12.1 网络通信要素—IP和端口号
IP地址
InetAddress:唯一的标识 Internet 上的通信实体。本地回环地址hostAddress为127.0.0.1,主机名hostName为localhost。IPV4:4个字节组成,以点分十进制表示,如192.168.0.1。IPV6:16个字节组成,每个整数用四个十六进制位表示,用 :分开,如:3ffe:3201:1401:1280:c8ff:fe4d:db39:1984
端口号标识正在计算机上运行的进程,端口号为 16 位的整数 0~65535。客户端应用程序的端口号是随机分配的,且同一时刻一个端口号仅可被一个程序使用。
- 公认端口:0~1023。被预先定义的服务通信占用(如:HTTP占用端口 80,FTP占用端口21)
- 注册端口:1024~49151。分配给用户进程或应用程序。(如:Tomcat占用端口8080,MySQL占用端口3306,Oracle占用端口1521等)。 这些是默认的,可以自行修改。
- 动态/私有端口:49152~65535
当在连接网络时输入一个主机的域名后,计算机先到本机查询目的IP地址,没有时则向域名服务器(DNS) 请求将域名转化成IP地址,取得返回值后和主机建立连接。每个域名对应唯一IP
静态方法获取InetAddress实例:public static InetAddress getLocalHost()public static InetAddress getByName(String host)InetAddress常用方法:public String getHostAddress():返回 IP 地址public String getHostName():获取此 IP 地址的主机名public boolean isReachable(int timeout):测试是否可以达到该地址
12.2 网络通信要素—网络协议
通信协议分层思想:同层间可以相互通信、相邻的上层可以调用下层所提供的服务。各层间互不影响。
传输层协议:传输控制协议TCP(Transmission Control Protocol),用户数据报协议UDP(User Datagram Protocol)。
TCP协议:
- 传输前“三次握手”建立点对点连接
- 必须先开启接收端,否则直接连接失败
- 传输完毕需释放已建立的连接,效率低
UDP协议:
- 将数据、源、目的封装成数据包,不需要建立连接。数据报大小限制在64K内
- 发送时不管对方是否准备好,接收方收到也不确认,故是不可靠的,支持广播发送
- 发送数据结束时无需释放资源,开销小,速度快
Socket:网络通信其实就是Socket通信,客户端和服务器的每次通信使用不同的套接字。
public Socket(InetAddress address,int port)创建一个流套接字并将其连接到指定 IP 主机的指定端口号。public Socket(String host,int port)Socket类的常用方法:public InputStream getInputStream()public OutputStream getOutputStream()public InetAddress getInetAddress()如果套接字是未连接的,则返回 null。public InetAddress getLocalAddress()获取套接字绑定的本地地址。public int getPort()此套接字连接到的远程端口号;如果尚未连接套接字,则返回 0。public int getLocalPort()返回此套接字绑定到的本地端口。 如果尚未绑定套接字,则返回 -1。public void close()关闭此套接字。同时关闭该套接字的 InputStream 和 OutputStream。public void shutdownInput()禁用此套接字的输入流public void shutdownOutput()禁用此套接字的输出流。对于 TCP 套接字,任何以前写入的数据都将被发送
12.3 TCP网络编程
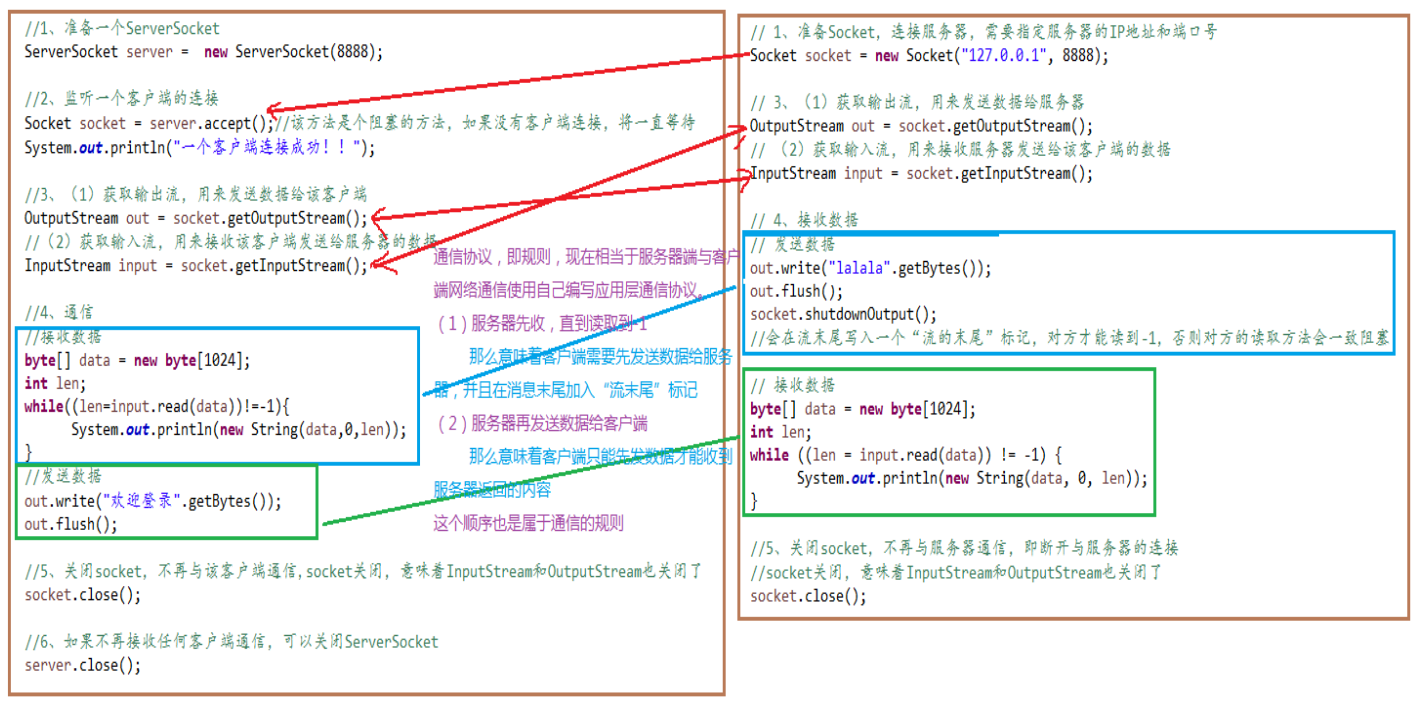
客户端Socket:1.创建 Socket:若服务器响应,则建立客户端到服务器的通信线路。若连接失败,会出现异常。2.获取 Socket 的输入/出流: getInputStream()/getOutputStream()方法获得流3.通过输入流读取服务器传来的信息,通过输出流将信息写入线程。4.关闭 Socket:断开客户端到服务器的连接,释放线路Socket s = new Socket(“192.168.40.165”,9999);OutputStream out = s.getOutputStream();out.write(" hello".getBytes());out.close();s.close();// 可以先判断流是否为null,再关闭更安全
服务器必须事先建立一个等待客户连接的ServerSocket对象。accept()方法会返回一个 Socket 对象。服务器与客户端端口要一致
服务器Socket:1.调用 ServerSocket(int port) :绑定到指定端口上。用于监听客户端的请求。2.调用 accept():监听连接请求,如果客户端请求连接,则接受连接,返回通信Socket。 该方法会持续监听,只要收到连接请求就会执行3.调用S getOutputStream() 和 getInputStream (),开始网络数据的发送和接收。4.关闭ServerSocket和Socket对象ServerSocket ss = new ServerSocket(9999);Socket s = ss.accept ();InputStream in = s.getInputStream();byte[] buf = new byte[1024];int len;while((len = in.read(buf))!=-1)String str = new String(buf,0,num);System.out.println(s.getInetAddress().toString()+”:”+str);s.close();ss.close();
12.4 UDP网络编程
UDP通过数据报套接字 DatagramSocket 发送和接收,系统不保证UDP数据报一定能够安全送到目的地,也不能确定什么时候可以抵达。 数据报中包含了发送端的IP地址和端口号以及接收端的IP地址和端口号,无须建立连接。
DatagramSocket 类的常用方法:public DatagramSocket(int port)创建数据报套接字并将其绑定到本地主机指定端口。套接字将被绑定到通配符地址,IP 地址由内核来选择。public DatagramSocket(int port,InetAddress laddr)创建数据报套接字,将其绑定到指定的本地地址。如果 IP 地址为 0.0.0.0,套接字将被绑定到通配符地址,IP 地址由内核选择。public void close()关闭此数据报套接字。public void send(DatagramPacket p)从此套接字发送数据报包。public void receive(DatagramPacket p)从此套接字接收数据报包。当此方法返回时,DatagramPacket 的缓冲区填充了接收的数据。此方法在接收到数据报前一直阻塞。如果信息比包的长度长,该信息将被截短。public InetAddress getLocalAddress()public int getLocalPort()public InetAddress getInetAddress()如果套接字未连接,则返回 null。public int getPort()返回此套接字的端口。如果套接字未连接,则返回 -1
DatagramPacket类的常用方法:public DatagramPacket(byte[] buf,int length)用来接收长度为 length 的数据包。 length 参数必须小于等于 buf.length。public DatagramPacket(byte[] buf,int length,InetAddress address,int port)构用来将长度为 length 的包发送到指定主机上的指定端口号。length参数必须小于等于 buf.length。public InetAddress getAddress()返回某台机器的 IP 地址,此数据报将要发往该机器或者是从该机器接收到的。public int getPort()返回某台远程主机的端口号,此数据报将要发往该主机或者是从该主机接收到的。public byte[] getData()返回数据缓冲区。接收到的或将要发送的数据从缓冲区中的偏移量 offset 处开始,持续 length 长度。public int getLength()返回将要发送或接收到的数据的长度。
UDP网络通信流程:1. 建立发送端,接收端2. 建立数据包3. 调用Socket的发送、接收方法4. 关闭Socket发送端:DatagramSocket ds = null;try {ds = new DatagramSocket(); // 广播,无需指定端口号byte[] by = "hello,atguigu.com".getBytes();DatagramPacket dp = new DatagramPacket(by, 0, by.length, InetAddress.getByName("127.0.0.1"), 10000); // 构造指向指定进程的数据包ds.send(dp); // 发送数据包} catch (Exception e) {e.printStackTrace();} finally {if (ds != null)ds.close();}接收端:DatagramSocket ds = null;try {ds = new DatagramSocket(10000); // 绑定接收端口byte[] by = new byte[1024];DatagramPacket dp = new DatagramPacket(by, by.length); // 构造空数据包ds.receive(dp); // 接受String str = new String(dp.getData(), 0, dp.getLength()); //System.out.println(str + "--" + dp.getAddress());} catch (Exception e) {e.printStackTrace();} finally {if (ds != null)ds.close();}
12.5 URL编程
URL(Uniform Resource Locator):统一资源定位符,表示Internet 上某一资源的地址,迅雷种子就是一种URL。 其用来标识一个资源,而且还指明了如何定位到这个资源。浏览器通过解析 URL 查找相应的文件或其他资源。
<传输协议>://<主机名>:<端口号>/<文件名>#片段名?参数列表http://192.168.1.100:8080/helloworld/index.jsp#a?username=shkstart&password=123协议 主机名 端口号 文件名 片段名 参数列表#片段名:即锚点,例如看小说,直接定位到章节参数列表:参数名=参数值&参数名= ;键值对写法,连接的服务器可以获取相应信息
URL类的构造器都声明抛出非运行时异常,必须对其进行处理。一个URL对象生成后,其属性是不能被改变的,但可以通过它给定的方法来获取相应属性。
URL 构造函数:public URL (String spec):通过URL地址的字符串构造URL对象public URL(URL context, String spec):通过基 URL 和相对 URL 构造一个 URL 对象。public URL(String protocol, String host, String file); 例如:new URL("http", "www.atguigu.com", “download. html");获取属性的方法:public String getProtocol( ) 获取该URL的协议名public String getHost( ) 获取该URL的主机名public String getPort( ) 获取该URL的端口号public String getPath( ) 获取该URL的文件路径public String getFile( ) 获取该URL的文件名public String getQuery( ) 获取该URL的查询名,即参数列表
若希望输出数据,例如向服务器端的 CGI (公共网关接口)程序发送一些数据,则必须先与URL建立连接,然后才能对其进行读写。
URL netchinaren = new URL ("http://www.atguigu.com/index.shtml");URLConnectonn u = netchinaren.openConnection(); // 通过URL对象获取连接对象u.connect(); // 进行连接u.getInputStream(); // 获取输入流u.disconnect(); // 使用完成后断开连接
URI、URL和URN的区别
URI(Uniform Resource Identifier)是统一资源标识符,用来唯一的标识一个资源。而URL(uniform resource locator)是统一资源定位符,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。而URN(Uniform Resource Name)统一资源命名,是通过名字来标识资源,比如mailto:java-net@java.sun.com。也就是说,URI是以一种抽象的,高层次概念定义统一资源标识,而URL和URN则是具体的资源标识的方式。URL和URN都是一种URI。
12.6 Jsoup网路爬虫与解析
String realUrl = String.format(url, productId, sortType, page);Document doc = Jsoup.connect(realUrl).header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36").ignoreContentType(true).get();String json = getCommentJson(doc.text());JSONObject object = new JSONObject(json);if (flag == 0) {commentMaxPage = object.getInt("maxPage");}flag++;Log.d("MainActivity", object.toString());JSONArray array = object.getJSONArray("comments");for (int i = 0; i < array.length(); i++) {JSONObject jsonObject = (JSONObject) array.get(i);if(!jsonObject.getString("content").contains("此用户未及时填写评价内容")){Comment comment = new Comment();comment.setId(jsonObject.getLong("id"));comment.setContent(jsonObject.getString("content"));comment.setCreation_time(jsonObject.getString("creationTime"));comment.setScore(jsonObject.getInt("score"));comment.setProduct_color(jsonObject.getString("productColor"));comment.setProduct_size(jsonObject.getString("productSize"));commentList.add(comment);}}Thread.sleep(((long) (Math.random() * 2 + 2)) * 1000);} catch (Exception e) {e.printStackTrace();Toast.makeText(context,"程序出现异常,请重新尝试",Toast.LENGTH_LONG).show();}}
// 获取HTML页面的Body部分Document doc = null;try {doc = Jsoup.connect(String.format("https://item.jd.com/%s.html", productId)).get();} catch (IOException e) {e.printStackTrace();}Element body = doc.body();Elements elements = body.select("div[class=w]");// 获取图片for (Element element : elements) {// 爬取商品图片image = element.select("div[class=product-intro clearfix]").select("div[class=preview-wrap]").select("div[class=preview]").select("div[id=spec-n1]").select("img[id=spec-img]").attr("data-origin");if (image != null && image.length() > 0) {break;}}
12.7 JSON
Java没有内置JSON的解析,因此需要借助第三方类库。以下教程基于 FastJson 讲解。
在 Maven 构建的项目中,在 pom.xml 文件中加入以下依赖。
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.47</version></dependency>
从 Java 变量到 JSON 格式的编码过程如下:
public void testJson() {JSONObject object = new JSONObject();//stringobject.put("string","string");//intobject.put("int",2);//booleanobject.put("boolean",true);//arrayList<Integer> integers = Arrays.asList(1,2,3);object.put("list",integers);//nullobject.put("null",null);System.out.println(object);}// {"boolean":true,"string":"string","list":[1,2,3],"int":2}
从 JSON 对象到 Java 变量的解码过程如下:
public void testJson2() {JSONObject object = JSONObject.parseObject("{\"boolean\":true,\"string\":\"string\",\"list\":[1,2,3],\"int\":2}");//stringString s = object.getString("string");//intint i = object.getIntValue("int");//booleanboolean b = object.getBooleanValue("boolean");//listList<Integer> integers = JSON.parseArray(object.getJSONArray("list").toJSONString(),Integer.class);//nullSystem.out.println(object.getString("null"));}
//从字符串解析JSON对象JSONObject obj = JSON.parseObject("{\"runoob\":\"菜鸟教程\"}");//从字符串解析JSON数组JSONArray arr = JSON.parseArray("[\"菜鸟教程\",\"RUNOOB\"]\n");//将JSON对象转化为字符串String objStr = JSON.toJSONString(obj);//将JSON数组转化为字符串String arrStr = JSON.toJSONString(arr);
12.8 Java解析HTML
使用Jsoup.parse(String str)即可将获取到的HTML内容解析得到一个Documend类,剩下的工作就是从Document中选择我们需要的数据了。
<html><div id="blog_list"><div class="blog_title"><a href="url1">第一篇博客</a></div><div class="blog_title"><a href="url2">第二篇博客</a></div><div class="blog_title"><a href="url3">第三篇博客</a></div></div></html>
public class DataLearnerCrawler {public static void main(String[] args) {List<String> titles = new ArrayList<String>();List<String> urls = new ArrayList<String>();String html = "<html><div id=\"blog_list\"><div class=\"blog_title\"><a href=\"url1\">第一篇博客</a></div><div class=\"blog_title\"><a href=\"url2\">第二篇博客</a></div><div class=\"blog_title\"><a href=\"url3\">第三篇博客</a></div></div></html>";//第一步,将字符内容解析成一个Document类Document doc = Jsoup.parse(html);//第二步,根据我们需要得到的标签,选择提取相应标签的内容Elements elements = doc.select("div[id=blog_list]").select("div[class=blog_title]");for( Element element : elements ){String title = element.text();titles.add(title);urls.add(element.select("a").attr("href"));}//输出测试for( String title : titles ){System.out.println(title);}for( String url : urls ){System.out.println(url);}}}/*第一篇博客第二篇博客第三篇博客url1url2url3*/

若有收获,就点个赞吧
0 人点赞
