
DevOps产生的价值,我比较认同IBM给出的解释,总共有三点,第一,它认为这个会增强客户的体验。这是比较容易理解的,第二点是提高创新能力,这个不好理解,创新和它有什么关系呢?它的说法是这样的,通过DevOps去实践,通过精益的方法论去减少我们的浪费、返工,将我们现有的价值及精力投入到更有价值的事情,创新是其中的一个非常重要的点。第三个就是更快的实现价值。
DevOps应该是永无止境的,它是一个持续改进的过程,它没有终点,它的目的是对影响交付质量的对象进行持续的改进,包括我们的技术、流程、团队,甚至企业的文化等。
那我们怎么去检验我们的软件交付过程是不是高效的?我个人总结了一个“短”五个“快”。短就是我们交付软件的开发周期要短,快就是排错、解决问题、测试、部署、反馈这个闭环一定要快
Gartner DevOps Model
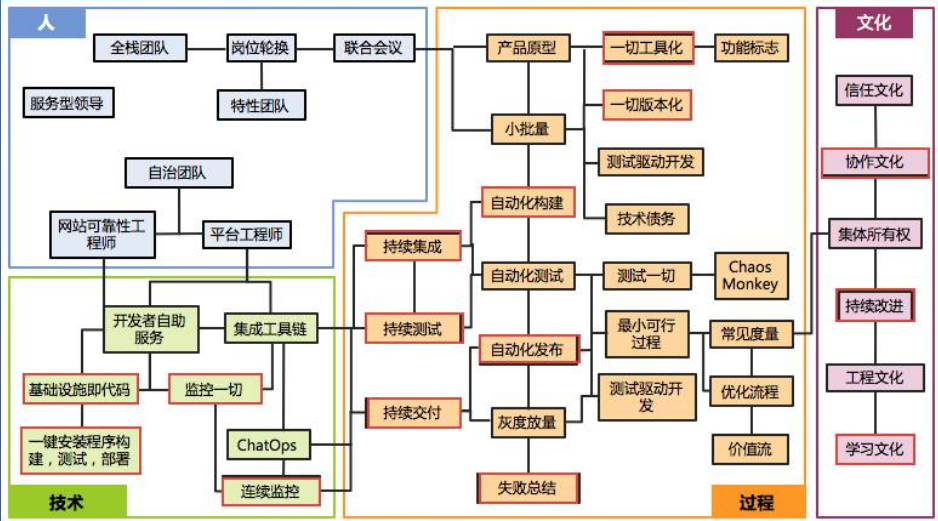
【技术】一个是【基础设施即代码】,第二个是【一键安装程序构建,测试、部署】,第三个是【监控一切】,第四个是【连续监控】。
【过程】应该关注的是【持续集成】、【测序】、【交付】这几个方面,另外还要关注到【自动化的构建】,包括【自动化发布】。我觉得【失败总结】这一点是比较重要的,当我们过程失败之后,必须要知道失败在哪里,要进行总结。另外一个是一切都要工具化,一切都要版本化。除了代码以外,我们的脚本或者是配置文件都要通过版本化进行管理。
在【文化】这部分,比较重要的就是协作的文化,还有持续的改进,还有学习的文化,这三个都不难理解,但是我认为,这里面是不是还遗漏了一点?我觉得少了信息的共享、透明,我认为这是非常关键。为什么这个很重要?在我们内部定期都会组织相关的讨论会,去讨论我们项目中碰到的问题以及风险,这些都是需要关注的,另外一点就是IBM提出的一个概念,运维要“左移”,意思是运维要在开发的生命周期阶段提前介入。这样做有什么好处呢?好处是有助于运维的问题提前在开发阶段提前暴露,我认为这是非常关键的一点。

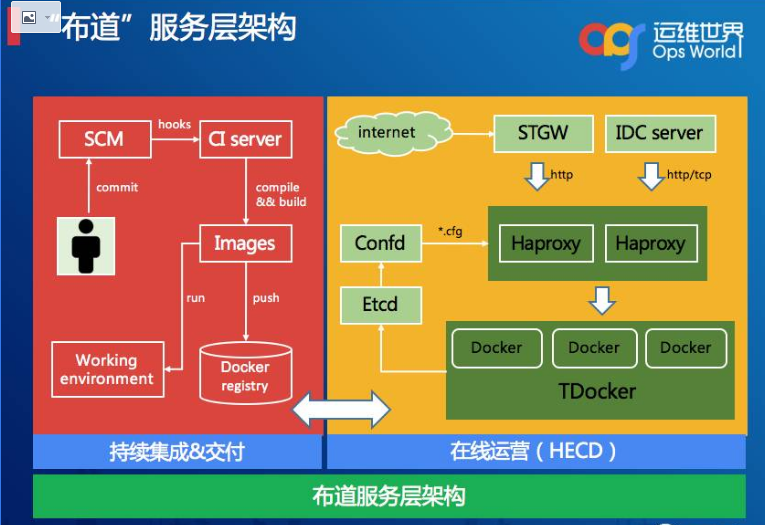
布道体系
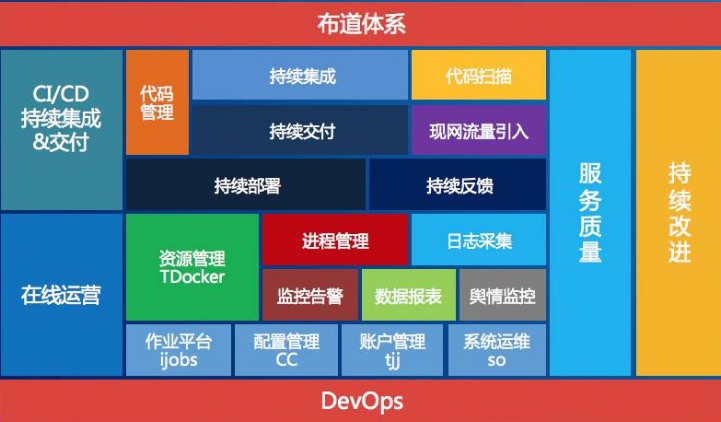
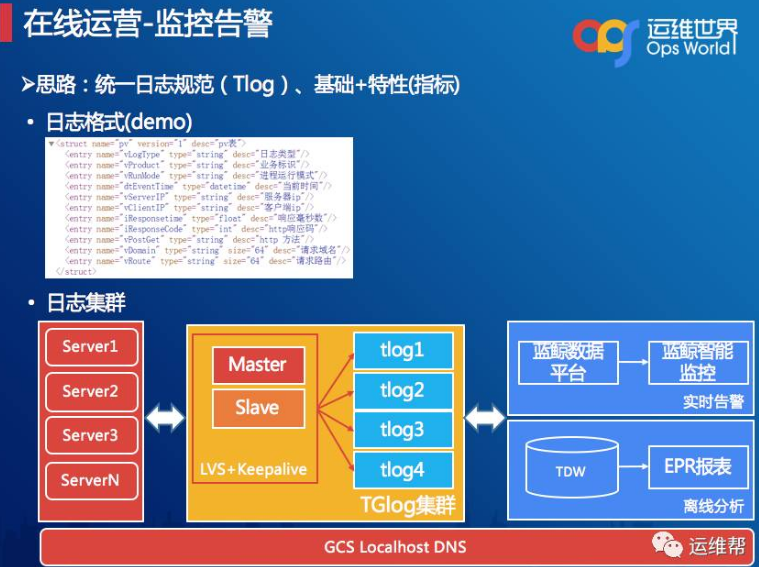
在告警方面我也分享一些思路,在腾讯已经有一套非常成熟的告警系统,我们在这里只是提供一些跟我们业务逻辑相关的策略,我们的思路首先是统一日志规范,每个人的开发水平和习惯都不一样,我们给他们统一一个规范,这个规范叫Tlog,另外引入基础+特性这两个指标。看到的这个DEMO,它通过XML的模式描述日志的结构。特性是跟业务绑定相关的,我这里有一些服务,这个服务我发了一些金币,发到某个区间可能出现问题了,我们就需要开发人员把这个发放的数值打印出来,我们好做一个曲线的跟踪。采集完之后就会进入一个日志采集环节,这个架构也很简单,就是LVS+Keepalive,采集完之后,这里就分两条线,一个是实时,一个是离线的。我们采用的是蓝鲸的实时数据平台,能够实现特性指标多维度的配置。
这是蓝鲸的智能监控的界面。它是实时流,内部用的是Storm做实时分析,然后支持定义灵活的配置,有支持SQL的函数,比如支持某个字段的累加、求和,这个频率可以控制为10分钟、15分钟。
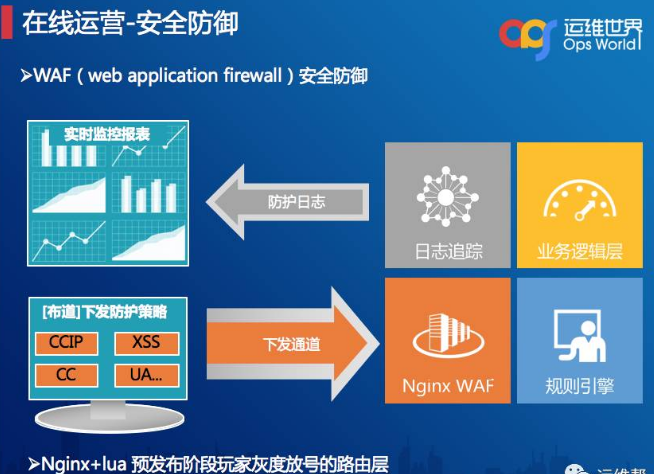
下面是我们安全这一块做的东西,首先是安全防御,在腾讯内部,安全这一块已经做得非常强悍,为什么我还讲安全呢?因为在公司层面做的安全防护更多是通用性或者基础类的防护,WAF更侧重在业务逻辑层,它的架构非常简单,通过布道做一些规则的下发到WAF,例如XSS、CC、UA、URI的规则等等,然后开启日志追踪,通过传输、实时分析防护日志,最终做到防护报告实时展示。
规则校验步骤与大家简单介绍一下,目前采用Nginx+LUA结合的方式,它的防护流程是在检查端口及域名是否匹配规则,匹配就下发规则,然后检查黑白IP名单,后面再开启CC防护,以及开启userAgent检查,最后是开启URI检查注入、XSS、SSRF等。
下面是舆情监控这一块,我们在这里特点就是关键词的实时监控、定时报送推送。从下面这个图可以看到,某一款游戏在某此活动期间的口碑展示情况,有多少是正面的,有多少是负面的报告。

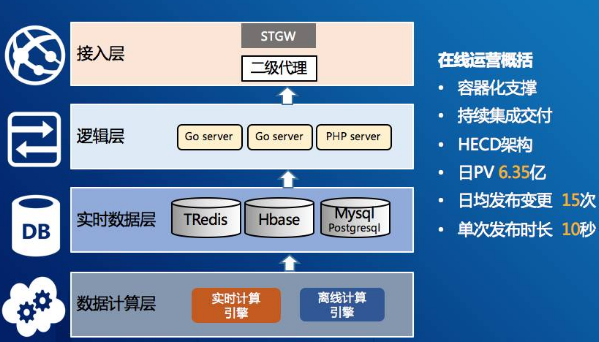
最后做一个总结,在线运营的运营经验,第一个是资源评估,我们要定一个标准,根据实际服务场景来做出评估,而不是拍脑袋做。这个评估有一个公式:设计数量=(PV/86400)×2/单机承载最大QPS/0.8。
第二个是灰度+热力度对蓝绿发布。蓝绿发布的目的是让我们的用户没有感知,我们做蓝绿发布,操作的步骤很多,一旦人工接触多了,就容易出现误操作。我们采用的是热更新方式,原理是服务A进程收到关闭信号量之后,启动B进程来接收已经创建的连接或新连接,当A进程连接完全释放之后就会自动关闭,整个过程用户无感知。灰度实际就是放量检验这个效果及功能,如中间没有出现问题,只需两步就完成变更。
第三个是修复了Supervisor一个bug。Supervisor没办法对进程fork子进程进行管理,所以我们修复了这个bug,如大家碰到同样的问题可以私下找我,我会给大家具体的解决方法。
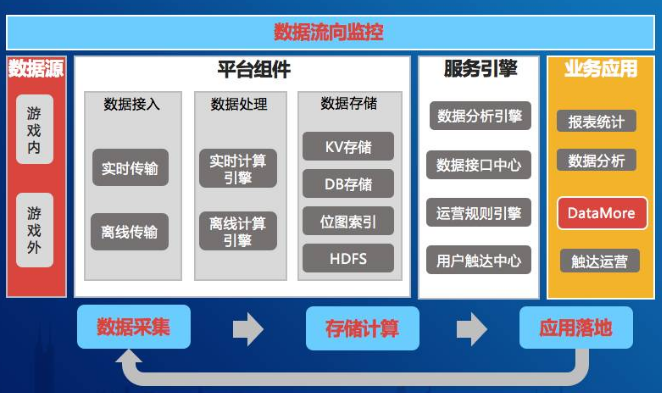
最后是一个数据流向监控的实现思路。首先简单介绍一下为什么要做这个流向监控。数据的流向监控在业界目前没有较好的方案,当我们的数据链、处理链、服务链拉得很长的时候,如何感知当数据源头有发生变更或异常,影响到我们的最终服务,这是非常难度的,而且它跟我们的业务特点关系非常大。同样我们逆向推导也是成立的,我发现玩家的某个对局数据不对,本来是胜局结果变成了负局,怎么确认数据是从哪个节点负责计算或存储的?这个非常有挑战性,这需要我们的数据服务能力一步一步做叠加,需要不断做扩展与关联,才能够达到某一个层次的服务水平。目前我们做的还没那么完美。首先我们要具备元数据管理,还有元信息的管理,这是非常重要的两层。第二个是要有数据字典管理,我们给数据表名称、字段说明,结构性的定义及标签。第三个就是血缘关系,能够定义到任务之间的关系。第四个是数据服务的注册,这是比较核心的一点,怎么注册,我们怎么知道你用了哪个数据源呢?这很关键,我们内部开发了一个通用组件,比如说你要引用后端的数据层,你必须使用这个组件接入,这样关系才能够建立起来,所以应用配置文件也是单独生成的。而最上游我们会提供一个数据流向查询,我们用了A数据,查下来就知道它在这个过程经过了哪些关键点,有可能是存储、计算、分析、接口等。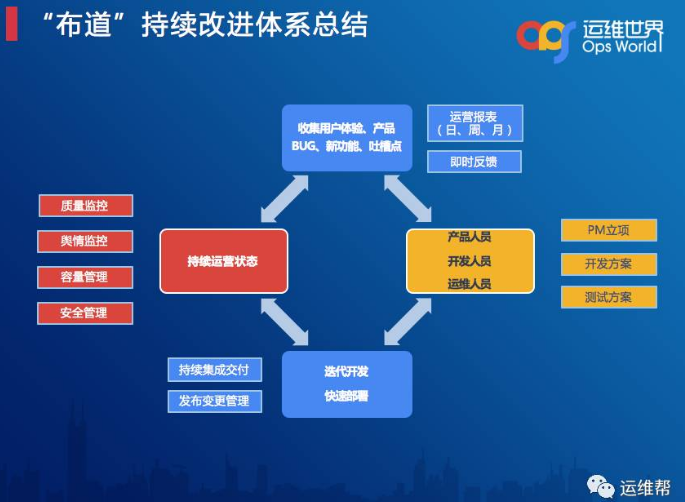
最后快速做一个总结,这是我们的持续服务的体系,在持续运营状态下,我们具备质量监控、舆情监控、容量管理、安全管理、故障治愈、故障修复等能力,同时收集用户服务体验、产品、BUG、新功能、吐槽点,将这些信息反馈给产品人员、开发人员和运维人员。再通过持续集成交付、发布变更管理,做到快速迭代及部署,最后就形成了良性的、持续改进的闭环。

若有收获,就点个赞吧
0 人点赞
