Mapping在ElasticSearch中是一个非常重要的概念。决定了一个index中的field使用什么数据类型存储,使用什么分词器解析,是否有子字段等。
为什么要学习Mapping?
如果没有Mapping,那么所有的text类型属性默认都使用standard分词器。所以如果希望使用IK分词器就必须配置自定义Mapping。
1、Mapping核心数据类型
ElasticSearch中数据类型有很多,在这里只介绍常用的数据类型。
只有text类型才能被分词。其他类型不允许。
文本(字符串):text
整数:byte、short、integer、long
浮点型:float、double
布尔类型:boolean
日期类型:date
数组类型:array {a:[]}
对象类型:object {a:{}}
不分词的字符串(关键字):keyword
2、dynamic Mapping对字段的类型匹配
true or false->boolean
123 -> long
123.123 -> double
2018-10-10 -> date
hello world -> text
[]-> array
{} -> object
在上述的自动mapping字段类型分配的时候,只有text类型的字段需要分词器。默认的分词器是standard分词器。
3、查看索引mapping
可以通过命令查看已有的index的mapping具体信息,语法如下 :
GET 索引名/_mapping
4、custom mapping
可以通过命令,在创建index和type的时候来定制mapping映射,也就是指定字段的类型和字段数据使用的分词器。
手动设置mapping时,只能新增mapping设置,不能对已有的mapping进行修改。
如:有索引A,其中有类型b,增加字段f1的mapping定义。后续可以加字段f2的mapping定义,但是不能修改f1字段的mapping定义。
通常都是手动创建index,并进行各种定义,如:setting,mapping等。
4-1 创建索引时指定mapping
PUT 索引名称{"mappings":{"properties":{"字段名":{"type":类型,["analyzer":字段的分词器,]["fields":{"子字段名称":{"type":类型,"ignore_above":长度限制}}]}}}}#"index" - 是否可以作为搜索索引。可选值:true | false#"analyzer" - 指定分词器。#"type" - 指定字段类型
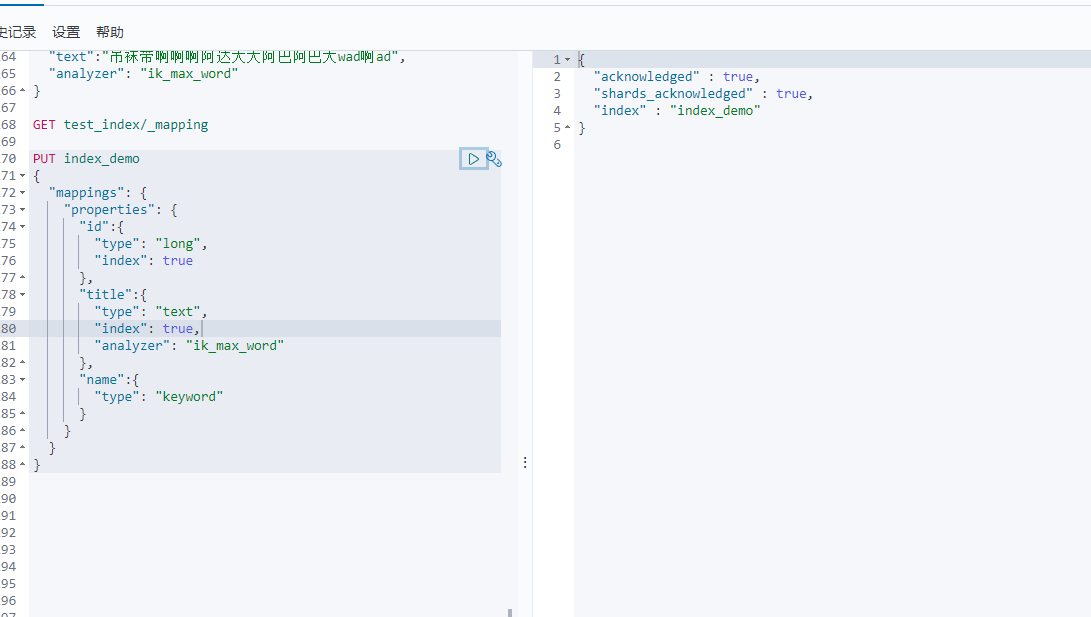
4-2 为已有的索引添加新的字段mapping
PUT 索引名/_mapping{"properties":{"新字段名":{"type":类型,"analyer":字段的分词器,"fields":{"子字段名":{"type":类型,"ignore_above":长度}}}}}

4-3 查看索引的mapping

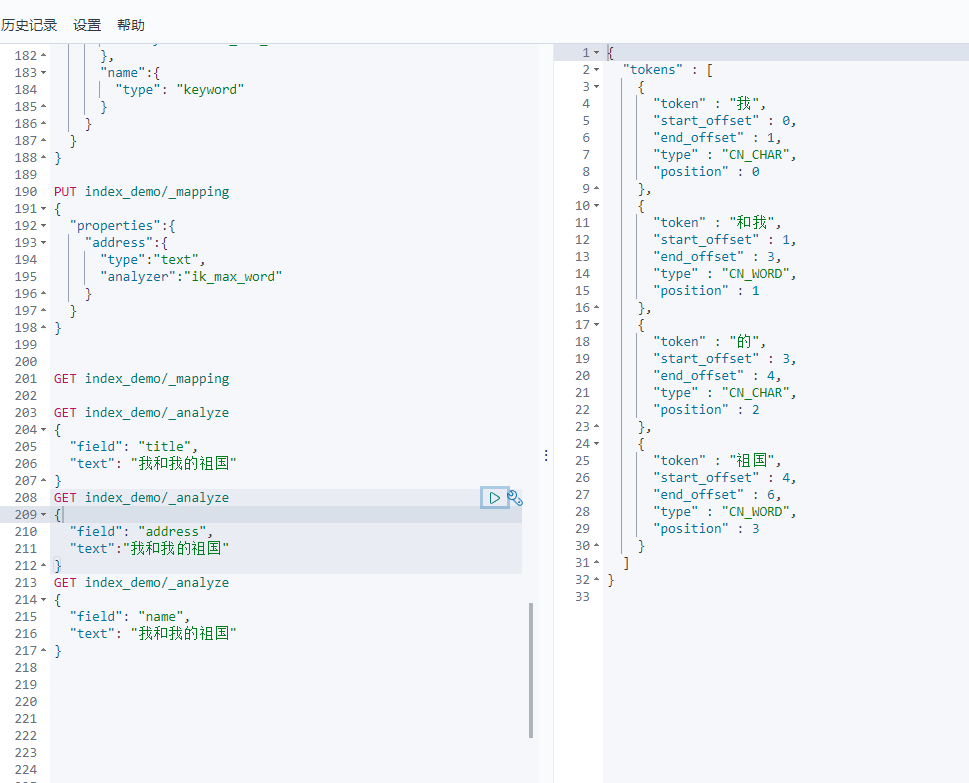
4-4 测试不同字段的分词器
GET 索引名称/_analyze{"field":"索引中的text类型的字段名","text":"要分词处理的文本数据"}


若有收获,就点个赞吧
0 人点赞
