K均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是,预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
使用场景
聚类分析是一个无监督学习 (Unsupervised Learning) 过程, 一般是用来对数据对象按照其特征属性进行分组,经常被应用在客户分群,欺诈检测,图像分析等领域。K-means 应该是最有名并且最经常使用的聚类算法了,其原理比较容易理解,并且聚类效果良好,有着广泛的使用。
聚类测试
数据集简介
我们所用到目标数据集是来自 UCI Machine Learning Repository 的 Wholesale customer Data Set。UCI 是一个关于机器学习测试数据的下载中心站点,里面包含了适用于做聚类,分群,回归等各种机器学习问题的数据集。
Wholesale customer Data Set 是引用某批发经销商的客户在各种类别产品上的年消费数。为了方便处理,本文把原始的 CSV 格式转化成了两个文本文件,分别是训练用数据和测试用数据。
图 5. 客户消费数据格式预览
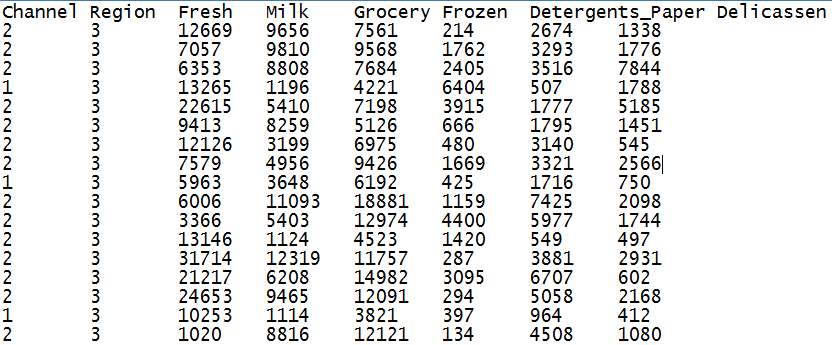
读者可以从标题清楚的看到每一列代表的含义,当然读者也可以到 UCI 网站上去找到关于该数据集的更多信息。虽然 UCI 的数据可以自由获取并使用,但是我们还是在此声明,该数据集的版权属 UCI 以及其原始提供组织或公司所有。
案例分析和编码实现
本例中,我们将根据目标客户的消费数据,将每一列视为一个特征指标,对数据集进行聚类分析。代码实现步骤如下
清单 1. 聚类分析实现类源码
object KMeansML {/*** 聚类分析 Wholesale customers Data Set*/def clusterWholeSale(): Unit = {// val conf = new SparkConf().setAppName("cluster wholesale customers data set")// var sc = new SparkContext(conf)//读取csv数据val spark = SparkSession.builder().appName("sparkdf").master("local[1]").getOrCreate()val filePath = "/home/data/mllib/Wholesale customers data.csv"val dataset = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true")).csv(filePath)dataset.show()val assembler = new VectorAssembler().setInputCols(Array("Channel", "Region", "Fresh", "Milk", "Grocery", "Frozen", "Detergents_Paper", "Delicassen")).setOutputCol("features")//数据及做切分 0.7训练数据 0.3测试数据val Array(trainingData, testData) = dataset.randomSplit(Array(0.7, 0.3))val kMeans = new KMeans().setK(8).setMaxIter(30)//新建流水线val pipeline = new Pipeline().setStages(Array(assembler, kMeans))val pipelineModel = pipeline.fit(trainingData)//从流水线中获取对应模型val KMeansModel = pipelineModel.stages(1).asInstanceOf[KMeansModel]println("Cluster Number:" + KMeansModel.clusterCenters.length)println("Cluster Centers Information Overview:")var clusterIndex:Int = 0KMeansModel.clusterCenters.foreach(x => {println("Center Point of Cluster " + clusterIndex + ":")println(x)clusterIndex += 1})// Make predictions,检验测试数据pipelineModel.transform(testData).select("features","prediction").collect().foreach { case Row(features: Vector,prediction: Int) =>println(s"($features) -> prediction=$prediction")}println("Spark MLlib K-means clustering test finished.")}}
如何选择 K
前面提到 K 的选择是 K-means 算法的关键,Spark MLlib 在 KMeansModel 类里提供了 computeCost 方法,该方法通过计算所有数据点到其最近的中心点的平方和来评估聚类的效果。一般来说,同样的迭代次数和算法跑的次数,这个值越小代表聚类的效果越好。但是在实际情况下,我们还要考虑到聚类结果的可解释性,不能一味的选择使 computeCost 结果值最小的那个 K。
清单 3. K 选择示例代码片段
//选取k值val ks:Array[Int] = Array(3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20)ks.foreach(cluster => {val model:KMeansModel = new KMeans().setK(cluster).setMaxIter(30).fit(trainingData)// Make predictionsval predictions = model.transform(trainingData)// Evaluate clustering by computing Silhouette scoreval evaluator = new ClusteringEvaluator()val silhouette = evaluator.evaluate(predictions)println("sum of squared distances of points to their nearest center when k=" + cluster + " -> "+ silhouette)})
K 选择示例程序运行结果
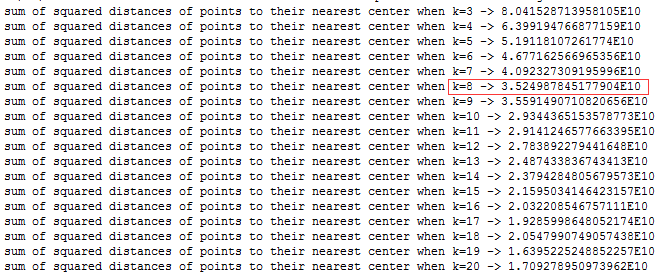
从上图的运行结果可以看到,当 K=9 时,cost 值有波动,但是后面又逐渐减小了,所以我们选择 8 这个临界点作为 K 的个数。当然可以多跑几次,找一个稳定的 K 值。理论上 K 的值越大,聚类的 cost 越小,极限情况下,每个点都是一个聚类,这时候 cost 是 0,但是显然这不是一个具有实际意义的聚类结果。

若有收获,就点个赞吧
0 人点赞
