第1章 概述
数据持久化:将内存中的数据保存到硬盘上,主要存储介质为数据库、文件等。
Java数据存储技术:Java使用 JDBC 直接访问数据库,JDO (Java Data Object )、Hibernate、Mybatis 对 JDBC 进行了封装。
JDBC(Java Database Connectivity)是通用的SQL数据库接口,定义了访问数据库的标准Java类库。其为访问任何提供了JDBC驱动程序的数据库提供了一种统一的途径,这就使得程序员无需对特定的数据库系统有过多的了解,从而大大简化了开发过程,同时保证了Java程序的可移植性。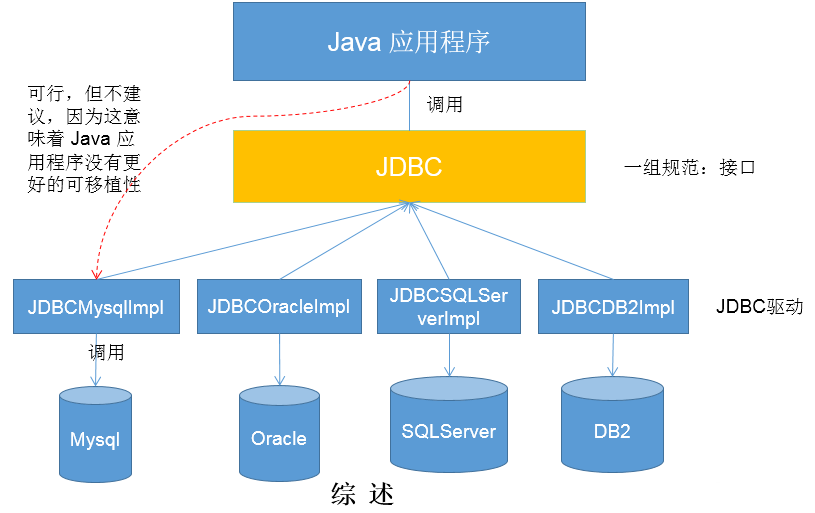
JDBC接口(API)包括两个层次:
- 面向应用的API:Java API,供应用程序开发人员使用(连接数据库,执行SQL语句,获得结果)。
- 面向数据库的API:Java Driver API,供开发商开发数据库驱动程序使用。
JDBC程序编写步骤: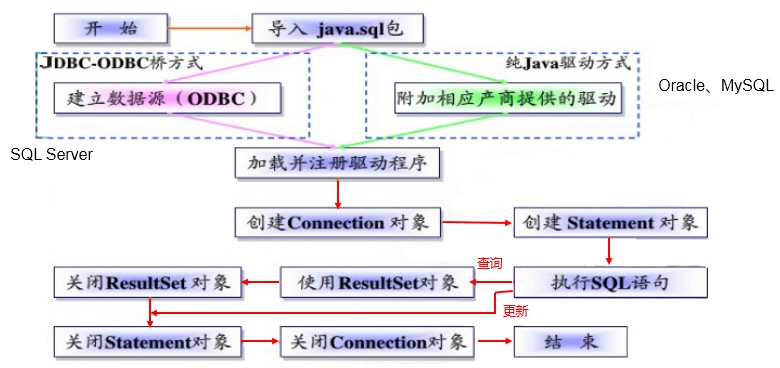
JDBC 使用 ORM 思想(object relational mapping)思想,即:
- 一个数据表对应一个java类
- 表中的一条记录对应java类的一个对象
- 表中的一个字段对应java类的一个属性
sql是需要结合列名和表的属性名来写。注意起别名。
第2章 获取数据库连接
2.1 连接要素
一、Driver接口实现类
java.sql.Driver 接口是提供给数据库厂商使用的,不同数据库厂商提供不同的驱动实现。在应用程序中由java.sql.DriverManager调用这些Driver实现。
- Oracle的驱动:oracle.jdbc.driver.OracleDriver
mySql的驱动: com.mysql.jdbc.Driver
// 加载与注册JDBC驱动Class.forName("com.mysql.jdbc.Driver"); // 加载特定类型数据库的 JDBC 驱动DriverManager.registerDriver(com.mysql.jdbc.Driver); // 使用驱动程序管理类来注册驱动
实现Driver 接口的驱动程序类都会在静态代码块中调用 DriverManager.registerDriver() 来注册自身的一个实例。因此通常来说无需显示调用此方法。
二、URL
JDBC URL 用于标识一个被注册的驱动程序,驱动程序管理器通过 URL 选择驱动程序从而建立到数据库的连接。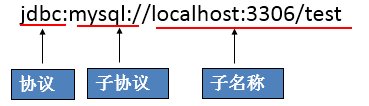
协议:JDBC URL中的协议总是jdbc
- 子协议:子协议用于标识一个数据库驱动程序
- 子名称:一种标识数据库的方法。包含主机名(对应服务端的ip地址),端口号,数据库名
几种常用数据库的 JDBC URL
- MySQL:jdbc:mysql://主机名称:服务端口号/数据库名称?参数=值&参数=值
jdbc:mysql://localhost:3306/atguigu?user=root&password=123456 - Oracle:jdbc:oracle:thin:@主机名称:服务端口号:数据库名称
jdbc:oracle:thin:@localhost:1521:atguigu - SQLServer:jdbc:sqlserver://主机名称:服务端口号:DatabaseName=数据库名称
jdbc:sqlserver://localhost:1433:DatabaseName=atguigu
三、用户名和密码
user,password可以用“属性名=属性值”方式告诉数据库
2.2 数据库连接方式举例(基于MySQL)
@Testpublic void testConnection() throws Exception {//1.使用当前类加载器获取指定配置文件InputStream is = Test.class.getClassLoader().getResourceAsStream("jdbc.properties");Properties pros = new Properties();pros.load(is);//2.读取配置信息中的四大要素String driverClass = pros.getProperty("driverClass");String url = pros.getProperty("url");String user = pros.getProperty("user");String password = pros.getProperty("password");//3.加载JDBC驱动Class.forName(driverClass);//4.获取连接(DriverManager静态代码块进行了JDBC驱动注册,因此无需书写相应代码块)Connection conn = DriverManager.getConnection(url,user,password);}
其中,配置文件声明在工程的src目录下:【jdbc.properties】
user=rootpassword=abc123url=jdbc:mysql://localhost:3306/testdriverClass=com.mysql.jdbc.Driver
使用配置文件可以实现代码和数据的分离,如果需要修改配置信息,直接在配置文件中修改,不需要深入代码,省去重新编译的过程。
第3章 使用PreparedStatement 实现CRUD操作
一个数据库连接就是一个Socket连接。 java.sql 包中分别定义了对数据库的三种不同调用方式:
- Statement:用于执行静态 SQL 语句
- PrepatedStatement:SQL 语句被预编译并存储在此对象中,可以使用此对象多次高效地执行该语句
- CallableStatement:用于执行 SQL 存储过程
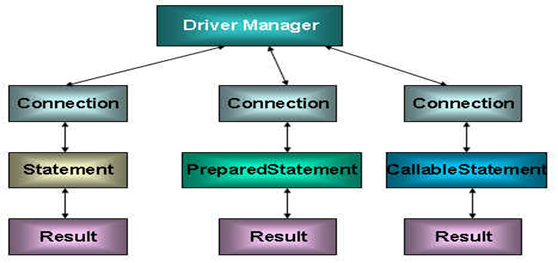
通过调用 Connection 对象的 createStatement() 方法即可创建Statement对象,Statement 接口中定义了下列方法:
int excuteUpdate(String sql):执行更新操作INSERT、UPDATE、DELETEResultSet executeQuery(String sql):执行查询操作SELECT
但是使用Statement操作数据表存在一些弊端:拼串操作,繁琐;存在SQL注入问题。
SQL 注入指利用某些系统没有对用户输入的数据进行充分的检查,在用户输入数据中注入非法的 SQL 语句段或命令(如:SELECT user, password FROM user_table WHERE user='a' OR 1 = ' AND password = ' OR '1' = '1') ,来利用系统的 SQL 引擎完成恶意行为的做法。
为了防范 SQL 注入,要使用 PreparedStatement(从Statement扩展而来) 取代 Statement。
PreparedStatement 接口是 Statement 的子接口,调用 Connection 对象的 preparedStatement(String sql) 获取其对象。对象所代表的 SQL 语句中的参数用 ? 来表示,调用对象的 setXxx() 方法设置参数。
PreparedStatement 的预编译能最大可能提高性能。Statement每执行一次都要对传入的语句编译一次。此外,PreparedStatement 还可以防止 SQL 注入 。
| Java类型 | SQL类型 |
|---|---|
| boolean | BIT |
| byte | TINYINT |
| short | SMALLINT |
| int | INTEGER |
| long | BIGINT |
| String | CHAR,VARCHAR,LONGVARCHAR |
| byte array | BINARY , VAR BINARY |
| java.sql.Date | DATE |
| java.sql.Time | TIME |
| java.sql.Timestamp | TIMESTAMP |
// 对数据库连接和关闭操作进行封装public class JDBCUtils {// 获取数据库连接public static Connection getConnection() throws Exception {// 1.读取配置文件中的4个基本信息InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("jdbc.properties");Properties pros = new Properties();pros.load(is);String driverClass = pros.getProperty("driverClass");String url = pros.getProperty("url");String user = pros.getProperty("user");String password = pros.getProperty("password");// 2.加载驱动并获取连接Class.forName(driverClass);Connection conn = DriverManager.getConnection(url, user, password);return conn;}/**** @Description 关闭连接和Statement或PreparedStatement 的操作* @param conn* @param ps*/public static void closeResource(Connection conn,Statement ps){try {if(ps != null)ps.close();} catch (SQLException e) {e.printStackTrace();}try {if(conn != null)conn.close();} catch (SQLException e) {e.printStackTrace();}}/**** @Description 关闭资源操作* @param conn* @param ps* @param rs*/public static void closeResource(Connection conn,Statement ps,ResultSet rs){try {if(ps != null)ps.close();} catch (SQLException e) {e.printStackTrace();}try {if(conn != null)conn.close();} catch (SQLException e) {e.printStackTrace();}try {if(rs != null)rs.close();} catch (SQLException e) {e.printStackTrace();}}}
数据库操作后要释放ResultSet, Statement,Connection。Connection用完后必须马上释放,否则有可能导致系统宕机。Connection的使用应当是尽量晚创建,尽量早的释放。可以在finally中关闭,保证即使其他代码出现异常,资源也一定能被关闭。
3.1 使用PreparedStatement实现增、删、改以及创建表
/** @Description 通用增、删、改操作* @param sql 泛化的增删改sql语句,不同的操作主要区别于SQL语句* @param Object 可变长度的SQL语句填充参数*/public void update(String sql,Object ... args){Connection conn = null;PreparedStatement ps = null;try {//1.获取数据库的连接conn = JDBCUtils.getConnection();//2.获取PreparedStatement的实例 (或:预编译sql语句)ps = conn.prepareStatement(sql);//3.填充占位符for(int i = 0;i < args.length;i++){ps.setObject(i + 1, args[i]); // 设置SQL语句占位符}//4.执行sql语句ps.execute();} catch (Exception e) {e.printStackTrace();}finally{//5.关闭资源JDBCUtils.closeResource(conn, ps);}}/*例子:String sql = "update customers set name = ? where id = ?";...ps.setObject(1,"莫扎特"); 填充占位符nameps.setObject(2,18); 填充占位符id*/
表的创建依然可使用ps.execute();方法,主要是将传入的SQL语句改为创建表操作即可。
3.2 使用PreparedStatement实现查询
3.2.1 ResultSet
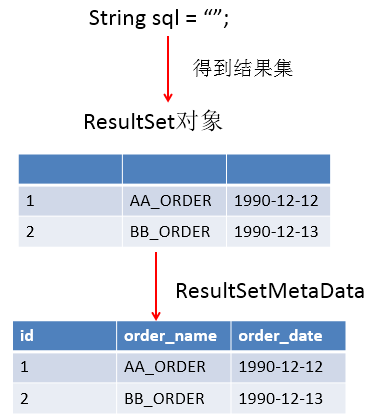
查询需要调用PreparedStatement 的 executeQuery(),查询结果是一个ResultSet对象。ResultSet 是一张数据表,该接口由数据库厂商提供。ResultSet 对象维护了一个指向当前数据行的游标,通过next() 方法移动到下一行或检测下一行是否有效。若有效,该方法返回 true,且指针下移。相当于Iterator对象的 hasNext() 和 next() 方法的结合体。可以通过 getXxx(int index) 或 getXxx(int columnName) 获取每一列的值。例如: getInt(1), getString(“name”)。
3.2.2 ResultSetMetaData
用于获取 ResultSet 对象中列的类型和属性信息的对象。ResultSetMetaData meta = rs.getMetaData();
- getColumnName(int column):获取指定列的名称
- getColumnLabel(int column):获取指定列的别名
- getColumnCount():返回当前 ResultSet 对象中的列数。
- getColumnTypeName(int column):检索指定列的数据库类型。
- getColumnDisplaySize(int column):指示指定列的最大标准宽度,以字符为单位。
- isNullable(int column):指示指定列中的值是否可以为 null。
- isAutoIncrement(int column):指示是否自动为指定列进行编号。
public void testGetForList(){// 使用通用方法查询Customer表String sql = "select id,name,email from customers where id < ?";List<Customer> list = getForList(Customer.class,sql,12);list.forEach(System.out::println);// 使用通用方法查询Order表String sql1 = "select order_id orderId,order_name orderName from `order`";List<Order> orderList = getForList(Order.class, sql1);orderList.forEach(System.out::println);}/** @Description 针对不同表的通用查询操作* @param clazz 对应表的Class类型* @param sql 带占位符的相应数据库SQL语句* @param args 可变长占位符参数*/public <T> List<T> getForList(Class<T> clazz,String sql, Object... args){Connection conn = null;PreparedStatement ps = null;ResultSet rs = null;try {// 1.获取数据库连接conn = JDBCUtils.getConnection();// 2.预编译sql语句,得到PreparedStatement对象ps = conn.prepareStatement(sql);// 3.填充占位符for (int i = 0; i < args.length; i++) {ps.setObject(i + 1, args[i]);}// 4.执行executeQuery(),得到结果集:ResultSetrs = ps.executeQuery();// 5.得到结果集的元数据:ResultSetMetaDataResultSetMetaData rsmd = rs.getMetaData();// 6.1通过ResultSetMetaData得到结果集中的列数(即有几个参数类型)int columnCount = rsmd.getColumnCount();ArrayList<T> list = new ArrayList<T>();while (rs.next()) { // 遍历结果集T t = clazz.newInstance(); // 获取相应的Class类型// 处理结果集一行数据中的每一个列:给t对象指定的属性赋值for (int i = 0; i < columnCount; i++) {Object columValue = rs.getObject(i + 1); // 获取列值String columnLabel = rsmd.getColumnLabel(i + 1); // 获取列标签// 6.2使用反射,给对象的相应属性赋值Field field = clazz.getDeclaredField(columnLabel);field.setAccessible(true);field.set(t, columValue);}list.add(t);}return list;} catch (Exception e) {e.printStackTrace();} finally {// 7.关闭资源JDBCUtils.closeResource(conn, ps, rs);}return null;}
3.3 操作BLOB类型
MySQL中BLOB是的大型容器,插入BLOB类型的数据必须使用PreparedStatement,该类型的数据无法使用字符串拼接。实际使用中根据需要存入的数据大小定义不同的BLOB类型。如果存储的文件过大,数据库的性能会下降。
| 类型 | 大小 |
|---|---|
| TinyBlob | 最大 255B |
| Blob | 最大 65KB |
| MediumBlob | 最大 16MB |
| LongBlob | 最大 4G |
如果在指定了Blob类型以后,还报错:xxx too large,可在mysql安装目录下找my.ini文件加上如下的配置参数: max_allowed_packet=16M,之后重新启动mysql服务。
一、向数据表中插入大数据类型
//获取连接Connection conn = JDBCUtils.getConnection();String sql = "insert into customers(name,email,birth,photo)values(?,?,?,?)";PreparedStatement ps = conn.prepareStatement(sql);// 填充占位符ps.setString(1, "徐海强");ps.setString(2, "xhq@126.com");ps.setDate(3, new Date(new java.util.Date().getTime()));// 操作Blob类型的变量FileInputStream fis = new FileInputStream("xhq.png");ps.setBlob(4, fis);//执行ps.execute();// 资源关闭fis.close();JDBCUtils.closeResource(conn, ps);
二、修改数据表中的Blob类型字段
Connection conn = JDBCUtils.getConnection();String sql = "update customers set photo = ? where id = ?";PreparedStatement ps = conn.prepareStatement(sql);// 填充占位符FileInputStream fis = new FileInputStream("coffee.png");ps.setBlob(1, fis);ps.setInt(2, 25);//执行ps.execute();// 资源关闭fis.close();JDBCUtils.closeResource(conn, ps);
三、从数据表中读取大数据类型
Connection conn = JDBCUtils.getConnection();String sql = "SELECT photo FROM customer WHERE id = ?";ps = conn.prepareStatement(sql);ps.setInt(1, 8);//执行查询rs = ps.executeQuery();if(rs.next()){//读取Blob类型的字段Blob photo = rs.getBlob(1);InputStream is = photo.getBinaryStream(); // 获取文件二进制流OutputStream os = new FileOutputStream("c.jpg"); // 构建文件输出流// 从输入流读取信息并向输出流写入数据byte [] buffer = new byte[1024];int len = 0;while((len = is.read(buffer)) != -1){os.write(buffer, 0, len);}if(is != null){is.close();}if(os != null){os.close();}}// 资源关闭JDBCUtils.closeResource(conn, ps, rs);
3.4 批量插入
使用批量处理的方式将比直接操作节省大量与数据库交互的时间,JDBC的批量处理语句包括下面三个方法:
- addBatch(String):添加批量处理的SQL语句或参数;
- executeBatch():执行批量处理语句;
- clearBatch():清空缓存的数据
通常我们会遇到两种批量执行SQL语句的情况:
- 多条SQL语句的批量处理;
- 一个SQL语句的批量传参;
mysql服务器默认关闭批处理,需要在配置文件url参数后加上?rewriteBatchedStatements=true开启批处理支持。
下面示例向数据表中插入20000条数据
CREATE TABLE goods(id INT PRIMARY KEY AUTO_INCREMENT,NAME VARCHAR(20));
@Testpublic void testInsert() throws Exception{Connection conn = JDBCUtils.getConnection();conn.setAutoCommit(false); // 设置为不自动提交数据,进一步减少和数据库的操作String sql = "insert into goods(name)values(?)";PreparedStatement ps = conn.prepareStatement(sql);// 进行批量插入操作for(int i = 1;i <= 1000000;i++){ps.setString(1, "name_" + i);//1.“攒”sqlps.addBatch();if(i % 500 == 0){//2.执行ps.executeBatch();//3.清空ps.clearBatch();}}conn.commit(); // 手动提交数据JDBCUtils.closeResource(conn, ps);}
第4章 数据库事务
4.1 简介
- 事务:一组逻辑操作单元(CRUD操作),使数据从一种状态变换到另一种状态。
- 事务处理:当一个事务中执行多个操作时,要么所有的事务都被提交(commit),这些修改永久地保存下来;要么数据库管理系统将放弃所有修改,整个事务回滚(rollback)到最初状态。
在JDBC中数据一旦提交,就不可回滚。当一个连接对象被创建时,默认情况下是自动提交事务的,在这种情况下每执行一个 SQL 语句,如果执行成功,就会向数据库自动提交,而不能回滚。当关闭数据库连接,数据就会自动提交。如果多个操作都使用的是自己单独的连接,则无法保证事务。因此同一个事务的多个操作必须在同一个连接下。
- 调用 Connection 对象的 setAutoCommit(false); 以取消自动提交事务
- 在所有的 SQL 语句都成功执行后,调用 commit(); 方法提交事务
- 在出现异常时,调用 rollback(); 方法回滚事务
若此时 Connection 没有被关闭,还可能被重复使用,则需要恢复其自动提交状态 setAutoCommit(true)。尤其是在使用数据库连接池技术执行close()方法前,建议恢复自动提交状态。
// 【案例:用户AA向用户BB转账100】public void testJDBCTransaction() {Connection conn = null;try {// 1.获取数据库连接conn = JDBCUtils.getConnection();// 2.开启事务conn.setAutoCommit(false);// 3.进行数据库操作String sql1 = "update user_table set balance = balance - 100 where user = ?";update(conn, sql1, "AA");// 模拟网络异常//System.out.println(10 / 0);String sql2 = "update user_table set balance = balance + 100 where user = ?";update(conn, sql2, "BB");// 4.若没有异常,则提交事务conn.commit();} catch (Exception e) {e.printStackTrace();// 5.若有异常,则回滚事务try {conn.rollback();} catch (SQLException e1) {e1.printStackTrace();}} finally {try {//6.恢复自动提交功能conn.setAutoCommit(true);} catch (SQLException e) {e.printStackTrace();}//7.关闭连接JDBCUtils.closeResource(conn, null, null);}}
4.2 事务的ACID属性
- 原子性(Atomicity)指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
- 一致性(Consistency)事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
- 隔离性(Isolation)指一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性(Durability)指一个事务一旦被提交,它对数据库中数据的改变就是永久性的。
4.2.1 数据库的并发问题
同时运行的多个事务访问数据库中相同的数据时, 如果没有采取必要的隔离机制, 就会导致各种并发问题:
脏读: T1 读取了已经被 T2 更新但还没有被提交的字段。之后, 若 T2 回滚, T1读取的内容就是临时且无效的。
- 不可重复读: T1 读取了一个字段, 然后 T2 更新了该字段。之后, T1再次读取同一个字段, 值就不同了。
- 幻读: T1 从一个表中读取了一个字段, 然后 T2 在该表中插入了一些新的行。之后, 如果 T1 再次读取同一个表, 就会多出几行。
一个事务与其他事务隔离的程度称为隔离级别,不同隔离级别对应不同的干扰程度,隔离级别越高,数据一致性越好, 但并发性越弱。数据库提供4种事务隔离级别,Mysql默认的事务隔离级别为: REPEATABLE READ:
| 隔离级别 | 描述 |
|---|---|
| READ UNCOMMITTED(读取提交数据) | 允许事务读取未被其他事务提交的变更。三个问题都不会避免 |
| READ COMMITTED(读已提交数据) | 只允许事务读取已被其它事务提交的变更。仅可避免脏读 |
| REPEATABLE READ(可重复读) | 确保事务可以多次从一个字段中读取相同的值。在这个事务持续期间,禁止其他事物对这个字段进行更新。可以避免脏读和不可重复读 |
| SERIALIZABLE(串行化) | 确保事务可以从一个表中读取相同的行。在这个事务持续期间,禁止其他事务对该表执行插入,更新和删除操作,所有并发问题都可以避免,但性能十分低 |
4.2.2 为MySql设置隔离级别
每启动一个 mysql 程序, 就会获得一个单独的数据库连接。每个数据库连接都有一个全局变量 @@tx_isolation, 表示当前的事务隔离级别。
查看当前的隔离级别:
SELECT @@tx_isolation;
设置当前 mySQL 连接的隔离级别为READ COMMITTED:
set transaction isolation level read committed;
设置数据库系统的全局的隔离级别为READ COMMITTED:
set global transaction isolation level read committed;
第5章 数据库连接池
5.1 数据库连接池
传统基于数据库的设计模式每次执行完SQL操作后都要断开数据库连接,这将导致很多问题:
频繁进行数据库连接将占用很多的系统资源,可能会造成服务器崩溃。
- 若忘记断开数据库连接且程序出现异常,将会导致数据库中的内存泄漏,最终将导致重启数据库。
- 不能控制被创建的连接对象的数量,系统资源会被毫无顾及的分配出去,如连接过多,也可能导致内存泄漏,服务器崩溃。
基本思想:为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。
数据库连接池负责分配、管理和释放数据库连接。数据库连接池中数据库连接的数量是由最小数据库连接数决定的,最大数据库连接数量限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
数据库连接池技术的优点
- 资源重用:避免了频繁创建,释放连接引起的大量性能开销,增加系统运行环境的平稳性。
- 更快的系统反应速度:连接池中的数据库连接的初始化工作均已完成。直接利用现有可用连接,避免了连接初始化和释放过程的时间开销,从而减少了系统的响应时间。
- 新的资源分配手段:对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接池的配置,实现某一应用最大可用数据库连接数的限制,避免某一应用独占所有的数据库资源。
- 避免数据库连接泄漏:可根据预先的占用超时设定,强制回收被占用连接,从而避免了常规数据库连接操作中可能出现的资源泄露。
5.2 开源的数据库连接池
JDBC 的数据库连接池使用 javax.sql.DataSource 来表示,该接口通常由服务器(Weblogic, WebSphere, Tomcat)提供实现,也有一些开源组织提供实现:
C3P0 速度相对较慢,但比较稳定。Hibernate官方推荐使用。
- DBCP 是 Tomcat 服务器自带的数据库连接池。速度相对较快,但自身存在BUG,Hibernate3已不再提供支持。
- Druid 是阿里提供的数据库连接池,速度和稳定性都不错。
DataSource取代DriverManager来获取Connection,获取速度快,同时可以大幅度提高数据库访问速度。整个应用只需要一个数据源即可。当数据库访问结束后,程序还是像以前一样关闭数据库连接:conn.close(); 但并没有关闭数据库的物理连接,而是将数据库连接归还给了数据库连接池。
5.2.1 C3P0数据库连接池
//使用C3P0数据库连接池的配置文件方式,获取数据库的连接private static DataSource cpds = new ComboPooledDataSource("helloc3p0");public static Connection getConnection() throws SQLException{Connection conn = cpds.getConnection();return conn;}
其中,src下的配置文件为:【c3p0-config.xml】
<?xml version="1.0" encoding="UTF-8"?><c3p0-config><named-config name="helloc3p0"><!-- 获取连接的4个基本信息 --><property name="user">root</property><property name="password">abc123</property><property name="jdbcUrl">jdbc:mysql:///test</property><property name="driverClass">com.mysql.jdbc.Driver</property><!-- 涉及到数据库连接池的管理的相关属性的设置 --><!-- 若数据库连接池中连接数不足时, 一次向数据库服务器申请多少个连接 --><property name="acquireIncrement">5</property><!-- 初始化数据库连接池时连接的数量 --><property name="initialPoolSize">5</property><!-- 数据库连接池中的最小的数据库连接数 --><property name="minPoolSize">5</property><!-- 数据库连接池中的最大的数据库连接数 --><property name="maxPoolSize">10</property><!-- C3P0 数据库连接池可以维护的 Statement 的个数 --><property name="maxStatements">20</property><!-- 每个连接同时可以使用的 Statement 对象的个数 --><property name="maxStatementsPerConnection">5</property></named-config></c3p0-config>
5.2.2 DBCP数据库连接池
如需使用该连接池实现,应在系统中增加如下两个 jar 文件:
- Commons-dbcp.jar:连接池的实现
- Commons-pool.jar:连接池实现的依赖库
该数据库连接池既可以与应用服务器整合使用,也可由应用程序独立使用。
配置属性说明:
| 属性 | 默认值 | 说明 |
|---|---|---|
| initialSize | 0 | 连接池启动时创建的初始化连接数量 |
| maxActive | 8 | 连接池中可同时连接的最大的连接数 |
| maxIdle | 8 | 连接池中最大的空闲连接数,超过的空闲连接将被释放,如果设置为负数表示不限制 |
| minIdle | 0 | 连接池中最小的空闲连接数,低于这个数量会创建新的连接。该参数越接近maxIdle,性能越好,但不能太大。 |
| maxWait | 无限制 | 最大等待时间,当没有可用连接时,连接池等待连接释放的最大时间,超过该时间限制会抛出异常,如果设置-1表示无限等待 |
| poolPreparedStatements | false | 开启池的Statement是否prepared |
| maxOpenPreparedStatements | 无限制 | 开启池的prepared 后的同时最大连接数 |
| minEvictableIdleTimeMillis | 连接池中的连接在时间段内一直空闲, 被逐出连接池的时间 | |
| removeAbandonedTimeout | 300 | 超过时间限制回收没有用的连接 |
| removeAbandoned | false | 超过removeAbandonedTimeout时间后,是否进行没用连接的回收 |
//使用dbcp数据库连接池的配置文件方式,获取数据库的连接
private static DataSource source = null;
static{
try {
Properties pros = new Properties();
InputStream is = DBCPTest.class.getClassLoader().getResourceAsStream("dbcp.properties");
pros.load(is);
//根据提供的BasicDataSourceFactory使用配置文件创建对应的DataSource对象
source = BasicDataSourceFactory.createDataSource(pros);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConnection() throws Exception {
Connection conn = source.getConnection();
return conn;
}
其中,src下的配置文件为:【dbcp.properties】
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true&useServerPrepStmts=false
username=root
password=abc123
initialSize=10
#...
5.2.3 Druid(德鲁伊)数据库连接池
Druid结合了C3P0、DBCP、Proxool等数据库连接池的优点,同时加入了日志监控,可以说是目前最好的连接池之一。
public static Connection getConnection() throws Exception {
Properties pro = new Properties();
pro.load(TestDruid.class.getClassLoader().getResourceAsStream("druid.properties"));
DataSource ds = DruidDataSourceFactory.createDataSource(pro);
return conn = ds.getConnection();
}
其中,src下的配置文件为:【druid.properties】
url=jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true
username=root
password=123456
driverClassName=com.mysql.jdbc.Driver
initialSize=10
maxActive=20
maxWait=1000
filters=wall
| 配置 | 缺省 | 说明 |
|---|---|---|
| name | 用于监控。如果没有配置,将会自动生成:”DataSource-“ + System.identityHashCode(this) | |
| url | 连接数据库的url | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里:https://github.com/alibaba/druid/wiki/使用ConfigFilter | |
| driverClassName | 根据url自动识别 这一项可配可不配(建议配置下) | |
| initialSize | 0 | 初始化时建立物理连接的个数。 |
| maxActive | 8 | 最大连接池数量 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxOpenPreparedStatements | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会有作用。 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,也执行检测连接是否有效。 |
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有:监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall | |
| proxyFilters | 类型是List,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
第6章 Apache-DBUtils
6.1 简介
commons-dbutils.jar 是对JDBC的简单封装,学习成本极低,并且能极大简化编码量,同时不影响性能。
- org.apache.commons.dbutils.QueryRunner:提供数据库操作的一系列重载的update()和query()操作
- org.apache.commons.dbutils.ResultSetHandler:此接口用于处理数据库查询操作得到的结果集。不同的结果集的情形由不同的子类来实现
工具类:org.apache.commons.dbutils.DbUtils
6.2 主要API的使用
6.2.1 DbUtils
提供如关闭连接、装载JDBC驱动程序等常规工作,里面的所有方法都是静态的。
public static void close(…) throws java.sql.SQLException:检查所提供的参数是不是NULL,如果不是就关闭Connection、Statement和ResultSet。
- public static void closeQuietly(…):检查所提供的参数是不是NULL,如果不是就关闭Connection、Statement和ResultSet,同时隐藏一些在程序中抛出的SQLEeception。
- public static void commitAndClose(Connection conn)throws SQLException: 提交连接,然后关闭连接
- public static void commitAndCloseQuietly(Connection conn): 提交连接,然后关闭连接,并且在关闭连接时不抛出SQL异常。
- public static void rollback(Connection conn)throws SQLException:允许conn为null,因为方法内部做了判断
- public static void rollbackAndClose(Connection conn)throws SQLException
- rollbackAndCloseQuietly(Connection)
public static boolean loadDriver(java.lang.String driverClassName):装载并注册JDBC驱动程序,如果成功就返回true。
6.2.2 QueryRunner类
简单化了SQL查询,与ResultSetHandler一起使用可以完成大部分的数据库操作。
更新
- public int update(Connection conn, String sql, Object… params) throws SQLException:用来执行一个更新(插入、更新或删除)操作,返回受影响条数。
- 插入
- public T insert(Connection conn,String sql,ResultSetHandler rsh, Object… params) throws SQLException:只支持INSERT语句
- 批处理
- public int[] batch(Connection conn,String sql,Object[][] params)throws SQLException: 支持INSERT, UPDATE, or DELETE语句
- public T insertBatch(Connection conn,String sql,ResultSetHandler rsh,Object[][] params)throws SQLException:只支持INSERT语句
- …..
查询
接口的主要实现类:
- ArrayHandler:把结果集中的第一行数据转成对象数组。
- ArrayListHandler:把结果集中的每一行数据都转成一个数组,再存放到List中。
- ColumnListHandler:将结果集中某一列的数据存放到List中。
- BeanHandler:将结果集中的第一行数据封装到一个对应的JavaBean实例中。
- BeanListHandler:将结果集中的每一行数据都封装到一个对应的JavaBean实例中,存放到List里。
- KeyedHandler(name):将结果集中的每一行数据都封装到一个Map里,再把这些Map存到一个map里,其key为指定的key。
- MapHandler:将结果集中的第一行数据封装到一个Map里,key是列名,value就是对应的值。
- MapListHandler:将结果集中的每一行数据都封装到一个Map里,然后再存放到List
- ScalarHandler:查询单个值对象,如
select count(*)```java /*
- 测试查询:查询多条记录构成的集合
使用ResultSetHandler的实现类:BeanListHandler */ @Test public void testQueryList() throws Exception{ QueryRunner runner = new QueryRunner(); Connection conn = JDBCUtils.getConnection3(); String sql = “select id,name,email,birth from customers where id < ?”;
BeanListHandler
handler = new BeanListHandler<>(Customer.class); List
list = runner.query(conn, sql, handler, 23); list.forEach(System.out::println);
JDBCUtils.closeResource(conn, null); }自定义返回一个类对象的ResultSetHandler的实现类 */ @Test public void testQueryInstance1() throws Exception{ QueryRunner runner = new QueryRunner(); Connection conn = JDBCUtils.getConnection3(); String sql = “select id,name,email,birth from customers where id = ?”;
ResultSetHandler
handler = new ResultSetHandler () { @Override public Customer handle(ResultSet rs) throws SQLException {
if(rs.next()){ int id = rs.getInt("id"); String name = rs.getString("name"); String email = rs.getString("email"); Date birth = rs.getDate("birth"); return new Customer(id, name, email, birth); } return null;} };
Customer customer = runner.query(conn, sql, handler, 23);
System.out.println(customer); JDBCUtils.closeResource(conn, null); }使用ScalarHandler */ @Test public void testQueryValue() throws Exception{ QueryRunner runner = new QueryRunner(); Connection conn = JDBCUtils.getConnection3();
//测试一: // String sql = “select count(*) from customers where id < ?”; // ScalarHandler handler = new ScalarHandler(); // long count = (long) runner.query(conn, sql, handler, 20); // System.out.println(count);
//测试二: String sql = “select max(birth) from customers”; ScalarHandler handler = new ScalarHandler(); Date birth = (Date) runner.query(conn, sql, handler); System.out.println(birth);
JDBCUtils.closeResource(conn, null); } ```
第7章 DAO及相关实现类
DAO(Data Access Object)即访问数据信息的类和接口,封装了针对于数据表的通用的操作。有时也称作:BaseDAO。目的是为了实现功能的模块化,更有利于代码的维护和升级。
层次结构:

【BaseDAO.java】
/**
* 用于被继承的对数据库进行基本操作的通用Dao
* @param <T>
*/
public abstract class BaseDao<T> { // 定义为抽象类主要是为了突出该类需要被继承
private QueryRunner queryRunner = new QueryRunner();
private Class<T> type; // 接收泛型的类型
// 构造函数:获取T的Class对象,获取泛型的类型,泛型是在被子类继承时才确定
public BaseDao() {
// 获取子类的类型
Class clazz = this.getClass();
// 获取父类的类型
// getGenericSuperclass()用来获取当前类的父类的类型
// ParameterizedType表示的是带泛型的类型
ParameterizedType parameterizedType = (ParameterizedType) clazz.getGenericSuperclass();
// getActualTypeArguments获取具体的泛型的类型
Type[] types = parameterizedType.getActualTypeArguments();
this.type = (Class<T>) types[0];
}
/**
* 通用的增删改操作
*/
public int update(Connection conn,String sql, Object... params) {
int count = 0;
try {
count = queryRunner.update(conn, sql, params);
} catch (SQLException e) {
e.printStackTrace();
}
return count;
}
/**
* 获取一个对象
*
* @param sql
* @param params
* @return
*/
public T getBean(Connection conn,String sql, Object... params) {
T t = null;
try {
t = queryRunner.query(conn, sql, new BeanHandler<T>(type), params);
} catch (SQLException e) {
e.printStackTrace();
}
return t;
}
/**
* 获取所有对象
*
* @param sql
* @param params
* @return
*/
public List<T> getBeanList(Connection conn,String sql, Object... params) {
List<T> list = null;
try {
list = queryRunner.query(conn, sql, new BeanListHandler<T>(type), params);
} catch (SQLException e) {
e.printStackTrace();
}
return list;
}
/**
* 获取一个数值的方法,专门用来执行像 select count(*)...这样的sql语句
*
* @param sql
* @param params
* @return
*/
public Object getValue(Connection conn,String sql, Object... params) {
Object count = null;
try {
// 调用queryRunner的query方法获取一个单一的值
count = queryRunner.query(conn, sql, new ScalarHandler<>(), params);
} catch (SQLException e) {
e.printStackTrace();
}
return count;
}
}
【BookDAO.java】
/*
* 定义需要实现的模板化操作
*/
public interface BookDao {
/**
* 从数据库中查询出所有的记录
*
* @return
*/
List<Book> getBooks(Connection conn);
/**
* 向数据库中插入一条记录
*
* @param book
*/
void saveBook(Connection conn,Book book);
/**
* 从数据库中根据图书的id删除一条记录
*
* @param bookId
*/
void deleteBookById(Connection conn,String bookId);
/**
* 根据图书的id从数据库中查询出一条记录
*
* @param bookId
* @return
*/
Book getBookById(Connection conn,String bookId);
/**
* 根据图书的id从数据库中更新一条记录
*
* @param book
*/
void updateBook(Connection conn,Book book);
}
【BookDaoImpl.java】
/*
* 对于某种类型对象的具体实现类
* 其继承了集成通用方法的BaseDao<T>并实现了声明特定对象Book要实现方法的接口BookDao
*/
public class BookDaoImpl extends BaseDao<Book> implements BookDao {
@Override
public List<Book> getBooks(Connection conn) {
List<Book> beanList = null;
String sql = "select id,title,author,price,sales,stock,img_path imgPath from books";
// 调用BaseDao中得到一个List的方法
beanList = getBeanList(conn,sql);
return beanList;
}
@Override
public void saveBook(Connection conn,Book book) {
String sql = "insert into books(title,author,price,sales,stock,img_path) values(?,?,?,?,?,?)";
// 调用BaseDao中通用的增删改的方法
update(conn,sql, book.getTitle(), book.getAuthor(), book.getPrice(), book.getSales(), book.getStock(),book.getImgPath());
}
@Override
public void deleteBookById(Connection conn,String bookId) {
String sql = "DELETE FROM books WHERE id = ?";
// 调用BaseDao中通用增删改的方法
update(conn,sql, bookId);
}
@Override
public Book getBookById(Connection conn,String bookId) {
Book book = null;
String sql = "select id,title,author,price,sales,stock,img_path imgPath from books where id = ?";
// 调用BaseDao中获取一个对象的方法
book = getBean(conn,sql, bookId);
return book;
}
@Override
public void updateBook(Connection conn,Book book) {
// 调用BaseDao中通用的增删改的方法
String sql = "update books set title = ? , author = ? , price = ? , sales = ? , stock = ? where id = ?";
update(conn,sql, book.getTitle(), book.getAuthor(), book.getPrice(), book.getSales(), book.getStock(), book.getId());
}
}

若有收获,就点个赞吧
0 人点赞
