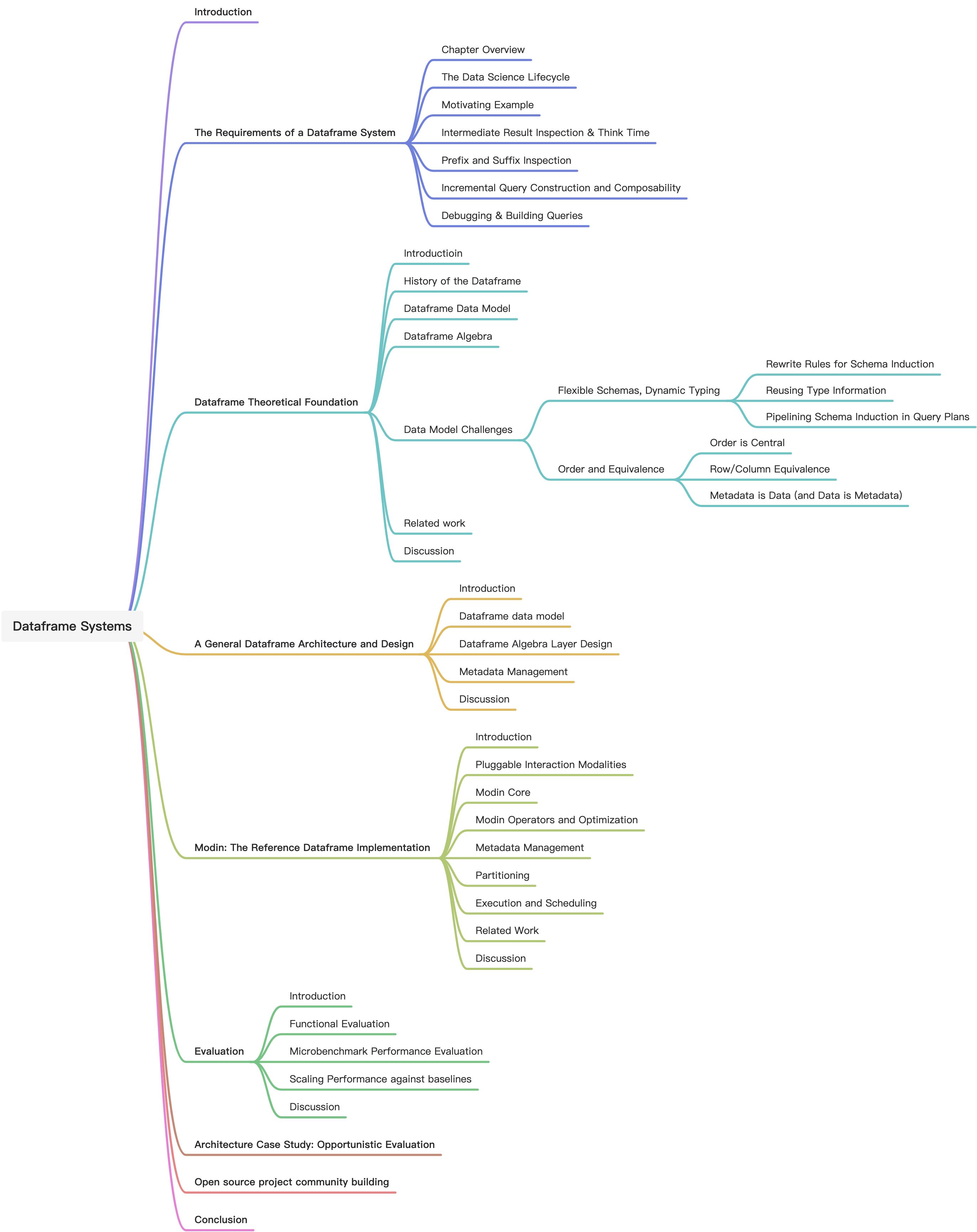
- 2. The Requirements of a Dataframe System
- 3. Dataframe Theoretical Foundation
- 4. A General Dataframe Architecture and Design
- 5. Modin: The Reference Dataframe Implementation
- 5.1 Introduction
- 5.2 Pluggable Interaction Modalities
- 5.3 Modin Core
- 5.4 Modin Operators and Optimization
- 5.5 Metadata Management
- 5.6 Partitioning
- 5.7 Execution and Scheduling
- 5.8 Related Work
- 5.9 Discussion
- Pros
- Q
- Modin
- Reference
2. The Requirements of a Dataframe System
2.1 Chapter Overview
We begin with a high level look at the typical data science lifecycle for most organizations. And then we providee a motivating example that will be used in subsequent chapters to provide a simplified model of a typical dataframe workload.
When inspecting results, the prefix (first k lines) and suffix (last k lines) are typically inspected to ensure that that a series of operators has executed as expected.
Composability is one of the most important features of the dataframe, because it allows users to incrementally test and build larger workflows in pieces.
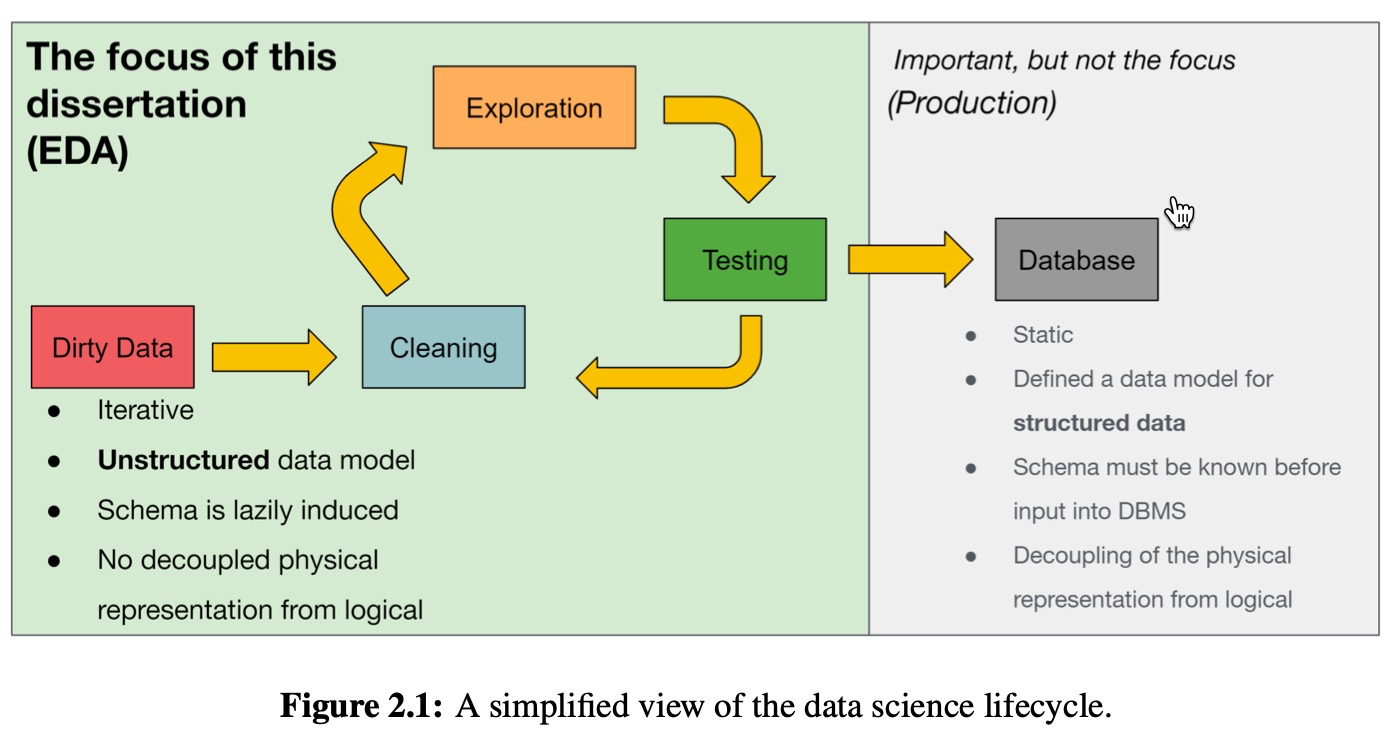
2.2 The Data Science Lifecycle
EDA: exploratory data analysis
Data scientists often operate or iterate on new or unknown datasets–in various degrees of cleanliness–to extract insights or value from them. This iteration cycle is shown in Figure 2.1.
Why are relational databases not suitable for EDA?
- Data needs to be defined schema-first before it can be examined
- Data that is not well-structured is difficult to query, and any query beyond SELECT * requires an intimate familiarity with the schema, which is particularly problematic for wide tables
- For more complex analyses, the declarative nature of SQL makes it awkward to develop and debug queries in a piecewise, modular fashion, conflicting with best practices for software development
Dataframes provide a functional interface that is more tolerant of unknown data structures and well-suited to developer and data scientist workflows, including REPL-style imperative interfaces and data science notebooks.
(A read–eval–print loop (REPL), also termed an interactive toplevel or language shell, is a simple interactive computer programming environment that takes single user inputs, executes them, and returns the result to the user; a program written in a REPL environment is executed piecewise.)
Dataframes have several characteristics that make them an appealing choice for data exploration:
- an intuitive data model that embraces an implicit ordering on both columns and rows and treats them symmetrically
- a query language that bridges a variety of data analysis modalities including relational (e.g., filter, join), linear algebra (e.g., transpose), and spreadsheet-like (e.g., pivot) operators
- an incrementally composable query syntax that encourages easy and rapid validation of simple expressions, and their iterative refinement and composition into complex queries
native embedding in a host language such as Python with familiar imperative semantics
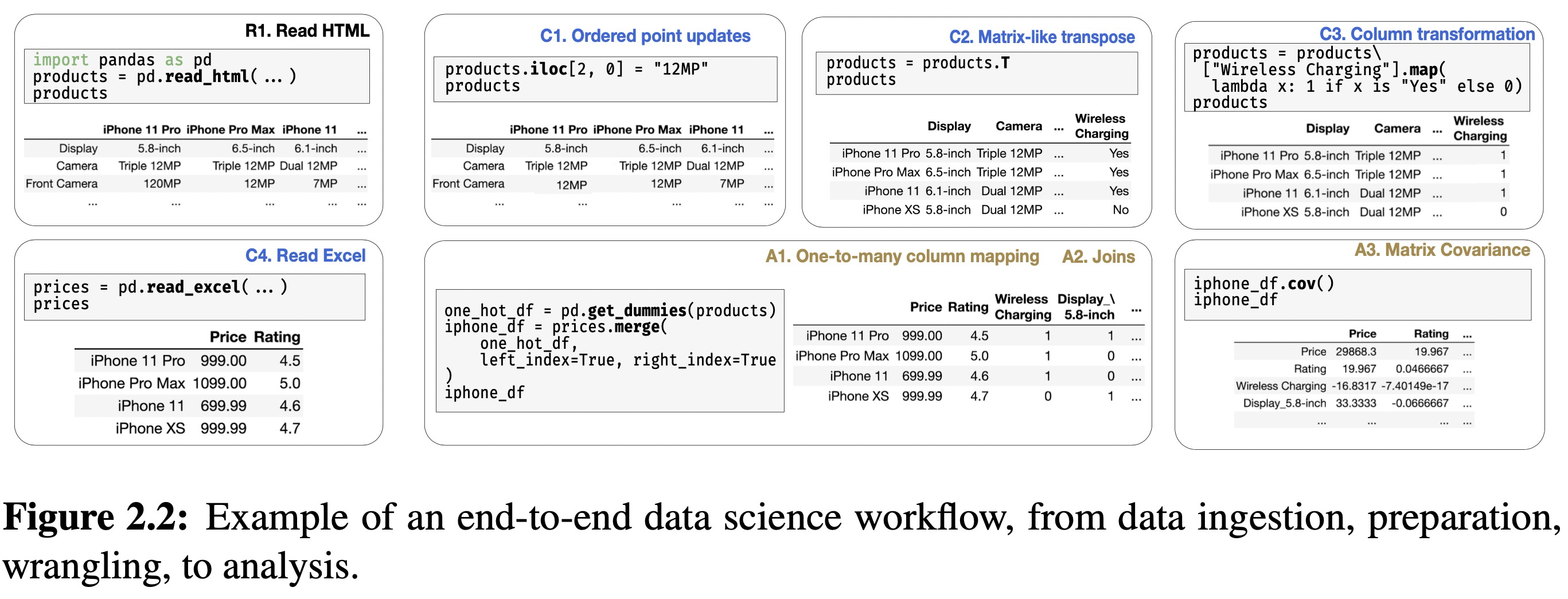
2.3 Motivatin Example
Data ingest and cleaning (Extract-Transform-Load)
R1: read the data from an e-commerce webpage and print out the first few lines to verify the data
- C1: Ordered point updates by performing a point update via
ilocand view the result - C2: Matrix-like transpose
- C3: Column transformation
-
Analysis
A1: One-to-many column mapping
- A2: Joins
-
Summarize
Dataframe mostly usage: immediate visual inspection after most operations, each incrementally building on the results of previous ones, point and batch updates via user-defined functions, and a diverse set of operators for wrangling, preparing, and analyzing data.
- Unlike in SQL where queries are submitted all-or-nothing, dataframe users construct queries in an incremental, iterative, and interactive fashion.
- Queries are submitted as a series of statements.
- Users rely on immediate feedback to debug and rapidly iterate on these statements and frequently revisit results of intermediate statements for experimentation and composition during exploration.
This interactive session-based programming model for dataframes creates novel challenges for overall system performance and imposes additional constraints on query optimization.
2.4 Intermediate Result Inspection & Think Time
eager model: every statement is evaluated as soon as it is issued. Program control is not returned to the user until the statement has been completely evaluated, forcing the user to be idle during that time. users are either rewarded or punished based on the efficiency of a query as it is written.
- lazy model: control is returned to the user im- mediately, and the system defers the computation until the user requests the result. The downside of lazy evaluation is that computation only begins when the user requests the result of a query.
Neither the lazy nor the eager mode takes advantage of the fact that the users spend time thinking between steps, during which the system is idle.
We can leverage this time for computation, allowing us to effectively achieve the benefits of both paradigms.
We describe a novel opportunistic query evaluation paradigm suitable for optimizing dataframes in an interactive setting. (详见:https://arxiv.org/pdf/2103.02145.pdf)
2.5 Prefix and Shuffix Inspection
The tabular view serves as a form of visualization that not only allows users to inspect individual data values, but also convey the structural information associated with the dataframe.
This tabular visualization typically contains a partial view of the dataframe displaying the first and last few rows of the dataframe, accessed using head, tail, or other print commands.
One starting point would be to design or select physical operator implementations that not just prioritize high output rate, but also preserve order, thereby ensuring that the first k rows will be produced as quickly as possible.
Since the top and bottom k rows are often the only results inspected for dataframe queries, we may benefit from materializing additional intermediates or supporting indexes to retrieve these rows efficiently.
We could, for example, materialize the prefix and suffix of a dataframe in original and transposed orientations, or the prefix or suffix of the dataframe sorted by various columns to allow for efficient processing subsequently. These materializations could happen during think-time as discussed in Section 2.4. (具体选择哪些列,做哪些排序,这个要怎么抉择,或有什么策略)
Another interesting usability-oriented challenge is whether this tabular view of prefixes or suffixes is indeed best for debugging— perhaps highlighting possible erroneous values or outliers in dataframe rows or columns that are not in the prefix or suffix may also be valuable.
2.6 Incremental Query Construction and Composability
In addition to challenges around enabling immediate feedback, query optimization is further complicated by the need to frequently evaluate and display results for intermediate sub- expressions (i.e., the results of statements) over the course of a session.
Since user statements often build on others, we can jointly optimize across these statements and resulting sub-expressions, sharing the work as much as is feasible.
Further, since users commonly return to old statements to try out new exploration paths, we can leverage materialization to avoid redundant reexecution.
We simply need to construct a query plan wherein sub-plans that correspond to intermediate dataframe results are materialized as by-products.
By observing the user’s likelihood of inspecting the intermediates over the course of many sessions, we can do a weighted joint optimization of all query subexpressions, where the weights for each intermediate dataframe correspond to its importance.
2.7 Debugging & Building Queries
The optimizer needs to handle the trade off between materialization overhead and the reduced execution time facilitated by availability of such intermediates to utilize storage in a way that maximizes saved compute—small intermediate dataframes that are time-consuming to compute and reused frequently should be prioritized over large intermediate dataframes that are fast to compute.
The prediction algorithm should take into consideration several factors, including user intent, past workflows, and operator lineage.
A simple heuristic is to persist intermediate results with high fan- outs; more advanced graph analysis techniques can be applied to determine prominent intermediate results.
3. Dataframe Theoretical Foundation
3.1 Introduction
As we described in Section 2, dataframes are not well understood in scientific literature. In this chapter, we explore the history of dataframes, and propose a data model and algebra as a solid theoretical basis that practical systems can implement.
3.2 History of the Dataframe
Dataframes begin with the S programming language in 1990. data.frames
The R programming language, an open-source implementation of S with some addi- tional innovations, was first released in 1995, with a stable version released in 2000, and gained instant adoption among the statistics community.
In 2008 Wes McKinney developed pandas in an effort to bring dataframe capabilities with R-like semantics to Python.
3.3 Dataframe Data Model
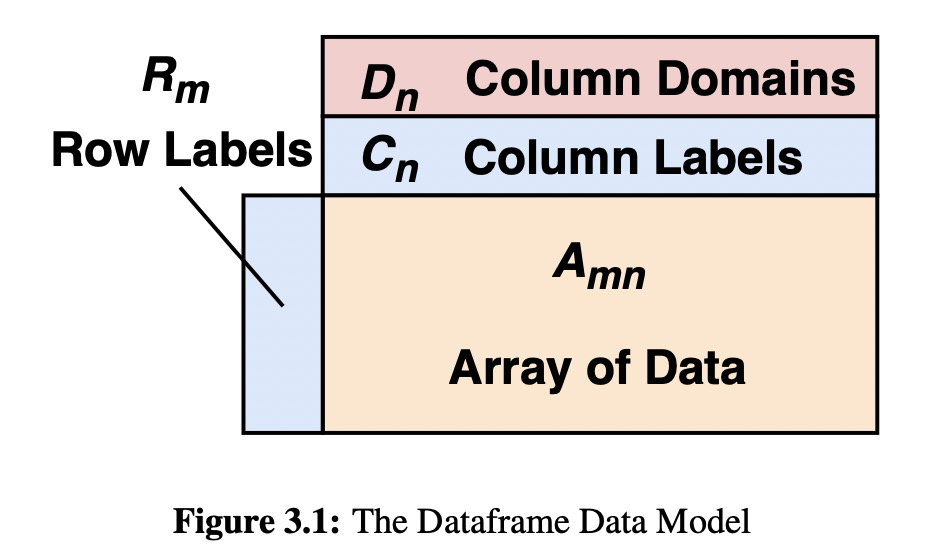
The elements in the dataframe come from a known set of domains Dom = {dom1, dom2, …}. For simplicity, we assume in our discussion that domains are taken from the set Dom = {Σ∗, int, float, bool, category}, though a few other useful domains like datetimes are common in practice.
A key aspect of a dataframe is that the domains of its columns may be induced from data post hoc, rather than being declared a priori as in the relational model.
Rows and columns are symmetric in many ways in dataframes.
A subtler distinction is that row and column labels are from the same set of domains as the underlying data (Dom), whereas in the traditional relational model, column names are from a separate domain.
One distinction between rows and columns in our model is that columns have a schema, but rows do not.
3.4 Dataframe Algebra
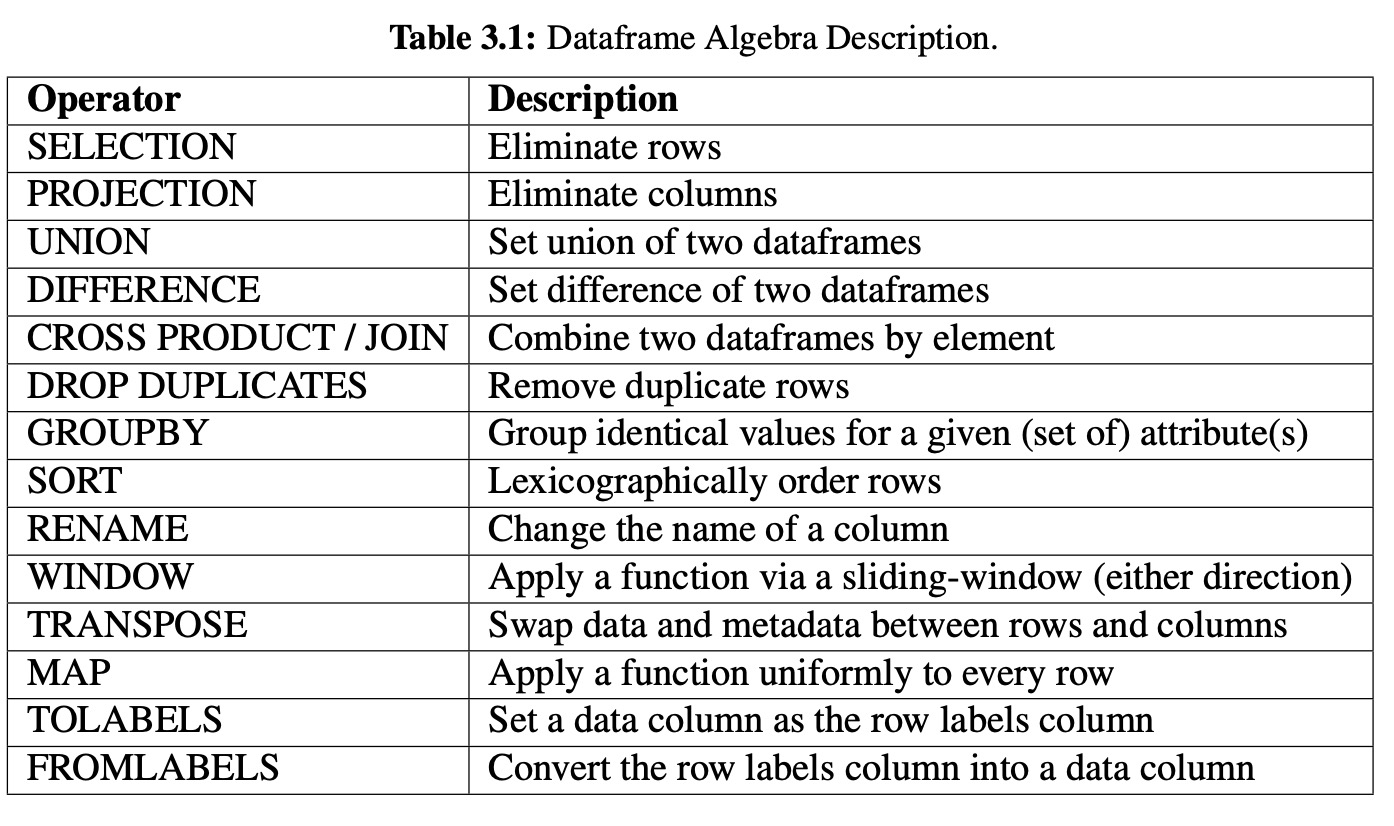
While studying pandas, we discovered that there exists a “kernel” of operators that encompasses the massive APIs of pandas and R.
- Transpose
- Map
- ToLabels
- FromLabels
- GroupBy
- Window
FROMLABELS is the opposite of the TOLABELS operator, and the two of these give the user complete control over moving data to and from the dataframe’s labels.
Algebra Examples
To demonstrate the expressiveness of the algebra above, we show how it can express pivot, which is particularly challenging in relational databases due to the need for relations to be declared schema-first.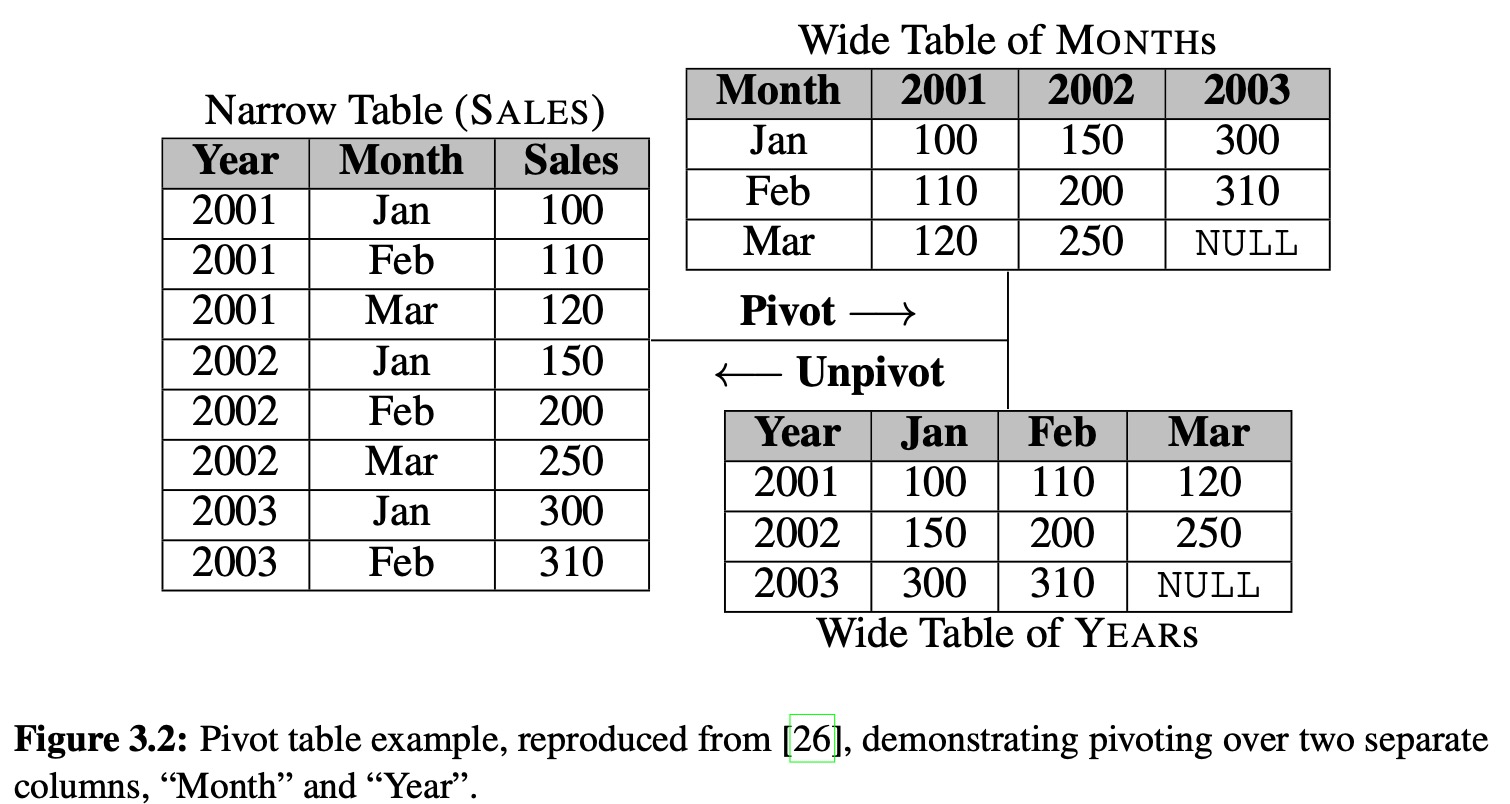
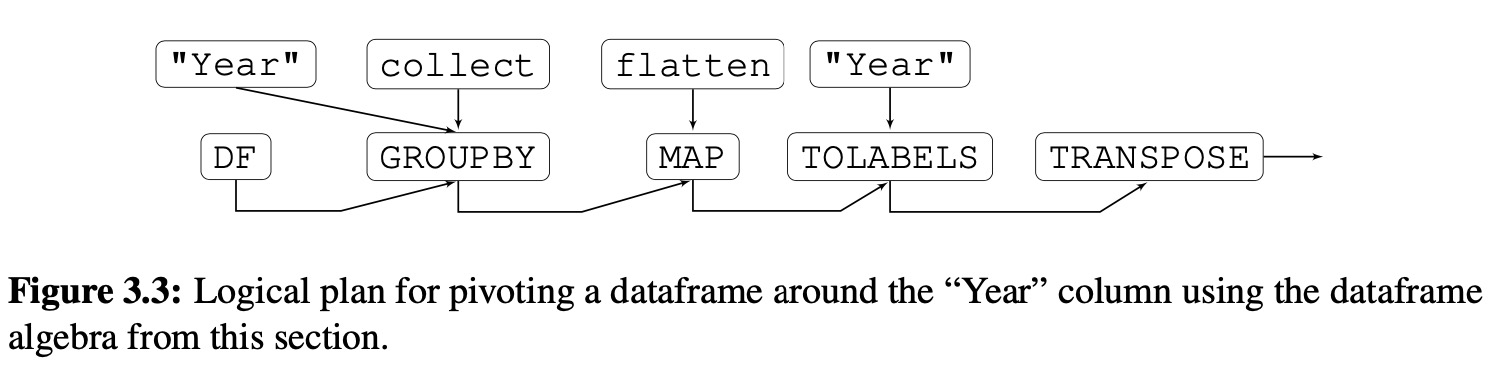
这个例子没看懂。
3.5 Data Model Challenges
3.5.1 Flexible Schemas, Dynamic Typing
Major challenges arise from the flexible nature of dataframe schemas.
Mitigating the costs inherent in flexible schemas and dynamic types therefore presents a major challenge for dataframes.
- In database terms, dataframes are more like views than tables
- Another source of dynamism arises from schema mutations
Rewrite Rules for Schema Induction
Due to their flexible schemas, dataframes support the addition and removal of columns as first-class operations, and at any point in time could have several columns with unknown type.
- ommit schema inference
-
Reusing Type Information
It is common to reuse a dataframe across multiple statements in a program.
In cases where the dataframe lacks explicit types, it can be very helpful to materialize the results of both schema induction and parsing—both within the invocation of a program (internal state), and across invocations in storage. Materialization of flexibly-typed schemas introduces a new set of challenges.
- View maintenance has a role in the dataframe context, with new challenges for type induction.
Pipeling Schema Induction in Query Plans
When applying S and the parsing function to columns is unavoidable, we may be able to reduce its cost by trying to fuse it with other operations that are type-agnostic and lightweight (e.g., data movement or serialization/deserialization) while adding minimal overhead, which we foresee to be a fruitful research direction.
Overall, the positioning of the schema induction operator within the query plan, by possibly fusing it with existing operators, combined with schema induction avoidance and reuse, is crucial for the development of a full-fledged dataframe query optimizer.3.5.2 Order and Equivalence
Order is Central
Row/Column Equivalence
Metadata is Data (and Data is Metadata)
3.6 Related work
3.7 Discussion
4. A General Dataframe Architecture and Design
4.1 Introduction
In this chapter we ignore imple- mentation details related to exposing the pandas API, and instead focus on the architecture design of a system that is able to implement the functionalities supported by the pandas API.
4.2 Dataframe data model
A dataframe consists of four main components, each of which will be described in
detail below. The four components of a dataframe are as follows:
- A collection of data, logically arranged into ordered columns and ordered rows: Data, logically arranged into columns and rows
- A set of row labels - one per row: row labels
- A set of column labels - one per column: Column labels
- A set of column types - one per column: Column types(domains)
4.3 Dataframe Algebra Layer Design
Differences with Dataframe Algebra
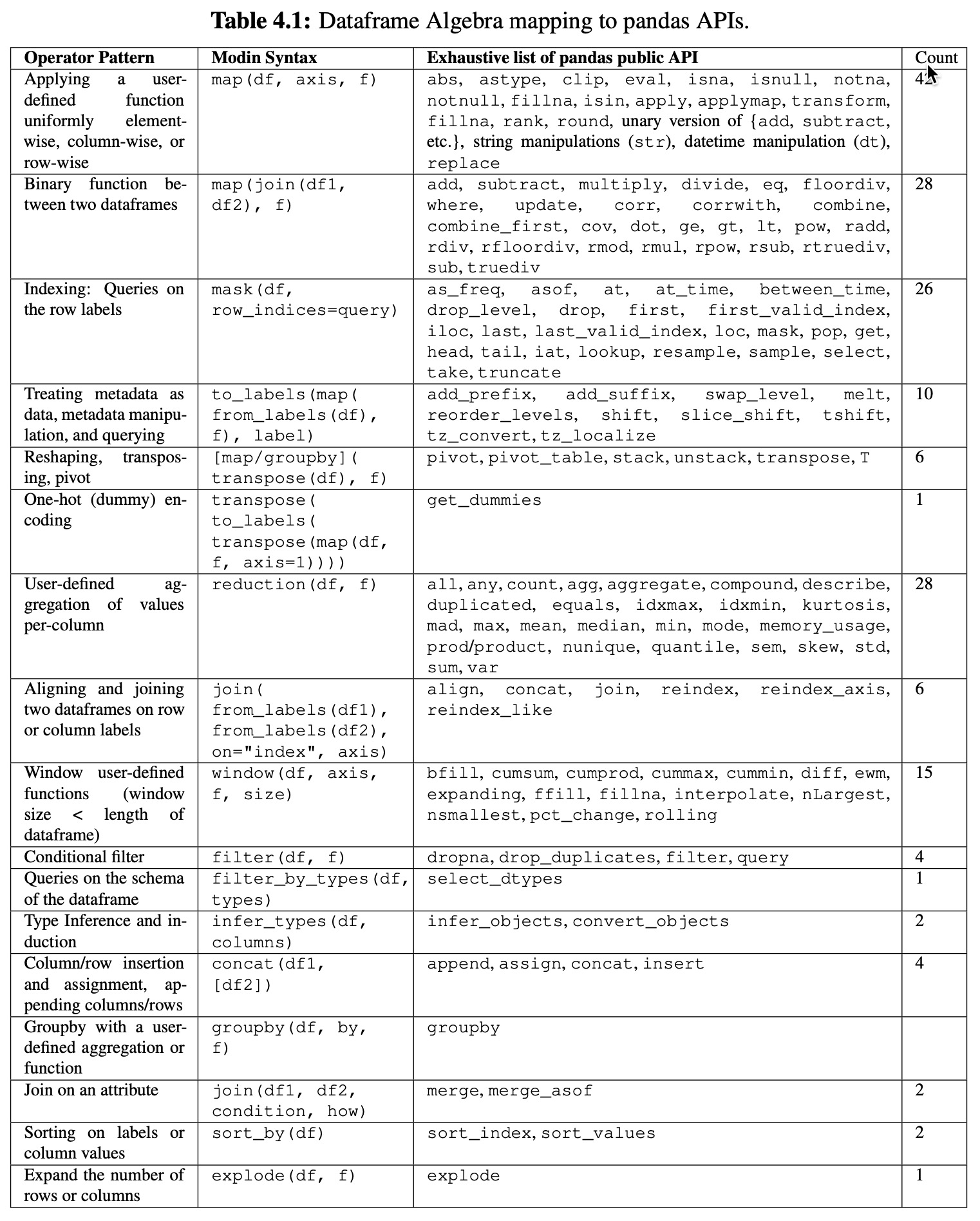
- mask
- filter_by_types
- map
- filter
- explode
- window
- window_reduction
- groupby
- reduction
- infer_types
- join
- concat
- transpose
- to_labels
- from_labels
-
Generalization of the algebra
The design here is a generalization of what pandas can implement, and can express opera- tions beyond the pandas API. It is intended to be able to support any dataframe API, from any system past or future.
4.4 Metadata Management
Schema Management
The type inference is fine-grained and can be applied at a column level, but it may be more efficient to infer the types of multiple columns that have been unspecified when the inference of one column is forced.
The article goes through each operator and its shcema management requirements. mask
- map
- filter
- explode
- window
- window_reduction
- groupby
- reduction
- infer_types
- join
- concat
- transpose
- to_lables
-
Logical Order Management
Logical order and position management is a key requirement of dataframe system. The system must be able to track the user’s order (or directly tie the physical representation to the logical order) to correctly execute dataframe queries.
mask
- map: depend on the user-defined function
- filter: depend on the condition function
- explode: depend on the user-defined
- window: the order must be materialized prior to executing the operator
- groupby: is value-based, does not rely on order
- reduction: must be materialized before the user-defined aggregation function can be applied in the case that it relies on the order of the data
- infer_types: does not need to be materialized
- join: must be materialized for the join to take place
- concat: need to be materialized before the operator can be applied
- transpose: the logical order does not need to be materialized
- to_labels: the logical order does not need to be materialized
- from_labels: does not need to be materialized
4.5 Discussion
5. Modin: The Reference Dataframe Implementation
5.1 Introduction
Modin is a parallel dataframe system, acting as a drop-in replacement for pandas. To build Mo- din, we had to address the dual problems of ensuring scalability of the rich set of dataframe operators when operating on the tolerant data model, while also providing clear, consistent, and correct semantics to users.
In this chapter we operationalize and extend the dataframe algebra presented in Chapter 3 and the design in Chapter 4 in a real implementation: Modin. We primarily target two key aspects, each with their associated challenges:
Rule-based Decomposition
To apply dataframe operations in parallel, along rows or columns or cells, we must develop a set of decomposition rules that allow us to flexibly rewrite dataframe operations on the original dataframe into analogous operations on vertical, horizontal, or block-based partitions of the dataframe.
Further, they must be tolerant to the fact that the column types may change in the decomposed dataframes in unpredictable ways, requiring possible coordination across the decompositions, which is expensive.
Moreover, the flexible data model blurs the boundary between data and metadata, and supports operators that query and manipulate the data and the metadata at the same time.
Finally, we need to outline these decomposition rules for a core set of dataframe algebraic operators, with the understanding that the entire set of operations (in systems like pandas) can be rewritten using this core set.
Metadata Independence
Dataframe systems such as pandas make several metadata- related design decisions that both impact scalability and semantics.
In particular, they tightly couple metadata with the physical representation of the dataframe; instead, we strive for metadata independence, where the metadata is captured at a logical level, with the physical representation of the metadata being decoupled from the logical.
Our goal is to develop an independent type system for dataframes that natively supports mixed types and unspecified types in a column, whereby we can defer type inference to only when it is needed.
We need to support order independence wherein the physical order can be made to match the logical order on demand, but isn’t done unless necessary.
Our Approach
Our core operators include relational operators adapted to the dataframe context (e.g., ordered versions of select, project, and join), operators used to query and manipulate the metadata (e.g., converting data to labels), and low-level operators that enable the application of system or user-defined functions (e.g., map and reduce). To allow these operators to be performed in parallel at scale, we identify flexible equivalence rules that express each operator on the dataframe as operators on decompositions or partitions thereof, with a suitable ordered concatenation operator to “reassemble” the overall dataframe if needed.
5.2 Pluggable Interaction Modalities

Currently, Modin exposes the full pandas API (with 600+ functions) while many popular dataframe systems, such as Koalas and Dask Dataframe , only support a subset of the pandas API that more directly corresponds to relational operators.
5.3 Modin Core
The Modin Core is the narrow-waist of Modin’s architecture. It contains a set of core operators, decides the best data layout or partitioning to parallelize the core operators, and efficiently manages metadata.
Core operators and data layout manager
To allow Modin’s core operators to be applied to large dataframes, Modin decomposes the dataframes into smaller partitions, enabling parallel execution of the operators on the partitions.
We’ll discuss the decomposition rules of each operator and optimization opportunities the stem from applying the decomposition rules in Section 5.4.
Metadata manager
The metadata manager is responsible for maintaining the metadata associated with a dataframe, including data types, column and row labels, and the mapping between logical order and physical order. We give an overview of metadata management here and discuss the details in Section 5.5.
Data types
We develop a dataframe type system to formally define the semantics of querying and manipulating types in a column.
Column and row labels
One of the biggest metadata challenges in dataframes is that metadata can become data, and vice-versa.
Logical order
Modin’s data layout decouples the logical order, also known as the user’s order, from the physical order through indirection. Since recomputing the specific position is costly and the specific position is rarely used, Modin will defer calculating position until necessary.
5.4 Modin Operators and Optimization
Modin supports a small set of core dataframe operators to implement the user-level APIs. This design requires addressing two major challenges.
- these operators need to be powerful and extensible such that they can be used to quickly implement new APIs or extend existing ones
- need to identify decomposition rules for each operator such that the operator can be executed in parallel to reduce interactive latency
How does Modin address these two challenges?
- First, we include dataframe versions of relational operations (e.g., join) since they are widely used in data analysis and are the building blocks for many user-level APIs. Second, we include non-relational operators that query and manipulate metadata (e.g., infer_types and transpose) to support flexible schema and mixed types. Finally, we include low-level operators (e.g., map, groupby, and explode) that accept an input function.
define the semantics of dataframe decompositions and propose a set of decomposition rules for parallelizing operators over dataframe decompositions
Semantics of Decomposing a Dataframe
A dataframe D is defined as a tuple (A,R,C,T), where A is an m × n array of entries that represents the dataframe content, R is a vector of m row labels, C is a vector of n column labels, and T is the type information for each column.
Decomposing a dataframe means dividing the dataframe content A into non-overlapping partitions, where for each partition Ak, we logically instantiate a new dataframe by adding the corresponding row labels Rk, column labels Ck, and type information Tk.
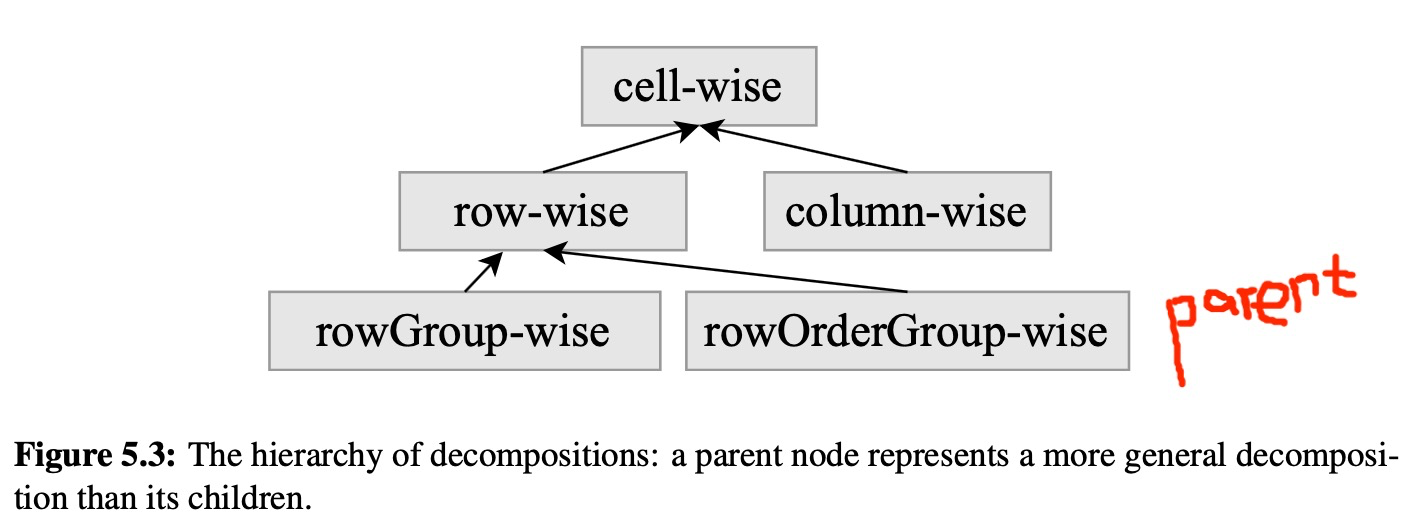
Five types of decompositions: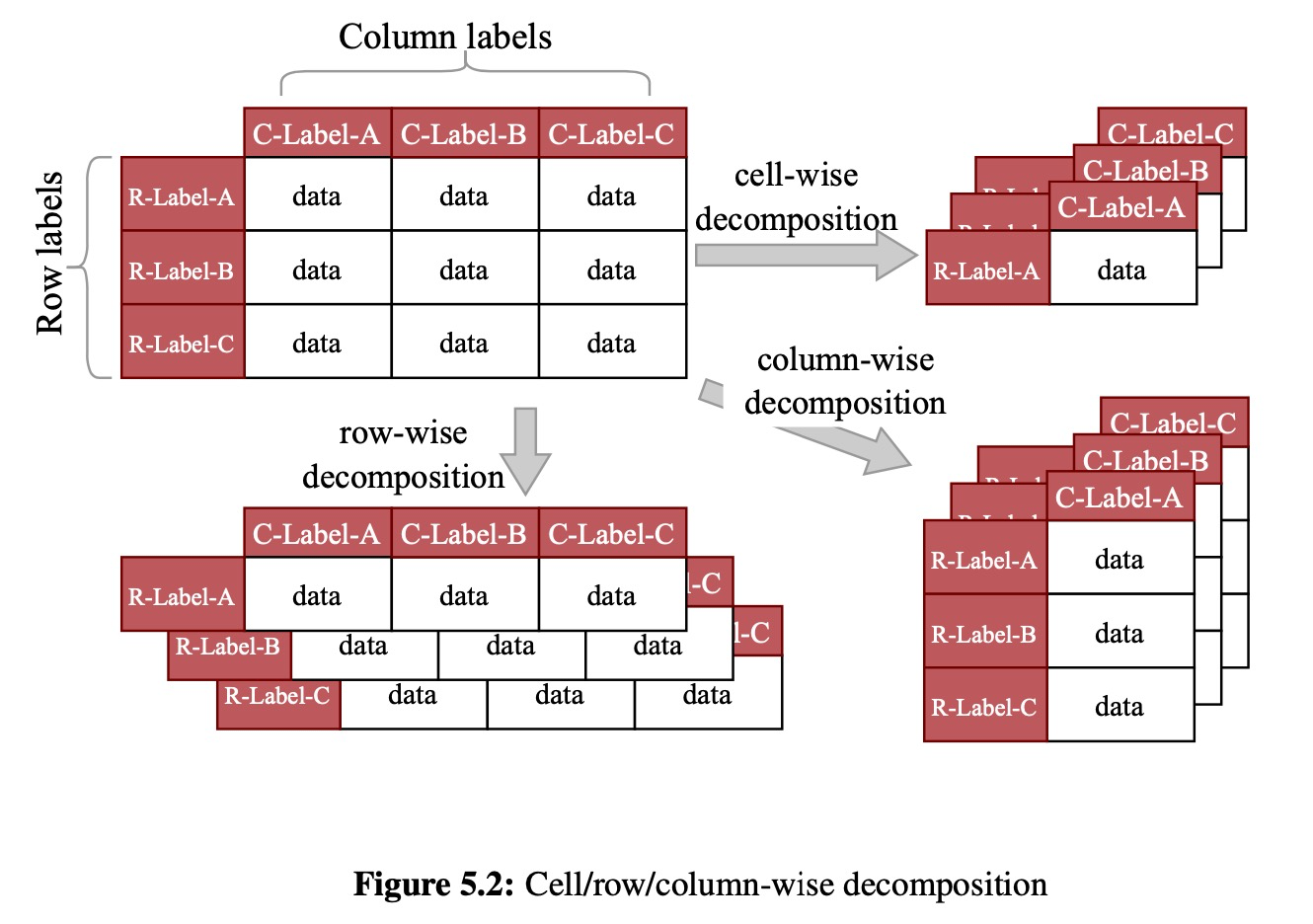
cell-wise
- row-wise
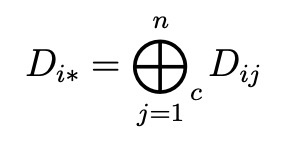
- column-wise
like row-wise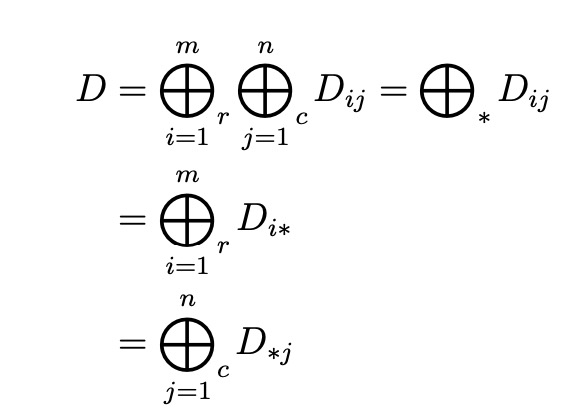
- rowGroup-wise
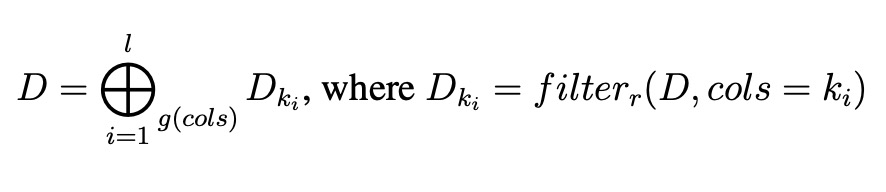
- rowOrderGroup-wise
Decomposition Rules for Operators
Low-level operators

Operators for querying and manipulating metadata

infer_types and filter_by_types
Since Modin supports mixed types in a column, we provide the infer_types operator to infer the type of a column by inspecting the type of each cell within the column and finding the common type. Modin organizes the types in a tree structure, where a parent node represents a more generic type than its child nodes.
to_labels and from_labels
Both operators support row-wise decomposition, but not column-wise.
transpose
We note that one system optimization in Modin is that we do not necessarily physically swap data and labels for the transpose operator, instead modifying the mapping from physical to logical for a no-shuffle dataframe transposition.
Relational operators

The dataframe operators that are adapted from relational operators include mask, filter, window, sort, join, rename, and concat.
mask and filter
window
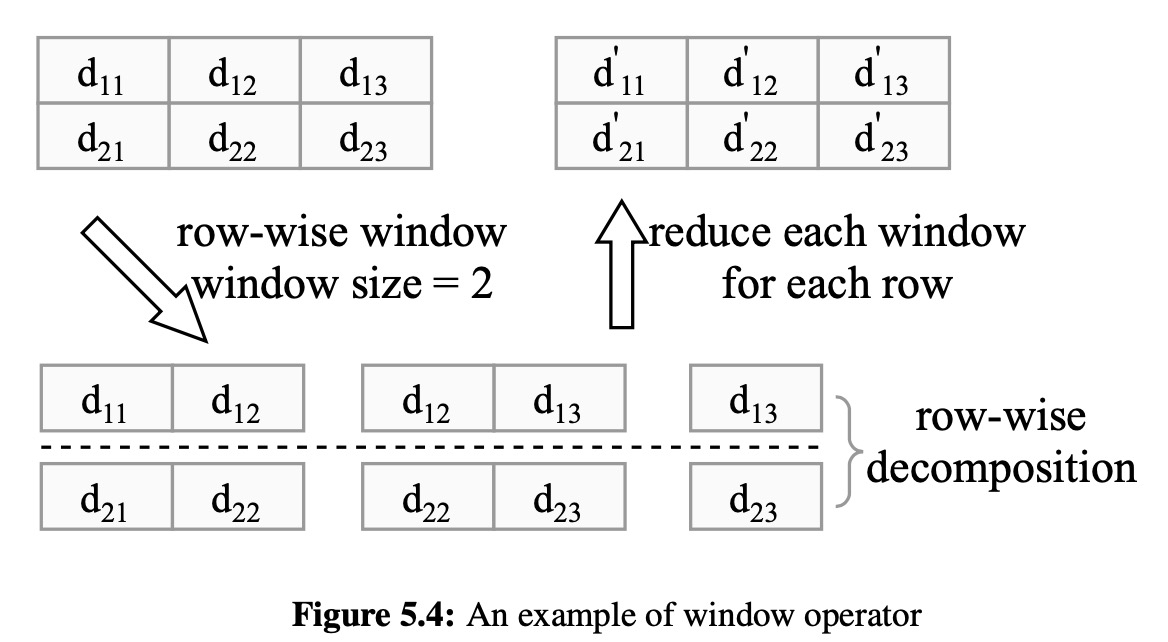
sort, join, rename and concat
- sort operator uses rowOrderGroup-wise decomposition
- join operator supports rowGroup-wise decomposition
- rename operator replaces the input dataframe’s row and column labels with the specified new labels. Since rename does not access the dataframe content, it does not have a decomposition rule
- concat operator is analogous to union in relational algebra. Modin currently supports inner and outer label join
Applying Different Decomposition Rules
We now identify two potential optimization opportunities made possible by intelligently choosing between decomposition rules. Since some operators can be decomposed in different ways, we can change the decomposition pattern based on the immediate preceding or succeeding operator decompositions.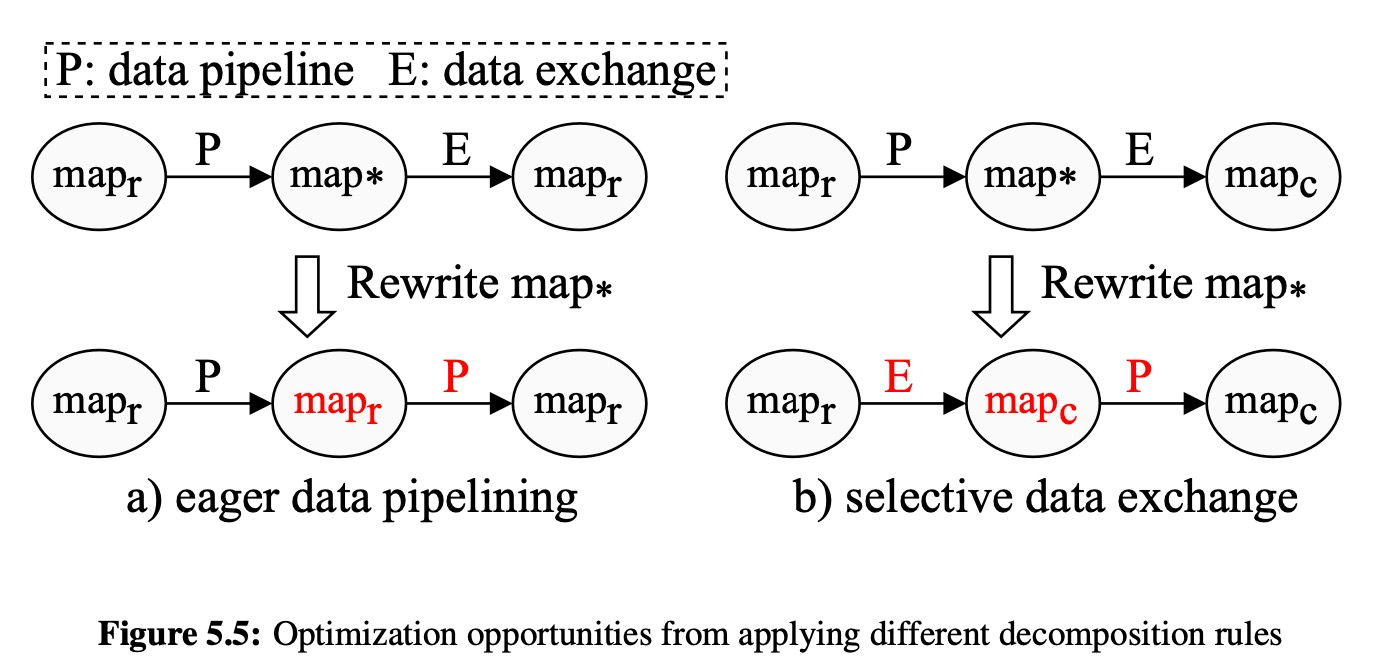
Eager data pipeling
Selective data exchange
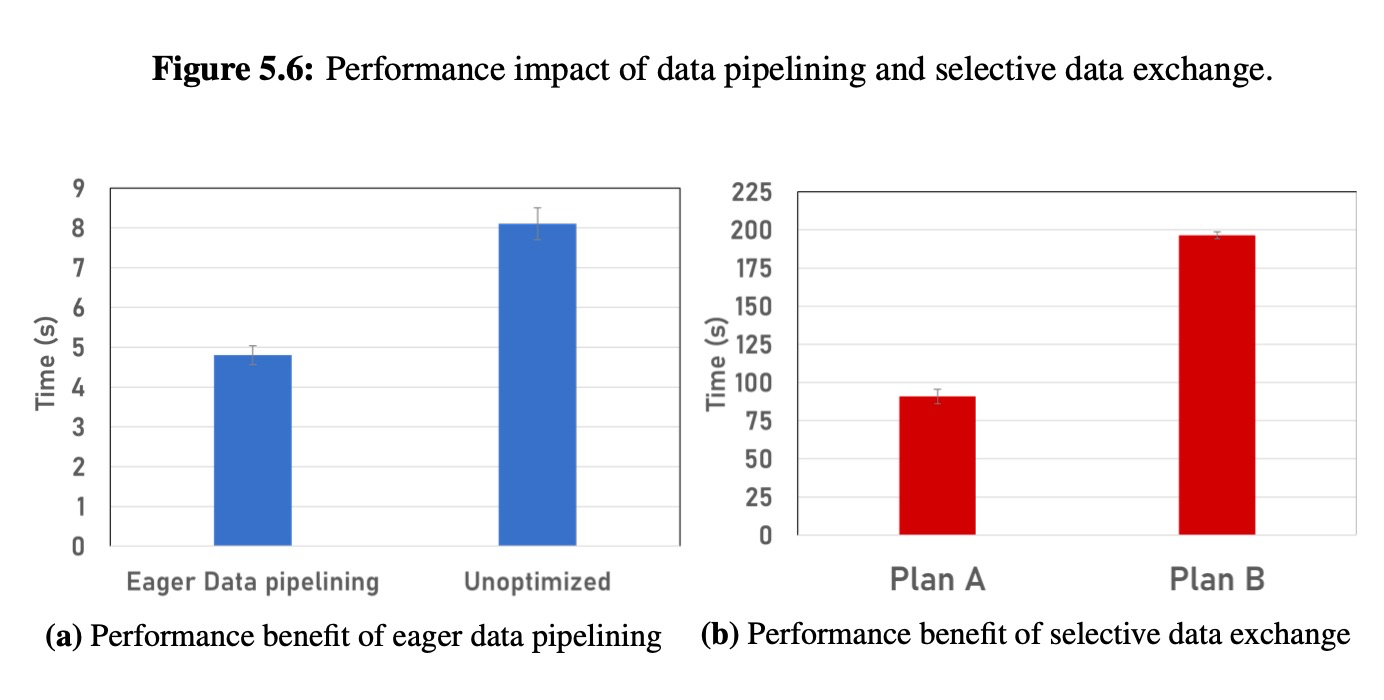
Performance impact of choosing different decomposition rules
5.5 Metadata Management
Modin manages various types of dataframe metadata: data types, the row/column labels, and the mapping between the logical order of columns and rows to the physical order.
Data Types
Columns in a dataframe can have mixed types, which poses multiple unique challenges. Dataframes must correctly and efficiently decide the type of a column that includes data of multiple types, as well as define the semantics of how each operator modifies the type information.
- We organize types into a hierarchy, where a parent node is a more general type than its children.
Then, we define how the core operators modify types.
Dataframe Type System
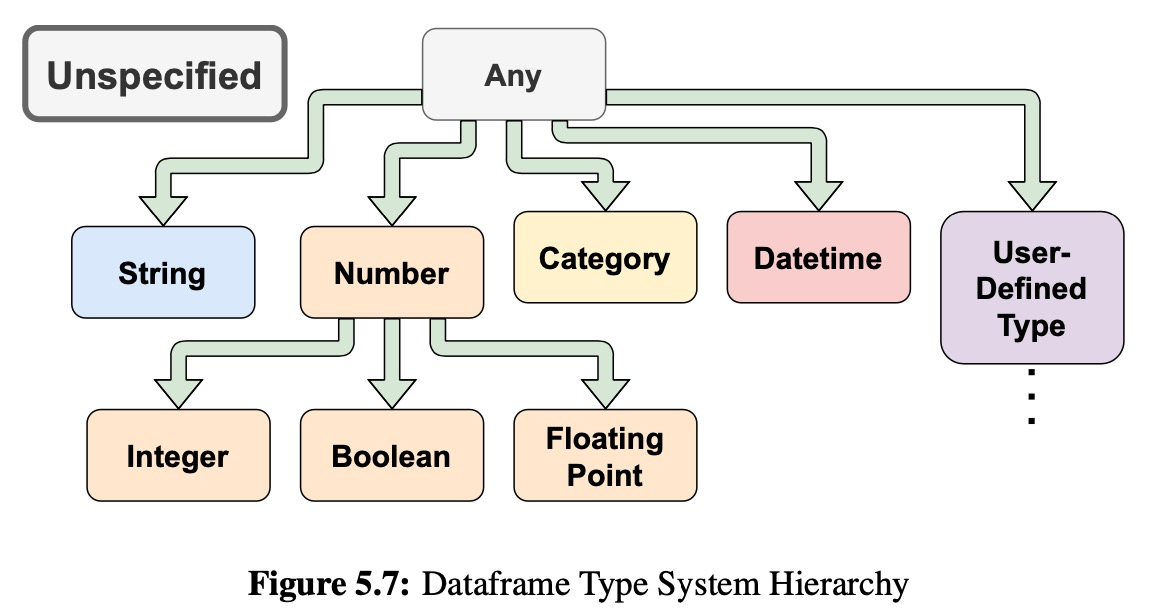
Invariant 5.5.1. The output column types of the operators that accept a UDF/SDF is either provided at invocation or designated as UNSPECIFIED and implicitly inferred by the dataframe system. Type inference is deferred until an operator requires it.
Invariant 5.5.2. A dataframe column i’s type Ti is always correct, even though the type Ti may not represent the most precise type for that column i.
Type Rules by Operator

“Inherited” means that the output data types will match the input dataframe’s types or remain UNSPECIFIED.Dataframe Label and Order Management
Dataframe label management
The labels of a dataframe are part of the metadata, but have unique properties which allow them to be treated as data at any point. This presents an interesting challenge: the metadata manager must be flexible enough to allow the labels to move into the data (i.e., to_label) and vise versa (i.e., from_label).
Modin addresses this challenge by maintaining two sets of labels. One set of labels is placed near the data to allow fast conversion between labels and data, the other set is maintained externally as an indexing structure to support querying based on labels. Modin lazily synchronizes the two sets of labels when one set of labels is changed and the other set is accessed.
Another challenge of dataframe labels is support for duplicate labels.Logical Order management
In dataframe systems like pandas, the logical and physical layer are tightly coupled, which can be beneficial at small scales, but quickly breaks down as datasets grow.
Instead, we propose a logical order management system that maintains the logical order and physical positions separately, that is, Modin will maintain the logical order, but not materialize the position.
Instead, the positions are only computed when requested.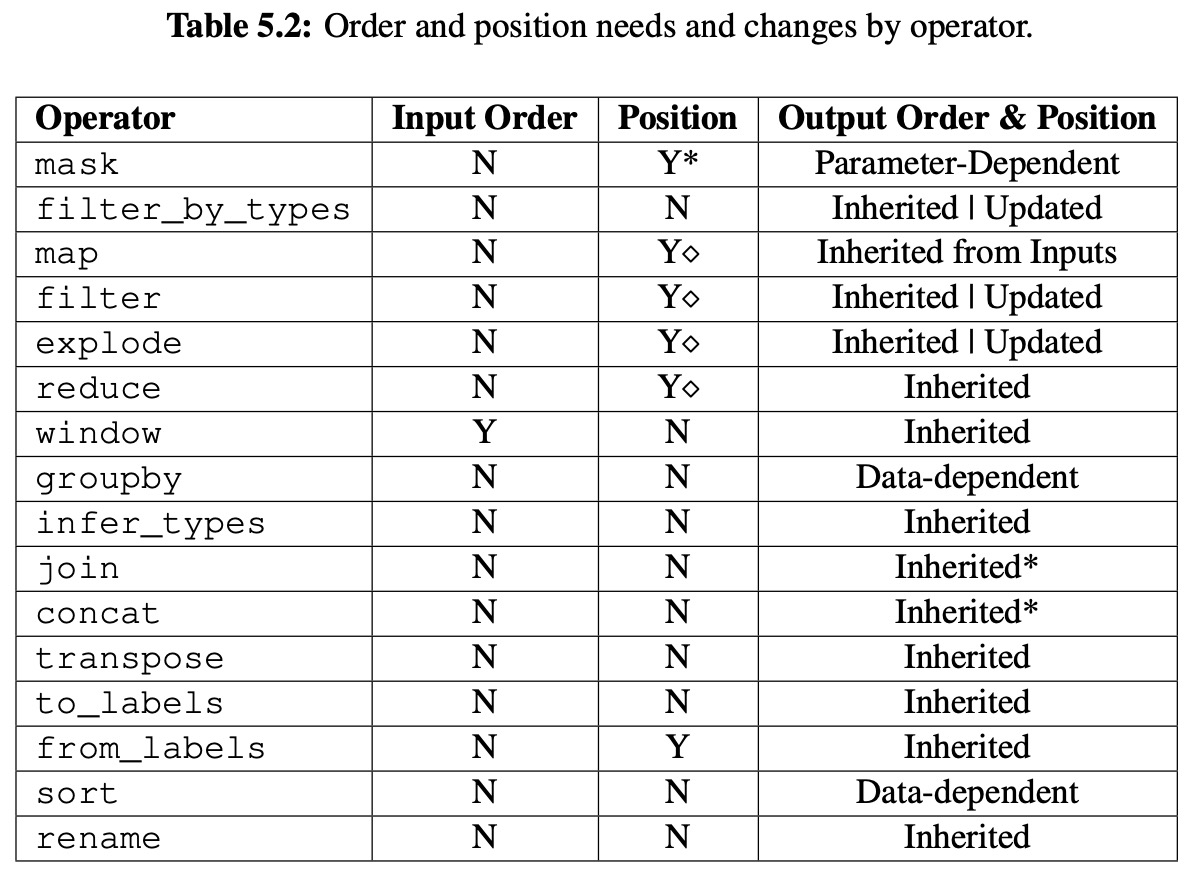
The “Input Order” column specifies whether the column’s order needs to be known (but not the position) before the operator can be applied.
- The “Position” column specifies whether the specific positions must be computed before the operator can be applied.
- “Output Order & Position“ shows how the output order is determined.
Y* 表示有条件的,比如 mask operator,只有当参数里用的是 position 时,才需要知道数据 positionY◇表示当应用在与 op 相反的轴上时,需要知道数据 position,比如 map operator,按行操作时,输入数据列的位置需要知道
5.6 Partitioning
The unique properties of dataframes that make them easier for users to manipulate data, like transposability and being able to operate on either rows or columns arbitrarily, also make distributed implementations more challenging and complex.
Partition Layer
To solve the unique issues related to the interchangeability of columns and rows in dataframes, The Modin DataFrame uses a block partitioning schema, which partitions along both columns and rows. 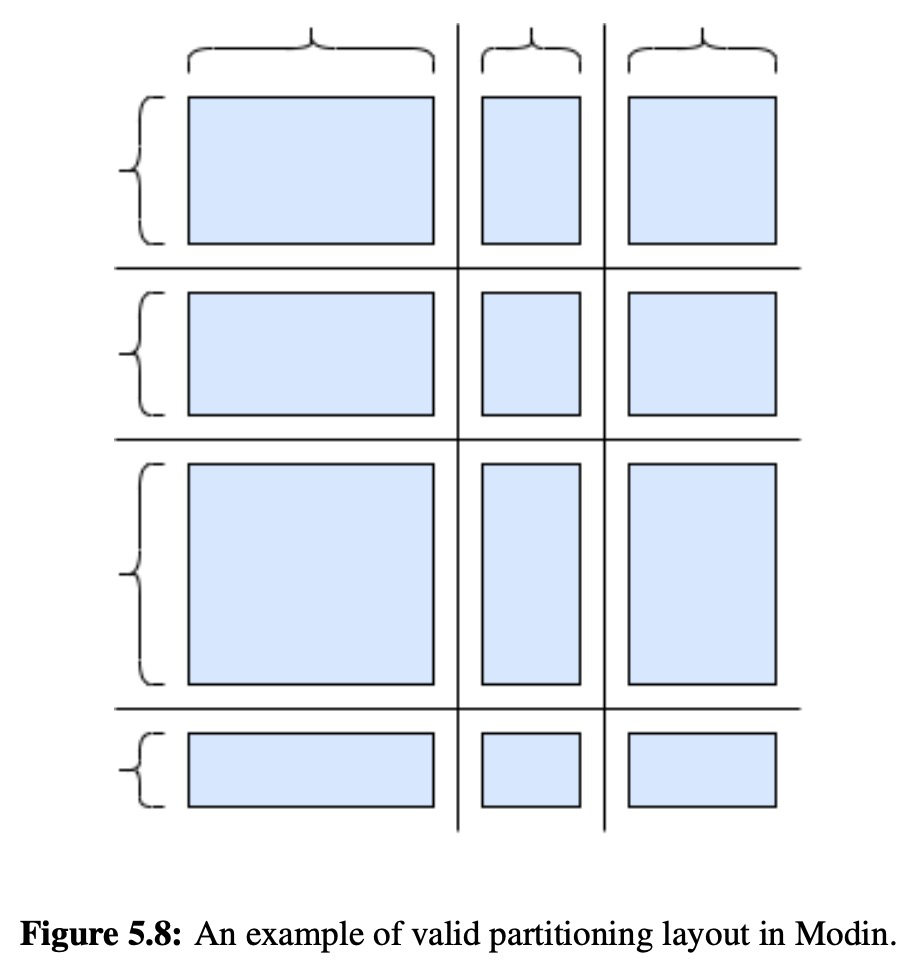
The only restriction on partitioning is that the partition widths and lengths must match along an axis of partitions.
Virtual Partitioning
To enable all types of access patterns, we implemented virtual partitioning.
With virtual partitioning, Modin developers are able to write algorithms and optimizations in whatever partitioning format is most natural, no matter the current physical partitioning.
没有说明Modin 里具体怎么实现的虚拟分区。
Partition Placement and Shuffling
Given the flexibility of the partitioning mechanism and the need to potentially shuffle data between every operator in the worst case, there is a significant amount of future work that will be needed to enable ideal partitioning and data shuffling for dataframes.
没有细说,可能是 Modin 里做的不太好。
5.7 Execution and Scheduling
For the reference implementation in Modin, we have enabled support for both Ray and Dask.
Execution on Ray
- 使用 task 模式性能更好
- Modin’s Ray engine currently uses Ray’s object store, but there are efforts planned to abstract the object store away from the Ray engine implementation in Modin so that we can also make use of high performance object stores.
- Ray has a unique Python decorator-style API for remote task submission, so naively enabling compute kernels to execute against a Ray engine would force us to define functions independently for Ray. Instead, we have one internal remote task declaration that has the required decorator and we serialize the compute kernel defined in the query compiler to ship it to the task.
Execution on Dask
Dask, like Ray, exposes task and actor abstractions. Dask’s API accepts the compiled compute kernel directly. Dask has a single, global scheduler with no fault tolerance, which is both a performance bottleneck for scheduling and a single point of failure, but gives . Given its position in the Python community, many data scientists are either familiar with Dask or are using it, so it is naturally a backend that would be useful to support in Modin.Execution on Omnisci
5.8 Related Work
Modin is the first dataframe system that supports the dataframe’s flexible data model and operations with correct and consistent semantics, while enabling dataframe operations to be parallelized at scale using formalized and flexible decomposition rules.Systems that support dataframe operations
Parallel/distributed database systems
Matrix computin and decomposition
5.9 Discussion
Pros
eager model 的一个好处是可以做算子优化,把几个操作合并处理,即查询优化。
延迟计算
Q
- Dataframe 为什么可以分解计算,是所有的运算都可以吗,还是只有部分?
每个算子定义了怎么分解,只有系统支持的算子才可以。
Modin
Libraries such as Dask DataFrame (DaskDF for short) and Koalas aim to support the pandas API on top of distributed computing frameworks, Dask and Spark respectively. Instead, Modin aims to preserve the pandas API and behavior as is, while abstracting away the details of the distributed computing framework underneath. Thus, the aims of these libraries are fundamentally different.[
](https://spark.apache.org/docs/latest/sql-programming-guide.html)
dask dataframe: https://docs.dask.org/en/stable/dataframe.html
pandas api on spark: https://koalas.readthedocs.io/en/latest/
spark dataframe: https://spark.apache.org/docs/latest/sql-programming-guide.html
Reference

若有收获,就点个赞吧
0 人点赞
