这个是携程的PaaS平台。七巧板这个图很有意思,把这两块东西改掉以后你会发现,整个东西有点像什么?配置为什么被剥离出去,因为现在大部分互联网公司,配置管理都变成了统一配置,有配置中心,不再采用配置文件或者让SCM帮你管理环境上的配置的方式。
这样变迁以后就是一个PaaS平台。最终你会发现,你要做持续交付、要做工程效能,最后可能做着做着就是一套完整的对公司内部的私有云或者内部的PaaS平台
一、代码管理
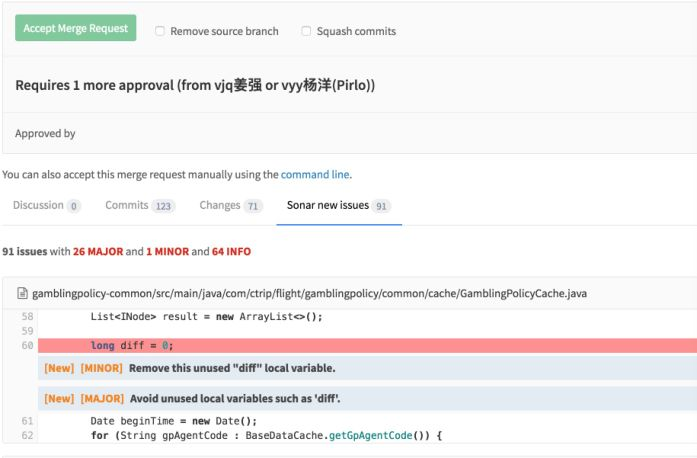
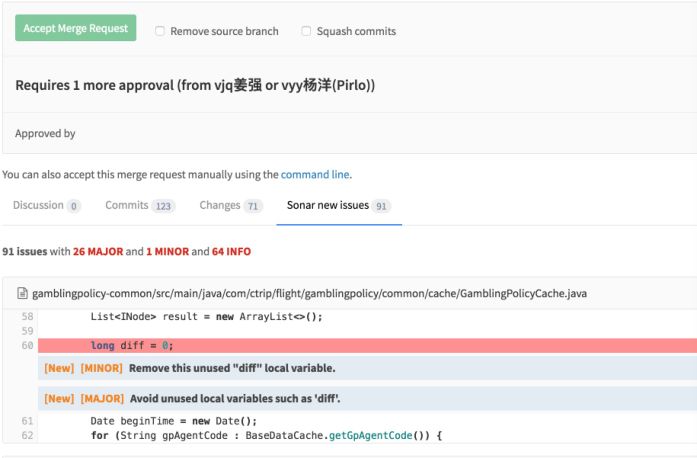
携程是一个标准化的往微服务走的方式,所以我们的代码仓库都很小,每个应用的代码能解耦的一定要解耦,用代码包管理的方式和包依赖的方式来解决最后集成的问题。因此每个仓库都不会很大,编译的速度以java为例平均一个项目一次编译是40秒。
二、集成构建
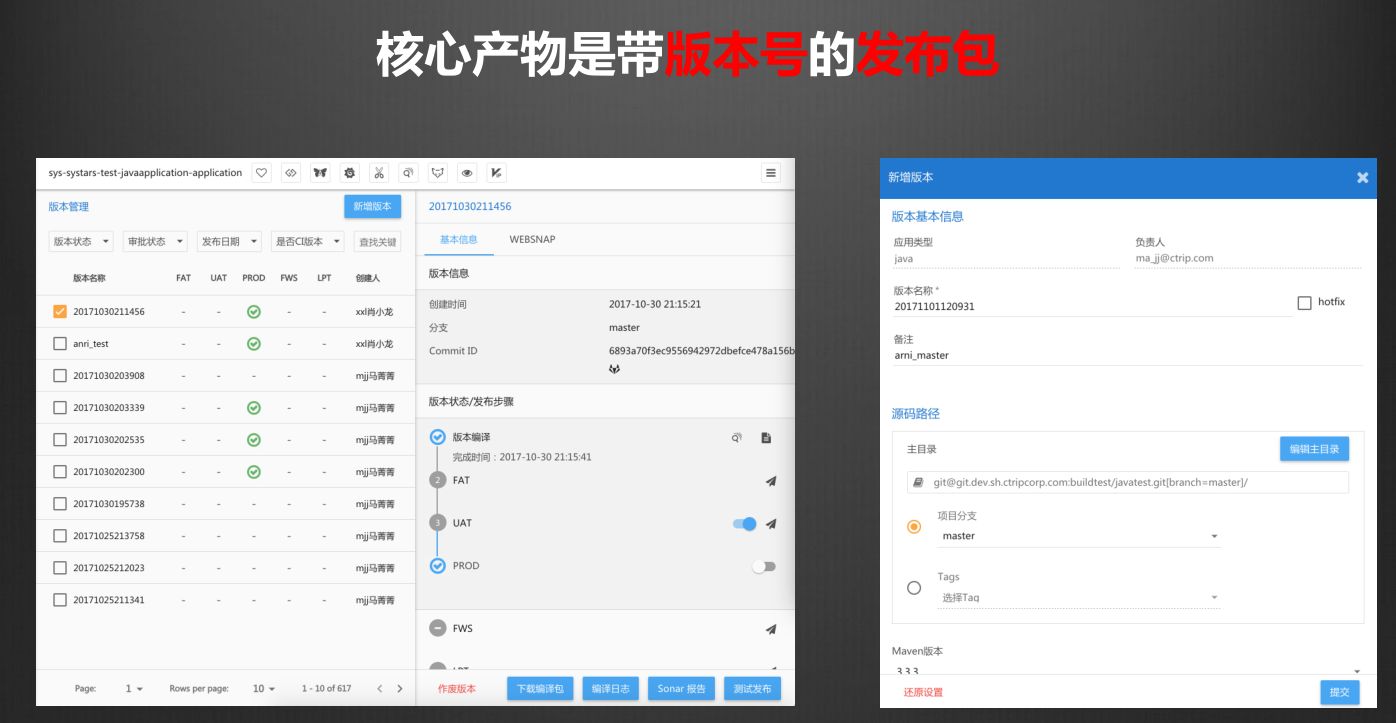
核心的概念是每一个编译其实都会产生一个带有唯一版本号的发布包。这是在携程做的事情,所以你去看带版本号的发布包是我们的最终产物。
这个平台上可以看到我们整个这一个应用,其所有历史版本的变迁,包括在每个环境上部署的情况,包括一些测试是否通过的数据。基本上编译就这么简单,没有特别复杂的。
复杂的是后端看不到的编译平台,我们在Jenkins之上又封装了一层。我们的Jenkins是跑在K8s上的,这是有坑的。
Jenkins本身有Master/Slave的方式,但其又不共享workspace,所有的Docker容器要实时调度,都要做到无状态,但workerspace是有状态的,而且这相当于你的缓存,相当于你提速的机制,在无状态下怎么做到兼容Jenkins有状态,到现在没有特别好的解决方案。
这个在存储方面可能要进行深度的加工,我们暂时现在是用快存储的方式进行共享。所以我们编译是根据你的编译需求,实时弹性产生编译资源的,所以我们会一直保持在40秒的平均水平线上。
这是我们的监控也会一直在追求整个编译的速度是否够快。我们目标是编译的时候不让开发有喝咖啡的时间,连抽烟的时间都没有。
三、灰度发布
在携程,灰度发布有两个概念,
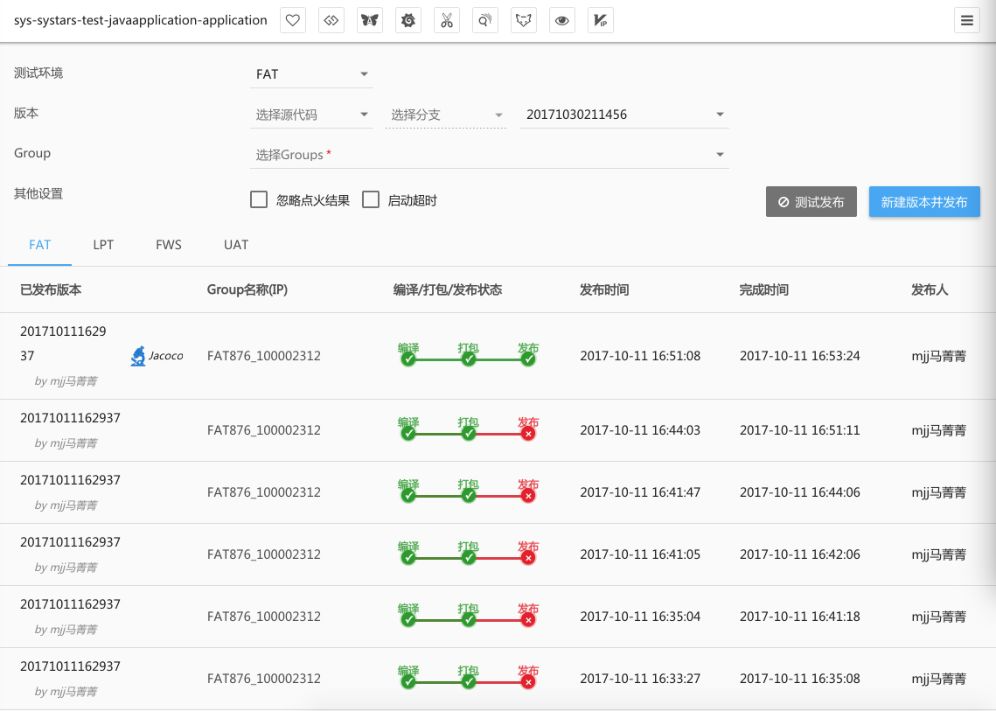
第一个是分环境进行发布测试。
携程有四套环境,第一套叫FAT,是用来跑Feature分支的,就是跑功能的,任何开发都可以往这套环境上部署你的代码,测试你自己的功能。
第二套环境是性能测试环境,主要是测性能的,我们不希望性能测试压力对我们正常持续交付过程产生影响,所以是套独立的环境。
有一套公共环境,我们叫FWS,我们把底层公共的service放在这套环境里面。这个可能涉及到本身服务治理的问题。
服务调用的顺序,首先根据开发配置的地址调用,如果没有配置则优先调用同一个子环境中的服务,如果同一个子环境中也没有这个服务,就调用公共环境中的。如果还有没,首先零级别是调用你配置上的。
最后一套是UAT环境,相当于一套集成的环境,所有携程的应用都会拷贝在UAT环境里面做集成。但这个在几年以前UAT环境被使用的特别多,现在越来越被弱化了。
走到微服务以后,会发现服务和服务之前解耦性很强了,我在功能测试环境测试完成了,在UAT中只要跑一些很简单的公共用例就可以了,不需要再做大量的测试。
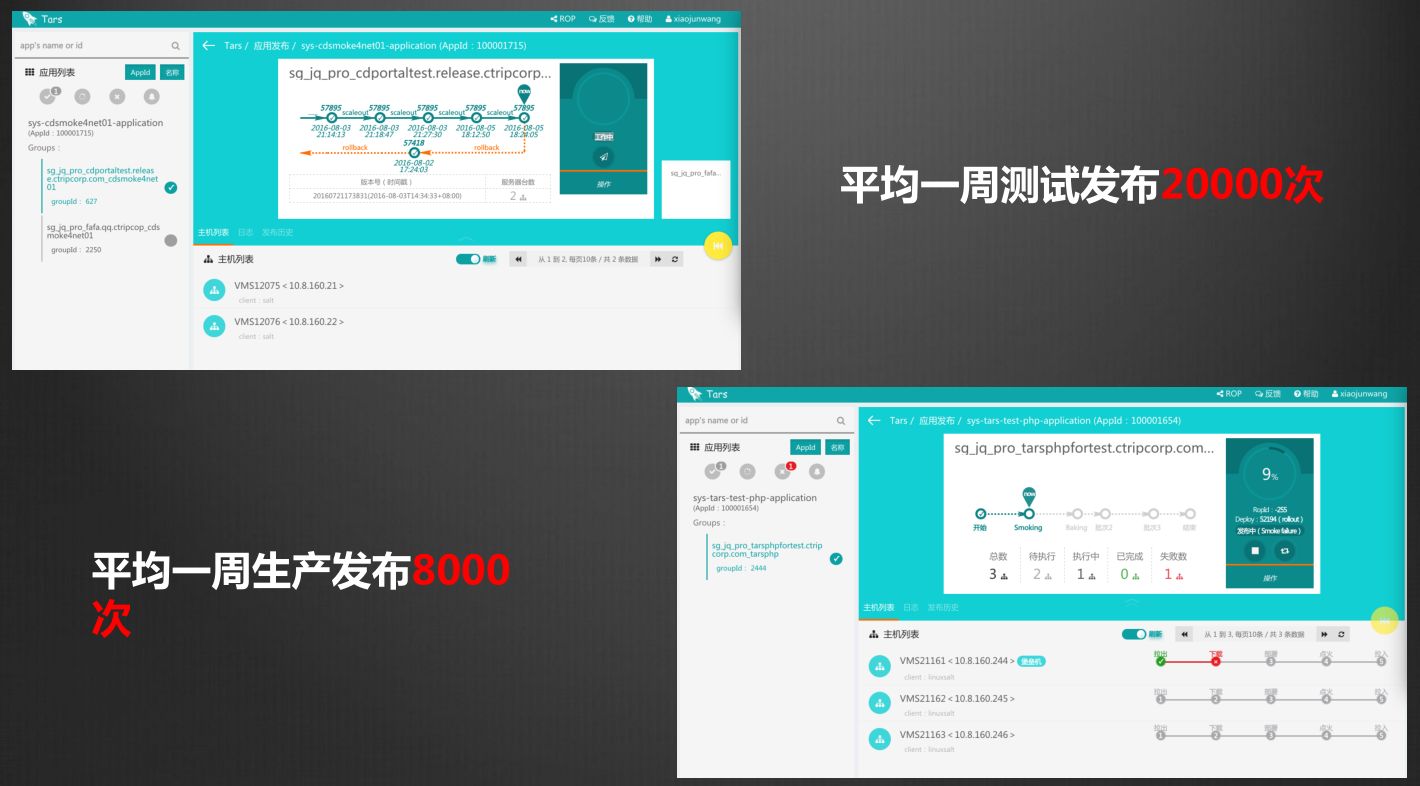
然后是生产环境,生产环境我们有一套独立的发布系统,是灰度发布的系统。
这里有两张图,一张图是未发布时的,版本和历史的情况,包括机器的分组,我们把所有发布最小的单元称之为group。一个group可能包含多台机器,也可能一个应用在多IDC,同一个IDC里面可能会有多个分组的机器,可以根据开发自己定义的分组,进行不同阶段的发布。
每个分组过程中本身也有一个灰度发布,可以控制实时拉出的机器比例,这些流程用户是不能打破的。
我们这边有一些数据,携程每周的发布次数大概是8000次,我们一共有活跃的应用是3000多个。每周生产发布次数是8000次。测试的发布次数是20000多次。
可以看到携程发布效率非常快。这样的好处是任何一个很小的变更就可以进行发布、测试、上线。这样解决了很大的问题:版本冲突没有了,写完就上,谁写的快谁上,没什么冲突。一旦发布解决了问题以后,对你代码也有一定管理推动的作用。
四、资源管理
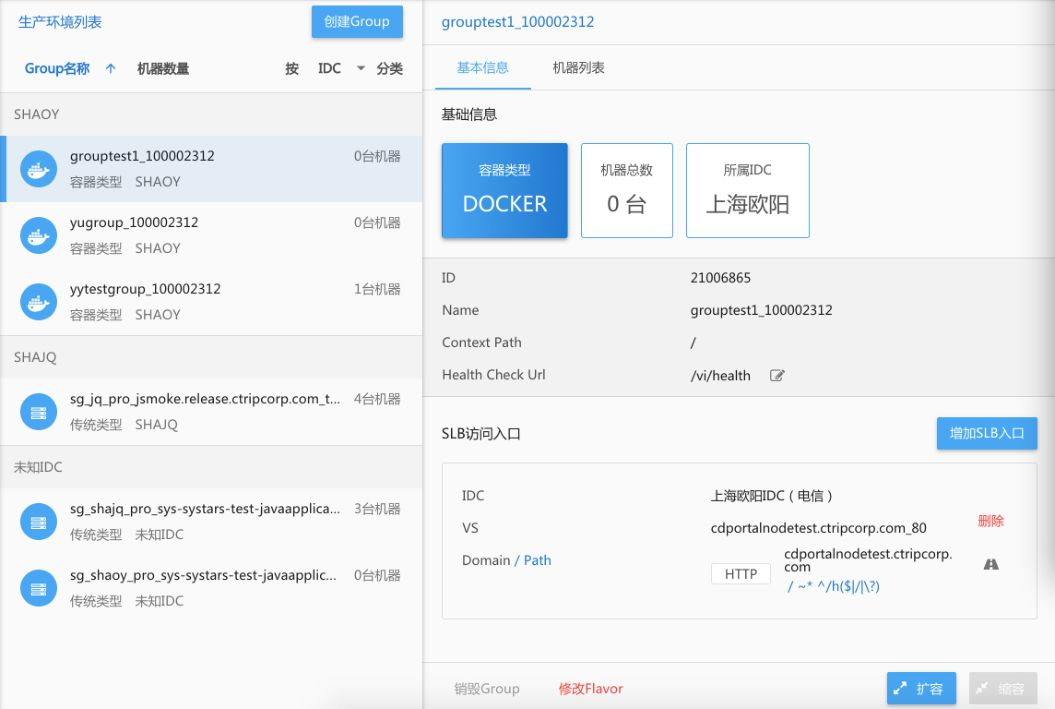
资源管理简单来说就是怎么拿到我的计算资源——机器。这是我们携程拿机器的一个主页面。
可以看到在这个页面上,我们划分了不同的IDC,每个IDC可以申请不同分组,申请不同机器的数量,可以是Docker也可以是虚拟机,甚至还做了云上的。
携程通过这个页面可以直接申请到阿里云或Amazon的机器。然后通过刚才的发布系统将代码包发上去就可以了。Docker我们不是发的代码包,是Docker镜像。
我们Build的过程中是两份产物,一个是可部署的代码包,第二个是可以直接部署的Docker镜像。这样针对终端用户是透明的,他不需要关注我发布的是什么,把代码部署好能跑起来就可以了。
然后在这样的环境下我们甚至是可以在这样页面上处理一些入口的问题,比如说我的域名,我的访问路径都是可以在这里一页解决掉的。右边会有一些不一样,应用每个group的基本信息。
这个是机器的情况,包括现在的版本,机器的发布状态,还可以对机器做一些简单受控的操作。
所以可以看到我们在解决一些什么问题,并不是让OPS去做这些事情,我们是让每个开发小组的开发人员或者测试人员,能够做这样事情角色做这样事情的,这才是刚才我说我们想做的事情是提供工具和提供给开发人员一些武器,让你在受控的时间自己去完成这些事情。
我们统计过申请一台机器,包括完成部署平均是1分钟左右。1分钟就可以拿到想要的东西。
五、测试环境
我们看一下测试环境的问题。对于所有的测试来说,测试环境才是最重要的。自动化测试都是有解决方案的,但测试环境目前没有统一的解决方案。
测试环境最头痛的问题就是一个,一家公司或者说我们公司到底需要多少套测试环境,或者需要多少套独立的测试环境,跟别人隔离的。
影响到我做预算,每年会做预算,明年我的业务怎么增长。要多少套配套。因为我同事并行开发的时候都会受到不隔离的影响,这些事情又是非常痛苦的。
在没有弹性,没有DevOps支撑,没有刚才我所说的资源管理支撑之下,你只能说很固定的做这个事情,每年采购机器,装机器,等着QA来用。最后发现这个项目砍掉了,没有用。我们携程有两个打造测试环境的依据和我们想做的目标。
第一个是我们想打造强大环境的克隆能力,这个克隆能力包含三个部分,第一个是我要版本+资源+发布融为一体。也就是我前面说的几个,集成构建、资源管理,加上灰度发布。
三大能力打造完之后,就会自然形成一种克隆的能力。这个克隆的能力恰恰又是我们现在碰到任何的Jenkins也好、Docker也好都没有办法企及的东西,Docker不解决环境问题。
任何环境工程师碰到Docker都会骂娘,因为实际上Docker在说一个概念就是不变化的部署,希望说产生一个镜像,一个镜像走天下。
但不可能的,你的测试环境跟生产环境一样吗?机器配置一样吗?不一样,网络环境一样吗?不一样。你要测的东西、辅助的工具一样吗?也不一样。
一个镜像走就是让所有环境工程师下岗,他根本没有解决方案,Docker根本没有想过这个问题。
只有当你有了很强大的克隆能力之后,你才可以解决这些问题,Docker一个镜像可以快速部署,但整个环境没有办法帮你部署的。他只能帮你部署起应用实例。
还有一个更讨厌的东西就是DB。微服务的解耦,所有的解耦到最后都会碰到一个核心的问题,就是DB是解耦不了,数据是耦合的。测试的时候没有办法脱离。
比如说最简单的问题,我是测试机票购买的,但我脱离不了用户数据,我必须得有用户数据才能测我的购买,否则怎么测。
所以就会变成我需要多少套完整DB的问题,携程的解决方案是我们对每套DB要求建立一套基准库,就是可测的,包含最少可测的数据结构、数据记录的基准库。用于被不同的子环境、测试环境克隆。
第二个就是刚才说到的,所有的服务要有非常清晰的路由控制能力。携程的RPC服务,是基于http协议的,做起来会比较简单,但是你只要有服务治理的系统,都是比较容易做到根据用户的需求来指定我要调用哪里的服务。
有时候一套子环境是不能充分支持你的测试的,必须要跨出子环境,调用别人的服务。这个必须是受控的,这个不被控制的话,你会发现你的环境没有办法做到隔离。
既使是你做到了隔离,你会发现被隔的太严重了,在一个孤岛上,没有办法跟别人进行互通。
所以你就在隔离孤岛和完全互通的概念中,形成一定的平衡,也就是有完整的路由控制能力之后,才能够很好的解决你测试环境的专用独立环境的目标。
六、架构适配
刚才说到的这些东西,多多少少都带出了一些架构适配的东西,包括路由也好,包括Docker整个环境架构。我下面会列一下到底有多少东西,如果架构给到我们支撑,我们持续交付能够很好的做到。
- 标准化。如果一家公司的标准化、技术标准化在架构层面没有办法达到统一,最简单的就是携程前几年这样,各种语言都有。java、.net、php、nodejs什么语言都有,要做持续交付挺难的。所以标准化是一家公司非常重要的在架构层面给到持续交付有力支撑的一点。一定要形成最核心的,不是说不同的语言不能存在,但你一家公司必须要有核心的标准化。比如说你的部署架构是不是有标准化。我代码可以用其他的,但你最后产出的包,例如nodejs有各种部署包,各种不同的启动脚本都可以达到你最后业务起来的需求,但你要标准化,形成一套唯一的标准化。
- 服务通讯。服务发现、服务调用、服务治理之间是否有足够架构的支撑,如果没有很痛苦,你的环境就变的非常痛苦。包括线上治理也会变得非常痛苦。
- 路由体系。有没有比较好的路由体系。
- 配置中心。建议大家把原始跟代码一起发布的配置文件剥离掉,剥离到远程配置中心。这样可以有很多配置灵活性,从架构层面来说也是比较推荐的方式。但我们要把配置划分成两块来看,第一块是我们通常说的业务配置,能够剥离到配置中心。第二个是环境配置,就是挂在我的环境上,或者说挂在我机器上的配置,比如说环境变量。这些必须固定,当你一个环境产生,或者一个机器产生以后这些环境变量不再变化,从他出生什么样就是什么样,除非销毁重来。这是配置中心的一些建议。
- APM。有全链路的监控,我们说你做持续交付,交付以后没有监控的,你也不知道这个产品交付出去好还是不好,一定要把这个补上。
- 其他。还有其他架构层面的支持,微服务、单元化,都是能够很好的帮助我们做到持续交付的。所以你会发现刚才的七巧板里面写的很好,要做持续交付,架构跟不上白扯。
七、组织适配
组织适配我最没有想明白的事。什么人适合做持续交付。很多公司持续交付的团队都是由原来的SCM团队、QA团队转型转过来的,这些人是不是真的适合?在我看来不太适合。
因为他对我所说的架构,应用的运行,不能很好的感知,没有掌握到很多技术核心点。单单从这些组织转过来的,很难最终达到我们想要的持续交付的效果。
这样的情况下必须要有架构团队,应用团队,ops团队合力协作,最终才能完成整个持续交付的过程。八、容器交付标准
容器技术现在比较火热。携程在做的事情,就是容器时代我们怎么做一些持续交付。
第一个是容器带来的非常大的剧变。剧变原因是什么?他把交付的标准改变了,所有人的交付产物变化了,以前大家都说环境这些东西是SCM或者QA团队提供的,现在变成开发一个人独挑。
开发给你一个可部署的镜像,包含环境,包含运行时的任何东西,把所有的标准都颠覆掉了。
举个简单的例子,我们现在很多人在跑Pipeline,是不是有一个开发说我特别牛,我不要这个Pipeline,我本机产一个镜像给你,我告诉你跑在哪些物理机上,或者连物理机是什么和宿主机都不告诉你,直接去跑吧,能跑起来的。
你敢不敢发布?巨大的问号。所以容器这个世界有很多东西是很模糊的,需要慢慢的摸索,也许我们传统的Pipeline方式,工程流的方式有他一定的作用来保证质量,能够提高效率,也许过几年回头看,也不一定。
这里容器我能给大家的分享和建议,至少在携程来看就是所有的平台、工具、应用都要往Cloud Native方式靠拢。什么叫Cloud Native?很难解释。我们现在采用的标准很简单,我一个应用或一个平台,能不能在阿里云马上跑起来,能就是Cloud Native,不能就改造。
最后我引用一句话做为我分享的结束“PaaS平台的能力,直接反应持续交付的能力”

若有收获,就点个赞吧
0 人点赞
