CRM知识框架
CRM,客户关系管理系统(Customer Relationship Management)。企业用CRM技术来管理与客户之间的关系,以求提升企业成功的管理方式,其目的是协助企业管理销售循环:新客户的招徕、保留旧客户、提供客户服务及进一步提升企业和客户的关系,并运用市场营销工具,提供创新式的个人化的客户商谈和服务,辅以相应的信息系统或信息技术如数据挖掘和数据库营销来协调所有公司与顾客间在销售、营销以及服务上的交互。
此系统主要是以教育行业为背景,为公司开发的一套客户关系管理系统。考虑到各位童鞋可能处于各行各业,为了扩大的系统使用范围,特此将该项目开发改为组件化开发,让同学们可以日后在自己公司快速搭建类似系统及新功能扩展。系统分为三部分:1. 权限系统,一个独立的rbac组件;2. stark组件,一个独立的stark组件;3. crm业务,以教育行业为背景并整合以上两个组件开发一套系统。
项目开发目录:
CRM 权限控制 RBAC模块
知识点结构:
- 权限 = url,一个url就是一个权限
- 不带正则的url
- 带正则的url
- 后台的权限表 Permission
- 权限名,与路由里面的url的name保持一致,方便后面权限控制到按钮
- url ,带正则的,所以中间件必须用正则匹配,且需要加上起始和终止符号
- menu_id , 所属一级菜单的id,有值的属于可做菜单的二级菜单 ,没有值是不可做菜单的二级菜单
- pid_id, 不可做菜单的权限与可做菜单的权限做关联,方便展开关联菜单
- 为了保证后台程序不出错,所有的受控权限的menu_id和pid不能同时为空
- 后台的一级菜单表 Menu
- 一级菜单名,一级菜单相当于权限归类,不是权限,所以没有url
- 一级菜单的图标 icon ( icon用https://fontawesome.dashgame.com/的来实现)
- 权限控制流程第一步:生成用户权限session表
- 用户登录,在views.login中,需要从权限表中获取用户的所有权限信息,构造权限session表,简单的权限session表只有url的列表
- 改进的权限session表1, 以权限名作为键的字典,方便在按钮的权限控制时,直接在模板渲染中做权限名的校验(字典的 key in dict 方法)
- 改进的权限session表2, 字典中加上 id 和 pid ,方便后面找到关联的菜单。逻辑是,如果pid存在,则pid对应的权限是关联菜单,如果pid没有值,则权限本身就是关联菜单,渲染时把menu_dict的相应class=‘hide’ or ‘show’做处理,免得在模板语法中再做判断
- 权限控制流程第二步: 生成用户菜单session表
- 菜单session表初级: 只存二级菜单,用列表存储,每个item是一个字典,其中存url,icon,权限名
- 菜单session表进阶:存两级菜单,一级菜单id做键值,一级菜单的信息做键值,其中增加一个children的键,存储二级菜单信息
- 菜单session表高级:在进阶表中的二级菜单信息中加入id信息,方便在第4项中的c方法中使用
- 权限控制流程第三步:中间件中加入权限控制
- 当用户访问时,获取用户的权限session表,把request.path与其中的url进行比对,成功则放行,否则给出404错误
- 同时,找到访问的权限对应的关联权限id,为菜单中的默认展开关联菜单做准备
- 获取用户的菜单session表
- 在inclusion_tag语法中,把关联菜单的class设为active,其父菜单展开
- 权限控制第四步: 权限控制细化到按钮
- 如果url的name在权限表的键中,则给显示,否则不显示
- 权限控制第五步:路径导航
- 当用户访问的时候把客户访问的权限的title和url加入导航列表
- 如果用户访问的是不能作为菜单的权限,需要同时添加其绑定的权限title
- 给当前访问的权限去掉链接和样式,不可点
- 可以把这些内容也放到inclusiontag中,方便作为模块使用
- 权限管理: 在django的admin模块中做权限表的增删改查操作
- 权限管理:用户/角色的增删改查
- ModelForm
- 增改的模板页面的公用
- 删除提示信息模板的公用
- 权限管理: 项目中权限的自动发现,自动添加到Permission表
- 权限分配
- 角色管理
- model form 和ORM
- 字段自定制
- 钩子方法
- 重写**init方法,批量给字段添加属性 **
- 错误提示(中文)
- 反向生成url,namespace,name
- 模板的查找顺序
- model form 和ORM
- 用户管理
- 菜单和权限管理
- 权限批量操作
- 角色管理
session的语法:
request.session[key]= value
request.session.get(key, “false_value”)
权限表结构设计:第一版
问答环节中已得出权限就是URL的结论,那么就可以开始设计表结构了。
- 一个用户可以有多个权限。
- 一个权限可以分配给多个用户。
你设计的表结构大概会是这个样子: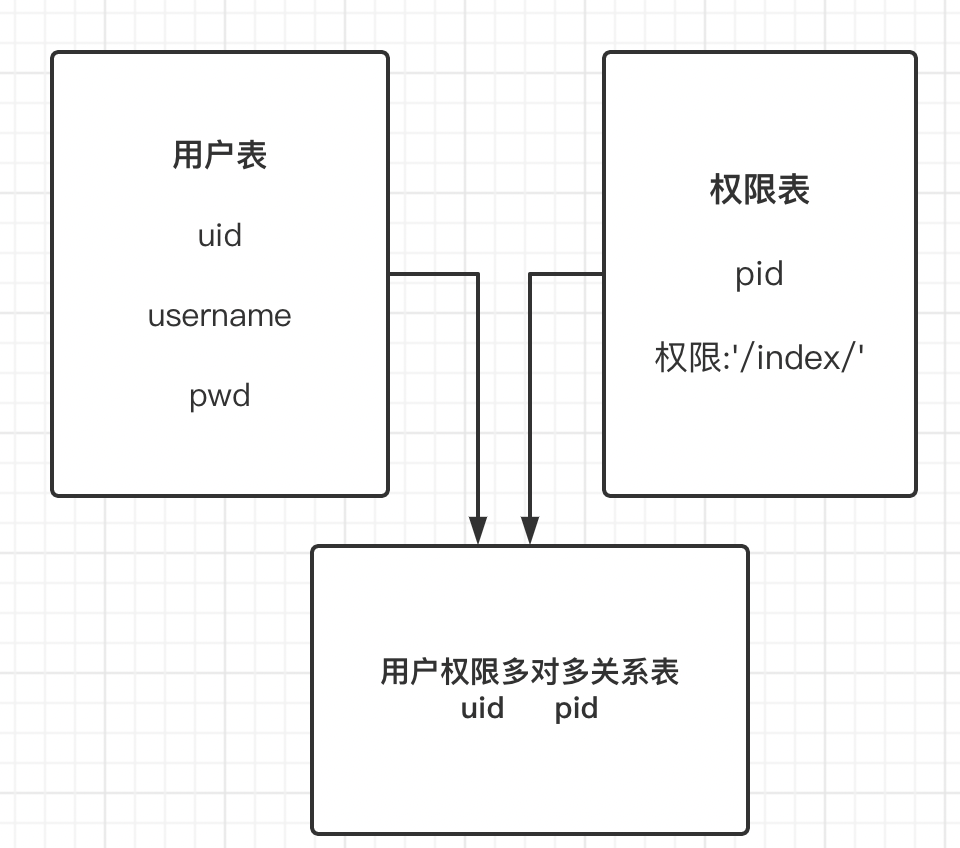
权限表结构设计:第二版
聪明机智的一定在上述的表述中看出了写门道,如果对用户进行角色的划分,角色划分是符合实际工作场景的权限归类法,方便快速的授权和批量修改授权等
- 一个人可以有多个角色。
- 一个角色可以有多个人。
- 一个角色可以有多个权限。
- 一个权限可以分配给多个角色。
表结构大概是这样子,设计三张表,实际五张表 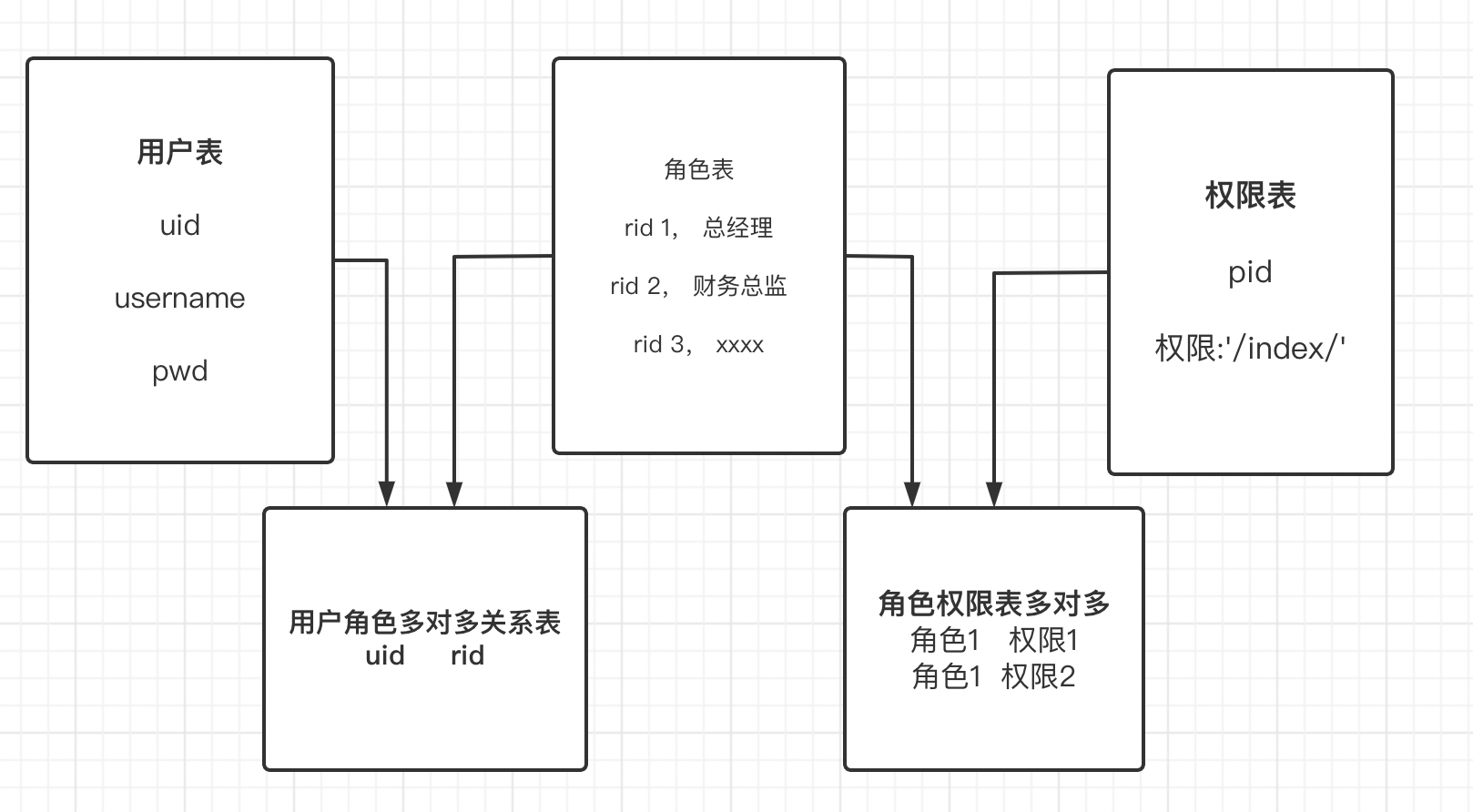
实际流程的处理:
第一步: 登录的时候获取用户的权限列表并保存到session中,注意权限列表要去重和去null值
第二步: 第二次访问的时候,读取session中的权限,如果匹配成功就给予放行,否则提示无访问权限
第三步: 把权限控制模块写到独立的rbac中,让其更方便迁移,具有通用性的模块
动态一级菜单
- 图标的显示
```html https://fontawesome.dashgame.com/ 下载fontawesome.min.css文件 把文件放入项目的static文件夹 在html文件中引入fontawesome.min.css
在需要使用图标的地方:
其中fa-dollar是图标的名称
- 一级菜单的实现原理
```html
在权限表中增加一列is_menu, 把可以设置为menu的设置为True
每次登录的时候把menu读取出来,存入session,下次访问时,直接从session中取到menu,渲染到页面中
动态二级菜单
- 实现原理(用字典做分层树形数据结构) ```html 增加一个menu表,存储所有的一级菜单
在权限表中,增加一个parent的字段,如果某个菜单可以作为二级菜单,就在这个parent里面存储他的父菜单的id
在每次登录的时候,读取menu创建一个字典套列表, 存入session: 如下:
{ 1:{ ‘一级菜单’:’订单管理’, ‘url’: ‘/order/‘, ‘children’:[{‘二级菜单名’:’增加订单’,’url’:’/order/add/‘},{‘二级菜单名’:’删除订单’,’url’:’/order/delete/‘},] }, 2: {‘一级菜单’:’发货管理’, ‘url’: ‘/consignment/‘, ‘children’:[{‘二级菜单名’:’增加发货单’,’url’:’/consignment/add/‘},{‘二级菜单名’:’删除发货单’,’url’:’/consignment/delete/‘},] }
}
在下次访问的时候,读取session中的menu,将它展示在页面中
- 二级菜单高亮
```python
第一步:
# 找到需要高亮的菜单id
request.hilight_menu_id = item['pid'] or item['id']
第二步:
# 找到高亮的菜单,把class设为hilight,父级菜单的hide属性去掉,然后结束循环
@register.inclusion_tag("left_menu.html")
def left_menu(request):
menu_dict = request.session[settings.MENU_LIST_KEY]
if request.hilight_menu_id:
for primary_menu in menu_dict.values():
for item in primary_menu['children']:
if request.hilight_menu_id == item['id']:
item['class']='hilight'
primary_menu['class']=''
return {"menu_list": menu_dict.values()}
return {"menu_list":menu_dict.values()}
# safe管道符将整型转换为字符串
- 路径导航 ```python 第一步: 获取当前访问的permission
第二步: 如果有pid,把父级菜单和本身都加到字典里面去 elif: 如果没有pid也没有mid,则为空 else: 如果有mid,则只把自己加入到字典中去
第三步: 在模板中渲染
代码如下:
<a name="seG9N"></a>
### ModelForm 增改工具
- 创建ModelForm的类
ModelForm和Form的区别:<br />a. modelform在Meta里面定义的field是数据来源(只写字段名即可),widget是控件样式<br /> form里面需要对每一个字段进行定义,类似于ORM,然后在字段里面的widget属性定义控件样式<br /> fields属性是一个字典,可用self.fields['字段名']的方式访问该字段对象
b. modelform的Select控件自动从该字段取值,不用手动操作,手动赋值的内容会添加进去而不是取代<br /> form的Select需要手动赋值,form有一个ChoiceField字段,这个比较另类,后面有案例
c. form.clearned_data["field_name"] 获取的是字段对象,不止是文本
d. form.instance 获取当前form对应的model对象,后面的操作可以等同于ORM的操作,比如跨表操作等等 <br /> 例1: form.instance.student.score <br /> 例2: form.instance.student.save() # Student表的记录的保存 <br /> 例3: form.instance.gender = 2 # form对应model的gender字段更新为2
e. 设置只读字段 <br /> 方法1. widgets = {**'customer'**:forms.TextInput(attrs={**'readonly'**:**True**})}<br /> 方法2.
<a name="dfQ0F"></a>
#### 常用增删改查操作
功能: 方便前端和后端的沟通,把从前端收集数据和手段解析数据的功能模块化
```shell
# 依赖的模块
from rbac import models
from django.forms import ModelForm, widgets #modelform的类,以及插件
from django import forms #forms的核心功能
import re
class MyModelForm:
# 新增加自定义字段
re_password = forms.CharField(label='确认密码')
class Meta:
model = Mymodel # 关联的ORM的model
# 前端要显示的控件字段,默认TextInput
fields = "__all__" / ['name','age','re_password']
exclude = ["password"] #除了email的所有字段
# 控件前端显示 ( 会这一种方法就行,高深的再说吧)
widgets = {
'create_date': forms.DateInput(attrs={'type':'date'}
# 显示日期空间和日期图标
"content": froms.Textarea(attrs={"cols": 30, "rows": 6}),
} # 设置textarea空间的显示长宽
# 控件前面显示的label名称,如不写,默认ORM里面的verbose-name
labels = { 'name': '用户名', 'age':'年龄' }
# 跟字段绑定的错误显示
error_messages = {
'name' : {'required':'书名不能为空'}
}
# 用户帮助信息
help_texts = {'name':'请输入用户名'}
def __init__(self, *args, **kwargs):
super(MyModelForm, self).__init__(*args,**kwargs)
# 在初始化中,将attr的readonly设为只读
fields["field_name"].widget.attrs["readonly"]=True
# 这里 type: data 可以让前端出现一个日期输入图标
fields["field_name"].widget.attrs["type"]= 'date'
# 批量化加上form-control的class属性
for name,field in self.fields.items():
field.widget.attrs["class"]="form-control"
def clean_age(self):
# 局部校验钩子
age = self.cleaned_data.get('age')
if False:
forms.ValidationError('输入错误')
else:
return age
前端:添加数据 ```html
{{ handle }}
备注: 仍然应该使用for语句来执行formset的字段渲染,因为系统会自动添加一个隐含的input,把每行的id加上去,没有的话,系统会报错missing management data; 隐含的input长下面这个样子。
- 后端: 添加数据python
第一种情况:所有字段信息都在request.POST中
def useradd(request):
if request.method == “GET”:
form = UserModelForm()
handle = “添加用户”
// 把实例化的空modelform传递给模板
return render(request,”role/change.html”,locals())
if request.method == “POST”:
# 通过modelform的data语法,可以直接读取POST里面的信息,并实例化UserModelForm
form = UserModelForm(data=request.POST)
# 其他初始化的方法: 同时使用instance和 data 两个参数,
# 执行顺序是先用obj来初始化对象,然后用POST数据来更新
obj = UserInfo.objects.filter(pk=2).first
form2 = UserModelForm(instance= obj, data=request.POST)
# 第三种初始化方法: 使用initial 参数
# 与instance方法不同的是,他自初始化,不关联ORM表记录
datadict = {‘name’:’Alex’,’age’:20, ‘password’:’1234’}
form3= UserModelForm(initial = datadict )
# .isvalid()方法:校验字段有效性,生成错误信息,生成清洁信息字典
if form.isvalid():
# .instance可以获取form关联的ORM对象,且可以进行赋值操作form.instance.name = ‘Flip’ # form.save()方法可以把获取的清洁信息字典作为键值对,并在关联ORM中创建新纪录 form.save() return redirect(reverse(“rbac:userlist”)) else: return render(request,”role/change.html”,locals()) 第二种情况:添加request.POST没有的字段 def permissionadd(request,sid): if request.method == “POST”: form = PermissionModelForm(data=request.POST) if form.isvalid(): secondmenuobj = models.Permission.objects.filter(pk=sid).first() if not secondmenuobj: return HttpResponse(“二级菜单不存在”) # 关键是下面这一句,通过form.instance.字段名可以对该字段赋值
form.instance.parent = secondmenuobj form.save()
- 前端:修改数据python
与添加数据的模板相同
- 后端:修改数据python
第一步: 新建一个modelform,只要其中两个字段# 用于用户信息编辑的model form class UserEditModelForm(ModelForm): class Meta: model = models.MyUser fields = “all“ exclude = “id” def init(self,args,**kwargs): super(UserEditModelForm,self).init(args,**kwargs) for name,field in self.fields.items(): field.widget.attrs[“class”]=”form-control” 第二步:展示可以修改信息 def useredit(request,pk): user_obj = models.MyUser.objects.filter(pk=pk).first() if request.method == “GET”: if not user_obj: return HttpResponse(“404错误”) # 初始化方式二: instance语法可以将ORM记录直接当成参数传递给个ModelForm form = UserEditModelForm(instance=user_obj) handle = “编辑用户” return render(request,”role/change.html”,locals()) 第三步: 提交修改的信息 if request.method == “POST”: # 下面的语法做了两件事情: # 1. 用user_obj实例化UserEditModelForm # 2. 用data数据更新对应字段信息
form = UserEditModelForm(instance=user_obj, data=request.POST) # 校验这一步必须要做 if form.is_valid(): # form.save()方法可以把获取的清洁信息字典作为键值对,并在关联ORM中创建新纪录 form.save() return redirect(reverse(“rbac:user_list”)) else: return render(request,”role/change.html”,locals())
- 前后端: 删除信息,比较简单,这里从略。只要注意一点即可:删除前给一个二次考虑的机会,避免误操作
- 设定输入的格式
知识要点:
1. 在内层定义的类对象不能使用上层类对象的变量名空间,但是外层的可以通过self.variable_name使用内层的变量,这个不知道有没有普遍性: 这个地方理解不对,其实modelform自己维护了一个fields属性
1. fields属性: 字段名列表
1. widgets属性:所有字段的显示模板样式及其参数 ,字典数据类型
1. widget属性: 某个字段的显示模板样式插件 语法是:field.widget = forms.RadioSelect(choices=xxx)python
# 导入模块 mark_safe
from django.utils.safestring import mark_safe
# 用于用户信息编辑的model form
class MenuAddModelForm(ModelForm):
choices = settings.AVATAR_CHOICES
class Meta:
# model = models.Menu
# fields = [“title”, “icon”]
# widgets = {
# “title”: forms.TextInput(attrs={“class”: “form-control”}),
# “icon”: forms.RadioSelect(choices= settings.AVATAR_CHOICES)
# }
model = models.Menu
fields = [“title”, “icon”]
widgets = {
“title”: forms.TextInput(attrs={“class”: “form-control”}),
# “icon”: forms.RadioSelect(choices=self.choice)
}
def __init(self, args, *kwargs):
choices = []
super(MenuAddModelForm, self).__init(args,*kwargs)
# 用set方法可以快速合并两个不重复列表
menu_set = set([item[‘icon’] for item in models.Menu.objects.values(“icon”)])
avatar_set = menu_set | set(settings.AVATAR_CHOICES)
for item in avatar_set:
node = (item, mark_safe(f”“))
choices.append(node)
self.fields[‘icon’].widget = forms.RadioSelect(choices = choices)
# RadioSelect(单选框组件)接受的参数choices的数据结构:
[(value, option_name),(xx,xx_title),()]
而且这个choice可以接受其他类似的可迭代对象,比如QuerySet,但每个元素必须是列表
# 对于option_name是html语言的,这里用mark_safe函数可以让字符串以html格式渲染到html文件中,而不是显示字符串本身
- widgets的源码分析python
class DateInput(DateTimeBaseInput):
input_type = “date”
format_key = ‘DATE_INPUT_FORMATS’
template_name = ‘django/forms/widgets/date.html’
# input_type = “date” 等同于 ##### django/forms/widgets/date.html #####
- ChoiceField 字段
语法如下:<br /> 要点1:直接初始化choices 参数,不用在widget里面写 ,这个不同于IntegerField <br />要点2:手动的添加choice,只能先在初始化添加一个列表,然后在inite方法里面choices+= xxxx <br />否则报错:queryset 与 列表不能直接concatatepython
class AutoPermissionAddModelForm(forms.Form):
second_menu_choices = models.Permission.objects.filter(menuisnull=False).values_list(“id”,”title”)
parent_id = forms.ChoiceField(label=”二级菜单”,choices=[(None,”——-“),],required=False)
def init(self,args,*kwargs):
super(AutoPermissionAddModelForm,self).__init(args,*kwargs)
self.fields[“parent_id”].choices += self.second_menu_choices
- modelform的高阶内容python
from django import forms
from app01.models import UserInfo
from django.forms import fields as Ffields
from django.forms import widgets as Fwidgets
import time, datetime
class UserInfoModelForm(forms.ModelForm):
age = Ffields.IntegerField(
label=’年龄’,
widget=Fwidgets.TextInput(attrs={‘class’: ‘form-control’}),
initial=22
)
gender = Ffields.CharField(
label=’性别’,
widget=Fwidgets.TextInput(attrs={‘class’: ‘form-control’}),
initial=’男’
)
birth = Ffields.DateField(
label=’生日’,
widget=Fwidgets.DateTimeInput()
)
class Meta:
# 与models建立了依赖关系…………………………………..
model = UserInfo
# 字段…………………………………………………
fields = [‘username’, ‘email’, ‘user_type’, ‘age’]
# 排除字段………………………………………………
exclude = None,
# 帮助提示信息……………………………………………
help_texts = {
‘username’: ‘请输入账号’,
‘email’: ‘请输入邮箱地址’,
‘user_type’: ‘请选择客户类型’
},
# 自定义插件……………………………………………..
widgets = {
‘username’: Fwidgets.TextInput(attrs={‘class’: ‘form-control’})
},
# 自定义字段类(也可以自定义字段)……………………………..
field_classes = {
# 设置此处,前端输入时,就必须是url,否则提示错误
# ‘email’: Ffields.URLField,
}
# 本地化,如:根据不同时区显示数据……………………………..
localized_fields = (‘ctime’,)
# 如果此处不写,会显示数据库模型设置的verbose_name………………..
labels = {
‘username’: ‘账号’,
‘email’: ‘邮箱’,
‘user_type’: ‘类型’
}
# 自定义错误信息…………………………………………..
# 整体错误信息from django.core.exceptions import NON_FIELD_ERRORS
error_messages = {
‘__all‘: {
‘required’: ‘此处不能为空’
},
‘age’: {
‘invalid’: ‘请输入一个有效的年龄’
}
}
<a name="Icl86"></a>
#### 给外键字段添加“增加记录”的按钮
方法一:重写widget插件, 加入一个a标签 代码如下:python
# 定制一个widget插件,把a标签加入到render里面class RelatedFieldWidgetCanAdd(widgets.Select): def __init(self, related_model, related_url=None, args, *kw): super(RelatedFieldWidgetCanAdd, self).__init(args, *kw) if not related_url: rel_to = related_model info = (rel_to._meta.app_label, rel_to._meta.object_name.lower()) related_url = ‘stark:%s%sadd’ % info # Be careful that here “reverse” is not allowed self.relatedurl = relatedurl def render(self, name, value, args, **kwargs): self.related_url = reverse(self.related_url) output = [super(RelatedFieldWidgetCanAdd, self).render(name, value, args, **kwargs)] output.append(u” + “ % (self.related_url)) return mark_safe(u’’.join(output)) class ClientHandler(StarkHandler): def get_model_form(self): class DynamicModelForm(ModelForm): country = forms.ModelChoiceField( required=False, queryset= models.Country.objects.all(), widget= RelatedFieldWidgetCanAdd(models.Country) ) class Meta: model = self.model_class fields = “__all“
方法二:通过ajax给前端传递一个js代码实现popup一个窗口,快速简易处理增加数据python
介绍原文地址:
https://djangopy.org/how-to/reverse-engineering-of-the-django-admin-foreign-keys-addedit-button/
#####################################
- 第一部分,显示popup窗口前端的添加按钮,绑定点击事件, 添加
点击添加按钮后触发这段js代码 function showAddPopup(triggeringLink) { # 获得html代码中id值 add_author, 并去掉add, 这是name= author,这样做让代码具有通用性 var name = triggeringLink.id.replace(/^add/, ‘’); # 获得html中的url地址
href = triggeringLink.href; # 打开一个窗口,并向url发起的get请求,窗口名称name,宽高500x500,语法如下: var win = window.open(href, name, ‘height=500,width=800,resizable=yes,scrollbars=yes’); # 新窗口获得聚焦 win.focus(); return false; } 注意: 假设链接中同时存在 href 与 onclick,如果想让 href 属性下的动作不执行,onclick 必须得到一个 false 的返回值。不信,你可以将 goGoogle 函数中的 return false 注释掉; 这个可以解释为什么上面的showAddPopup return false,而且onclick里面有return this: 触发的a标签
##################################### 第二部分 post提交新建的数据
# 服务器端的view.py 作者弹窗的返回数据, def AuthorCreatePopup(request): form = AuthorForm(request.POST or None) # 如果有数据,说明是post请求,如果没有数据说明是get请求 if form.isvalid(): # 如果数据校验合格,存在数据库,返回instance
instance = form.save() ## Change the value of the “#idauthor”. This is the element id in the form # 把下面这段js代码返回给前端,关键是authorid,这个值必须来自于数据库 # 我们看前端怎么处理这段代码
# 下面’%s‘要加引号,因为这段要显示在前端的时候,不加引号视为变量 return HttpResponse(‘‘ % (instance.pk, instance)) return render(request, “authorform.html”, {“form” : form}) # 前端对这段代码的处理
# 记住前面已经弹窗了一个/author/create/的窗口,且把空数据的form渲染进去 # 填完数据以后,收到服务器返回的代码 ‘ % (instance.pk, instance) 详解上面的js代码: 1. opener相当于 window.opener 这个window是本窗口,window.opener是其父窗口,调用父窗口中的closePopup函数来关闭本窗口,函数如下: 父窗口中函数: function closePopup(win, newID, newRepr, id) { $(id).children().attr(‘selected’,false); $(id).prepend(‘‘) win.close(); // 必须要刷新picker,否则不显示也搜不到 $(id).selectpicker(‘refresh’); $(id).selectpicker(‘render’); } 知识点: 必须要有这两句,才可以把新增的选项动态添加到options当中
$(id).selectpicker(‘refresh’); $(id).selectpicker(‘render’);
<a name="OQGqX"></a>
#### 给外键添加下拉搜索框
依赖的js和css代码文件:
bootstrap-select.js
bootstrap-select.css
在github上下载的下面的文件:
bootstrap-select-1.13.14 (由MIT实验室开发)
目录结构,其中dist文件夹是我们需要的,下面有两个子文件夹 css,js,找到上面其中的两个文件:
bootstrap-select.js
bootstrap-select.css
把他们引用到html文件中即可
** sample.html **
{# 带选择的下拉框 #}
自定义一个popup_list, 只要在这里面的字段,就给他一个➕
<a name="xlCzG"></a>
#### ModelForm上传文件python
第一步:
前端在form中必须加上属性 enctype=”multipart/form-data”
第二步:
把request.FILES 参数加入到form_class的初始化中,注意关键字参数instance要放最后
其他操作与普通字段的存储完全一样
if request.method == “POST”:
form = form_class(instance=edit_obj,data=request.POST)
if request.FILES:
# 关键就是这一句
form = form_class(request.POST,request.FILES,instance=edit_obj)
if form.is_valid():
responds = self.save_form(form,request,True,args,kwargs)
return responds
else:
return render(request, self.edit_list_template or “stark/change_list.html”, locals())
- 下载文件python
def download_file(self,request,file_name, *args,kwargs):
file_path = os.path.join(settings.MEDIA_ROOT,file_name)
with open(file_path,’rb’) as f:
try:
response = HttpResponse(f)
response[‘Content-Type’] = ‘application/octet-stream’
response[‘Content-Disposition’] = ‘attachment;filename=”%s”‘ % (file_name)
return response
except Exception as e:
print(e)
return HttpResponse(“下载失败”)
# 知识点:
下载文件的response要设置content-type 和 content-disposition两个键值
<a name="Qq85i"></a>
#### 不想让用户编辑的字段
可以在modelform中加上disabled属性,注意django内部外键字段渲染的时候用的是Select控件python
class CourseRecordModelForm(StarkModelForm):
class Meta:
model = CourseRecord
fields = “__all“
widgets = { ‘classes’:forms.Select(attrs={‘disabled’:True})}
<a name="W4wEb"></a>
#### 添加数据时初始化个别字段python
def add_list(self, request, args, kwargs):
if request.method == “GET”:
form = AddStudentModelForm()
if request.GET:
query_para = request.GET.get(‘_filter’)
if re.match(‘classes_id’,query_para):
name,classes_id = query_para.split(“=”,1)
class_obj = Classes.objects.filter(pk=classes_id).first()
form.fields[‘classes’].initial=class_obj
知识点:
设置初始值:
form.fields[‘classes’].initial=class_obj
- 初始化时,instance和initial的冲突解决
问题: 下单日期不能自动加载,这是什么原因了。 form实例化以后,
用form.instance.confirm_date = ’‘ 不显示
原因:instance赋值以后,initial不起作用了,这两个有冲突,为什么,怎么办
# instance是python的对象,并不会直接影响前端显示,所以应该用initial方法,而form是表单对象
具体机理后面再进一步探讨,目前先解决问题下面的解决方案可行: form = ConfirmApplyOrderModelForm(instance=order_obj,initial={‘confirm_date’:’2022-05-08’}) 但是下面的不行: form = ConfirmApplyOrderModelForm(instance=order_obj) form.fields[‘confirm_date’].initial = ‘2022-02-08’
<a name="NEerD"></a>
#### 后端手动申报错误python
if formset.is_valid():
print(formset.cleaned_data)
row_list = formset.cleaned_data
failure = False
for i, row in enumerate(row_list):
print(‘i,row:’,i,row )
print(row[“dist_amount”],type(row[“dist_amount”]))
print(row[“id”], type(row[“id”]))
dist_amount = row[“dist_amount”]
applyorder_obj = row[“id”]
if dist_amount == 0:
continue
try:
pay2order_obj= Pay2Orders(order=applyorder_obj,payment=inwardpay_obj, amount=dist_amount)
if dist_amount > applyorder_obj.collect_amount:
# 重点在这里 formset的errors信息的格式: {字段:[错误信息,]}
formset.errors[i].update({‘dist_amount’: [‘关联金额不能大于应收金额’,]})
raise forms.ValidationError(‘关联金额不能大于应收金额’)
elif dist_amount < 0:
raise forms.ValidationError(‘关联金额必须大于0’)
inwardpay_obj.validate_unique()
inwardpay_obj.torelate_amount -= dist_amount
applyorder_obj.rcvd_amount += dist_amount
pay2order_obj.save()
inwardpay_obj.save()
applyorder_obj.save()
except Exception as e:
print(e)
# formset.errors[i].update({‘dist_amount’:e.messages})
failure = True
if failure:
return render(request, ‘dipay/related_to_orders.html’, locals())
知识点:
formset的错误信息的底层格式:
formset的errors信息的格式: {字段:[错误信息,]}
formset.errors[i].update({‘dist_amount’: [‘关联金额不能大于应收金额’,]})i是每行的行号,dist_amount是字段名 modelform的错误信息格式: form.errors 存储所有的错误,其为一个字典,{‘dist_amount’: [‘关联金额不能大于应收金额’,]} 所以手动报错语法为: form.errors.update({‘dist_amount’: [‘关联金额不能大于应收金额’,]})
<a name="op8yN"></a>
#### 同时涉及两张表的数据的处理html
formset_factory 如果部分字段内容来自另外一个表,怎么处理呢,有两种思路:
1. 如果以要创建的表为基础,则需要把其他字段内容手动放到formset的initial里面,且需要用instance.字段名的方式,避免显示输入控件2. 如果以内容比较多的表为基础,另外一张表额外添加字段,然后手动处理。因为modelform只能以一张表为基础
<a name="emPdP"></a>
### 反向生成 URL
- 反向生成: namespacepython
**project/urls.py **
path(‘rbac/‘, include((“rbac.urls”, “rbac”), namespace=”rbac”)),
说明:include的第一个参数是元组(二级路由,namespace)
**rbac/urls.py **
url(‘\customer\edit(?Pnamespace的报错:specifying a namespace in include without providing an app_name is not allowed <br />解决方案:python
方案一:
如上段代码,在include((“rbac.urls”, “rbac”)中加上了app_name: “rbac”.方案二: 在rbac.urls中指定app_name
**project/urls.py ** path(‘rbac/‘, include(“rbac.urls”, namespace=”rbac”)), 说明:include的第一个参数是元组(二级路由,namespace) **rbac/urls.py ** app_name=”rbac” # 在这里指定app_name也可以 url(‘\customer\edit(?P
- 反向生成:python
** urls.py **
url(‘\customer\edit(?P- 反向生成: reversepython
1. 不带参数的url
reverse(“customer_list”)
2. 带参数的url:当原路由做的无名分组 url(‘\customer\edit(\d+)’,view.customer_list)
reverse(“customer_list”,args=(1,))
3. 带参数的url:当有名分组 url(‘\customer\edit(?P- 反向生成的模板使用
<a name="GjD8Y"></a>
### 有序字典python
第一步:导入
from collections import OrderedDict
第二步:初始化
order_dict = OrderedDict()
第三步:取到排序的键
key_list = sorted(menu_dict)
第四步:循环key_list,把键值存入order_dict
方法一:
for k in key_list:
order_dict[k] = menu_dict[k]
方法二:
item[0]表示按键排序,item[1]按键值排序,reverse = True 逆序
order_dict= sorted(menu_dict.items(),key=lambda item:item[0],reverse=True)
方法三:
order_dict = {k:menu_dict[k] for k in key_list }
# python 3.7以后已经支持有序字典了,所以可以用方法三
# 最保险的是用方法一- 模板语法数据类型不一致的处理:管道符safepython
# 这里通过safe可以把整型转换为字符串,排除类型不一致的问题
<a name="lCDC3"></a>
### 保留原搜索条件
需求背景: 添加一个记录以后,跳转回原来的页面并把原来的筛选条件保留下来 <br />思路: <br />原页面路径和搜索条件 customer/list/?mid=1&sid=2
第一步:<br />添加按钮: 在路径后面拼接 customer/add/?_filter="mid=1&sid=2"<br />拼接的时候要对=和&进行转义,使用QueryDict.urlencode()方法
第二步:<br />进入添加页面 customer/add/?_filter="mid=1&sid=2"<br />添加记录完成
第三步: <br />跳转回来<br />从_filter里面取回搜搜索条件,拼接回去 <br />redirect("/customer/list/?mid=1&sid=2")python
第一步:
** customer_list.html **
{% load rbac %} //rbac.py 存的都是tags处理的方法编辑 第二步: **
url = reverse(name, args=args, kwargs=kwargs) if request.GET: query_dict = QueryDict(mutable=True) # mutable 可变的,否则query dict不支持修改 query_dict[‘_filter’] = request.GET.urlencode() url = “{}?{}”.format(url,query_dict.urlencode()) return url # /rbac/permission/menu/add/?_filter=mid%3D3%26sid%3D2 第三步:
** views * def menu_del(request,pk): handle = “删除一级菜单” filter_term = request.GET.get(“_filter”) # get方法自动解码,自己调用querydict # mid=3&sid=2 cancel = reverse(“rbac:permission_list”) if filter_term: cancel = “{}?{}”.format(cancel,filter_term) return render(request,”role/delete.html”,locals()) 回顾知识:render这个方法不会改变地址栏的地址,只呈现需要render的页面内容 # 为了程序的解耦合,把公共模块放在utils的文件夹中,并把类似的功能放在同一个文件中,便于统一维护和修改
<a name="ATKpA"></a>
### 外键字段限定数据源shell
limit_choices_to={“departmenttitle”:”销售部”},
如下案例:
# 客户表
class Customer(models.Model):
title = models.CharField(max_length=11,verbose_name=”客户名”)
contact = models.CharField(max_length=128,verbose_name=”联系方式”, null=True)
age = models.IntegerField(verbose_name=”年龄”)
courses = models.ManyToManyField(to=Course,related_name=”customer”,verbose_name=”意向课程”)
note = models.CharField(max_length=128, verbose_name=”备注”)
consultant = models.ForeignKey(to=MyUserInfo,
on_delete=models.CASCADE,
verbose_name=”销售顾问”,
limit_choices_to={“departmenttitle”:”销售部”},
null=True,blank=True )
status = models.IntegerField(choices= [(1,”已报名”),(2,”咨询中”),(3,”不考虑”)], verbose_name=”状态”,default=2)
date = models.DateTimeField(auto_now_add=True,verbose_name=”创建日期”)
last_contact_date = models.DateTimeField(verbose_name=”最后跟进日期”, auto_now=True)
<a name="S97Jg"></a>
### formset批量添加
- 前端使用
功能:一次添加多个表单html
批量添加权限
- 后端使用
```python
第一步:定义forms.Form
****************** forms.py *********************
class PermissionMultAddModelForm(forms.Form):
choices = models.Permission.objects.filter(menu__isnull=False,parent__isnull=True).values_list("id","title")
title = forms.CharField(max_length=30,label="权限名",widget=forms.widgets.TextInput())
urls = forms.CharField(max_length=30,label="URL",widget=forms.widgets.TextInput())
name = forms.CharField(max_length=30,label="URL别名",widget=forms.widgets.TextInput())
parent_id = forms.IntegerField(label="二级菜单",widget=forms.widgets.Select(choices=choices),required=False)
第二步:def views函数
分为三小步:
a,导入 django.forms import formset_factory
b,定义自定义的formset类
c,初始化自定义formset对象
其中的initial参数可以使用一个字典列表来初始化每一行数据,每个字典初始化一行,字段名要对应
以下明细:
****************** views.py *********************
def permission_mult_add(request,sid):
Formset_class = formset_factory(PermissionMultAddModelForm,extra=2)
if request.method == "GET":
initial = [{"parent_id":item} for item in [sid,]*4]
formset = Formset_class(initial= initial)
return render(request,"permission_mult_add.html", {"formset":formset})
if request.method == "POST":
formset = Formset_class(data=request.POST)
if formset.is_valid():
valid_data = formset.cleaned_data
flag = True
for i in range(0,formset.total_form_count()):
item = valid_data[i]
new_permission = models.Permission(**item)
try:
new_permission.validate_unique()
new_permission.save()
except Exception as e:
formset.errors[i].update(e)
flag = False
if flag:
return HttpResponse("批量添加成功")
return render(request,"permission_mult_add.html", {"formset":formset})
# 知识要点:
1. formset.is_valid() 校验成功得到clean_data, 否则得到errors列表,两者互斥
2. ORM对象的validate_unique()方法如果发现有唯一索引错误,则手动报唯一索引的错误
3. formset的cleandata是一个列表,每个元素是一个表单的数据(字典)
4. formset的errors也是一个列表,每个元素存的是一个表单的错误数据,错误信息存在每个字段下
5. 模板文件中必须加: {{ formset.management_form }} 否则不能正确解析,formset是传入的formset的变量名字
ModelFormset 工具
基本用法与formset相似
知识点
modelformset里面的每一行是一个form,而这个form有一个instance属性,对应的是ORM数据库中的一条记录,可以用ORM语法获取相应的数据
modelformset 初始化
```python * views.py **
from web import models from django.views import View from django.shortcuts import redirect, render, HttpResponse, reverse from django.forms.models import modelformset_factory # queryset from web.forms.studyrecord_form import StudyRecordDeialModelForm
学生学习记录信息
class StudyRecordDeialView(View): def get(self, request, class_record_id):
# 通过当前学生记录id找到班级记录对象
class_record_obj = models.ClassStudyRecord.objects.get(pk=class_record_id)
# 找到班级记录找到对应的所有的学生记录
all_study_recored = models.StudentStudyRecord.objects.filter(
classstudyrecord=class_record_obj,
)
# 关键语法一: 创建一个modelformset_factory对象(model=学生记录,
# form=modelform,extra=默认参数)
form_set_obj = modelformset_factory(model=models.StudentStudyRecord, form=StudyRecordDeialModelForm, extra=0)
# 关键语法二:
# 初始化方法一:(queryset参数) 好处是不用单独传递id
formset = form_set_obj(queryset=all_study_recored)
# 初始化方法二 initial参数
formset2 = formset_class(
initial= [{'id':1,'name':'rb','course':'python'},
{'id':2,'name':'rba','course':'ruby'},])
# 或者写为
formset3 = formset_class(
initial=
Permission.objects.filter(status=0).values('id','name','urls') )
# 在modelform中id要定义进去且设为HiddenInput(),则不显示到前端,且不放到表格中。在post数据时,会携带着传递到服务器
return render(request, 'student/study_record_detail.html', {'formset': formset})
def post(self, request, class_record_id):
# 创建一个modelformset_factory对象(model=学生记录,form=modelform,extra=默认参数)
form_set_obj = modelformset_factory(model=models.StudentStudyRecord, form=StudyRecordDeialModelForm, extra=0)
# 对象中保存request.POST
formset = form_set_obj(queryset=all_study_recored, data=request.POST)
# formset调用is_valid方法
if formset.is_valid():
# 保存formset.save方法
formset.save()
else:
# 否则打印错误信息
print(formset.errors)
# 重定向
# return redirect(reverse('study_record', args=(class_record_id,)))
return redirect(reverse("class_record"))
知识点:
创建自定义modelformset类 form_set_obj = modelformset_factory(model= ORM_Model, form= ModelForm, extra=0) # extra是额外增加的空白行数
初始化自定modelformset对象
第一种:从queryset获取初始值, 不能是values或者values_list formset = form_set_obj(queryset= Queryset_obj)
第二种:从request.POST formset = form_set_obj(request.POST)
第三种:参数为空 会从model里面取到所有的值用于初始化
特别注意,modelform里面为forms.Select字段设置的choices没有用,不知道为什么?
html模板文件中必须使用 {{ formset.management_form }} ,否则不能正确识别
html中必须有 {{form.id}} 字段,否则报错 form-0-id
这个地方比较神奇,存的是model_obj
form.id存的是model_obj applyorder_obj = row[“id”]
在html中,以input hidden type的不显示
```html
<tbody>
{{ formset.management_form }}
{% for form in formset %}
<tr>
# 这个不能缺少,否则报错,尤其是所有本model的字段都没有以控件形式显示的时候
{{ form.id }}
<td>{{ form.instance.order_number }}</td>
<td>{{ form.instance.customer.shortname }}</td>
<td>{{ form.instance.currency.icon }}{{ form.instance.amount }}</td>
<td>{{ form.instance.currency.icon }}{{ form.instance.rcvd_amount }}</td>
<td>{{ form.instance.currency.icon }}{{ form.instance.collect_amount }}</td>
<td>{{ form.dist_amount }} <span style="color: #ff4500">{{ form.dist_amount.errors.0 }}</span></td>
</tr>
{% endfor %}
</tbody>
- modelformset里面的数据信息格式
```html
data = { … ‘form-TOTAL_FORMS’: ‘3’, … ‘form-INITIAL_FORMS’: ‘2’, … ‘form-0-title’: ‘Article #1’, … ‘form-0-pub_date’: ‘2008-05-10’, … ‘form-0-ORDER’: ‘2’, … ‘form-1-title’: ‘Article #2’, … ‘form-1-pub_date’: ‘2008-05-11’, … ‘form-1-ORDER’: ‘1’, … ‘form-2-title’: ‘Article #3’, … ‘form-2-pub_date’: ‘2008-05-01’, … ‘form-2-ORDER’: ‘0’, … }
formset = FormsetClass(data)
备注: form-序号-字段名 大写的是系统管理字段,小写用户自定义字段
<a name="hSBG7"></a>
#### formset里面手动提起错误
```python
手动提起错误
# new_obj.validate_unique() #检验unique唯一索引字段的唯一性,如果不唯一报错
row_data = formset.cleaned_data # 存起来,因为一旦报错,cleaned_data的值就会清空
for i in range(0, formset.total_form_count()):
pk = row_data[i].pop("id")
new_obj = models.Permission.objects.filter(pk=pk).first()
try:
# new_obj.title = row_data[i]["title"]
# new_obj.urls = row_data[i]["urls"]
# new_obj.name = row_data[i]["name"]
# new_obj.menu_id = row_data[i]["menu_id"]
# new_obj.parent_id = row_data[i]["parent_id"]
# 采用反射来写上面的五行,省点纸
for key,value in row_data[i].items():
setattr(new_obj,key,value)
new_obj.validate_unique()
new_obj.save()
except Exception as e:
formset.errors[i].update(e)
failure = True
# 如果要手动报错,应该按照下面的格式
# formset的errors信息的格式: {字段:[错误信息,]}
formset.errors[i].update({'dist_amount': ['关联金额不能大于应收金额',]})
# 更高级的方法目前还没有找到,后面再补充
modelformset注意事项
formset_factory 如果部分字段内容来自另外一个表,怎么处理呢,有两种思路:
1. 如果以要创建的表为基础,则需要把其他字段内容手动放到formset的initial里面,且需要用instance.字段名的方式,避免显示输入控件
2. 如果以内容比较多的表为基础,也是一样道理,但是收集的数据比较少,应该采用这种方式
初始化时,如果同时存在instance和initial,必须在初始化时同时赋予这两个字段,不能后来再赋值
否则form不能同步
初始化时两个参数queryset,request.POST可以同时作用,顺序是queryset为先,然后用post数据更新
权限分配
自动发现项目中的权限
from django.urls import URLPattern, URLResolver
def get_all_url(pre_namespace,pre_url,urlpatterns,url_dict):
"""
递归获取项目中所有url
:param pre_namespace:
:param pre_url:
:param urlpattern:
:param url_dict:
:return:
"""
for item in urlpatterns:
if isinstance(item, URLPattern):
if not item.name:
continue
name = "%s:%s" % (pre_namespace,item.name) if pre_namespace else item.name
url = pre_url+ item.pattern.regex.pattern
url = url.replace("^","").replace("$","")
url_dict[name] = {"name":name,"url":url}
if isinstance(item,URLResolver):
if pre_namespace:
if item.namespace:
namespace ="{}:{}".format(pre_namespace,item.namespace)
else:
namespace = pre_namespace
else:
if item.namespace:
namespace = item.namespace
else:
namespace = None
if item.pattern:
url = pre_url+item.pattern.regex.pattern
else:
url = pre_url
get_all_url(namespace,url, item.url_patterns,url_dict)
return url_dict
def auto_crawle_permission(request):
""" 自动收集项目中所有的url,name和title"""
# 导入跟路由模块
from django.utils.module_loading import import_string
root_url_md = import_string(settings.ROOT_URLCONF)
url_dict = {}
# 调用递归函数获取所有的urls
all_urls = get_all_url(None,'/',root_url_md.urlpatterns,url_dict)
for k, v in all_urls.items():
print(k,":",v['url'])
return HttpResponse("....")
知识点:
1. 用字符串方式导入模块 from django.utils.module_loading import import_string
module = import_string(get("module"))
2. ulrpatterns的数据结构 (django ver. 3)
[ url_obj, url_obj, url_obj ]
url_obj 的属性:pattern.regex.pattern (url)
name (url 别名)
namespace (命名空间,相当于父级别名)
url_patterns (下级路由的urlpatterns列表)
前两个属性是普通路由具有的属性,
后面两个是转发路由具有的属性
3. 多级命名空间的数据形式: 父级namespace:子级namespace:孙级namespace:name
如果某一级别没有namespace则用上一级的namespace
4. 递归的方式适合于解决树状遍历的问题
批量更新数据库中的权限
- 解决思路 ```python 用集合的方法解决两个数据集的同步问题
项目中发现的权限集合set1 数据库中的权限集合 set2
set1-set2 (表示项目中有而数据库中没有的) 应添加 set2-set1 (表示数据库中有而项目中实际没有的) 应删除 set1 & set2 (表示项目中和数据库中都有的)应按照项目中的添加
- 代码实现
```python
def auto_crawle_permission(request):
""" 自动收集项目中所有的url,name和title"""
add_formset_class = formset_factory(AutoPermissionAddModelForm, extra=0)
update_formset_class = formset_factory(AutoPermissionEditModelForm, extra=0)
post_type = request.GET.get("type")
add_formset_list = None
to_update_name_list = None
to_update_url_list = None
# 处理批量添加提交的数据
if request.method == "POST" and post_type == "add":
formset = add_formset_class(data=request.POST)
if formset.is_valid():
row_data = formset.cleaned_data
failure = False
for i in range(0,formset.total_form_count()):
new_obj = models.Permission(**row_data[i])
try:
new_obj.validate_unique()
new_obj.save()
except Exception as e:
formset.errors[i].update(e)
failure = True
if failure:
add_formset_list = formset
else:
add_formset_list = formset
# 批量更新urlname,提交的数据
if request.method == "POST" and post_type == "update_urlname":
formset = update_formset_class(data=request.POST)
if formset.is_valid():
row_data = formset.cleaned_data
failure = False
for i in range(0, formset.total_form_count()):
pk = row_data[i].pop("id")
new_obj = models.Permission.objects.filter(pk=pk).first()
try:
new_obj.title = row_data[i]["title"]
new_obj.urls = row_data[i]["urls"]
new_obj.name = row_data[i]["name"]
new_obj.menu_id = row_data[i]["menu_id"]
new_obj.parent_id = row_data[i]["parent_id"]
new_obj.validate_unique()
new_obj.save()
except Exception as e:
formset.errors[i].update(e)
failure = True
if failure:
to_update_name_list = formset
else:
to_update_name_list = formset
# 批量更新url,提交的数据
if request.method == "POST" and post_type == "update_url":
formset = update_formset_class(data=request.POST)
if formset.is_valid():
row_data = formset.cleaned_data
failure = False
for i in range(0, formset.total_form_count()):
pk = row_data[i].pop("id")
new_obj = models.Permission.objects.filter(pk=pk).first()
try:
new_obj.title = row_data[i]["title"]
new_obj.urls = row_data[i]["urls"]
new_obj.name = row_data[i]["name"]
new_obj.menu_id = row_data[i]["menu_id"]
new_obj.parent_id = row_data[i]["parent_id"]
new_obj.validate_unique()
new_obj.save()
except Exception as e:
formset.errors[i].update(e)
failure = True
if failure:
to_update_url_list = formset
else:
to_update_url_list = formset
# 导入根路由模块
from django.utils.module_loading import import_string
root_url_md = import_string(settings.ROOT_URLCONF)
url_dict = {}
# 调用递归函数获取项目中所有的urls
all_urls = get_all_url(None,'/',root_url_md.urlpatterns,url_dict)
project_urlname_set = set(all_urls.keys())
project_url_dict = {item['urls']:item['name'] for item in all_urls.values()}
# 从数据库中获取所有的urls,做成字典{name:{name:"", title:"", url:"", menu_id:"", parent_id:""}, }
permission_url_dict = {}
permission_urlname_set = set()
to_update_url_dict = {}
to_update_url_set = set()
for item in models.Permission.objects.values("id","name","title","urls","menu_id","parent_id"):
permission_urlname_set.add(item["name"])
permission_url_dict[item['name']]= item
if item['name'] in project_urlname_set and item['urls'] != all_urls[item['name']]['urls']:
item['urls'] = f"数据库和项目中的url不一致-{all_urls[item['name']]['urls']}"
to_update_url_set.add(item['name'])
if item['urls'] in project_url_dict and item['name'] != project_url_dict[item['urls']]:
item['name'] = "数据库和项目中的name不一致"
to_update_url_dict[item['urls']] = item
# 使用自动获取的项目中的url路由信息批量更新数据库
# 1. 需要添加的set集合: 项目中有,数据库没有的
to_add_url_set = project_urlname_set - permission_urlname_set
to_add_url_list = [ item for name,item in all_urls.items() if name in to_add_url_set]
if add_formset_list is None:
add_formset_list = add_formset_class(initial= to_add_url_list)
# 2. 需要删除的set集合: 数据库中有,项目中没有的
to_del_url_set = permission_urlname_set - project_urlname_set
to_del_url_list = [item for name,item in permission_url_dict.items() if name in to_del_url_set]
# 3. 需要更新的set集合:数据库和项目中name相同的,url不相同的
# to_update_url_set = permission_urlname_set & project_urlname_set
if to_update_url_list is None:
to_update_url_list = update_formset_class(initial=[item for name,item in permission_url_dict.items() if name in to_update_url_set])
# 4. 需要更新的set集合: 数据库和项目中url相同,而name不同的
if to_update_name_list is None:
to_update_name_list = update_formset_class(initial =[ item for name,item in to_update_url_dict.items()])
return render(request,"auto_permission_update.html",{
"add_formset_list":add_formset_list,
"to_update_name_list":to_update_name_list,
"to_update_url_list":to_update_url_list,
"to_del_url_list":to_del_url_list,
})
权限分配
- 复选框的选中:
```python
{{ row.title }}
a in dict 的处理效率比较高
只要有checked属性,不管是什么值,都可被选中
- 使用隐藏的input标签传递type信息
优点是信息对用户不可见,比较安全和友好
```python
<input type="hidden" name="type" value="add_role_to_user">
********* views.py ************
post_type = request.GET.get("type")
- JavaScript里面的prop和attr有什么区别 ```python prop 属性checked不存在,prop获取的是False
attr : 目前发现如果属性checked不存在,attr获取的值是undefined
以下是全选的js代码
$(function () { $(‘input[id^=”checkall“]’).change(function () { var is_check = $(this).prop(“checked”); var children_cls = $(this).attr(“id”) $(“.”+children_cls).prop(“checked”,is_check);
})
})
知识点: change事件比click好,click对于checkbox只能起一次作用,而change每一次都能触发 prop对于checked等属性比一般字符串属性处理到更好,建议对特殊属性使用prop
<a name="zom8I"></a>
### 权限组件的文档
"""
1. 将rbac组件拷贝项目的根目录。
1. 将rbac/migrations目录中的数据库迁移记录删除,保留__init__.py文件
1. 从django.conf 导入settings
1. 业务系统中用户表结构的设计
业务表结构中的用户表需要和rbac中的用户有继承关系,如:<br />之所有这么选择是因为:表的数据都在一张表里面,比较好管理,而使用关联表的方式虽然简单,但数据分散不好。 如果系统已经使用很久的情况下,也可以考虑。 <br />继承的情况下一定要加上 abstract = True, 否则会生成一张重复的表,系统报错,特别注意。<br />不用系统自带的userinfo表,逻辑自己写比较好控制
```python
rbac/models.py
class RbacUserInfo(models.Model):
# 用户表
name = models.CharField(verbose_name='用户名', max_length=32)
password = models.CharField(verbose_name='密码', max_length=64)
email = models.CharField(verbose_name='邮箱', max_length=32)
roles = models.ManyToManyField(verbose_name='拥有的所有角色', to=Role, blank=True,
limit_choices_to = {"department__isnull":True })
class Meta:
class Meta:
# django以后再做数据库迁移时,不再为UserInfo类创建相关的表以及表结构了。
# 此类可以当做"父类",被其他Model类继承。
abstract = True
# limit_choices_to 可以对数据源进行筛选
严重提醒 Role 不要加引号,否则按字符串可能找不到
业务/models.py
from rbac.models import RbacUserInfo
class UserInfo(RbacUserInfo):
phone = models.CharField(verbose_name='联系方式', max_length=32)
level_choices = (
(1, 'T1'),
(2, 'T2'),
(3, 'T3'),
)
level = models.IntegerField(verbose_name='级别', choices=level_choices)
depart = models.ForeignKey(verbose_name='部门', to='Department')
def __str__(self):
return self.name
将业务系统中的用户表的路径写到配置文件。
RBAC_USER_MODLE_CLASS = “app01.models.UserInfo”
用于在rbac分配权限时,读取业务表中的用户信息。业务中的用户表
业务逻辑开发
将所有的路由都设置一个name,如:
url(r’^login/%2C%0A%20%20%20%20%20%20%20%20%20url(r’%5Elogout%2F#card=math&code=%27%2C%20account.login%2C%20name%3D%27login%27%29%2C%0A%20%20%20%20%20%20%20%20%20url%28r%27%5Elogout%2F&id=Knzsk)’, account.logout, name=’logout’),
用于反向生成URL以及粒度控制到按钮级别的权限控制。url(r'^index/$', account.index, name='index'), url(r'^user/list/$', user.user_list, name='user_list'), url(r'^user/add/$', user.user_add, name='user_add'), url(r'^user/edit/(?P<pk>\d+)/$', user.user_edit, name='user_edit'), url(r'^user/del/(?P<pk>\d+)/$', user.user_del, name='user_del'), url(r'^user/reset/password/(?P<pk>\d+)/$', user.user_reset_pwd, name='user_reset_pwd'), url(r'^host/list/$', host.host_list, name='host_list'), url(r'^host/add/$', host.host_add, name='host_add'), url(r'^host/edit/(?P<pk>\d+)/$', host.host_edit, name='host_edit'), url(r'^host/del/(?P<pk>\d+)/$', host.host_del, name='host_del'),权限信息录入
- 在url中添加rbac的路由分发,注意:必须设置namespace
urlpatterns = [
…
url(r’^rbac/‘, include(‘rbac.urls’, namespace=’rbac’)),
] - rbac提供的地址进行操作
- 在url中添加rbac的路由分发,注意:必须设置namespace
相关配置:自动发现URL时,排除的URL:
# 自动化发现路由中URL时,排除的URL
AUTO_DISCOVER_EXCLUDE = [
'/admin/.*',
'/login/',
'/logout/',
'/index/',
]
编写用户登录的逻辑【进行权限初始化】
from django.shortcuts import render, redirect
from app01 import models
from rbac.service.init_permission import init_permission
def login(request):
if request.method == ‘GET’:
return render(request, ‘login.html’)
相关配置: 权限和菜单的session key:user = request.POST.get('username') pwd = request.POST.get('password') user_object = models.UserInfo.objects.filter(name=user, password=pwd).first() if not user_object: return render(request, 'login.html', {'error': '用户名或密码错误'}) # 用户权限信息的初始化 init_permission(user_object, request) return redirect('/index/')setting.py PERMISSION_SESSION_KEY = "luffy_permission_url_list_key" MENU_SESSION_KEY = "luffy_permission_menu_key"编写一个首页的逻辑
def index(request):
return render(request, ‘index.html’)
相关配置:需要登录但无需权限的URL
# 需要登录但无需权限的URL
NO_PERMISSION_LIST = [
'/index/',
'/logout/',
]
# 白名单,无需登录就可以访问
VALID_URL_LIST = [
'/login/',
'/admin/.*'
]
- 通过中间件进行权限校验 ```python MIDDLEWARE = [ ‘django.middleware.security.SecurityMiddleware’, ‘django.contrib.sessions.middleware.SessionMiddleware’, ‘django.middleware.common.CommonMiddleware’, ‘django.middleware.csrf.CsrfViewMiddleware’, ‘django.contrib.auth.middleware.AuthenticationMiddleware’, ‘django.contrib.messages.middleware.MessageMiddleware’, ‘django.middleware.clickjacking.XFrameOptionsMiddleware’, ‘rbac.middlewares.rbac.RbacMiddleware’, ]
权限校验
```javascript
rbac/middleware/__init__.py
---------------------------------
class RbacMiddleWare(MiddlewareMixin):
def process_request(self,request):
current_url = request.path
# 如果访问的是白名单, 直接通过
for item in settings.WHITE_LIST:
if re.match(item,current_url):
return None
if not request.user.username:
return redirect('/login/')
# 判断路径是否在登录以后,自动授权的名单内
for item in settings.AUTO_PERMISSION_LIST:
if re.match(item,current_url):
request.hilight_menu_id = ''
request.navi_list = []
return None
#获取用户的权限
permission_dict = request.session.get(settings.PERMISSION_KEY)
# print(permission_dict)
print('curren url',current_url)
# 判断用户的访问路径是否在权限里面
if permission_dict:
for item in permission_dict.values():
reg = "^{}$".format(item["url"])
if re.match(reg,current_url):
request.menu = request.session.get(settings.MENU_LIST_KEY)
# 设置导航条的nav_list, 如果pid和mid都不存在,就设导航条为空
# print(999999, item,item['pid'], item['mid'])
if not item['pid'] and not item['mid']:
request.navi_list = []
return
if item['pid']:
request.navi_list = [{"title":item['p_title'],"url":item['p_url']},
{"title":item['title'],"url":""}
]
else:
request.navi_list = [{"title": item['title'], "url": ""} ,]
# 找到需要高亮的菜单id
request.hilight_menu_id = item['pid'] or item['id']
return
# return HttpResponse("无访问权限")
- 粒度到按钮级别的控制
``` {% extends ‘layout.html’ %} {% load rbac %}
{% block content %}
{% if request|has_permission:'host_add' %}
<a class="btn btn-default" href="{% memory_url request 'host_add' %}">
<i class="fa fa-plus-square" aria-hidden="true"></i> 添加主机
</a>
{% endif %}
</div>
<table class="table table-bordered table-hover">
<thead>
<tr>
<th>主机名</th>
<th>IP</th>
<th>部门</th>
{% if request|has_permission:'host_edit' or request|has_permission:'host_del' %}
<th>操作</th>
{% endif %}
</tr>
</thead>
<tbody>
{% for row in host_queryset %}
<tr>
<td>{{ row.hostname }}</td>
<td>{{ row.ip }}</td>
<td>{{ row.depart.title }}</td>
{% if request|has_permission:'host_edit' or request|has_permission:'host_del' %}
<td>
{% if request|has_permission:'host_edit' %}
<a style="color: #333333;" href="{% memory_url request 'host_edit' pk=row.id %}">
<i class="fa fa-edit" aria-hidden="true"></i></a>
{% endif %}
{% if request|has_permission:'host_del' %}
<a style="color: #d9534f;" href="{% memory_url request 'host_del' pk=row.id %}"><i
class="fa fa-trash-o"></i></a>
{% endif %}
</td>
{% endif %}
</tr>
{% endfor %}
</tbody>
</table>
</div>
{% endblock %}
总结,目的是希望在任意系统中应用权限系统。<br />- 用户登录 + 用户首页 + 用户注销 业务逻辑<br />- 项目业务逻辑开发<br />注意:开发时候灵活的去设置layout.html中的两个inclusion_tag
- 权限信息的录入<br />- 配置文件
```python
# 注册APP
INSTALLED_APPS = [
...
'rbac.apps.RbacConfig'
]
# 应用中间件
MIDDLEWARE = [
...
'rbac.middlewares.rbac.RbacMiddleware',
]
# 业务中的用户表
RBAC_USER_MODLE_CLASS = "app01.models.UserInfo"
# 权限在Session中存储的key
PERMISSION_SESSION_KEY = "luffy_permission_url_list_key"
# 菜单在Session中存储的key
MENU_SESSION_KEY = "luffy_permission_menu_key"
# 白名单
VALID_URL_LIST = [
'/login/',
'/admin/.*'
]
# 需要登录但无需权限的URL
NO_PERMISSION_LIST = [
'/index/',
'/logout/',
]
# 自动化发现路由中URL时,排除的URL
AUTO_DISCOVER_EXCLUDE = [
'/admin/.*',
'/login/',
'/logout/',
'/index/',
]
- 粒度到按钮级别的控制
# inclusion_tag
{% request|has_permission:"host_edit" %}
“””
CRM的Stark组件(增删改查)
准备知识
- 单例模式
- 路由的include的原理
- django启动之前的自启动程序
自动生成新路由
第一步:创建StarkSite单例类,汇集每个app里面的路由,整合为urls路由列表
from django.conf.urls import url
from tracker import views
class StarkSite(object):
def __init__(self):
self._registry = []
@property
def urls(self):
patterns = []
for app in self._registry:
pattern = url(r"^%s" % (app),views.index)
patterns.append(pattern)
# 二级路由的数据返回格式是一个元组,第一个是urlpatterns列表
return (patterns, app_name, namespace)
site = StarkSite()
第二步: django的自启动程序设置
首先要保证stark已经在settings里面注册了
from django.apps import AppConfig
from django.utils.module_loading import autodiscover_modules
class StarkConfig(AppConfig):
default_auto_field = 'django.db.models.BigAutoField'
name = 'stark'
def ready(self):
autodiscover_modules("preload")
# ready方法的作用:这个方法在启动过程中自动执行
# autodiscover_modules 在项目文件中寻找所有名字为preload.py的文件,然后导入他们
第三步: 把每个app的路由加入到site._registry列表中
from stark.luffy import site
site._registry.append("tracker")
第四步:在项目根路由中使用自定义的site.urls
from django.contrib import admin
from django.urls import path, include
from stark.luffy import site
print("加载路由过程中。。。。。")
urlpatterns = [
# ....
path('test/', site.urls), # site.urls = (urls, app_name, namespace)
# ....
]
视图函数的基类
展示字符串字段
准备知识:
获取Model的所有字段对象
fields_list = self.model_class._meta.fields
获取字段名称
field.verbose_name
通过字段名获取field字段对象
self.model_class._meta.get_field('name')
通过字段名获取字段的值
field_val = getattr(obj, field.name)
获取对象的所有属性的python方法 dir()
dir(self.model_class._meta)
# 从而掌握该对象的使用方法
- 编辑和删除按钮 ```javascript
def edit_display(hander_obj,obj=None,is_header=False): “”” 在列表页显示编辑按钮 :param obj: :param is_header: :return: “”” if is_header: return “操作” else:
# 方式一 edit_url = self.reverse_edit_url(args=(obj.id,))
# 方式二
if hander_obj.site.namespace:
edit_url_name = "%s:%s" %(hander_obj.site.namespace,hander_obj.get_edit_url_name)
else:
edit_url_name = hander_obj.get_edit_url_name
edit_url = reverse(edit_url_name,args=(obj.id,))
if hander_obj.request.GET:
edit_url = "%s?%s" %(edit_url,hander_obj.get_query_param())
return mark_safe("<a href='%s'><i class='fa fa-edit'></i></a>" % edit_url )
def del_display(hander_obj, obj=None, is_header=False): “”” 在列表页显示删除按钮 :param obj: :param is_header: :return: “”” if is_header: return “操作” else: del_url = hander_obj.reverse_del_url(args=(obj.id,)) return mark_safe(““ % del_url)
<a name="PYj0x"></a>
####
- 展示choice字段
```python
def get_choice_text(field):
def inner(handler_obj ,obj=None ,is_header=None):
"""
功能:显示choice字段的数值对应的title
:param handle_obj: show_list处理需要的第一个占位参数,hander对象
:param obj: 一条queryset记录,有get_field_display方法
:param is_header: 是否表头
"""
if is_header:
return handler_obj.model_class._meta.get_field(field).verbose_name
else:
# getattr方法可用字符串方式从对象中调取方法或者属性
method_func = getattr(obj ,"get_%s_display" % field)
return method_func()
return inner
- 展示manytomany字段
def manytomany_display(field): def inner(handler_obj ,obj=None ,is_header=None): """ 功能:显示manytomany字段的数值 :param xself: show_list处理需要的第一个占位参数,hander对象 :param obj: 一条queryset记录,有get_field_display方法 :param is_header: 是否表头 :return: """ if is_header: return handler_obj.model_class._meta.get_field(field).verbose_name else: # getattr方法可用字符串方式从对象中调取方法或者属性 field_obj = getattr(obj,field) queryset = field_obj.all() return ','.join([ str(row) for row in queryset]) return inner
应用模板
分页器(stark版)
知识点:
- request.GET 存的url的?后面的参数部分
因为 request.GET不可更改的数据类型,所以需要 .copy() 和._mutable = True的方法使他可变 ```python
######## 1. 分页
query_params = request.GET.copy() query_params._mutable = True pager = Pagination( current_page= request.GET.get("page"), all_count= self.model_class.objects.all().count(), base_url= request.path, query_params= query_params, per_page = 2, )
"""
def __init__(self, current_page, all_count, base_url, query_params, per_page=20, pager_page_count=11):
分页初始化
:param current_page: 当前页码
:param per_page: 每页显示数据条数
:param all_count: 数据库中总条数
:param base_url: 基础URL
:param query_params: QueryDict对象,内部含所有当前URL的原条件
:param pager_page_count: 页面上最多显示的页码数量
"""
类对象的编外知识
```python
"""
类有成员
1. 在类的范围内,所有的方法,属性,嵌套的类都是类的成员
2. 同一层成员可以通过方法的self参数(代表类的实例对象)来进行沟通,也可以直接访问 )
3. 同一层的变量和静态方法之间可以访问
4. 里层类没有办法直接访问外层类的变量,因为外层类的属性是外层类的成员,不能向上直接沟通
5. 外层可以通过成员所属关系访问内层的变量
6. 全局变量对所有类开放
"""
from serial import Serial
from types import FunctionType,MethodType
#与类和实例无绑定关系的function都属于函数(function);
当以类的方法调用时,方法其实是一个函数,需要手动传递self参数
#与类和实例有绑定关系的function都属于方法(method)
与实例绑定的是方法,不需要传递self,如果强行传递,会多一个函数
排错: 发现没有走闭包,原来是有判断,导致其中一个分支加了装饰器,一个没有加 ,还以为是闭包本身出问题了
使用闭包来给函数加点功能
# 闭包函数传进来的func = self.show_list, 相当于self已作为第一个参数传递了,所以inner()的参数不能再接收self
def wrapper(self,func):
@functools.wraps(func)
def inner(request,*args,**kwargs):
self.request = request
return func(request,*args,**kwargs)
return inner
# wrapper() 的执行结果返回一个函数名
# wrapper()() 当这个函数执行时:
获取三个参数,必须跟原函数保持一致
先执行 self.request = request
然后 返回原函数执行结果
wrapper()() = func()
# 在没有改变原函数的任何代码的情况下,加装了 self.request = request
起名字千万别重复了,后面的就把前面的覆盖了。 并不会报错。
可扩展性
利用类的继承特性,以及方法和属性的查找顺序来设置钩子
从self对象的类的起点开始查找
把类里面的公共变量抽出来,这样在继承类中可以重新定义
可以同时再定义一个get_val 的函数,增加更多的灵活性,判断用户的权限,决定怎么对待自己的对象没有,按左手法则向上查找
左手法则确保了,钩子方法的有效性
排序
order_list = ['id']
模糊搜索
# 如果不加__contains则是精准匹配,不符合模糊搜索的目标
search_list = ['name__contains','age__lt']
# 读取列表,用Q函数连接,并进入模糊过滤
# 然后进行其他的数据处理,比如排序,组合筛选等等
############## 1. 模糊搜索 ###############
search_list = self.search_list
user_query = self.request.GET.get("p")
print("user_query:", user_query)
if user_query:
conn = Q()
conn.connector = "OR"
for item in search_list:
# 使用ORM的Q函数来构造OR条件的查询
# conn = Q()
# conn.connector = "OR"
conn.children.append((item, user_query))
searched_queryset = self.model_class.objects.filter(conn)
""" 等同于这个效果
model.objects.filter(Q(title__contains ="s")|Q(addr__contains="s"))
"""
else:
searched_queryset = self.model_class.objects.all()
批量操作
列表传递函数名,函数名作为select选项的value,然后通过反射拿到对应操作函数进行处理
第一步:定义处理函数
def batch_del(self,request):
print("batch del request",request)
pk_list = request.POST.getlist("pk")
self.model_class.objects.filter(id__in = pk_list).delete()
return
batch_del.text = "批量删除"
# 函数也是对象,可以给函数对象赋值一个新属性
# ORM的筛选功能可以使用 id__in的判断id是否在列表里面
第二步:把函数名和text传给views,并在前端展示
views.show_list()
--------------------------
if self.batch_process_list:
batch_process_dict = {} # {"batch_del":"批量删除","batch_init":"批量初始化" }
for func in self.batch_process_list:
batch_process_dict[func.__name__] = func.text
# func.__name__ 函数的名称
else:
batch_process_dict = None
show_list. htlm
--------------------------
{% if batch_process_dict %}
<select name="handle_type">
<option value="">请选择处理方式</option>
{% for func,text in batch_process_dict.items %}
<option value="{{ func }}">{{ text }}</option>
{% endfor %}
</select>
<button type="submit" class="btn btn-primary">执行</button>
{% endif %}
组合筛选
- 实现思路 **基本原理:
把model里面外键字段和choice字段的内容找到,作为关键字标签显示在页面上
点击这些标签,把字段和内容作为以get关键字参数传递到后台
根据这些组合条件筛选数据库,然后展示在前台
**
- 用到的基本知识
- 字符串方式获取model中的字段对象
field_obj = model._meta.get_field(“field_nam”)
- 从foreignkey或者manytomany字段对象获取关联的model
field, field_obj.related_model (django 3.2 版本)
field_obj.rel.model (django 1.1 版本)
- 获取field_obj的choices
field_obj.choices
from django.db.models import ForeignKey,ManyToManyField
option_group_dict = {}
if self.option_group: # option_group = ["country",]
for field in self.option_group:
field_obj = self.model_class._meta.get_field(field)
if isinstance(field_obj,ForeignKey) or isinstance(field_obj,ManyToManyField):
print(field,field_obj.related_model)
else:
print(field_obj.choices)
组合筛选的URL设计
class RenderData: def __init__(self, data,field,verbose_name,query_dict): self.data = data self.field = field self.verbose_name = verbose_name self.query_dict = query_dict def __iter__(self): yield self.verbose_name yield '<div class="others">' query_dict = self.query_dict.copy() query_dict._mutable = True if query_dict.get(self.field): del query_dict[self.field] yield '<a href="?%s">全部</a>' % (query_dict.urlencode()) else: yield '<a href="?%s" class="active">全部</a>' % (query_dict.urlencode()) for item in self.data: query_dict = self.query_dict.copy() val = query_dict.get(self.field) query_dict._mutable = True if isinstance(self.data, QuerySet): query_dict[self.field] = item.id if str(item.id) == val: is_active = "active" query_dict.pop(self.field) else: is_active = "" yield '<a href="?%s" class="%s">%s</a>' % (query_dict.urlencode(), is_active,item.name) else: query_dict[self.field] = item[0] is_active = "active" if str(item[0]) == val else "" yield '<a href="?%s" class="%s">%s</a>' % (query_dict.urlencode(),is_active, item[1]) yield '</div>'组合搜索的知识点:
1. 直接在后台为每一个按钮动态生成url和get参数,让他点击实现想要的效果,最大限度节约前台判断的代码,这个是django的一种思路,前后端分离应该是另外一种思路。这个思路的好处在于前端代码量非常少,判断工作由python来做,效率非常高request.GET 是一个query_dict , 可以通过以下方式获取并修改内容
- query_dict = self.query_dict.copy() 深拷贝防止原始内容被修改
- query_dict._mutable = True mutable是可修改
- query_dict.urlencode() 可以把query_dict转为字符串格式 gender=1&country=2
- 生成器的妙用,在循环时,生成器比for循环和next方法更加灵活,可实现按定制内容顺序输出一些内容
自动发现项目中的url
知识点:
- modelformset 批量添加记录
- url分发的机制和语法
比较两个数据集的异同,如果有选择的同步
modelformset 批量添加记录
class AutoPermissionAddModelForm(forms.Form): second_menu_choices = models.Permission.objects.filter(menu__isnull=False).values_list("id","title") menu_choices = models.Menu.objects.values_list("id","title") title = forms.CharField(max_length=30,label="权限名",widget=forms.widgets.TextInput()) urls = forms.CharField(max_length=128,label="URL",widget=forms.widgets.TextInput()) name = forms.CharField(max_length=128,label="URL别名",widget=forms.widgets.TextInput()) parent_id = forms.ChoiceField(label="二级菜单",choices=[(None,"-----"),],required=False) menu_id = forms.ChoiceField(label="一级菜单",choices= [(None,"-----"),],required=False) def __init__(self,*args,**kwargs): super(AutoPermissionAddModelForm,self).__init__(*args,**kwargs) self.fields["parent_id"].choices += self.second_menu_choices self.fields["menu_id"].choices += self.menu_choices```python from django.forms import formset_factory,modelformset_factory add_formset_class = formset_factory(AutoPermissionAddModelForm, extra=0)
to_add_url_list = [ {‘name’:’rbac:role_list’,’url’:’/rbac/role/list/‘}, {‘name’:’rbac:role_add’,’url’:’/rbac/role/add/‘},]
formset_list = add_formset_list = add_formset_class(initial= to_add_url_list)
注意:initial语法用于初始化formset_class
```python
<form method="post" action="?type=add">
{% csrf_token %}
{{ add_formset_list.management_form }}
<table class="table table-striped table-bordered">
<thead>
<th>权限名</th>
<th>URL</th>
<th>URL别名</th>
<th>父权限</th>
<th>菜单</th>
</thead>
<tbody>
{% for row in add_formset_list %}
<tr>
{% for field in row %}
<td>{{ field }}
<span style="color:orangered">{{ field.errors.0 }}</span>
</td>
{% endfor %}
</tr>
{% endfor %}
</tbody>
</table>
<button type="submit" class="btn btn-success">提交</button>
</form>
# 知识点:
1. 额外键值: {{ add_formset_list.management_form }} formset必须要的
2. 额外键值 {% csrf_token %} form表单post必须的
3. field.errors.0 报错信息
url分发的机制和递归遍历并获取url权限和name的方法 ```python from django.urls import URLPattern, URLResolver def get_all_url(pre_namespace,pre_url,urlpatterns,url_dict): “”” 递归获取项目中所有url :param pre_namespace: 上一级路由的namespace :param pre_url: 上一级路由的url :param urlpattern: 本级路由的patterns列表 :param url_dict: 要返回的url & name的字典 :return: “”” def check_exclude_url(url):
"""检查url是否在排除名单里面""" exclude_list = settings.AUTO_DISCOVER_EXCLUDE for regex in exclude_list: if re.match(regex,url): return Truefor item in urlpatterns:
if isinstance(item, URLPattern): if not item.name: continue name = "%s:%s" % (pre_namespace,item.name) if pre_namespace else item.name url = pre_url+ item.pattern.regex.pattern url = url.replace("^","").replace("$","") if check_exclude_url(url): continue url_dict[name] = {"name":name,"urls":url} if isinstance(item,URLResolver): if pre_namespace: if item.namespace: namespace ="{}:{}".format(pre_namespace,item.namespace) else: namespace = pre_namespace else: if item.namespace: namespace = item.namespace else: namespace = None if item.pattern: url = pre_url+item.pattern.regex.pattern else: url = pre_url get_all_url(namespace,url, item.url_patterns,url_dict)return url_dict
知识点:
pattern对象的属性:
pattern_obj.namespace 命名空间
pattern_obj.name 权限变量名
pattern_obj.url_patterns 下一级的patterns列表
pattern_obj.pattern.regex.pattern 本级路由的路径
URLPattern 普通路由对象
URLResolver 路由转发器对象
3. 比较两个数据集的异同,如果有选择的同步
```python
to_add_url_set = project_urlname_set - permission_urlname_set
CRM业务
公户和私户管理
- 公户和私户的区分 ```python 分别定义两个不同的handler: class PrivateCustomerHandler: pass
class PublicCustomerHandler: pass
url用前缀prev来区分,如:
stark/work/customer/private/list (显示私户)
stark/work/customer/public/list (显示公户)
site注册: site.register(models.Customer, PrivateCustomerHandler, prev=”private”) site.register(models.Customer, PublicCustomerHandler, prev=”public”)
- 查看跟进记录
```python
第一步:定义一个按钮
第二步:重写跟进记录表的get_urls方法,跟进记录表的显示url加上\d+,用于筛选客户id
第三步:跟进记录表的get_queryset方法,按照客户id筛选之后return queryset
批量添加公户到私户 ```python def batch_to_private(self, request): “”” 把公户批量添加到私户中去,每个销售的私户数量上限是150人 :param request: :return: “”” pk_list = request.POST.getlist(“pk”) user = request.session.get(settings.LOGIN_KEY) # user = {username:xx, id:xx}
if not user:
return HttpResponse("请先登录")current_total_count = Customer.objects.filter(consultant=user[“id”], status=2).count() new_total_count = current_total_count + len(pk_list) if new_total_count >150:
return HttpResponse("超过人数上限")from django.db import transaction
with transaction.atomic():
public_customers = self.model_class.objects.filter(id__in=pk_list,status = 2, consultant__isnull=True ).select_for_update() if public_customers.count() == len(pk_list): public_customers.update(consultant = user['id']) else: return HttpResponse("手速太慢,已经有人捷足先登")return redirect(self.reverse_list_url())
知识点:
django的事务管理(原子性) from django.db import transaction with transaction.atomic()
通过数据长度来判断操作是否存在问题
公户客户要同时满足两个条件: status为潜在,consultant为空
每个销售私户数量有150人的上限 ```
- 对于需要同步的信息,要手动同时更新多张表
批量创建记录中控制每批提交的数量: model.objects.bulk_create(Object_list, batch_size = 20)
ModelFormSet 的批量操作
作业提交和批改
modelform上传作业文件,并控制上传文件类型 ```python class SubmitHomeworkModelForm(StarkModelForm): class Meta:
model = StudentHomework fields = ['upload_work',]def clean_upload_work(self):
upload_file_obj = self.cleaned_data.get('upload_work') # 获取上传文件的后缀名 name,suffix = upload_file_obj.name.rsplit('.',1) if suffix in ['zip','rar']: return upload_file_obj raise forms.ValidationError('类型必须是zip或者rar压缩文件')
### views/submitworks.py/
def upload_file(self,request,pk,args,*kwargs): student_id = request.user.student.id student_homework_obj = self.model_class.objects.filter(pk=pk,student_id =student_id).first() if not student_homework_obj: return HttpResponse(“老师还没有给你布置作业,请联系老师”) if request.method==”GET”: form = SubmitHomeworkModelForm(instance=student_homework_obj) return render(request,”submitwork.html”,locals()) else: form = SubmitHomeworkModelForm(request.POST,request.FILES,instance=student_homework_obj) if form.is_valid(): form.save() return redirect(‘stark:work_courserecord_list_stu’) else: return render(request,”submitwork.html”,locals())
- 控制上传文件后缀方法二 (model validator )
```python
from django.db import models
from django.core import validators
class Asset(models.Model):
user = models.CharField(max_length=32, verbose_name='用户名')
avatar = models.ImageField(
upload_to='avatars/',
verbose_name='用户头像',
default='avatars/xxx.png',
validators=[validators.FileExtensionValidator(['jpg', 'png', 'jpeg'])]
)
file = models.FileField(
upload_to='files/',
verbose_name='用户文件',
default='files/xxx.txt',
validators=[validators.FileExtensionValidator(['pdf', 'zip', 'rar'])]
)
def __str__(self):
return self.user
# 知识点:
validators=[validators.FileExtensionValidator(['pdf', 'zip', 'rar'])]
这句定义了文件字段可以接受的后缀名的列表
from django.shortcuts import render, HttpResponse, redirect
from django.core.exceptions import ValidationError
from django import forms
from app01 import models
class FileModelForm(forms.ModelForm):
class Meta:
model = models.Asset
fields = ['user', 'avatar', 'file']
error_messages = {
"file": {"invalid_extension": "必须上传文件, 且上传文件的类型必须是 pdf zip rar"},
"avatar": {"invalid_extension": "必须上传图片,且上传文件的类型必须是 jpg png jpeg"},
}
labels = {
"file": "文件上传",
"avatar": "图片上传"
}
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 为所有的字段添加相同的属性
for field in self.fields.values():
field.widget.attrs.update({"class": "form-control"})
field.error_messages.update({"required": "该字段不能为空"})
modelform知识点:
error_messages 定义每个字段的错误类型显示给用户的文字,后缀名错误类型invalid_extension
labels 定义每个字段在前端显示的文字
views的处理就都一样了。
定时任务
APScheduler定时器
APScheduler是一个 Python 定时任务模块,使用起来十分方便。提供了基于日期、固定时间间隔以及 crontab 类型的任务,并且可以持久化任务、并以daemon方式运行应用。
$ pip install apscheduler
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
# 输出时间
def job():
print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
# BlockingScheduler
scheduler = BlockingScheduler()
# 定时执行任务 cron方式
scheduler.add_job(job, 'cron', day_of_week='1-5', hour=6, minute=30)
scheduler.start()
# 间隔时间执行任务 interval方式
scheduler.add_job(job, 'interval', seconds=30)
scheduler.start()
# 移除任务,放在start前才有效
schedule.remove_job('myjob_id')
# 非阻塞式执行方式
from apscheduler.schedulers.background import BackgroundScheduler
# 初始化非阻塞模式
scheduler = BackgroundScheduler()
特别注意:两种方法都需要保证主进程不结束,如果主进程结束,定时任务也终结了,所以使用要跑一个while True,保持主进程在线,这个怎么解决还不知道呢。待后面再说
import schedule
def job():
print("I'm working...")
schedule.every(10).minutes.do(job)
schedule.every().hour.do(job)
schedule.every().day.at("10:30").do(job)
schedule.every().monday.do(job)
schedule.every().wednesday.at("13:15").do(job)
while True:
schedule.run_pending()
- 定时任务工具 方法二:celery ```python 1 celery 简要概述
Celery是一个简单,灵活,可靠的分布式系统,用于处理大量消息,同时为操作提供维护此类系统所需的工具。
它是一个任务队列,专注于实时处理,同时还支持任务调度。
celery 的优点
简单:celery的 配置和使用还是比较简单的, 非常容易使用和维护和不需要配置文件
高可用:当任务执行失败或执行过程中发生连接中断,celery 会自动尝试重新执行任务
如果连接丢失或发生故障,worker和client 将自动重试,并且一些代理通过主/主或主/副本复制方式支持HA。
快速:一个单进程的celery每分钟可处理上百万个任务
灵活: 几乎celery的各个组件都可以被扩展及自定制
1.1 celery 可以做什么?
典型的应用场景, 比如
异步发邮件 , 一般发邮件比较耗时的操作,需要及时返回给前端,这个时候 只需要提交任务给celery 就可以了.之后 由worker 进行发邮件的操作 . 比如有些 跑批接口的任务,需要耗时比较长,这个时候 也可以做成异步任务 . 定时调度任务等 2 celery 的核心模块
2-1 celery 的5个角色
Task
就是任务,有异步任务和定时任务
Broker
中间人,接收生产者发来的消息即Task,将任务存入队列。任务的消费者是Worker。
Celery本身不提供队列服务,推荐用Redis或RabbitMQ实现队列服务。
Worker
执行任务的单元,它实时监控消息队列,如果有任务就获取任务并执行它。
Beat
定时任务调度器,根据配置定时将任务发送给Broker。
Backend
用于存储任务的执行结果。
版权声明:本文为CSDN博主「阿常呓语」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/u010339879/article/details/97691231
<a name="GtUS0"></a>
## 报错处理
1. Form和ModelForm不能混淆,否则会报错keyerror
2. s不能少,拼写不要错
2. list.sort() 没有返回值
2. modelform的手动报错,手动更新错误的格式
<a name="huMIL"></a>
###
<a name="jmPEG"></a>
## 用openPyxl来操作 Excel表
| **类别** | **语句** | **备注** |
| --- | --- | --- |
| 在pycharm上安装openPyxl, | 在 pycharm中进入preference设置<br />然后选择python interpretor , 点加号,搜索openpyxl, 安装即可。 |
|
| **导入openPyxl模块** | from openpyxl import Workbook | Workbook 子模块可以创建exl文件,exl字表,写入数据,存储等 |
| **打开已有文件** | from openpyxl import load_workbook<br />wb =load_book(“路径+文件名") |
|
| **新建exl文件** | wb=Workbook() | wb是一个exl文件实例 |
| **访问exl表和单元格** | wb.active<br />wb.sheetnames<br />ws = wb[“子表名"]<br />ws[“A5"]<br />ws[“1"]<br />ws[“A"] | 当前活动表<br />子表的名字列表<br />1,访问子表<br />2,访问A5单元格<br /> 列号要在前 否则报错<br />3,访问第一行<br />4, 访问第一列 |
| 写入 excel | ws.append([列表]) | 添加到表的最后一行,列表每一项对应一个单元格 |
| **存储exl文件 **<br />**关闭文件** | wb.save(“要存储的文件名")<br />wb.close() |
|
| 单元格格式设置<br />1,字体 | from openpyxl.styles import Fonts, PatternFill 导入字体 和填充模式<br /><br />font=Font(name='黑体', #字体<br />size=12, #大小<br />bold=True,<br />italic=True,<br />color='rgb值转为hex') #16进制颜色 |
|
| 单元格格式设置<br />1,填充色 | Fill = PatternFill( <br />fill_type= ‘solid" #填充类型<br />start_color=“FFFFFF” #前景色 <br />end_color= 0000000” #背景色 <br /> )<br />2, cell.fill = Fill | 备注: 颜色用十六进制 RGB 颜色 |
| 2, 对齐 | Alignment(<br />horizontal=‘center‘, #水平居中<br />vertical=‘center‘) #垂直居中 |
|
<br />案例:
```python
from openpyxl import load_workbook
from openpyxl import workbook
def register(username, password):
db_file_path = os.path.join(BASE_DIR, FILE_NAME)
if os.path.exists(db_file_path):
# 打开excel文件,workbook
wb = load_workbook(db_file_path)
# 读取第一张sheet表
sheet = wb.worksheets[0]
# sheet表的max_row最后一行的行号
next_row_position = sheet.max_row + 1
else:
wb = workbook.Workbook()
sheet = wb.worksheets[0]
next_row_position = 1
# 读取单元格内容
user = sheet.cell(next_row_position, 1)
user.value = username
pwd = sheet.cell(next_row_position, 2)
# MD5加密
pwd.value = md5(password)
ctime = sheet.cell(next_row_position, 3)
# 日期字段字符串化
ctime.value = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
wb.save(db_file_path)
备注:
遍历每行的方法: 参数2是起始行数
for row in sheet.iter_rows(2):
print(row[1].value)
def studentAdm(request, current_page = 1):
# print(student.stu.birthday)
if request.method == "GET":
if request.GET.get("page"):
current_page = int(request.GET.get("page"))
print("current_page",current_page)
return showStudent(request,current_page=current_page)
# 接收前端上传的excel文档
else:
upload_file = request.FILES.get("upload_file")
print(upload_file)
file_path = os.path.join("media",upload_file.name)
# 存入media文件夹
with open(file_path,"wb") as f:
for line in upload_file:
f.write(line)
# 读取excel文件
excel_file = load_workbook(file_path)
ws = excel_file.active
count = 0
# 应该考虑使用批量导入,而不是一条一条导入
try:
# 使用事务管理transaction来避免导入失败时已经导入部分数据,数据出现不一致
with transaction.atomic():
# 先把创建的对象放入列表,然后用bulk_create一次添加,从而提高效率
student_list = []
# 读取文件每一行,如果出错,直接报错
for row in ws.iter_rows(min_row=2):
if not row[0].value:
break
print("row[4].value",row[4].value,type(row[4].value))
sex_choice = {"男": 0, "女": 1, "保密": 2}
sex = sex_choice.get(row[1].value.strip())
if sex == None:
raise KeyError
birthday = datetime.strftime(row[4].value,"%Y-%m-%d")
stu_detail = Stu_details.objects.create(mobil=row[2].value, email=row[3].value, birthday=birthday)
clas= Clas.objects.get(name=row[5].value)
student = Student.objects.create(name=row[0].value, sex=sex, clas_id=clas.id, stu_id=stu_detail.id)
print(row[0].value, birthday, sex, student.id, clas.id)
count += 1
student_list.append({"name":row[0].value, "sex":sex, "birthday":birthday, "clas":clas.name})
# 捕捉错误,返回给前端
except Clas.DoesNotExist:
res = {"status": False, "msg": "导入失败,班级名称不存在"}
except KeyError:
res = {"status": False, "msg": "导入失败, 性别存在错误"}
except Exception:
res = {"status": False, "msg": "导入失败, 邮件地址重复错误"}
else:
res = {"status": True, "msg": "成功导入{}条记录".format(count),"students":student_list}
return JsonResponse(res)
CRM上线项目的bug修复日志
2022.5.19日:
修复订单号的bug,因为订单号有唯一索引,所以申请新订单的时候订单号不能存储为J_格式,只能在审核前隐藏单号
还有申请中的订单不可编辑,只有配单号以后才可以编辑
便于更新维护的办法,是保持本机的环境和服务器的环境完全一致,这样可以直接复制拷贝本地项目文件到服务器即可完成更新,非常的nice

若有收获,就点个赞吧
0 人点赞
