- sortByKey如何实现全局排序
- 有一台服务器:32G内存,如何在内存中对1T数据进行排序
- 谈一下你对Spark的理解,Spark和Hadoop之间是什么关系?
- 按照你的理解,在工作中最常用的是Spark的哪一种任务提交方式?说出你的理由?
- 你们目前工作中开发Spark代码是使用scala语言还是java语言?你倾向于使用哪一种语言?
- 在Spark程序中将处理的结果数据按照一定的规则,输出到多个不同的目录中,实现多路输出
- 如何使用Spark程序实现对WordCount的结果排序输出?
- 如何使用Spark实现自定义二次排序Key的开发?
- Spark中join和cogroup的区别?
- Spark如何读取多个不同目录下的数据(多路输入)?
- 介绍一下Spark的远程进程通信机制?
- 谈一下你对宽依赖和窄依赖的理解,以及Stage的个数和宽依赖之间的关系?
- 谈一下你对Spark性能优化的总结,到底哪种优化策略的效果最明显?
- 想要在Spark中直接操作MySQL应该如何实现?
- 如何在SparkSQL中使用自定义函数(UDF)?
- 算子优化在优化方案中常见吗?都适合在哪些场景中使用?
- Spark中的repartition和coalesce有什么区别?
- 谈一下你对SparkSQL和Hive的理解?
- 分析一下SparkSQL的执行流程?
- Spark的任务执行流程
- Spark的运行流程
- Spark的作业运行流程是怎么样的?
- Spark的特点
- Spark源码中的任务调度
- Spark作业调度
- Spark的架构
- Spark的使用场景
- Spark on standalone模型、YARN架构模型(画架构图)
- Spark的yarn-cluster涉及的参数有哪些?
- Spark提交job的流程
- Spark的阶段划分
- Spark处理数据的具体流程说下
- Sparkjoin的分类
- Spark map join的实现原理
- 介绍下Spark Shuffle及其优缺点
- 什么情况下会产生Spark Shuffle?
- 为什么要Spark Shuffle?
- Spark为什么快?
- Spark为什么适合迭代处理?
- Spark数据倾斜问题,如何定位,解决方案
- Spark的stage如何划分?在源码中是怎么判断属于Shuffle Map Stage或Result Stage的?
- Spark join在什么情况下会变成窄依赖?
- Spark的内存模型?
- Spark分哪几个部分(模块)?分别有什么作用(做什么,自己用过哪些,做过什么)?
- RDD的宽依赖和窄依赖,举例一些算子
- Spark SQL的GroupBy会造成窄依赖吗?
- GroupBy是行动算子吗
- Spark的宽依赖和窄依赖,为什么要这么划分?
- 说下Spark中的Transform和Action,为什么Spark要把操作分为Transform和Action?常用的列举一些,说下算子原理
- Spark的哪些算子会有shuffle过程?
- Spark有了RDD,为什么还要有Dataform和DataSet?
- Spark的RDD、DataFrame、DataSet、DataStream区别?
- Spark的Job、Stage、Task分别介绍下,如何划分?
- Application、job、Stage、task之间的关系
- Stage内部逻辑
- 为什么要根据宽依赖划分Stage?为
- 什么要划分Stage
- Stage的数量等于什么
- 对RDD、DAG和Task的理解
- DAG为什么适合Spark?
- 介绍下Spark的DAG以及它的生成过程
- DAGScheduler如何划分?干了什么活?
- Spark容错机制?
- RDD的容错
- Executor内存分配?
- Spark的batchsize,怎么解决小文件合并问题?
- Spark参数(性能)调优
- 介绍一下Spark怎么基于内存计算的
- 说下什么是RDD(对RDD的理解)?RDD有哪些特点?说下知道的RDD算子
- RDD底层原理
- RDD属性
- RDD的缓存级别?
- Spark广播变量的实现和原理?
- reduceByKey和groupByKey的区别和作用?
- reduceByKey和reduce的区别?
- 使用reduceByKey出现数据倾斜怎么办?
- Spark SQL的执行原理?
- Spark SQL的优化?
- 说下Spark checkpoint
- Spark SQL与DataFrame的使用?
- Sparksql自定义函数?怎么创建DataFrame?
- HashPartitioner和RangePartitioner的实现
- Spark的水塘抽样
- DAGScheduler、TaskScheduler、SchedulerBackend实现原理
- 介绍下Sparkclient提交application后,接下来的流程?
- Spark的几种部署方式
- 在Yarn-client情况下,Driver此时在哪
- Spark的cluster模式有什么好处
- Driver怎么管理executor
- Spark的map和flatmap的区别?
- Spark的cache和persist的区别?它们是transformaiton算子还是action算子?
- Saprk Streaming从Kafka中读取数据两种方式?
- Spark Streaming的工作原理?
- Spark Streaming的DStream和DStreamGraph的区别?
- Spark输出文件的个数,如何合并小文件?
- Spark的driver是怎么驱动作业流程的?
- Spark SQL的劣势?
- 介绍下Spark Streaming和Structed Streaming
- Spark为什么比Hadoop速度快?
- DAG划分Spark源码实现?
- Spark Streaming的双流join的过程,怎么做的?
- Spark的Block管理
- Spark怎么保证数据不丢失
- Spark SQL如何使用UDF?
- Spark温度二次排序
- Spark实现wordcount
- Spark Streaming怎么实现数据持久化保存?
- Spark SQL读取文件,内存不够使用,如何处理?
- Spark的lazy体现在哪里?
- Spark中的并行度等于什么
- Spark运行时并行度的设署
- Spark SQL的数据倾斜
- Spark的exactly-once
- Spark的RDD和partition的联系
- park 3.0特性
- Spark计算的灵活性体现在哪里
sortByKey如何实现全局排序
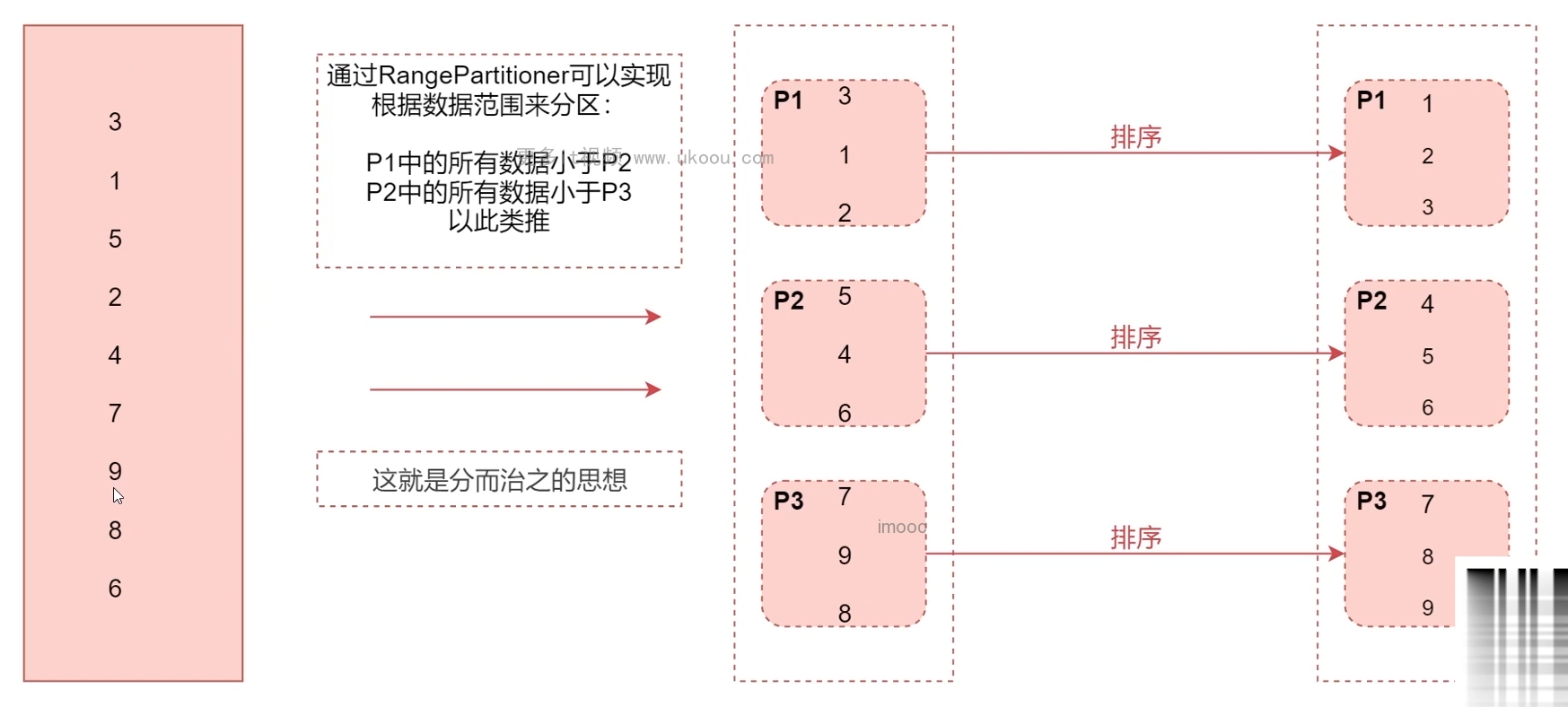
有一台服务器:32G内存,如何在内存中对1T数据进行排序
首先对1T数据进行分区,每一个区间的数据都是<某个值的,区间内无序,区间外有序,然后一个区间32G,假设32G内存都是可用的,将这些区间一个一个放进去进行排序,最后把文件顺序进行排序,这1T数据就是有序的了,这就是分而治之的思想,归并排序
谈一下你对Spark的理解,Spark和Hadoop之间是什么关系?
Spark是一种基于内存的计算引擎,它可以运行在Hadoop集群上。其中,Spark包括多种操作,有SparkSQL,SparkStreaming,SparkML,GraphX等。而我们常说Hadoop是一个生态体系。里面包含了很多大数据相关组件,Spark就包含在里面。
按照你的理解,在工作中最常用的是Spark的哪一种任务提交方式?说出你的理由?
你们目前工作中开发Spark代码是使用scala语言还是java语言?你倾向于使用哪一种语言?
在Spark程序中将处理的结果数据按照一定的规则,输出到多个不同的目录中,实现多路输出
如何使用Spark程序实现对WordCount的结果排序输出?
如何使用Spark实现自定义二次排序Key的开发?
Spark中join和cogroup的区别?
Spark如何读取多个不同目录下的数据(多路输入)?
介绍一下Spark的远程进程通信机制?
谈一下你对宽依赖和窄依赖的理解,以及Stage的个数和宽依赖之间的关系?
谈一下你对Spark性能优化的总结,到底哪种优化策略的效果最明显?
想要在Spark中直接操作MySQL应该如何实现?
如何在SparkSQL中使用自定义函数(UDF)?
算子优化在优化方案中常见吗?都适合在哪些场景中使用?
Spark中的repartition和coalesce有什么区别?
谈一下你对SparkSQL和Hive的理解?
分析一下SparkSQL的执行流程?
Spark的任务执行流程
Spark的运行流程
Spark的作业运行流程是怎么样的?
Spark的特点
Spark源码中的任务调度
Spark作业调度
Spark的架构
Spark的使用场景
Spark on standalone模型、YARN架构模型(画架构图)
Spark的yarn-cluster涉及的参数有哪些?
Spark提交job的流程
Spark的阶段划分
Spark处理数据的具体流程说下
Sparkjoin的分类
Spark map join的实现原理
介绍下Spark Shuffle及其优缺点
什么情况下会产生Spark Shuffle?
为什么要Spark Shuffle?
Spark为什么快?
Spark为什么适合迭代处理?
Spark数据倾斜问题,如何定位,解决方案
Spark的stage如何划分?在源码中是怎么判断属于Shuffle Map Stage或Result Stage的?
Spark join在什么情况下会变成窄依赖?
Spark的内存模型?
Spark分哪几个部分(模块)?分别有什么作用(做什么,自己用过哪些,做过什么)?
RDD的宽依赖和窄依赖,举例一些算子
Spark SQL的GroupBy会造成窄依赖吗?
GroupBy是行动算子吗
Spark的宽依赖和窄依赖,为什么要这么划分?
说下Spark中的Transform和Action,为什么Spark要把操作分为Transform和Action?常用的列举一些,说下算子原理
Spark的哪些算子会有shuffle过程?
Spark有了RDD,为什么还要有Dataform和DataSet?
Spark的RDD、DataFrame、DataSet、DataStream区别?
Spark的Job、Stage、Task分别介绍下,如何划分?
Application、job、Stage、task之间的关系
Stage内部逻辑
为什么要根据宽依赖划分Stage?为
什么要划分Stage
Stage的数量等于什么
对RDD、DAG和Task的理解
DAG为什么适合Spark?
介绍下Spark的DAG以及它的生成过程
DAGScheduler如何划分?干了什么活?
Spark容错机制?
RDD的容错
Executor内存分配?
Spark的batchsize,怎么解决小文件合并问题?
Spark参数(性能)调优
介绍一下Spark怎么基于内存计算的
说下什么是RDD(对RDD的理解)?RDD有哪些特点?说下知道的RDD算子
RDD底层原理
RDD属性
RDD的缓存级别?
Spark广播变量的实现和原理?
reduceByKey和groupByKey的区别和作用?
reduceByKey和reduce的区别?
使用reduceByKey出现数据倾斜怎么办?
Spark SQL的执行原理?
Spark SQL的优化?
说下Spark checkpoint
Spark SQL与DataFrame的使用?
Sparksql自定义函数?怎么创建DataFrame?
HashPartitioner和RangePartitioner的实现
Spark的水塘抽样
DAGScheduler、TaskScheduler、SchedulerBackend实现原理
介绍下Sparkclient提交application后,接下来的流程?
Spark的几种部署方式
在Yarn-client情况下,Driver此时在哪
Spark的cluster模式有什么好处
Driver怎么管理executor
Spark的map和flatmap的区别?
Spark的cache和persist的区别?它们是transformaiton算子还是action算子?
Saprk Streaming从Kafka中读取数据两种方式?
Spark Streaming的工作原理?
Spark Streaming的DStream和DStreamGraph的区别?
Spark输出文件的个数,如何合并小文件?
Spark的driver是怎么驱动作业流程的?
Spark SQL的劣势?
介绍下Spark Streaming和Structed Streaming
Spark为什么比Hadoop速度快?
DAG划分Spark源码实现?
Spark Streaming的双流join的过程,怎么做的?
Spark的Block管理
Spark怎么保证数据不丢失
Spark SQL如何使用UDF?
Spark温度二次排序
Spark实现wordcount
Spark Streaming怎么实现数据持久化保存?
Spark SQL读取文件,内存不够使用,如何处理?
Spark的lazy体现在哪里?
Spark中的并行度等于什么
Spark运行时并行度的设署
Spark SQL的数据倾斜
Spark的exactly-once
Spark的RDD和partition的联系
park 3.0特性
Spark计算的灵活性体现在哪里

若有收获,就点个赞吧
0 人点赞
