数据库 MySQL
一 MySQL基础
功能:存储和管理数据,尤其是大型数据;可以类比为一个大型的复杂的文件夹和文件
常用的集中数据库管理系统
- MySQL 免费+收费
- Oracal 甲骨文 收费,一般国企公司用的多,传统数据库大佬
- 微软 SQL Server,Access
- IBM的 DB2 免费+收费
- Ricard个人开发的 SQLlite 免费
- 数据库管理系统 DBMS。 数据库是文件夹,DBMS是管理(增删改查等动作的)的软件系统,客户端通过指令与DBMS交互,获取数据
- 数据库管理,类似于文件夹
- 数据表管理,类似于Excel表
- 数据行管理 ,类似于Excel表的行
- 安装MySQL
- 到网址download.mysql.com 找到对应操作系统版本,下载安装即可
- 主要的互联网公司采用5.7版本,而新一点的采用5.8版本,区别不大。最新的是8系列版本
- mac的版本安装,5.7.31版本,直接到官网下载dmg格式文件,傻瓜安装即可
- 2022.5.月份改为下载 MySQL Community Server 版本,选择不登录直接下载 ,安装。
- 启动:
- 在文件目录下 usr/local/mysql下面新建文件夹etc,下面新建文件my.cnf
- 这个文件夹是隐藏的,在mac系统下找到finder的菜单:前往 - 前往文件夹
- 在系统终端输入 usr/local/mysql/support-files/mysql.server start
- 启动成功,显示SUCCESS
- 安装路径: /usr/local/mysql (本机地址)
- 在文件目录下 usr/local/mysql下面新建文件夹etc,下面新建文件my.cnf
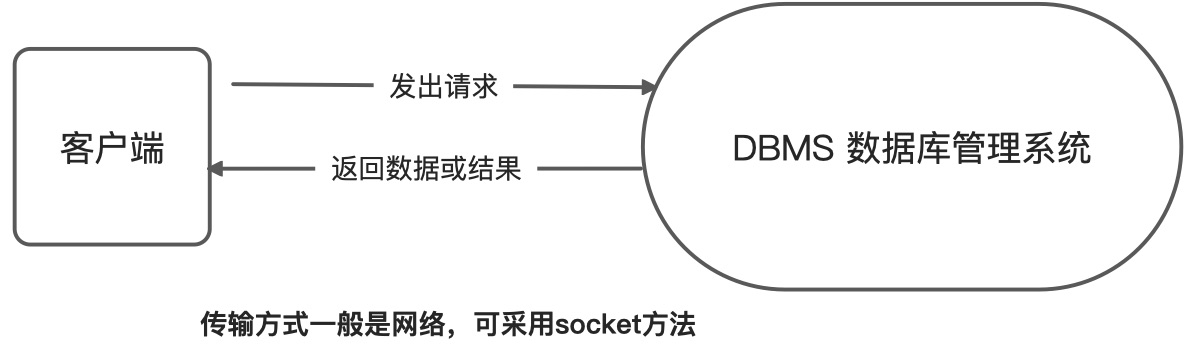
- 数据库DBMS与客户端之间的交互关系图
终端登录数据库
mysql -h 'host-name' -P 3306 -u username -p# -h 主机名# -P 端口# -u user# -p password
MySQL的基本指令
数据库的操作
- 数据库的创建
```plsql
create database 数据库名 default charset utf8 collate utf8_general_ci;
— 注意最后的分号; collate是校对的意思,意思是按后面的排序
查看数据库创建语句 SHOW CREATE DATABASE ZOOG;
汉字的长度问题
```python
遇到的问题:load_info字段设定的是 varchar(128), 存储汉字的字符数不超长度,但是数据库认为超长
本机装的mysql 5.7版本, 服务器装的mariaDB 10.3.28版本
原因:
MySQL的汉字的字符长度计算
Server version: 5.7.31 MySQL Community Server (GPL)
5.0以上汉字按一个长度计算
测试 select length('测试'); # 6 utf-8一个汉字3个字节
测试 select char_length('测试'); # 2 字符数量2
轻量服务器的数据库是mariaDB, 版本Server version: 10.3.28-MariaDB MariaDB Server
show variables like 'character%';
MariaDB [(none)]> show variables like 'character%';
+--------------------------+------------------------------+
| Variable_name | Value |
+--------------------------+------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | latin1 | # 数据库
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 | # 服务器
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mariadb/charsets/ |
+--------------------------+------------------------------+
mariaDB的配置文件所在位置:
/etc/my.cnf
/etc/my.cnf.d/
目录下文件列表
auth_gssapi.cnf enable_encryption.preset mysql-clients.cnf
client.cnf mariadb-server.cnf
数据库的删除
drop database 数据库名;数据库列表的显示
show databases; -- 注意复数s数据库的打开
use 数据库名;数据表的操作
表的创建
- mysql中的字段名不论大小写
- mysql中的命令无论大小写,这可能跟最终由银行等大型机构使用的原因 ```plsql create table tb(列名1 类型 性质,列名2 类型 性质) default charset=utf8 ;
— 举例 create table tb4( id int not null auto_increment primary key, name char(10) not null, — 姓名,字符串, 不为空, 主键 age, int default 18, — 年龄,整型,默认值18 gender enum(“男”,”女”) default “男” — 性别,数据序列,默认值男 ) default charset=utf8; — 字符集 utf8
2. 表的显示
```plsql
show tables; -- 显示当前数据库中的表的清单
desc tbname; -- 显示表的字段细节
表的字段设置
alter table tb add 字段名 类型; -- 增加字段 alter table tb change 原字段名 新字段名 类型; -- 修改原字段表的删除
drop table tb3;表的清空
delete from tb3; truncate table tb3; -- 这个不能恢复,慎用数据行的操作
数据行的添加 ```plsql insert into infotb (id,name,pwd) values(1,”alex”,”123213”);
insert into infotb (pwd) values(“123213”);
如果只插入一列,其他列取默认值或者自增
2. 数据行的删除
```sql
delete from tb where id = 1;
- 数据行的修改 ```plsql update tb3 set name = “alex”; — 如果不指定范围,将会修改所有行的name的值
update tb3 set name = “alex” where id>3; — id大于3的,将会修改所有行的name的值
4. 数据的查询 ** 各种花式查询
```plsql
select * from infotb where name="alex" and password="123213";
-- 条件之间用and或者or连接
- 数据库的导出和导入
二 各种查询方法
1. group 分组
```sql — group的功能是按某个列名把列名里面重复的进行归并 — 用途: — 统计某个值的出现次数,或者对某个人的成绩进行汇总,平均等
select count(1) from tb order group by name;
<a name="TtV0S"></a>
### 2. order 排序
```sql
select * from tb order by name desc; -- 按姓名降序排列
select * from tb order by amount asc; -- 按金额升序排列
-- order可以放在sql语句的最后,执行顺序比较靠后
3. 视图
(select * from tb where amount>60 order by name desc) as tb2
-- 查询到的临时表可以当成表来对待,称为视图,但它不是物理上存储的表
2. 命令优先级
select -- 选择的字段
name,
title
from -- 数据来源
table1
left join talbe2 on table1.tb2ID= table2.id - 表之间的连接点
where
name = "三年二班" -- 筛选条件
and title not in ("班长","学习委员")
group by -- 按name分组
name
having
num < 3 -- group之后再筛选用having
order by
num desc limit 2; - 按num降序排序,取前2行数据
3. SQL参数化查询 pymysql
- 作用是防SQL注入
- 特别注意,pymysql里面的参数占位符永远是%s, 不区分数据类型 ```sql cursor.execute(“select * from tb1 where aid=%(aid)s”,{“aid”=1}) — #这里面第二个参数必须是一个字典 — #但是在函数传参数时,会自动把关键字参数变成字典,所以这个过程可能会造成混乱
cursor.execute(“select * from tb1 where aid=%s”,(1,)) — 第二种用法是不用关键字占位,而按位置传,后面的参数必须是一个元组和列表,元组里面的参数只能是字符串或者数值,且个数和位置与%s必须一一对应。 — 所以只有一个元素时,必须写成(1,)或者[1,]
<a name="fdGyZ"></a>
### 4. case when 方法
```plsql
-- 系统拿num与1进行比较,如果相等则“yes", 否则”no“, 列名设为v1
case num when 1 then "yes" eles "no" end v1
-- 如果不是相等关系,case后面为空,应写成:
case when num<1 then "yes" eles "no" end v1
-- else不写的,默认为”none“
case when num<1 then "yes" end v1
-- 对case when语句进行sum操作,别名要写在外面,否则报错
sum(case when num<1 then 1 else 0 end) as x1
5. 内置函数
-- 数学, 通常与group连用
min()
max()
count()
sum()
avg()
-- 字符串
concat() -- 用,连接字符串
group_concat() -- 分组的时候,把所有的数据用‘,’连接成长字符串
reverse() -- 翻转字符串
char_length()
insert()
lower()
upper()
...
-- 系统
sleep() -- 停几秒
-- date_format 函数
# 功能: 从datetime数据中取年或者月,或者年月
# 语法:
select date_format(dt, "%Y-%m") from datetime_table
# 结果:date_format(dt,"%Y-%m") 2018-06
6. 自定义函数
delimiter $$
create function f1(i1 int, i2 int)
returns int -- 这个地方是returns,多个s表明不是要从这里跳回,只是说明返回值类型
begin
declare num int;
declare maxId int;
select max(id) from big into maxId;
set num = i1+i2 +maxId;
return (num); -- 有没有括号都行
end $$
delimiter;
数据表关联
左联、右联
from tb1 left join tb2 on tb1.tb2ID = tb2.id -- 数据表左连接
tb1 union tb2 - 数据表的上下连接
外键
-- 建表的时候添加外键, 特别注意:字段名用的是括号不是点
create table t1 (name varchar(10), age int, constraint fk_name foreign key (name) references t2(name) ) default charset =utf8;
-- 建表之后添加外键
alter table t1 add constraint fk_name foreign key (name) references t2(name)
create table orders ( oid int not null auto_increment primary key,
customer_id int,constraint fk_cus foreign key (customer_id) references customer(id)) default charset=utf8;
-- 特别注意order是关键字,不能用为表名。
用户管理和授权
创建用户
create user kaifeng@localhost identified by "root123";
-- 创建用户kaifeng,访问位置localhost 密码root123
rename user kaifeng@localhost to kai@"127.0.0.1";
-- 修改用户
set password for kaifeng@localhost Password=("123");
授权
grant all privileges on *.* to username@localhost;
-- 把所有的权限都授予username从localhost位置访问
show grants for username@localhost;
-- 查username的授权
flush privileges;
-- 授权立即生效
权限列表
all privileges 除grant外的所有权限
select 仅查权限
select,insert 查和插入权限
...
usage 无访问权限
alter 使用alter table
alter routine 使用alter procedure和drop procedure
create 使用create table
create routine 使用create procedure
create temporary tables 使用create temporary tables
create user 使用create user、drop user、rename user和revoke all privileges
create view 使用create view
delete 使用delete
drop 使用drop table
execute 使用call和存储过程
file 使用select into outfile 和 load data infile
grant option 使用grant 和 revoke
index 使用index
insert 使用insert
lock tables 使用lock table
process 使用show full processlist
select 使用select
show databases 使用show databases
show view 使用show view
update 使用update
reload 使用flush
shutdown 使用mysqladmin shutdown(关闭MySQL)
super 使用change master、kill、logs、purge、master和set global。还允许mysqladmin调试登陆
replication client 服务器位置的访问
replication slave 由复制从属使用
root密码遗失
当root用户无法登录时,set password也没法用,这个时候不要傻了,这么办:
以下参考:https://www.cnblogs.com/Neeo/articles/13062703.html#本地管理员用户密码忘记了
主要思路是:停止mysql; 安全无登录; 修改密码;重启mysql
第一步:停止mysql (如果数据库是mariadb版本,这里应该是stop mariadb)
[root@cs mysql]# systemctl stop mysqld
第二步:禁用授权表
[root@cs mysql]# mysqld_safe --skip-grant-tables --skip-networking &
第三步:重新无密码登录
[root@cs mysql]# mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.7.20 MySQL Community Server (GPL)
Copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
第四步:修改密码
mysql> alter user root@'localhost' identified by '123';
Query OK, 0 rows affected (0.00 sec)
第五步:使授权生效
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> exit;
第六步: 重启mysql
[root@cs mysql]# pkill mysqld # 杀死已有进程很重要,因为mysqld_safe进程阻止网络连接
[root@cs mysql]# systemctl start mysql ( 或者 mariadb)
三 索引
索引的原理
# 两种索引 聚簇索引和非聚簇索引
- Innodb 是聚簇索引,目前用的比较多的, mysql 5.5版本以后默认用他
- myisam 非聚簇索引,索引和数据分开存储
索引的使用
- 主键索引
create table tb1 id primary key, auto_increment, not null -- 自动创建主键索引
- 主键联合索引
primary key (id,name) -- 主键联合索引
- 唯一索引
unique index_name (name) -- index_name 索引的名字
create unique index 索引名 on 表名(列名) -- 添加索引名
- 唯一联合索引, 索引名字可以省略,括号不可以省略
unique index_name (name, pwd) -- 当两个字段加在一起有唯一性的时候使用
- 普通索引 index_name可以省略
index index_name (name) -- 创建表时添加
create index 索引名 on 表名(列名) -- 表已存在,添加普通索引名
- 普通联合索引
index index_name (name, pwd)
索引不能命中
- 类型不匹配 (主键例外)
- or
- !=
- 开头使用了通配符:% , _
- 联合索引没有遵循左前缀原则
- 使用了函数可能导致
- 排序可能导致不能走索引
# 不能命中的情况下,查询效率会急剧下降
# 执行计划: explain SQL语句; 可以提前预测SQL语句是否命中索引,
四 数据库导出导入
mysqldump 导出
mysqldump -uroot -p123456 -S /tmp/mysql.sock blog -B >blog.sql
# -u 用户名
# -p 密码
# -S 指定socket (问题是这个socket在哪里查)
# blog数据库
# -B 指定数据库
# > 导出到指定数据文件
先记着这一个工具即可
在shell终端导出数据库
导出全部数据库
>>> mysqldump -uroot -p --all-databases > alldata.sql
导出指定数据库
>>> mysqldump -uroot -p userdb > userdb.sql ## 没有建库
>>> mysqldump -uroot -p -B userdb > userdb.sql ## -B 包含建库 -d 只有结构
案例:
mysqldump -h bdm818511667.my3w.com -ubdm818511667 -p -B bdm818511667_db > alldata.sql
导出多个数据库
>> mysqldump -uroot -p --databases test1 test2 > 2.sql
导出单张表
>> mysqldump -uroot -p db_name tb_name > t2.sql;
Mysql的终端 导入
进入mysql命令行,输入:
mysql> source day27db.sql
在shell终端导入数据库
>>> mysql -u root -p db_name < /Users/wupeiqi/day27db.sql
注意数据库db_name必须先存在
在mysql终端导入数据库:
通过navicat工具导入, 在数据库名上右键,运行SQL文件,在其中找到导出的sql文件,导入即可。有一个办法就行,不用太深究其中奥秘,后面越学越通的。
五 阿里云虚拟主机
wordpress的博客系统安装
- 首先从WP的官网上下载WP的程序,解压到本地
- 找到wp-config.php文件,一般在config文件夹中
- 用文本编辑器打开,找到需要配置的项目:
- mysql的服务器地址
- mysql的用户名和密码
- 以上信息可以在阿里云的虚拟主机的管理后台找到
- 下载cyberduck(FTP工具),连接主机空间
- cyberduck新建连接
- 需要配置的主机地址
- FTP用户名和密码
- 以上信息也是在阿里云虚拟主机后台找
- cyberduck新建连接
- 用cyberduck将wp的文件整体上传到主机htdocs目录下
- 主机的目录结构如下:
- /. 根目录,只读
- htdocs 用户目录,存放网站的文件,php等
- wwwlogs 网站访问数据 只读
- myfolders 存放用户不对外的数据
- 主机的目录结构如下:
- 从浏览器进去主机的域名,wp自动进行安装设置,后面的就比较傻瓜
阿里云的mysql数据库
这个数据库只有一个用户,且只有一个数据库,只能在该数据库中创建表 
这唯一的用户的权限如下:
所以这个空间是不能进行其他开发的,有点扯。
六 Pymysql模块
连接数据库
conn = pymysql.connection(host=xxx.xxx.xx, port=3306, user="root",password="xx")
cursor = conn.cursor()
-- 光标 可选参数是按字典还是元组返回信息,默认是元组
cursor = conn.cursor(pymysql.cursors.DictCursor)
-- 光标, 返回的值是字典
发查询和接受信息
cursor.execute(sql)
-- 向服务器发送查询语句
cursor.fetchone()
-- 接收服务器返回信息,只取第一条
cursor.fetchall()
-- 接收服务器返回信息,取所有条
conn.commit()
-- 执行只能是连接conn来做,cursor没有commit方法
事务
conn.begin()
try:
cursor.execute(sql1)
cursor.execute(sql2)
conn.commit()
except Exception as e:
conn.rollback()
排他锁
目的:当多线程执行时,避免数据混乱,尤其是交易的时候,类似于python里面的进程或者线程锁
作用: 上锁后其他线程不能读写
关键字:for update
import pymysql
conn.bigin()
cursor.execute("select count from tb where id=2 for update")
# for update 就是排他锁的关键字,其他线程要等待
result = cursor.fetchone()["count"]
if result>0:
cursor.execute("update tb set count=count-1 where id=2")
else:
print("all is sold out")
# 执行它
conn.commit()
共享锁
目的:同排他锁
作用: 上锁后其他线程只能读,不能写
关键字:lock in share mode
七 触发器trigger
在执行某个操作之间或者之后(before/after后面的语句),执行begin—end体里面的代码,其中:
- old 代表已存在的数据
- new代表后插入的数据或者更新的数据
```plsql
delimiter $$
CREATE TRIGGER tri_before_insert_t1 — 触发器的名称
BEFORE INSERT ON t1 FOR EACH ROW — 触发的场合
BEGIN
— NEW.id NEW.name NEW.email
— INSERT INTO t2 (name) VALUES();
IF NEW.name = ‘alex’ THEN
END IF;INSERT INTO t2 (name) VALUES(NEW.id);
END $$ delimiter ;
<a name="PMrcs"></a>
## 八、 视图
视图可以视为一张临时表
```plsql
create view v1 as select id,name from d1 where id > 1; -- 创建视图
drop view v1; -- 删除视图
select * from v1; -- 像使用一张正常的表一样
博客作业总结
- 开发思路和习惯养成
- 功能要调查清楚,而且要很细
- 先有大框架,用思维导图比较好
- 然后详细到每个流程,客户可能的输入和系统的反馈
- 可以通过一个原型程序去找到用户的细微的每一个具体需求
- 把以上的需求详细的记录下来,然后整理成一个完整的需求文档,作为交货标准
- 然后将需求文档中的要求进行规范化,哪些是可实现的,哪些是不规范的有害的需求,再次与需求方沟通,以便达成一个可以实现的合理的需求文档,经过以上两个过程基本可以确定需求文档,主要方向上不能再有大的改动
- 局部改动可以允许,但是只能是方法上的允许,不能推倒需求文档的重要部分,否则说明前期的工作不到位,应该改进前期的工作方法
- 功能要调查清楚,而且要很细
- 具体的实现方法 ``` 闭包: 如果进入一个程序和退出一个程序都会固定执行的代码,可以用闭包的方式实现
事务: mysql中的事务有原子性,一致性,隔离性和持久性,所以适宜于重要的事情,比较交易,同时更新两张表,而且内容相互关联,不容出错 语法:conn.begin() try: sql1 sql2 except exceptions as e: conn.rollback() else: conn.commit — 这句或者写到try的最后面也可以
堆栈: 这里可以应用在终端导航栏的设计上,用列表的append和pop方法实现
property装饰器: 可用于某些不需要参数(除self以外)的调用场合,有点小用处
sql语句中的两种参数传递方法,args和*kwargs
```
- 体会
- 学无止境,总有更优雅和高效的方法
- 编程此条路很深,慢慢修行吧
- 如果以编程者的态度做事情,哪有不成功的
- 这些有效的方法可以移植到其他事情上
- 当然领域的有效方法也可以移植到编程上
- 代码世界和现实世界打通的地方越来越大
- 构建自己的学习树,不断生长
- 方法不是最重要的,而与需求相匹配的方法才是,炫技不可取
- 写代码就跟写文章,境界决定层次
- 当一个项目足够大,对于每一小段代码的质量要求就提高了,所以基本功要扎实
- 项目逐渐变大,然后代码的逻辑性和模块性要从小开始培养
- 代码的执行效率和维护方便性将会是下一步的要求
- 学无止境,总有更优雅和高效的方法
张导的考核意见
抽时间细化以下内容 2021.11.29
mysql的进阶的东西,还需要后续自己多找找资料多看看,包括但不限:
- 备份,掌握最基本的备份命令
- mysqldump -uroot -p123 blog > blog.sql -u用户名 -p密码 blog数据库 blog.sql 导出的文件
- mysqldump -uroot -p123 -B blog > blog.sql -B 带数据库建库语句
- 日志(slow log,bin log, error log)
- 其中最重要的是bin log可以用于备份和恢复数据,具体怎么用看博客
- https://www.cnblogs.com/Neeo/articles/14006790.html#about
- error log错误日志,记录了错误的信息,便于后期维护。
- 存储引擎,InnoDB
- 事务 redo log undo log
- 隔离级别
- 读写分离
- 执行计划
- MySQL常见的优化
掌握集中非关系型数据库:
- redis 适合做缓存,尤其是热点查询
- mongodb 适合做集群
- elasticsearch 适合做大文本搜索
九、sqlite3 数据库
简介:是一款软数据库,简单灵活,硬件要求低。SQLite 是一个自包含的、轻量级数据库,可轻松创建、解析、查询、修改和传输数据。
- 安装及命令行
sqlite3 # shell下输入命令进入sqlite3的提示命令符
.q 退出 # 所有的系统命令都是点开头,除了SQL命令
.tables 查看表
.databases 查看数据库
.show 显示参数
- 创建数据库
.open database_name.db # 如不存在,相当于创建
.open dataebase_name.db # 如果已经存在,则相当于use
- 表的增删改
create table name (id int not null, name text not null) # SQL语句
- 表的查询
十、 MariaDB (MySQL的分支)
来源:
创建MariaDB数据库服务的原因之一,是因为MySQL的创始人Michael Widenius早前曾以10亿美元的价格,将自己创建的公司MySQL AB卖给了SUN,之后SUN又被甲骨文公司(Oracle)收购,MySQL的所有权也落入Oracle的手中。
被甲骨文公司收购后,MySQL的开发者担心甲骨文公司会有将MySQL闭源的风险,所以创建了MySQL的一个分支,也就是免费开源的MariaDB数据库服务,完全兼容MySQL。MariaDB名称来自Michael Widenius的女儿Maria的名字。
虽然是分支,但是MariaDB在某些方面的性能强于MySQL,例如在扩展功能、存储引擎以及一些新的功能改进方面都强过MySQL。
当MariaDB被开发后,大型互联网用户以及Linux发行商纷纷抛弃MySQL,转投MariaDB阵营,MariaDB是目前最受关注的MySQL数据库衍生版,也被视为开源数据库MySQL的替代品。
MariaDB优秀的地方在于: 更快的查询,更快的引擎

若有收获,就点个赞吧
0 人点赞
