 拥有iter和next方法
- 并在iter方法中返回自身,在next方法中返回下一个值,
- 并在最后一个值之后抛出StopIteration异常的对象。
- 如果类中有可迭代方法,并返回一个迭代器对象,则称以这个类创建的对象为可迭代对象
- 六 网络编程
- 七 并发:进程与线程
- print(1111,form.instance.ttcopy.name)
- print(3333,form.instance.ttcopy.url)
- pycharm开发工具
- pycharm为每个工程准备了一个虚拟环境,每个项目的环境是相互隔离的,不会产生干扰
- python从3.x版本开始就有较大的升级,区别于之前的版本,所以现在python3是安装包与python完全不一样,兼容度比较差,python3的包管理器是pip3, 而不是pip,特别注意
一、 数据类型
1. 数值
1.1 整数的进制
- 十进制是以整型存在,其他进制以字符串形式存在
二进制,八进制和十六进制之间不能直接转化,可以通过十进制为媒介
# 二进制 - 十进制v2 = "0b000000001"num_int = int(v2,base=2)v2 = bin(num_int)
八进制 - 十进制
v8 = "0o123267"num_int = int(v8,base=8)v16 = oct(num_int)
十六进制 - 十进制
# 十六进制 - 十进制v16 = "0x982ABCDEF"num_int = int(v16,base=16)v16 = hex(num_int)
非十进制之间转换
# 二进制 - 十六进制num_int = int(v2,base=2)v16 = hex(num_int)一个8位二进制可以转化为2位十六进制
- 浮点数 float
- 小数 Decimal
```python Decimal 和 float的转换问题 - Decimal是以字符的方式存储小数,完全精确,而float是双精度数,小数点后有四舍五入
- float转化为Decimal,或者Decimal转化为float都会出现精度的差异,小数点后第三位出现问题。所以应该保证所有的小数计算都在Decimal内执行,而不做float的转化
<a name="Zvfxh"></a>### 2. 字符串 *字符串的特点:- 有序不可变- 跟元组比较类似字符串的方法:- 拆分、连接、替换- strip (rstrip, lstrip)- split (rsplit, 但没有lsplit, 因为split默认为左切)- split(str, 2) 参数2是切2刀的意思- 在处理前后缀时可以采用控制切刀方向和数量的办法- join- ",".join([list or tuple]) 只能接收一个参数,元组、列表或者其他可迭代对象- ",".join("hello") 如果参数是一个字符串,则将它看成列表 # h-e-l-l-o- replace- s.replace("被替换子字符串", "替换后的字符串")- 如果没找到被替换字串则不报错,直接返回原字符串- upper /lower- 将字符串中所有的字符转换为大写/小写- rjust(长度,填充字符) # 用填充字符把源字符串补到指定长度- zfill(8) # 补0,专门用于二进制处理- center(8, "填充字符") # 把字符串放在中间,总长度8,两边填充字符- 查找- count- find (找不到返回-1,找到返回序号)- index- 判断- endswith startswith- isdecimal isdigit- isdecimal 可以判断整数,如果含有点也是False,所以不能判断小数- isdigit 还可以判断带圈的数字,所以不适合判断整数- 要判断是否是小数,最好用re表达式- 格式化- {0}".format(data) format (老师比较推崇的方法,不如f来的快)特殊用法:- 格式化- f格式化 f"hello {name} "- 原义字符串 r"hello %s" (很少用)- unicode字符串 u"\x0867"- 字符加颜色 \033[1;31;40m; 中间字符串 \033[0m- 颜色三种格式- RGB (0,255,255) #红 绿 蓝 (不是红黄蓝三原色)- RGBa (0,255,255,0) #最后一位是透明度- 功能字符- \r 将光标移到行开头, 利用这个功能实现进度条 打印竖黑线*i 来显示进度- \b 将光标后退一格字符串的格式化方法和打印:```pythonprint("") #默认带一个\n回车符" 内容%*s"% (len,string)# s前面加星号可以在len这个地方指定打印宽度,len为正是右对齐,len为负数则是左对齐# 百分号 %(关键字)s的格式化方法"this is a world %(field)s" % {'field':'great greate'}”{:20.3}内容“.format("hello")#这是老师推荐的format方式, :20指定整个输出宽度(默认左对齐) .3是指字符串本身指输出前面三位"hel"”{:>20.3}内容“.format("hello")# >大于号表示右对齐”{:0.4f}内容“.format(1.45678)# 输出四位小数的浮点数,四舍五入'{:{}s} {:{}d} {:{}f}'.format(字符1, len1, 字符2, len2,数值,len3)# 花括号里面在加一个冒号然后跟一个花括号,就可以加上输出长度'{:{}{}}'.format(字符1, ">",len1)# 输出的是右对齐,长度len1'{:_^{}}'.format(字符1, ">",len1)# 冒号后面的_^ 表示把字符串1放中间,两边用_来填充长度(len1)
3. 布尔
4. 列表
列表的主要方法:
- 建 list()
- 增 append, extend, insert
- 删 pop remove clear
- 查 index count
- 排序 sort (不同数据之间不可排序,报错)
- 反列 list.reverse() —原列表颠倒顺序, 没有返回值
- 加法,相当于extend
- 乘法,多个相同列表相加
- 切片方法
```python li = [1,2,3,4,5] li[-1::-1] # 列表倒置 [5,4,3,2,1] [起点:终点:步长] li[-1] # 表示最后一个元素
如果把切片赋给新变量,则是一个新的列表
li = [1,2,3,7,4,9,0,12,6,2,1,] l2 = li[3:5] # l2:[7,4] # l2新的列表,任何变化与原列表无关 l2[1]=200 # l2:[7,200] print(li) # [1,2,3,7,4,9,0,12,6,2,1,] 没有变化
li[0:2]=[200,300] print(li) # [200,300,3,7,4,9,0,12,6,2,1,]
li.sort(key=xx) # 排序方法 students = [( ‘john’ , ‘A’ , 15 ), ( ‘jane’ , ‘B’ , 12 ), ( ‘dave’ , ‘B’ , 10 )] students.sort( key = lambda student : student[ 2 ])
<a name="PPrtW"></a>### 5. 元组- 建 tuple()- 增 只能外增,加法:+ 乘法: * (同列表)- 删 不行- 查 index count (find方法没有)- 排序 不行<a name="LhsnN"></a>### 6. 集合1. 一堆不重复的数据的群,集合的三个特点:- 花括号包裹,容易与字典要混淆,所以不能用{}来建立空集合。- 不重复- 可删,不可改(无序不能定位)- 集合的元素不能是列表、字典等可变数据,必须是可哈希的数据- 无序,集合是哈希存储,所以不能索引引用2. 集合的普通方法:```pythons.add(" ") #增加元素set() #新建或者转化一个列表和元组为集合s.discard("元素") #删除元素 没有不报错也不返回s.remove("元素") #功能同discard,但没有找到会报异常s.pop() # 随机pop一个元素 (但是对于全数值类型,不是完全随机的)memeber in s # in 运算
- 集合的特殊方法:
```python
s1 | s2 # 求并集
s1 & s2 # 求交集
s1 - s2 # 求差集
# 没有加法运算
4. 集合的优点:
- 快速去重
- 查询效率高,哈希函数
- 适合于群组等特点使用场景
5. 集合与列表、元组的比较
- 可变可哈希,不可变不可哈希
| 类型 | 是否可变 | 是否有序 | 元素要求 | 是否可哈希 | 转换 | 定义空 |
| --- | --- | --- | --- | --- | --- | --- |
| list | 是 | 是 | 无 | 否 | list(其他) | `v=[]或v=list()` |
| tuple | 否 | 是 | 无 | 是 | tuple(其他) | `v=()或v=tuple()` |
| set | 是 | 否 | 可哈希 | 否 | set(其他) | `v=set()` |
<a name="W5iQ4"></a>
### 7. 字典
由键和键值组成的数对构成的集合,特点:
- 继承了集合的无序、不重复,可修改
- 键必须是可哈希的值
字典的普通方法:增、删、改、查
```python
dict.get("键") #获取键值,没有返回None (这个实用性比较好)
{}.fromkeys([1,2,3,4,5],"键值") #快速以列表为键,键值为键值快速初始化字典
dict(zip(l1,l2)) #快速从两个列表创建字典,通过zip函数
dict.keys() #所有键的生成器
dict.values() #所有键值的生成器
dict.items() #所有键和键值对的生成器
data.setdefault("age", 18) #设置默认值的方法
data.update( {"age":14,"name":"武沛齐"} ) #更新或者添加值的方法
data = info.pop("age") #按键名pop某个键和键值 参数不能为空,否则报错的
del data["age"] #删除键值对,不返回
data = info.popitem() #pop末尾的键和键值
字典的末尾在哪里?
copy() #不常用的 这是浅copy,只复制第一层,第二层还是公用内存地址
clear() #不常用的
sorted(di) 返回排好序的键列表,相当于 list(keys())
sorted(di.keys()) 意思同上,可以加上key参数
sorted(di.keys(), key=lambda x:x*2)
sorted(dd.items(), key=lambda x:x[0]) #items返回元组的列表,x[0]按照键排序,
字典的特殊方法
字典转化为集合可以求交、并、差 #求字典的并集,当有相同的键时后面的覆盖前面的。
比如:
d.items() & d2.items()
d.values() | d2.values()
d | d2 #这会报异常 字典的并集应该用update方法。
字典的循环应该这么写:
for k,v in d.items():
不能写成:
for k, v in d:
因为字典不是元组,切记
字典与列表的相互转化
a = dict( ("k1", "v1"), ["k2", "v2"]) #转化为字典
v1 = list(info) # ["age","status","name"] 与.keys相同
v2 = list(info.keys()) # ["age","status","name"]
v3 = list(info.values()) # [12,True,"武沛齐"]
v4 = list(info.items()) # [ ("age",12), ("status",True), ("name","武沛齐") ]
#把键值对变成元组存到列表返回
字典的优点:
- 跟集合一样,速度快
可以建立一个对应关系表
有序字典 OrderedDict ```python from collections import OrderedDict dd = {1:0,5:2,2:3} od = OrderedDict(sorted(dd.items(),key=lambda t:t[0]) # 直接按照键对dd排序后
new_menu_dict = OrderedDict() for k in sorted(menu_dict.keys()): # sorted(menu_dict) 返回字典键的排序后列表 new_menu_dict[k[0]] = menu_dict[k]
python3的字典已经是有序字典,所以这个用法意义不是很大了。直接给字典排序就行
d2 = dict(sorted(d.items(),key=lambda x:x[0]))
<a name="QaPrm"></a>
### 8. 队列
```python
from queue import Queue
li = [1,2,3,4,6]
q = Queue() # 先进先出队列
q.put(li[0]) # 入队
q.get() # 出队
q.empty() # 判断对是否为空
######## 双边队列 deque
from collections import deque
dq = deque('abcede')
# 出列
cur = dq.pop()
print('dq.pop:',cur)
print('dq:', dq)
# 左出列
cur = dq.popleft()
print('dq.popleft:',cur)
print('dq:', dq)
# 入列
nd = 'f'
dq.append(nd)
print('dq after append:', dq)
# 左入列
nd = 'f'
dq.appendleft(nd)
print('dq after left append:', dq)
主要数据类型大对比
| 类型 | 性质 | 公共方法 | 独有方法 |
|---|---|---|---|
| 列表 | 有序可变 | 增 + 加法(extend有区别)*乘法 删 del copy remove pop clear 改 sort 查 索引 count index 切片 in |
.append .insert extend |
| 元组 | 有序不可变 | 增 + 加法 * 乘法 删 no. 改 no. 查 索引 count index 切片 in |
|
| 字符串 | 有序不可变 | 增 + 加法 * 乘法 删 no. 改 no. 查 索引 count index 切片 in |
center format strip split (反义词 .join ) upper lower replace find(没找到返回-1) endswith startswith isdecimal isdigit |
| 字典 | 无序可变 | 增 update 并集 删 del copy clear pop 出栈 改 键值索引 改 查 键值索引 in |
.keys .values .items get(独有) |
| 集合 | 无序可变 | 增 update | &. - 并集 交集 差集 删 del copy clear pop 字符型随机 remove(报错) discard(没有就啥不做也不报错) 改 键值索引改 查 in 运算 |
add 增加方法 |
数据类型的作业
作业需求:
1、生成一副扑克牌(自己设计扑克牌的结构,小王和大王可以分别用14、15表示 )
2、3个玩家(玩家也可以自己定义)
user_list = [“alex”,”武沛齐”,”李路飞”]
3、发牌规则
默认先给用户发一张牌,其中 J、Q、K、小王、大王代表的值为0.5,其他就是则就是当前的牌面值。
用户根据自己的情况判断是否继续要牌。
要,则再给他发一张。(可以一直要牌,但是如果自己手中的牌总和超过11点,你的牌就爆掉了(牌面变成0))
不要,则开始给下个玩家发牌。(没有牌则则牌面默认是0)
如果用户手中的所有牌相加大于11,则表示爆了,此人的分数为0,并且自动开始给下个人发牌。
4、最终计算并获得每个玩家的分值,例如:
result = {
“alex”:8,
“武沛齐”:9,
“李路飞”:0
}
必备技术点:随机抽牌
import random
total_poke_list = [(“红桃”, 1), (“黑桃”, 2), ……,(“大王”, 15), (“小王”, 14)]
随机生成一个数,当做索引。
index = random.randint(0, len(total_poke_list) - 1)
获取牌
print(“抽到的牌为:”, total_poke_list[index])
踢除这张牌
total_poke_list.pop(index)
print(“抽完之后,剩下的牌为:”, total_poke_list)
保留关键字
python3.7 版本的保留关键字:
逻辑: 'False', 'None', 'True', 'not', 'or',
'__peg_parser__', 'and', 'as',
定义:'class', 'assert' 'def'
流程控制: 'if' 'for' 'continue', 'pass' 'while' 'elif', 'else', 'except', 'finally', 'return' 'yield' 'async', 'await' 'break',
, 'del',
'from', 'global',
'import', 'in', 'is', 'lambda', 'nonlocal',
'raise', ,
'try', , 'with',
赋值操作
a=3
相当于:创建一个内存容器,存入3,然后把a的标签贴在该容器上
诡异的连续赋值的执行顺序
i = x[i] =3
他相当于:
首先 i=3 然后: x[i]=3
而不是
x[i]=3, i=x[i]
逻辑处理
判断
if a>b:
pass
elif c<d:
pass
else:
return xx
- 逻辑运算的优先级问题
not > and > or
循环
while循环
# 例1 普通循环
l2 = [1,2,3]
i = 0
while i < 10:
l2[i]= l2[i]+3
i += 1
# 例2 死循环
while True:
socket.lisen()
for循环
#列表的循环:
for i in list1:
i = i +1
# 字典的循环
for name, val in d.items():
print(name,val)
for k in d.keys():
print(k)
for val in d.values():
print(val)
# 可迭代对象的循环
f = open("file.txt","rb")
for line in f:
print(line)
循环的结束
continue 结束一次循环
break 结束整个一层循环
特别注意:循环结束时,循环变量并不删除,而是保留退出时的值
循环语句的else形式
for i in li:
if i>5:
print('有大于5的数:',i)
break
else:
print('列表里面不存在大于5的数')
如果for循环执行了break语句,将不执行else语句,如果没有break语句将顺序执行else
while i>0:
print(i)
break
else:
print(i)
while循环,如果break执行了,则跳过else语句,否则else语句将在while循环结束之后执行
异常处理
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
except IOError:
print "Error: 没有找到文件或读取文件失败"
else:
print "内容写入文件成功"
fh.close()
二、 文件操作
文件的打开、读、写、 存
- 打开
```python
f=open(文件名,模式,编码)
默认 只读 编码utf-8
mode:
rb rt 只读模式,如果不存在则报错 wb wt 覆盖写模式,源文件清空,然后再写 ab at 添加模式,从结尾处开始写,如果文件不存在直接创建一个,但是不能创建文件夹
- 加强模式,读写
w+ 很危险,打开则首先清空文件,然后写读,所以以这种模式打开文件是读不到东西的。
r+ 可以读,写的时候覆盖写的长度内容,不会清空文件, 对于需要清空文件的不推荐
2. 读
```python
f.read() #读所有
f.readline() #读一行
写
f.write() # 必须在写模式下, #注意写从光标所在的位置开始特别注意: 写的内容格式必须跟新建的时候的格式一致,比如打开rb是字节,写必须是字节格式。
存
f.close() # 存储并关闭,释放内存资源光标
f.tell() #查找当前光标索引 返回索引值 f.seek(0) #移动光标到索引位置with open(file) as f:
with open("filename.txt",mode="rt",encoding="utf-8") as f1: pass #好处在于能自动关闭,免得忘了关文件获取文件的简介信息
info = os.stat(路径/文件名) #返回一个stat对象,其中包括文件大小 info.at_size # 文件大小
熟悉几种常用文件
- csv文本文件 由逗号隔开的文本文件
- ini 文件 一般是系统的配置文件
- 有专门的读取模块:configparse,不用自己瞎想
- XML格式文件
- 用于网络传输的文件
- 用于java的配置文件
- 专门的读取写工具 xml.etree (不清楚查文档就行)
- Excel文件
打开表的两种方式
sheet= sheets[0] sheet= sheets[“表名”]
访问单元格的两种方式
cell = sheet.cell(1,2)
cell = sheet[“A2”]
遍历一行或者一列所有单元格
for cell in sheet[2] for cell in sheet[“A”]
for row in sheet[2].iter_rows(min_row =2 )
修改单元格的值
cell.value= 12
存储xls文件
wb.save(“路径+文件名”)
- 案例2
```python
# 遍历每行,获取每一行信息
# 存储字段名
field_list = []
for i,field in enumerate(ws[1]):
if field.value:
field_list.append((i,field.value))
print('field list:',field_list)
for row in ws.iter_rows(2):
# 用户存储每一行的数据
data_dict = {}
# 查询系统里面是否有该订单号
for num, field in field_list:
if row[num].value:
data_dict[field] = row[num].value
invoice_number = data_dict.pop('order')
order_obj = FollowOrder.objects.filter(order__order_number=invoice_number).first()
if not order_obj:
continue
# 把数据存入跟单对象记录
for field,val in data_dict.items():
setattr(order_obj,field,val)
# order_obj.save()
count += 1
新建xls表
from openpyxl import workbook file_xls = workbook.Workbook()对齐设置
- 边框设置
- 字体设置
- 颜色设置
获取当前文件上级目录
os.path.dirname(文件路径+文件名) # 从路径字符串中分理处上级目录名字
判断路径是否存在
os.path.exists(路径)
判断是否文件夹
os.path.isdir(路径)
拼合路径和文件名
os.path.join(路径,子目录,文件名) #实际就是用”/“做字符串拼接
创建目录
os.makedirs(“路径”)
文件列表
os.listdir()
删除文件或者目录
os.remove(路径)
复制、移动文件
import shutil
shutil.copy(“源文件”,”目标路径“)
shutil.move(“源文件”,”目标路径“)
<a name="qAaJZ"></a>
# 三 函数
<a name="SfgFN"></a>
## 函数初步
1. 函数的名称和参数,注意:函数名本身也是对象
1. 函数的返回,返回的是一个内存地址,可以指向任何对象
1. 函数的用法
<a name="XgwVn"></a>
## 函数进阶
<a name="XJZuZ"></a>
### 默认参数
1. 默认参数的位置要在普通参数之后,动态参数之前
1. 默认参数会在函数定义时在内存维护一块区域,这个跟一般理解的不一样
1. 默认参数不传参不会报错
1. 传参方式有两种:
```python
def f(a,b=0):
print(a,b)
f(1) # 1 0
f(1,2) # 1 2
f(1,b=3) # 1 3
- 默认参数的坑
```python
因为默认参数会维护一块固定内存区域,当默认参数是可变类型时,会出现一些坑
比如:
def f(a,b=[1,2]): b.append(a) print(a,b) return b
v1 = f(1) # a=1, b=[1,2,1], v1与b同一个内存地址
v2 = f(2,[4,5]) #a=2, b=[4,5,2] v2与新的b同内存地址
v3 = f(3)
a=3, b=[1,2,1,3] v3与v1的内存地址一样,也就是说默认参数会维护一块固定的内存区域,只要没有传参数,就会到这个区域取值
总结:尽量避免给默认参数传可变类型的值
<a name="y6jcV"></a>
### 函数的动态参数 *args **kwargs
1. *args : 将实参的多个元素当成是一个元组
1. **kwargs : 将实参中 k1= 1, k2=3 的关键字参数当成是一个字典
1. 第二点中应该区分默认参数是优先于关键字参数的
1. 特别注意:形参表里面默认参数要在写在关键字参数之前
- 参数顺序:位置参数 -> 默认参数 -> 关键字参数
- 关键字参数和默认参数外表一样容易混淆,最好不一起使用 **
- 对于参数数量明确的情况下不要使用动态参数
- 在调用情况多样化的情况下,对于确定的参数用普通参数,对于不确定的参数用动态参数
- 动态参数不传不会报错,置为空,可以在函数使用上有灵活性,尤其是在函数复用上
```python
def f(a,b=0,*args,**kwargs):
print(a,b,args,kwargs)
f(1,2,3,4) # a=1 b=2 args=(3,4) kwargs={}
f(1,b=3) #a=1 b=3 args=() kwargs={}
f(1,b=2,3,4) # 这种会报错,b=2被认为是关键字参数,要放在普通参数之后
f(1,2,3,4,b=2) #这会报错,因为b已被记为默认参数,同时在位置上被认为是关键字参数,被两次赋值
f(1,2,3,4,c=5) # 1 2 (3, 4) {'c': 5}
- 如果同时有默认参数和动态参数,则关键字传参方法必须在arg后面 ```python def func(a,b=False,args,**kwargs): print(a,b,args,kwargs)
c= {} func(1, b=False, (1,),*c)
上面的情况报错:
TypeError: func() got multiple values for argument ‘b’
解决方案:
- 位置参数和默认值参数都用位置传参法,不用关键字方法,避免混乱 b=False 改为 False
- 对所有的参数都用关键字方法,(这可能还是会造成混乱) ```
函数的作用域和变量作用域
- 函数内的变量仅在内部有效
- 同名情况,优先级是函数内部,然后是函数父级的变量的值
- 对于父亲变量只能读取,不能直接赋值,但是对可变类型,可以改变其内部变量,如列表和字典
- 如果想在局部改变全局变量,可以使用global关键字
- 但是要注意函数作用的外溢性,让程序变得复杂而难以维护
- 函数体的作用域与变量的同理,函数的内部可以调用同辈和父及祖父辈函数的函数名,但是不能调用其侄级或者孙级的函数。
- 函数内部必须先定义再使用,但是在类对象的内部可以不受这个顺序的限制,类对象在执行的时候会扫描整个领域
- 函数的变量作用范围从其定义开始的位置来查看,而不是调用的位置。
Python的变量回收机制
- 任何对象都有一个引用计数器
- 当引用计数器为0时,此对象立即被回收,没人记得你,你将消失
- 只要引用计数器不为0,则会始终在内存中维护
-
函数高级
函数嵌套
函数嵌套按照变量的作用域一样的原理
- 即使是将内部函数名return到外部,它仍然带有它父亲的记号,层级关系依然存在
- 在作用域中寻找值时,要确保此次此刻值是什么
- 分析函数的执行,并确定函数作用域链。(函数嵌套),回到函数原来定义的地方
函数装饰器
- 使用一个嵌套函数方法,在不改变原函数的情况下,给他加装一点东东
- 这样在调用形式不变的情况下,实现给原函数加装功能,写法简便实用
- 要注意的点是:
- 不导入functools,也可以实现装饰器的功能
- 但是后期开发可能会出错,要特别注意,因为程序会对函数名进行检查,重名则会报错。
匿名函数 lambda
- 格式:lambda 参数:函数体 (返回值= 函数体的计算值)
-
三元运算 if
格式: a if 条件成立 else b 含义 如果条件成立表达式的值为a,否则为b
- 扩展,列表的for 表达式:[ i*2 for i in range(10) ] 等价于: [0,1,2,….9]
- 相当于一个小的for函数 for i in range(10): a = i*2, [].append(a) 这和迭代器也有点像。
- if 和 for的结合 x if True else xx for x in iters
星号表达式
范例:
- a, *b = [1,2,3,4] # a=1, b =[2,3,4]
- a,*b,c = [1,2,3,4] # a=1 b=[2,3], c=4
- *b, = [1,2,3,4] #b = [1,2,3,4]
- *b = [1,2,3,4] #报错
总结: b不能单独使用,必须构成一个元组,可以理解为除指定参数以外的其他参数
生成器
- 生成器是由函数+yield关键字创造出来的写法,在特定情况下,用他可以帮助我们节省内存。
- 生成器对象,执行生成器函数时,会返回一个生成器对象,函数体不执行。
- yield是一个程序执行断点,并返回一个值
- 使用: next(生成器对象) run一次,执行yield的一段代码,下一次执行从上次断点继续执行,一直到下一个yield
```python
def func():
print(11)
yield 11
print(22)
yield 22
print(33)
yield 33
v1 = func() # v1是一个生成器对象
n1 = next(v1) # 执行 func里面yield 11之前的代码,然后返回11给n1 n2 = next(v2) # 从之前断点yield 11开始执行,然后返回22给n2
- 如果生成器已经迭代完毕,再继续执行会报错 StopIteration
- 实际使用场景,用for循环
```python
for item in data: # 这里data是生成器对象,跟迭代器有点像
print(item)
- 生成器的方法 ```python next(生成器) #访问生成器到一下断点,并返回
data.send(数值)
举例
def func(): print(111) v1 = yield 1 print(v1)
print(222)
v2 = yield 2
print(v2)
data = func()
n1 = data.send(None) # 第一个参数必须是None print(n1)
n2 = data.send(666) # 从yield 1断点处继续,将666赋值给v1,继续执行 print(n2)
n3 = data.send(777) # 从yield 2断点处继续,将777赋值给v2,继续执行 print(n3)
<a name="d2GQe"></a>
### 内置函数
第一组: 数学函数
- divmod 求商和余数,返回一个元组
```python
divmod(大数,小数) # 返回元组 (商,余数)
- pow 幂函数
- min 的特殊用法
min([1,2,3,-3,9,100,-3],key=lambda x: abs(x))
先将列表元素按key的方法处理之后在比较大小,然后输出最小值(注意还是处理之前的值)
第二组:逻辑函数
- all 是否全部为True 只接受一个arg (一个iterable对象,列表,元组等,所有元素都是True才是True)
- any 是否有True 只接受一个arg (接受一个iterable对象,只要一个为True结果就是True)
第三组 进制转换
- bin 十进制转二进制
- oct 十进制转八进制
- hex 十进制转16进制
第四组: 字符
- ord 获得字符的unicode
- chr 十进制转对应字符
第五组:数据类型
- int float str list dict set tuple bool bytes
- 可用于转换数据类型
- 但是如果类型不对会报错
- 可用于转换数据类型
第六组 系统功能
- len
- open
- type
- range
- id
- help
- enumerate # 把后面的可迭代对象加上序号,返回元组
```python
for num, value in enumerate(list,n)
得到一个元组,每个单元含序号num(从n开始)和value(为列表的元素)
for i, value in enumerate(zip([1,2,3],[11,12,18,19])): print(i,value)
“”” 0 (1, 11) 1 (2, 12) 2 (3, 18) “””
for i, value in enumerate(zip([1,2,3],[11,12,18,19]),2): print(i,value)
“”” 如有参数n,则序号从n开始 2 (1, 11) 3 (2, 12) 4 (3, 18) “””
- zip # 得到zip对象
```python
zip([1,2,3],[3,4,5,6],[2,1,9,0,1,1])
# zip对象里面的item是
(1,3,2),(2,4,1), (3,5,9) # 长度以最短列表为准
- map # 相当于一种简单的循环语句
```python map(int,可迭代对象)
注意map的返回值: map对象,所以最好对列表进行处理,不需要额外的返回值
- sorted 排序函数 **强大**
- sorted(dict) 只对键进行排序,返回列表
- sorted(dict.items(), key = lambda x: x[1]["id"]) # 此处x表示 items里面的一个元组单元
- 上面这一行代码相当于按key的方法对dict.items的元组进行排序的一段程序,这样写好处是精炼,缺点是可读性差一点。炫技到底好不好?
- sorted(list) 直接返回一个新的排好序的列表,方便。
- 如果列表元素是字符串,则按字符串从左到右逐个比较,这与数值的比较不同。
<a name="YVa8X"></a>
### 列表推导式
```python
[i for i in range(10)] # [0,1,2,3....9]
[[i,i] for i in range(10)] #[[0,0],[1,1],[2,2].....[9,9]]
[i for i in range(10) if i>6 ]
{"alex-{0}".format(i):i for i in range(10)} # 也支持字符串格式化
推导式对列表、字典、集合、元组都有效,只是元组的情况不同,只会创建一个生成器,而不立即执行
下面的有点烧脑的lambda的推导式:
data_list = [lambda x: x + i for i in range(10)] # [函数,函数,函数]
v1 = data_list[0](100) # lambda函数的父级作用域是for循环,里面的i=9
v2 = data_list[3](100) # 创建里列表是lambda函数没有执行
print(v1, v2) # 109 109
def num():
return [lambda x: i * x for i in range(4)]
# 1. num()并获取返回值 [函数,函数,函数,函数] i=3
# 2. for循环返回值
# 3. 返回值的每个元素(2)
result = [m(2) for m in num()] # [6,6,6,6]
print(result)
----
# 下面情况略有不同
def num():
return (lambda x: i * x for i in range(4)) #如果改成圆括号,就是生成器
# 1. num()并获取返回值 [函数,函数,函数,函数] i=3
# 2. for循环返回值
# 3. 返回值的每个元素(2)
result = [m(2) for m in num()] # [0,2,4,6]
print(result)
内置模块
OS模块
- os.path.exists # 判断路径是否存在
- os.mkdir(path) # 创建文件目录
- os.listdir(“路径”) # 获取路径下的文件名列表,但是顺序不是我们理解的顺序,有点随机,需要进行排序
- os.path.join(base_dir, 需拼接的路径) # 返回拼接后的路径,对于不同操作系统都可用
hashlib 模块
其中的md5加密功能是主要功能,语法规则如下:
- 加密之后的密码字符长度是32位或者64位,根据系统决定
```python
import hashlib
hashlib_obj = hashlib.md5(b”afaljlfaslfjlasjflajlf”) # 这里的二进制字符串是salt
hashlib_obj.update(b”password”)
pwd_md5 = hashlib_obj.hexdigest()
print(pwd_md5)
“”“
加盐(salt)才能防破解
”“”
<a name="g18gO"></a>
#### json模块
1. Json是一种网络数据传输格式,可以与python以及java的数据格式相互转化,本质是长字符串
1. json的主要的用法:
- 从python数据格式转为json json.dumps(dicts)
- json.dump(d, file) 直接序列化d,然后写到文件里面
- json的文件格式是里面只允许一个字典,或者一个列表,把所有的数据都放在里面作为一个元素存储
```python
f = open("file.json")
data = json.load(f) # f必须是文件句柄
data = json.loads(f.read()) # loads可以载入一个长字符串
- 从json转为python数据格式 json.loads(string)
- json不能处理的对象:
- 不支持集合
- 不支持其他特殊对象
- 能支持的只有:int float, list, tuple, dict, str, bool, none
Flask 模块
用于写网站, 范例如下:
import json
from flask import Flask
app = Flask(__name__)
def index():
"""功能模块,返回数据"""
return "首页"
def users():
data = [
{"id": 1, "name": "武沛齐", "age": 18},
{"id": 2, "name": "alex", "age": 18},
]
return json.dumps(data)
app.add_url_rule('/index/', view_func=index, endpoint='index') # 行为触发
app.add_url_rule('/users/', view_func=users, endpoint='users')
if __name__ == '__main__':
app.run()
time模块
- time模块
- time.time() 时间戳格式,获得从1970-1-1到现在过去的秒数
- time.timezone 获得时区
- time.sleep(5) 停止5秒
- time.strftime(time, “%Y-%m-%d %H:%M:%S”) #按格式来把时间变成字符串
- time.strptime(str_time, “%Y-%m-%d %H:%M:%S”) #按格式来解读字符串的时间
- time 和 datetime 模块不能直接读取,只能通过字符串方法来沟通
- datetime模块 用的比较多
- 现在的时间 datetime.now() ```python from datetime import datetime, timezone, timedelta
v1 = datetime.now() # 当前本地时间 print(v1)
tz = timezone(timedelta(hours=7)) # 当前东7区时间 v2 = datetime.now(tz) print(v2)
v3 = datetime.utcnow() # 当前UTC时间 print(v3)
- 时间格式转字符串 datetime.strftime(ctime)
- v1 = datetime.now()
- val = v1.strftime("%Y-%m-%d %H:%M:%S") # 日期对象有strftime方法
- val = datetime.strftime(v2, "%Y-%m-%d %H:%M:%S") # 等价于上面的方法
- 应用场景,对日期进行格式化打印输出,或者读取字符串格式日期
- 字符串转时间格式
- str_time = datetime.strptime("2021-10-27",**"%Y-%m-%d"**) #必须严格对应
- 计算时间差
- 时间的加减 timedelta对象
- v2 = datetime.now() + timedelta(days=140, minutes=5)
- 应用场景:算多少天之后/之前的日期
- 算过了多长时间,只能用两个时间的相减, 不能加,因为没有意义。
- 语法:tt= datetime.now()-datetime.utcnow()
- 应用:算两个时间的间隔,看花了多少时间
2021.10.28日复习时间模块,搞定,一周以后再看看。
```python
v1 = datetime.now()
print(v1)
# 时间的加减
v2 = v1 + timedelta(days=140, minutes=5)
print(v2)
# datetime类型 + timedelta类型
正则表达式模块
- 匹配模式
```latex
“abc” 匹配子字符串”abc”
[abc] 匹配a or b or c
[^abc] 不匹配a/b/c ^必须放在方括号的最开头才起作用 [a-z] 匹配a-z的任意字符 [0-9] 等同于\d . 匹配除了换行符以外的任意字符 \w 代指单词字符字母或数字或下划线或中文 \W 非单词字符
\d 代指数字 \D 非数字 \s 代指任意的空白符,包括空格、制表符等 \S 非空白
一下是匹配次数
- 任意次 比如: 2* 2匹配0次或以上
- 匹配一次以上 比如 2+ 2至少匹配一次
2? 2匹配0次或者1次 问号 0-1次
2{n} 2匹配n次
2{n,} 2匹配n次或者以上 2{n,m} 2匹配n到m次 (?=.\d) ?=表示将 .\d匹配数字并放到分组中,密码规则中经常使用
^ 从开头匹配 $ 结尾匹配
() 括号表示提取区域,可分组
.*? 加问号是非贪婪匹配,否则是最大匹配
2. match findall search方法:
```python
正则表达式的用法
MATCH: 从第一字符开始匹配,仅匹配一次,返回match对象
res = re.match('a\d+','a10') 从第一个字符开始匹配,返回匹配对象或者None
res.group() 匹配到的字符串 # a10
res.group(1) 正则表达式里面的括号中要提取的字符内容 # 10
要点是从第一个字符匹配,
re.match('a\d+','ba10') # 返回 None
ret.start() # 匹配的起始序号
ret.span() # (匹配起始序号,结尾序号)
SEARCH: 可以任意位置匹配,匹配一次,返回search对象
res = re.search('a\d+','ba10 a10')
扫描整个字符串并返回第一个成功的匹配。返回匹配对象 或者None
res.group() 匹配到的字符串 # a10
res.group(1) 正则表达式里面的括号中要提取的字符内容 #10
FINDALL: 任意位置匹配,匹配多次,返回列表
res = re.findall('a(\d+)','ba10 a10') # ['10','10']
扫描整个字符串并返回所有成功的匹配。返回匹配到的元素,并提取括号中内容做成列表[]
● findall(匹配模式,text) #找到符合匹配模式的字符串,返回列表
● match(匹配模式,text, flag) #返回一个match对象 match.group() 里面包含找到的字符串
○ flag 是控制使用匹配模式的方法 有如下选择
■ re.M re.ASCII
修饰符 描述
re.I 使匹配对大小写不敏感
re.L 做本地化识别(locale-aware)匹配
re.M 多行匹配,影响 ^ 和 $
re.S 使 . 匹配包括换行在内的所有字符 点不匹配换行符, 加上re.S,让点可以匹配空白字符
re.U 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.
re.X 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。
注意:
关于python正则匹配
search是贪婪匹配,他的贪婪是按顺序的,前面的字符会尽量多匹配,匹配不了的留给后面的。
match是从头匹配, findall是最大匹配返回列表
关于django的orm.save() 没有返回值
- 正则的正向预查和反向预查 ```python 问号是 \d{8,9}?非贪婪模式,优先匹配8个 | 管道符是或者
反向预查, r”(?<=收汇)\s*([MJX]\d{4}-?\d?)\s+([MJX]\d{4}-?\d?){,1}”, ‘收汇J4016-3 迪拜 Manoj’
正向预查,
- 正则的锚点和边界
```python
分组,锚点和边界
- 正则的分组和无提取分组 :::tips 无提取分组 :::
Faker模块 (搞测试专用)
3.Faker的使用
引用包:
from faker import Faker
初始化:
f=Faker(locale='zh_CN')
关于初始化参数locale:为生成数据的文化选项,默认为en_US,只有使用了相关文化,才能生成相对应的随机信息(比如:名字,地址,邮编,城市,省份等)
可选择的文化信息:
ar_EG - Arabic (Egypt)
ar_PS - Arabic (Palestine)
ar_SA - Arabic (Saudi Arabia)
bg_BG - Bulgarian
cs_CZ - Czech
de_DE - German
dk_DK - Danish
el_GR - Greek
en_AU - English (Australia)
en_CA - English (Canada)
en_GB - English (Great Britain)
en_US - English (United States)
es_ES - Spanish (Spain)
es_MX - Spanish (Mexico)
et_EE - Estonian
fa_IR - Persian (Iran)
fi_FI - Finnish
fr_FR - French
hi_IN - Hindi
hr_HR - Croatian
hu_HU - Hungarian
it_IT - Italian
ja_JP - Japanese
ko_KR - Korean
lt_LT - Lithuanian
lv_LV - Latvian
ne_NP - Nepali
nl_NL - Dutch (Netherlands)
no_NO - Norwegian
pl_PL - Polish
pt_BR - Portuguese (Brazil)
pt_PT - Portuguese (Portugal)
ru_RU - Russian
sl_SI - Slovene
sv_SE - Swedish
tr_TR - Turkish
uk_UA - Ukrainian
zh_CN - Chinese (China)
zh_TW - Chinese (Taiwan)
然后即可使用系统提供的方法:
一段简单的测试代码
f.name() #生成姓名
f.address() #生成地址
4.常用方法一览
city_suffix():市,县
country():国家
country_code():国家编码
district():区
geo_coordinate():地理坐标
latitude():地理坐标(纬度)
longitude():地理坐标(经度)
lexify():替换所有问号(“?”)带有随机字母的事件。
numerify():三位随机数字
postcode():邮编
province():省份
street_address():街道地址
street_name():街道名
street_suffix():街、路
random_digit():0~9随机数
random_digit_not_null():1~9的随机数
random_element():随机字母
random_int():随机数字,默认0~9999,可以通过设置min,max来设置
random_letter():随机字母
random_number():随机数字,参数digits设置生成的数字位数
color_name():随机颜色名
hex_color():随机HEX颜色
rgb_color():随机RGB颜色
safe_color_name():随机安全色名
safe_hex_color():随机安全HEX颜色
bs():随机公司服务名
company():随机公司名(长)
company_prefix():随机公司名(短)
company_suffix():公司性质
credit_card_expire():随机信用卡到期日
credit_card_full():生成完整信用卡信息
credit_card_number():信用卡号
credit_card_provider():信用卡类型
credit_card_security_code():信用卡安全码
currency_code():货币编码
am_pm():AM/PM
century():随机世纪
date():随机日期
date_between():随机生成指定范围内日期,参数:start_date,end_date取值:具体日期或者today,-30d,-30y类似
date_between_dates():随机生成指定范围内日期,用法同上
date_object():随机生产从1970-1-1到指定日期的随机日期。
date_this_month():
date_this_year():
date_time():随机生成指定时间(1970年1月1日至今)
date_time_ad():生成公元1年到现在的随机时间
date_time_between():用法同dates
future_date():未来日期
future_datetime():未来时间
month():随机月份
month_name():随机月份(英文)
past_date():随机生成已经过去的日期
past_datetime():随机生成已经过去的时间
time():随机24小时时间
timedelta():随机获取时间差
time_object():随机24小时时间,time对象
time_series():随机TimeSeries对象
timezone():随机时区
unix_time():随机Unix时间
year():随机年份
file_extension():随机文件扩展名
file_name():随机文件名(包含扩展名,不包含路径)
file_path():随机文件路径(包含文件名,扩展名)
mime_type():随机mime Type
ascii_company_email():随机ASCII公司邮箱名
ascii_email():随机ASCII邮箱
ascii_free_email():
ascii_safe_email():
company_email():
domain_name():生成域名
domain_word():域词(即,不包含后缀)
email():
free_email():
free_email_domain():
f.safe_email():安全邮箱
f.image_url():随机URL地址
ipv4():随机IP4地址
ipv6():随机IP6地址
mac_address():随机MAC地址
tld():网址域名后缀(.com,.net.cn,等等,不包括.)
uri():随机URI地址
uri_extension():网址文件后缀
uri_page():网址文件(不包含后缀)
uri_path():网址文件路径(不包含文件名)
url():随机URL地址
user_name():随机用户名
isbn10():随机ISBN(10位)
isbn13():随机ISBN(13位)
job():随机职位
paragraph():随机生成一个段落
paragraphs():随机生成多个段落,通过参数nb来控制段落数,返回数组
sentence():随机生成一句话
sentences():随机生成多句话,与段落类似
text():随机生成一篇文章(不要幻想着人工智能了,至今没完全看懂一句话是什么意思)
word():随机生成词语
words():随机生成多个词语,用法与段落,句子,类似
binary():随机生成二进制编码
boolean():True/False
language_code():随机生成两位语言编码
locale():随机生成语言/国际 信息
md5():随机生成MD5
null_boolean():NULL/True/False
password():随机生成密码,可选参数:length:密码长度;special_chars:是否能使用特殊字符;digits:是否包含数字;upper_case:是否包含大写字母;lower_case:是否包含小写字母
sha1():随机SHA1
sha256():随机SHA256
uuid4():随机UUID
first_name():
first_name_female():女性名
first_name_male():男性名
first_romanized_name():罗马名
last_name():
last_name_female():女姓
last_name_male():男姓
last_romanized_name():
name():随机生成全名
name_female():男性全名
name_male():女性全名
romanized_name():罗马名
msisdn():移动台国际用户识别码,即移动用户的ISDN号码
phone_number():随机生成手机号
phonenumber_prefix():随机生成手机号段
profile():随机生成档案信息
simple_profile():随机生成简单档案信息
四 项目开发规范
文件结构
- 文件名
- 简洁明了
- 不以数字开头
- 只用字母数字和下划线
- 文件夹名称
- import导入方式 ```python 导入一个模块 import directory as 别名 如果导入一个包(文件夹): 导入文件夹下的init.py
导入一个包
import dir.file : 导入文件里面所有的函数和变量
2. from xx import xx
```python
from xx import xx
导入一个模块
from xx import file
导入一个成员
from xx.xx import func
导入所有成员
from xx.xx import *
坑:
from xx import xx 不能导入包
- 在命令行状态下运行py程序的环境的报错 ```shell
要安装依赖包 pip3 install xxx
pip3 install xxxpycharm运行的依赖路径必须加入终端系统的依赖路径中,否则找不到或者报错 在pycharm中的python console中运行 sys.path获取环境依赖路径列表
把路径依赖写入python的环境变量中
在文件前面加入: sys.path.extend([前面获取的路径列表])因为虚拟环境的作用,python解释器做了分隔,路径中间加了venv,所以有时候找不到资源,python命令需要加绝对路径,可直接从pycharm的run监视器中获取详细信息,直接在命令行中使用即可
/Users/wongbrank/PycharmProjects/pythonProjec/makePDF/venv/bin/python /Users/wongbrank/PycharmProjects/pythonProjec/makePDF/main.py
实践证明:第4条的解释是对的,2和3实际都没有什么用。就此打住。 ☺
报错贴这,便于后面分析:
Traceback (most recent call last):
File “/Users/wongbrank/PycharmProjects/pythonProjec/makePDF/main.py”, line 9, in
- mac的批处理命令文件
```shell
第一步:新建 test.command
第二步:打开『终端』程序。给test.command加上可执行权限。命令为chmod +x test.command
第三步:用编辑器vim打开文本文件。输入可以在终端执行的指令。例如ls
根据自己的需求。编写你自己的批处理文件把。这里有一个问题。就是批处理执行完了。弹出的那个命令行不会自动关闭。为了解决这个问题。在批处理文件的最后加上代码:
osascript -e 'tell application"Terminal" to close (every window whose name contains".command")' &
exit
第四步:保存退出,双击运行
总结:
import xx | from xx import xx
后一种方式不节约内存,第二种方式也会导入所有成员
导入包级别的只能用import
- 导入的路径,寻找顺序如下:
- 第一顺位:执行文件所在的目录
- 第二顺位:系统默认的路径
- pycharm会自动把项目路径加入到sys.path, 给小白养成不良习惯
手动把目录加到系统路径中
import sys sys.path.append("指定路径") #导入的语法: #相对路径 #所有 from xxx import xxx,xxx from xxx import xxx as xx from .. import xxx from xxx import *导入要避免循环导入,比如a.py中 import b, 而b.py中 import a, 循环导入语句会被直接忽略,造成错误
- 导入流程图和坑
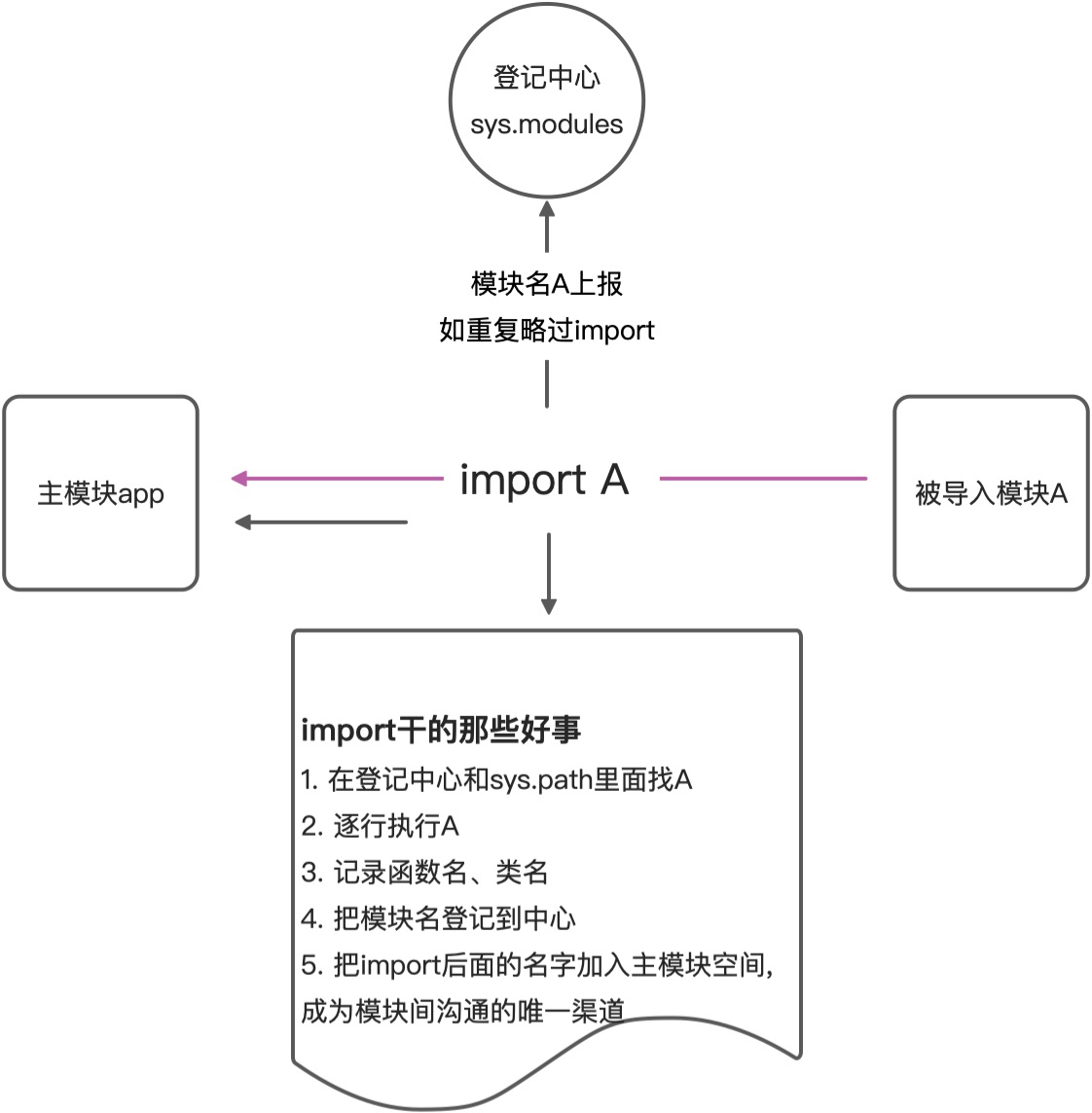
- 导入的模块和母文件之间是绑定关系,其他模块是看不到他的,模块之间的关系是单向的,主模块可以看见被导入的模块的资源,但是被导入的模块里面的代码是看不见主模块的内容的,这是一个单向观看的方法,可以透过儿子模块看见孙子模块。 导入的机理是把被导入模块的名称树加入自己的资源空间,而被导入模块是不会执行相应的动作,避免出现外溢效应。
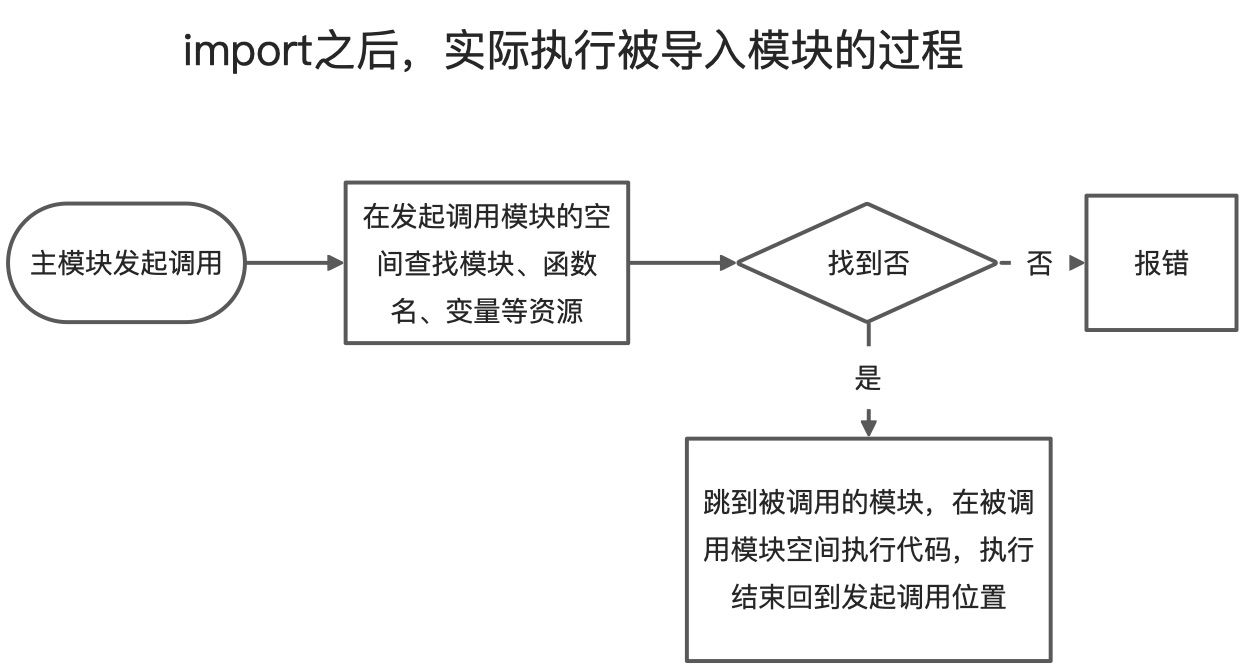
理解:
- 不是被加载进入内存的资源大家都能随便调用,每个模块只能在自己的一亩三分地耕种
- 可以透过导入的链条,隔级调用,但是特别注意关系网是单向,只能是发起导入的模块去调用被导入模块资源,或者透过被导入模块去调用被导入模块导入的资源
- 导入链条不要出现首尾相连,否则与登记中心里面重复的模块不会被执行,直接略过,不会报错
- 导入的过程
- 被导入模块会完整的按顺序执行一遍
- 将被导入的目标模块或者函数的名称加入主模块的资源列表 (dir(), dir()只能在全域执行的时候才能扫描到资源,在函数内部执行dir()显示为空, 因为资源列表只存在于空间根目录
- 项目开发原则:
- 主模块负责总览全局,调配资源
- 子模块只负责功能,不保留数据,源数据集中保存,统一取用(一对多模式)
- 配置文件要包括整个项目要用到的关键参数
- 每个功能区各司其职,不要混杂,给以后大型项目的开发奠定坚实的基础
- 避免循环调用和循环导入
五 面向对象
类和对象
类从形式上看是有关联性一些方法和数据的集合体,从意义上来说,它是模拟现实中的一些事物、人或机构,然后按这个思路去编写程序。对象是按照类(可以理解为类别)这个模板来实例化的实体。
类和对象的语法规则:
class Kind:
name = "xxx"
def xxx:
pass
k1 = Kind() #Kind是类, k1实例化的Kind对象
类的特性:
- 封装
- 数据的封装,这个数据只属于这个类,而不是共有的
- 方法的封装 ,这个方法只属于这个类,不是公有的
- 继承
- 子类可以继承父类中的公有方法和公有变量
- 继承关系可以有层级,可以有多个父亲,一般按照左手、深度优先原则
- 当调用发生时,先从对象内部查找,然后到父类中按左手、深度优先原则逐一查找,找到就返回
多态
实例变量,类变量
- self = 实例化变量之后,系统自动创建一块内存区域,并返回地址,当调用对象的方法时,python自动将当前对象当成参数self传递进去。
- 绑定方法 参数带self
- 类方法 参数带cls @classmethod
- 如果涉及类的变量,则可以选用类方法
- 静态方法 没有参数 @staticmethod
- 如果不涉及任何传入参数(包括self),则可以用静态方法
- 属性 @property 加上方法来实现,调用的时候可以省略后面的括号,就像访问变量一样
```python class Kind: @property def x(self):
k1 = Kind() v = k1.x # 这相当于 k1.x()return aa
属性的另外一个用法:
```python
class Kind:
def getx(self):
pass
def setx(self):
pass
deef delx(self):
pass
x = property(getx,setx,delx,"this is property") # 最后的是注释
k1 = Kind()
k1.x # 执行getx 一般是读取
k1.x = 20 # 执行setx 一般是赋值
del k1.x # 执行delx 一般是删除
.setter装饰器 ```python class Person: def init(self,name):
self.__name = name@property def name2(self):
return self.__name@name2.setter def name3(self,name):
self.__name = name
person = Person(‘晓明’) print(person.name2) # 晓明 person.name3 = ‘xiaoming’ print(person.name2) # ’xiaoming ‘
知识点:
1,@property 装饰器的作用是在调用时不用加括号,person.name 等价于 person.name()
2, @name2.setter 这里的name2必须跟property装饰器的方法同名,否则报错
3,name3可以与方法name2同名,也可以不同,不同的时候必须按 person.name3 = ‘xxx’的方式调用,而习惯上让这三个名字保持一致,可以简化使用方法。
4,这个跟property的如下方法类似:
def getx(self):
return self.x
def setx(self,n):
self.x =n
def delx(self):
del self.x
x = property(getx,setx,delx,’这是property函数’)
print(x) # 调用 getx x = 2 # 调用 setx(2) del x # 调用delx()
6. 成员修饰符:私有和公有的区分
- 私有变量和方法前面有双下划线 __ , 只有内部可以访问,外部无法访问
- 私有变量和方法不会被子代继承
- 特殊语法也可以访问私有变量和方法,仅做了解不推荐
- 特别注意区分:
- ` def __func(): ` 私有方法 (不可继承)
- ` def __init__() ` 特殊内置方法 (可继承)
7. 构造方法 __new__ , 这个是在__init__执行之前的一个步骤,先创建一个空对象
7. __call__ 方法 对象加括号 obj() 会触发类的call方法
7. __str__ 方法 str(obj)时调用的方法,打印对象的时候自动调用它输出其中内容
7. __dict__ 方法
7. __getitem__ __setitem__ __delitem__ 方法
1. 对象名[参数],调用getitem方法,将参数传入,并获得返回值
1. 对象名[参数] = 123 , 调用setitem方法,把参数和123传入
1. del 对象名[参数] ,调用delitem方法
12. 类中的上下文管理用法,enter 和 exit 方法,在下面方法时起作用:
```python
class Func:
def __enter__(self):
return self
def __exit__(self):
print("exit the object")
with Func() as f:
pass
# 执行过程:
# 1. Func() 初始化一个实例
# 2. 执行enter方法,返回一个实例对象
# 3. 将实例对象赋值给f
# 4. 执行正文
# 5. 退出正文时,执行exit方法
func() 可能是函数,也可能是类的实例化,也可能是有call方法的对象,要特别注意区分
可迭代对象
如果类中有可迭代方法,并返回一个迭代器对象,则称以这个类创建的对象为可迭代对象
<a name="kIU4a"></a>
## 类的嵌套
- 类之间的关联关系
在一个类的对象作为元素放到另外一个类的属性中,建立关联关系。类似于链表。在一个类中方法中,把另一个对象的作为参数传进来,这样可以通过一个对象的属性去访问另外一个对象,形成嵌套关系,可以多层嵌套
```python
class Student:
def __init__(self,name,age,school_obj):
self.name = name
self.age = age
self.school = school_obj
def show_student(self):
print(self.name,self.age,self.school.name)
class School:
def __init__(self,name,addr):
self.name = name
self.addr = addr
- 类的里面再定义一个类
```python
class Outter:
name = ‘alex’
class Meta:
pass
- c3算法
- mro()
<a name="ZdAEP"></a>
## 与类相关的内置方法
- callable() 检测对象是否可以call
- type() 检测是什么类 用这个方法可以找到对象对应的类
- isinstance(对象,类) 检测对象是否类的对象
- issubclass(类1,类) 类1是否类的子孙类
- **反射**:按字符串获取对象成员,有如下几个, getattr() setattr() hasattr() delattr()
- getattr(对象,“变量/属性/方法名”,参数) 如果取不到返回参数,如果不设置则报错 AttributeError, 参数可以是变量或者对象,可以实现一些有意思的操作
```python
stu_field = getattr(stu_obj, 'name')
setattr(stu_obj, 'name', 'alex')
hasname = hasattr(stu_obj, 'name')
delattr(stu_obj, 'name')
- super() 函数 ,可以调用父类的方法,避免多重继承导致的死循环
class A(object):
def add(self, x):
y = x+1
print(y)
class B(A):
def add(self, x):
super(B, self).add(x)
b = B()
b.add(2) # 3
在python3中可以省略掉 super里面的参数
重写对象索引方法
class Soup: class A: def __getitem__(self, item): return '索引方法返回值' a = A() Soup().a['x'] # '索引方法返回值'重写调用方法 call
- 重写迭代方法 iter
- 重写文本显示方法 str
六 网络编程
网络基础
两层交换机的小型网络
由路由器+两层交换机组建的局域网
三层路由器组织的局域网
互联网
IP地址和子网掩码
IP地址的公网地址不足的解决方案: NAT
公网IP和私网IP是不同范围内使用的,依赖NAT机制配合使用
IPV4的数量2**32 = 42亿
目前互联产品的数量远超这个数字,而IPv6虽然好使,但远水解不了近渴!于是就有了NAT
NAT解决方案
IP地址的分类
以左起第一段为准
- A类 1-127
- B类 128-191
- C类 192 -223
- D类 224 -239 (组播)
- E类 240-255 保留
私网可使用的段:
- 公私分开
- 公网地址绝不能重复
-
NAT具体实现
NAT是一个机制,位于网关 (自我理解:NAT像是女生宿舍的宿管大妈)
- 私网访问公网时,NAT将私网地址隐藏,加上本网关的公网地址,然后把数据包发给目标IP地址,目标地址回包的时候NAT执行相反的操作,将数据包回发给私网IP,这样就解决了IP不够的问题 (自我理解:女生宿舍内的人要往外发信,只能把信交给宿管大妈,大妈把女生的名字涂掉(当然大妈会偷偷记下来),贴上楼栋号(公网IP)发出去, 男神收到信以后原路回过去,宿管大妈收到信查找当时记下的名字,以后转交给那位女生。
外网不能主动访问局域网的私网IP地址,因为NAT机制隐藏了私网IP地址,外网不能主动获取。(自我理解: 宿管大妈把所有女生的名字对外隐藏了,所以男神不能主动给某个女生发信,只能等心仪的女生先发信给他)
疑问解答:
每台电脑是否同时有公网IP和私网IP地址?
答:否定的,局域网内的电脑只有私网IP地址,只有对外通信时,网关才会把公网IP地址贴在他的数据包上对外发送。- 外网发到内网的信如何到达具体的某台电脑?
答:一般是发不进来的。 只有在其中的某台电脑给外网发了信了,外网可以给他回信。回信的时候按来的路径返回。
网内IP和公网IP ipv4 ipv6
OSP7层链路结构
- 应用层:规定数据的格式 http
- http协议 数据请求格式,数据响应格式
- 表示层:对数据进行压缩编码 encode
3. 会话层:与目标建立连接 listen accept
4. 传输层:建立端口之间的联系 port
- TCP协议
- UDP协议
- 网络层:标记目标的ip地址 ip
6. 数据链路:对数据进行分组、设置源和目标mac地址 nat
7. 物理层:二进制数据在物理媒介上的传输 光纤
两种传输协议 UDP TCP
网络编程python代码
用socket模块构建UDP连接的CS服务
用socket模块构建的TCP连接的CS服务
B/S和C/S结构
BS 浏览器加服务器
CS 客户端加服务器
Socket 模块
socket 可以通过ip地址来连接主机,并发送数据,主要功能:
- 主机端
- 创建主机对象,TCP的主机 socket.socket(socket.AF_INET, socket.SOCK_STREAM. ) UDP主机 socket.socket(socket.AF_INET, socket.SOCK_DGRAM) UDP不管能不能到,直接发,效率高
- 绑定ip和端口 sock.bind(“ip地址”,8001)
- 接听连接 sock.listen(5)
- 接受连接 connect, addr = sock.accept()
- 发送消息 connect.sendall(msg.encode(“utf-8”)) connect.send()
- 接受消息 connet.recv(1024)
- 客户端
- 创建客户对象, socket.socket()
- 连接主机 sock.connect(ip地址,端口)
- 发送消息 sock.sendall(msg) msg是字节类型
- 接受消息 sock.recv(1024)
- 如何收发空文件,答:空文件没有收发的意义,在开始就拒绝比较好,否则出奇怪的错误
- 怎么保证收发同步,答:主机如果是不阻塞,客户端不阻塞,会出现不同步的情况,解决方法:
- 采用粘包解决方案
- 对于密集io操作,临时改用阻塞模式,避免缓冲区堵塞,报BlockingIOError,亲测好用。
ConnectionResetError: [Errno 54] Connection reset by peer 这个错误的发生背景:server不阻塞,client阻塞,使用struct方法收发数据,server在处理sock.recv()时提示这个错误,寻求原理解释和解决方案:
一个进程下可以有多个进程,共享进程资源。cpython里面有GIL锁,保证同一时间只有一个线程被调度
- 计算密集型,用多进程,提高并发能力
- IO密集型,用多线程,不涉及CPU能力,只要是网卡的负载。
进程
模块名和导入方法:
- multiprocessing
- 创建进程对象: p = multiprocessing.Process(target=task, args=(arg1,arg2))
- 运行进程对象 p.start()
- 子进程的调度的时间是不确定的,主进程执行完以后会等待子进程执行,然后才关闭程序;当然也可以设置不等待,语法: setDaemon(False/True)
模式:
- fork 拷贝父进程的资源 unix
- spawn 不拷贝任何资源,需要传参 unix win
- forkserver 也不拷贝资源,但拷贝模板,需要传参 unix linux
进程锁可以传参给子进程
导入模块 import threading
- 创建线程对象 t = threading.Thread(target,args(arg1,arg2))
- 运行线程对象 t.start()
- 进程等待 t.join() # 主线程会等待子进程完成再往下执行
- 进程锁
- 递归锁,可以反复锁开 lock_object = threading.Rlock()
- 同步锁,只能锁一次 lock_object = threading.lock()
- 申请锁 lock_object.acquire()
- 释放锁 lock_object.release()
- ** 特别注意,进程锁可以传参给子进程,而线程锁不行
- 死锁
- 两个进程相互申请对方的锁,卡死在一个地方
- 线程池,线程太多可能会导致效率反倒降低,所以可以使用线程池
t = threading.Thread(target=task,args=(form.instance.ttcopy.path,)) t.start()
<a name="DJkjD"></a>
## 进程和线程的结合
- 进程耗费资源比较大
- 两者的调用语法类似,可以结合使用
- 一个进程里面可以创建多个线程,范例如下:
```python
# 进程函数内定义两个线程
def task():
t1 = threading.Thread(target=task2)
t2 = threading.Thread(target=task2)
t1.start()
t2.start()
# 创建一个进程
p = multiprocessing.Process(target = task)
p.start()
pycharm开发工具
- mac上的安装
- 环境设置
```shell
pycharm为每个工程准备了一个虚拟环境,每个项目的环境是相互隔离的,不会产生干扰
当然可以选择已经存在的环境,避免重复安装 不过为了环境的洁净,应该为每个特定的工程安装充分必要的环境依赖即可,过多也是浪费资源
python从3.x版本开始就有较大的升级,区别于之前的版本,所以现在python3是安装包与python完全不一样,兼容度比较差,python3的包管理器是pip3, 而不是pip,特别注意
- 常见问题
```shell
1. unindent does not match any outer indentation level
Python中遇到IndentationError,以后第一时间就要想到,是不是由于TAB键和空格混搭使用了。
解决方案: 用pycharm中的option+command+L的快捷键启动格式检查和更正,或者菜单code - reformat code,一样的。
2.

若有收获,就点个赞吧
0 人点赞
