- 如何在Hive中开发自定义SQL函数实现单词首字母大写转换功能?
- 如何开发开发只产生一次shuffle且无子查询的SQL语句?
- 使用Hive SQL统计一份订单销售数据,计算出月环比
- 针对一个用到了union all和group by的SQL,在数据量很大的情况下,就会很慢,如何优化此SQL?
- 在一份海量数据中,如何使用HiveSQL发现倾斜的Key?
- 摘取自某同学工作中的实际需求:使用Hive加载指定复杂嵌套格式的数据
- 生产环境中为什么建议使用Hive外部表?
- Hive分区表如何开启自动加载分区?
- Hive中支持多种数据存储格式,默认是TextFile,还可以SequenceFile、RCFile、ORCFile等,这4种数据存储格式有什么优缺点?">Hive中支持多种数据存储格式,默认是TextFile,还可以SequenceFile、RCFile、ORCFile等,这4种数据存储格式有什么优缺点?
- 说下为什么要使用Hive?Hive的优缺点?Hive的作用是什么?
- 说下Hive是什么?跟数据库区别?
- Hive架构
- Hive内部表和外部表的区别?
- 为什么内部表的删除,就会将数据全部删除,而外部表只删除表结构?为什么用外部表更好?
- Hive建表语句?创建表时使用什么分隔符?
- Hive删除语句外部表删除的是什么?
- Hive数据倾斜以及解决方案
- Hive如果不用参数调优,在map和reduce端应该做什么
- Hive的用户自定义函数实现步骤与流程
- Hive的三种自定义函数是什么?实现步骤与流程?它们之间的区别?作用是什么?
- Hive的cluster by、sort bydistribute by、orderby区别?
- Hive分区和分桶的区别
- Hive的执行流程
- Hive SQL转化为MR的过程?
- Hive SQL优化处理
- Hive的存储引擎和计算引擎
- Hive的文件存储格式都有哪些
- Hive中如何调整Mapper和Reducer的数目
- 介绍下知道的Hive窗口函数,举一些例子
- Hive的count的用法
- Hive的union和unionall的区别
- Hive的join操作原理,leftjoin、right join、inner join、outer join的异同?
- Hive如何优化join操作
- Hive的mapjoin
- Hive语句的运行机制,例如包含where、having、group by、orderby,整个的执行过程?
- Hive使用的时候会将数据同步到HDFS,小文件问题怎么解决的?
- Hive Shuffle的具体过程
- Hive有哪些保存元数据的方式,都有什么特点?
- Hive SOL实现查询用户连续登陆,讲讲思路
- Hive的开窗函数有哪些
- Hive存储数据吗
- Hive的SOL转换为MapReduce的过程?
- Hive的函数:UDF、UDAF、UDTF的区别?
- UDF是怎么在Hive里执行的
- Hive优化
- row_number,rank,dense_rank的区别
- Hive count(distinct)有几个reduce,海量数据会有什么问题
- HQL:行转列、列转行
- 一条HQL从代码到执行的过程
- 了解Hive SQL吗?讲讲分析函数?
- 分析函数中加Order By和不加Order By的区别?
- Hive优化方法
- Hive里metastore是干嘛的
- HiveServer2是什么?
- Hive表字段换类型怎么办
- parquet文件优势
如何在Hive中开发自定义SQL函数实现单词首字母大写转换功能?
如何开发开发只产生一次shuffle且无子查询的SQL语句?
使用Hive SQL统计一份订单销售数据,计算出月环比
针对一个用到了union all和group by的SQL,在数据量很大的情况下,就会很慢,如何优化此SQL?
在一份海量数据中,如何使用HiveSQL发现倾斜的Key?
摘取自某同学工作中的实际需求:使用Hive加载指定复杂嵌套格式的数据
生产环境中为什么建议使用Hive外部表?
使用外部表的话,通常配合分区表一起使用,并且结合视图进行查找之类,还有一个好处就是误删除表的话,不会影响源文件的内容,因为外部表删除之后只会在hive元数据中删除关于这个表的信息,而不会删除HDFS上的文件,这样如果这个文件有其他用途的话,是不会影响到它的使用的
Hive分区表如何开启自动加载分区?
方式一:设置动态分区,这样对于分区那个列,不同的数据就会自动划分不同的分区 set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; 方式二:使用shell脚本,去导入数据到分区
#!/bin/bash#⾃动加载前⼀天的离线数据#获得前⼀天的⽇期yesterday=`date -d "-1 day" +%Y%m%d`#定义变量,给定数据⽂件的路径access_log_dir=/opt/datas/test_hive_access_logs/${yesterday}#给出 hive 的安装⽬录HIVE_HOME=/opt/moudles/apache-hive-0.13.1-bin#统计⽂件夹下⽂件的个数。其实是想判断⼀下⽂件夹是不是为空。count=`ls ${access_log_dir} | wc -l`#⽂件夹⽬录存在,并且⽬录不为空,执⾏逻辑,加载数据。if [ -d ${access_log_dir} -a ${count} -gt "0" ]; thenecho "${count} files exists."for file in `ls ${access_log_dir}`doday=${file:0:8}hour=${file:8:2}echo "${day} : ${hour}"# hive 表是⼀个⼆级分区表,⼀级分区是⽇期,⼆级分区是⼩时。${HIVE_HOME}/bin/hive -e "load data local inpath '${access_log_dir}/${file}' into table load_to_hive.load_to_hive_testpartition(date='${day}',hour='${hour}')"doneelse#⽬录不存在,或者⽬录是空的,就不执⾏加载动作了。echo "directory : ${access_log_dir} does not exists."echo "${count} files exists."fi有了这个脚本之后,只要把它挂在 crontab 下⾯定时执⾏就可以了。这只是⼀个简单⽰例,实际应⽤的场景可能会稍微复杂⼀些。
Hive中支持多种数据存储格式,默认是TextFile,还可以SequenceFile、RCFile、ORCFile等,这4种数据存储格式有什么优缺点?
TextFile和SequenceFile是行存储的,ORCFile和RCFile是列存储的
说下为什么要使用Hive?Hive的优缺点?Hive的作用是什么?
当下已经进入了大数据时代,面对日益剧增的大数据,不仅仅产生速度快,数据类型多样,数据量大,同时数据的价值也非常巨大,而传统的关系型数据库在面对这些特征时,难以有效的应对,而Hive在这一方面,有着独特优势,从而使用Hive。 Hive优点:基于HDFS实现存储,基于MapReduce实现计算,能够存储大量数据,支持分区操作,提供类SQL语言实现业务操作。 Hive缺点:查询效率低,计算结果慢,简单索引,不支持事务,不建议删改数据。 Hive作用:用于OLAP联机分析处理,能够将大量数据放入Hive,帮助企业进行数据的存储,同时使用HQL进行数据分析,为企业高层人员的决策提供一定的数据支持
说下Hive是什么?跟数据库区别?
Hive是一种支持海量数据存储的数据库,主要应用于海量数据的分析处理,它是Hadoop生态体系中的一个产品。
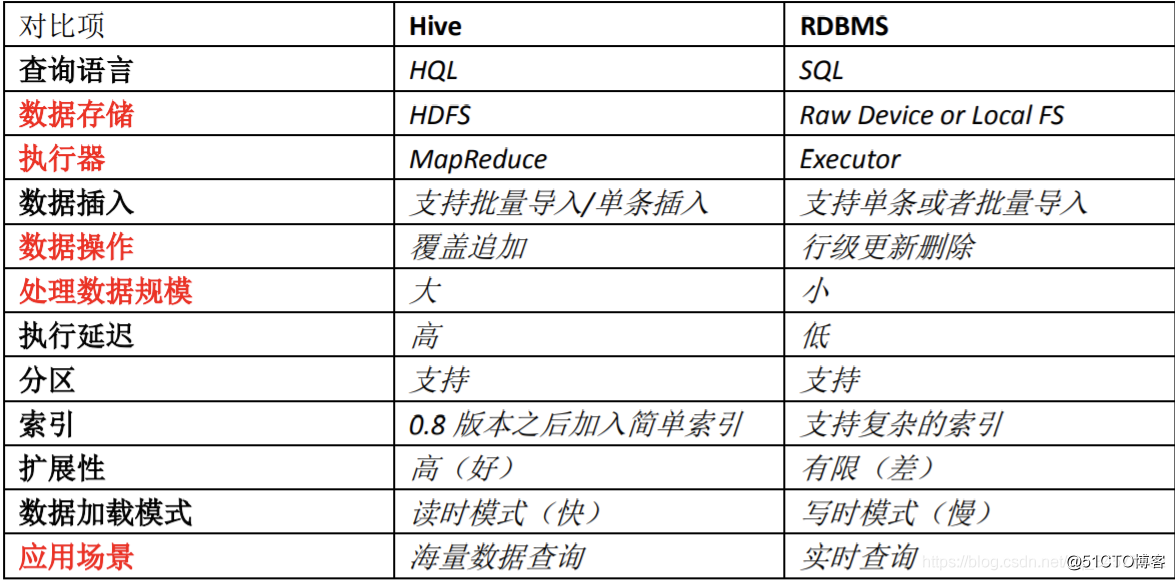
Hive架构
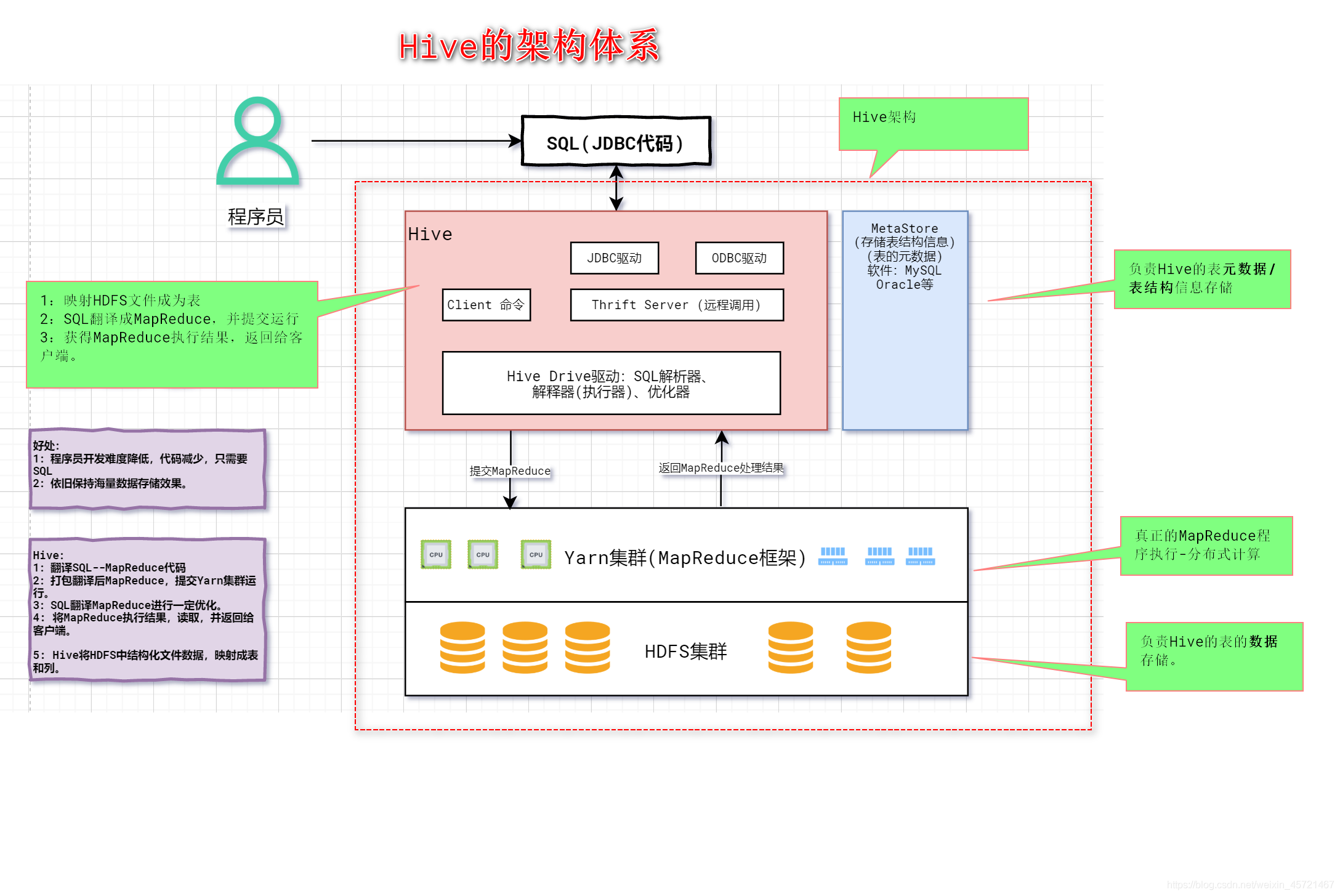
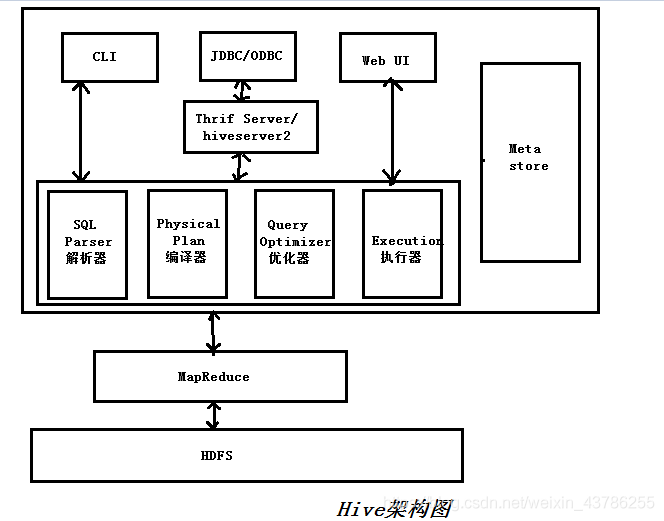
Hive内部表和外部表的区别?
Hive内部表不仅仅会将数据表的元数据信息存储到对应的元数据信息库,同时对数据的操作将会直接作用于源数据。 Hive外部表类似关系型数据中的视图,删除外部表并不会删除源数据,仅仅删除这个外部表的元数据信息,从而不会影响到源数据的在其它应用中的使用。 内部表由Hive自身管理,外部表数据由HDFS管理; 内部表的存储位置是hive.metastore.warehouse.dir(默认是/user/hive/warehouse),外部表数据的存储位置由自己制定(如果没有LOCATION,Hive将在HDFS上的/user/hive/warehouse文件夹下以外部表的表名创建一个文件夹,并将属于这个表的信息存放在这里); 删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除; 对内部表的修改会将修改同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name)
为什么内部表的删除,就会将数据全部删除,而外部表只删除表结构?为什么用外部表更好?
创建表时:创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径, 不对数据的位置做任何改变。 删除表时:在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
Hive建表语句?创建表时使用什么分隔符?
Hive删除语句外部表删除的是什么?
Hive中删除外部表删除的其实是外部表在元数据库中的信息,不会删除元数据
Hive数据倾斜以及解决方案
Hive如果不用参数调优,在map和reduce端应该做什么
Hive的用户自定义函数实现步骤与流程
Hive的三种自定义函数是什么?实现步骤与流程?它们之间的区别?作用是什么?
Hive的cluster by、sort bydistribute by、orderby区别?
Hive分区和分桶的区别
Hive的执行流程
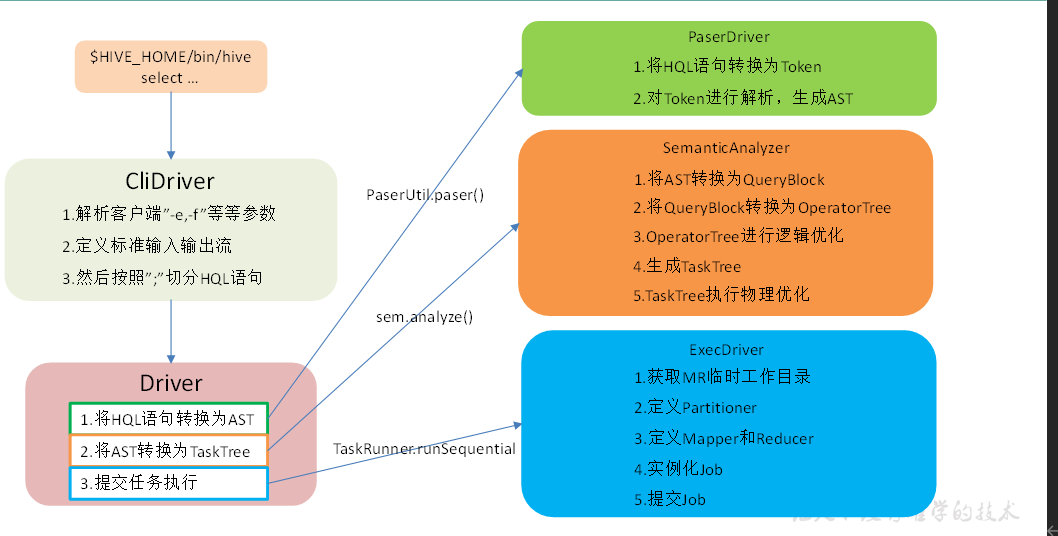

Hive SQL转化为MR的过程?
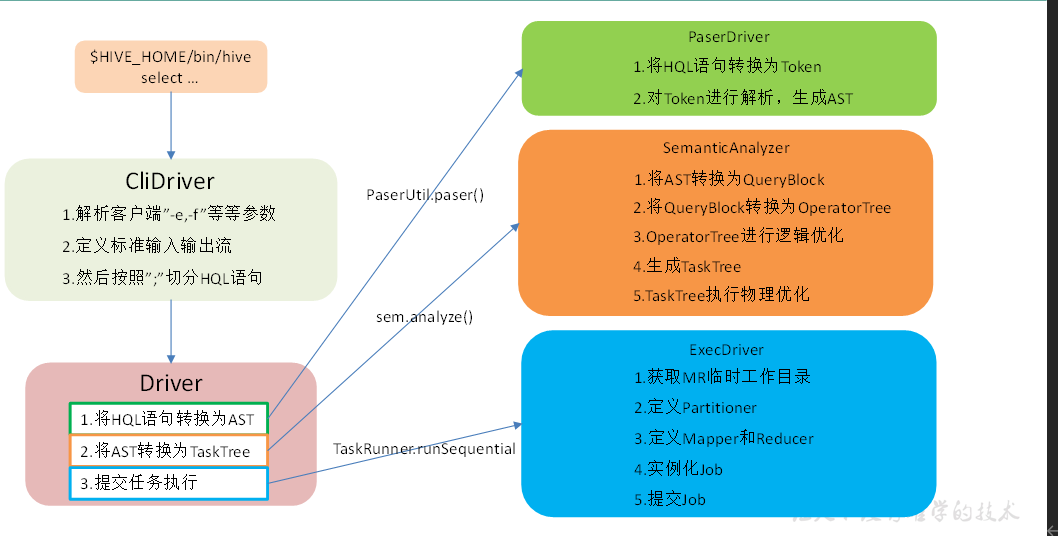

Hive SQL优化处理
Hive的存储引擎和计算引擎
Hive的文件存储格式都有哪些
Hive中如何调整Mapper和Reducer的数目
介绍下知道的Hive窗口函数,举一些例子
Hive的count的用法
Hive的union和unionall的区别
Hive的join操作原理,leftjoin、right join、inner join、outer join的异同?
Hive如何优化join操作
Hive的mapjoin
Hive语句的运行机制,例如包含where、having、group by、orderby,整个的执行过程?
Hive使用的时候会将数据同步到HDFS,小文件问题怎么解决的?
Hive Shuffle的具体过程
Hive有哪些保存元数据的方式,都有什么特点?
Hive SOL实现查询用户连续登陆,讲讲思路
Hive的开窗函数有哪些
Hive存储数据吗
Hive不存储数据,Hive中的数据是依靠HDFS存储的,Hive提供一种类似SQL的语句对数据进行查询等操作
Hive的SOL转换为MapReduce的过程?
Hive的函数:UDF、UDAF、UDTF的区别?
UDF是怎么在Hive里执行的
Hive优化
row_number,rank,dense_rank的区别
Hive count(distinct)有几个reduce,海量数据会有什么问题
HQL:行转列、列转行
一条HQL从代码到执行的过程
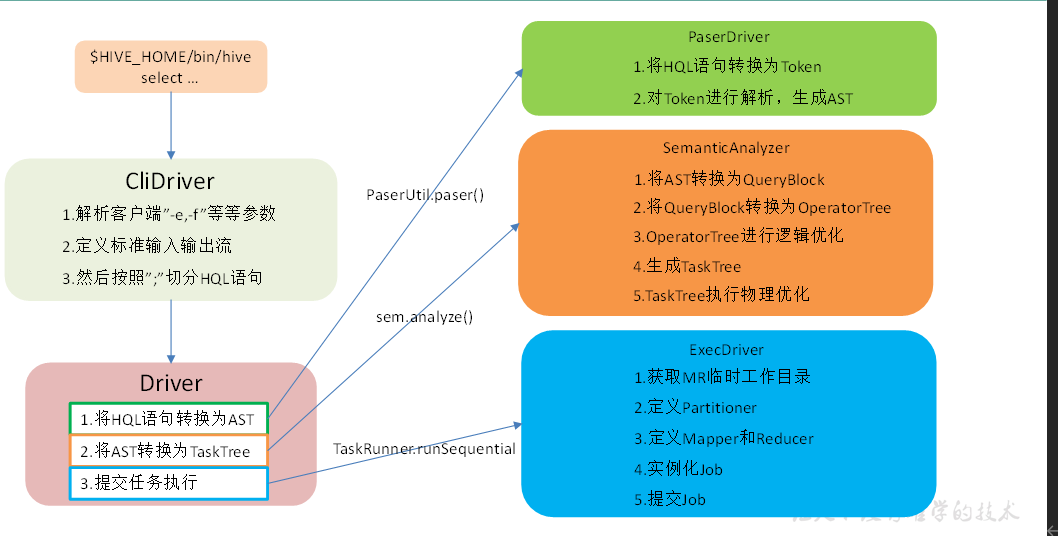

了解Hive SQL吗?讲讲分析函数?
分析函数中加Order By和不加Order By的区别?
Hive优化方法
Hive里metastore是干嘛的
Hive中的元数据主要存储表信息
HiveServer2是什么?
Hive表字段换类型怎么办
parquet文件优势
通常我们使用关系数据库存储结构化数据,而关系数据库中使用数据模型都是扁平式的,遇到诸如List、Map和自定义Struct的时候就需要用户在应用层解析。但是在大数据环境下,通常数据的来源是服务端的埋点数据,很可能需要把程序中的某些对象内容作为输出的一部分,而每一个对象都可能是嵌套的,所以如果能够原生的支持这种数据,这样在查询的时候就不需要额外的解析便能获得想要的结果。 Parquet的灵感来自于2010年Google发表的Dremel论文,文中介绍了一种支持嵌套结构的存储格式,并且使用了列式存储的方式提升查询性能。Parquet仅仅是一种存储格式,它是语言、平台无关的,并且不需要和任何一种数据处理框架绑定。这也是parquet相较于orc的仅有优势:支持嵌套结构。Parquet 没有太多其他可圈可点的地方,比如他不支持update操作(数据写成后不可修改),不支持ACID等.

若有收获,就点个赞吧
0 人点赞
