1、测试数据
1-1 建索引
PUT test_search{"mappings": {"properties": {"dname" : {"type" : "text","analyzer": "standard"},"ename" : {"type" : "text","analyzer": "standard"},"eage" : {"type": "long"},"hiredate" : {"type": "date"},"gender" : {"type" : "keyword"}}}}
1-2 插入数据
POST test_search/_bulk{ "index": {}}{ "dname" : "Sales Department", "ename" : "张三", "eage":20, "hiredate" : "2019-01-01", "gender" : "男性" }{ "index": {}}{ "dname" : "Sales Department", "ename" : "李四", "eage":21, "hiredate" : "2019-02-01", "gender" : "男性" }{ "index": {}}{ "dname" : "Development Department", "ename" : "王五", "eage":23, "hiredate" : "2019-01-03", "gender" : "男性" }{ "index": {}}{ "dname" : "Development Department", "ename" : "赵六", "eage":26, "hiredate" : "2018-01-01", "gender" : "男性" }{ "index": {}}{ "dname" : "Development Department", "ename" : "韩梅梅", "eage":24, "hiredate" : "2019-03-01", "gender" : "女性" }{ "index": {}}{ "dname" : "Development Department", "ename" : "钱虹", "eage":29, "hiredate" : "2018-03-01", "gender" : "女性" }
2、 query DSL
DSL——Domain Specified Language ,特殊领域的语言
请求参数是请求体传递的。在Elasticsearch中,请求体的字符集默认为UTF-8。
语法格式:
GET 索引名/_search{"command":{ "parameter_name" : "parameter_value"}}
2-1 查询所有数据
GET 索引名/_search{"query" : { "match_all" : {} }}

2-2 match search(项目搜索功能使用此命令)
全文检索。要求查询条件拆分后的任意词条与具体数据匹配就算搜索结果。类似于SQL 语句中的 LIKE %字段值%
GET 索引名/_search{"query": {"match": {"字段名": "搜索条件"}}}
<br />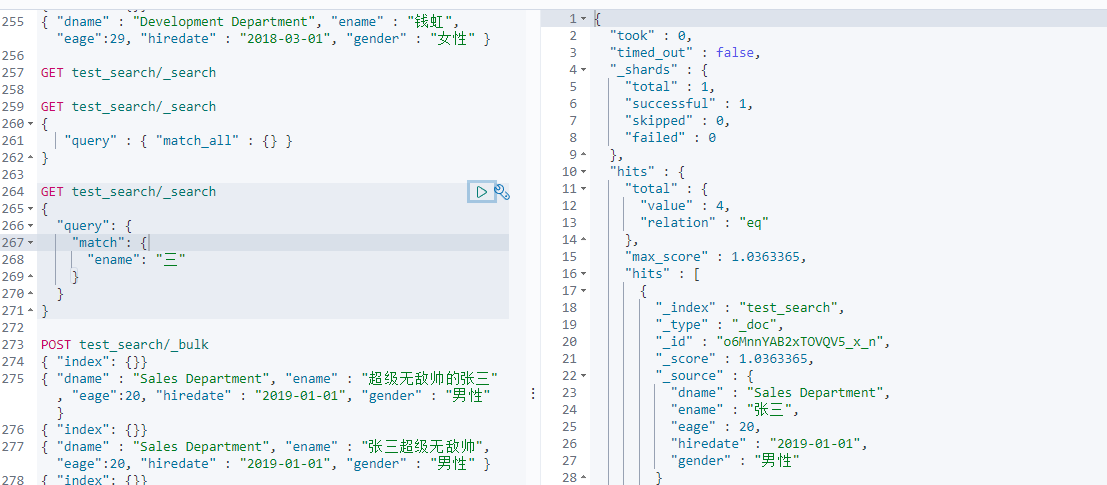
2-3 phrase search
短语检索。要求查询条件必须和具体数据完全匹配才算搜索结果。其特征是:
a.对搜索条件进行拆词
b.把拆词当做一个整体,整体去索引(索引是存储内容被拆词后的结果)中匹配,必须严格匹配(存储内容拆词后是:北京,大兴,朝阳。条件拆词是:北京,朝阳。这种情况是不能被查询的,因为北京和朝阳之间还有大兴)才能查询到。
GET 索引名/_search{"query": {"match_phrase": {"字段名": "搜索条件"}}}
2-4 range
范围搜索
GET 索引名/类型名/_search{"query" : {"range" : {"字段名" : {"gt" : 搜索条件1,"lte" : 搜索条件2}}}}
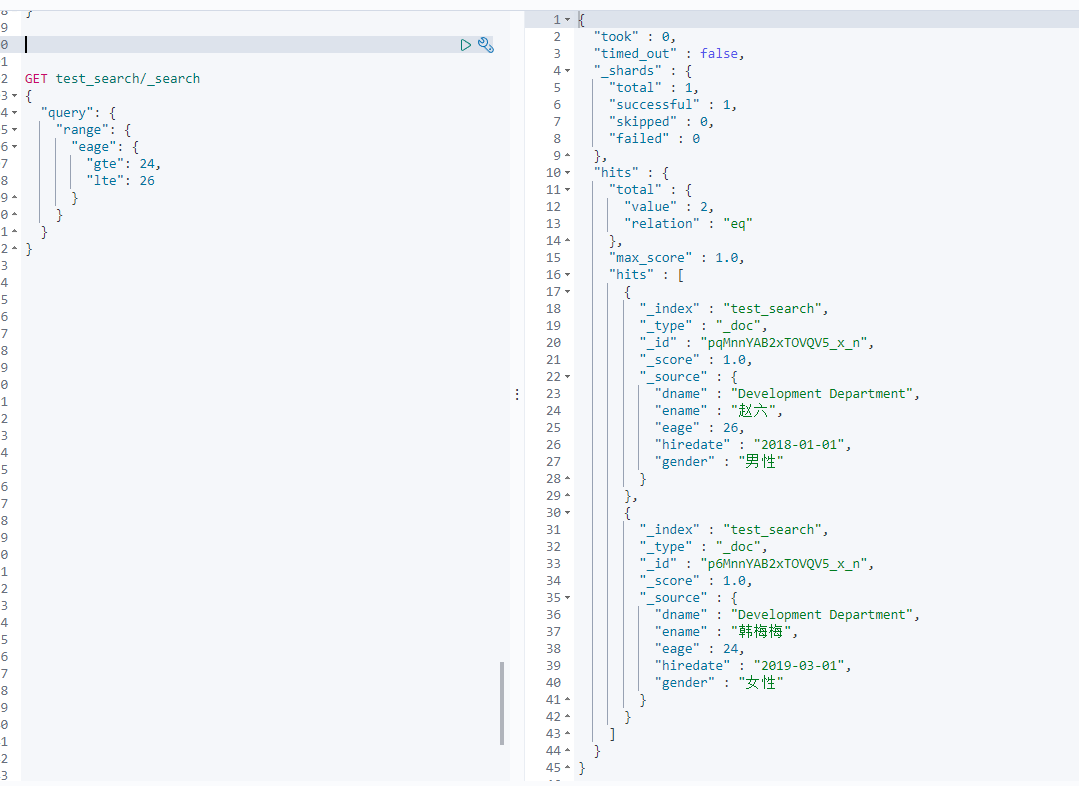
2-5 多条件复合搜索
在一个请求体中,有多个搜索条件。如:条件为部门名称是 Sales Department,员工年龄在20-26之间,员工姓名叫张三;上述条件中,部门名称为可选条件,员工年龄必须满足要求,部门员工姓名为可选要求。这就是复合搜索。
GET 索引名/类型名/_search{"query": {"bool": {"must": [ #数组中的多个条件必须同时满足{"range": {"字段名": {"lt": 条件}}}],"must_not":[ #数组中的多个条件必须都不满足{"match": {"字段名": "条件"}},{"range": {"字段名": {"gte": "搜索条件"}}}]"should": [# 数组中的多个条件有任意一个满足即可。{"match": {"字段名": "条件"}},{"range": {"字段名": {"gte": "搜索条件"}}}]}}}
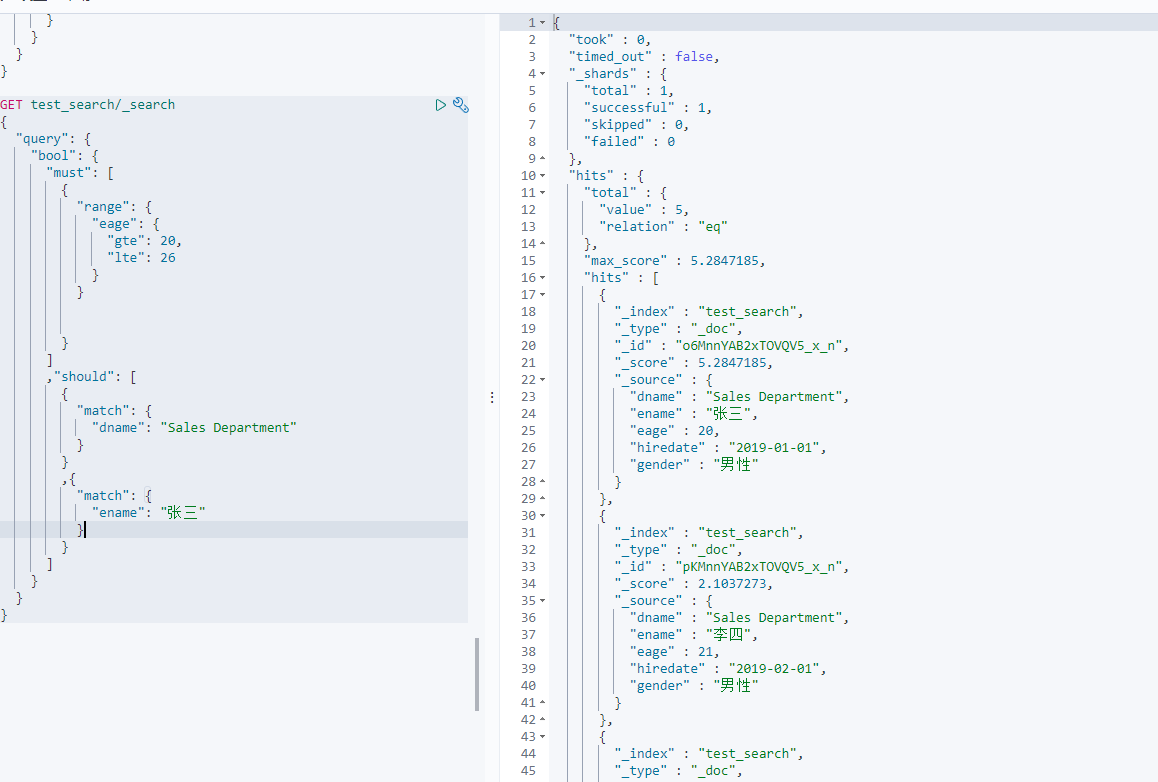
2-6 排序
在Elasticsearch的搜索中,默认是使用相关度分数实现排序的(所以上个图片中结果肯定是张三排最前面)。可以通过搜索语法实现定制化排序。
GET 索引名/_search{"query": {[搜索条件]},"sort": [{"字段名1": {"order": "asc"}},{"字段名2": {"order": "desc"}}]}
下面我们用年龄来倒序排序<br />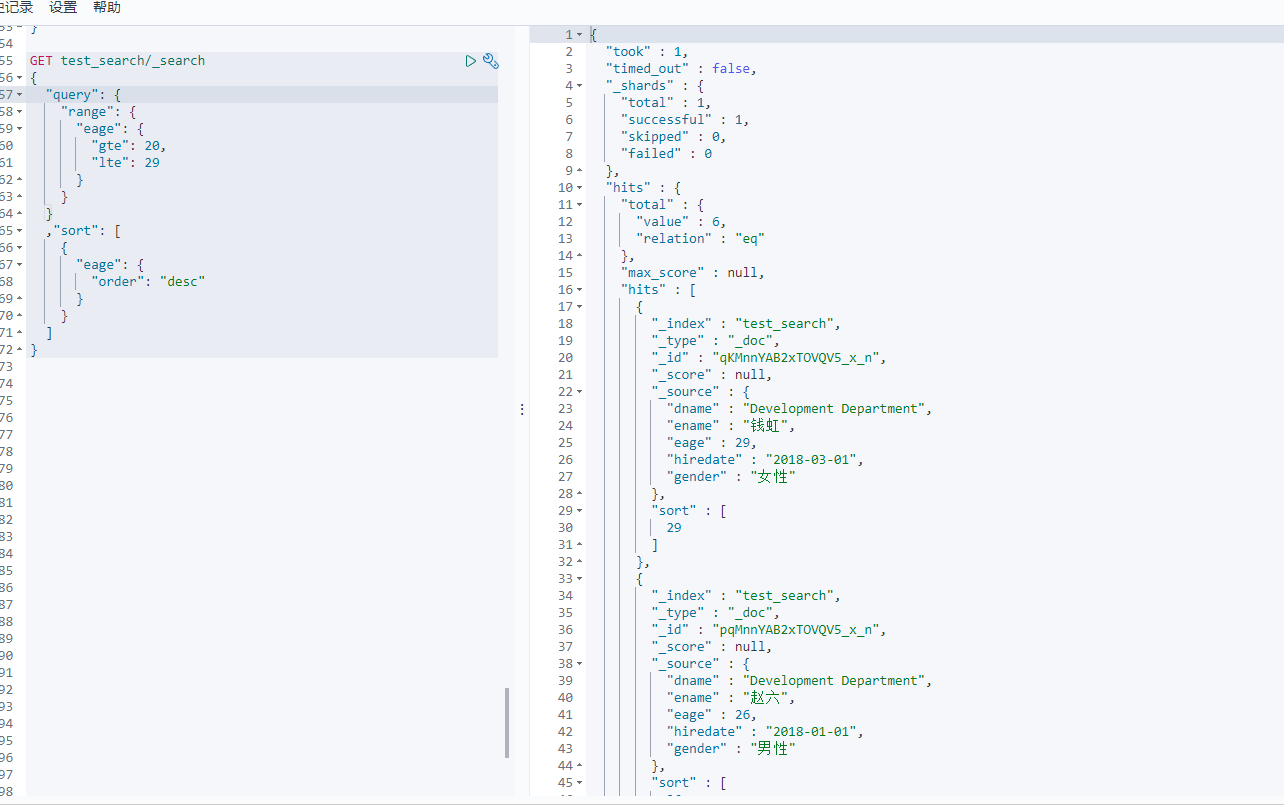<br />再来查询 部门名称是 Sales Department,员工年龄在20-26之间的员工,然后年龄升序排序<br />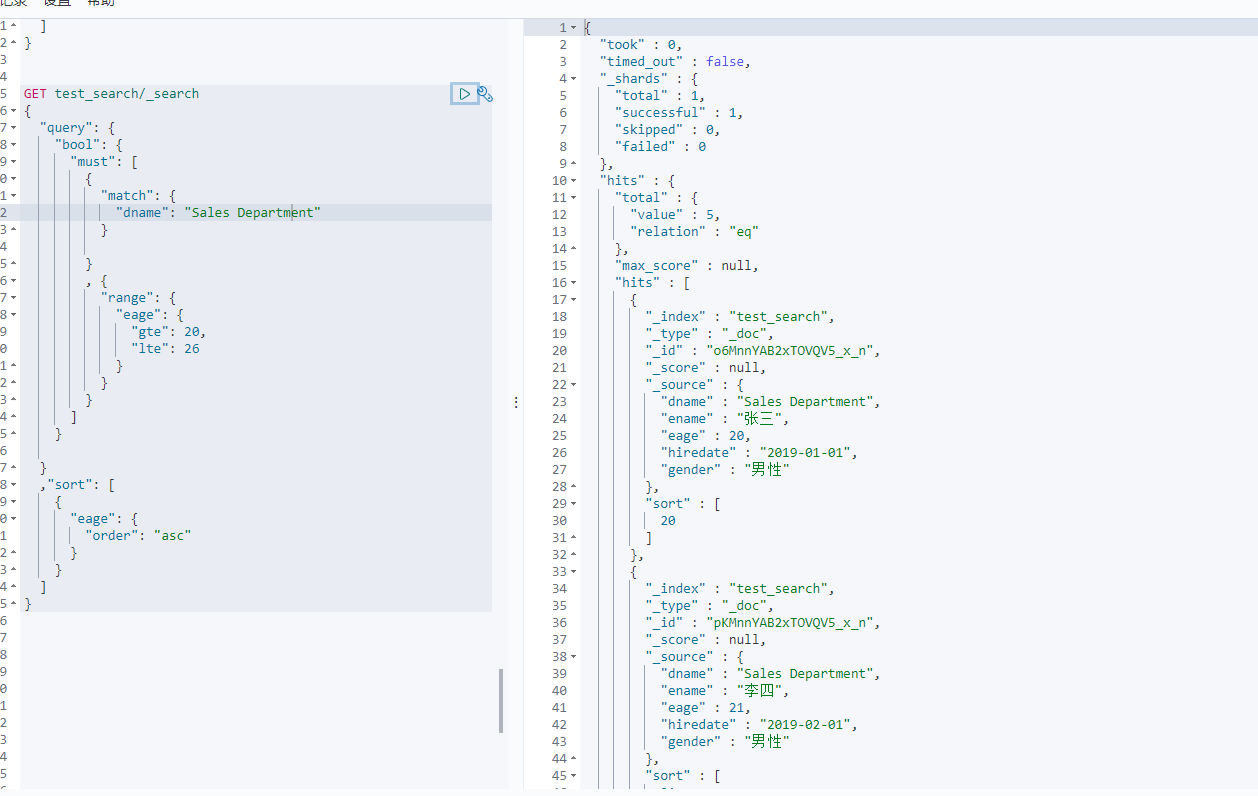<br />**注意:在Elasticsearch中,如果使用text类型的字段作为排序依据,会有问题。Elasticsearch需要对text类型字段数据做分词处理。如果使用text类型字段做排序,Elasticsearch给出的排序结果未必友好,毕竟分词后,先使用哪一个单词做排序都是不合理的。所以Elasticsearch中默认情况下不允许使用text类型的字段做排序,如果需要使用字符串做结果排序,则可使用keyword类型字段作为排序依据,因为keyword字段不做分词处理**。
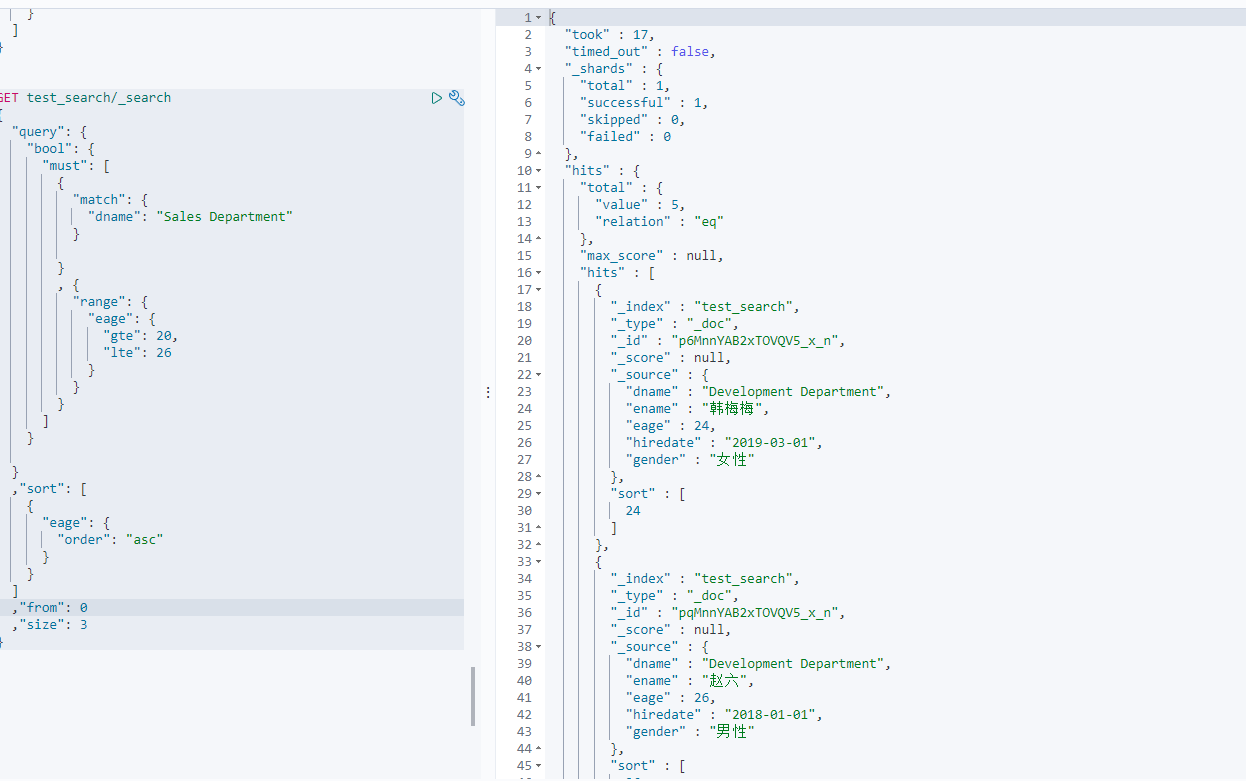
2-7 分页
DSL分页也是用from和size实现的
GET 索引名称/_search{"query":{"match_all":{}},"from": 起始下标,"size": 查询记录数}
2-7 highlight display 高亮显示
在搜索中,经常需要对搜索关键字做高亮显示,这个时候就可以使用highlight语法
GET 索引名/_search{"query": {"match": {"字段名": "条件"}},"highlight": {"fields": {"要高亮显示的字段名": {"fragment_size": 5, #每个分段长度,默认20"number_of_fragments": 1 #返回多少个分段,默认3}},"pre_tags": ["前缀"],"post_tags": ["后缀"]}}
<br />fragment_size:代表字段数据**如果过长**,则分段,每个片段数据长度为多少。长度不是字符数量,是Elasticsearch内部的数据长度计算方式。默认不对字段做分段。<br />number_of_fragments:代表搜索返回的高亮片段数量,默认情况下会将拆分后的所有片段都返回。<br />pre_tags:高亮前缀<br />post_tags:高亮后缀<br />很多搜索结果显示页面中都不会显示完整的数据,这样在数据过长的时候会导致页面效果不佳,都会按照某一个固定长度来显示搜索结果,所以fragment_size和number_of_fragments参数还是很常用的。<br />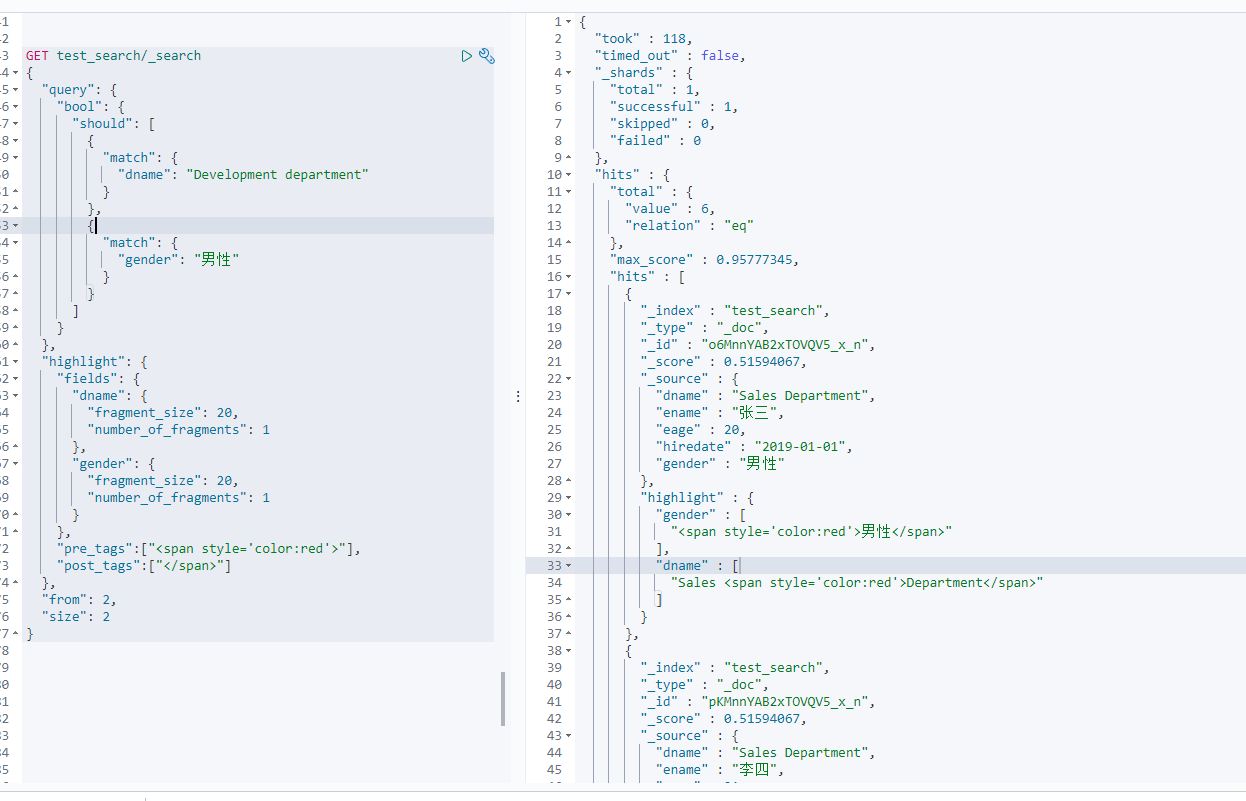

若有收获,就点个赞吧
0 人点赞
