introduction
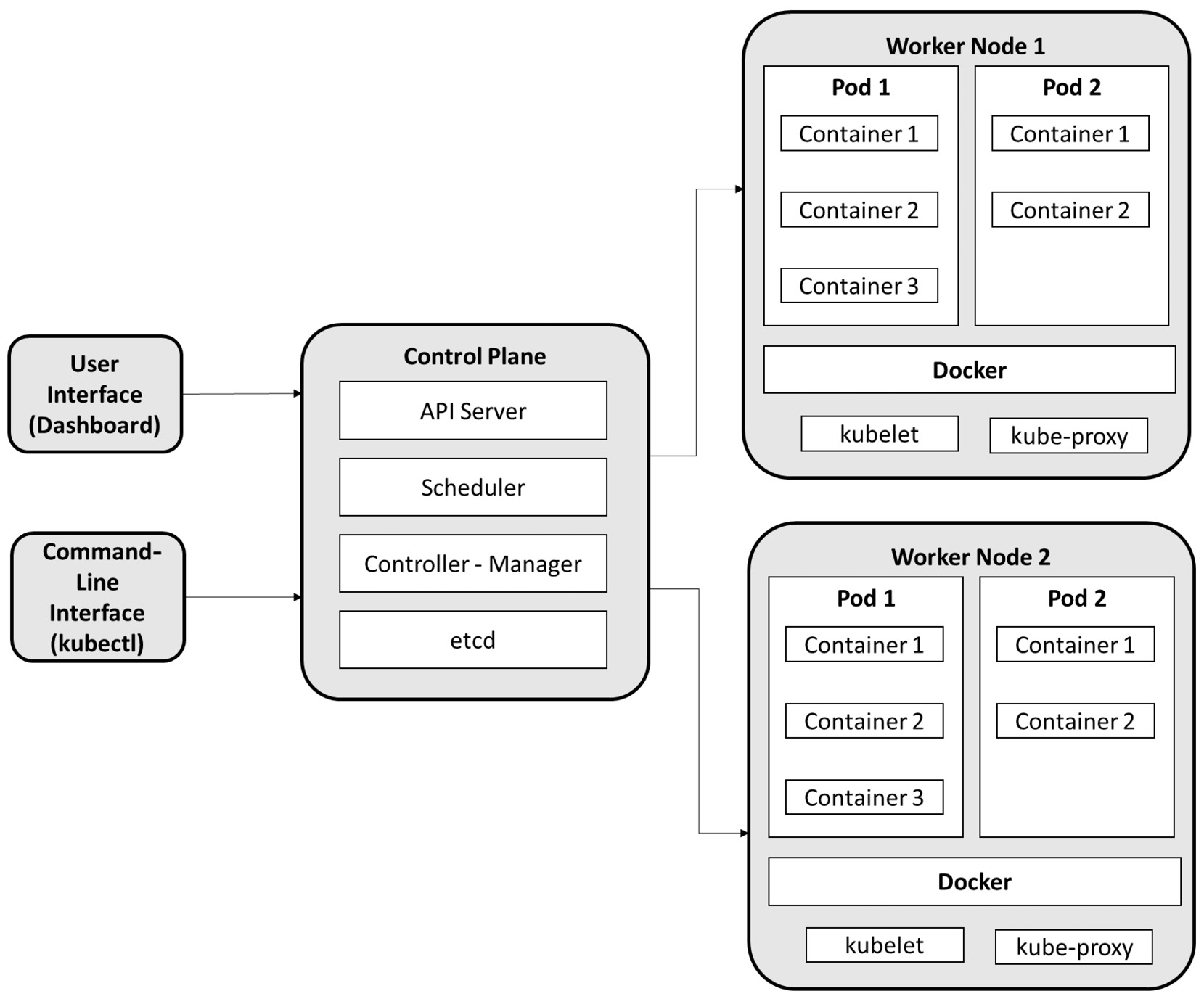
- 集群包含两种资源:
- A control plane that controls the cluster
- Nodes—the worker Nodes that run applications
- 集群中的所有操作都由控制平面协调,包括调度应用程序、维护应用程序的预期状态、扩展应用程序和推出新的更新等等。每个节点可以是一个虚拟机(VM)或一台物理计算机,用作集群中的工作机。
- Kubernetes控制平面是三个进程的集合:应用程序编程接口(API)服务器、控制器管理器和调度程序。
- 集群上每个单独的非控制面板节点都有一个kubelet进程,负责与k8s控制面板通信,一个kube-proxy负责节点的所有网络通信,一个容器运行时,例如docker。
- 当需要在 Kubernetes 上部署应用程序时,控制平面会发出命令来启动应用程序容器,然后容器被控制平面安排在集群的对应节点上运行。
- 节点使用控制平面公开的 Kubernetes API 与控制平面通信。
Design
steps
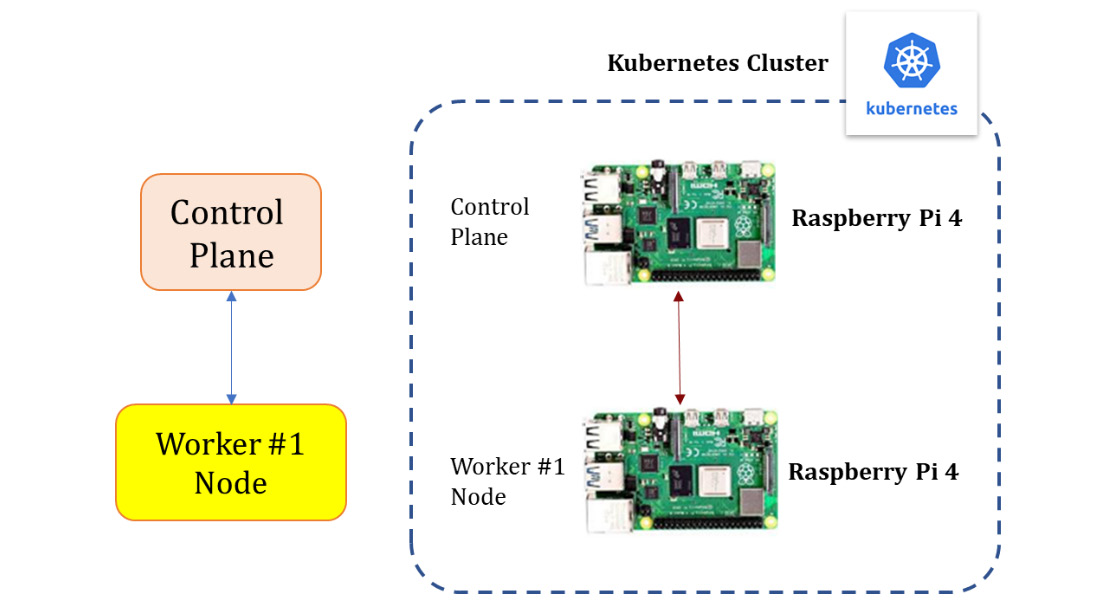
- 在每个板上安装和配置MicroK8s // 使用一个虚拟机代替一个开发板
- 向集群添加节点
- 加入多个deployment部署以形成一个双节点集群(一个控制平面节点/一个工作节点)
安装系统
- 使用Raspberry Pi Imager工具安装ubuntu2
下载网址:https://www.raspberrypi.com/software/
- 系统安装后修改system-boot分区中的network-config配置文件
- 创建ssh空文件
默认用户名密码ubuntu,密码修改后为123456789q
- 配置控制组cgroup
# 进入系统修改 /boot/firmware/cmdline.txt# 或直接修改sd卡system-boot分区中cmdline.txt# 第一行的最前面添加cgroup_enable=memory cgroup_memory=1
安装microk8s
sudo snap install microk8s --classic# 具体可参考microk8s安装
将工作节点添加到Controlplane
$controlplane sudo microk8s.add-node# 提供连接的字符串以及对应指令# eg 注意 加入集群前需将主机名写入集群中hosts文件# 添加工作节点# microk8s join <control plane_ip>:<port>/<token>$worker microk8s join 192.168.31.204:25000/06db3d8dfbbef045ae9bf146f7bb07dc/068ebba17ecd$controlplane kubectl get nodes
删除节点
# 从集群中删除节点 controlsudo microk8s remove-node <node name># 离开集群 workersudo microk8s.leave
部署容器化应用程序
apiVersion: apps/v1kind: Deploymentmetadata:name: nginx-deploymentspec:selector:matchLabels:app: nginxreplicas: 2 # tells deployment to run 2 pods matching the templatetemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.14.2ports:- containerPort: 80affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: "app"operator: Invalues:- nginxtopologyKey: "kubernetes.io/hostname"
# 执行部署示例kubectl apply -f deployment.yaml# 显示有关部署信息kubectl describe deployment nginx-deployment# 验证应用是否已经部署kubectl get pods -l app=nginx# 检查pod的运行位置# kubectl get pods -l app=nginx -o wide
k8s所做的工作:
- 寻找一个合适的节点来运行应用程序的实例(我们有两个可用节点),并根据podAntiAffinity规则安排在对应节点上运行。
- podAntiAffinity规则根据当前节点上运行的其他pod标签限制pod deployment可以调度到哪些节点。
- 已将群集配置为在需要时在新节点上重新调度实例。
使用新软件版本对应用程序执行滚动更新
滚动更新:
- 将应用程序从一个环境转移到另一个环境(通过容器镜像更新)。
- 回滚到应用程序的之前版本。
- 通过最少的停机时间实现应用程序的持续集成和持续交互(CI/CD) continuous integration/delivery
重复使用之前的deployment示例,nginx.1.14.2->nginx 1.16.1
apiVersion: apps/v1kind: Deploymentmetadata:name: nginx-deploymentspec:selector:matchLabels:app: nginxreplicas: 2strategy:rollingUpdate:maxSurge: 0maxUnavailable: 1type: RollingUpdatetemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.16.1 # Update the version of nginx from 1.14.2 to 1.16.1ports:- containerPort: 80affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: "app"operator: Invalues:- nginxtopologyKey: "kubernetes.io/hostname"
# 更新应用部署kubectl apply -f deployment-update.yaml# 查看pod是否重新创建kubectl get pods -l app=nginx
滚动更新的工作原理:
- 使用修改后的配置,它会创建一个新的部署。
- 增加/减少新旧控制器上的副本数量,直到达到正确的数量。
- 最后,原本部署和关联的 pod 将被删除。
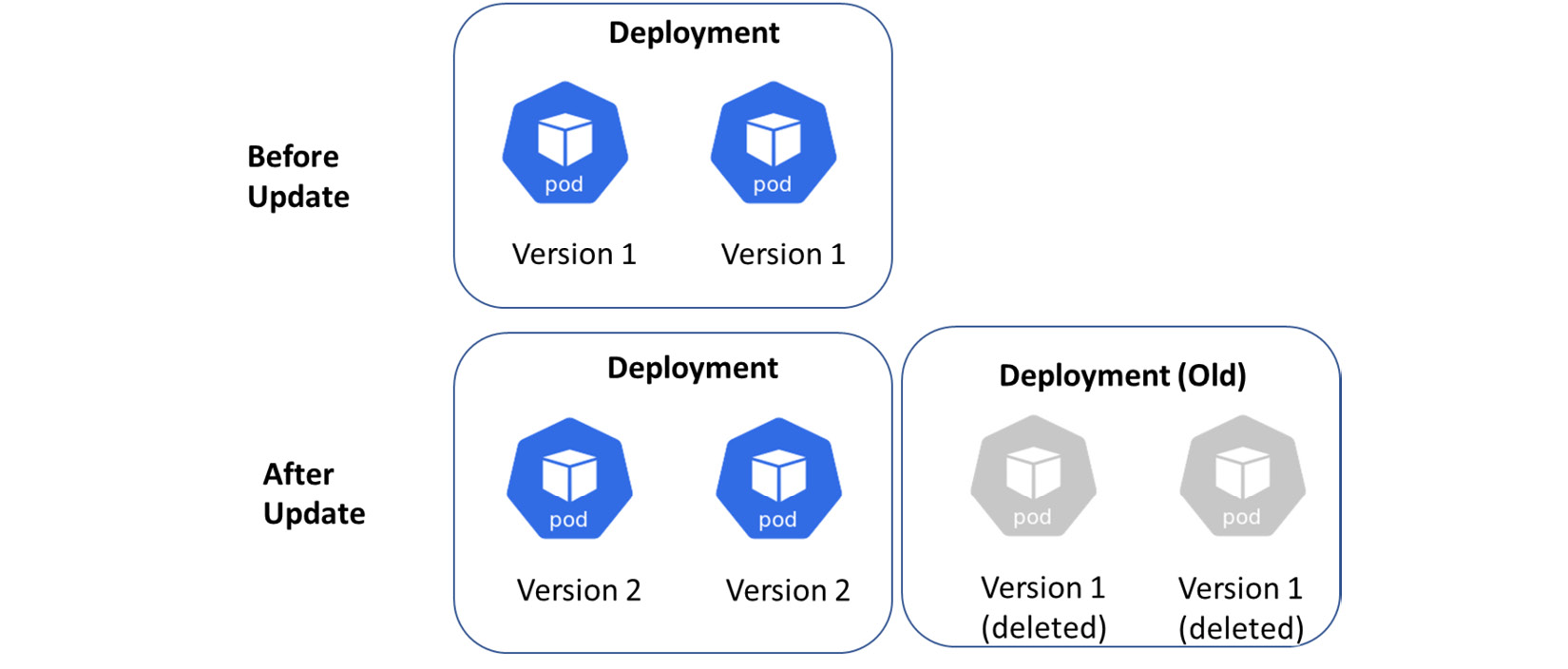
当使用RollingUpdate方法微调更新过程时,还有两个附加选项(yaml文件中属性
maxSurge:在更新期间,可以创建的最大 Pod 数量大于所需的 Pod 数量。
maxUnavailable:升级过程中可能变得不可用的 pod 数量。
maxSurge=0表示一次最多可以生成新的pod数量为0
maxUnavailable=1表示一次最多可以销毁的旧 Pod 数量为1
该策略表明,随着新 pod 的创建,旧的 pod 将被一一销毁
各种k8s deployment策略
Recreate(重建):所有就pod被杀死并用新的替换
Blue/green deployments(蓝/绿部署):旧新版本的应用程序同时部署,两者都启动时,消费者只能访问绿色部署;蓝色部署提供给QA(quality assurance)团队使用,以在不同服务上或通过直接端口转发测试自动化。
Canary deployments(金丝雀部署):类似蓝绿部署,但它更受控制并使用逐步交互的分阶段(progressive delivery phased-in technique)技术,还包括暗执行(dark launch)和A/B测试(A/B testing)。
Dark deployments or A/B deployments(暗部署或A/B部署):金丝雀部署的变体,唯一的区别是暗部署处理前端而不是后端。
扩展应用程序部署
更改部署中的副本数以允许扩展部署。当部署被扩展时,将创建新的 Pod 并将其调度到具有可用资源的节点上。
Kubernetes 也支持自动缩放 Pod,也可以扩展到零,这将终止给定部署中的所有 pod。
apiVersion: apps/v1kind: Deploymentmetadata:name: nginx-deploymentspec:selector:matchLabels:app: nginxreplicas: 4 # Update the replicas from 2 to 4template:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.14.2ports:- containerPort: 80
扩展:
运行应用程序的许多实例需要一种在它们之间分配流量的方法。
内置负载均衡器在一个Services对象中,将网络流量分配给暴露的 Deployment 中的所有 pod;端点将用于持续监控正在运行的 Pod,确保流量仅定向到可用的 Pod。
kubectl apply -f deployment-scale.yamlkubectl get pods -l app=nginx# 使用命令行增加nginx部署(非使用yaml文件kubectl scale deployments/nginx-deployment --replicas=5kubectl scale deployments/nginx-deployment --replicas=4kubectl get pods -o wide
容器生命周期管理
没有限制的容器可能会导致与其他容器发生资源冲突,并导致计算资源消耗效率低下。
可使用ResourceQuota和LimitRange限制资源利用率。- ResourceQuotas用于限制命名空间中所有容器消耗的资源总量;也可以限制其他Kubernetes对象,例如当前名称空间中的pods数量。 Quota 配额
- 如果您担心有人可能使用您的集群生成大量ConfigMaps,您可以使用LimitRange来防止这种情况。

部署和共享HA应用
High Availability
高可用性 (HA) 是系统在指定时间段内连续运行而不会出现故障的能力。

ConfigMap
用于管理应用程序代码之外的所有配置,保存非敏感设置。敏感信息请使用机密资源(例如凭据),机密资源不能作为环境变量传入,而应作为卷安装在容器中。

若有收获,就点个赞吧
0 人点赞
