在Flink1.13版本中,官方宣布引入对弹性伸缩的初步支持,支持了Reactive模式下的自动扩缩容服务。该特性主要由Flink社区PMC Robert Metzger大佬操刀设计和实现。可以实现任务随着TaskManager数量的变化来自动重启并自动修改并行度,最终尽量占满所有slot来运行任务。这也就意味着,可以对任务的状态进行监控,判断其在当前任务状态下资源是否不足或者过量,然后触发新增TaskManager或者删除已有TaskManager的动作,然后重启任务重新指定并行度,使得任务在更贴合实际计算资源需求的情况下运行。
目前该模式还仅支持在standalone application部署模式下启用。实际上,该特性目前还处于MVP(minimum viable product)阶段,有很多地方还需完善。话不多说,我们先跑个测试看看效果。
任务实测
由于该模式目前仅支持standalone application部署,所以测试首先要找一个安装好Flink环境的机器。将用户jar放到lib目录,然后用standalone-job脚本配上reactive模式参数启动任务。
./bin/standalone-job.sh start -Dscheduler-mode=reactive -Dexecution.checkpointing.interval="10s" -j org.apache.flink.streaming.examples.windowing.TopSpeedWindowing
任务启动后,此时的集群是没有TaskManager的,可用slot为0,所以任务并没有马上运行起来,而是处于INITIALIZING状态,等待足够的slot。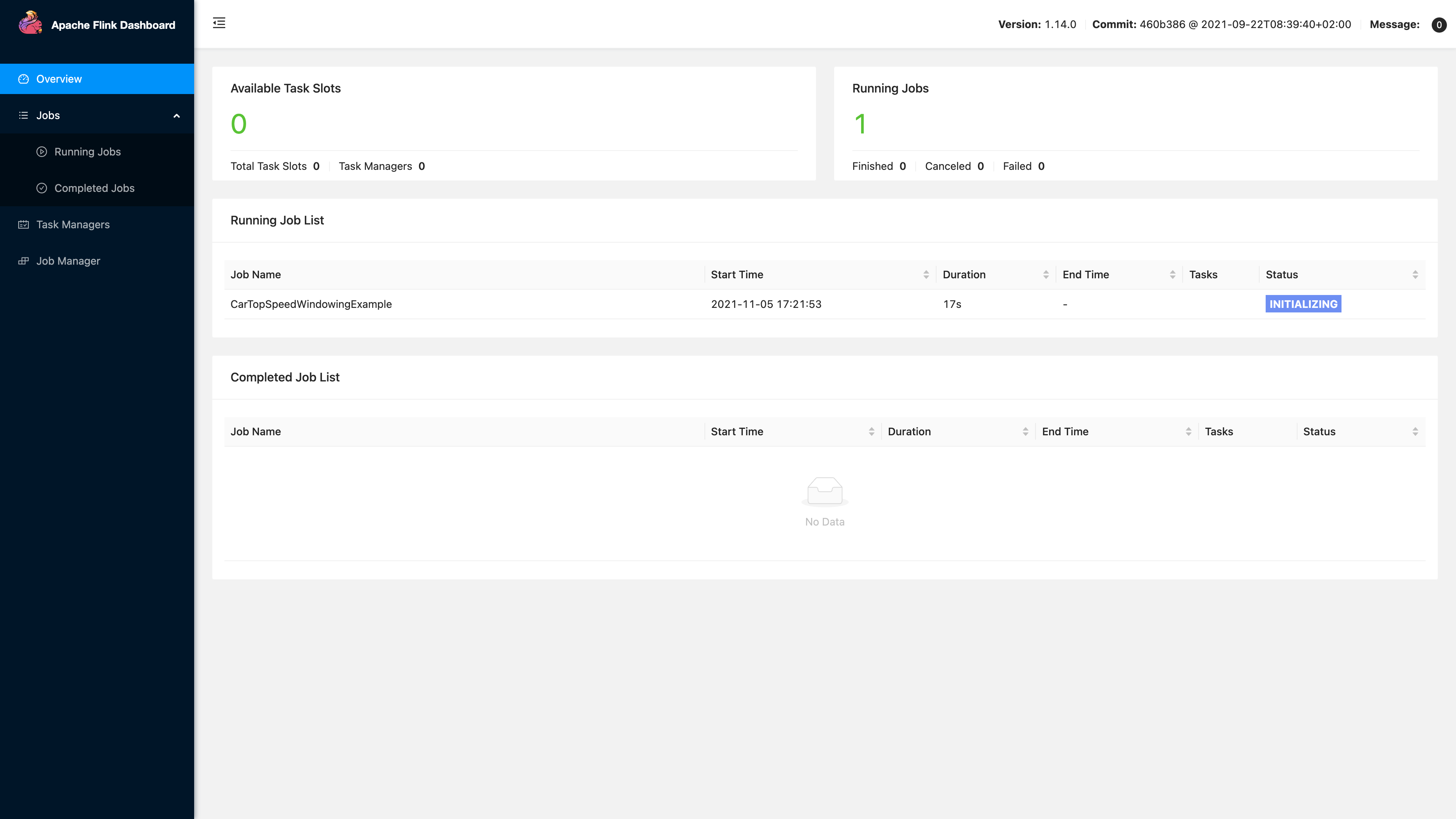
然后,手动启动一个TaskManager进程,不一会儿,Flink UI上slot数目变为8,然后任务进入RUNNING状态,注意观察UI上,Source所在的Task和下游Window所在Task均显示并行度为1,但是subtask数目却为8,等于slot的数量,点击去看两个Task,都是这样的情况,系统此时显示可用的slot数量也为0。
然后我们以同样的方式再启动一个TaskManager的实例,此时任务重启了,而且从上次CheckPoint恢复了,现在Flink UI显示slot总数为16,但是任务重启后各个Task的subtask数目也都从8变成16,slot又被占满了。
这里,停止TaskManager的测试没放上来,其实,效果也是相对应的,停止一个TaskManager之后,任务会重启并占满slot数目,subtask数目也与之对应。
通过上面的测试可以看出来,Reactive模式会使得任务随着TaskManager的数目变化去通过从重启任务来追随可用的slot数目,它采用的是一种尽量占满的策略,最大化地利用已有的资源。可以说,它的弹性伸缩模式是“任务随着资源伸缩而伸缩”。
原理分析
很明显,Reactive模式是尽可能去用完所有的slot,而且看上去是把所有的算子的并行度都设置成已有slot的总数,它伸缩的粒度是具体到TaskManager数量上的,是一种横向伸缩模式,并不是去调节TaskManager的物理规格,比如核心数和内存数量。在非容器环境下,只需要简单启动或者关停TaskManager实例即可,简单有效。在资源分配上,它其实并不是看上去简单把所有算子的并行度改成slot个数的,因为在一个Flink任务中,算子可以通过SlotGroup去分组,同个SlotGroup内的slot可能出现slot共享的情况,即一个slot跑有不同算子的多个subtask。所以Reactive模式实际上是把当前可用slot数目去除以SlotGroup总数,均分到每个SlotGroup中,假设每个SlotGroup分得的slot数量为x,那么该组中所有task的并行度都是x。
说到这里,有一个点需要注意。我们知道,在自定义Source算子时,如果实现的只是SourceFunction,那么Source算子的并行度只会是1,即使手动去set,也会报错,除非实现的是ParallelSourceFunction,否则Source算子是不会并行化的。那么Reactive模式中,如果我们实现的只是SourceFunction,那么增加TaskManager之后重启后Source算子的并行度会增加吗。答案是确实会,但是这也没报错,原因是对于非ParallelSourceFunction类型的Source算子,其并行度校验是在StreamGraph解析时去做。而任务重启后并行度的变化时在ExecutionGraph上去设置的,由于ExecutionGraph在StreamGraph解析的下一层,所以这样去修改并不会报错。但是,这样修改虽然可以,却存在一定风险。设置SourceFunction和ParallelSourceFunction的目的就在于支持不同的场景,确实有些Source连接是不可以并行化的,可能出现多实例数据重复或错乱的情况,这样的风险其本身由于只有用户自身清楚,所以他采用对应的接口便可以规避。Reactive的这种策略从更底层破坏了用户代码的约束。因为从,在上述某些场景下,Reactive模式是不推荐使用的。官方文档暂时没提到这点,后期我也会联系作者确定下这个。
未来发展
前面提到Reactive当前只是MVP(minimum viable product)阶段,离生产实践还远远不够。它核心的地方是解决了任务如何去适应资源的变化,反应到任务本身就是并行度去贴近slot数目。但这只是弹性伸缩最后的一步。一个全链路的自动化弹性伸缩,理应是资源随着任务的需求进行适应变化,比如任务背压了或者任务的CPU负载长期很低,这时候去进行任务并行度的变化,然后资源随着变化,这才是我们最朴素的认识。简而言之,TaskManager的数目调节太粗粒度,最好细化到去调节瓶颈算子的并行度。Robert Metzger在对Reactive模式进行介绍的博客中提到,通过监控任务的延迟背压等情况,然后去调节资源,最后任务通过Reactive模式来自动变更并行度,这是目前的设计方向。但是目前已经实现的功能里也并没有涉及到触发伸缩的算法部分,也没有涉及到目标资源计算算法。实际上,何时该触发一次自动伸缩,更像是一个规则Pattern,也许每个用户对于伸缩的临界条件都有不同的容忍度。即使Flink可以设置一些默认值,但是这部分逻辑已经超出了Flink作为一款计算引擎本身的职能了,我推测后续大概率是推出一系列触发伸缩的接口,然后具体的实现则交由各家公司去做,实现一个规则平台即可。如何求得一个合理的目标资源量或者任务并行度也是难以界定的事情,比较容易想到的应该是按照数据量、cpu负载、内存使用量在最近历史时期变化的倍率去相应以对等倍率去伸缩。计算好了要变化的并行度或者slot数目后,如何伸缩物理资源也是难题,独立的物理机需要管理平台来人工触发启停,在容器环境下这个问题稍微容易些,AWS的Auto Scaling groups,Google Cloud的Managed Instance groups,或者简单Kubernetes提供的Horizontal Pod Autoscalers功能也行。
上面说到,目前设计方向只考虑到了TaskManager数目粒度的伸缩,除了单个算子并行度可以考虑伸缩以外,承载算子的Slot资源规格也是一个可以伸缩的方向,社区目前在发展的Fine-grained Resource Management未来就可能与Reactive模式结合起来,通过调整单个slot本身的cpu和内存来满足更细粒度的资源需求。说了这么多,任务的自动弹性伸缩其实是一个非常复杂的工程,涉及到Metric采集和监控、规则引擎、资源调度(横向和纵向)以及Flink本身任务调度等多个方面,已经不止是单单一个Flink能解决的事情,可以研究细分方向和深度都大有可为。非常期待社区能把这件事情做到什么程度,这可能是一个计算引擎真正走向智能化的关键一步。同学们,一起加油!

若有收获,就点个赞吧
0 人点赞
