1. Introduction
Shuffle is a key primitive in many data processing applica- tions. It is the foundation of the MapReduce model and large-scale data processing applications such as distributed sort.
The key challenge in large-scale shuffle is efficiently moving the large number of very small intermediate blocks from each mapper to each reducer.
First, designing and implementing a shuffle system is a sig- nificant developer effort, often impeding innovation.
Second, while shuffle systems are of course highly opti- mized for shuffle operations, they are not flexible in supporting other workloads. The semantics offered by a shuffle system are synchronous: the shuffle results can only be used once all reduce tasks complete.
The popular wisdom is that specialized systems are necessary for shuffle performance because of a fundamental trade- off between performance and flexibility. We show that this is not the case: distributed shuffle can be implemented as an application and with high performance and reliability using a generic distributed computing system.
In this paper, we show that with a task-based distributed futures abstraction, it is possible to: (1) express past optimizations such as push-based shuffle in a few hundred lines of purely application-level Python code, and (2) achieve fine-grained pipelining with downstream operations, such as for distributed training, without modifying the shuffle system.
What are the common problems encountered by shuffle systems? First, the shuffle system must manage distributed coordination between the mappers and reducers, to ensure that each intermediate block is moved to the appropriate reducer. Second, the shuffle system must manage intermediate blocks across memory, disk, and network. Finally, the shuffle system must ensure fault tolerance, i.e. each record in the input should appear in the output exactly once and failures should impede progress as little as possible.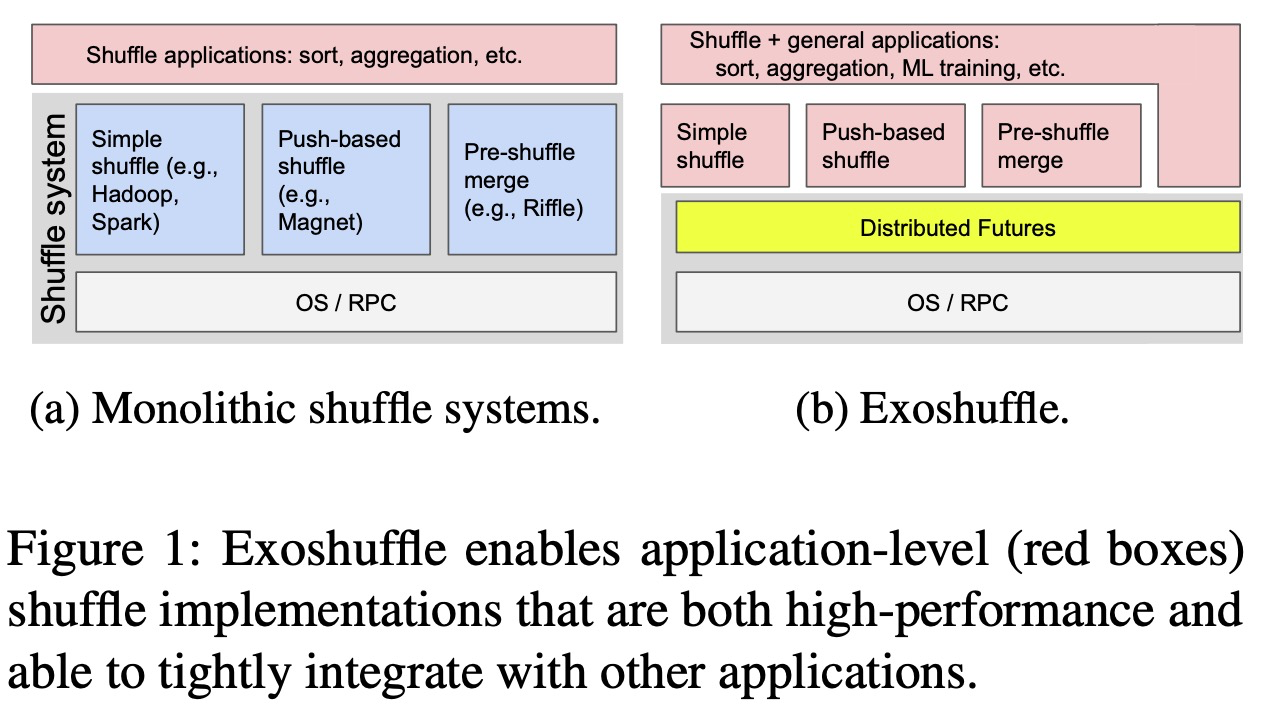
We identify the components of a distributed futures implementation that are necessary for shuffle performance and reliability. First, for coordination, we use a shared-memory object store that acts as an intermediary between the map and reduce tasks: map tasks store their outputs in the object store and reduce tasks retrieve their arguments from the object store. Second, for block management, the system orchestrates transparent data movement between the object store and local disk and across the network, to fulfill the task dependencies specified by the application(spill). The system also implements timely garbage collection to ensure object store availability. Finally, for fault tolerance, the system uses lineage reconstruction to ensure that each object is reachable.
Key Words: push-based shuffle, pipelining
2. Background
Identifying the common components of shuffle systems that can be factored out into distributed futures.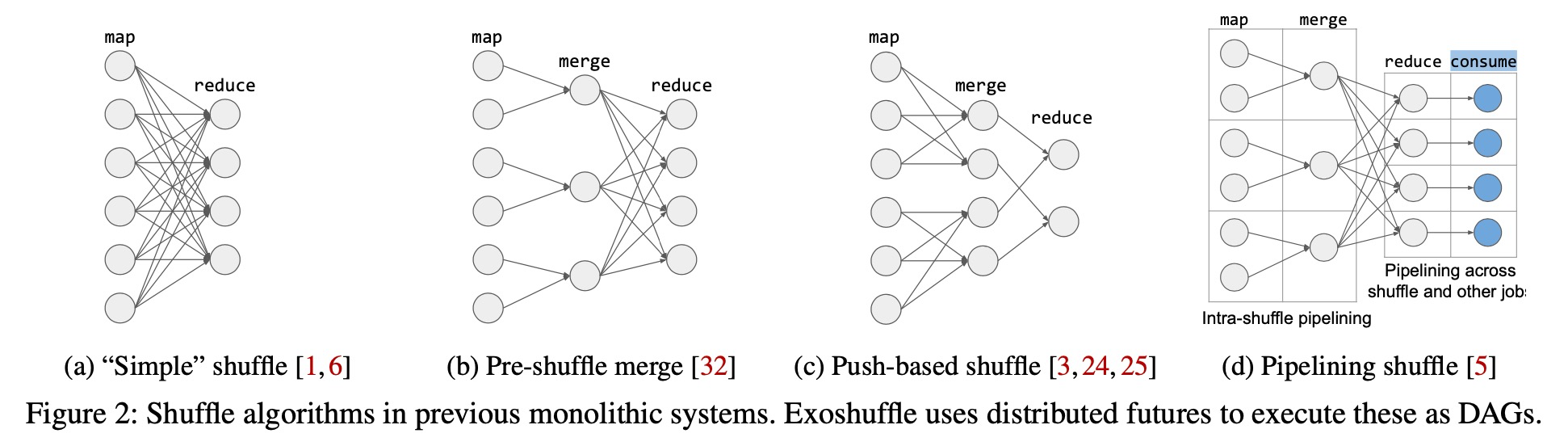
Distributed coordination
First, many shuffle systems merge shuffle blocks into larger ones to increase disk I/O efficiency. For example, Riffle merges map outputs that reside on the same mapper node, reducing the total number of blocks by a constant factor (Fig. 2b). Magnet and Cosco merge map outputs from different mapper nodes before the final reduce stage (Fig. 2c). All of these systems require additional external shuffle services and protocols to coordinate between the mappers, intermediate mergers, and reducers.
Meanwhile, with distributed futures, we can offload coordination between executors to the underlying system. The shuffle application uses distributed futures to express the optimizations studied in previous shuffle systems as task DAGs. For example, it can express Figures 2b and 2c by passing the distributed futures returned by a map task to an intermedi- ate merge task, then passing those outputs to a final reduce task (§3). The system is then responsible for fulfilling the dependencies in the resulting DAG.
Pipelining execution
Traditional shuffle is pull-based (Fig. 2a): reduce tasks only pull the shuffle blocks from the map tasks once the map stage is complete, which limits pipelining.
A common solution for pipelining execution and disk I/O is to increase task parallelism, allowing one task to write to disk while another executes. To pipeline network I/O, some systems use push-based shuffle. In this scheme, mappers push their outputs immediately to the reducers, where they can be partially merged on disk before the final reduce stage (Fig. 2c). Such pipelining is also valuable for overlapping shuffle tasks with other workloads, as shown in Figure 2d.
Furthermore, the use of distributed futures as a common interface enables interoperability with any other job that can consume a distributed future (Fig. 2d).
Note: It is not clear how to pipeline across shuffle and other job
Handling executor and network failures
First, similar to an external shuffle service, a distributed object store decouples the lifetimes of intermediate blocks and individual executors.
Second, in the case of an object store failure, the system can minimize interruptions by using lineage reconstruction, i.e. re-executing the DAG that created the lost object.
3. Shuffle With Distributed Futures
Showing how optimizations from previous monolithic shuffle systems can be expressed as applications.
3.1 Distributed Futures
We show that shuffle coordination, block management, and fault tolerance can be factored out into a common generic system for distributed memory management, much like RPC factors out remote task execution.
In this API, aprogram can invokemethods, knownastasks, that execute and return data on a remote node. When calling a remote function, instead of receiving the function’s return value directly, the caller receives a distributed future that represents the eventual return value.
3.2 Shuffle at the Application Level
3.2.1 Simple Shuffle

问题
map_out[:, r] for r range(R)中的 map_out[:, r] 表达有歧义,它表示的意思应该是取每个 map 的第 r 个 shuffle 的数据。
3.2.2 Pre-shuffle Merge

The key design of Riffle is merging map blocks locally first before they are pulled by the reducers.
For simplicity, the code assumes that the first F map tasks are scheduled on node 1, the next F map tasks on node 2, etc.
3.2.3 Push-based Shuffle
Push-based shuffle (Fig. 2c) is an optimization in shuffle blocks are pushed to the reducer nodes as soon as they are computed, rather than pulled to the reducer when they are required.
Magnet is a specialized shuffle service for Spark that performs this optimization by merging intermediate blocks on the reducer node before the final reduce stage. shuffle_magnet in Listing 2 implements this design.
3.3 Pipelining
The key aspect to achieving high performance shuffle is ensur- ing high utilization of all system components: CPU, memory, disk and network. This can be done by pipelining the tasks such that when one part of the system is busy (e.g. CPU is sorting and data is in memory), another part of the system could do work for another round of tasks (e.g. writing output to disk).
In Exoshuffle, the intra-shuffle pipelining shown in Figure 2d can be expressed at the application level by scheduling tasks in rounds, as shown in Listing 3.
The code skeleton in Listing 3 works for both the Riffle- and Magnet-style shuffle algorithms in Listing 2. Map and merge tasks are scheduled in rounds according to the task parallelism P.
At round i, the application will:
- Submit the i-th round of map tasks.
- Block until the last round of merge tasks finish.
- Submit i-th round of merge tasks to consume the i-th round of map tasks’ outputs.
- Delete the i-th round of map tasks’ outputs.
In Exoshuffle, the application achieves this by choosing P such that the outputs produced by P concurrent map tasks will not exceed in-memory object store capacity.
总结
一轮一轮的跑,是用少的资源跑更大的数据,每一轮跑完都可以删除掉中间的 map_out 数据。
3.4 Fault Tolerance
The main requirement from the application is that each remote function defined by the ap- plication is idempotent and side effect-free.
3.5 Straggler Mitigation
Stragglers are tasks that take longer to finish than most other tasks.
Data skew is a related problem, where data is unevenly distributed, causing some reduce tasks to receive more work than others and become stragglers.
One way to handle stragglers is through speculative execution.
Shuffle services including Riffle and Magnet also imple- ment “best-effort merge”, where a timeout can be set on the shuffle and merge phase. If some merge tasks are cancelled due to timeout, the original map output blocks will be fetched instead. This ensures straggler merge tasks will not block the progress of the entire system.
Best-effort merge can be implemented in Exoshuffle as shown in Listing 5 using an additional ray.cancel() API which cancels the execution of a task.
亮点
best-effort merge 是个好主意,如果 merge 超时了,则直接去 map 的输出 reduce。
3.6 Application Interoperability
A major benefit of Exoshuffle is that since shuffle is implemented at the application level, it can easily interoperate with other non-shuffle applications.
3.6.1 Online Aggregation: Streaming Shuffle
Online aggregation is straightforward to implement in Exoshuffle because it does not require modifying the underlying distributed futures system.
Listing 6 shows an example of a word count program modified for online aggregation.
总结
这个表达的是有 shuffle 有的执行的快,有的执行的慢,可以把执行快的先展示出来。
3.6.2 Shuffling Data Loader for Distributed Machine Learning Training

By pipelining reducer outputs from the shuffle routines shown in Listings 1 and 2 directly into the ML trainers, model training can start as soon as the first batch of data arrives, and data can be transferred entirely in-memory.
Furthermore, tasks in the shuffle routine can be pipelined with the Trainer.train tasks.
4. System Architecture
Designing and building a distributed futures system that
can execute a large-scale application-level shuffle of 100TB, on 100 nodes.
In this section, we identify important facilities provided by the underlying distributed futures implementation that contribute to efficient shuffle performance.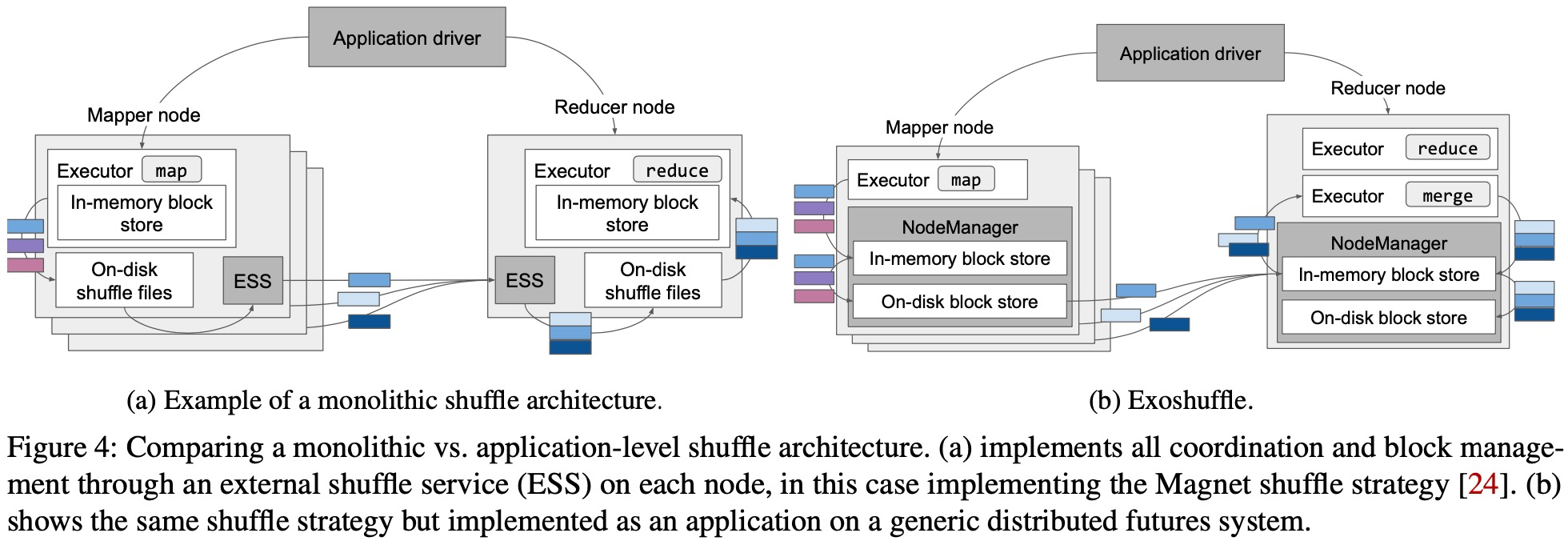
4.1 Coordination: The Distributed Object Store
4.1.1 First-class Object References
4.1.2 Shared-memory Object Store
4.1.3 Task Scheduling
Achieving high throughput in shuffle requires a high level of task parallelism and the ability to load-balance evenly across the cluster, to mitigate the possibility of stragglers.
4.2 Block Management
4.2.1 Reference Counting
4.2.2 Object Allocation and Pipeling
There are two categories of object memory allocations in Exoshuffle: new objects created for task returns (e.g., map task outputs), and copies of objects fetched as task arguments (e.g., shuffle task inputs).
4.2.3 Object Spilling
Object spilling is transparent. Whenever the memory alloca- tion subsystem has queued allocation requests, the spilling subsystem of Ray will try to migrate referenced objects to disk to free up memory.
4.3 Fault Tolerance
Similarly, we rely on previous work in lineage reconstruction for distributed futures to recover objects lost due to node failure
5. Evaluation
6. Related Work
7. Discussion
8. Conclusion
论文重要的是 2,3,4 章,其中2,3章最为重要。
Reference
- https://arxiv.org/abs/2203.05072
- Jeffrey Dean and Sanjay Ghemawat. Mapreduce: Simplified data processing on large clusters. Commun. ACM, 51(1):107–113, jan 2008.
- Apache Software Foundation. Hadoop. https:// hadoop.apache.org, June 2021.
- Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauly, Michael J. Franklin, Scott Shenker, and Ion Stoica. Resilient distributed datasets: A Fault-Tolerant abstraction for In-Memory cluster computing. In 9th USENIX Sympo- sium on Networked Systems Design and Implementa- tion (NSDI 12), pages 15–28, San Jose, CA, April 2012. USENIX Association.
- Paris Carbone, Asterios Katsifodimos, Stephan Ewen, Volker Markl, Seif Haridi, and Kostas Tzoumas. Apache flink: Stream and batch processing in a single engine. Bulletin of the IEEE Computer Society Technical Com- mittee on Data Engineering, 36(4):28–38, 2015.
- Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I. Jordan, and Ion Stoica. Ray: A distributed framework for emerg- ing AI applications. In 13th USENIX Symposium on Op- erating Systems Design and Implementation (OSDI 18), pages 561–577, Carlsbad, CA, October 2018. USENIX Association.
- HaoyuZhang,BrianCho,ErginSeyfe,AveryChing,and Michael J. Freedman. Riffle: Optimized shuffle service for large-scale data analytics. In Proceedings of the Thirteenth EuroSys Conference, EuroSys ’18, New York, NY, USA, 2018. Association for Computing Machinery.
- Dmitry Borovsky and Brian Cho. Cosco: An efficient facebook-scale shuffle service - databricks. https://databricks.com/session/ cosco-an-efficient-facebook-scale-shuffle-service, May 2019. (Accessed on 01/19/2022).
- Yanfei Guo, Jia Rao, and Xiaobo Zhou. iShuffle: Improving hadoop performance with Shuffle-on-Write. In 10th International Conference on Autonomic Computing (ICAC 13), pages 107–117, San Jose, CA, June 2013. USENIX Association.
- Min Shen, Ye Zhou, and Chandni Singh. Magnet: Push-based shuffle service for large-scale data processing. Proc. VLDB Endow., 13(12):3382–3395, aug 2020.
- Qian Wang, Rong Gu, Yihua Huang, Reynold Xin, Wei Wu, Jun Song, and Junluan Xia. Nadsort. http: //sortbenchmark.org/NADSort2016.pdf, 2016. (Accessed on 01/26/2022).
- Tyson Condie, Neil Conway, Peter Alvaro, Joseph M. Hellerstein, Khaled Elmeleegy, and Russell Sears. Mapreduce online. In Proceedings of the 7th USENIX Conference on Networked Systems Design and Imple- mentation, NSDI ’10, page 21, USA, 2010. USENIX Association.
- Konstantin Mishchenko, Ahmed Khaled, and Peter Richtarik. Random reshuffling: Simple analysis with vast improvements. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 17309–17320, Virtual, 2020. Curran Associates, Inc.
- Ajay Gupta. Revealing apache spark shuffling magic. https://medium.com/swlh/revealing-apache-spark-shuffling-magic-b2c304306142, may 2020. (Accessed on 02/01/2022).
- Gabe Joseph. Better shuffling in dask: a proof- of-concept : Coiled. https://coiled.io/blog/ better-shuffling-in-dask-a-proof-of-concept/, October 2021. (Accessed on 01/26/2022).

若有收获,就点个赞吧
0 人点赞
