代码地址:git@github.com:pengbiaobeyond/kafka.git
kafaka为追求高吞吐量而设计,性能较好,可支持无线扩容。大量应用于大数据中连接应用系统与hadoop记录各种日志进行实时或者离线分析,但是Broker并不保存消费者状态,所以可靠性比较差;
1、概念:
在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统。
Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务
2、优点:
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
3、kafafa相关名称:
Broker:Kafka节点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群
Topic:一类消息,消息存放的目录即主题,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发
massage: Kafka中最基本的传递对象。
Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列
Segment:partition物理上由多个segment组成,每个Segment存着message信息
Producer : 生产者,生产message发送到topic
Consumer : 消费者,订阅topic并消费message, consumer作为一个线程来消费
Consumer Group:消费者组,一个Consumer Group包含多个consumer
Offset:偏移量,理解为消息partition中的索引即可
4、kafafa环境搭建:
kafka_2.13-2.4.0.tgz
1. 解压安装包tar -zxvf zookeeper-3.4.10.tar.gz2. 重新命名mv zookeeper-3.4.10 zookeepercd /usr/local/zookeeper/confmv zoo_sample.cfg zoo.cfg修改conf: vi zoo.cfg 修改两处(1) dataDir=/usr/kafka/zookeeper/data(注意同时在zookeeper创建data目录)(2)最后面添加server.0=192.168.212.174:2888:3888server.1=192.168.212.175:2888:3888server.2=192.168.212.176:2888:3888每台zk服务器节点,创建服务器标识创建文件夹: mkdir data创建文件myid并填写内容为0: vi myid (内容为服务器标识 : 0)关闭每台服务器节点防火墙,systemctl stop firewalld.service启动zookeeper:路径: /usr/local/zookeeper/bin执行: zkServer.sh start(注意这里3台机器都要进行启动)状态: zkServer.sh status(在三个节点上检验zk的mode,一个leader和俩个follower)
tar -zxvf kafka_2.11-1.0.0.tgz
mv kafka_2.12-0.11.0.0 kafka
vi ./kafka/config/server.properties
broker.id=0
listeners=PLAINTEXT://192.168.131.130:9092
zookeeper.connect=192.168.212.164:2181,192.168.212.167:2181,192.168.212.168:2181
其他两台只需要修改server.properties中的broker.id分别为 1 ,2
1、开启3台虚拟机的zookeeper程序
/usr/local/zookeeper/bin/zkServer.sh start
开启成功后查看zookeeper集群的状态
/usr/local/zookeeper/bin/zkServer.sh status
出现Mode:follower或是Mode:leader则代表成功
2、在后台开启3台虚拟机的kafka程序(cd /usr/local/kafka)
./bin/kafka-server-start.sh -daemon config/server.properties
3、在其中一台虚拟机(192.168.131.130)创建topic
/usr/local/kafka/bin/kafka-topics.sh --create –zookeeper 192.168.212.131:2181 –replication-factor 3 –partitions 1 –topic my-replicated-topic
// 查看创建的topic信息
/usr/local/kafka/bin/kafka-topics.sh –describe –zookeeper 192.168.212.132:2181 –topic my-replicated-topic
5、Springboot项目整合:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.4.RELEASE</version>
<relativePath/>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.10</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.72</version>
</dependency>
</dependencies>
server:
port: 9092
spring:
kafka:
bootstrap-servers: 192.168.66.6:9092,192.168.66.7:9092,192.168.66.8:9092
consumer:
groupId: myGroup
keyDeserializer: org.apache.kafka.common.serialization.StringDeserializer
valueDserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
groupId: myGroup
keyDeserializer: org.apache.kafka.common.serialization.StringSerializer
valueDserializer: org.apache.kafka.common.serialization.StringSerializer
kafka:
topics:
- name: topic11
num-partitions: 3
replication-factor: 1
- name: topic21
num-partitions: 1
replication-factor: 1
- name: topic31
num-partitions: 2
replication-factor: 1
@Component
@ConfigurationProperties(prefix = "kafka")
@Getter
@Setter
public class TopicConfiguration {
private List<Topic> topics;
@Autowired
private GenericWebApplicationContext genericContext;
@PostConstruct
public void init(){
initializeBeans(topics);
}
private void initializeBeans(List<Topic> topics) {
topics.forEach(t -> genericContext.registerBean(t.name, NewTopic.class, t::toNewTopic));
}
@Setter
@Getter
@ToString
static class Topic {
String name;
Integer numPartitions = 3;
Short replicationFactor = 1;
NewTopic toNewTopic() {
return new NewTopic(this.name, this.numPartitions, this.replicationFactor);
}
}
}
@RestController
@SpringBootApplication
@EnableKafka
public class KafkaController {
/**
* 注入kafkaTemplate
*/
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 发送消息的方法
*
* @param key 推送数据的key
* @param data 推送数据的data
*/
private void send(String key, String data) {
// topic 名称 key data 消息数据
kafkaTemplate.send("topic11", key, data);
}
private void sendMsg(String data) {
// topic 名称 key data 消息数据
kafkaTemplate.send("topic11", data);
}
/**
* 有回调---confirm机制
* @param msg
*/
public void kafkaProducer(String msg) {
// TODO Auto-generated method stub
ListenableFuture<SendResult<String, String>> listen = kafkaTemplate.send(/*config.getTopic()*/"", msg);
// logger.info("sendTopic: "+config.getTopic());
listen.addCallback(new ListenableFutureCallback<SendResult<String, String>>(
) {
@Override
public void onSuccess(SendResult<String, String> result) {
// TODO Auto-generated method stub
// logger.infof("发送底层Kafka消息{}成功!", msg);
}
@Override
public void onFailure(Throwable ex) {
/*logger.errorf("发送底层Kafka消息{}失败!", ex.getMessage());*/
}
});
}
// test 主题 1 my_test 3
@RequestMapping("/kafka")
public String testKafka() {
int iMax = 10;
for (int i = 1; i < iMax; i++) {
send("key" + i, "data" + i);
}
return "success";
}
@RequestMapping("/getOrderKafka")
public String getOrderKafka() {
String orderId = System.currentTimeMillis() + "";
// 无序
// sendMsg(getSqlMsg("insert", orderId));
// // 发送Updatemsg
// sendMsg(getSqlMsg("update", orderId));
// // 发送deletemsg
// sendMsg(getSqlMsg("delete", orderId));
// 有序
send(orderId, getSqlMsg("insert", orderId));
// 发送Updatemsg
send(orderId, getSqlMsg("update", orderId));
// 发送deletemsg
send(orderId, getSqlMsg("delete", orderId));
return "success";
}
public String getSqlMsg(String type, String orderId) {
JSONObject dataObject = new JSONObject();
dataObject.put("type", type);
dataObject.put("orderId", orderId);
return dataObject.toJSONString();
}
public static void main(String[] args) {
SpringApplication.run(KafkaController.class, args);
}
/**
* 消费者使用日志打印消息
*/
// @KafkaListener(topicPartitions = {@TopicPartition(topic = "mayikt", partitions = {"0"})})
// @KafkaListener(topics = {"${kafka.topic.topic-test-transaction}"}, id = "bookGroup")
@KafkaListener(topics = {"topic11"})
public void receive(ConsumerRecord<?, ?> consumer) {
System.out.println("topic名称:" + consumer.topic() + ",key:" +
consumer.key() + "," +
"分区位置:" + consumer.partition()
+ ", 下标" + consumer.offset() + ",msg:" + consumer.value());
}
}
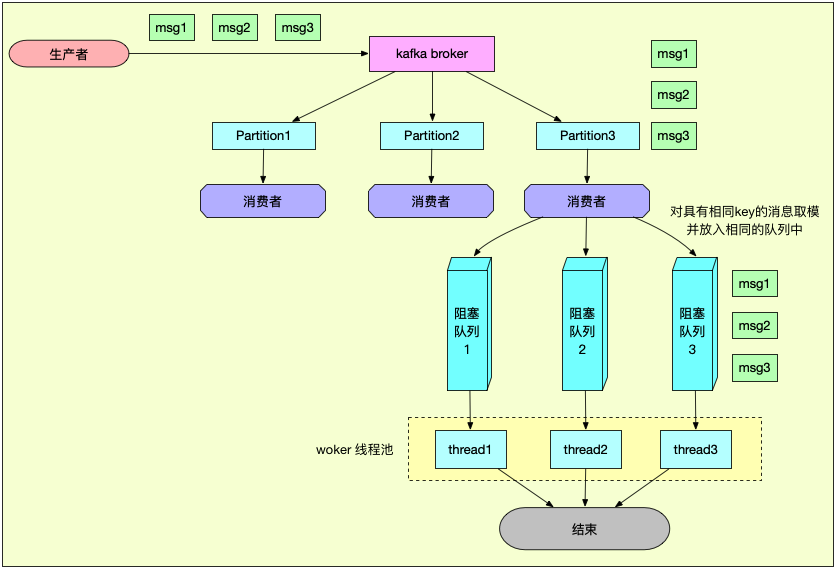
5、怎样保证顺序消费:
就像我们上边那张图片看到的一样,如果我们需要保证消费者消费消息的有序性,则我们需要在发送消息的时候,将有序消息发送时设置相同的路由可以,则将可以发送到相同的broker,然后选择集群中的某个消费者去消费,每个消费者都可能有多个内存队列,则将key值取余内存队列的数量然后有序的消息就进入到了相同的队列中,每个队列对饮一个线程去消费,这样就保证了消费的有序性;
其实recketmq保证消息的有序性也是相似的,也是依据路由key然后发送到不同内存队列中,然后每个内存队列只对应一个线程去消费;
6、 Kafka如何保证高吞吐量
1. 支持顺序读写实现数据存储
2. 支持批量投递和获取消息 频繁读写io
传统方式消息如何投递:
在1s内有1万消息,循环遍历1万次投递消息到MQ中;非常浪费服务器内存
异步批量投递 可能会丢失
3. 采用零拷贝机制
4. 采用分区存放消息
5. 对我们消息实现压缩 减少服务器带宽传输

若有收获,就点个赞吧
0 人点赞
