Hadoop概述
- Hadoop是一个开源分布式计算平台
-
HDFS
Hadoop Distributed File System
优点
高容错性:Hadoop能够自动保存数据的多副本,并且能够自动将失败的任务重新分配
- 高伸缩性:方便扩展节点
- 高效性:Hadoop能够在节点之前动态地迁移数据,以保证各个节点的动态平衡,因此其处理速度非常快
- 高可靠性:Hadoop按位存储和处理数据
这两个优点允许用户将Hadoop部署在低廉的硬件上,形成分布式系统。
其他特性
- 采用了主从(Master/Slave)结构模型,一个HDFS集群由一个NameNode和若干个DataNode组成
NameNode
NameNode作为主服务器,管理文件系统的命名空间和客户端文件的访问操作,比如打开、关闭、重命名文件或目录等,它也负责数据块到具体DataNode的映射。
NameNode是所有HDFS元数据的管理者。用户保存的数据不会经过NameNode,而是直接流向存储数据的DataNode。DataNode
DataNode负责处理文件系统客户端的文件读写请求,并在NameNode的统一调度下进行数据块的创建、删除、和复制工作。管理存储的数据。元数据
元数据包括:
- 文件系统目录树信息:
- 文件和目录的从属关系。
- 文件名,目录名。
- 文件和目录的大小,创建及最后访问的时间。
- 文件和块的对应关系:
- 文件由哪些快组成。
- 块的存放位置:
- 机器名,块ID。
磁盘元数据文件:
磁盘元数据文件包括以下四个:
- fsimage:元数据镜像文件。是元数据的一个持久化的检查点,包含 Hadoop 文件系统中的所有目录和文件元数据信息,但不包含文件块位置的信息。文件块位置信息只存储在内存中,是在 datanode 加入集群的时候,namenode 询问 datanode 得到的,并且间断的更新。
- edits:日志文件。存放的是 Hadoop 文件系统的所有更改操作(文件创建,删除或修改)的日志,文件系统客户端执行的更改操作首先会被记录到 edits 文件中。
- fstime:保存最近一次Checkpoint的时间。
- VERSION:标志性文件,最后被创建,它的存在表明前三个元数据文件的创建成功。
存储原理
文件被分成若干个数据块,而且这若干个数据块被放在一组DataNode上
文件写入
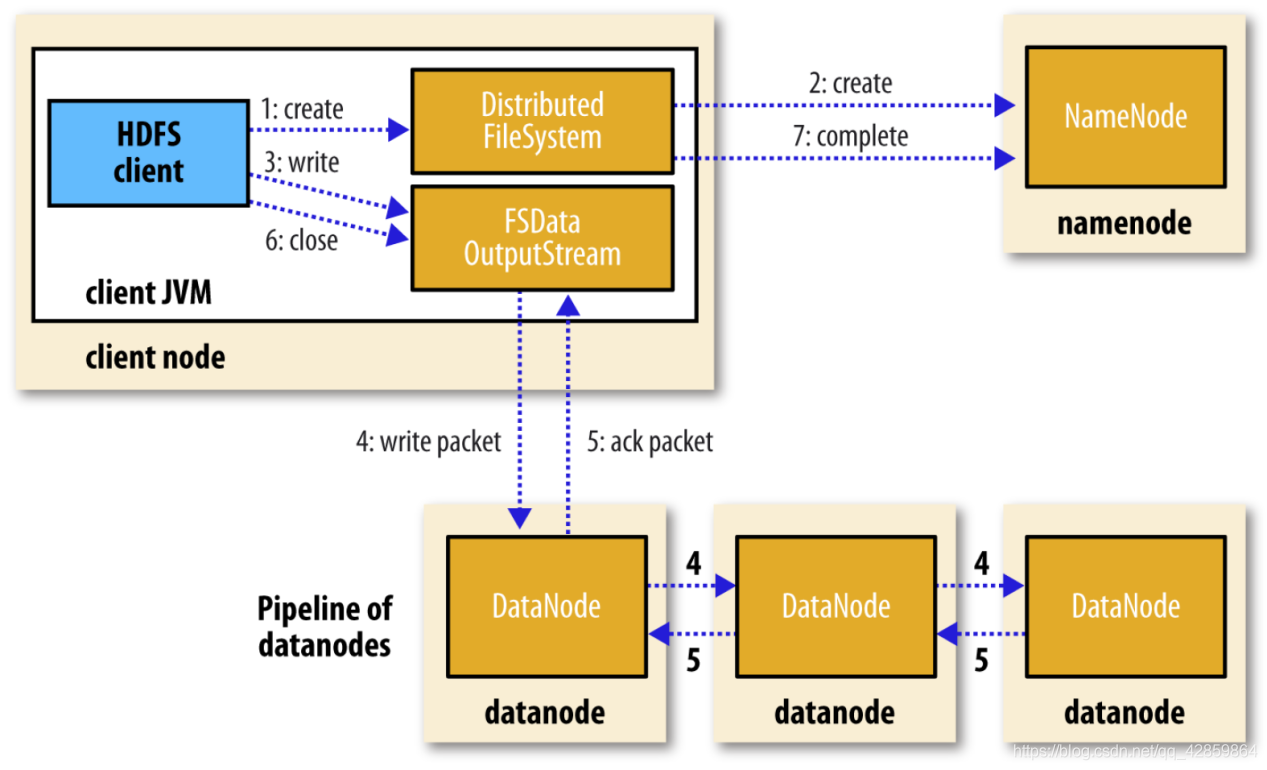
- Clinet向NameNode发起文件写入请求。
- NameNode根据文件大小和文件块配置情况,返回给Client所管理的DataNode的信息。
Client将文件划分为多个Block,根据DataNode的地址信息,将按顺序将其写入到每一个DataNode块中。
文件读取
Client向NameNode发起文件读取请求。
- NameNode返回文件存储的DataNode信息。
-
Block复制
NameNode发现部分文件的Block不符合最小复制数这一要求或部分DataNode失效。
- 通知DataNode相互复制。
- DataNode开始直接相互复制。
HDFS优点功能
- 文件块的放置:一个Block会有三个备份,一份放在NameNode指定的DataNode上,另一份放在与指定DataNode不在同一台机架的DataNode上,最后一份放在与指定DataNode同一Rack的DataNode上。备份的目的是为了数据的安全,采用这种配置方式主要是考虑同一Rack失败的情况,以及不同Rack之前进行数据复制会带来的性能问题。
- 心跳检测:用心跳检测DataNode的健康状况,如果发现问题就采取数据备份的方式来保证数据的安全性。
- 数据复制(场景为DataNode失败,需要平衡DataNode的存储利用率和平衡DataNode数据交互压力等情况):使用Hadoop时可以用HDFS的balancer命令配置Threshold来平衡每一个DataNode的磁盘利用率。假设设置了Threshold为10%,那么执行balancer命令时,首先会统计所有DataNode的磁盘利用率的平均值,然后判断如果每一个DataNode的磁盘利用率超过这个平均值,那么将会把这个DataNode的Block转移到磁盘利用率低的DataNode上,这对于新节点的加入十分有用。
- 数据校验:采用CRC32做数据校验。在写入文件块的时候,除了会写入数据外还会写入校验信息,在读取的时候则需要先校验后读入。
- 单个NameNode:
- 数据管道性的写入:当客户端要写入文件到DataNode上时,首先会读取一个Block,然后将其写到第一个DataNode上,接着由第一个DataNode将其传递到备份的DataNode上,直到所有需要写入这个Block的DataNode都成功写入后,客户端才会开始写入下一个Block。
MapReduce
任务处理流程

若有收获,就点个赞吧
0 人点赞
