Flink 团队在 2015 年发表的论文,主要讲述了 Streaming System 如何做 snapshot 的,是对 Chandy-Lamport 算法(详见:Distributed Snapshots: Determining Global States of Distributed Systems)的改进和优化。
Abstract
Existing approaches rely on periodic global state snapshots that can be used for failure recovery. Those approaches suffer from two main drawbacks. First, they often stall the overall computation which impacts ingestion. Second, they eagerly persist all records in transit along with the operation states which results in larger snapshots than required. In this work we propose Asynchronous Barrier Snapshotting (ABS), a lightweight algorithm suited for modern dataflow execution engines that minimises space requirements. ABS persists only operator states on acyclic execution topologies while keeping a minimal record log on cyclic dataflows.
In this work, we focus on providing lightweight snapshotting, specifically targeted at distributed state- ful dataflow systems, with low impact on performance.
Our technique does not halt the streaming operation and it only intro- duces a small runtime overhead.
The Apache Flink System
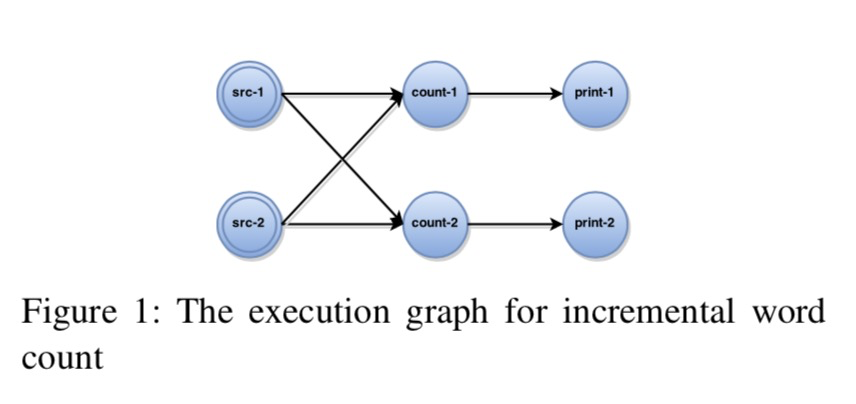

The Streaming Programming Model
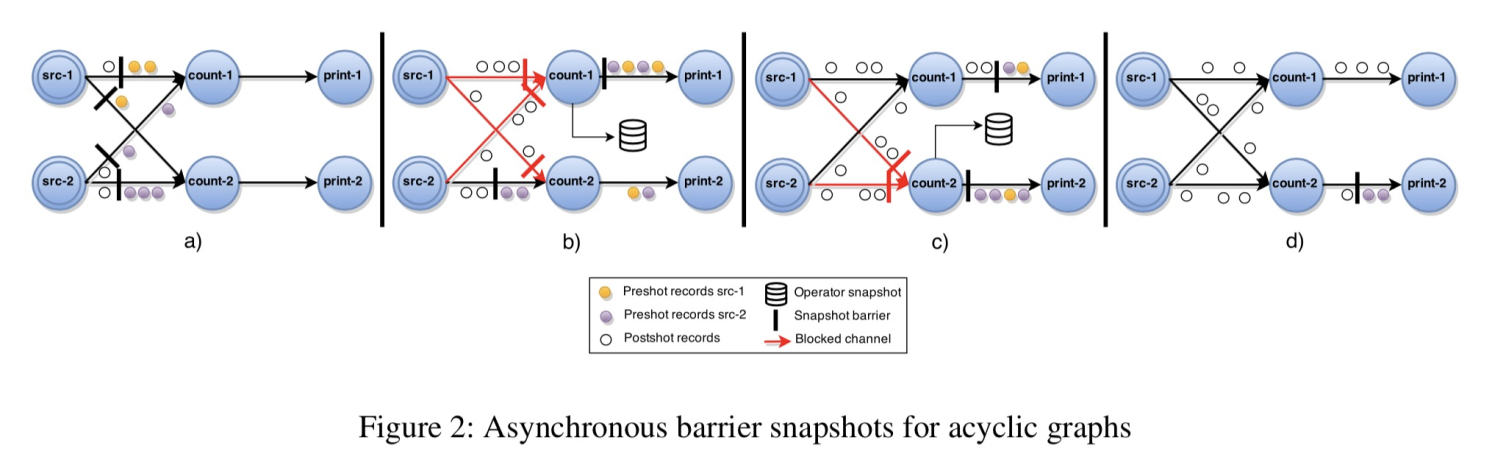
Asynchronous Barrier Snapshotting
In order to provide consistent results, distributed processing systems need to be resilient to task failures. A way of providing this resilience is to periodically capture snapshots of the execution graph which can be used later to recover from failures. A snapshot is a global state of the execution graph, capturing all necessary information to restart the computation from that specific execution state.
It is feasible to do snapshots without persisting channel states when the execution is divided into stages.
The core idea behind our algorithm is to create identical snapshots with staged snapshotting while keeping a continuous data ingestion.
In our approach, stages are emulated in a continuous dataflow execution by special barrier markers injected in the input data streams periodically that are pushed throughout the whole execution graph down to the sinks. Global snapshots are incrementally constructed as each task receives the barriers indicating execution stages. We further make the following assumptions for our algorithm:
- Network channels are quasi-reliable, respect a FIFO delivery order and can be blocked and unblocked. When a channel is blocked all messages are buffered but not delivered until it gets unblocked.
- Tasks can trigger operations on their channel components such as block, unblock and send messages. Broadcasting messages is also supported on all output channels.
- Messages injected in source tasks (i.e. stage barriers) are resolved into a “Nil” input channel.

Failure Recovery
There are several failure recovery schemes that work with consistent snapshots. In its simplest form the whole execution graph can be restarted from the last global snapshot as such: every task t (1) retrieves from persistent storage its associated state for the snapshot st and sets it as its initial state, (2) recovers its backup log and processes all contained records, (3) starts ingesting records from its input channels.
参考

若有收获,就点个赞吧
0 人点赞
