官方文档地址:https://docs.starrocks.com/zh-cn/main/introduction/StarRocks_intro
1.StarRocks 基本概念及系统架构
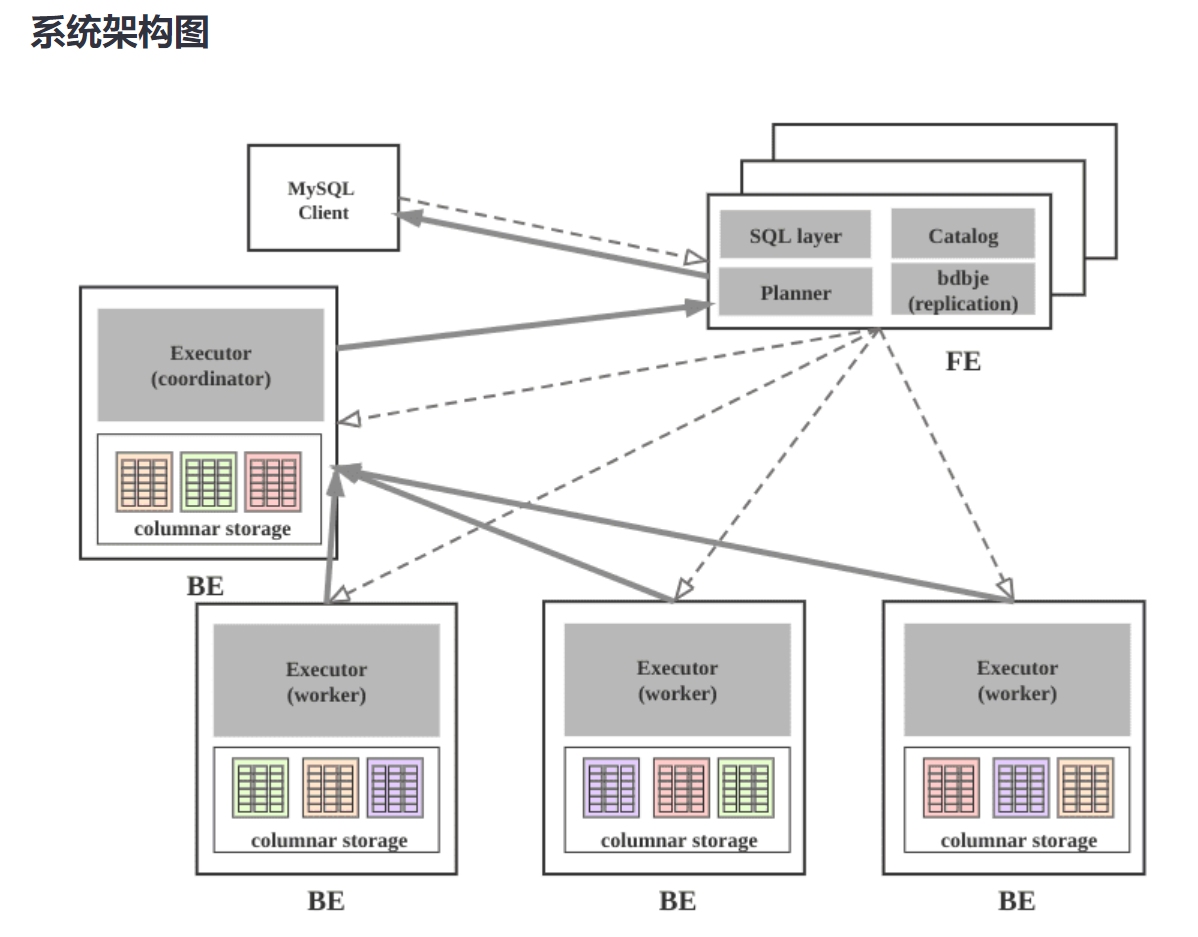
FrontEnd
简称 FE,是 StarRocks 的前端节点,负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作。FE 接收 MySQL 客户端的连接, 解析并执行 SQL 语句。
- 管理元数据, 执行 SQL DDL 命令, 用 Catalog 记录库, 表,分区,tablet 副本等信息。
- FE 的 SQL layer 对用户提交的 SQL 进行解析,分析, 改写, 语义分析和关系代数优化, 生产逻辑执行计划。
- FE 的 Planner 负责把逻辑计划转化为可分布式执行的物理计划,分发给一组 BE。
- FE 监督 BE,管理 BE 的上下线, 根据 BE 的存活和健康状态, 维持 tablet 的副本的数量。
- FE 协调数据导入, 保证数据导入的一致性。
FE 高可用部署,使用复制协议选主和主从同步元数据, 所有的元数据修改操作,由 FE leader 节点完成, FE follower 节点可执行读操作。 元数据的读写满足顺序一致性。FE 的节点数目采用 2n+1,可容忍 n 个节点故障。当 FE leader 故障时,从现有的 follower 节点重新选主,完成故障切换。
BackEnd
简称 BE,是 StarRocks 的后端节点,负责数据存储,计算执行,以及 compaction,副本管理等工作。
BE 管理 tablet 的副本。
- BE 受 FE 指导, 创建或删除 tablet。
- BE 接收 FE 分发的物理执行计划并指定 BE coordinator 节点,在 BE coordinator 的调度下,与其他 BE worker 共同协作完成执行。
- BE 读本地的列存储引擎获取数据, 并通过索引和谓词下沉快速过滤数据。
- BE 后台执行 compact 任务,减少查询时的读放大。
数据导入时, 由 FE 指定 BE coordinator, 将数据以 fanout 的形式写入到 tablet 多副本所在的 BE 上。
其他组件
Broker
Broker 是 StarRocks 和 HDFS 对象存储等外部数据对接的中转服务,辅助提供导入导出功能,如需使用 broker load,spark load,备份恢复等功能需要安装启动 Broker。
Hdfs Broker: 用于从 Hdfs 中导入数据到 StarRocks 集群,详见 数据导入 章节。
StarRocksManager
StarRocksManager 是 StarRocks 企业版提供的管理工具,通过 Manager 可以可视化的进行 StarRocks 集群管理、在线查询、故障查询、监控报警、可视化慢查询分析等功能。
2.数据模型
明细模型: 表中存在主键重复的数据行, 和摄入数据行一一对应, 用户可以召回所摄入的全部历史数据。
- 聚合模型: 表中不存在主键重复的数据行, 摄入的主键重复的数据行合并为一行, 这些数据行的指标列通过聚合函数合并, 用户可以召回所摄入的全部历史数据的累积结果, 但无法召回全部历史数据。
更新模型&主键模型: 聚合模型的特殊情形, 主键满足唯一性约束, 最近导入的数据行, 替换掉其他主键重复的数据行。相当于在聚合模型中, 为数据表的指标列指定的聚合函数为REPLACE, REPLACE函数返回一组数据中的最新数据。
2.1明细模型
StarRocks建表的默认模型是明细模型(Duplicate Key(排序键))
数据表所有维度列构成排序键, 所以后文中提及的排序列, key列本质上都是维度列。
- 排序键可重复, 不必满足唯一性约束。
- 数据表的每一列, 以排序键的顺序, 聚簇存储。
- 排序键使用稀疏索引。
建表示例:
CREATE TABLE `analysis_place_implementation_total_current_month` (id bigint(20) NULL COMMENT "组织机构id",place_all_total int(11) NULL COMMENT "场所总量",place_all_follow_total int(11) NULL COMMENT "场所关注总量",inspection_total int(11) NULL COMMENT "消防场所总量",security_total int(11) NULL COMMENT "治安场所总量",production_total int(11) NULL COMMENT "安全生产场所总量",public_total int(11) NULL COMMENT "公共场所总量",equipment_total int(11) NULL COMMENT "特种设备场所总量",industries_total int(11) NULL COMMENT "特种行业场所总量",other_total int(11) NULL COMMENT "其他场所总量",finance_total int(11) NULL COMMENT "金融场所总量",inspection_follow_total int(11) NULL COMMENT "消防场所关注总量",security_follow_total int(11) NULL COMMENT "治安场所关注总量",production_follow_total int(11) NULL COMMENT "安全生产场所关注总量",public_follow_total int(11) NULL COMMENT "公共场所关注总量",equipment_follow_total int(11) NULL COMMENT "特种设备场所关注总量",industries_follow_total int(11) NULL COMMENT "特种行业场所关注总量",other_follow_total int(11) NULL COMMENT "其他场所关注总量",finance_follow_total int(11) NULL COMMENT "金融场所关注总量") ENGINE=OLAPDUPLICATE KEY(`id`)COMMENT "重点场所落实场所总量表"DISTRIBUTED BY HASH(`id`) BUCKETS 4PROPERTIES ("replication_num" = "1","in_memory" = "false","storage_format" = "DEFAULT");
2.2聚合模型
聚合模型(Aggregate Key)
在建表时, 只要给指标列的定义指明聚合函数, 就会启用聚合模型; 用户可以使用AGGREGATE KEY显式地定义排序键。
建表示例
- site_id, date, city_code为排序键;
- pv为指标列, 使用聚合函数SUM。 ``` CREATE TABLE IF NOT EXISTS aggregate_tbl ( site_id LARGEINT NOT NULL COMMENT “id of site”, date DATE NOT NULL COMMENT “time of event”, city_code VARCHAR(20) COMMENT “city_code of user”, pv BIGINT SUM DEFAULT “0” COMMENT “total page views” )ENGINE=OLAP DISTRIBUTED BY HASH(site_id) BUCKETS 4 PROPERTIES ( “replication_num” = “1”, “in_memory” = “false”, “storage_format” = “DEFAULT” );
CREATE TABLE IF NOT EXISTS aggregate_tb2 ( site_id LARGEINT NOT NULL COMMENT “id of site”, date DATE NOT NULL COMMENT “time of event”, city_code VARCHAR(20) COMMENT “city_code of user”, pv BIGINT SUM DEFAULT “0” COMMENT “total page views” )ENGINE=OLAP
AGGREGATE KEY(site_id,date,city_code) DISTRIBUTED BY HASH(site_id) BUCKETS 4 PROPERTIES ( “replication_num” = “1”, “in_memory” = “false”, “storage_format” = “DEFAULT” );
<a name="fhuJ9"></a>## 2.3更新模型/主键模型- StarRocks收到对某记录的更新操作时,会通过主键索引找到该条记录的位置,并对其标记为删除,再插入一条新的记录。相当于把Update改写为Delete+Insert。- PRIMARY KEY更新模型使用UNIQUE KEY 主键模型使用 PRIMARY KEY 如用户需要更加实时/频繁的更新功能,建议使用[主键模型](https://docs.starrocks.com/zh-cn/main/table_design/Data_model##%E4%B8%BB%E9%94%AE%E6%A8%A1%E5%9E%8B)。
CREATE TABLE analysis_place_implementation_total_current_month (
id bigint(20) NOT NULL COMMENT “组织机构id”,
place_all_total int(11) NULL COMMENT “场所总量”,
place_all_follow_total int(11) NULL COMMENT “场所关注总量”,
inspection_total int(11) NULL COMMENT “消防场所总量”,
security_total int(11) NULL COMMENT “治安场所总量”,
production_total int(11) NULL COMMENT “安全生产场所总量”,
public_total int(11) NULL COMMENT “公共场所总量”,
equipment_total int(11) NULL COMMENT “特种设备场所总量”,
industries_total int(11) NULL COMMENT “特种行业场所总量”,
other_total int(11) NULL COMMENT “其他场所总量”,
finance_total int(11) NULL COMMENT “金融场所总量”,
inspection_follow_total int(11) NULL COMMENT “消防场所关注总量”,
security_follow_total int(11) NULL COMMENT “治安场所关注总量”,
production_follow_total int(11) NULL COMMENT “安全生产场所关注总量”,
public_follow_total int(11) NULL COMMENT “公共场所关注总量”,
equipment_follow_total int(11) NULL COMMENT “特种设备场所关注总量”,
industries_follow_total int(11) NULL COMMENT “特种行业场所关注总量”,
other_follow_total int(11) NULL COMMENT “其他场所关注总量”,
finance_follow_total int(11) NULL COMMENT “金融场所关注总量”
) ENGINE=OLAP
PRIMARY KEY(id)
COMMENT “重点场所落实场所总量表”
DISTRIBUTED BY HASH(id) BUCKETS 4
PROPERTIES (
“replication_num” = “1”,
“in_memory” = “false”,
“storage_format” = “DEFAULT”
);
```
注意:
- 主键列仅支持类型: boolean, tinyint, smallint, int, bigint, largeint, string/varchar, date, datetime, 不允许NULL。
- 分区列(partition)、分桶列(bucket)必须在主键列中。
- 和更新模型不同,主键模型允许为非主键列创建bitmap等索引,注意需要建表时指定。
- 由于其列值可能会更新,主键模型目前还不支持rollup index和物化视图。
- 暂不支持使用ALTER TABLE修改列类型。 ALTER TABLE的相关语法说明和示例,请参见 ALTER TABLE。
- 在设计表时应尽量减少主键的列数和大小以节约内存,建议使用int/bigint等占用空间少的类型。暂时不建议使用varchar。建议提前根据表的行数和主键列类型来预估内存使用量,避免出现OOM。内存估算举例:
a. 假设表的主键为: dt date (4byte), id bigint(8byte) = 12byte
b. 假设热数据有1000W行, 存储3副本
c. 则内存占用: (12 + 9(每行固定开销) ) 1000W 3 * 1.5(hash表平均额外开销) = 945M3.分区分桶副本

若有收获,就点个赞吧
0 人点赞
