提到Flink的CheckPoint语义,可能大家更多想到和听到的都是端到端的“exactly-once”和“at-least-once”两种语义,这个一般可以具体到Sink算子往Kafka生产如何在任务失败恢复时保证数据不重不漏。但是这是Flink与外部系统交互时的语义问题,在Flink本身去设置开启CheckPoint时,在其框架内部也支持这两种语义的设置,不同在于,这里的语义作用在Flink任务在重启恢复时如何保证数据在重复拉取后不会在state重复计算。官方默认开启exactly-once,可能很多同学平时注意到这个参数了,也都直接选择默认值,但是exactly-once并非任何情况下的最佳选择,at-least-once在某些场景下也有其独特的优势,了解这一点将成为我们调优时的宝藏小tips。
理想模式
在讲这个问题之前,我们不妨抛开已有的知识,想想如果让你去设计一个流式计算框架的快照流程你会怎么做,这个问题有助于我们更好的理解当前Flink 状态架构设计。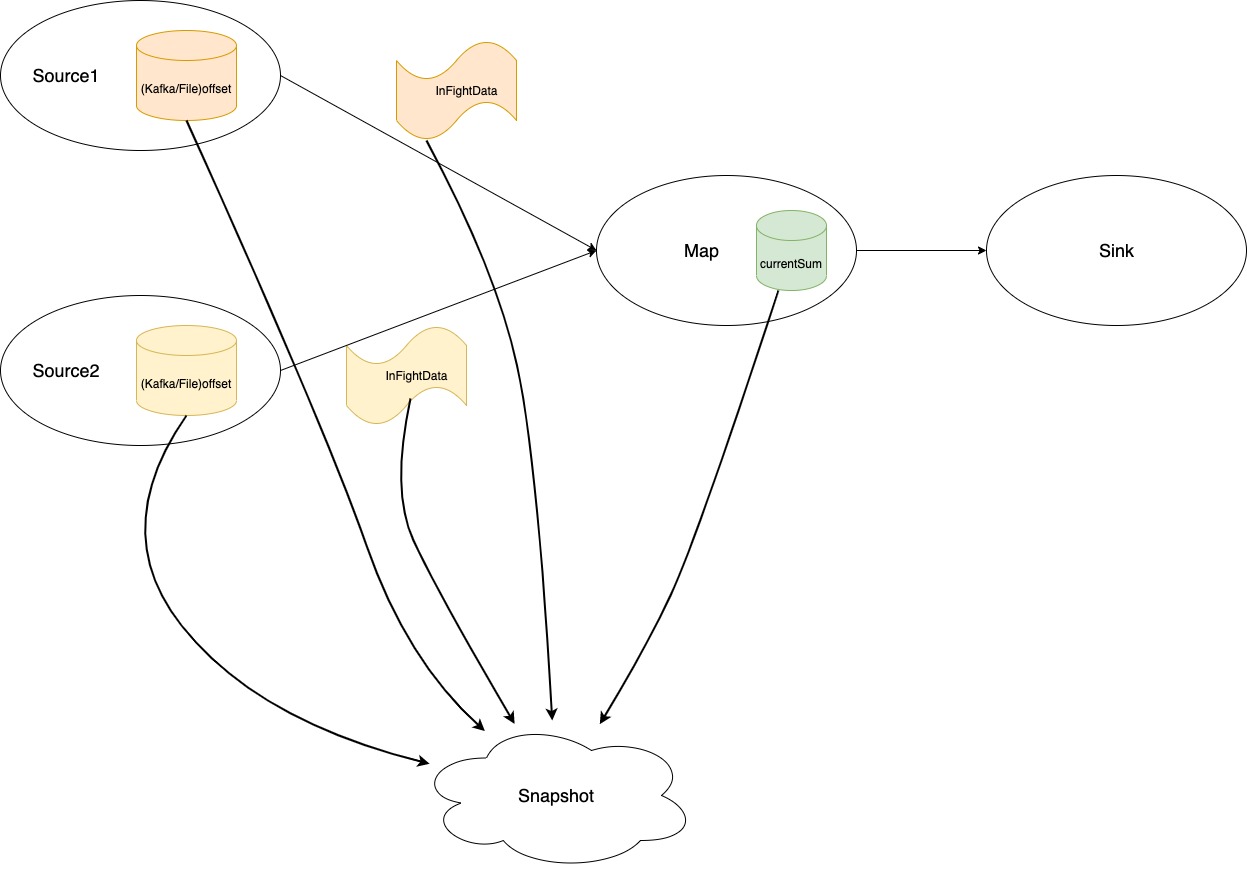
一个理想的设计如上图所示,我们真的去保存一个高速运行的流式系统的所有数据,包括这一瞬间的Source中的状态(比如Kafka和File的offset)、还在传输中或者算子内部还未计算的数据(InFlightData)以及其他算子内部当前的State。这个理想的情况有些什么问题呢。
- 首先,要做到完整保存上述的数据,我们需要暂停Source的拉数动作,暂停中间算子的计算,暂停Sink算子的发送动作。是的,我们暂停了一切的动作,在一个追求实时化高速的流式计算引擎里“stop the world”。这对用户当然是不可接受的,他们将需要等待上面提到的一系列数据去转存到外部持久化存储中,数据大的时候这个时间也许很长,这将是灾难性的。
- 如果说我们存储算子中的state还可以接受,那么我们存储算子中尚未计算的所有数据将会代价沉重。一旦数据处理达到一定量级,那么从Source到Sink中成百上千的subtask中所有的数据大小的总和将是非常大的,而且如果我们还要周期性去做快照的话,从算子中数据传输到持久化存储(例如HDFS)将占用非常大的网络带宽,耗时也是问题,持久化存储本身的存储容量消耗也要考虑的问题。这样的快照过于“笨重”。
- 最后,在任务恢复重启时,我们有需要把状态从持久化存储拉取回来恢复到算子中,又是同样的问题,带宽和耗时。
总的来说,上面的方案最大的问题可能在于“stop the world”和体量巨大的InFlightData也需要存为状态数据。下面我们看看Flink当前状态机制在此之上如何去优化和设计的。
Exactly Once
Flink通过在持续的数据流中插入Barrier来隔离不同Checkpoint之间的数据,使得数据流在收到Barrier的算子上“局部停顿”,这种“局部停顿”停止的也只是数据的处理,数据的接收仍在进行,只是被存入了本地的buffer中,所以上游的算子不会阻塞,这一步采用折中的方式解决了“stop the word”的问题。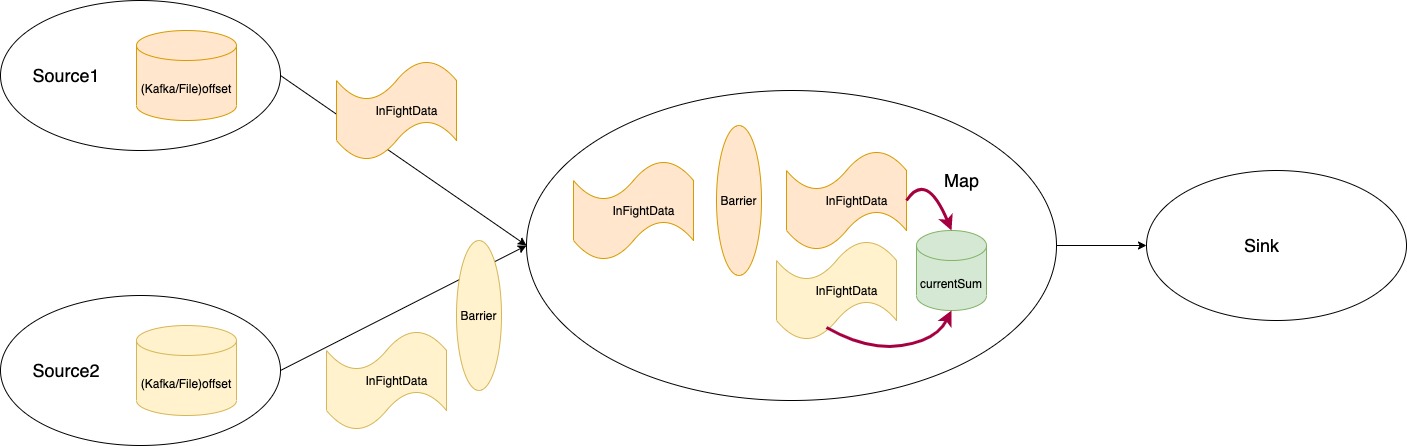
其次,当某个subtask收到了上游所有channel发来的Checkpoint Barrier后,它将向下游广播Barrier,并开始制作快照。在Checkpoint Barrier之前的数据将全部计算并更新结果到本地的state上,于是,我们的state则代表了Barrier以前所有数据的计算结果。state将被通过网络传入到持久化存储中,到这里一个算子的Checkpoint全部完成。同样的,下游的算子收到Barrier,停止该channel数据的计算,并重复上述过程。当末端的Sink算子也完成Checkpoint后,一次完整的任务Checkpoint也就完成了。
我们试着梳理下。制作快照前会将本地的InFightData(Barrier之前的)进行计算并更新结果到state中,这一步就解决了前面提到需要存储InFightData到快照中的问题,state一般是是计算的结果,其本身不包含普通的数据对象,所以不会很大。我们只需要把所有算子上的state去持久化到远程存储中即可。这部分state代表了什么了,它代表了在Checkpoint Barrier之前所有数据的计算结果。很显然,我们把数据流进行了逻辑上的切分,“Barrier前”和“Barrier后”的,Barrier前的数据都被计算消耗掉,变成了最终的计算结果,也就是state。由于我们在Source算子的state中存储了消费上游数据的偏移量(Kafka/File Offset),所以如果我们的任务崩溃,从state中恢复重启时,我们将重新去从offset处去拉取数据,继续我们上次的任务,一切仿佛什么都未发生过一样,新到来的数据将继续计算并更新state。
那么,我们再看看exactly-once语义是如何被保障的。因为当收到某个channel的Barrier后,来自这个Barrier的数据流就被截断,之前的数据被计算到state中,之后的暂存buffer中。所以收到Barrier的channel都进行这样的操作,那么即使收到第一个Barrier和收到最后一个Barrier之间的时间差再大,这一批Barrier之前的数据都不会参与计算并反应到state中,这是非常重要的。因为我们任务故障恢复后,重新拉取的正是这批Barrier之前的数据。是的,这批数据被拉取了两次,但是上一次拉取来并未参与计算,只有故障恢复后才拉取到的才会参与计算并更新state。也就意味着对于数据的计算和state的更新是一致的,对齐的,没有数据被多计算,state的值是准确无误的。
这是我们最朴素的理解,也是追求最终计算一致性理所应当考虑的设计。
At Least Once
我们接着说说为什么我们依然需要at-least-once,或者说它的缺点如何被优点所掩盖的。
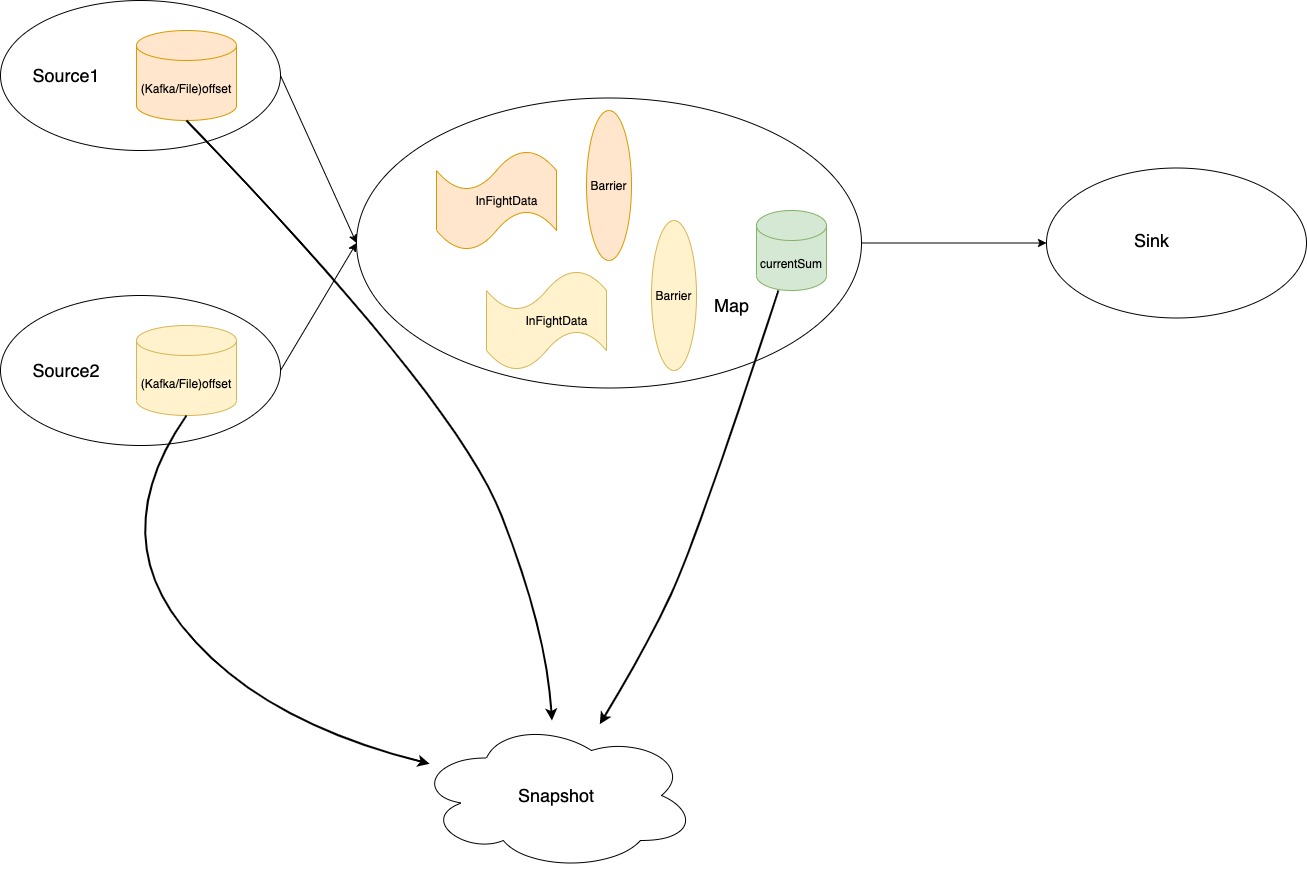
相比exactly-once,at-least-once与之最大的区别在于当它收到来自某个channel的Barrier后,并不会阻塞该channel,数据的接收和计算将继续,所以state的值也会更新。当当前subtask收到所有上游channel的Barrier后,这时候再去制作快照。但是此时的state所反映的不仅仅是这一批Barrier之前数据计算的结果了,因为Barrier先到达的那个channel其Barrier后的数据也继续被计算并更新到state上了。问题在这个时候产生了。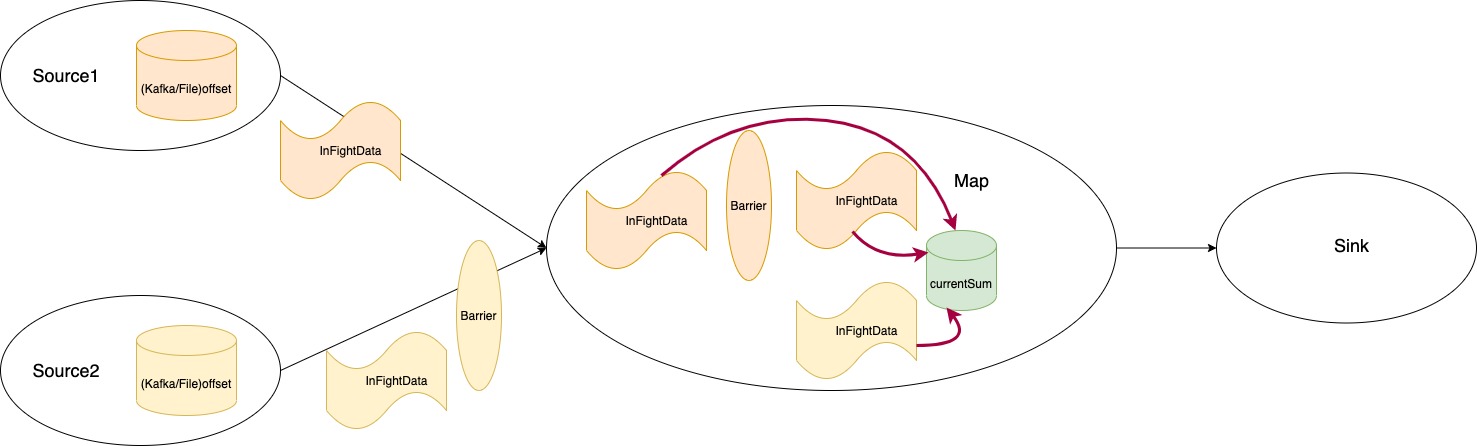
对于Source算子而言,它们的Checkpoint不是被Barrier所触发的,原因有很容易理解,因为Source已经是最上游的算子了,没有其他算子把Barrier发送给它们,因此,它们的Checkpoint实际上是由CheckpointCoordinator通过RPC调用触发的,Source算子将收到一个代表需要触发Checkpoint的Mail。由于进行数据处理和Mail处理的是同一个线程,所以对于任意一个Source的subtask而言,即使它们收到Mail的时刻有早晚区别,但是他们都是在收到Mail进行Checkpoint的,这时候数据处理时不会进行的。如果把Mail也看多Checkpoint Barrier的话,那么Source只需要收到一个Mail(也只有一个)就会开始Checkpoint,没有类似多个Barrier对齐的逻辑。也就是说,Source在做Checkpoint的时候是不会有Mail之后的数据流过的,其state记录的offset也正是收到Mail时的offset。它们发送Barrier也是在收到Mail后和继续处理数据之前,下游task在接受这些Barrier时,如果是在at-least-once语义下,那么下游的某些算子的subtask将会超前消费并处理Source记录的offset之后的一些数据,并反应在state上。因为,当任务从故障恢复时,Source依然会从记录的offset去拉取数据,然而之前这些数据中的某一些已经到达过下游的subtask,并算入state中,此时又会计算一遍并更新state,所以,重复计算的现象产生了。这就是所谓的at-least-once,数据至少会被计算一次,但是后果就是计算的结果会错误,会变大或者变多。
at-least-once语义的好处显而易见,数据不会阻塞,即使收到Barrier后依然继续处理数据,这对于追求低延迟高速率的流式任务至关重要,更多的数据被处理,数据被更及时处理。坏处是结果会重复算多,这是坏处吗,或者说任何情况下都是坏处吗?非也,试想一下如果我们的下游算子处理数据的逻辑是“某条数据是否出现过”或者“已经出现过的最大数是多少”,那么某条数据被处理一次还是两次,结果都是一样的。是的,如果我们的state更新操作是逻辑幂等的,那么这种情况下即使多次计算也不会有问题,结果不会算错。
总结
大家在使用官方算子或者API时,可能总是喜欢直接选择默认值,或者总是忽略一些不怎么被提及的配置。然而,任何程序的调优都不是基于默认值的,适合自己场景的参数才是合适的,对于追求低延迟而且下游支持幂等或者去重的用户,使用at-least-once绝对是优于exactly-once的。所以,但凡想深入学习调优的同学,角落里不为人注意的小知识点都可能会带来巨大的改变,毕竟,设计者当初做出这么多差异化的参数可不是无聊之举。入门到进阶的改变就在这里,加油同学们!

若有收获,就点个赞吧
0 人点赞
