1、Elasticsearch默认提供的常见分词器
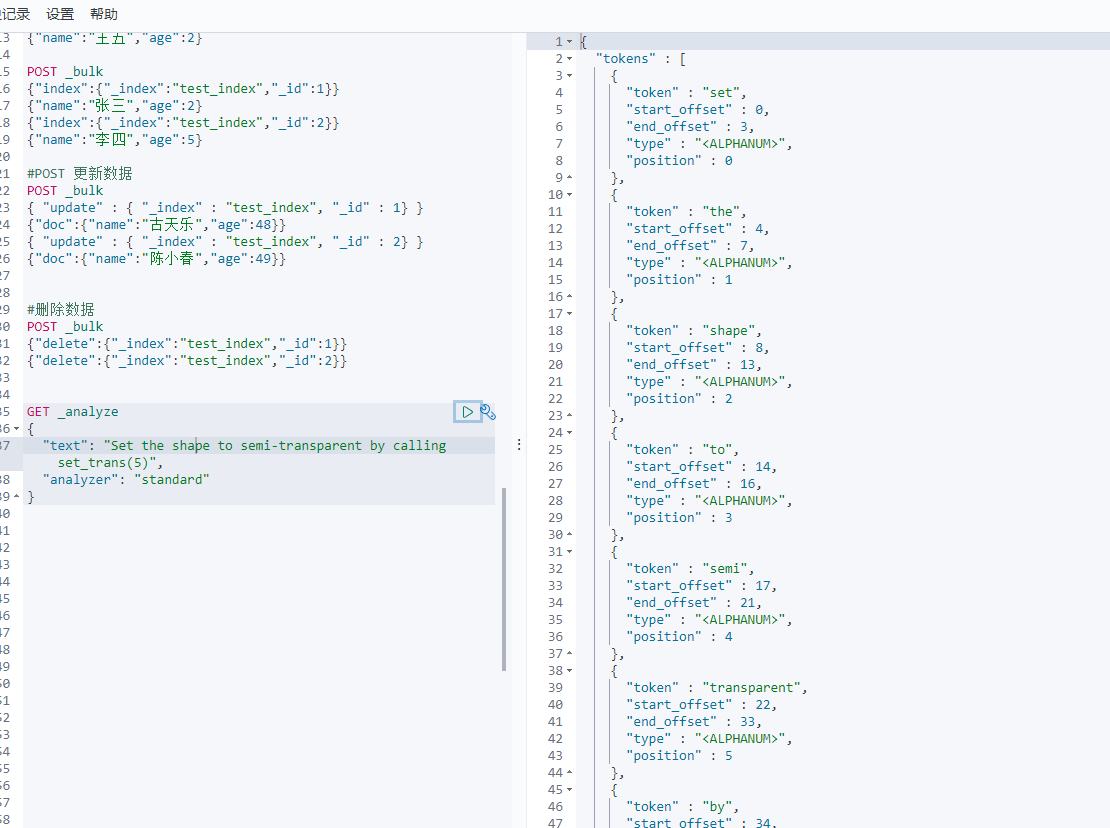
要切分的语句:Set the shape to semi-transparent by calling set_trans(5)
1-1 standard analyzer 标准分词器:
Elasticsearch中的默认分词器。标准分词器,处理英语语法的分词器。
切分后的key_words:set, the, shape, to, semi, transparent, by, calling, set_trans, 5。
这种分词器也是Elasticsearch中默认的分词器。切分过程中不会忽略停止词(如:the、a、an等)。会进行单词的大小写转换、过滤连接符(-)或括号等常见符号。
GET _analyze{"text": "Set the shape to semi-transparent by calling set_trans(5)","analyzer": "standard"}
1-2 simple analyzer 简单分词器:
切分后的key_words:set, the, shape, to, semi, transparent, by, calling, set, trans。
就是将数据切分成一个个的单词。使用较少,经常会破坏英语语法。
GET _analyze{"text": "Set the shape to semi-transparent by calling set_trans(5)","analyzer": "simple"}
1-3 whitespace analyzer 空白符分词器:
切分后的key_words:Set, the, shape, to, semi-transparent, by, calling, set_trans(5)。
就是根据空白符号切分数据。如:空格、制表符等。使用较少,经常会破坏英语语法。
GET _analyze{"text": "Set the shape to semi-transparent by calling set_trans(5)","analyzer": "whitespace"}
1-4 language analyzer 语言分词器:
如英语分词器(english)等。切分后的key_words:set, shape, semi, transpar, call, set_tran, 5。根据英语语法分词,会忽略停止词、转换大小写、单复数转换、时态转换等,应用分词器分词功能类似standard analyzer。
GET _analyze{"text": "Set the shape to semi-transparent by calling set_trans(5)","analyzer": "english"}
注意:Elasticsearch中提供的常用分词器都是英语相关的分词器,对中文的分词都是一字一词。
2、普通方式安装中文分词器
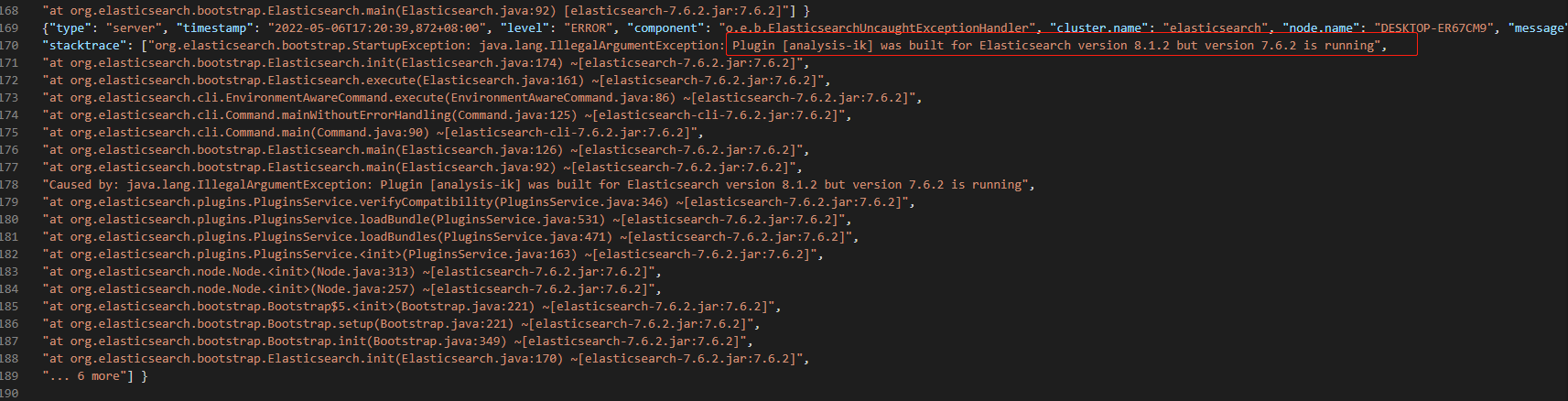
2-1 Linux安装
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
新建目录
# cd /usr/local/es/plugins
# mkdir ik
使用xftp上传ik压缩包elasticsearch-analysis-ik-7.6.2.zip到/usr/local/es/plugins/ik
解压
# cd ik
# unzip elasticsearch-analysis-ik-7.6.2.zip
关闭kibana
使用jps和kill -9关闭elasticsearch
启动elasticsearch
# cd /usr/local/es/bin
刚安装完内容后直接前台启动,启动成功后在用后台启动。
# ./elasticsearch
2-2 Windows安装
解压后放到ES的plugins目录下重启即可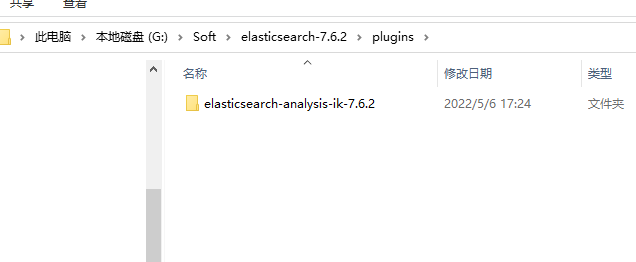
2-3 测试IK分词器
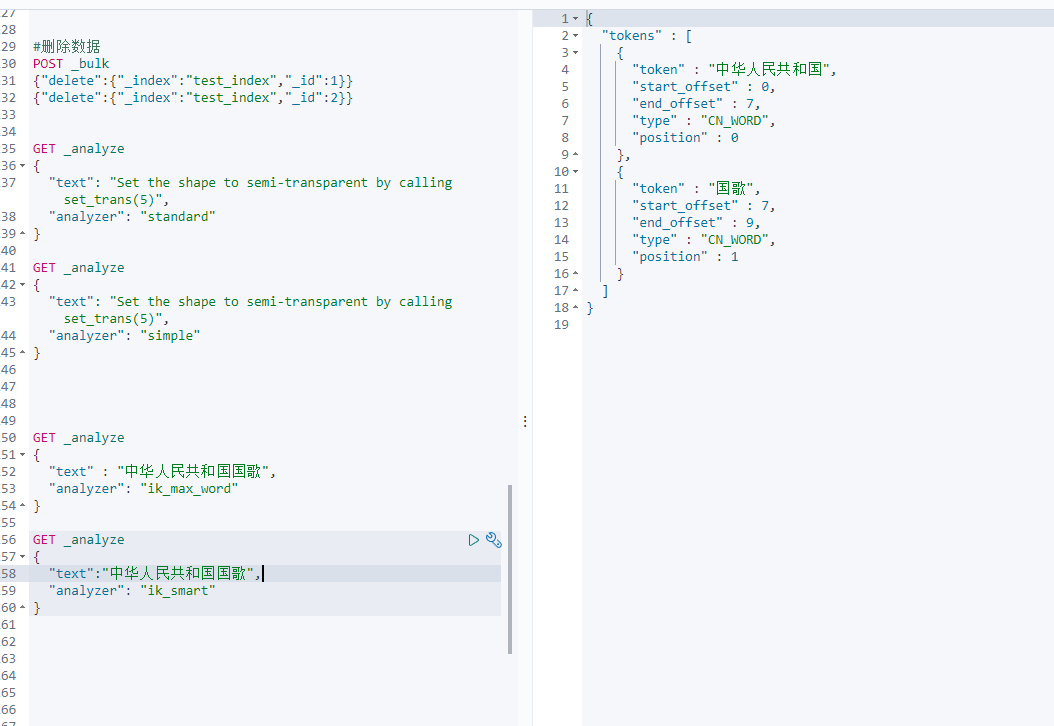
IK分词器提供了两种analyzer,分别是ik_max_word和ik_smart。
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,国,国歌”,会穷尽各种可能的组合;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。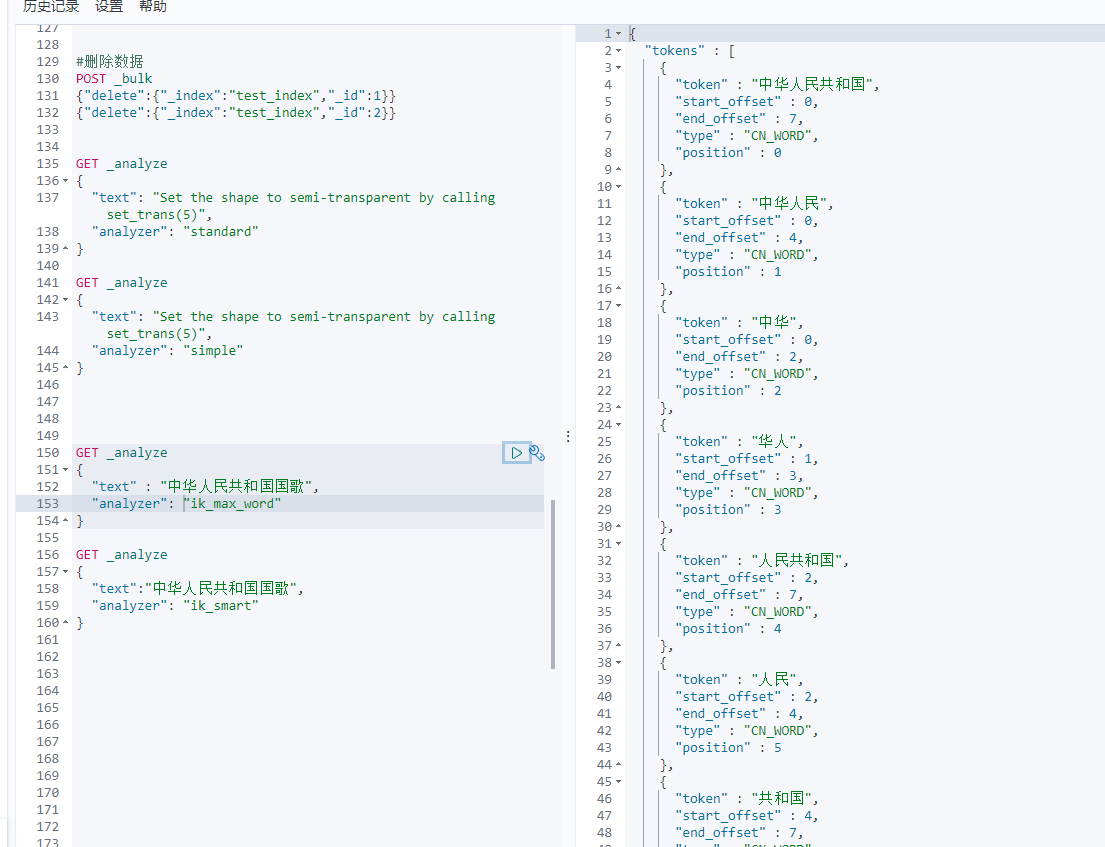
3、基于Docker安装中文分词器
3-1 进入容器
3-2 安装IK
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip
3-3 重启容器
3-4 测试
如2-3
4、基于Docker手动安装IK步骤
4-1 删除ES的容器
如果容器在运行中,需要先停止容器
# docker stop es
# docker rm es
4-2 创建容器,并指定共享目录
先在宿主中创建一个目录
# mkdir /usr/local/es
创建并运行容器,指定共享目录./bjsxt是容器内部目录,如果不存在,会自动创建
docker run —name=es -d -p 9200:9200 -p 9300:9300 -v /usr/local/es:/bjsxt -e “discovery.type=single-node” elasticsearch:7.6.2
4-3 上传分词器
scp -r 或者直接使用XFTP上传到宿主机的:/usr/local/es目录下
4-4 在容器中安装
进入容器内部
# docker exec -it es /bin/bash
进入plugins文件夹
# cd plugins
创建ik目录
# mkdir ik
# cd ik
复制ik压缩包
# cp /bjsxt/elasticsearch-analysis-ik-7.6.2.zip ik.zip
解压
# unzip ik.zip
删除压缩包
# rm -f ik.zip
推出容器
# exit
重启容器.重启过程需要花费一点时间。
# docker restart es
判断是否启动成功
# curl http://localhost:9200
5、配置词条
5-1 使用基于Docker手动安装IK时配置词条步骤(步骤4)
由于在容器内部直接vi时词条为乱码,所以需要在windows或linux中操作。
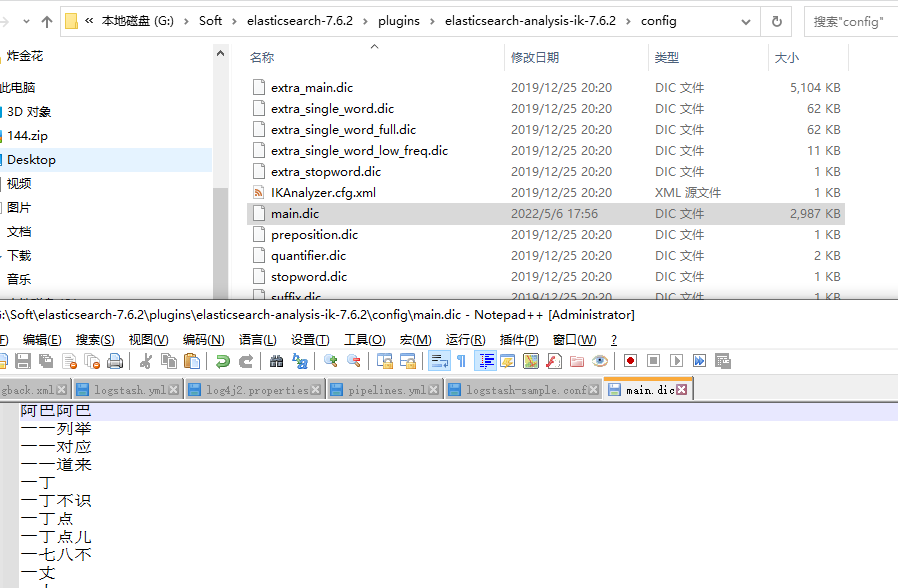
在压缩包中config目录中main.dic中配置需要配置的文字内容。
每个中文词语独占一行。
最简单方法:
在linux中/usr/local/es中直接操作main.dic,在此处操作成功后,容器内容跟随变化。
进入到容器内部后,直接进入/usr/shard/elasticsearch/plugins/ik/config 中
执行:
# cp /bjsxt/config/main.dic main.dic
# exit
# docker restart es
5-2 基于Docker安装IK时配置步骤(步骤3)
把词典文件拷贝出来
# docker cp es:/usr/share/elasticsearch/config/analysis-ik/main.dic /usr/local/main.dic
进入local目录
# cd /usr/local
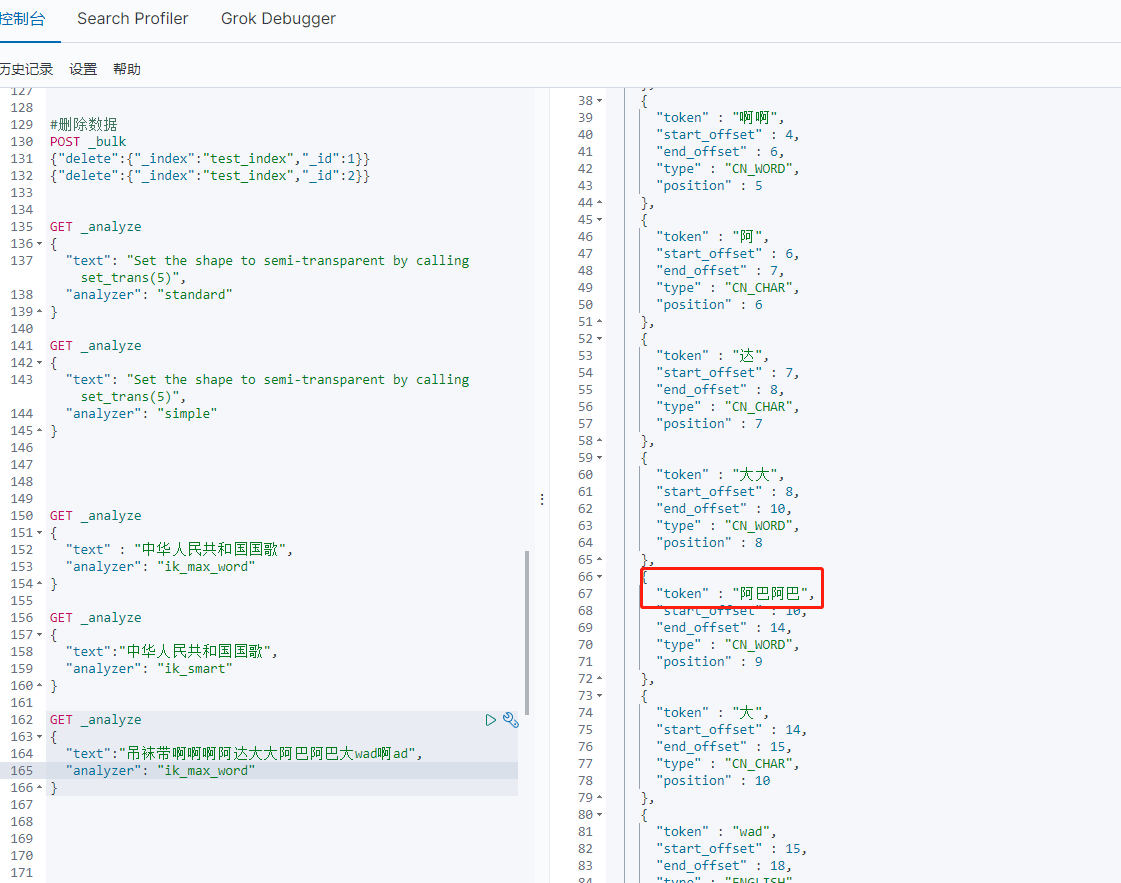
修改文件,在文件中第一行添加自己想添加的一个词语。示例中添加:阿巴阿巴
# vim main.dic
把配置文件放入到容器内部
# docker cp /usr/local/main.dic es:/usr/share/elasticsearch/config/analysis-ik/main.dic
重启容器
# docker restart es
5-3 Windows
5-4 测试
GET _analyze{"text":"吊袜带啊啊啊阿达大大阿巴阿巴大wad啊ad","analyzer": "ik_max_word"}

若有收获,就点个赞吧
0 人点赞
