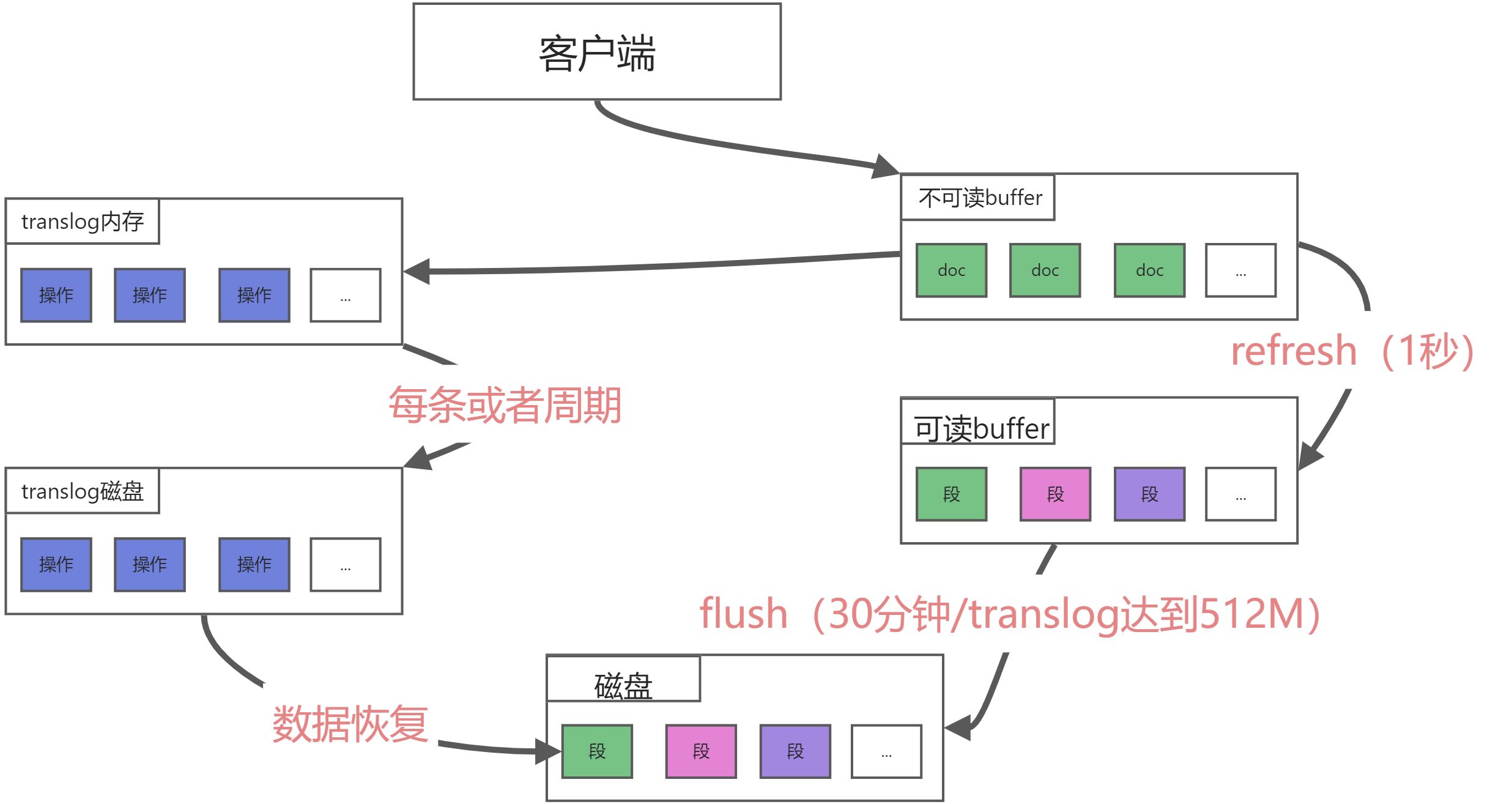
- Elasticsearch数据物理提交流程
- Elasticsearch的倒排索引是什么?
- Elasticsearch索引数据多了怎么办,如何调优,部署?
- Elasticsearch是如何实现master选举的?
- 详细描述一下Elasticsearch索引文档的过程?
- 详细描述一下Elasticsearch搜索的过程?
- Elasticsearch在部署时,对Linux的设置有哪些优化方法?
- lucence内部结构是什么?
- Elasticsearch中的节点(比如共20个),其中的10个选了一个master,另外10个选了另一个master,怎么办?
- 客户端在和集群连接时,如何选择特定的节点执行请求的?
- 详细描述一下Elasticsearch更新和删除文档的过程。
- 在Elasticsearch中,是怎么根据一个词找到对应的倒排索引的?
- 对于GC方面,在使用Elasticsearch时要注意什么?
- Elasticsearch对于大数据量(上亿量级)的聚合如何实现?
- 在并发情况下,Elasticsearch如果保证读写一致?
- 如何监控Elasticsearch集群状态?
- 是否了解字典树?
- 拼写纠错是如何实现的?">拼写纠错是如何实现的?
- elasticsearch 冷热分离">elasticsearch 冷热分离
- Elasticsearch 中的集群、节点、索引、文档、类型是什么?
- 什么是近实时搜索?">什么是近实时搜索?
- 如何理解 Elasticsearch 的近实时的性质,并改善它的不足?
- Elasticsearch 集群脑裂问题?有哪些解决方法?
- Elasticsearch和HBase对比分析">Elasticsearch和HBase对比分析
Elasticsearch数据物理提交流程
Elasticsearch的倒排索引是什么?
倒排索引主要由单词词典(Term Dictionary)和倒排列表(Posting List)及倒排文件(Inverted File)组成。
单词词典(Term Dictionary):搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。 倒排列表(Posting List):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息及频率(作关联性算分),每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档中包含某个单词。 倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件
Elasticsearch索引数据多了怎么办,如何调优,部署?
- 动态索引层面:基于模板+时间+rollover api滚动创建索引,举例:设计阶段定义:blog索引的模板格式为:blogindex时间戳的形式,每天递增数据。这样做的好处:不至于数据量激增导致单个索引数据量非常大,接近于上线2的32次幂-1,索引存储达到了TB+甚至更大。一旦单个索引很大,存储等各种风险也随之而来,所以要提前考虑+及早避免
- 存储层面:冷热数据分离存储,热数据(比如最近3天或者一周的数据),其余为冷数据。对于冷数据不会再写入新数据,可以考虑定期force_merge加shrink压缩操作,节省存储空间和检索效率
- 部署层面:一旦之前没有规划,这里就属于应急策略。结合ES自身的支持动态扩展的特点,动态新增机器的方式可以缓解集群压力,注意:如果之前主节点等规划合理,不需要重启集群也能完成动态新增
Elasticsearch是如何实现master选举的?
- Elasticsearch的选主是ZenDiscovery模块负责的,主要包含Ping(节点之间通过这个RPC来发现彼此)和Unicast(单播模块包含一个主机列表以控制哪些节点需要ping通)这两部分
- 对所有可以成为master的节点(node.master: true)根据nodeId字典排序,每次选举每个节点都把自己所知道的节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点
- 如果对某个节点的投票数达到一定的值(可以称为master节点数n/2+1)并且该节点自己也选举自己,那么这个节点就是master,否则重新选举一直到满足上述条件
- master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data节点可以关闭http功能
详细描述一下Elasticsearch索引文档的过程?
1、读操作可以从主分片或者其他任意副本分片检索文档 2、客户端向Node1发送读请求,Node1为协调节点 3、节点使用文档的_id来确定文档属于哪个分片。分片的主副分片存在与哪几个节点上,协调节点在每次请求的时候都会通过轮询的方式将请求打到不同的节点上达到负载均衡 4、收到请求的节点将文档返回给协调节点,协调节点返回给客户端
详细描述一下Elasticsearch搜索的过程?
1、搜索过程被执行成一个两阶段过程,称之为Query Then Fetch 2、在初始查询阶段时,查询会广播到索引中每一个分片(主分片或者副本分片)。每个分片在本地执行搜索并构建一个匹配文档的大小为from+size的优先队列。PS:在搜索的时候是会查询Filesystem Cache的,但是有部分数据还在Memory Buffer,所以搜索是近实时的。 3、每个分片返回各自优先队列中,所有文档的ID和排序值给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表 4、接下来就是取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片提交多个GET请求。每个分片加载并丰富文档,接着返回文档给协调节点。一旦所有的文档都被取回来,协调节点放回结果给客户端
自己理解: 1、Query Then Fetch 2、首先客户端发送请求,类似国家主席告诉国家体育队,通知安排一些运动员参加奥运会 3、国家队这时候向所有的省级队发送通知 4、省级队自己进行选拔,把符合条件的前几名的名单和成绩先发给国家队 5、国家队再次对统计上来的结果进行选拔,选出最优的几个,告诉省级队,此时省级队把人送过来,最后国家队把这些人送去参加奥运
Elasticsearch在部署时,对Linux的设置有哪些优化方法?
修改系统文件:/etc/security/limits.conf,允许Elasticsearch打开的最大文件数需要修改成65536
#在文件最后添加如下内容:* soft nofile 65536* hard nofile 131072* soft nproc 2048* hard nproc 65536
修改系统文件:/etc/sysctl.conf,修改一个进程可以拥有的虚拟内存区域的数量
#在文件最后添加如下内容
vm.max_map_count=262144
修改系统文件:/etc/security/limits.d/20-nproc.conf,修改允许最大线程数为4096
#修改如下内容
* soft nproc 4096
lucence内部结构是什么?
- Index:索引,由很多的Document组成
- Document:由很多的Field组成,是Index和Search的最小单位
- Field:由很多的Term组成,包括Field Name和Field Value
- Term:由很多的字节组成。一般将Text类型的Field Value分词之后的每个最小单元叫做Term
Elasticsearch中的节点(比如共20个),其中的10个选了一个master,另外10个选了另一个master,怎么办?
- 当集群master候选数量不小于3个时,可以通过设置最小投票通过数量(discovery.zen.minimum_master_nodes)超过所有候选节点一半以上来解决脑裂问题
- 当候选数量为2个时,只能修改为唯一的一个master候选,其他作为data节点,避免脑裂问题
客户端在和集群连接时,如何选择特定的节点执行请求的?
TransportClient 利用 transport 模块远程连接一个 elasticsearch 集群。它并不加入到集群中,只是简单的获得一个或者多个初始化的 transport 地址,并以 轮询 的方式与这些地址进行通信。
详细描述一下Elasticsearch更新和删除文档的过程。
1、删除和更新也都是写操作,但是Elasticsearch中的文档是不可变的,因此不能被删除或者改动以展示其更变 2、磁盘上的每个段都有一个相应的.del文件。当删除请求发送后,文档并没有真的被删除,而是在.del文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在.del文件中被标记为删除的文档将不会被写入新段 3、在新的文档被创建时,Elasticsearch会为该文档指定一个版本号,当执行更新时,旧版本的文档在.del文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
在Elasticsearch中,是怎么根据一个词找到对应的倒排索引的?
- Lucene的索引过程,就是按照全文检索的基本过程,将倒排表写成此文件格式的过程。
- Lucene的搜索过程,就是按照此文件格式将索引进去的信息读出来,然后计算每篇文档 打分(score)的过程。
个人感觉: 通过字典树,找到该词对应的文档,然后根据文档去找索引
对于GC方面,在使用Elasticsearch时要注意什么?
- 倒排词典的索引需要常驻内存,无法 GC,需要监控 data node 上 segmentmemory 增长趋势。
- 各类缓存,field cache, filter cache, indexing cache, bulk queue 等等,要设置合理的大小,并且要应该根据最坏的情况来看 heap 是否够用,也就是各类缓存全部占满的时候,还有 heap 空间可以分配给其他任务吗?避免采用 clear cache等“自欺欺人”的方式来释放内存。
- 避免返回大量结果集的搜索与聚合。确实需要大量拉取数据的场景,可以采用scan & scroll api 来实现。
- cluster stats 驻留内存并无法水平扩展,超大规模集群可以考虑分拆成多个集群通过 tribe node 连接。
- 想知道 heap 够不够,必须结合实际应用场景,并对集群的 heap 使用情况做持续的监控。
- 根据监控数据理解内存需求,合理配置各类circuit breaker,将内存溢出风险降低到最低
Elasticsearch对于大数据量(上亿量级)的聚合如何实现?
Elasticsearch 提供的首个近似聚合是 cardinality 度量。它提供一个字段的基数,即该字段的 distinct 或者 unique 值的数目。它是基于 HLL 算法的。HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。其特点是:可配置的精度,用来控制内存的使用(更精确 = 更多内存);小的数据集精度是非常高的;我们可以通过配置参数,来设置去重需要的固定内存使用量。无论数千还是数十亿的唯一值,内存使用量只与你配置的精确度相关。
在并发情况下,Elasticsearch如果保证读写一致?
悲观并发控制:这种方法被关系型数据库广泛应用,它假定有变更冲突可能发送,因此阻塞访问资源以防止冲突。一个典型的例子就是读取一行数据之前先将其锁住,确保只有获取锁的线程才能够对这行数据进行修改 乐观并发控制:Elasticsearch中使用的这种方法假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何解决冲突。例如:可以重试更新、使用新的数据、或者将相关情况报告给用户
- 可以通过版本号使用乐观锁并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
- 对于写操作:一致性级别支持 quorum/one/all,默认为 quorum。
- quorum:即只有当大多数(一半以上)分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
- one:即只要主分片数据保存成功,那么客户端就可以进行查询操作了。
- all:是最高的一致性级别,要求所有分片的数据要全部保存成功,才可以继续进行。
- 对于读操作:可以设置 replication 为 sync(默认为同步),这使得操作在主分片和副本分片都完成后才会返回;设置 replication 为 async(异步)时,也可以通过设置搜索请求参数_preference 为 primary 来查询主分片,确保文档是最新版本。
如何监控Elasticsearch集群状态?
Marvel让你可以很简单的通过Kibana监控Elasticsearch。你可以实时查看你的集群健康状态和性能,也可以分析过去的集群、索引和节点指标。
是否了解字典树?
字典树(Trie)又称单词查找树,Trie树。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较。 基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串
- 每个节点的所有子节点包含的字符都不相同
拼写纠错是如何实现的?
BK树(Burkhard-Keller树)是一种基于树的数据结构,被设计于快速查找近似字符串匹配,比方说拼写检查器,或模糊查找,当搜索“aeek”时能返回“seek”和“peek”
elasticsearch 冷热分离
冷热分离是目前ES非常火的一个架构,它充分的利用的集群机器的优劣来实现资源的调度分配。ES集群的索引写入及查询速度主要依赖于磁盘的IO速度,冷热数据分离的关键点为使用固态磁盘存储数据。若全部使用固态,成本过高,且存放冷数据较为浪费,因而使用普通机械磁盘与固态磁盘混搭,可做到资源充分利用,性能大幅提升的目标。因此我们可以将实时数据(5天内)存储到热节点中,历史数据(5天前)的存储到冷节点中,并且可以利用ES自身的特性,根据时间将热节点的数据迁移到冷节点中,这里因为我们是按天建立索引库,因此数据迁移会更加的方便。
Elasticsearch 中的集群、节点、索引、文档、类型是什么?
cluster:整个Elasticsearch默认就是集群状态,整个集群是一份完整、互备的数据 node:集群中的一个节点,一般指一个进程就是一个node shard:分片,即使是一个节点中的数据也会通过hash算法,分成多个片存放,7.x默认是一片,之前版本默认5片 index:相当于table type:一种逻辑分区,7.x版本已废除,用固定的_doc占位替代 document:类似于RDBMS中的row、面向对象中的object field:相当于字段、属性
什么是近实时搜索?
实时搜索(Real-time Search)很好理解,对于一个数据库系统,执行插入以后立刻就能搜索到刚刚插入到数据。而近实时(Near Real-time),所谓“近”也就是说比实时要慢一点点。 在 Elasticsearch 和磁盘之间是文件系统缓存。在内存索引缓冲区中的文档会被写入到一个新的段中。 但是这里新段会被先写入到文件系统缓存,这一步代价会比较低,稍后再被刷写到磁盘—这一步代价比较高。不过只要文件已经在缓存中,就可以像其它文件一样被打开和读取了。在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 refresh 。 默认情况下每个分片会每秒自动刷新一次,即刷新文件系统缓存。这就是为什么我们说 Elasticsearch 是 近实时搜索:文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。这些行为可能会对新用户造成困惑:他们索引了一个文档然后尝试搜索它,但却没有搜到。这个问题的解决办法是用 refresh API 执行一次手动自动刷新:/users/_refresh。
如何理解 Elasticsearch 的近实时的性质,并改善它的不足?
并不是所有的情况都需要每秒刷新。可能你正在使用 Elasticsearch 索引大量的日志文件,你可能想优化索引速度而不是近实时搜索, 可以通过设置 refresh_interval , 降低每个索引的刷新频率。refresh_interval 可以在既存索引上进行动态更新。 在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来。
# 关闭自动刷新
PUT /users/_settings
{ "refresh_interval": -1 }
# 每一秒刷新
PUT /users/_settings
{ "refresh_interval": "1s" }
Elasticsearch 集群脑裂问题?有哪些解决方法?
脑裂问题(两个master)
- 网络问题:集群间的网络延迟导致一些节点访问不到master,认为master挂掉了从而选举出新的master,并对master上的分片和副本标红,分配新的主分片
- 节点负载:主节点的角色既为master,又为data,访问量较大时可能导致ES停止响应造成大面积延迟,此时其他节点得不到主节点的响应认为主节点挂掉了,会重新选取主节点
- 内存回收:data节点上的ES进程占用的内存较大,引发JVM的大规模内存回收,造成ES进程失去响应
解决方案:
- 减少误判:discovery.zen.ping_timeout节点状态的响应时间(超过这个时间就会重新选举master),默认为3s,可以适当调大,如果master在该响应时间范围内没有做出响应应答,判读该节点已经挂掉了。调大参数,可以减少误判
- 选举触发:discovery.zen.minimum_master_nodes:1该参数是用于控制选举行为发生的最小集群主节点数量。当备选主节点的个数大于等于该参数的值,且备选主节点中有该参数个节点认为主节点挂了,进行选举。官方建议为(n/2)+1,n为主节点个数(即有资格称为主节点的节点个数)
- 角色分离:即master节点与data节点分离,限制角色
- 主节点配置为:node.master: true, node.data: false
- 从节点配置为:node.master: false, node.data: true
Elasticsearch和HBase对比分析

若有收获,就点个赞吧
0 人点赞
