项目中哪里用了redis
- 首页广告信息的一级缓存
- 与gateway配合,当作令牌桶存储令牌
- spring cloud gateway 默认使用redis的RateLimter限流算法,在配置文件中说明生成令牌速度和令牌桶最大容量
- 用户登录后将购物车添加信息存储在redis里面
- 使用hash类型存储(key:username vlaue{ key:spuId,value: orderItemBean})
- 因为购物车数据操作相对商品等信息更频繁,属于当前情况下的热点数据
- 临时存储到redis中,等用户下单后就把数据从redis中取出存入到mysql中
- 传统的单点登录技术方法一般将用户身份信息存储到单独的存储介质中,一般考虑性能是redis,但我们的系统没有这么做
- 一般系统:用户认证后将登录信息token存储在认证服务器的redis中,用于后续资源服务器找认证服务器验证。
- 我们系统使用公钥私钥解决,认证服务器将用户信息封装在jwt中,并用私钥加密,资源服务器可以用公钥解密获取用户信息,公钥解密后可以验证token的合法性
- 用以解决用户支付后微信服务器发送的支付状态信息没有收到的问题,每次下单后将订单信息存储在redis队列中,定时每5s检查一次redis队列是否有数据,如果有就去微信服务器查询支付状态
- 未支付就把订单信息重新放回redis队列
- 已支付或者支付失败就将查询到的状态同步到mysql表中
- 定时将商品信息存储到redis当中
- 以hash形式存储,命名空间为参与秒杀开始时间,key为秒杀商品id,value为秒杀商品信息
- 记录用户排队抢单信息,如果不让他们提前排上队,直接处理订单太慢了。
- 使用hash存储,namespace是用户排队信息,key是用户名,value是商品id
- 用户排队时,可以查询当前排队状态,后端就是通过状态查询接口取出排队信息
- 秒杀时记录用户有没有重复排队,通过redis自增来记录排队次数,检查排队次数保证没有重复排队情况
秒杀时防止超卖问题,使用redis用两种方案解决
单线程没有线程上下文切换,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
- 完全基于内存,绝大部分请求是纯粹的内存操作,非常快速;
- 数据结构简单,对数据操作也简单;
- 使用多路 I/O 复用模型,非阻塞 IO。可以结合redis得epoll多路复用模型
如何保证redis数据不丢失
单机单节点模式:
使用AOF和RDB结合的方式
RDB做镜像全量持久化,AOF做增量持久化。因为RDB会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据,所以需要AOF来配合使用。
在redis实例重启时,会使用RDB持久化文件重新构建内存,再使用AOF重放近期的操作指令来实现完整恢复重启之前的状态。
redis集群模式:
master节点持久化
如果不做master节点持久化,可能在master宕机重启的时候数据是空的,然后可能一经过复制,salve node数据也丢了。
redis断点续传
从redis 2.8开始,就支持主从复制的断点续传,如果主从复制过程中,网络连接断掉了,那么可以接着上次复制的地方,继续复制下去,而不是从头开始复制一份。
redis分布式锁
为什么要使用分布式锁
保证同一时刻,仅有一个jvm的一个进程在执行操作逻辑,尽可能将并发带来的不确定性转换为同步的确定性
如何使用redis分布式锁
使用set(set if not exists)key value NX PX 3000
如果key不存在,为key设定指定的值,返回1
如果key存在,返回0
使用expeir key timeout 给对应的key设置一个过期时间,超过这个时间锁自动释放,避免死锁
delete key:事务结束之后,删除key
在redis集群里面设置一个键值对,键可以是方法名,set nx属性表示如果不存在就可以设置成功,如果存在就返回0表示失败。这样就能保证只有一个线程在加锁,解锁就是删除这个记录
问题1:a线程加锁设置了超时时间,时间过了自动删除,但是a还没执行完,b加锁了,a执行完把b的锁删了,这种情况怎么办?
value不是保存无意义的值,而是保存和加锁线程相关的值,在删除锁的时候,先检查当前使用锁的线程是不是自己,如果不是自己,就不能删除。
同时也可以依靠value实现锁重入。
这个逻辑要使用lua脚本来写,从而保证查看是不是自己和删除数据是原子操作.
同时redis数据的过期时间也应当经过实验再设置,大约是时间时加锁代码块运行时间的2-3倍。防止锁倍删除。
现在redis发布了redisson,可以通过调用接口实现分布式锁
- 原理在于,获取锁时上锁操作通过lua脚本实现,保证原子性
- 如果有其他线程想持有锁,发现redis已经有这条数据了,就一直while循环,直到能够加锁成功。
- 锁重入原理:redis存储锁的数据类型是hash类型,hash类型的key保存来当前线程的信息。
redis主从复制

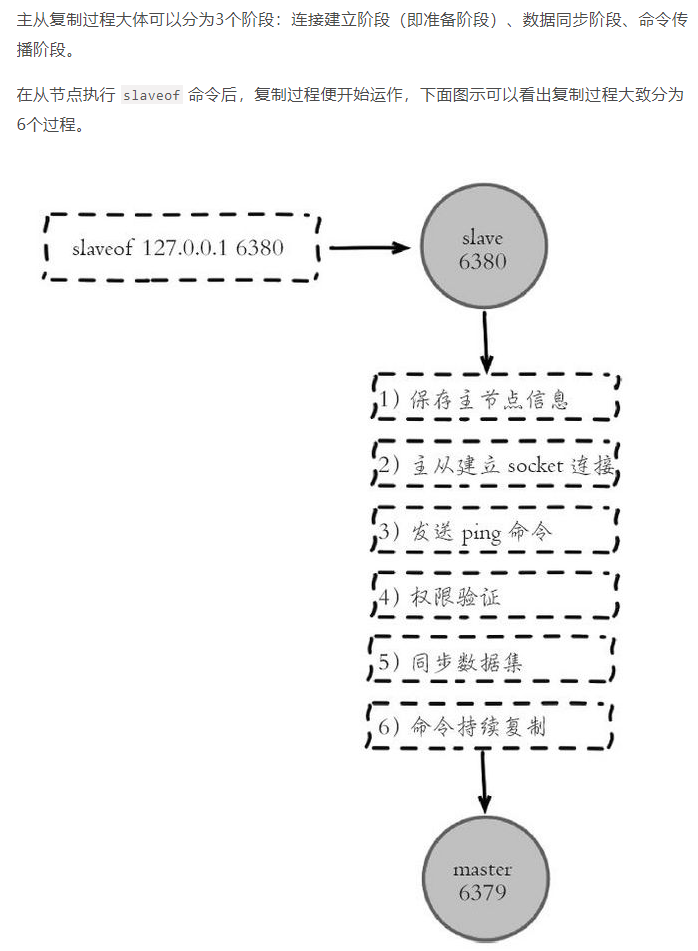
主从复制启用

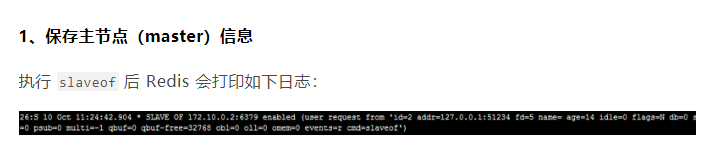
主从复制过程



数据集同步就是全量复制——>用rdb
持续复制用aof,建立缓冲区,进行增量复制
哨兵机制

哨兵监控机制

redis持久化
- rdb(快照持久化):保存某个时间点的redis快照(也会应用于主从复制)
- 优点:
- 紧凑压缩二进制文件,占用空间小
- 直接保存了数据,恢复快
- 缺点:
- 无法做到实时,总会有一些在生成快照过程中做出的更改没法保存下来
- 存储的效率低
- bgsave要执行fork操作创建子进程,牺牲了一部分性能
- redis众多版本没有对rdb格式进行统一,可能出现不同版本的rdb文件无法兼容
- 优点:
- aop(追加文件持久化):以独立日志的方式记录每次写命令,重启时重新执行这些命令
- 优点:
- 存储指令,而非直接存储大量数据,效率高
- 采用不同的策略可以得到不同的完整性(每次/每秒)
- 资源消耗少(每秒的策略)
- 缺点:
- 占用空间较大
- 数据恢复慢
- aof重写:当aof大小超过一定阈值后,就进行重写,只保留可以恢复数据的最小指令集
- 重写过程中会开启aof重写缓冲区,在重写过程中产生的操作会放到缓冲区里面,再加到重写后的文件当中。
- 优点:
- 4.0以后用aop和rdb混合持久化,aof重写时直接把rdb的内容写在aof最前面,这样结合双方的优点,快速加载的同时比面丢失数据,但也有缺点,rdb不已aof的格式保存,可读性较差

若有收获,就点个赞吧
0 人点赞
