參考鏈接:注意力機制在分類網路中的應用:SENet、SKNet、CBAM
我們通常將軟注意力機制中的模型結構分為三大注意力域來分析: 空間域、通道域、混合域 。
(1) 空間域 —— 將圖片中的的空間域資訊做對應的 空間變換 ,從而能將關鍵的資訊提取出來。對空間進行掩碼的生成,進行打分,代表是Spatial Attention Module。
(2) 通道域 ——類似於 給每個通道上的訊號都增加一個權重,來代表該 通道與關鍵資訊的相關度 的話,這個權重越大,則表示相關度越高。對通道生成掩碼mask,進行打分,代表是senet, Channel Attention Module。
(3) 混合域 —— 空間域的注意力是忽略了通道域中的資訊,將每個通道中的圖片特徵同等處理, 這種做法會將空間域變換方法侷限在原始圖片特徵提取階段,應用在神經網路層其他層的 可解釋性不強 。而通道域的注意力是對一個通道內的資訊直接全域性平均池化,而忽略每一個通道內的區域性資訊 ,這種做法其實也是比較暴力的行為。所以結合兩種思路,就可以設計出混合域的注意力機制模型。 同時對通道注意力和空間注意力進行評價打分,代表的有BAM, CBAM。
SENet:對特徵圖的通道注意力機制的研究 ,
CBAM:對特徵圖通道注意力+空間注意力機制的研究。
SKNet:針對卷積核的注意力機制(感受野)研究。
1 - Squeeze-and-Excitation Networks(SENet)
Code參考:SE-Net (Squeeze-and-Excitation Networks) 架構介紹
論文的核心點在對CNN中的feature channel(特徵通道依賴性)利用和創新 。 提出的SE模組思想簡單,易於實現,並且很容易可以載入到現有的網路模型框架中。SENet主要是 通過顯式地建模通道之間的相互依賴關係,自適應地重新校準通道的特徵響應 ,換句話說,就是 學習了通道之間的相關性,篩選出了針對通道的注意力 ,整個網路稍微增加了一點計算量,但是效果比較好。
這種結構的原理是 想通過控制scale的大小,把重要的特徵增強,不重要的特徵減弱,從而讓提取的特徵指向性更強。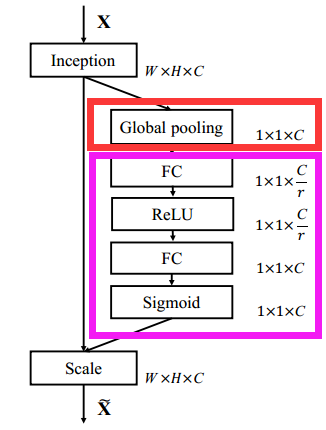
2 - Selective Kernel Networks(SKNet)
論文解讀:https://liaowc.github.io/blog/SKNet-structure/
💡Idea:神經元是動態調節自身感受野的。
SKNet的主要改進就是讓神經網路模型使用數種 kernel size 進行卷積並且能學習到如何選擇 kernel size(所以才叫 selective kernel)。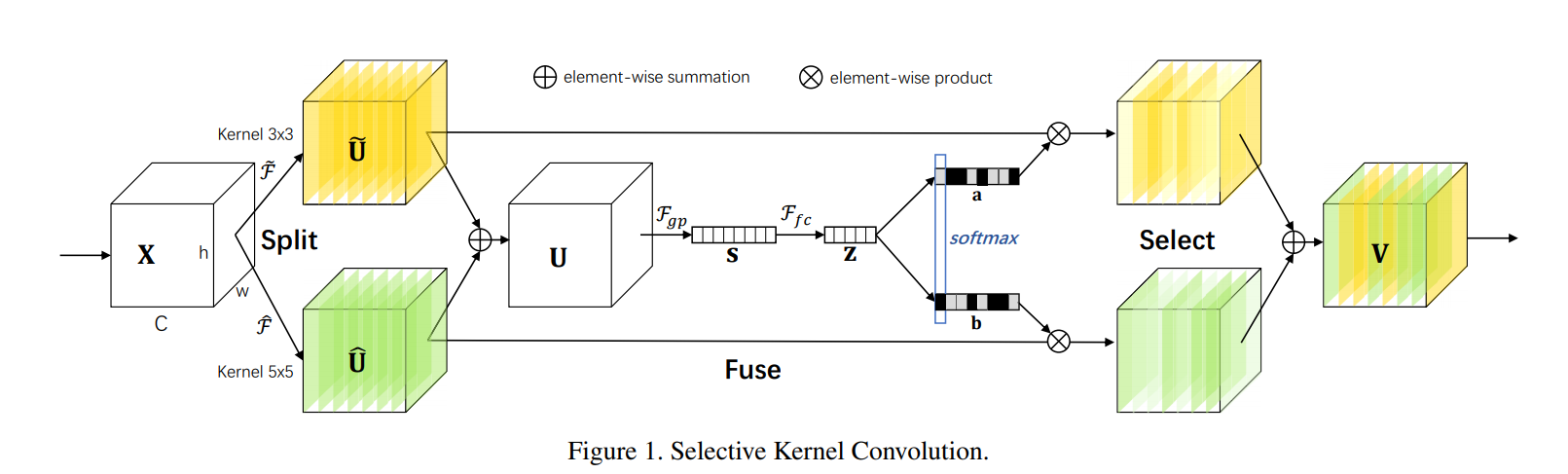
操作步驟:
- Split:分成數個平行的分支,每個分支皆為卷積層但各自的 kernel size 不同。以上圖為例,分成兩種 kernel size:3x3 和 5x5。實作上,5x5 不一定會真的有 25 個參數,可能用 3x3 且 dilation 為 2 的卷積層代替。
TIP:這裡的操作採用組/深度可分離卷積,BN、Relu,為了進一步提神效率,5x5卷積用 3x3 且 dilation 為 2 的卷積層代替。
- Fuse:
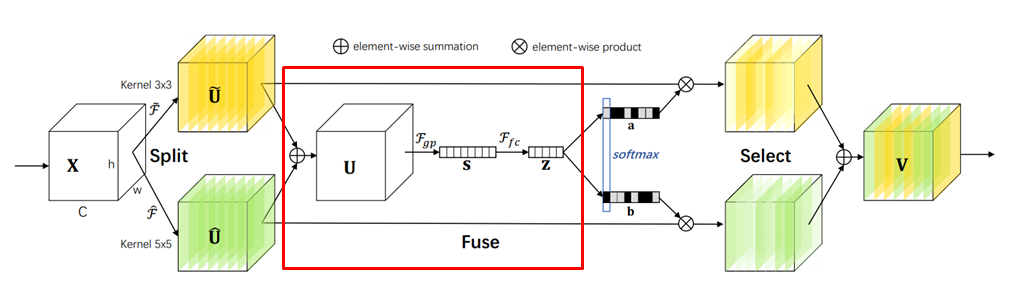
- 把頭上有不同符號的那些的 U 各對應的元素加起來,得到 U。
- 對 U 做全域平均池化(global average pooling)得到 s。
- s 經過全連接層(fully-connected layer)+ Batch Normalization + ReLU 得到 z。z 的維度為 d=max(C/r,L),r 是一個控制用的比例,L 是 d 的最小值。
- Select:
- 各分支在這邊皆有一個全連接層對 z 做運算。所以兩個分支就有兩個全連接層,以上圖來說,a、b 便是這兩個全連接層的產物。
- 之後各分支的全連接層進行 channel-wise 的 softmax,讓各全連接層各對應的通道的和為 1,做到比例分配的效果。從上圖來看,可以看到a、b相對應的通道有一個是黑色另一個不是黑色,表示在這個通道上對不同 kernel size 的分支產生的結果的比例不同,也就是:縱向的(每一列)進行softmax。
- 之後依各分支的全連接層對各分支一開始的卷積結果進行權重計算最後相加得到結果 V。以上圖來說,也就是 a、b 上各通道的值是各通道的權重。
實驗:在大多數通道中,當目標增大時,5x5卷積核所佔的權重也增加。此現象中存在的中淺層當中。
3 - Convolutional Block Attention Module (CBAM)
論文解讀及CODE參考:CBAM: Convolutional Block Attention Module
在該論文中,作者研究了網路架構中的注意力,注意力不僅要告訴我們重點關注哪裡,還要 提高關注點的表示 。目標是通過使用注意機制來增加表現力,關注重要特徵並抑制不必要的特徵。為了強調空間和通道這兩個維度上的有意義特徵,作者 依次應用通道和空間注意模組,來分別在通道和空間維度上學習關注什麼、在哪裡關注。 此外,通過了解要強調或抑制的資訊也有助於網路內的資訊流動。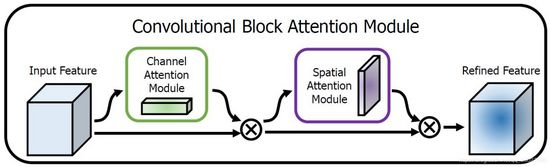
上圖為整個CBAM的示意圖,先是通過注意力機制模組,然後是空間注意力模組,對於兩個模組 先後順序 對模型效能的影響,本文作者也給出了實驗的資料對比,先通道再空間要比先空間再通道以及通道和空間注意力模組並行的方式效果要略勝一籌。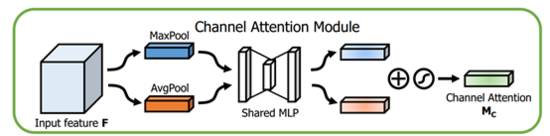
通道注意力模組
這個部分大體上和SENet的注意力模組相同,主要的區別是CBAM在S步採取了 全域性平均池化以及全域性最大池化 ,兩種不同的池化意味著提取的高層次特徵更加豐富。接著在E步同樣通過兩個全連線層和相應的啟用函式建模通道之間的相關性,合併兩個輸出得到各個特徵通道的權重。最後,得到特徵通道的權重之後,通過乘法逐通道加權到原來的特徵上,完成在通道維度上的原始特徵重標定。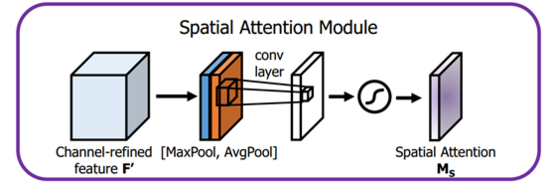
空間注意力模組
首先輸入的是經過通道注意力模組的特徵,同樣利用了全域性平均池化和全域性最大池化,不同的是,這裡是在通道這個維度上進行的操作,也就是說把所有輸入通道池化成2個實數,由(hwc)形狀的輸入得到兩個(hw1)的特徵圖。接著使用一個 77 的卷積核,卷積後形成新的(hw*1)的特徵圖。最後也是相同的Scale操作,注意力模組特徵與得到的新特徵圖相乘得到經過雙重注意力調整的特徵圖。
4 - Deep Residual Shrinkage Network
深度残差收缩网络(Deep Residual Shrinkage Network)
論文解讀:https://zhuanlan.zhihu.com/p/121801797
(1)噪声的含义
深度残差收缩网络面向的是数据包含噪声的情况。事实上,这里的“噪声”,可以有更宽泛的解释。“噪声”不仅可以指数据获取过程中所掺杂的噪声,而且可以指“与当前任务无关的信息”。比如说,我们在训练一个猫狗分类器的时候,如果图像中存在老鼠,那么老鼠就可以理解为一种噪声。
(2)兩種深度殘差收縮網絡
DRSN-CS(Deep Residual Shrinkage Networks with Channel-shared Thresholds):通道之间共享阈值的深度残差收缩网络
DRSN-CW(Deep Residual Shrinkage Networks with Channel-wise Thresholds):逐通道不同阈值的深度残差收缩网络
(3)軟閾值 Soft thresholding
软阈值是很多传统信号去噪方法的关键步骤,通过将原始信号变换到某一个领域,在这个领域中噪声的值靠近零,是不重要的,然后应用 soft thresholding, 将靠近零的值转为零。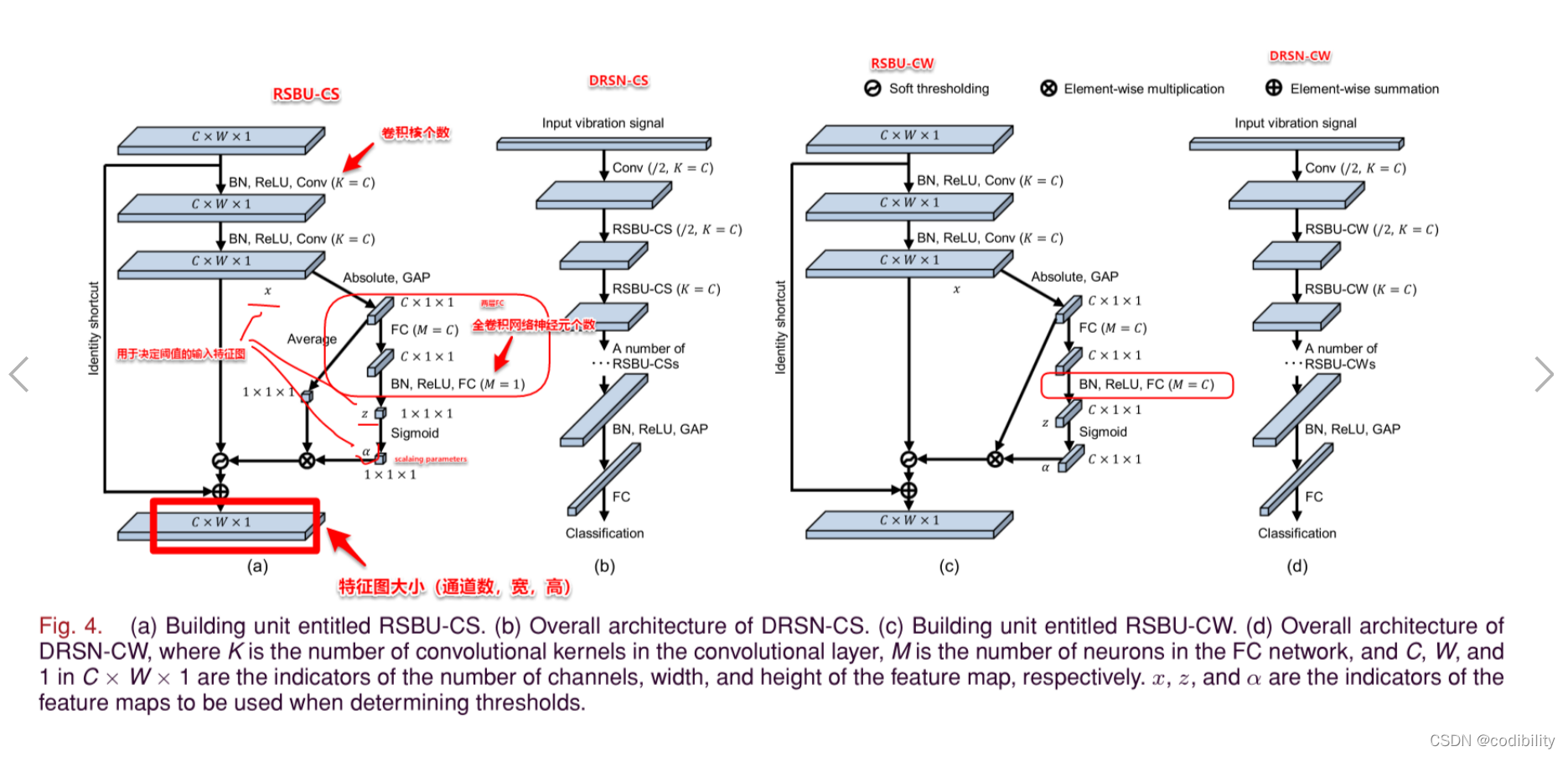

若有收获,就点个赞吧
0 人点赞
