一. 基础语法
增、删、改、查 (节点为Person)
1.基础信息 ()小括号里面为节点对象,[] 中括号里一般为关系,{}大括号内一般为属性 ,标签其实质也只是节点的属性,所以一般出现在小括号内,跟着 : 后面。
取属性的方式一般为 alias. propName, 取类型的方式一般为 typeName(alias)。
Match 方法中 (node:Tag{name:’tom’}) == (node:Tag) where node.name = ‘tom’。
- 添加数据
- Create(node1:Tag {prop:’prop’}) return node1;
创建节点 node1 , 标签名称为Tag ,属性为{prop}, 并且返回node1的信息;
- **Create(node1:Tag {prop:'prop'})-[:Relationship {prop:'prop'}]->(node2:{prop:'prop'}) return node1._创建节点 node1和node2,并指定node1和node2关系 Relationship .<br /> :前面类似于指定一个别名,在return中使用 如果不用return 可以 直接 create(:Tag{prop:''}).<br />这个语句可以一直向下添加关系,例如如果给node2指定关系,那么直接在node2节点继续输入关系链即可。<br />如果Tag不存在,那么会创建Tag<br />如果node有多个节点,那么创建时 node1:Tag1:Tag2:Tag3 ,节点便具有3个tag_- **MATCH (p1:Person),(p2:Person) WHERE p1.name='x' AND p2.name='y' CREATE (p1)-[r:Relationship{prop:''}]->(p2) return p1._ p1节点 p2节点 创建 为 Relationship 的关系_- **示例**- 创建marry节点,标签为Person, 属性为json内的数据 <br />
删除数据
- **Match(p:Person) WHERE id(p)=1 DELETE p;
Match(p:Person) WHERE p.name=’name’ DELETE p; 删除节点无非是先查询到节点,然后直接delete, 但是注意,一旦存在关系,节点是无法删除的,所以需要先删除关系。 - Match(p:Person) WHERE id(p)=1 DETACH DELETE p;
Match(p:Person) WHERE p.name=’name’ DETACH DELETE p; 删除节点及其所有的关系。id 能够指定单独节点, p.name 删除同name的所有节点**// MATCH (n) DETACH DELETE** n 删除所有节点和关系 ,慎用。 - **Match(p:Person)-[r:Relationship]->() WHERE id(p)=1 DELETE r;删除关系,删除节点id=1 的关系为Relationship的关系。
- 示例
- 删除 节点 name=nancy 的FRIEND关系** Match(p:Persion)-[r:FRIEND]->() where p.name =’nancy’ delete r;
- 删除id = 节点和这个节点所有的关系
Match(p:Persion) WHERE id(p)=180 DETACH DELETE p;
- **Match(p:Person) WHERE id(p)=1 DELETE p;
修改数据
- Match(p:Person) where id(p) = 6 SET p.age =18 return p ;
Match(p:Persion)-[r:Relationship]->() where id(r) = 1 set r.time=’one years’ return r;
设置节点p的单个属性
设置关系 r 的单个属性
另外对于年龄的类型 也可以使用 += 之类的操作 ,多个属性用 ,逗号 隔开 - Match(p:Person) where id(p) = 6 SET p={name:’’,age:17,sex:’’} return p ;
Match(p:Persion)-[r:Relationship]->() where id(r) = 1 SET r ={time:’two years’,level:’young man relationship’} return r;
更新节点p的所有属性
更新关系r的所有属性 - Match(p:Person) where id(p) = 6 SET p.age =null return p ;
Match(p:Person) where id(p) = 6 REMOVE p.age return p;
删除属性 , 一个是set属性值为null, 另外一种是 移除改属性 - MATCH (node1), (node2) WHERE id(node2) = 1 and node1.name=’jack’ SET node2 = node1 RETURN node2,node1
复制节点属性 复制node1的属性到node2上 ,同时如果有相同的属性 node1上的属性会覆盖node2 - Match(p:Person) where id(p) = 6 set p:DIRETOR return p ;
节点 p 设置标签 DIRETOR , 注意 这里是添加标签,不会进行覆盖 ,所以执行完成后 p将会有两个标签Person,DIRETOR - MATCH(p:Person) WHERE id(p)=180 REMOVE p:DIRETOR RETURN p;
移除节点 p的 DIRETOR 标签 ,如果需要移除多个标签 只需要 remove p:tag1:tag2:tag3 即可
- Match(p:Person) where id(p) = 6 SET p.age =18 return p ;
查询数据
SQL语法原因,我更喜欢用where条件查询,这样查询 语句会简单清晰- Match (p:Person) where id(p) = ? and p.name= ? return p,labels(p) order by id(p) desc limit 10;
单节点查询**查询节点p, 节点标签为 Person 节点类型 id=? , 节点属性 名称 name=? ,并且返回节点p的信息和节点p 标签数组(labels 表示返回节点标签),按id 倒序排序, 并且限制返回前10条数据。
另外一中属性的写法 查询名称为jack的节点。
Match (p{name:’jack’})return p,labels(p) order by id(p) desc limit 10; - MATCH (p)-[r]->(p2) where name=’’Cuba’ and id(p) = 1 RETURN p2,p,r,type(r)
MATCH (p)—(p2) where name=’’Cuba’ and id(p) = 1 RETURN p2,p
查询和节点p有关系的所有节点,节点p id=1 ,name=Cuba ,如果不需要返回返回关系,可以简写为第二种格式
type(r) 返回r的类型 - **Match(p1:Person)<-[:FRIEND]-(p2) where id(p1) = 1 return p1,p2根据关系逆向查找节点,寻找FRIEND是p1的节点 , p1节点的id等于1. 根据箭头指向方向决定逆向和顺向。
- MATCH(p:Person)-[:r1]->(s:School)<-[:r2]-(p2:Person) return p,p2,s
查询p节点对应r1关系下的节点s和s存在关系r2的节点p2(如果r1是study,r2是teaching,那么就是 查询Person就读的学校s的授课Person) - Match(p:Person)-[:Study | :Teaching]->(s:School) return p,s;
查询多种关系,查询Person 中在School Study 或者Teaching 的节点 MATCH(p:Persion)-[:Study*1..3]-(s:School) where id(p)=1 return p,s;
深度关系查询 *1..3 表示查询关系的深度, 该语句的意思为 查询 和p同样就读过s学校的Person就读的其他学校信息,也就是和p就读的学校有关系的节点, 查询结果见左图,数据库中关系见右图。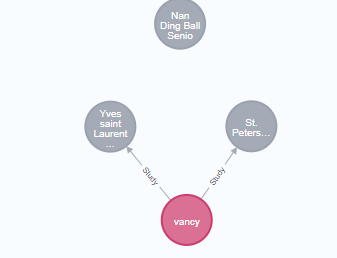
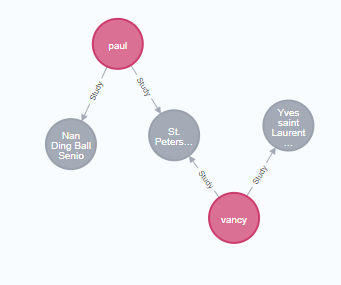 vancy 即 P 节点, Vancy 就读于 ST学校,paul也曾就读于St学校,另外paul还就读了Nan学校,关系第一级 为St节点,第二级为 paul节点,第三级为 Nan,此处查询为3级,所以查询结果会显示 Nan节点。
vancy 即 P 节点, Vancy 就读于 ST学校,paul也曾就读于St学校,另外paul还就读了Nan学校,关系第一级 为St节点,第二级为 paul节点,第三级为 Nan,此处查询为3级,所以查询结果会显示 Nan节点。
另:如果数值不做限定就是匹配所有层级的关系 ,如[:Study*] 的写法OPTIONAL MATCH
1.match (a) where a.name = ‘vancy’ optional match (a)<-[:FRIEND]-(x) return a,x;
2.match (a)<-[:FRIEND]-(x) where a.name = ‘vancy’ return a,x;
对于语句1 ,会找到Vancy 节点,如果没有找到FRIEND为vancy的节点x,那么x返回null,a返回vancy
- Match (p:Person) where id(p) = ? and p.name= ? return p,labels(p) order by id(p) desc limit 10;
对于语句2,如果没有找到FRIEND为vancy的节点,a,x 均返回null
optional match 操作类似于SQL 外连接,主数据的正常显示,副数据未查询到就以null显示
- **With 聚合查询<br />match (a) WITH a,toUpper(a.name) AS uname where uname = 'VANCY' return a;<br />**_对属性name 大写,然后再进行条件匹配_<br />**Match (a:Person)-[:FRIEND]->(b) WITH b,count(*) AS countNum where countNum >=2 return b,countNum;<br />**_查询朋友总数大于等于2人的节点b , 并显示 b的朋友总数<br />**注意**,和Group by 一样, with 后面跟的是聚合的对象,所以return时也只能显示 with后的对象<br />_****_Skip + Limit 可以达到分页的效果_**
练习 :
1.创建一个节点p(姓名 vancy,年龄 18,教育程度 初中,性别 女),并且p是 已经存在的节点 n(n的id为180)的FRIEND.
2.vancy 就读于(Study) Yves saint Laurent high School, 并且是高二学生在读。创建关系 Study, 创建节点s:School (名称:Yves saint Laurent high School,地址:地球)
3.创建关系Teaching , nancy任教于(Teaching)Yves saint Laurent high School,授课课程是生物。
4.p曾就读于Petersburg middle school,毕业成绩为A(95).
5.查询Jack的朋友圈中和Jack姓名相同的人
学习 【relationships】,【shortestPath】 方法
1.match(n:Persion) where id(n) = 180 create (p:Persion{name:’vancy’,age:18,edu:’middle school’,sex:’male’})-[:FRIEND]->(n) return p;
2.Match(p:Persion) where id(p)= 181 create (p)-[r:Study{level:3,status:’readed’,score:’A(95)’}]->(s:School{name:’St. Petersburg middle school’,address:’Earth’}) return p,s,r

若有收获,就点个赞吧
0 人点赞
