课程链接
tensorflow2.0入门与实战 2019年最通俗易懂的课程
目录
- 1 课程简介
- 2 机器学习原理—线性回归
- 3 tf.keras实现线性回归
- 4 梯度下降算法
- 5 多层感知器(神经网络)与激活函数
- 6 多层感知器(神经网络)代码实现
- 7 逻辑回归和交叉熵
- 8 逻辑回归实现
- 9 softmax分类
- 10 softmax代码实现-FashionMnist数据分类实例
- 11 热独编码与交叉熵损失函数
- 12 优化函数、学习速率、反向传播算法
- 13 网络优化和超参数选择
- 14 Dropout抑制过拟合和网络参数选择总原则
- 15 Dropout和过拟合抑制
- 16 函数API和多输入输出模型
- 17 Tensorflow系统知识学习安排
1 课程简介
tf.keras 是构建和训练模型的核心高阶API
(一)单输入单输出的Sequential顺序模型
函数式API
(二)Eger模式与自定义训练
直接迭代和直观调试,Eager模式下求解梯度与自定义训练
(1)Eager模式
直接迭代和直观调试
(2)tf.GradientTape
求解梯度,自定义训练逻辑
(三)tf.data
加载图片数据与结构化数据
(四)介绍tf.function
自动图运算
(五)卷积神经网络
(六)多输出卷积神经网络综合实例
(七)迁移学习
2 机器学习原理—线性回归
(1)查看tensorflow的版本
print(tf.__version__)
(2)读取数据集
import pandas as padata = pd.read_csv('./dataset/Income1.csv')data
(3) 绘图
import matplotlib.pyplot as plt% matplotlib inlineplt.scatter(data.Education,data.Income)
(4)成本函数和损失函数的设计
成本函数
成本函数使用均方误差(f(x)-y)
优化方法:梯度下降的方法
3 tf.keras实现线性回归
x = data.Eductiony = data.Incomemodel = tf.keras.Squential()model.add(tf.keras.layers.Dense(1,input_shape= (1,)))# 第一个1表示输出的维度。 shape里面的1表示输入 的数据维度是1,因为输入的x是一个变量model.summary()# 输入模型的形状,其中dense层中output shape的第一个维度表示样本的个数model.compile(optimizer='adam',#编译。使用梯度下降优化方法loss = 'mse')#使用均方误差方法作为损失函数history = model.fit(x,y,epochs = 5000)#开始训练,训练次数是5000次model.predict(x)#预测结果,x是预测已知的值model.predict(pd.Series(20))#预测20对应的的y.pd.Series是改变格式数字格式
4 梯度下降算法
梯度下降法是一种致力于找到函数极值点的算法。
梯度的输出向量表明了在每个位置损失函数增长最快的方向,可将它视为表示在函数的每个位置向哪个方向移动函数值可以增长。
损失函数 :Z = (f(x)-y)/n
5 多层感知器(神经网络)与激活函数
(1)单个神经元(二分类)

(2)多个神经元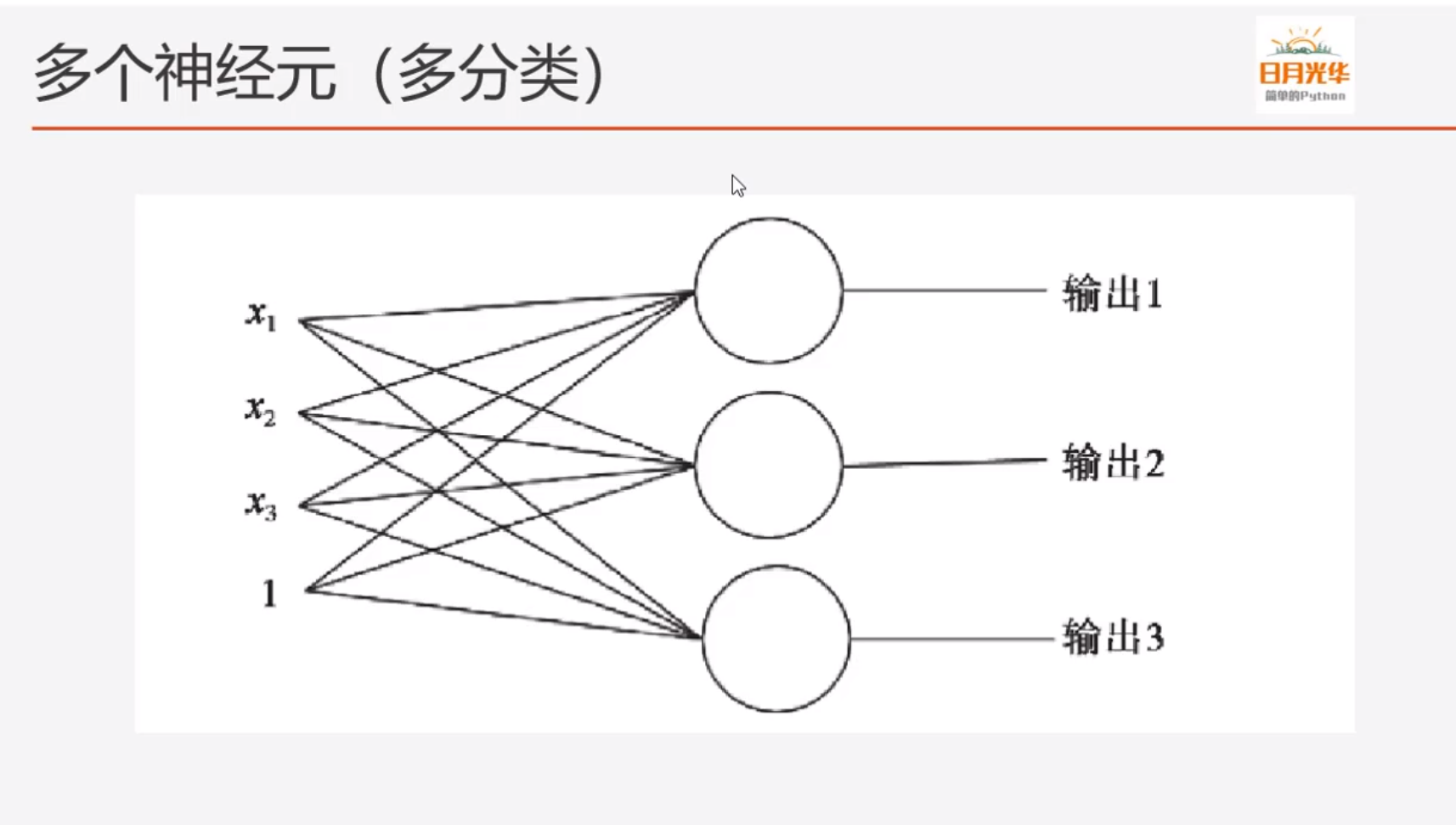
(3)单层神经元的缺陷
- 无法拟合“异或”运算,异或问题看似简单,使用单层的神经奥运确实没有办法解决
- 神经元要求数据必须是线性可分的
- 异或问题无法找到一条直线分割成两个类
(4)神经元的启发
(5)多层感知器
生物的神经元一层一层连接起来,当神经网络信道达到某一个条件,这个神经元就会激活,然后继续传递信息下去,为了继续使用神经网络解决这种不具备线性可分性的问题,采取在神经网络的输入端和输出端之间插入更多的神经元。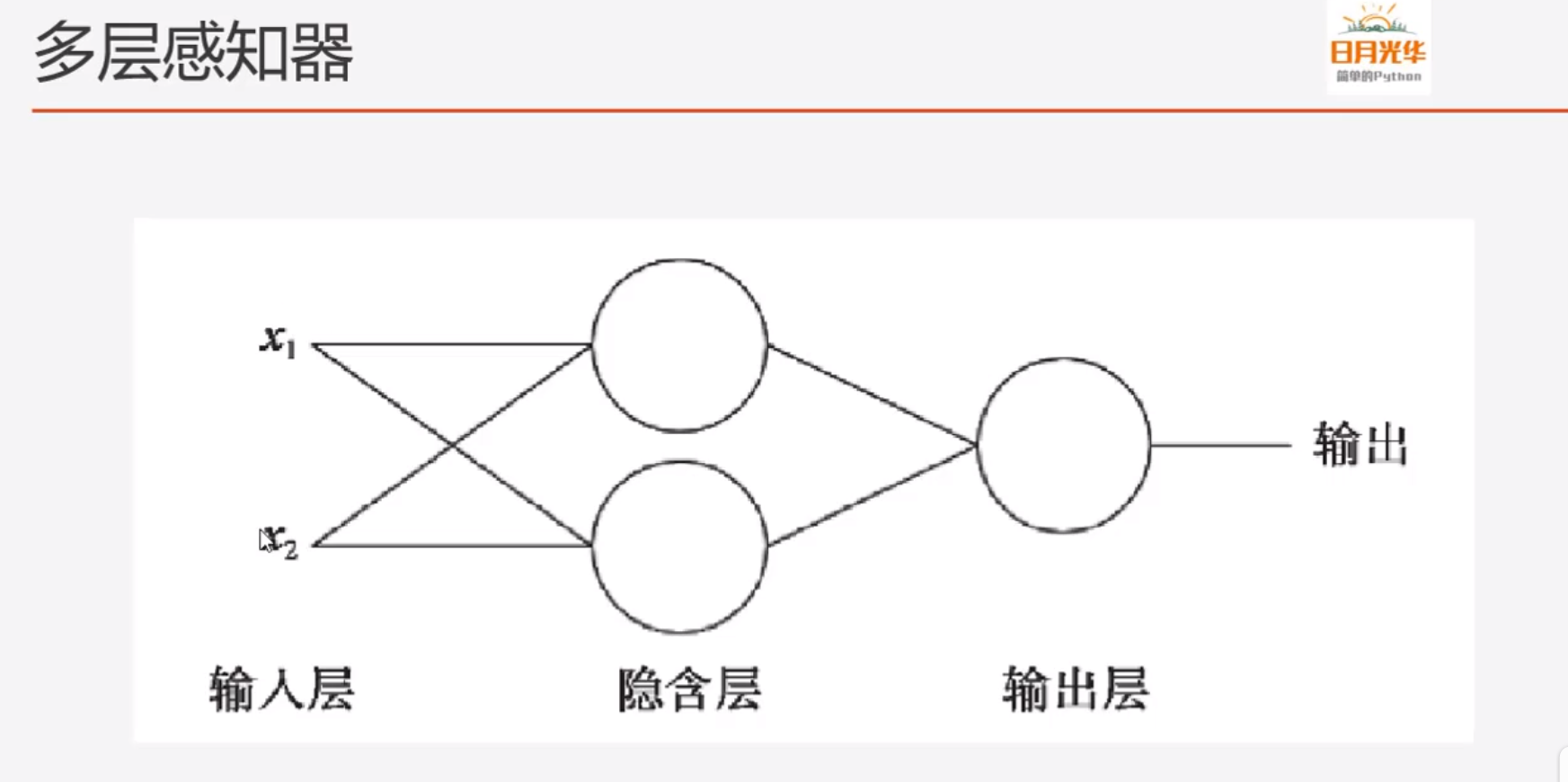
(6)激活函数
- relu激活函数

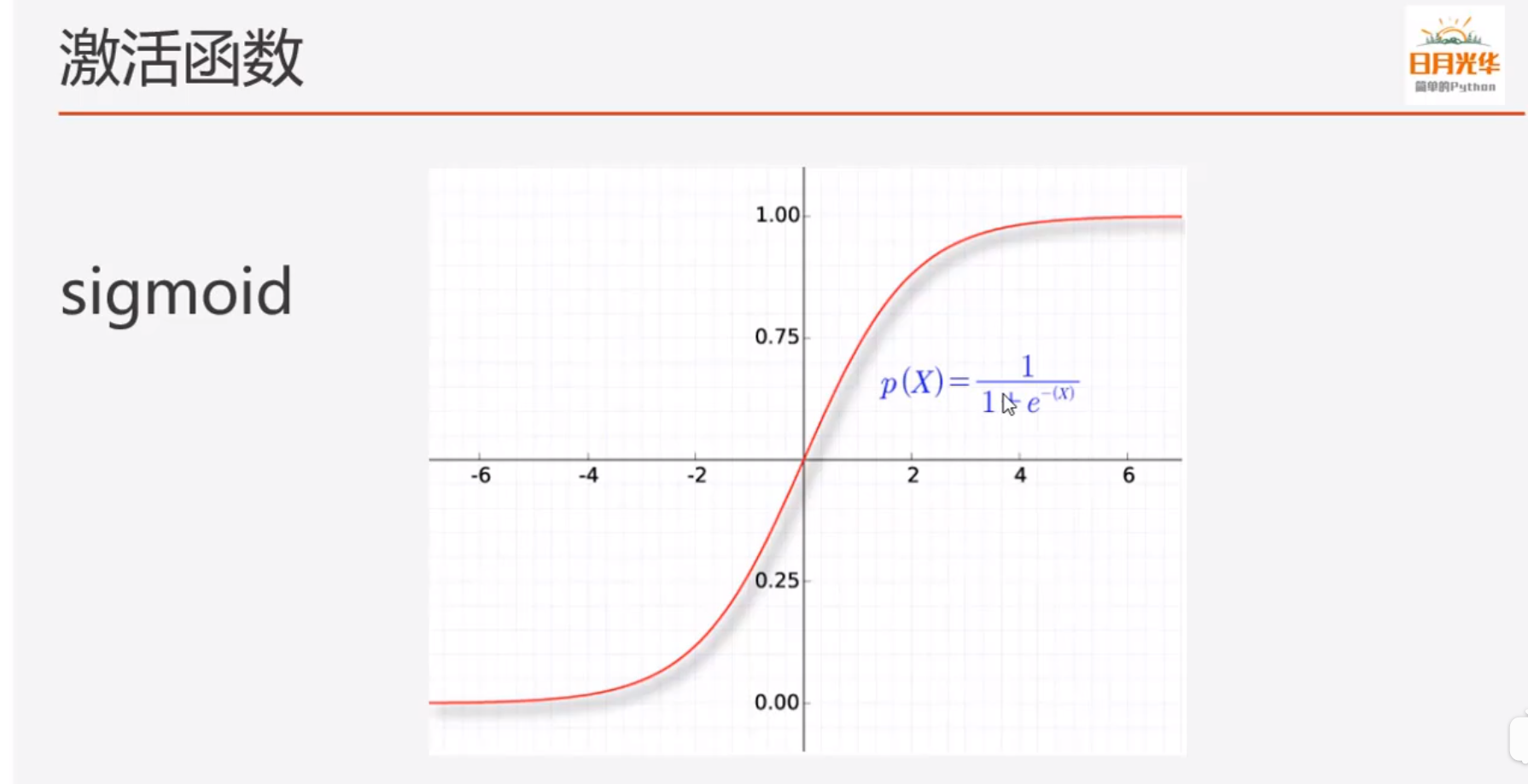
- sigmod激活函数
- tanh激活函数(-1~1)

- leak relu
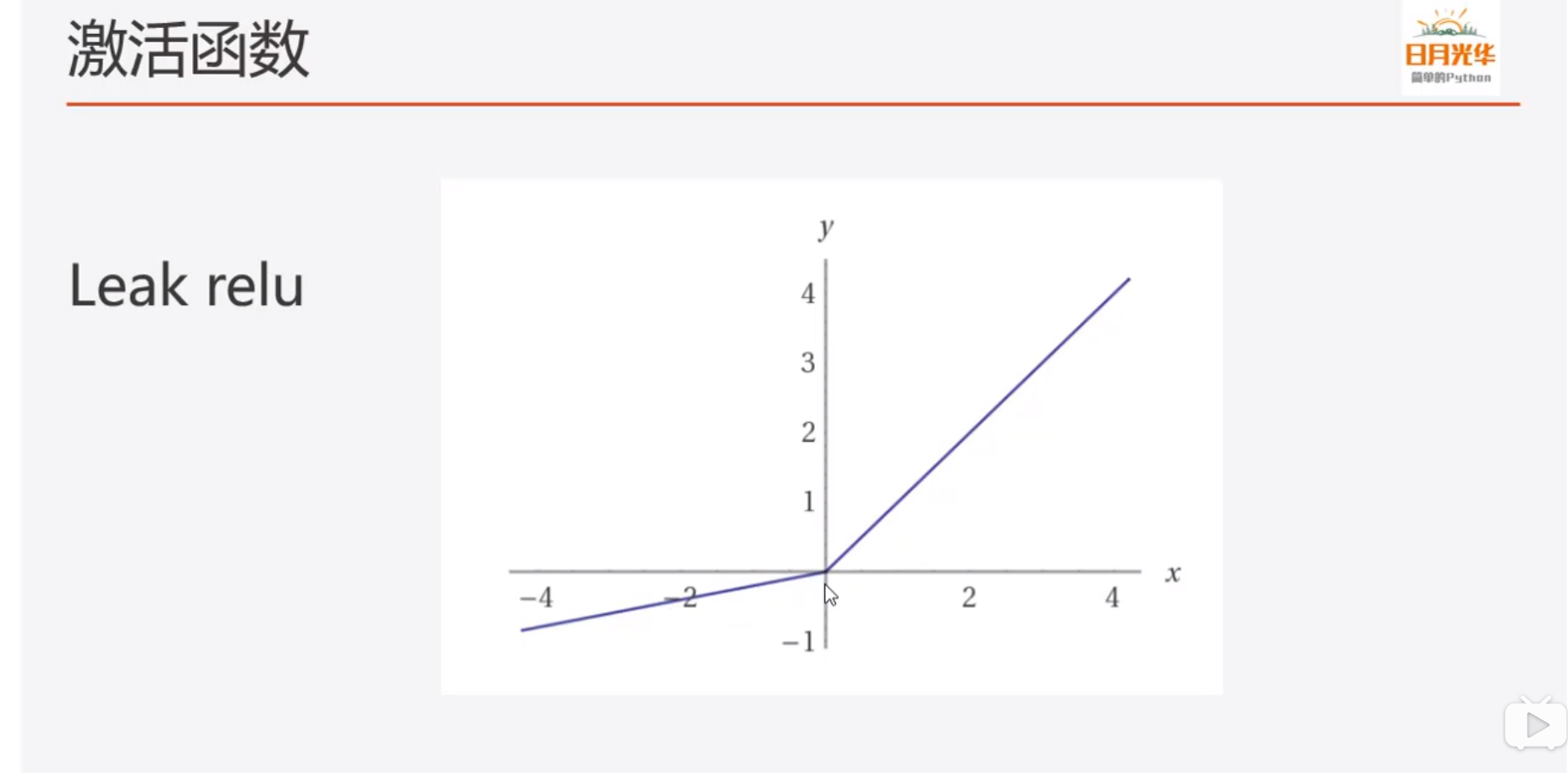
一般用在生存网络中
6 多层感知器(神经网络)代码实现
import tensorflow as tfimport pandas as paimport numpy as npimport matplotlib.pyplot as pltdata = pa.read_csv('/dataset/Adverising.csv')data.head()# 显示数据表的表头plt.scatter(data.TV,data.sales)plt.scatter(data.newspaper,data.sales)x = data.iloc[:,1:-1]# 取所有行,列取出去第一列到负一列。其他都取y = data.ilot[:,-1]#取最后一列model = tf.keras.Squential([tf.keras.layers.Dense(10,input_shape(3,),activation = 'relu'),tf.keras.layers.Dense(1)])# 10表示隐层神经元个数,3表示输入的维度,最后一个Dense中的1表示输出维度是1model.summary()model.complie(optimizer ='adam'loss ='mse')model.fit()#训练Htest = data.iloc[:10,1:-1]#取前十个数据model.predict(test)
7 逻辑回归和交叉熵
(1)逻辑回归的概念:线性回归越策是是一个连续值,逻辑回归给出的“是”和“否”的回答
sigmod函数是一个概率分布函数
(2)逻辑回归损失函数
平方差所惩罚的是与损失为同一数量级的情形。对于分类问题,我们最好的使用交叉熵损失函数会更有效,交叉熵会输出一个更大的损失。
(3)交叉熵损失函数
交叉熵刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近,假设概率分布为p为期望输出,概率分布q为实际输出,H(p,q)为交叉熵。则
在keras中,我们使用binary_crossentropy来计算二元交叉熵
8 逻辑回归实现
import tensorflow as tfimport pandas as paimport numpy as npimport matplotlib.pyplot as pltdata = pa.read_csv('/dataset/credit-a.csv')data.head()# 显示数据表的表头+前五行data.ilot[:,-1].value_counts()#计算值有多少航x = data.iloc[:,:-1]y = data.iloc[:,-1].replace(-1,0)#把数据里的-1替换成0model = tf.keras.Sequetntial()model.add(tf.keras.layers.Dense(4,input_shape = (15,),activation = 'relu'))#4表示隐藏层神经元数目,15表示输入的数据有15列model.add(tf.keras.layers.Dense(4,activation = 'relu'))#第二个隐藏层model.add(tf.keras.layers.Dense(1,activation = 'sigmod'))#第三个隐藏层。逻辑回归的需要model.compile(optimizer = 'adam',loss = 'binary_crossentropy'metrics = ['acc'])#运行过程中会显示正确率history = model.fit(x,y.epochs = 100)history.history.keys()#打印出有哪些列会显示,在这里是loss和acc两列的数据会显示plt.plot(history.epoch,history.history.get('loss'))#绘制loss的曲线图plt.plot(history.epoch,history.history.get('acc'))#绘制准确率的曲线图
9 softmax分类
(1)softmax介绍
对数几率回归解决的是二分类问题,对于多个选项的问题,我们可以使用softmax函数,它是对数几率回归在N个可能不同的值上的推广。
神经网络的原始输出不是一个概率值,实质上知识输入端数值做了复杂的加权和与非线性处理之后的一个值而已,softmax的作用就是将它的输出变为概率分布。
softmax要求每个样本必须属于某个类别,且所有可能的样本均被覆盖。softmax样本分量之和为1,当只有两个类别时,与对数几率回归完全相同。
(2)tf.keras交叉熵
在tf.keras里面,对于多分类问题我们使用categorical_crossentropy和sparse_categorical_crossentropy来计算sofamax交叉熵。
- 在softmax的分类网络中,当输出的是分类用数字表示的时候,用sparse_categorical_crossentropy交叉熵
- 采用one-hot热独编码时才采用categorical_crossentropy
(3)Fashion MNiST数据集
Fashion MNIST的作用是成为经典MNIST数据集的简易替换。比常规MNIST手写数据集更有挑战性,这两个数据集相对较小,用于验证某个算法能够如期正常运行,它们都是测试和调试代码的良好起点。包含70000张灰度图像,涵盖了10个类别。
我们将使用6000张训练网络,10000张测试准确率。可以从TensorFlow直接访问Fashion MNIST,只需要导入数据即可。
import tensorflow as tf
import pandas as pa
import numpy as np
import matplotlib.pyplot as plt
#一般下载会很慢,建议从其他地方下载。放到:用户/keras/datasets下
(train_image,train_label) ,(test_image,test_label) = tf.keras.datasets.fashion_mnist.load_data()#加载数据集
10 softmax代码实现-FashionMnist数据分类实例
# 续以上的代码
plt.imshow(train_image[0])
#查看最大值
np.max(train.image[0])
#归一化数据
train_image = train_image/255
test_image = test_image/255
# 打印训练集的大小
train.image.shape
#建立模型
model = tf.keras.Squential()
#扁平化数据,改变维度
model.add(tf.keras.layers.Flatten(input_shape =(28,28)))#变成28× 28的向量
model.add(tf.keras.layers.Dense(128,activation = 'relu'))'
model.add(tf.keras.layers.Dense(10,activation = 'softmax'))#把10个输出变成概率分布
# 训练
# 在softmax的分类网络中,当输出的是分类用数字表示的时候,用sparse_categorical_crossentropy交叉熵
# 采用one-hot编码时才采用categorical_crossentropy
model.compile(optimizer = 'adam',loss = 'sparse_categorical_crossentropy',
matrics = ['acc'])
model.fit(train_image,train_label,epochs = 50)
# 测试准确率
model.evluable(test_image,test_lable)
11 热独编码与交叉熵损失函数
# 续以上代码
# 转onehot编码
train_label_onehot = tf.keras.utils.to_categorical(train_label)
train_label_onehot[-1]
test_label_onehot = tf.keras.utils.to_categorical(test_label)
#建立模型
model = tf.keras.Squential()
#扁平化数据,改变维度
model.add(tf.keras.layers.Flatten(input_shape =(28,28)))#变成28× 28的向量
model.add(tf.keras.layers.Dense(128,activation = 'relu'))'
model.add(tf.keras.layers.Dense(10,activation = 'softmax'))#把10个输出变成概率分布
# 训练
# 在softmax的分类网络中,当输出的是分类用数字表示的时候,用sparse_categorical_crossentropy交叉熵
# 采用one-hot编码时才采用categorical_crossentropy
# 这里是使用的是one-hot编码
model.compile(optimizer = 'adam',loss = 'categorical_crossentropy',
matrics = ['acc'])
model.fit(train_image,train_label_onehot,epochs = 50)
# 测试准确率
model.evluable(test_image,test_label_onehot)
# 预测
predict = model.predict(test_image)
# 预测结果的矩阵大小
predict.shape
# 打印第一个预测样本的概率分布
predict[0]
# 显示第一个测试样本中,预测最大概率的数
np.max(predict[0])
# 打印真实的结果
test_label[0]
12 优化函数、学习速率、反向传播算法
(1)学习速率
梯度:表明损失函数相对参数的变化率
学习速率:对梯度进行缩放的参数,是一种超参数(手工配置的)
学习速率的选取:可通过查看损失函数值随时间的变化曲线来判断学习速率的选取是否合适。合适的学习速率,损失函数随着时间会下降,直到一个底部不合适的学习速率,损失函数可能会发生震荡。
(2)反向传播算法
是一种高效计算数据流图中梯度的技术,每一层的导数都是后一层的导数与前一层输出之积,这正是链式法则的奇妙之处,误差反向传播算法利用的正是这一特点。前馈时,从输入开始,逐一计算每个隐含层的输出,知道输出层。然后开始计算导数,并从输出层经各层隐含层逐一反向传播,为了减少计算量,还需对所有已经完成计算的元素进行复用。
(3)常见的油画函数
优化器(optimizer)是编译模型的所需的两个参数之一。你可以先实例化一个优化器对象,然后将它传入model.compile(),或者你可以通过名称来调用优化器,在后一种情况下,将使用优化器的默认参数。
- SGD:随梯度下降优化器;随梯下降优化器SGD和mini-batch是同一个意思,抽取m个小批量(独立同分布)样本,通过计算他们平梯度均值
- RMsprop:经验上,有效且使用的深度学习网络优化算法。增加了一个衰减系数来控制历史信息的获取多少,会对学习率进行衰减。
- Adam:可以看做是修正后的Momentum+RMSProp算法,通常被认为对超参数的选择相当鲁棒。学习率建议为0.001。是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重。Adam通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
#lr表示学习速率
# 使用不同的优化器:tf.keras.optimizer....
model,compile(optimizer = 'tf.keras.optimizer.Adam(lr = 0.01),
loss = 'categorical_crossentropy',
matrics = ['acc']
)
13 网络优化和超参数选择
(1)网络容量
网络中的神经元越多,层数越多,神金网络的拟合能力越强,但是训练速度、难度越大、越容易产生过拟合
(2)如何选择超参数
超参数:就是搭建神经网络中,需要我们自己做选择的哪些参数(不是通过梯度下降算法去优化的),比如神经元个数、学习速率
(3)如何提高网络的拟合能力
- 增加层
- 增加隐层神经元个数
单纯的增加神经元个数对于网络性能没有显著提高,增加层会大大提高拟合能力。单层的神经元个数不能太小,太小的话,会造成信息瓶颈,使得模型欠拟合。
14 Dropout抑制过拟合和网络参数选择总原则
(1)过拟合:在训练集数据上得分很高,但是在测试集上相对得分很低
欠拟合:训练数据集得分很低,测试集得分也很低
history = model.fit(train_image,train_label_one_hot,epochs = 10
validation_data = (test_image,test_label_onehot)#添加验证集
)
# 绘制训练集和测试集的损失曲线
plt.plot(history.epoch,history.history.get('loss'),label ='loss')
plt,plot(history.epoch,history.history.get('val_loss'),label='val_loss')
polt.legend()
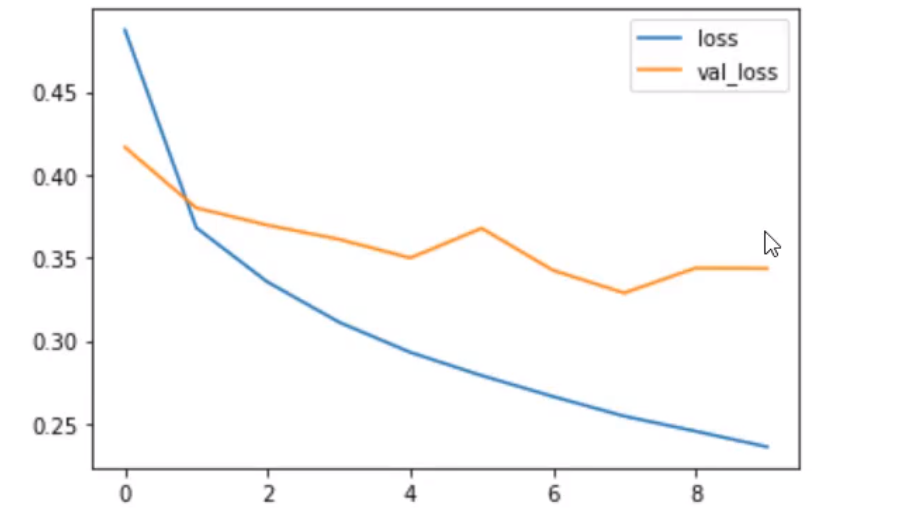
图片中,黄色的测试集的损失随着训练,还上升了,这是过拟合的表现。
plt.plot(history.epoch,history.history.get('acc'),label ='acc')
plt,plot(history.epoch,history.history.get('val_acc'),label='val_acc')
polt.legend()

图中训练集和测试集的准确率差距逐渐增大也是一种过拟合 的表现。
(2)dropput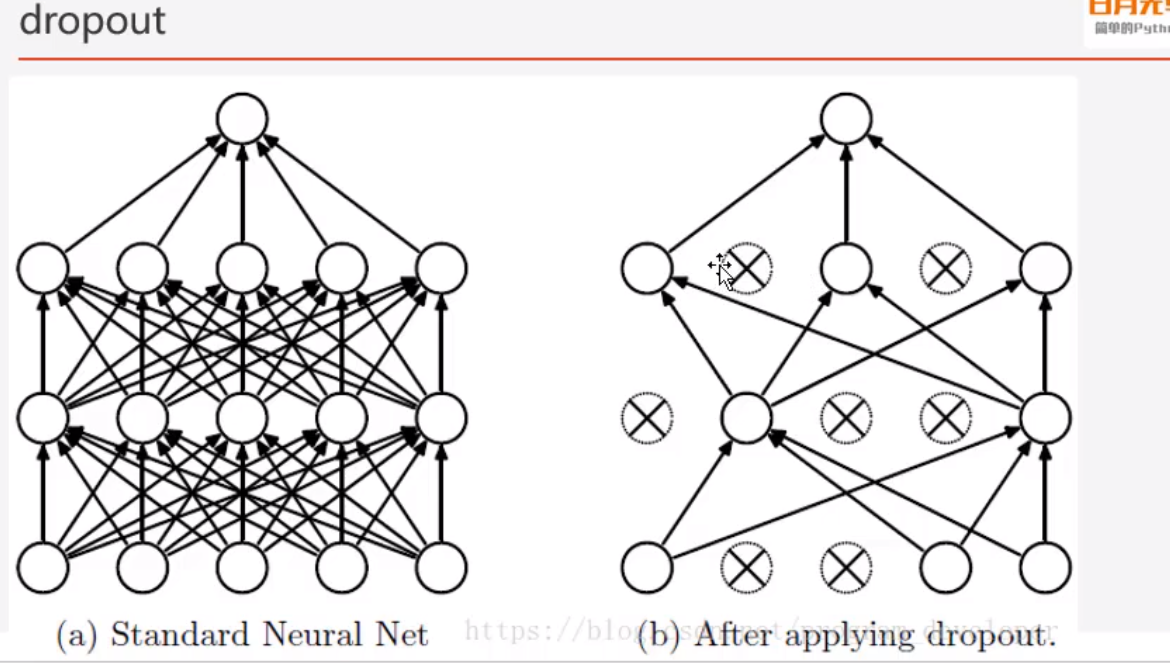
(3)为什么dropout能够解决过拟合
- 取平均的作用:先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到五个不同的结果,此时我们可以采用“5个结果均值”或“多数取胜的投票策略”去决定最终结果。
- 减少神经元之间复杂的共适应关系,因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不在依赖于有固定关系的隐含节点的共同作用。阻止了某些特征仅仅在其他特定特征下才有效果的情况。
(4)参数选择原则
首先开发一个过拟合的模型
- 添加更多的层
- 让每一层变得更大
- 训练更多的轮次
然后抑制过拟合
- dropout
- 正则化
- 图像增强
再次调节超参数
- 学习速率
- 隐藏层单元数
- 训练轮次
超参数的选择是一个经验不断测试的结果,经典机器学习的方法,如特征工程、增加训练数据要做交叉验证。
(5)构建网络的总原则
- 增大网络容量,直到过拟合
- 彩玉措施抑制过拟合
- 继续增大网络容量,直到过拟合
15 Dropout和过拟合抑制
model = tf.keras.Squential()
model.add(tf.keras.Flatten(input_shape = (28,28)))
model.add(tf.kereas.layers.Dense(128,activation = 'relu'))
model.add(tf.keras.Dropout(0.5))# 0.5表示丢失神经元的比例
model.add(tf.kereas.layers.Dense(128,activation = 'relu'))
model.add(tf.keras.Dropout(0.5))
model.add(tf.kereas.layers.Dense(128,activation = 'relu'))
model.add(tf.keras.Dropout(0.5))
model.add(tf.kereas.layers.Dense(128,activation = 'softmax'))
16 函数API和多输入输出模型
(1)函数式API实现神经网络模型
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
fashion_mnist = keras.datasets.fashion_mnist
(train_images,train_labels),(test_images,test_labels) = fashion_mnist.load_data()
train_images = train_images /255.0
test_images = test_images / 255.0
input = keras.Input(shape=(28,28))
x = keras.layers.Flatten()(input)#类似于调用input函数
x = keras.layers.Dense(32,activation = 'relu')(x)
x = keras.layers.Dropout(0.5)(x)
x = keras.layers.Dense(64,activation = 'relu')(x)
output = keras.layers.Dense(10,activation = 'softmax')(x)
model = keras.Model(inputs = input,outputs = output)
model.summary()
model,compile(optimizer ='adam',
loss = 'sparse_categorical_crossentropy',
matrics = ['accuracy']
)
history = model.fit(train_images,
train_labels,
epochs = 30,
validation_data = (test_images,test_labels))
test_loss,test_acc = model.evaluate(test_images,test_labels)
plt.plot(history.epoch,hisrory.history['loss'],'r',label ='loss')
plt.plot(history.epoch,hisrory.history['val_loss'],'r',label ='val_loss')
plt.legend()
# 判断两个图片是不是一个图片
input1 = keras.Input(shape=(28,28))
input2 = keras.Input(shape=(28,28))
x1 = keras.layers.Flatten()(input1)#类似于调用input函数
x2 = keras.layers.Flatten()(input2)#类似于调用input函数
x = keras.layers.concatenate([x1,x2])# 合并为一起
x = keras.layers.Dense(32,activation = 'relu')(x)
output = keras.layers.Dense(1,activation = 'sigmod')(x)
model = keras.Model(inputs =[intput1,input2],outputs = output)#两个输入,一个输出
17 Tensorflow系统知识学习安排
以上学习的是深度学习的一些基础和tf.keras的基本使用。接下来还有其他知识体系
- tf.data输入模块
- 计算机视觉-卷积神经网路
- tf.keras高阶API实例
- Eager模式月自定义训练
- Tensorboard可视化
- 自定义训练综合实例与图片增强
- 使用与训练网络(迁移学习)
- 多输出模型实例
- 模型保存与恢复
- 图像定位
- 自动图运算与GPU使用策略
- 图像语义分割
- RNN循环神经网络
- RNN徐磊预测实例-空气污染预测
- 使用免费的GPU加速训练
- 1.X版本课程

若有收获,就点个赞吧
0 人点赞
