很多用户在使用Flink的时候,需要依赖外部的系统进行数据的交互处理。在默认的Pipeline模式下,如果使用Map算子来做,由于与外部系统的交互,每次查询都需要依赖网络,所以串行化执行往往带来很大的累积延迟。异步IO的出现解决了这个问题,数据的发出和结果的取回不再绑定在一起,而是变成数据不再阻塞,持续发送,至于如何取回结果则引入回调来解决。这部分代码由阿里开发并贡献给社区,涉及的类和代码量也不算大,其中使用的数据结构也比较经典直观,可以作为阅读Flink源码的入门尝试。
以下代码均基于Flink 1.12版本。
看之前
在深入阅读之前,我们稍微思考下,如果让你来实现这块功能,你会怎么办,需要着重解决哪些问题,有哪些细节需要注意。首先,异步IO支持有序和无序两种模式,所谓有序和无序指的是什么,是否有范围限制,其背后通过上面数据结构来实现的。其次,由于异步IO突破了经典的流水线模式,多个数据之间的处理不再是串行,那么是否会瞬间接受大量数据打爆内存,是否或者怎样去控制数据流速。想清楚这些,我们阅读起来会更加轻松愉悦,也更有目的性。
顺序性
在官方给出的代码示例中,我们可以看到异步IO对外暴露的两个接口,分别通过AsyncDataStream.orderedWait和AsyncDataStream.unorderedWait来创建有序和无序的异步IO处理模式。实际上,当在ProcessingTime之下,所谓的有序和无序就是我们一般意义上的认知,但是在EventTime下,这种顺序性的定义略有差别。在EventTime模式中,数据流中掺杂了Watermark,这里的无序则变成两个Watermark之间这段数据的一种无序关系,即在当前两个Watermark之间的这部分数据可以在经过异步IO算子后依然是排在再往前两个Watermark之间这些数据之后的,但是当前这段数据其内部是可以来不再保持原先的先后顺序的。相当于Watermark把数据一截截地分开,每截数据之中的可以乱序,但是Watermark之间则不可以乱序。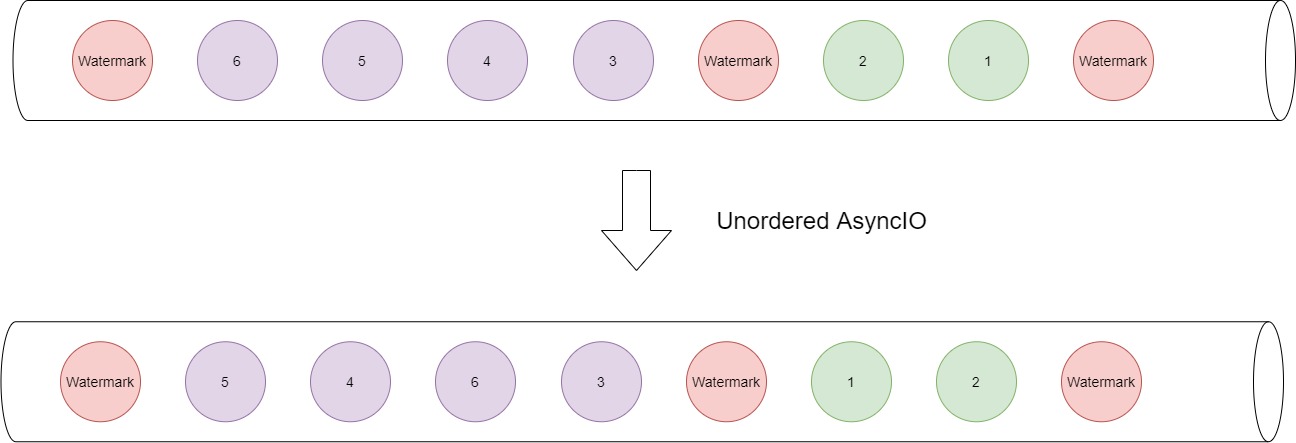
为什么在EventTime下数据的顺序性要被Watermark所截断呢,因为Watermark是用来驱动框架内部的时间线的,Watermark的陆续到达会触发时间窗口计算,如果不同Watermark之间的数据也乱掉了,那么可能Window触发时,其中的某些数据仍在异步IO的处理流程中。这会严重破坏Flink内部的原有框架设计,所以必须用Watermark来隔绝乱序的产生。这种限制也因此增加了异步IO设计的复杂性,如何用同一套代码兼容EventTime和ProcessingTime中的无序逻辑,是异步IO中最难实现的部分。
实现原理
有序
根据前面的描述,如果要求输出结果和输入结果顺序保持一致,这时候其实无论是EventTime还是Watermark都没太大区别。需要做的都是把按顺序去读取到达的数据并进行异步的查询交互逻辑,再按照输入顺序依次输出就行。很容易想到,采用队列类似的数据结构就可以满足上面的需求。在有序模式中,确实使用了OrderedStreamElementQueue来存储数据。其本质上使用了ArrayDeque来顺序存储上游的StreamElement,对于上游的StreamRecord,其被包装为StreamRecordQueueEntry,对于Watermark,其被包装为WatermarkQueueEntry。每个数据都会被塞入队列中,然后触发计算。不同在于,当用户的代码中完成异步操作,调用complete函数时,StreamRecordQueueEntry就被置为“完成”状态。而WatermarkQueueEntry被塞入队列时就会置为“完成”状态。也就是在ArrayDeque中的数据,随着时间增长,单个数据的状态都会从“未完成”走向“已完成”,那么只要去ArrayDeque去检测队头数据是否已完成,若已完成,则可输出,不断地去把队头的已完成数据输出,就会形成一条输出顺序和输入顺序一致的数据流。这里很明显我们能看出,为了保证输入输出顺序一致,我们的队头数据只要未完成就不会出队,即使这时候队中其他数据有已完成的,那么它们也得乖乖等着轮到它们自己成为队头,这样保证了逻辑上的有序性,但代价显而易见,某个数据即使处理完成,也得等待前面的数据都被处理完才可以输出。也就是增加了单个数据端到端的延迟,同时一定程度上降低了系统的吞吐率。
无序
在前面的有序模式中,所有的数据都放在同一个队列上,根据数据是否变成“完成”状态来以及是否在队列头部来决定其是否输出。到无序模式中,显然单单一个队列时解决不了问题的,所以在无序模式中,增加了一个Set。尚未完成的StreamRecord数据放在Set中,如果完成了,便从Set移到Queue中。这样谁先完成了就可以直接排到队列尾部,队列中的全部是已经完成的数据,直接从队列依次输出即可。Watermark照例算是“已完成”的数据,直接放入Queue中。Set和Queue都放到一个Segment实例中,这里的Segment就充当了有序模式里队列的角色,存储了到来和即将输出的数据。
到达的数据也前面提到的StreamRecordQueueEntry的继承类SegmentedStreamRecordQueueEntry来封装,SegmentedStreamRecordQueueEntry中有个Segment实例,引用了该SegmentedStreamRecordQueueEntry对象所在的Segment实例。方便当该数据从异步IO中完成返回时,将其从代表“未完成”的Set转移到代表“已完成”的Queue中。 但
但
正如开头所提到的,Flink依靠Watermark来触发窗口的计算,所以在原来的夹杂了Watermark的数据流中,处于Watermark之前的数据不可以在异步IO后变到Watermark后,Watermark之后的数据也不能跑到Watermark之前。为了避免两个Watermark之间的数据因为异步IO的原因而穿越了这个Watermark区间,这里又需要特殊设置了一种数据结构来建立数据分段屏障。Watermark之间的数据都被放入同一个Segment,在这里走完从“未完成”到“已完成”的过程。这样装载了每个数据段的Segment再放入一个队列中,便形成了所谓的分段屏障。
我们从代码角度来看看具体的操作过程。StreamRecord的放入相对简单,如果Segment队列是空的,那么新建一个Segment对象,然后将该数据放入“未完成”Set中。如果Segment队列不为空,则取队尾的Segment对象,将数据放入。
private StreamElementQueueEntry<OUT> addRecord(StreamRecord<?> record) {// ensure that there is at least one segmentSegment<OUT> lastSegment;if (segments.isEmpty()) {lastSegment = addSegment(capacity);} else {lastSegment = segments.getLast();}// entry is bound to segment to notify it easily upon completionStreamElementQueueEntry<OUT> queueEntry =new SegmentedStreamRecordQueueEntry<>(record, lastSegment);lastSegment.add(queueEntry);return queueEntry;}
Watermark的处理相对麻烦点,因为Watermark即为屏障,需要将Watermark前后的数据放到不同的Segment中。在放入Watermark时,如果Segment队列不为空而且其队尾Segment为空,那么这个Segment对象可以直接拿来用,将Watermark放入,此时Watermark将成为“已完成”Queue的队头。如果此时Segment队列为空,或者不为空但队尾Segment也不为空,那么这时候会新建一个Segment,依然把Watermark放到“已完成”Queue的队头。将Watermark放入合适的Segment后,最后会再新建一个Segment来存放后续到来的StreamRecord。
private StreamElementQueueEntry<OUT> addWatermark(Watermark watermark) {Segment<OUT> watermarkSegment;if (!segments.isEmpty() && segments.getLast().isEmpty()) {// reuse already existing segment if possible (completely drained) or the new segment// added at the end of// this method for two succeeding watermarkswatermarkSegment = segments.getLast();} else {watermarkSegment = addSegment(1);}StreamElementQueueEntry<OUT> watermarkEntry = new WatermarkQueueEntry<>(watermark);watermarkSegment.add(watermarkEntry);// add a new segment for actual elementsaddSegment(capacity);return watermarkEntry;}
看到这里,是不是一切都明了了。Watermark会放到一个空的Segment中,而这个Segment放完Watermark之后,不会再放入任何数据。后面到来的StreamRecord会放到一个新建的Segment中,如果后面到来的也是Watermark,那么会重复上面的流程,独占一个Segment。这样设计的结果就是存放StreamRecord的Segment和存放Watermark的Segment是不同的,而所有的Segment是放在一个队列里的,有着严格的前后关系,输出也是按照队列顺序进行的,所以StreamRecord和Watermark之间不会乱序,也就保证了后面窗口触发的逻辑不会出错,数据不会分到错误的窗口里。其实,可以看出所谓的无序模式,实际上是一种局部的无序。如果用Watermark将数据分段,那么数据段之间是有序的,而数据段内的数据经过异步IO处理后可以无序输出。
如何持续输出
在有序模式中,数据在队列的相对位置从来不会改变,改变的只是一个状态,从“未完成”状态变成“已完成”状态。当一个数据在异步IO的AsyncFunction�.asyncInvoke方法中调用了ResultFuture
.complete后,它就完成了“已完成”状态。如果是的在无序模式中,数据完成后,会从Set转移到Queue里,也算是变成“已完成”状态了。当数据在异步IO中完成后,这时候就需要考虑是不是可以输出这个数据,如果这个数据是在队列头,那么确实可以输出,但是绝对不能由当前的异步IO线程来输出。为什么?首先在Flink框架中,所有算子接受数据的动作和发送结果的动作都是由同一个算子的主线程来管理和进行,异步IO不能违反这种设计规范。更重要的是,如果由异步IO线程在数据完成后去输出,那么每个数据都由一个异步IO线程去输出,而输出时有判断是否是队头和出队的动作,多个线程在同一个队列上做这两个动作会导致并发问题,必须加上同步逻辑,这就由带来了设计的复杂性和并发竞争的性能损耗。源码的设计通过Actor模型解决了这个问题,简单说就是,异步IO线程在数据变成“已完成”后,向主线程发了一封信(Mail),发完信异步IO线程便结束了。这封信中告诉了主线程如何去输出这个已完成的数据,由于主线程总是在交替做处理数据和读信的动作,所以当主线程结束了一次数据处理后,它就会读到这封信,然后输出数据的任务就交到它身上了。当主线程开始打开一封信,并开始按照信件中的方法去输出数据时,它会判断有序模式里的队头是否“已完成”或者无序模式里Segment的“已完成”Queue队头是否不为空,符合添加则输出结果,但是此时队头后面也许也有数据已经完成,所以主线程会给自己再发一封信,告诉自己回头再去输出这个已完成的数据。
最后补充一点,由于Watermark无论在有序还是无序模式中一开始就是“已完成”状态,所以它不会经过异步IO线程处理,但是它依然需要被输出,所以它在放入有序模式里的队列或者无序模式里的Segment后,都会由主线程给自己发一封信,让主线程自己稍后输出这个Watermark。如果对“写信->收信”这个模式还不明白的同学,建议好好研究下Flink中涉及到处理input数据那块的源码,这部分的设计将Actor模型的思想发挥到了极致,认真看完对于架构上的成长大有裨益。
private void processInMailbox(Collection<OUT> results) {// 当前异步IO线程向主线程发送一封信,告诉主线程如何输出数据mailboxExecutor.execute(() -> processResults(results),"Result in AsyncWaitOperator of input %s",results);}private void processResults(Collection<OUT> results) {// Cancel the timer once we've completed the stream record buffer entry. This will// remove the registered// timer taskif (timeoutTimer != null) {// canceling in mailbox thread avoids// https://issues.apache.org/jira/browse/FLINK-13635timeoutTimer.cancel(true);}// 有序模式则把结果放到StreamRecordQueueEntry的一个集合中,无序模式则完成同样操作后然后把该数据从“未完成”Set转移到“已完成”Queue中resultFuture.complete(results);// 输出结果outputCompletedElement();}private void outputCompletedElement() {if (queue.hasCompletedElements()) {// 有序模式如果队头是不为空且“已完成”,则输出。无序模式如果“已完成”Queue队头不为空,则输出。queue.emitCompletedElement(timestampedCollector);// 如果还有数据可以输出,则给自己写一封信,后续再输出一次if (queue.hasCompletedElements()) {mailboxExecutor.execute(this::outputCompletedElement, "AsyncWaitOperator#outputCompletedElement");}}}public void processWatermark(Watermark mark) throws Exception {addToWorkQueue(mark);// 被主线程添加到已完成队列后,主线程给自己写信,后续再输出outputCompletedElement();}
如何限流
很简单,在添加数据的时候保证池子里的数据量始终小于或等于设定的capacity即可,添加失败则一直等到可以添加。
private ResultFuture<OUT> addToWorkQueue(StreamElement streamElement) throws InterruptedException {Optional<ResultFuture<OUT>> queueEntry;while (!(queueEntry = queue.tryPut(streamElement)).isPresent()) {mailboxExecutor.yield();}return queueEntry.get();}@Overridepublic Optional<ResultFuture<OUT>> tryPut(StreamElement streamElement) {if (size() < capacity) {StreamElementQueueEntry<OUT> queueEntry;if (streamElement.isRecord()) {queueEntry = addRecord((StreamRecord<?>) streamElement);} else if (streamElement.isWatermark()) {queueEntry = addWatermark((Watermark) streamElement);} else {throw new UnsupportedOperationException("Cannot enqueue " + streamElement);}numberOfEntries++;LOG.debug("Put element into unordered stream element queue. New filling degree " +"({}/{}).", size(), capacity);return Optional.of(queueEntry);} else {LOG.debug("Failed to put element into unordered stream element queue because it " +"was full ({}/{}).", size(), capacity);return Optional.empty();}}
总结
其实异步IO部分的设计本身没有太高的复杂性,但是在有序无序的设计上以及后面提到的输出流程上,确实是可圈可点的,非常值得赞扬,不得不说阿里这件事做的很不错。这部分源码如果要完全读懂,可能会联系到Flink内部很多其他模块的设计原理,如果有时间,建议花点时间好好啃下来,触类旁通,你很快会对Flink的一些基本原理有了清晰认知。总之,还是建议大家从异步IO这类简单的源码入手,一步步深入,培养自己阅读源码的能力,当你看的越多,理解的越深刻后,不知不觉自己的架构能力就会上升到一个比较高的水平。Apache基金会里的顶级项目都是由世界各地的大牛来贡献代码的,阅读源码,就如同读大师写的书,甘之如饴。进入这道门,世界更加宽广。同学们,大家加油!

若有收获,就点个赞吧
0 人点赞
