 ">
">
参考资料
https://www.bilibili.com/video/BV1d4411v7u7?from=search&seid=7479248173779678370
什么是操作系统?
开机
计算机取址执行 boot -> setup -> system
X86 PC开机时CPU处于实模式(16位模式)
开机时,CS=0xFFFF;IP=0x0000
寻址0XFFFF0(ROM BISO映射区)(和保护模式对应,实模式寻址CS:IP(CS左移四位+IP))
检查RAM,硬盘,显示器,软硬磁盘
将磁盘0磁道扇区(引导扇区)读入0x7c00
设置cs=0x07c0,ip=0x0000
0x7c00处存放的代码,引导扇区代码
-> bootsect.s(init logo(loading sysmtem …)) 
-> setup.s 完成OS启动前的设置 读取并保存硬件参数
挪动system 基址 0
初始化gdt , 切换保护模式(32位模式)
-> system 控制文件Makefile 控制依赖树形
执行第一个模块head.s 初始化参数,设置页表,执行main(0,0,0)envp,argv,argc
初始化各模块 mem_init 4k=0
操作系统接口
什么是操作系统接口?
用户态->操作系统接口->内核态
用户使用程序调用操作系统接口完成硬件交互
操作系统接口:系统调用
POSIX 统一IEEE定制的标准族
任务管理
->fork 创建进程
->execl 运行可执行程序
->pthread_create 创建线程
文件系统
->open 打开一个文件/目录
->EACCES 返回值,表示没有权限
->mode_t_st_mode文件头结构:文件属性
系统调用的实现
用户态 -> int0x80 -> _system_call -> 查表,调用kernel接口
1.将内核程序和用户程序隔离
区分内核态和用户态:一种处理器”硬件设计”
CS:IP CS最低的两位 -> 0:内核态,1/2:OS,3:用户态
段寄存器CPL(CS)当前特权级0/1/2/3,RPL(DS),DPL目标端 1.DPL>=CPL 2.DPL>=RPL
2.硬件提供了进入内核的方法
int0x80 中断指令int: 暂时将使CS的CPL改成0 “内核态”
sched_init(void){set_system_gate(0x80,&system_call);} 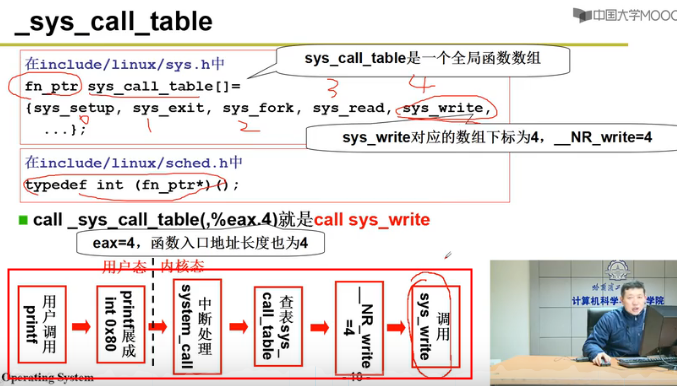
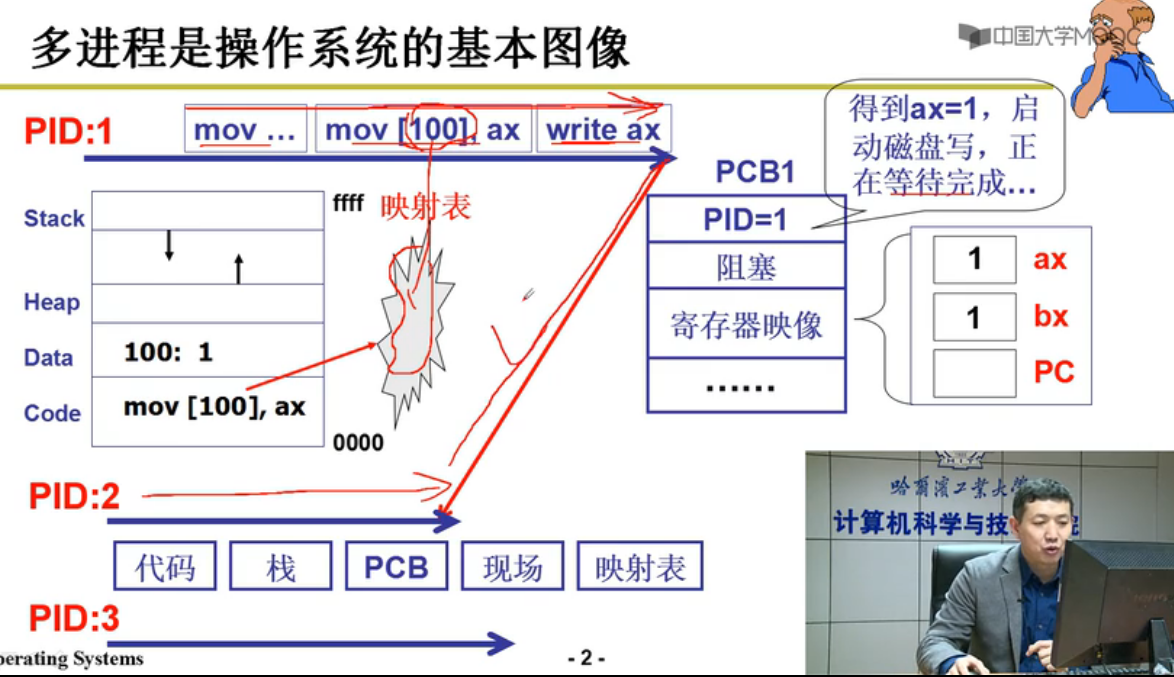
CPU多进程图像
基本概念
CPU工作原理:自动的取址执行
提升CPU利用率:多道程序,交替执行
进程:进行中的程序
多进程图像:操作系统记录多个进程推进,按照合理的次序推进(分配资源,进行调度)PCB记录状态
开机程序main.c
-> init执行了shell(Window桌面)
-> shell再启动其他进程
支持组织多进程:PCB+状态+队列
由PCB形成多队列(就绪队列,磁盘等待队列…)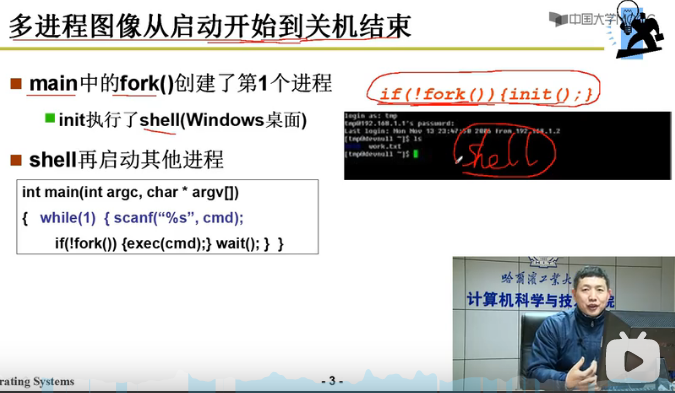
进程状态
新建态->loop就绪态
<->运行态
->阻塞态 ->loop就绪态
->终止态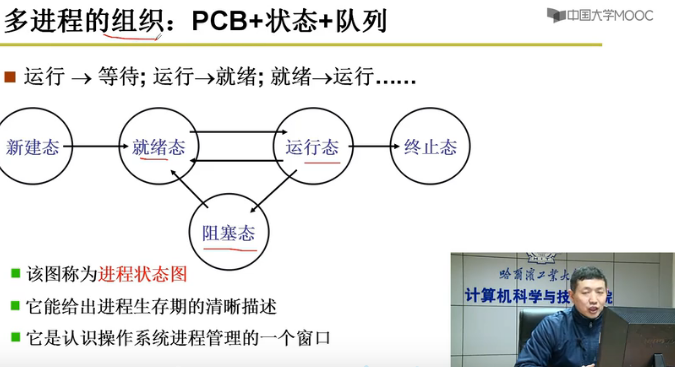
多进程如何交替?
1.设置状态
2.放至队列
3.进程切换 - schedule()
schedule(){pNew = getNext(ReadyQueue);// 就绪队列找到下一个进程PCB(CPU调度)switch_to(pCur,pNew);// 根据PCB切换}
多进程切换
1.映射表完成地址空间分离,数据隔离
2.进程同步加锁,合理的推进顺序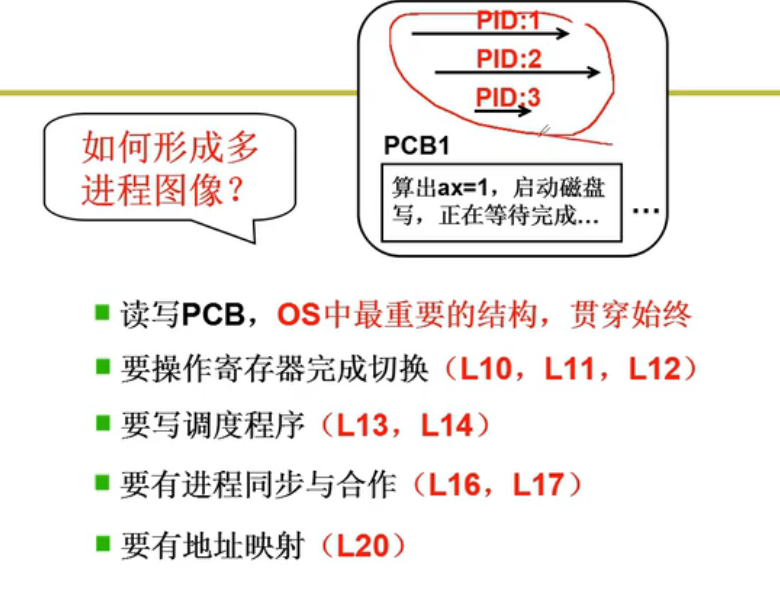
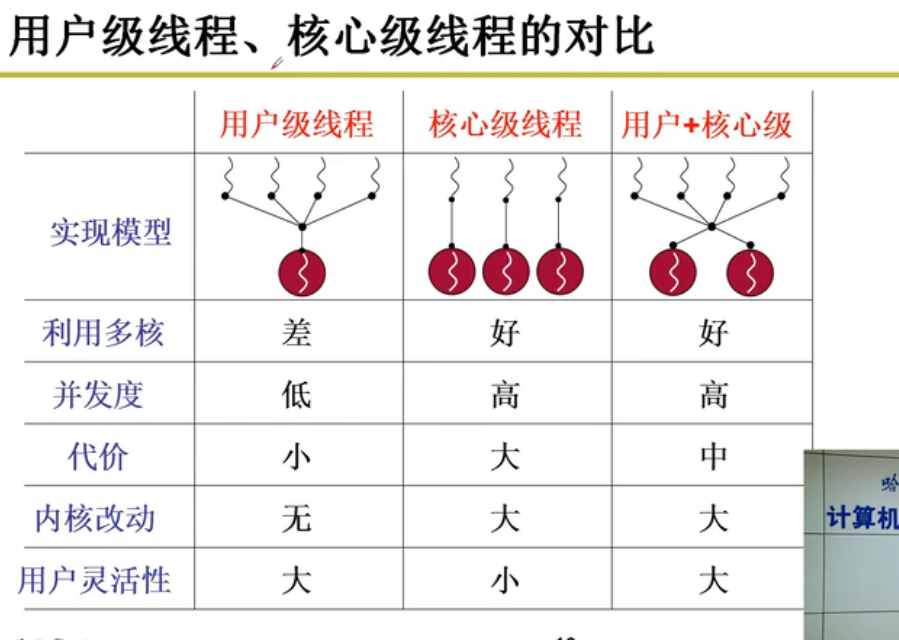
用户级线程
基本概念
进程 = 资源 + 指令执行序列
将资源和指令执行分开
一个资源 + 多个指令执行序列
线程:保留了并发的优点,避免了进程切换代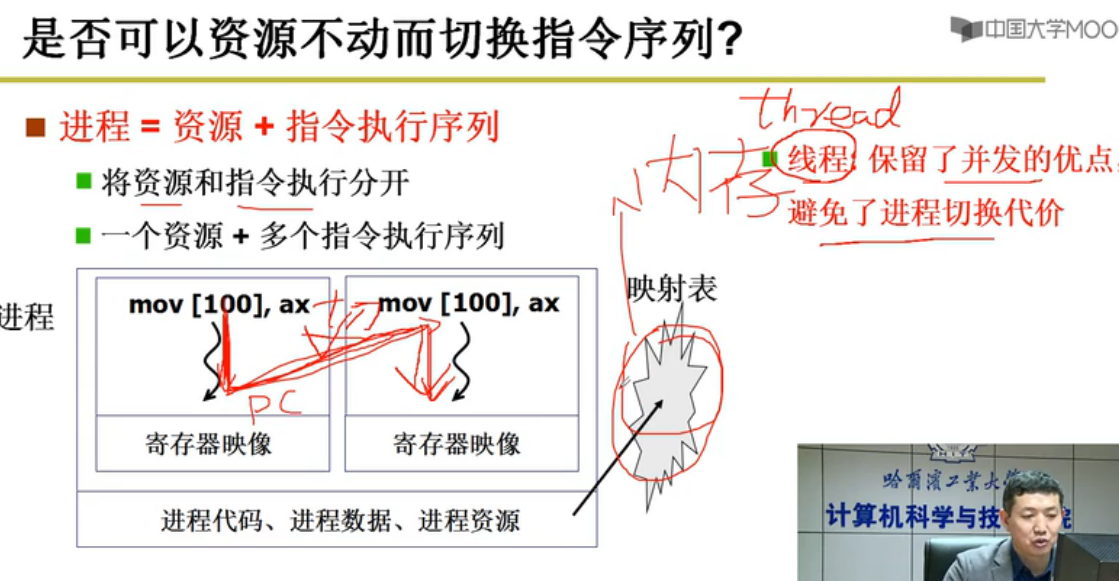
核心是Yield
切换时需要保存什么样子?
创建时要创建什么样子?
解决:从一个栈到两个栈
数据结构TCB 存esp栈信息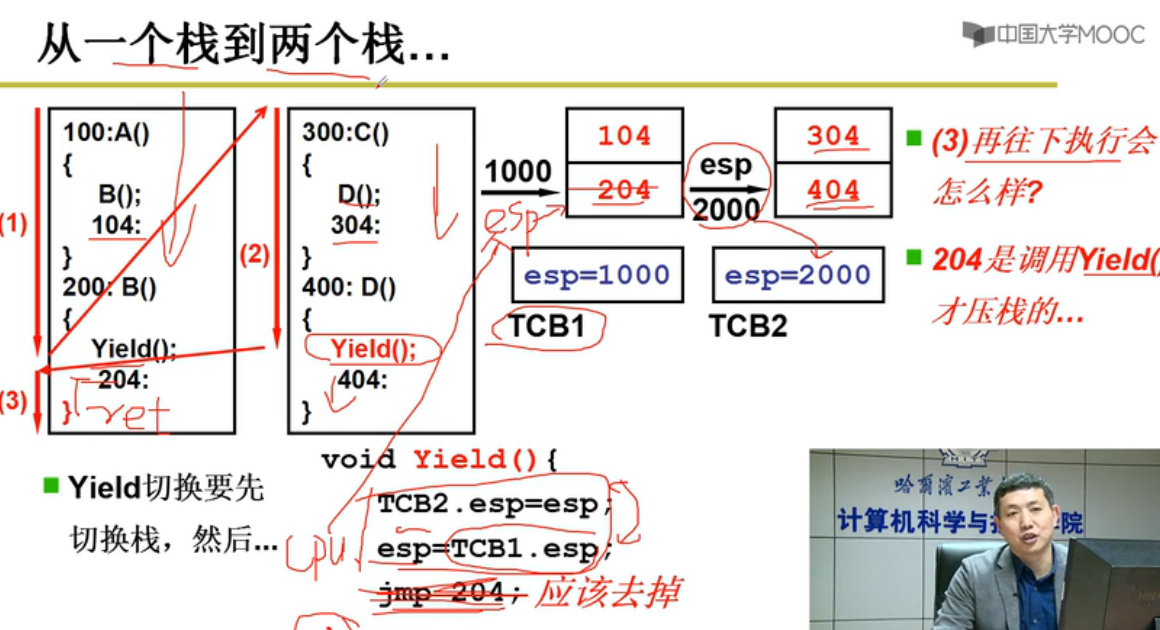
内核级线程
核心级线程公用MMU存储单元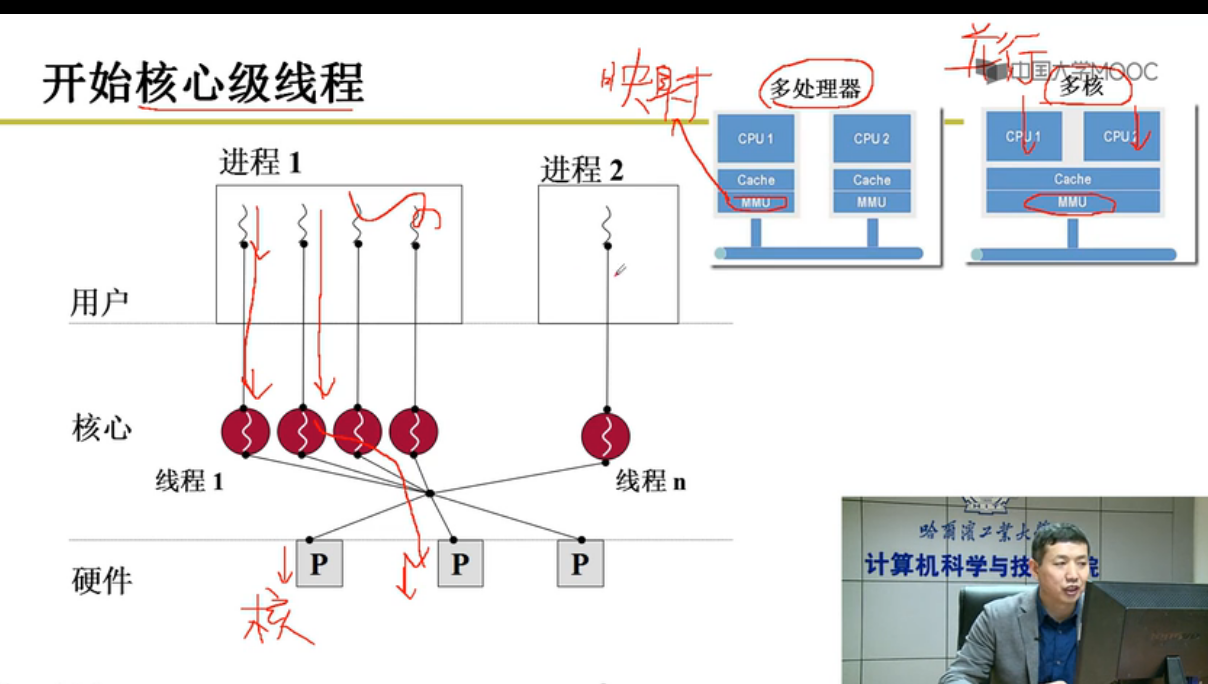
一个栈到一套栈;两个栈到两套栈
INT中断指令启用内核栈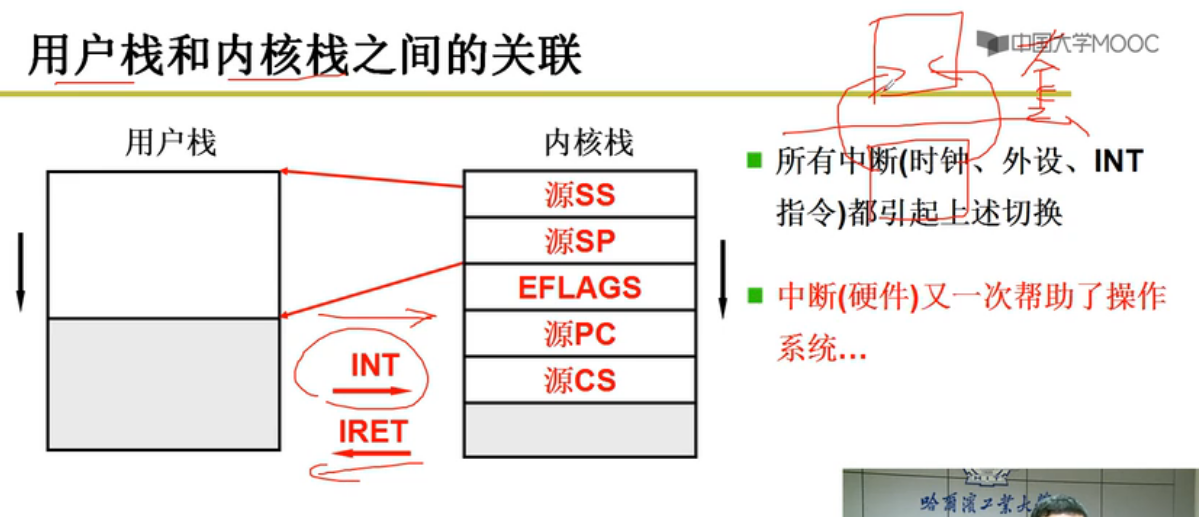
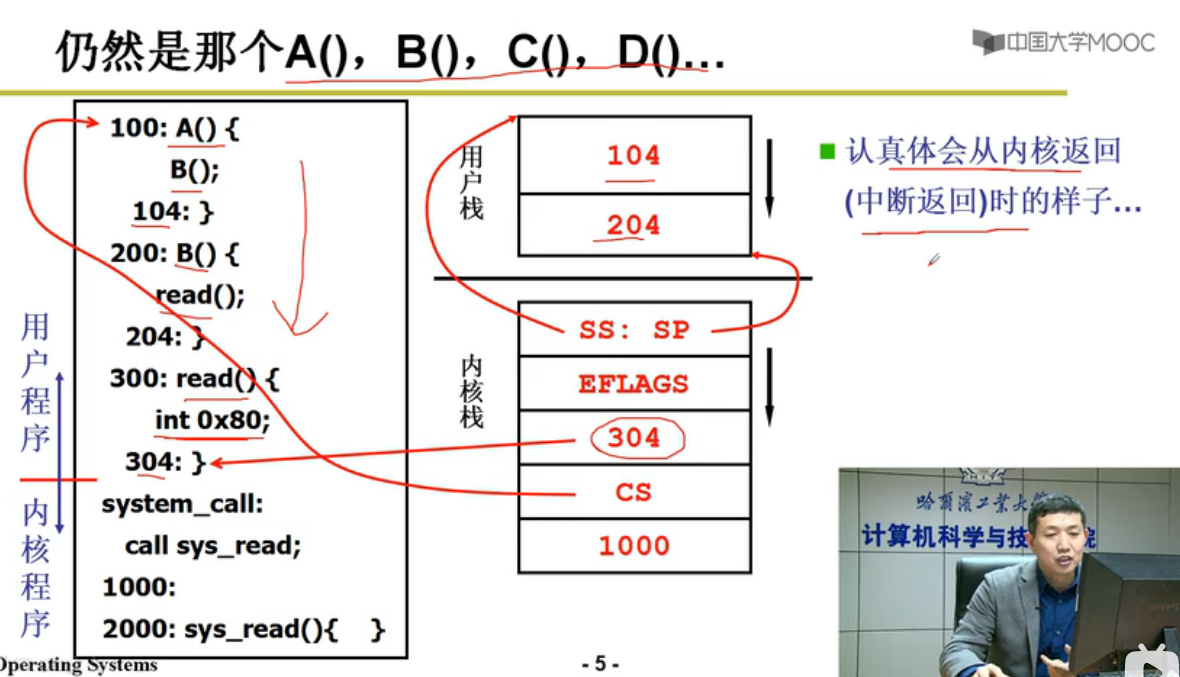
switch_to五段论
中断入口(进入切换) -> 中断处理(引发切换) ->schedule : swithc_to -> 内核栈切换 ->中断出口
特征比较
CPU调度
吞吐量:完成任务数量
周转时间:后台任务从进入到结束
响应时间:前台任务交互时间
Shortest Job First (SJF) 先来先服务

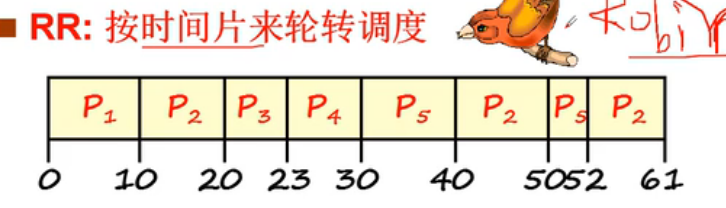
Round Robin (RR)轮转调度
进程同步与信号量

如何实现线程同步?
信号量临界区保护
竞争条件:和调度有关的共享数据语义错误
修改信号量代码必须保证语义正确
临界区:一次只允许一个进程进入的该进程的那一段代码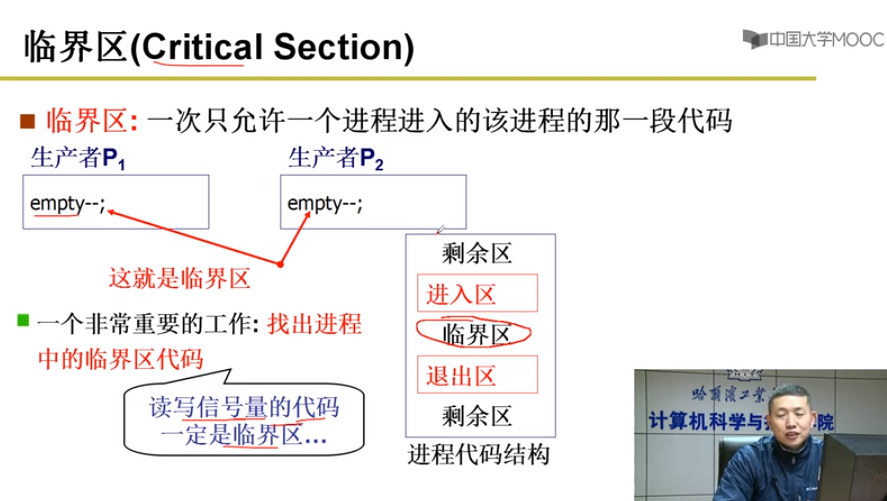
临界区代码的保护原则
基本原则
互斥进入:如果一个进程在临界区中执行,则其他进程不允许进入
有空让进:若干进程要求进入空闲临界区时,应尽快使一进程进入临界区
有限等待:从进程发出进入请求到允许进入,不能无限等待
软件法
轮换法:各进程轮流进入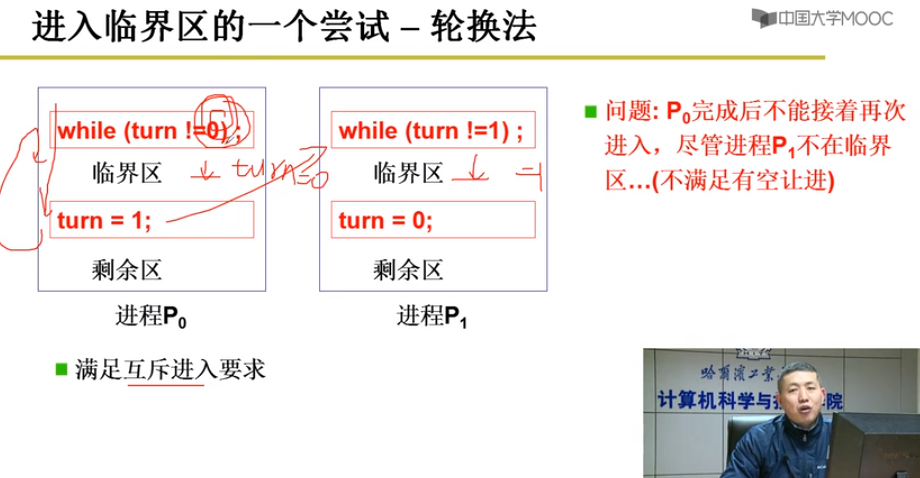
标记法:进程进入临界区时标记
对称标记 -> 同时标记,无法进入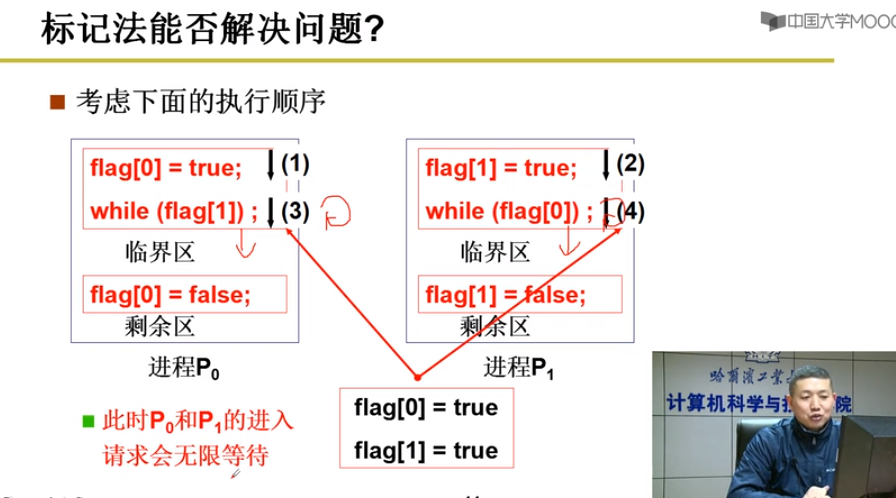
非对称标记
peterson算法

面包店算法
硬件法
cli()关中断/sti()开中断
cpu INTR寄存器数据隔离 
原子指令法(硬件信号量)
原子指令不能被打断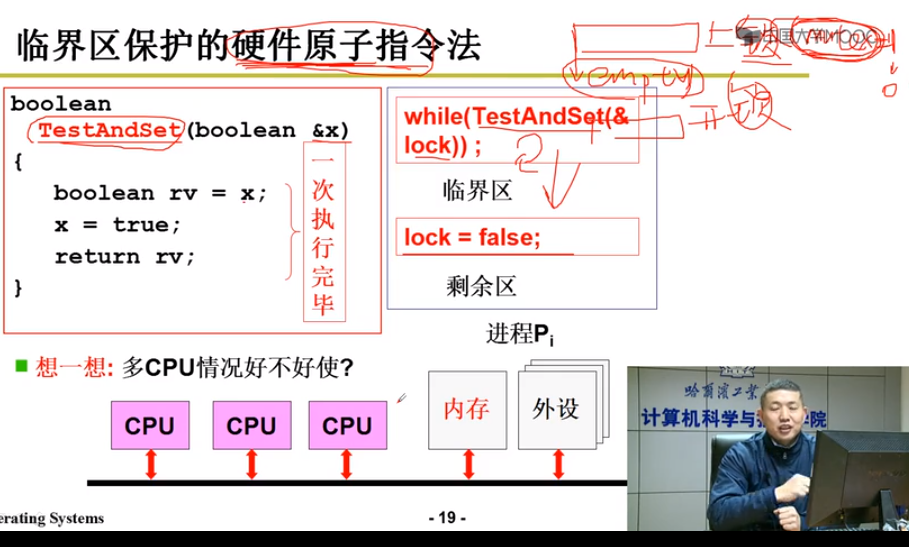
while(lock) : 唤醒所有等待队列 由schedule()根据优先级调度
死锁处理
死锁的成因
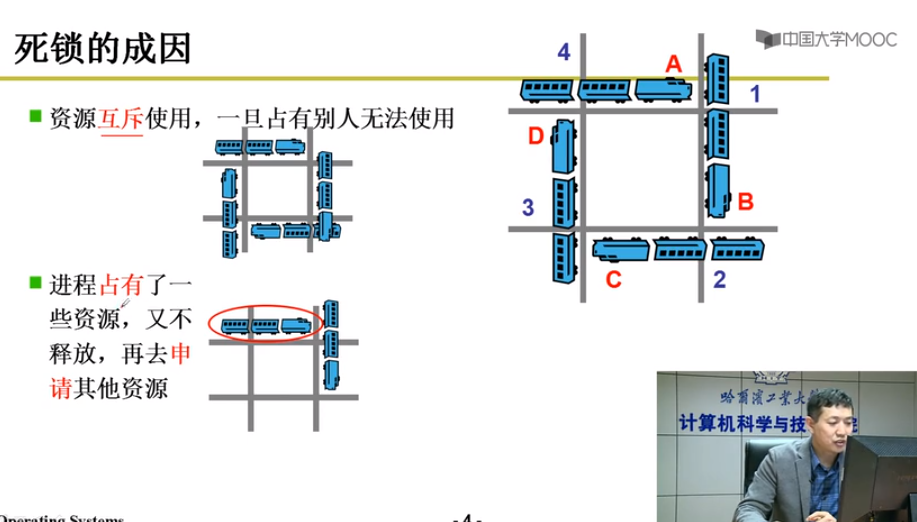
四个必要条件
互斥使用:资源的固有特性
不可抢占:资源只能自愿放弃
请求和保持:进程必须占有资源,再去申请
循环等待:再资源分配图中存在一个环路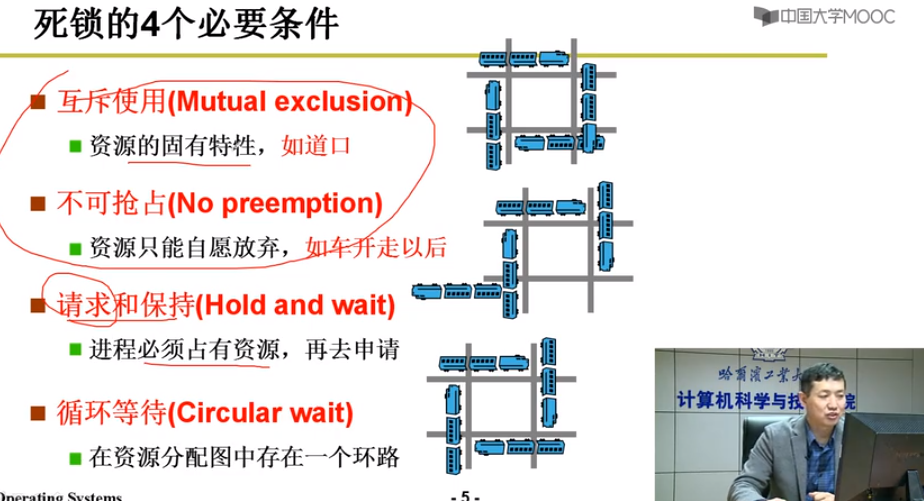
死锁处理方法
死锁预防:破坏死锁的必要条件
1.在进程执行前,一次性申请所有需要的资源
2.对资源类型进程排序,资源申请必须按序进行,不会环路等待
死锁避免:检测每个资源请求,如果造成死锁就拒绝
银行家算法:如果系统中的所有进程存在一个可完成的执行序列P1,…Pn,则称系统处于安全状态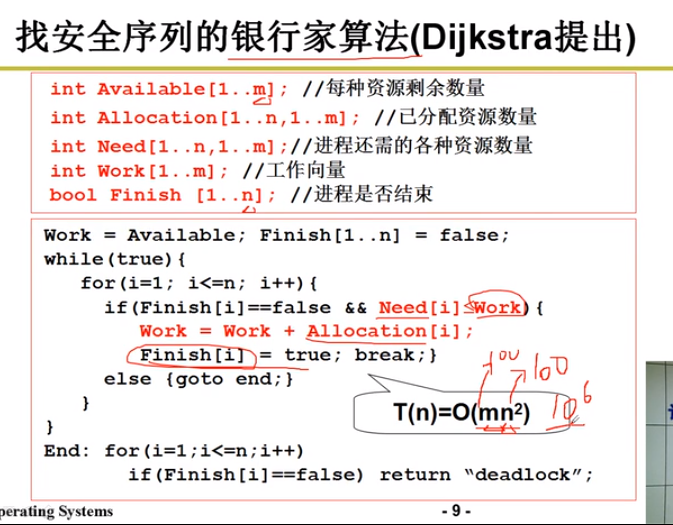
死锁检测+恢复:检测到死锁出现时,让一些进程回滚,让出资源
每次申请执行检查安全序列,效率低.发现问题再处理
死锁忽略:忽略死锁
内存使用和分段
首先让程序进入内存
-> 重定位:修改程序中的地址(相对地址/逻辑地址)
什么时候完成重定位?
编译时 - 嵌入式系统地址不变静态编译
载入时 - 动态修改逻辑地址,更加灵活
程序载入后还需要移动
一个重要概念:交换(swap)
内存 <-> 磁盘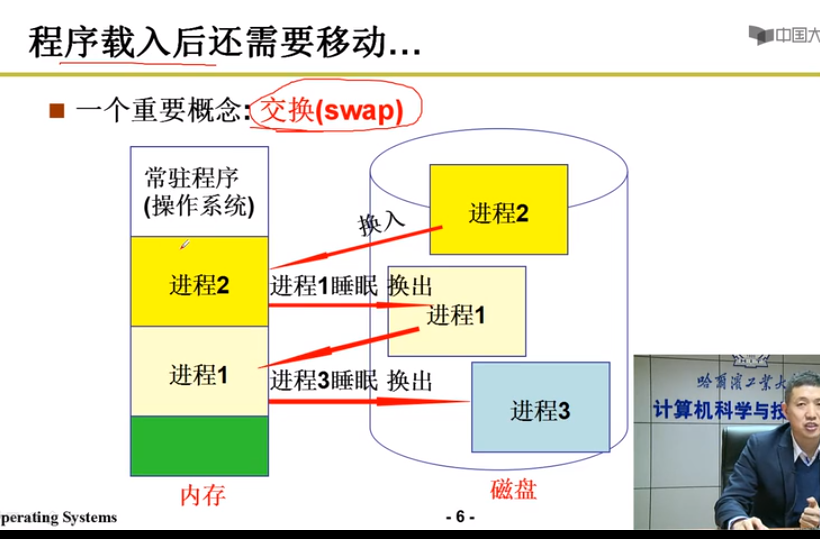
运行时重定位/地址翻译
在运行每条指令时才完成重定位
程序描述信息/基地址 存在PCB中 地址 = base+offset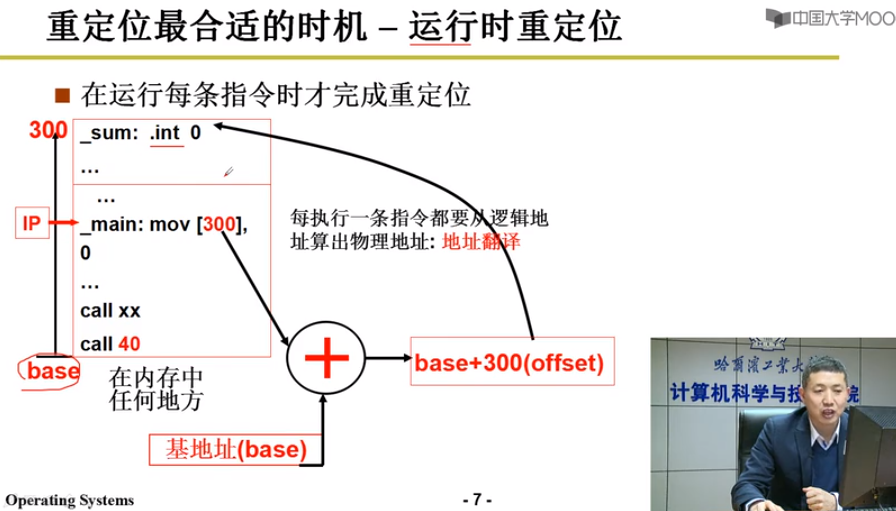
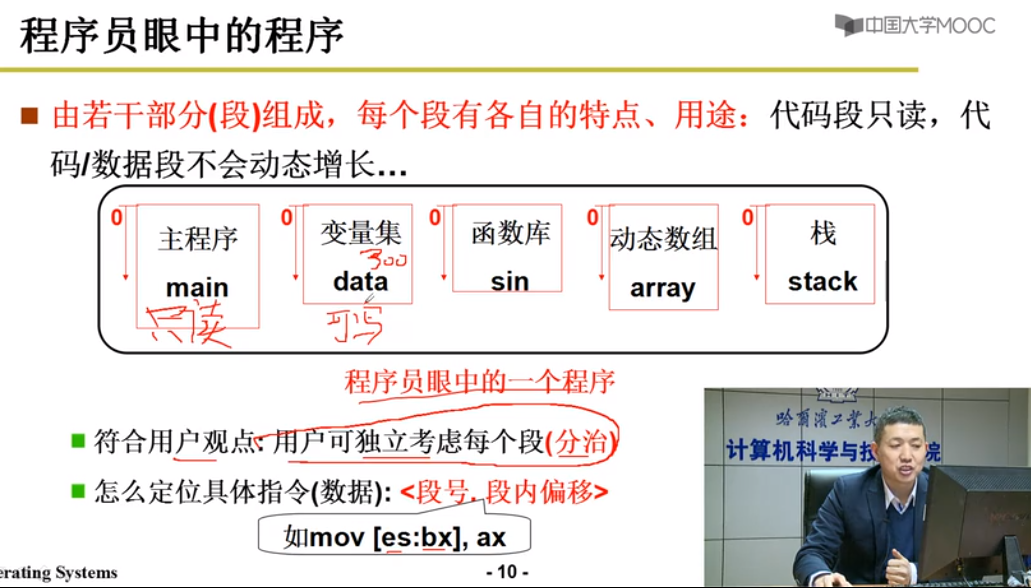
内存分段
程序内存由若干部分(段)组成,每个段有各自的特点,用途
代码只读,代码/数据段不会动态增长
可独立考虑每个段(分治)
定位 段号[段内偏移] [ds:offset]
段表
OS段表 = GDT段表寄存器 jmpi 0,8
每个进程段表 = LDT段表寄存器
存储段号,基址,长度,权限保护
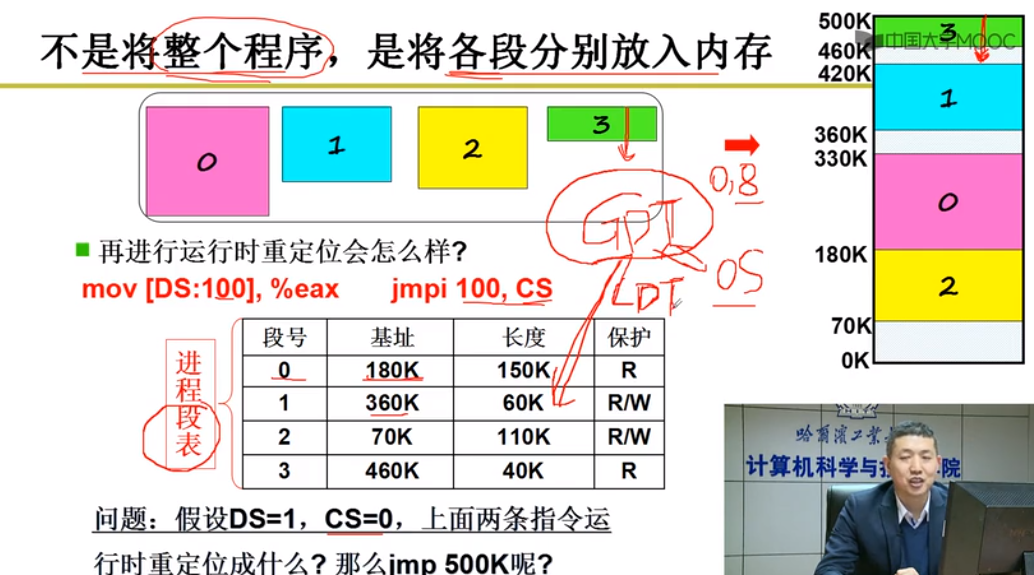 内存分区与分页
内存分区与分页
段 - 内存怎么割?
固定分区 与 可变分区
固定分区:切分固定大小区域使用
可变分区:不固定分区切割
可变分区数据结构 - 空闲分区表/已分配分区表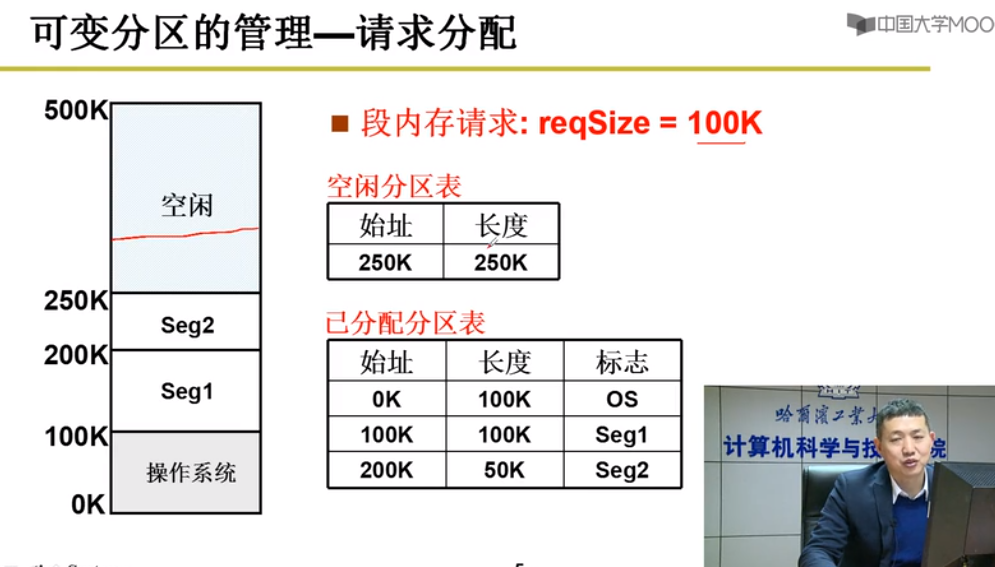
首先适配:找到第一个适合的空间大小适配
最佳适配:找到最合适空间大小适配
最差适配:找到最大的空间大小适配
引入分页:解决物理内存分区导致的内存效率
内存碎片问题 -> 内存紧缩
针对每个段的请求,系统一页一页的分配给段
mem_map 分页表

多级页表与快表
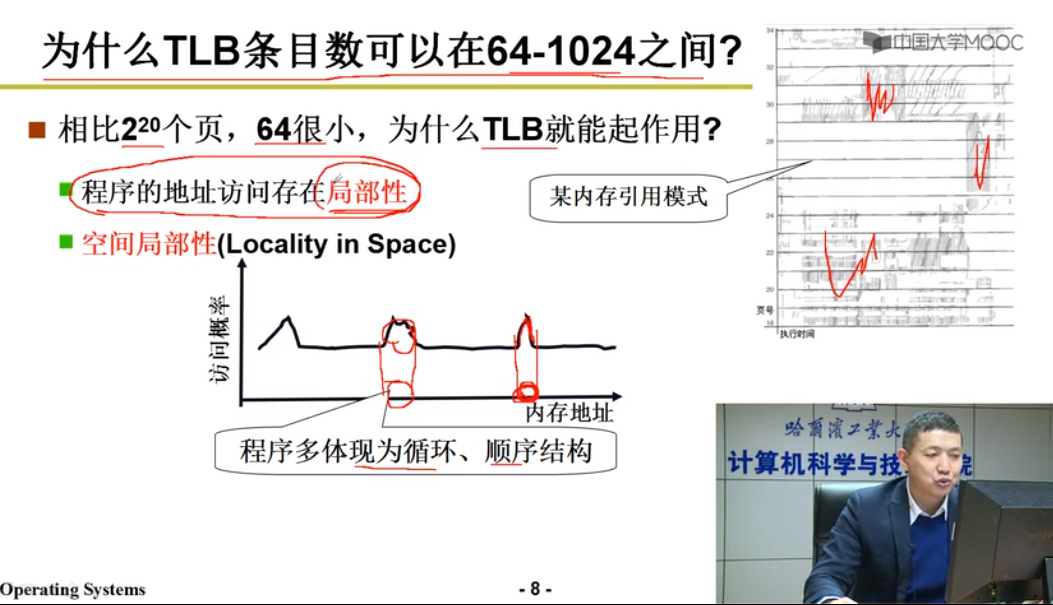
为了提高内存空间利用率,页应该小 => 页表项增加
1.只存放用到的页 [淘汰]
需要比较,查找,折半 => 效率慢
2.多级页表 [空间换时间]
一级页表[二级页表:页号:offset]
即使用页表的页表项
一级
->二级v1
->三级v1
->二级v2
->三级v2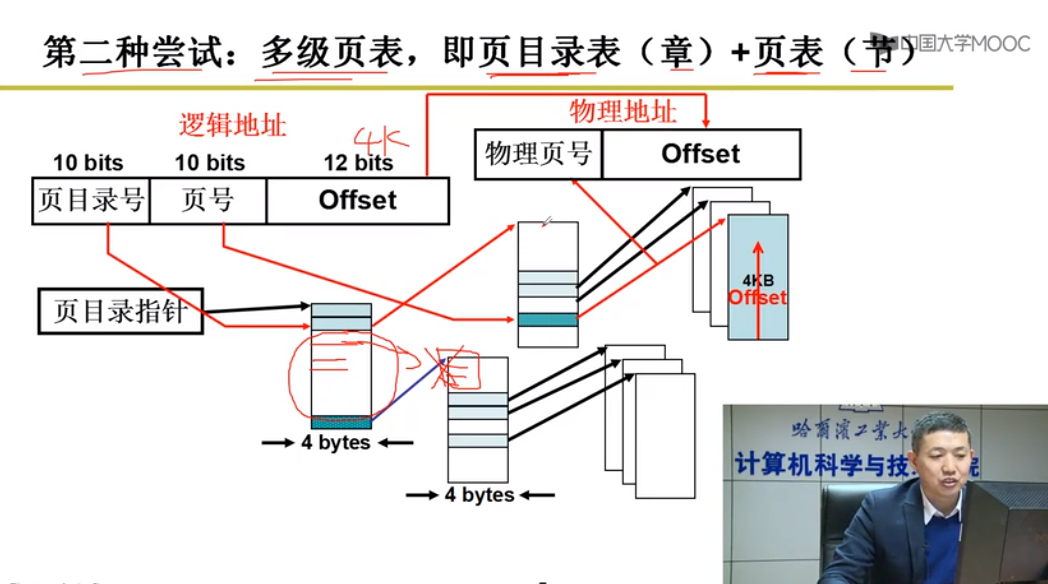
3.快表 [空间换时间]
TBL是一组项链快速存储,是寄存器
一次比对直接找到物理页号
有效时间 = HitR(TBL+MA) + (1-HitR)(TBL+2MA)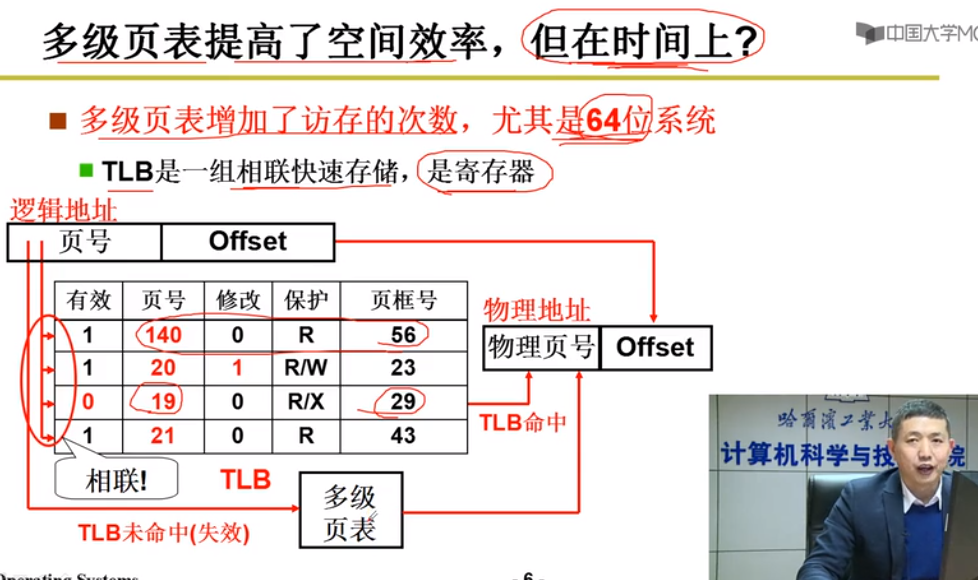
段页结合的实际内存管理
程序员:段->物理内存
物理内存:页->物理内存
解决方案:段 -> 虚拟内存 -> 物理内存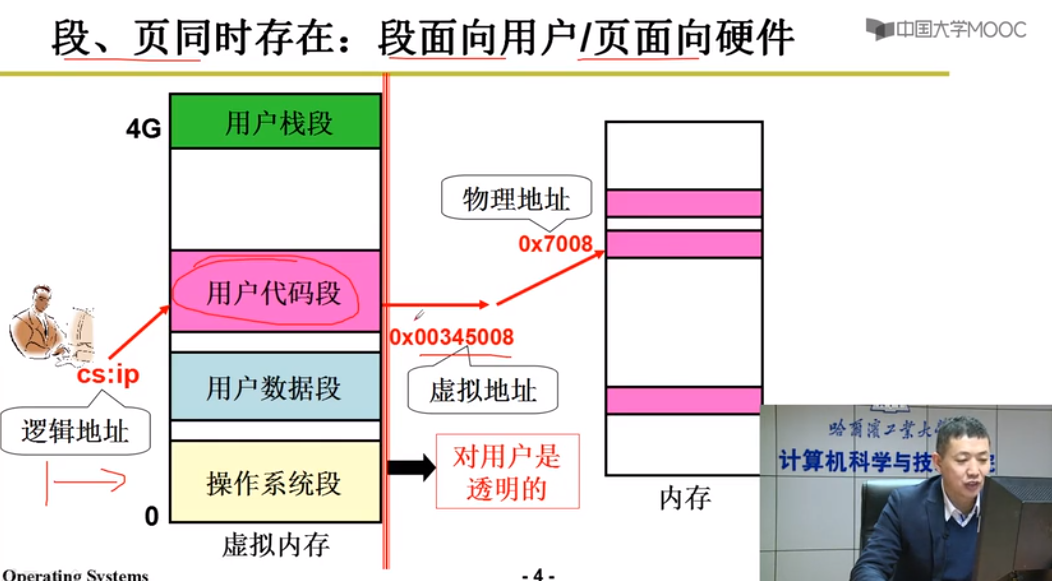
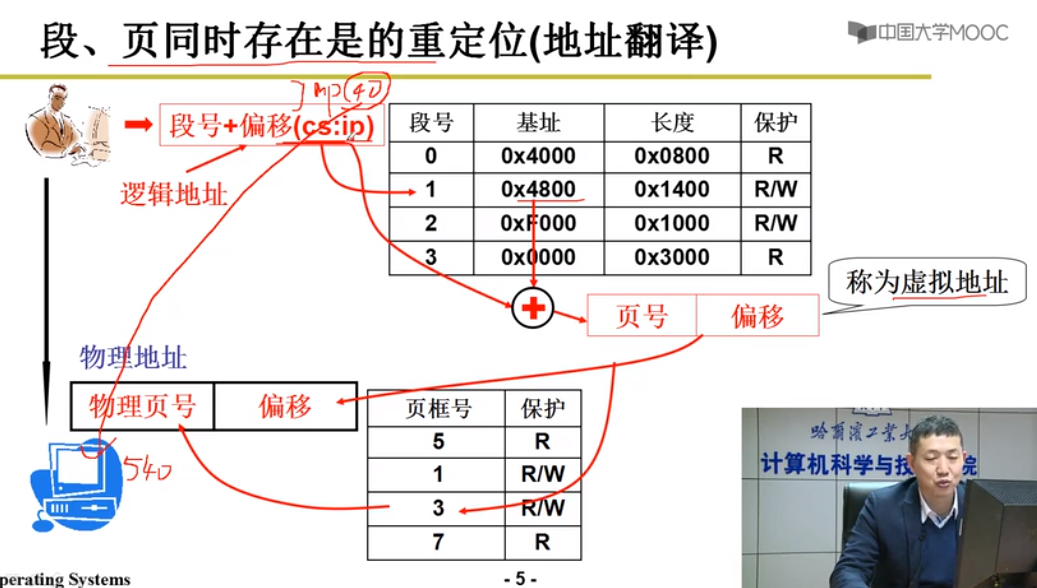
段,页同时存在的重定位
逻辑地址根据段号+偏移(cs:ip)
->找到虚拟地址(分段)
->根据虚拟地址算出页号根据偏移(分页)得到物理地址
 代码步骤
代码步骤
1.虚拟内存中分割代码段
new_data_base = nr0x4000000;// 64M虚拟地址空间,互不重叠
2.建立段表
set_base(p->ldt[1],new_data_base);// 虚拟内存基址赋给段表
3.物理内存中找一个空闲页
// 父进程已经建立
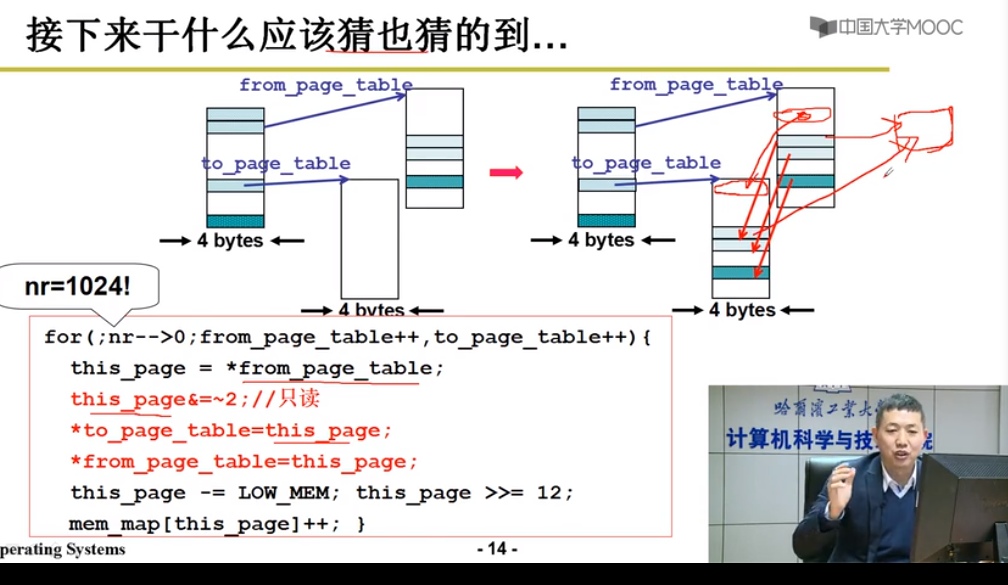
4.建立页表
copy_page_tables(old_data_base,new_data_base,data_limit);// 根据虚拟内存基址copy
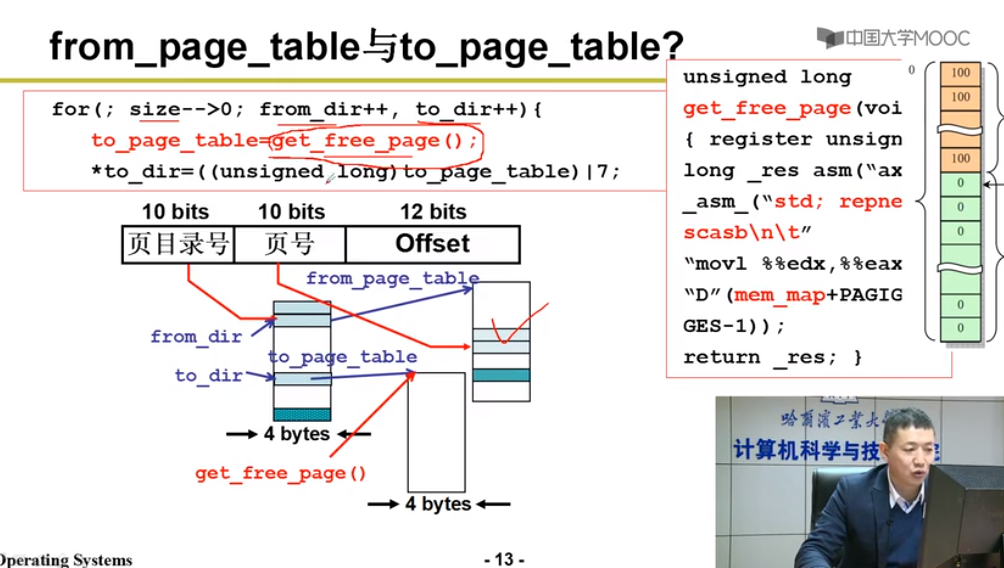
from_dir = (unsigned long )((from>>20&0xffc);// 32虚拟地址左移20位*4 = 10bits 页目录号
to_page_table = get_free_page(); // 获取空闲页表
5.重定位使用内存
只要段表和页表弄好,执行指令时MMU(内存管理单元)自动完成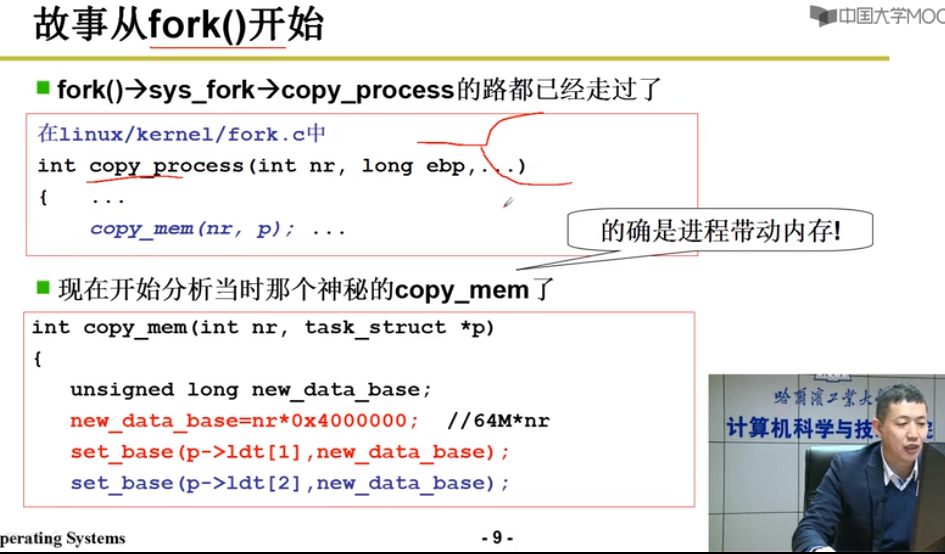
内存换入与换出
swap in 换入
逻辑访问虚拟内存p(=0G-1G)时,将这部分映射到物理内存
再访问p(=3G-4G)时,再映射这一部分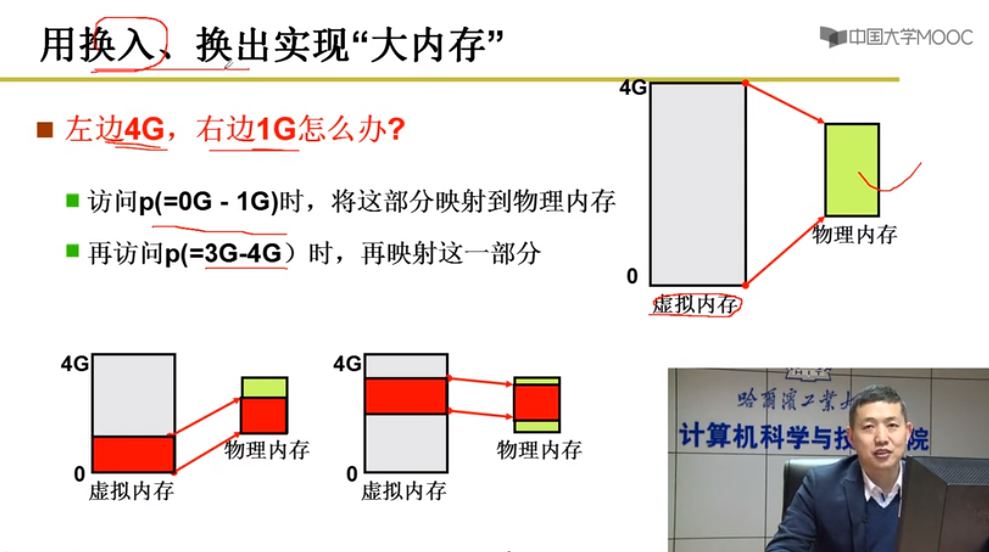
请求调页
MMU查找页表没查到,页错误处理程序(中断)去磁盘查找页,放入物理内存
->trap_init(void){set_trap_gate(14,&page_fault);}// 初始化缺页中断
->page_fault{movl %cr2, %edx}// 错误码压栈,压栈页错误线性地址参数
->do_no_page(){ get_free_page()//得到物理空闲页
bread_page()// 磁盘读入一个页
put_page// 建立映射}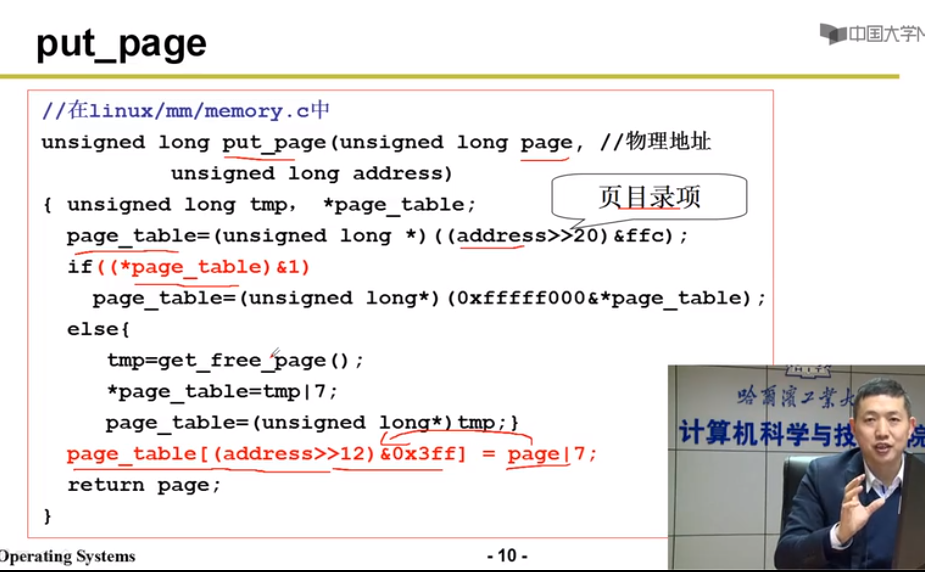
sawp out 换出
get_free_page 并不能总是获得新的页,内存时有限的
FIFO算法
先入先出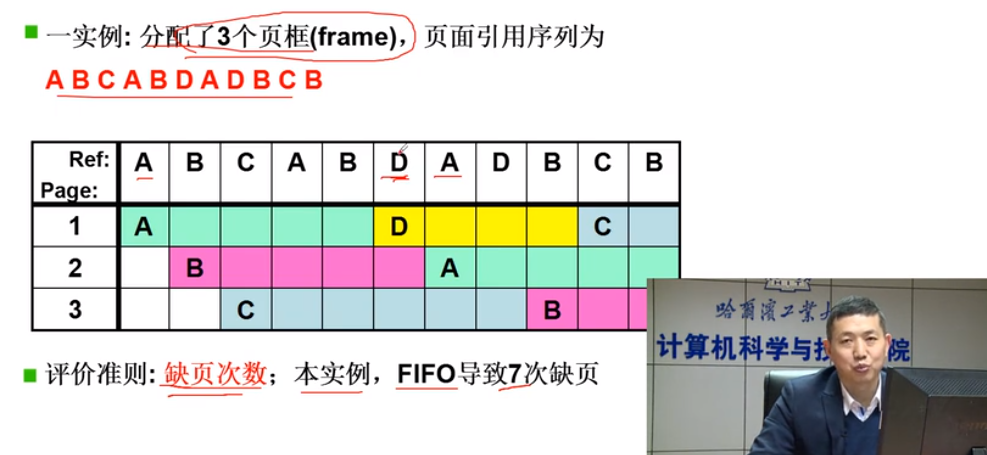
MIN算法
将选最远将使用的页淘汰,是最优方案
需要知道将来发生的置换,无法使用
LRU算法
用过去的历史预测将来,选最近最长一段时间没有使用的页淘汰(最近最少使用)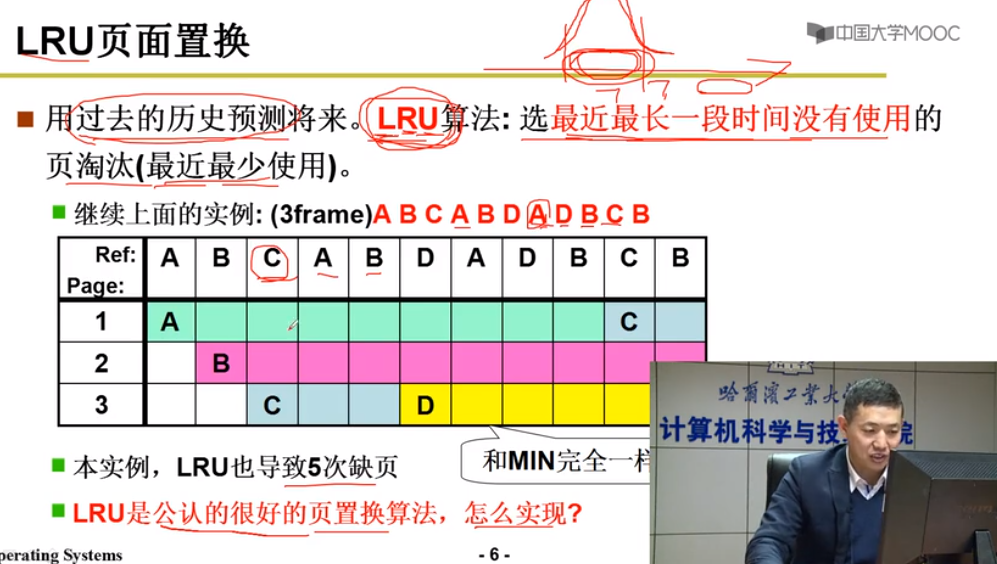
怎么实现?
1.每页维护一个时间戳
维护需要成本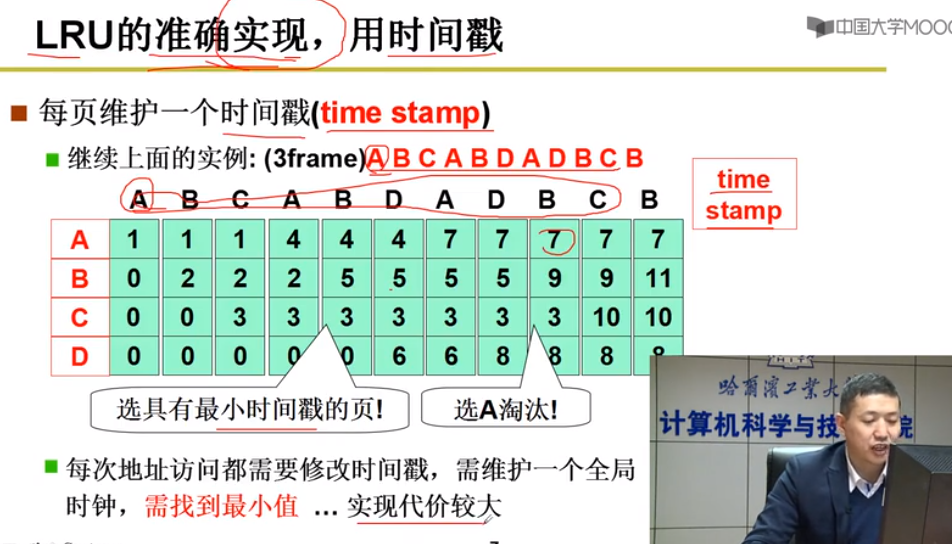
2.用页面栈
每次地址访问都需要修改栈
LRU近似实现SCR(CLOCK) - 将时间计数变为是和否
每个页加一个引用位
每次访问一页,硬件自动设置该位
选择淘汰页:扫描改位,是1时清0,并继续扫描;是0时淘汰该页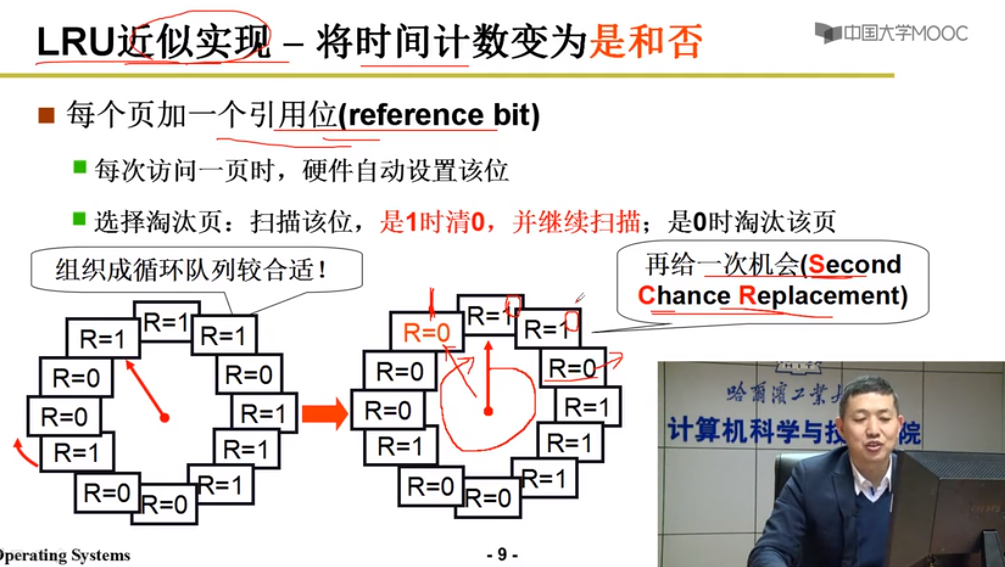
缺页很少 - 退化FIFO => 定时清除R位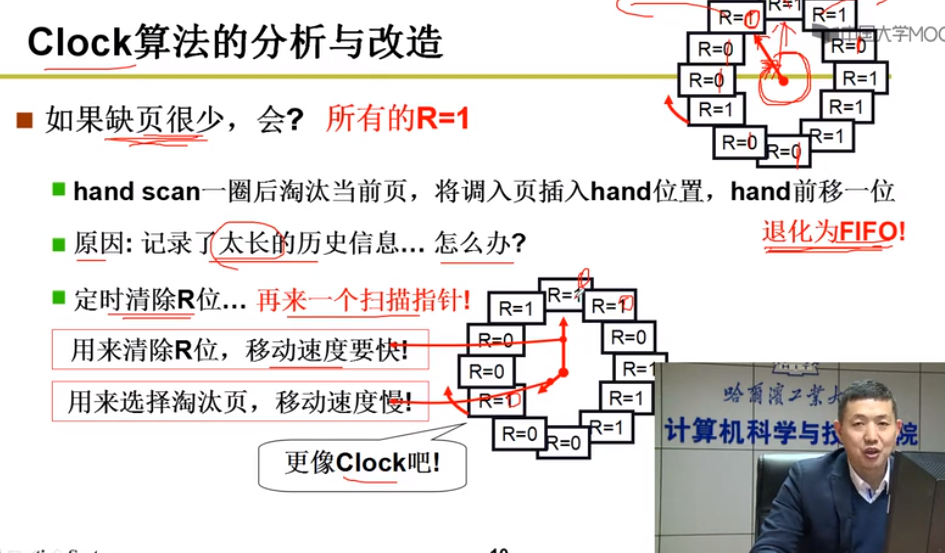
给进程分配多少页框(帧frame)?
工作集算法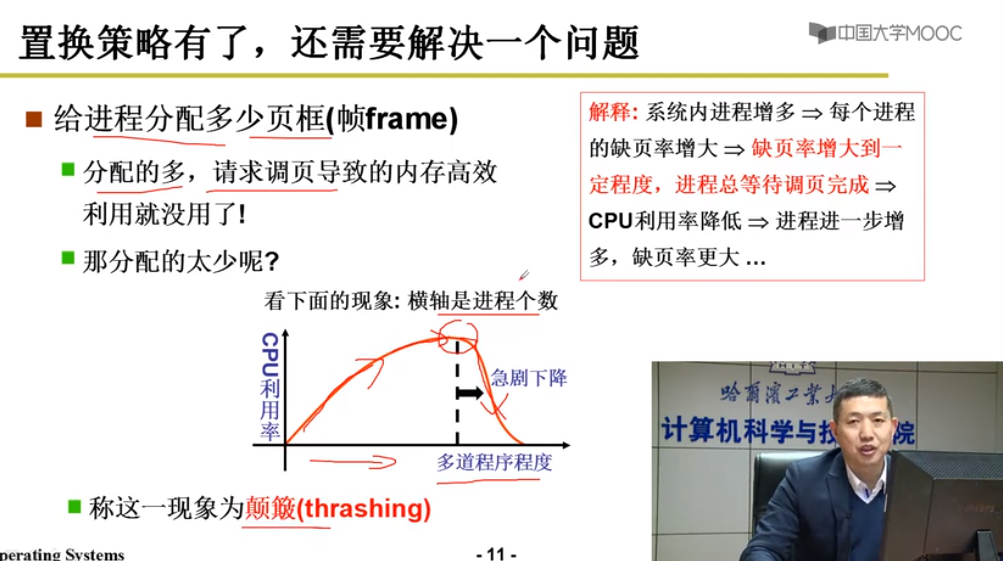
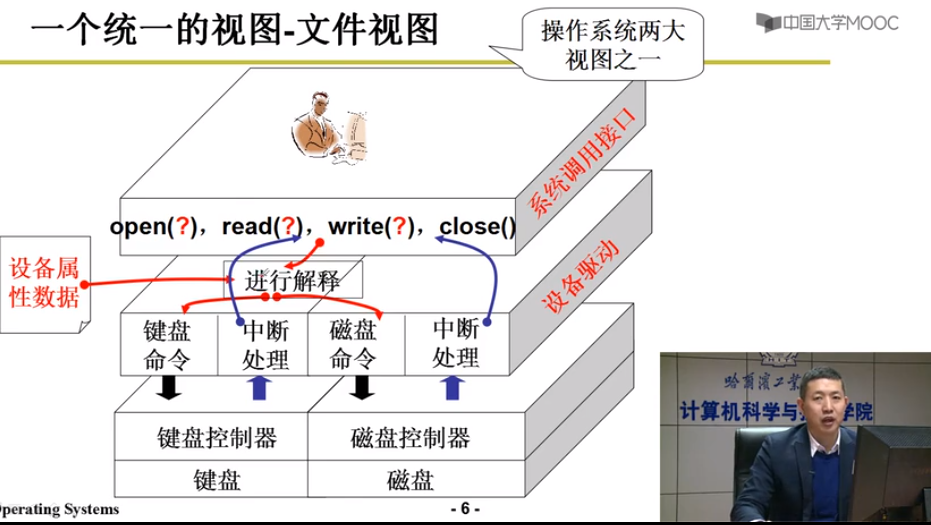
I/O
CPU通过总线发出命令调用外设I/O设备
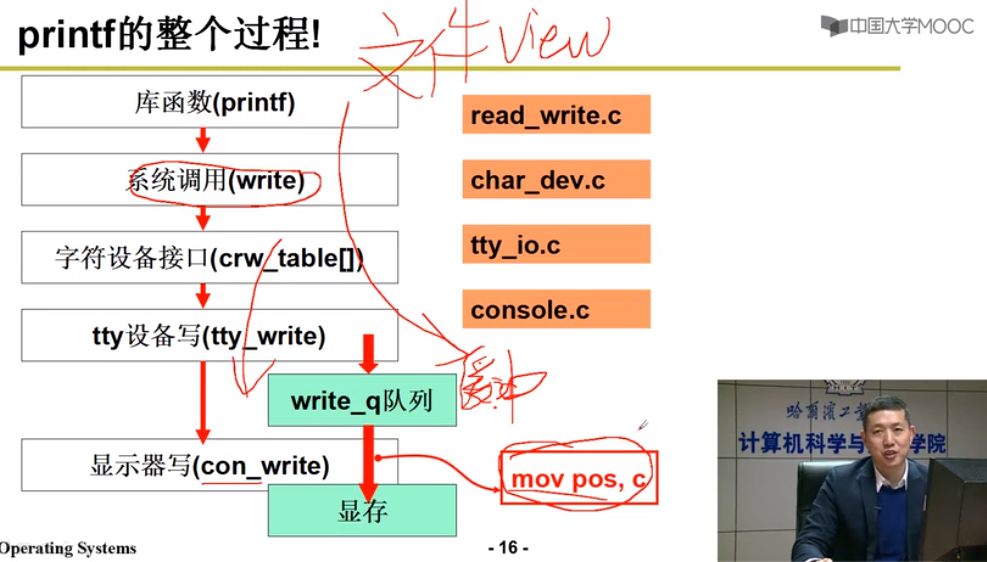
外设执行out指令,工作完进行中断处理,使用外设变得简单 - 文件视图
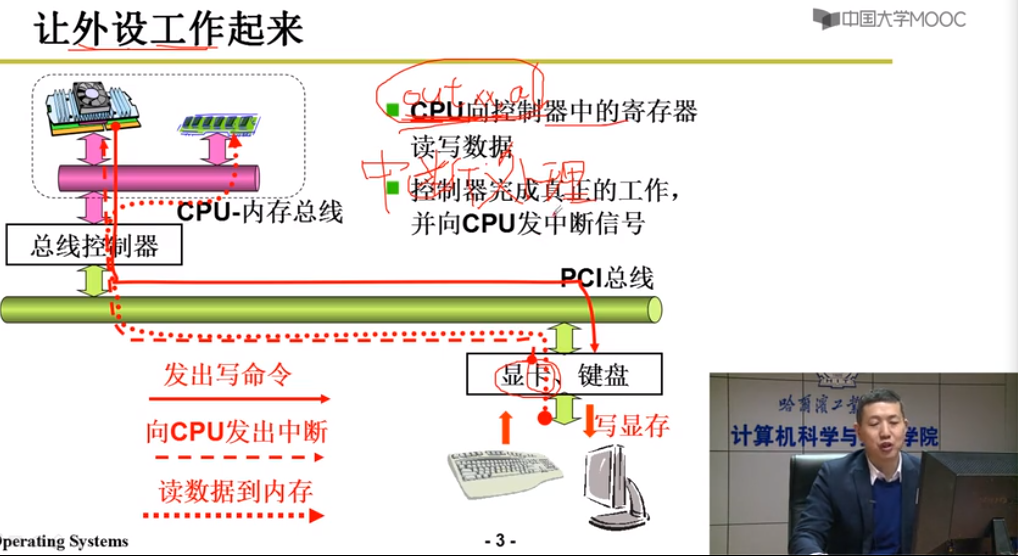
流程
生磁盘
磁盘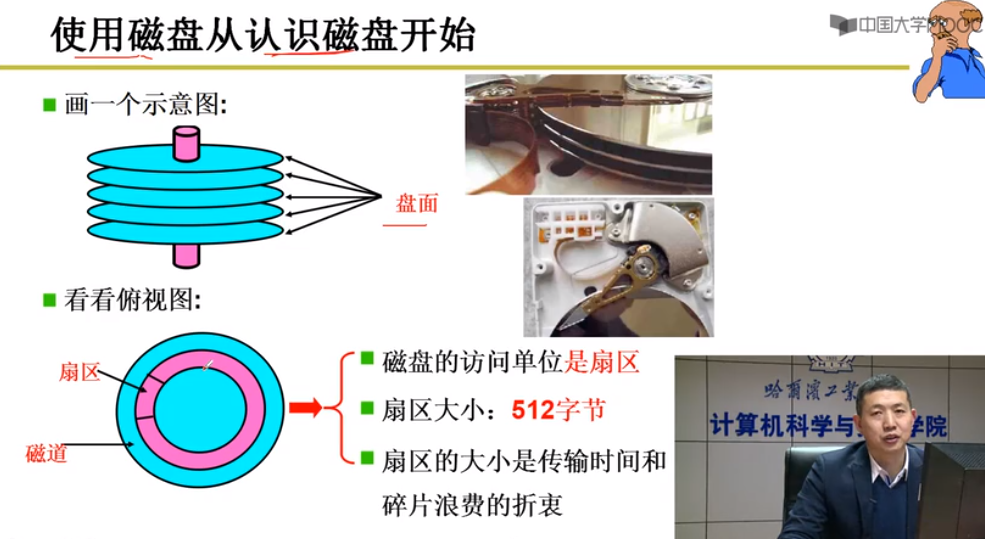
磁盘的I/O过程
控制器->寻道->旋转->数据传输
1.移动磁头到相应的磁盘上
2.旋转磁盘到相应的扇区
3.进行读(磁生电)写(电生磁)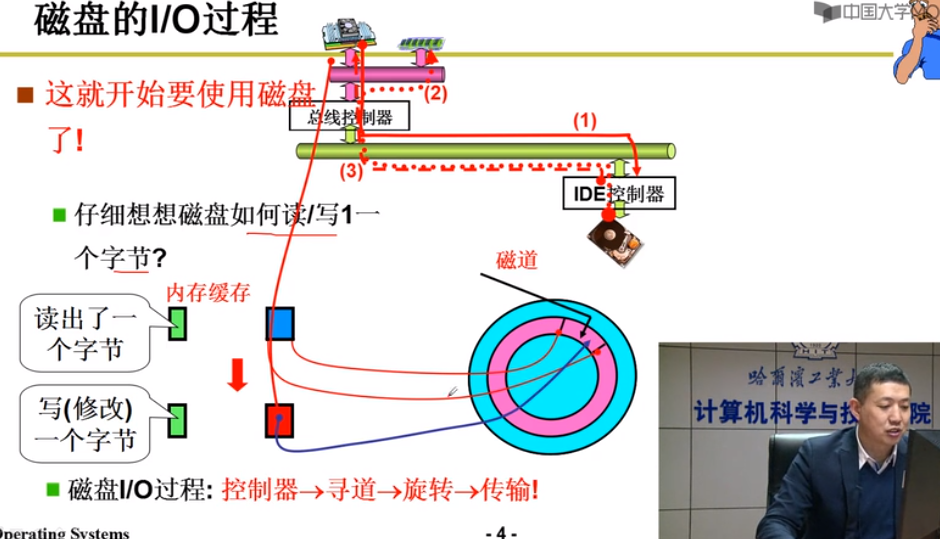
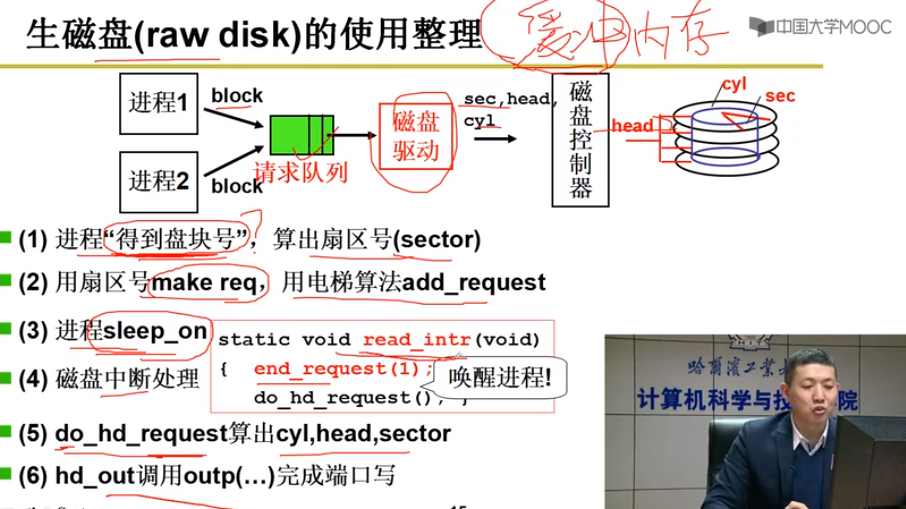
直接使用磁盘
只要往控制器中写入柱面cyl,磁头head,扇区sec, 缓存cache位置
通过盘块号读写磁盘(一层抽象) = 一次读取多个扇区
磁盘驱动负责从block计算出柱面,磁头,扇区 CHS
block相邻的盘块可以快速读出 => 扇区相邻
磁盘访问时间 = 写入控制器时间 + 寻道时间 + 旋转时间 + 传输时间
block = 柱面 磁头数 扇区 + 磁头数 * 扇区数 + s
block % sectors = s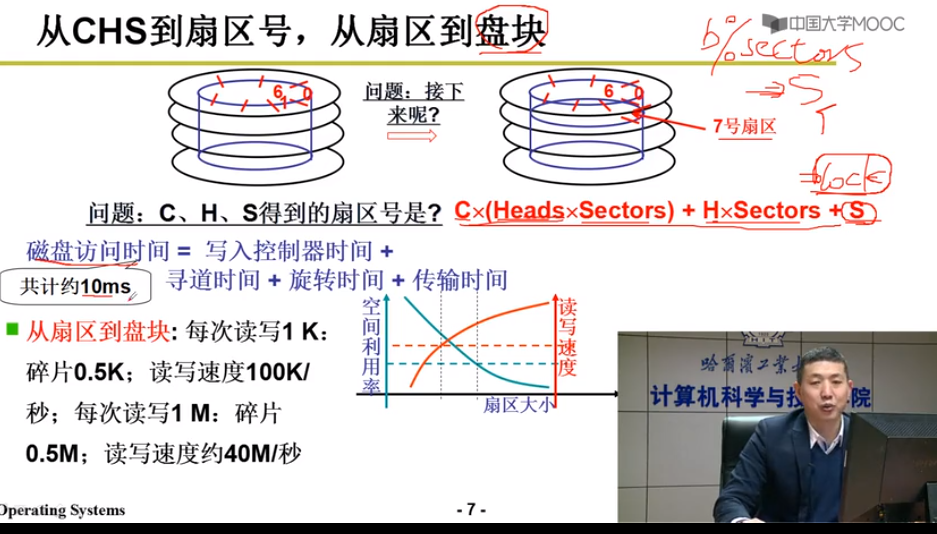
多个进程通过队列使用磁盘(第二层抽象)
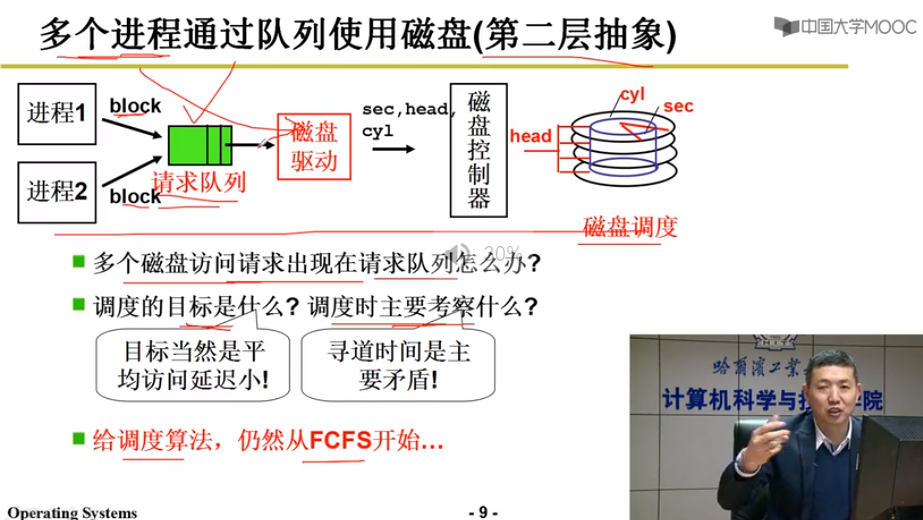
队列调度算法
FCFS 先来先服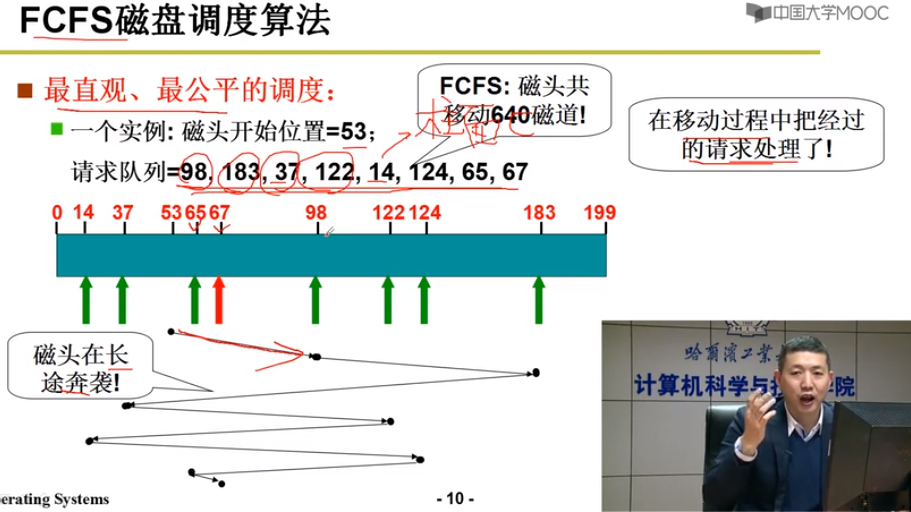
SSTF 短寻道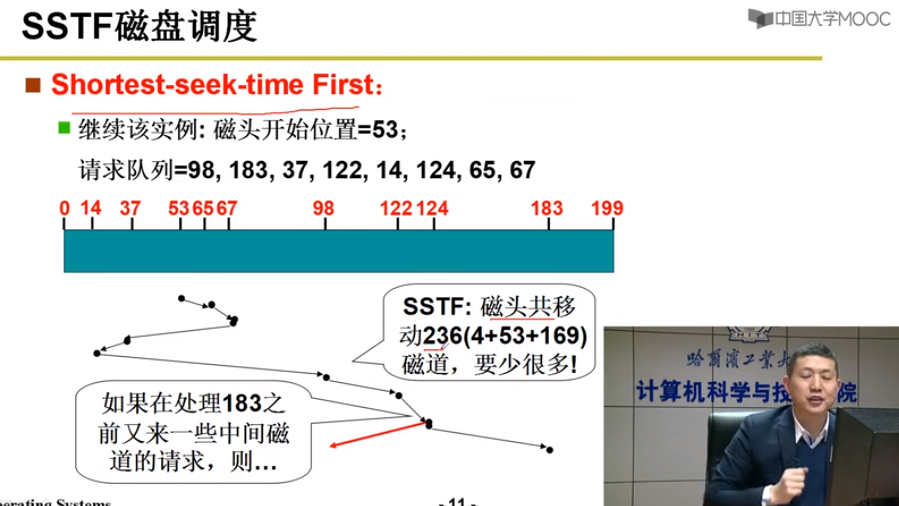
SSTF存在饥饿问题
SCAN 扫描调度 - SSTF中途不回折
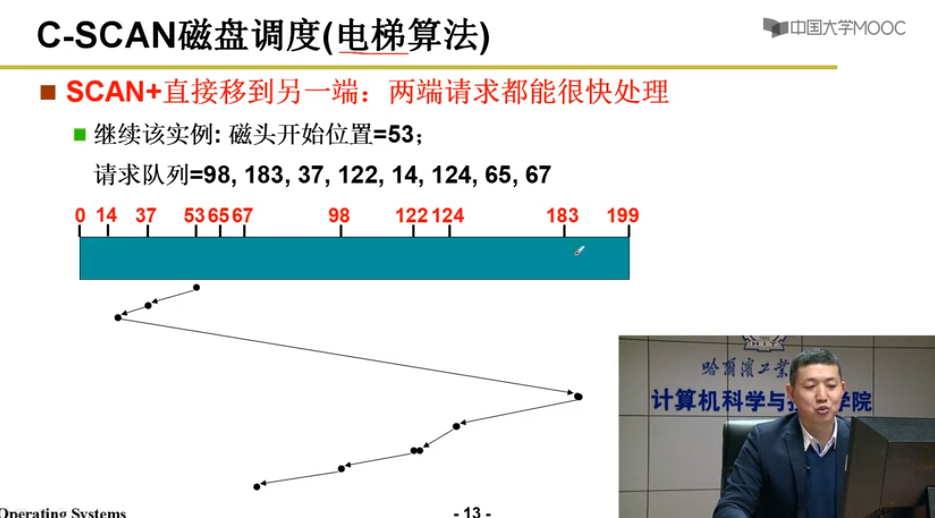
使用整理
熟磁盘(从生磁盘到文件,第三层抽象)
连续结构来实现文件 - 读写快,动态慢

链式结构来实现文件 - 读写慢,动态快
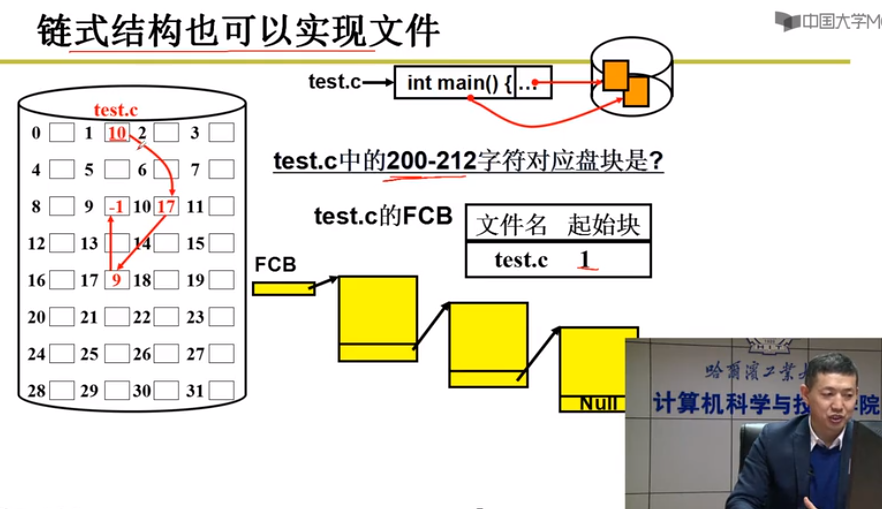
索引结构
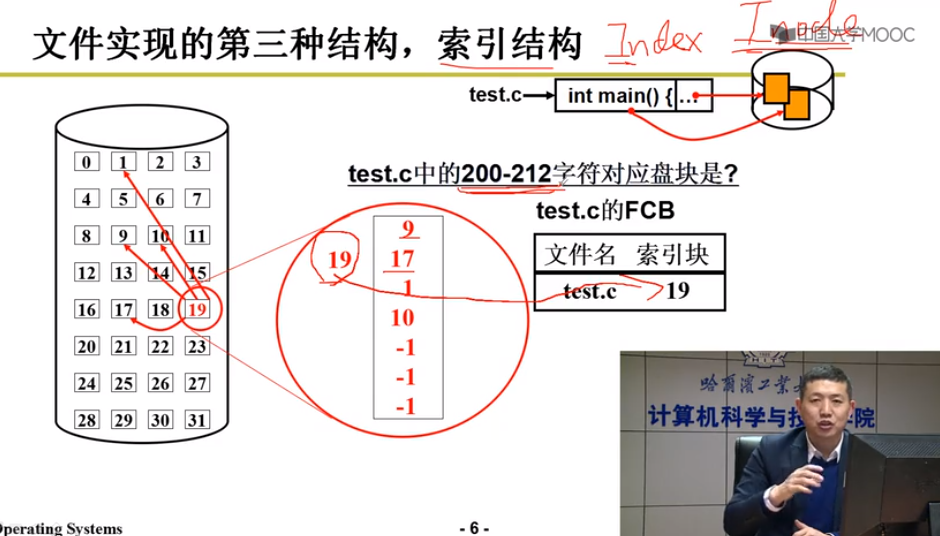
多级索引
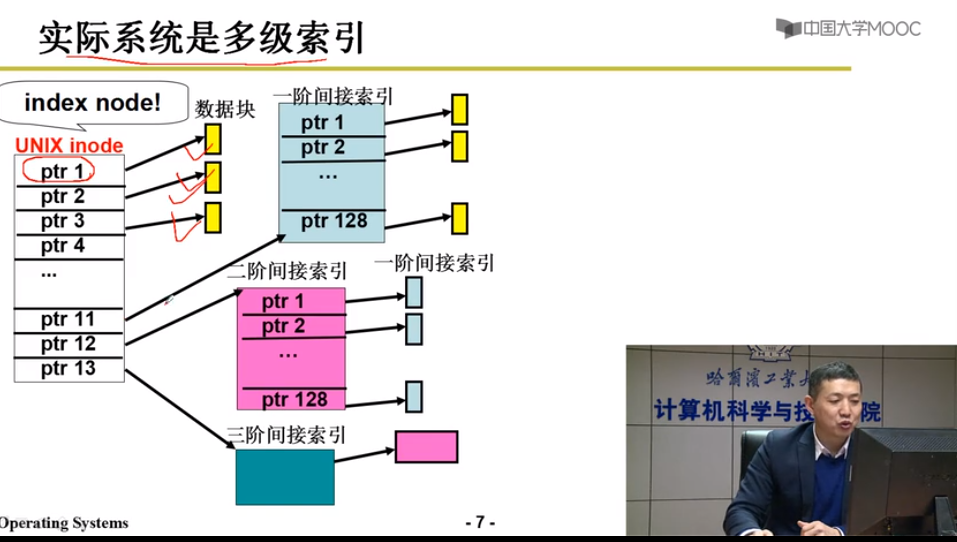
目录与文件系统
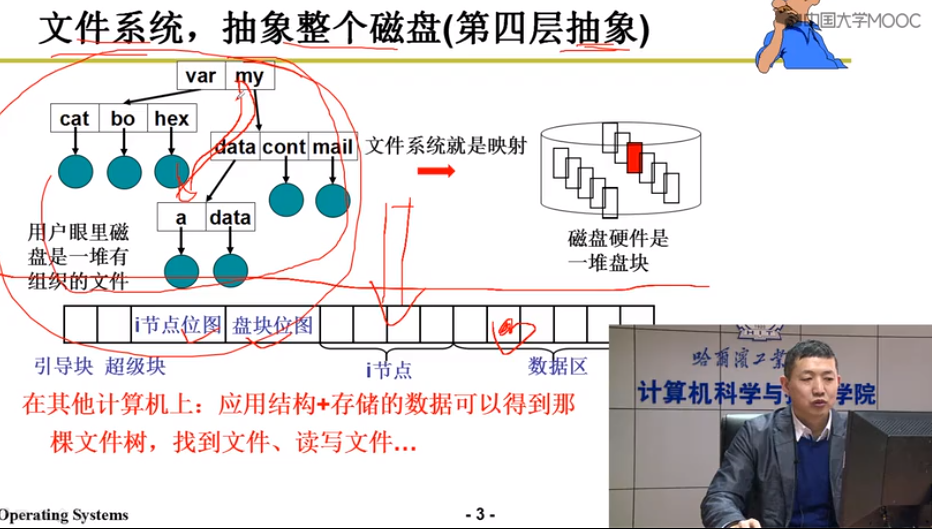
文件系统, 抽象整个磁盘(第四层抽象)
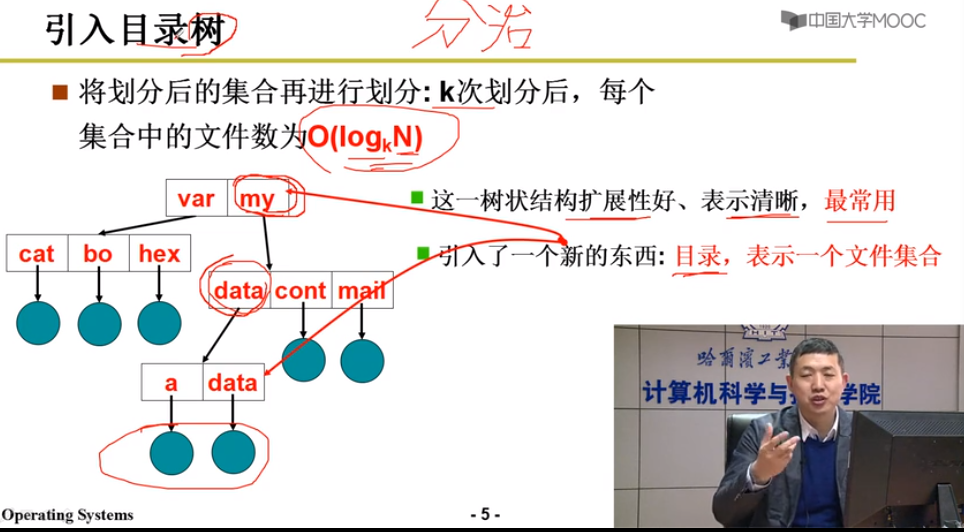
目录树

若有收获,就点个赞吧
0 人点赞
