什么是幻读?
简单来说:事务A的两次读之间有其他事务写操作,比如事务A统计年龄 > 30,当A两次读数据之间其他事务新添加了记录,所以事务A第二次读取到的数据突然多了一个,仿佛出现了幻觉一般,这就是一种幻读
(来源:https://www.cnblogs.com/JMrLi/p/12705188.html)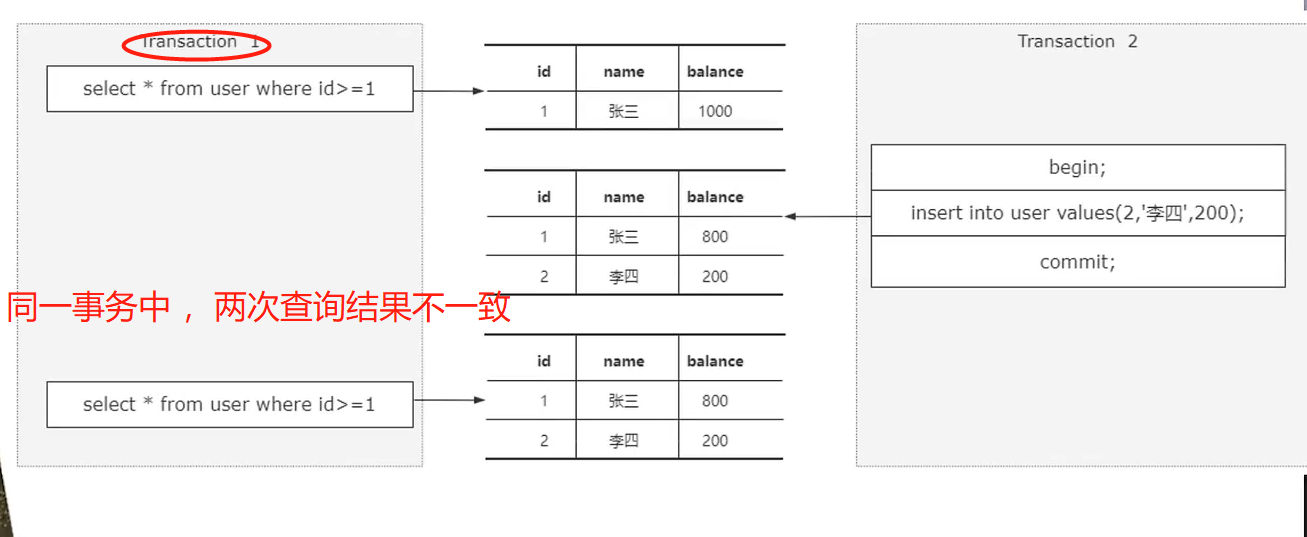

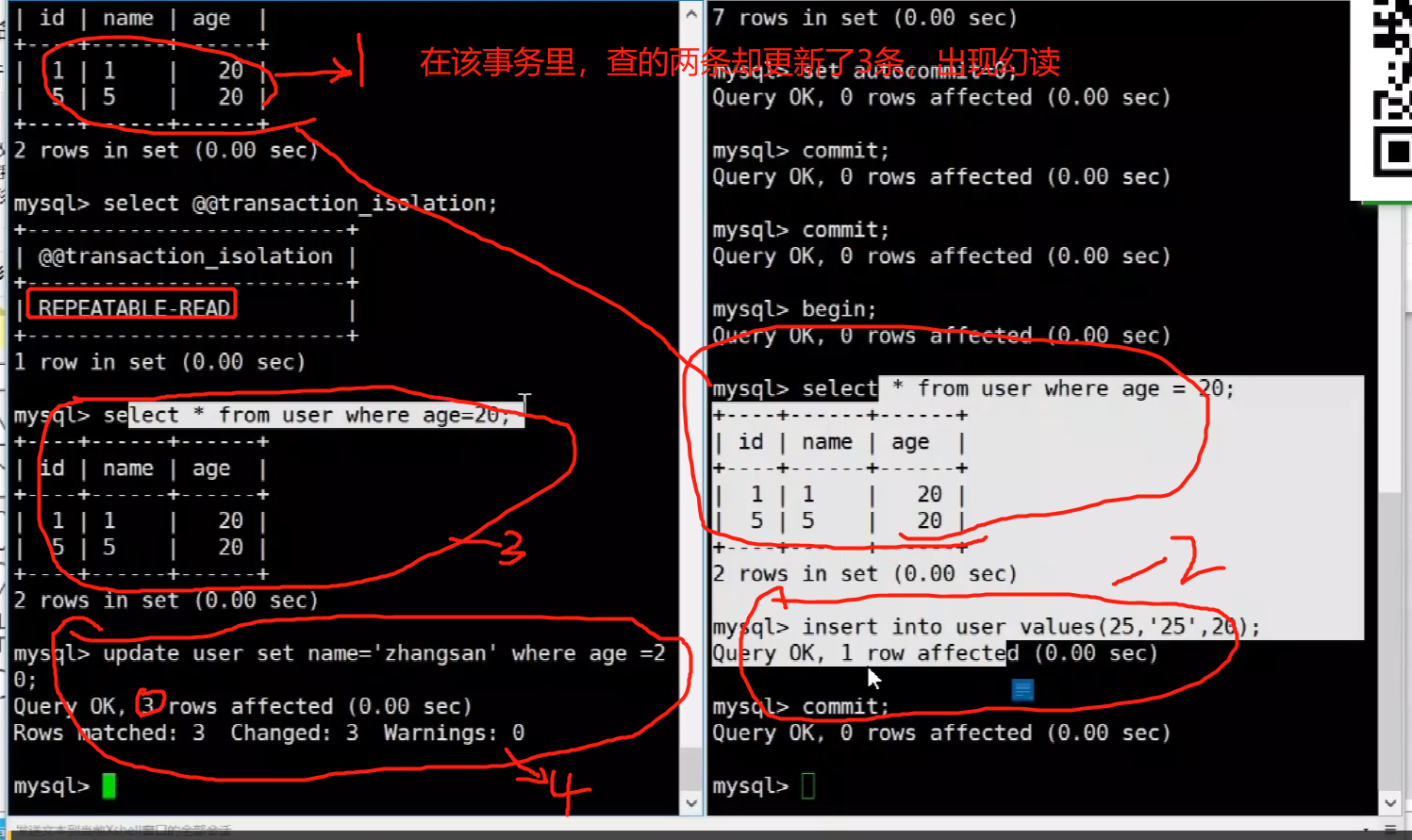
mysql如何解决幻读?
- SERIALIZABLE 串行化
- MVCC + Next-Key Lock(MVCC解决了基于快照读下的幻读,但是MVCC无法解决当前读下的幻读。)
串行化:
- 事务在读操作时,先加表级别的共享锁,直到事务结束才释放
- 事务在写操作时,先加表级别的排它锁,直到事务结束才释放
串行化锁定了整张表,幻读不存在的!
Next-Key Lock是Gap Lock(间隙锁)和Record Lock(行锁)的结合版,都属于Innodb的锁机制
select * from tb where id>100 for update;
- 主键索引 id 会给 id=100 的记录加上 record行锁
- 索引 id 上会加上 gap 锁,锁住 id(100,+无穷大)这个范围
其他事务对 id>100 范围的记录读和写操作都将被阻塞
插入 id=1000的记录时候会命中索引上加的锁会报出事务异常;
Next-Key Lock会确定一段范围,然后对这个范围加锁,保证A在where的条件下读到的数据是一致的,因为在where这个范围其他事务根本插不了也删不了数据,都被Next-Key Lock锁堵在一边阻塞掉了。
(来源:https://www.cnblogs.com/JMrLi/p/12705188.html)
什么是ACID及其理解
事务(transaction)所应该具有的四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
原子性
是指事务是一个不可再分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性
是指在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。这是说数据库事务不能破
坏关系数据的完 整性以及业务逻辑上的一致性。
1.案例
对银行转帐事务,不管事务成功还是失败,应该保证事务结束后ACCOUNT表中aaa和bbb的存款总额为2000元。
隔离性
多个事务并发访问时,事务之间是隔离的,一个事务不应该影响其它事务运行效果。
这指的是在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。由并发事务所做的修改必须与任何其他并发事务所做的修改隔离。事务查看数据更新时,数据所处的状态要么是另一事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看到中间状态的数据。
持久性
意味着在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
mysql默认隔离级别?
MySQL的默认隔离级别就是Repeatable read。
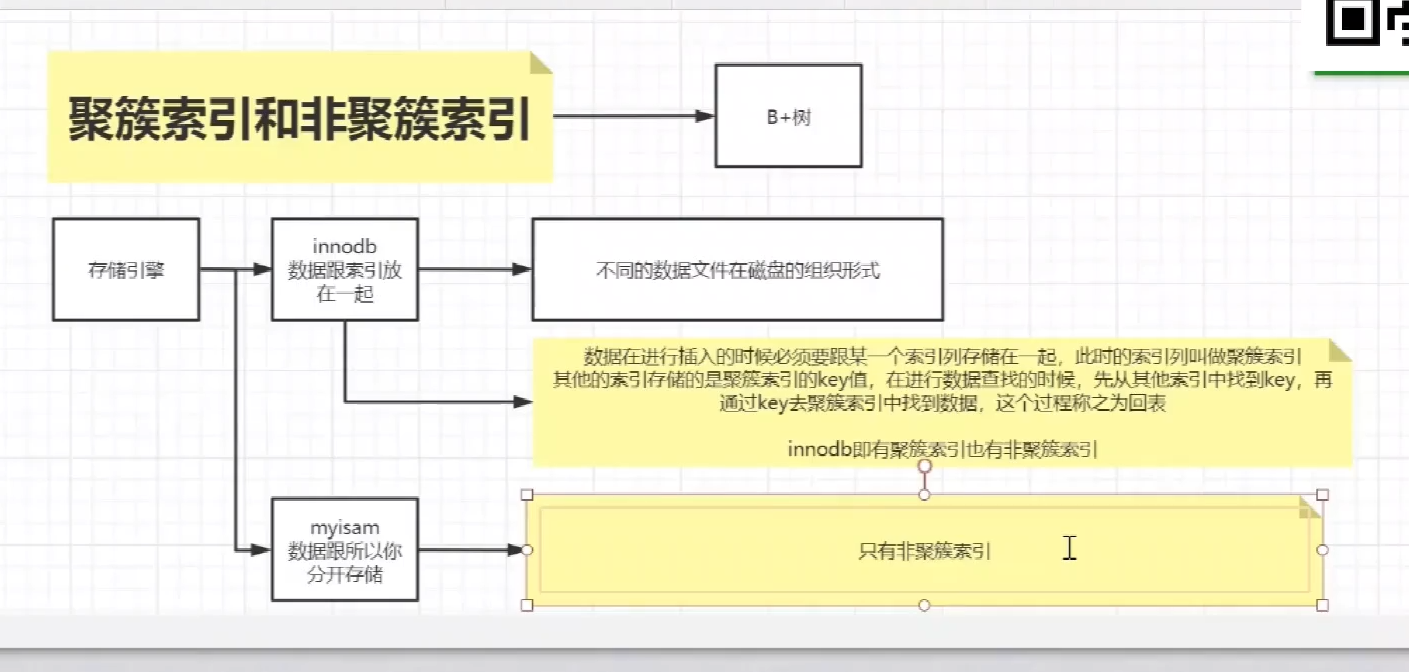
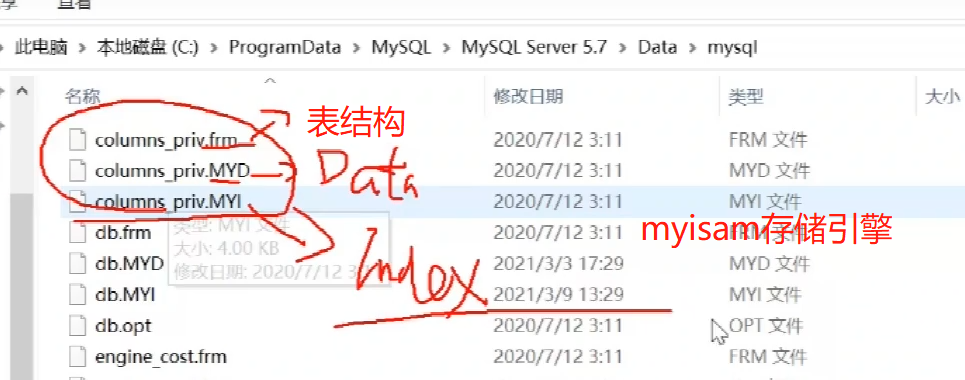
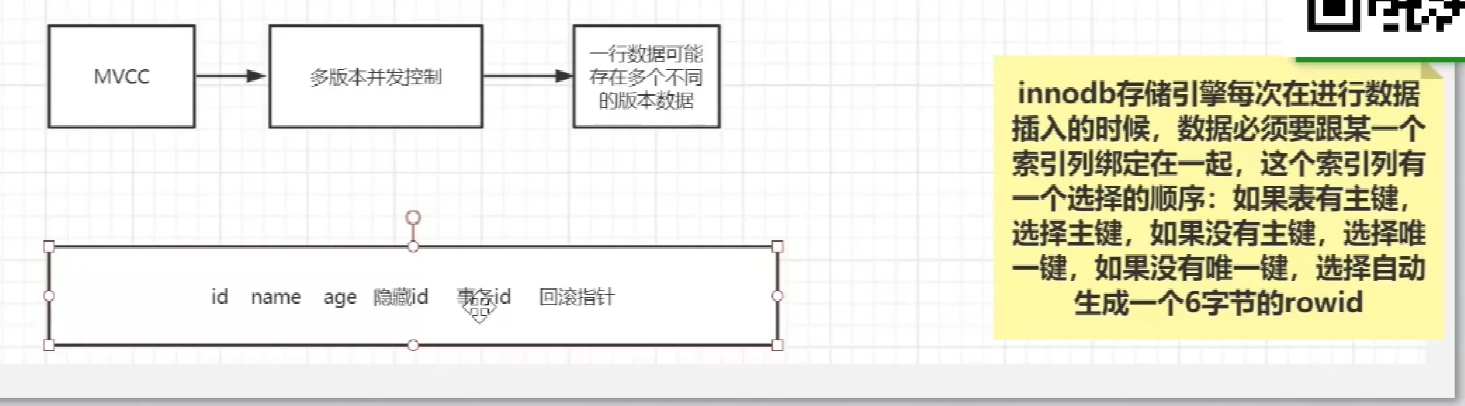
什么是聚簇索引 非聚簇索引
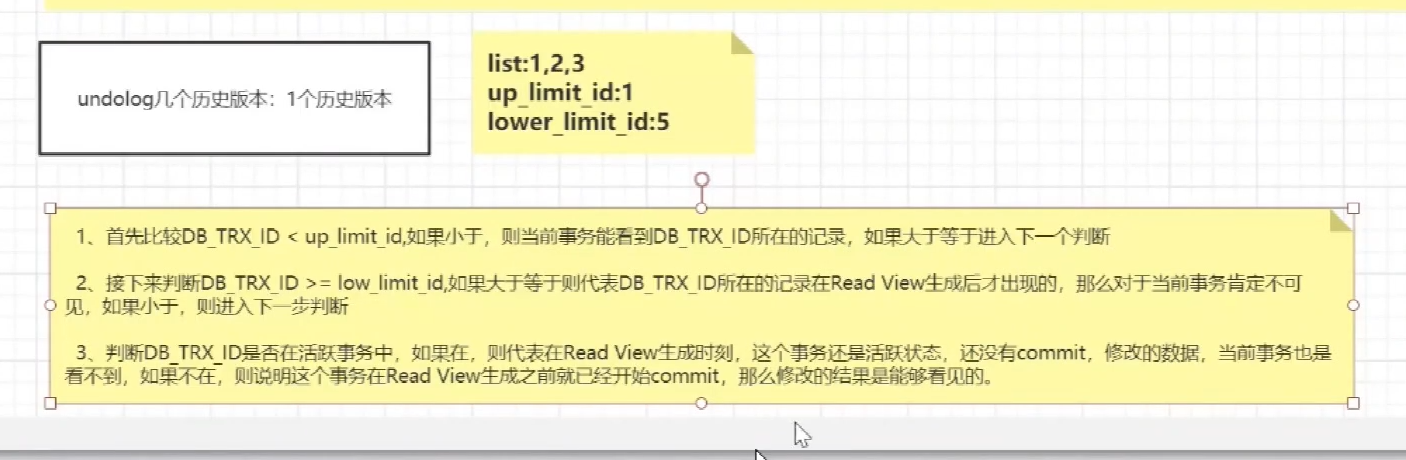
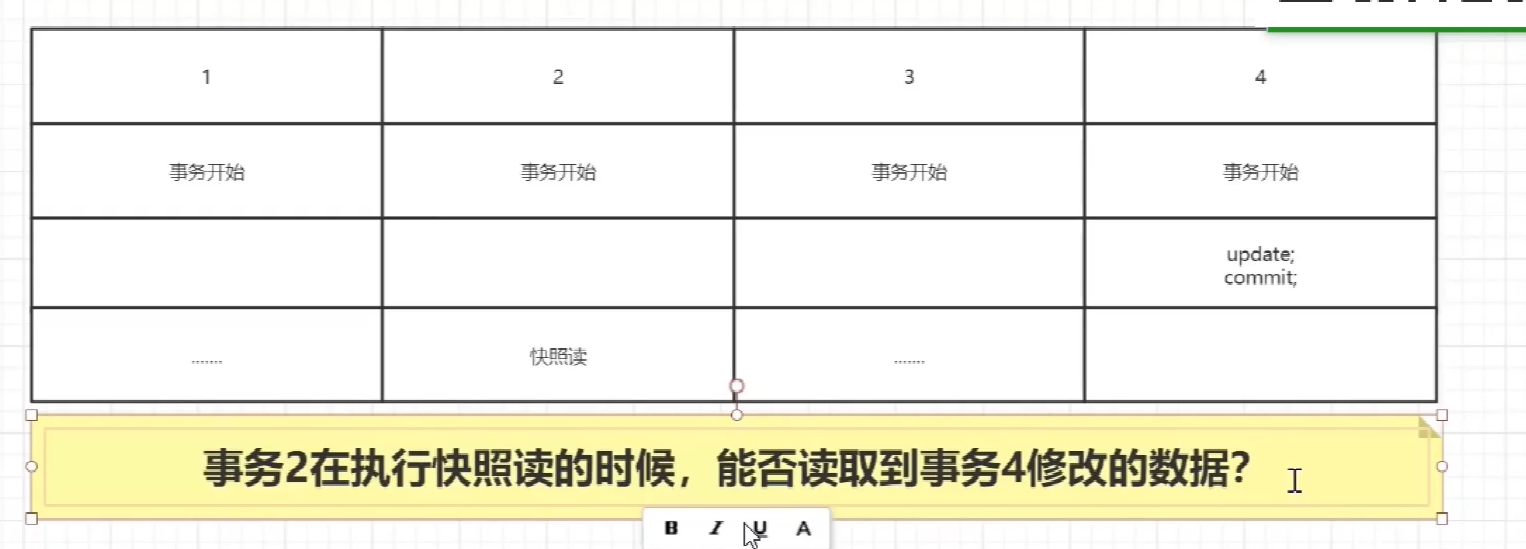
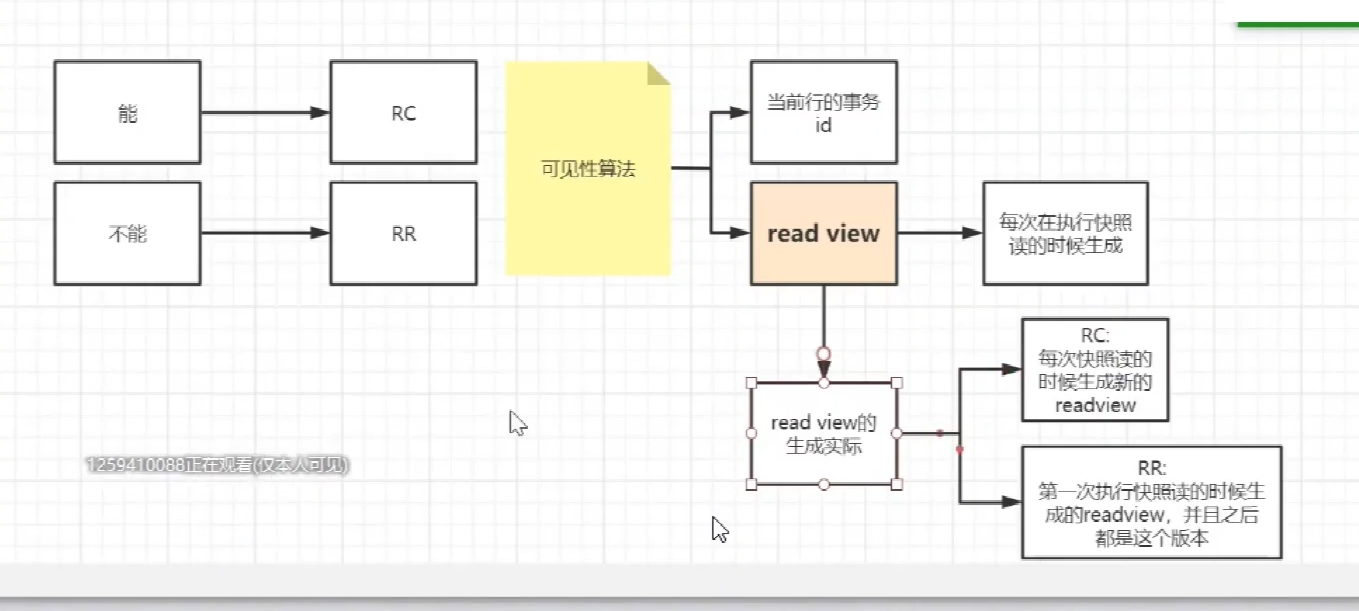
mvcc

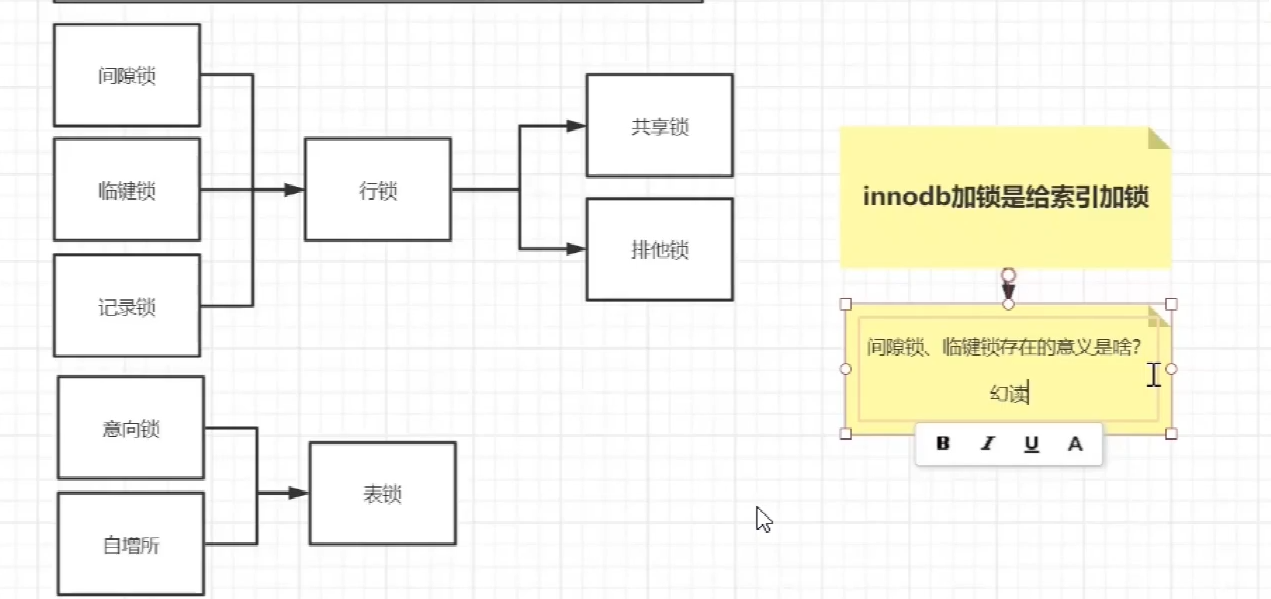
mysql的锁



MyISAM和InnoDB的区别
一、数据存储引擎
数据库应用项目是通过数据库引擎与数据库链接的。何为数据库引擎呢?简而言之,数据库引擎就是驱动各种数据库的程序,它负责处理数据库相关工作的整个核心部份。同样的,数据库应用项目的操作指令,均会通过数据库引擎的处理作用到数据库上。
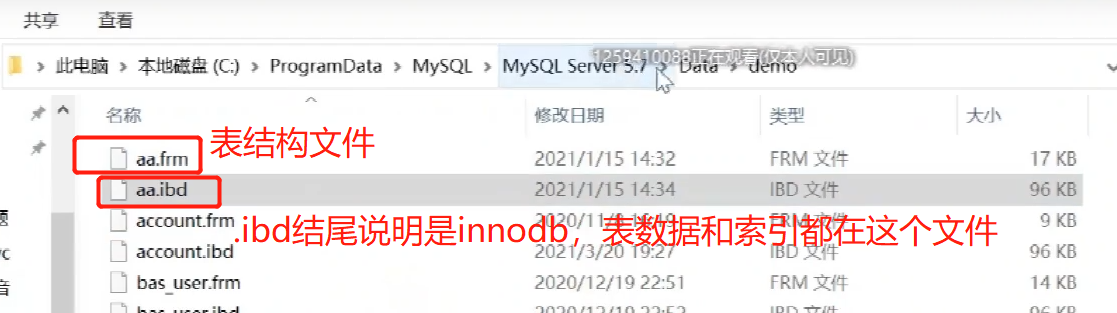
数据库中的存储引擎其实是对使用了该引擎的表进行某种设置,数据库中的表设定了什么存储引擎,那么该表在数据存储方式、数据更新方式、数据查询性能以及是否支持索引等方面就会有不同的“效果”。
MySQL数据库中,引擎主要有:Innodb、MyIASM、ISAM、HEAP、CSV,每种引擎都有不同的功效,但是最常用的还是Innodb、MyIASM这两种,这两种中引擎最常用还是Innodb。
二、为什么最常用的数据库存储引擎是Innodb
Innodb存储引擎提供了事务安全的支持、回滚、行级锁,提高并发量。正是这些特性使得Innodb存储引擎成为最常用的存储引擎。
三、MyISAM和InnoDB的区别
3.1、索引的区别
(1)MyISAM存储引擎的索引
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。通过地址可以快速的获取到对应的记录。并且主键索引和辅助索引没有任何结构上的区别,唯一不同的是辅助索引 的key值可以重复,不具有唯一性。myISAM不存在回表查找。
主键索引的结构
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。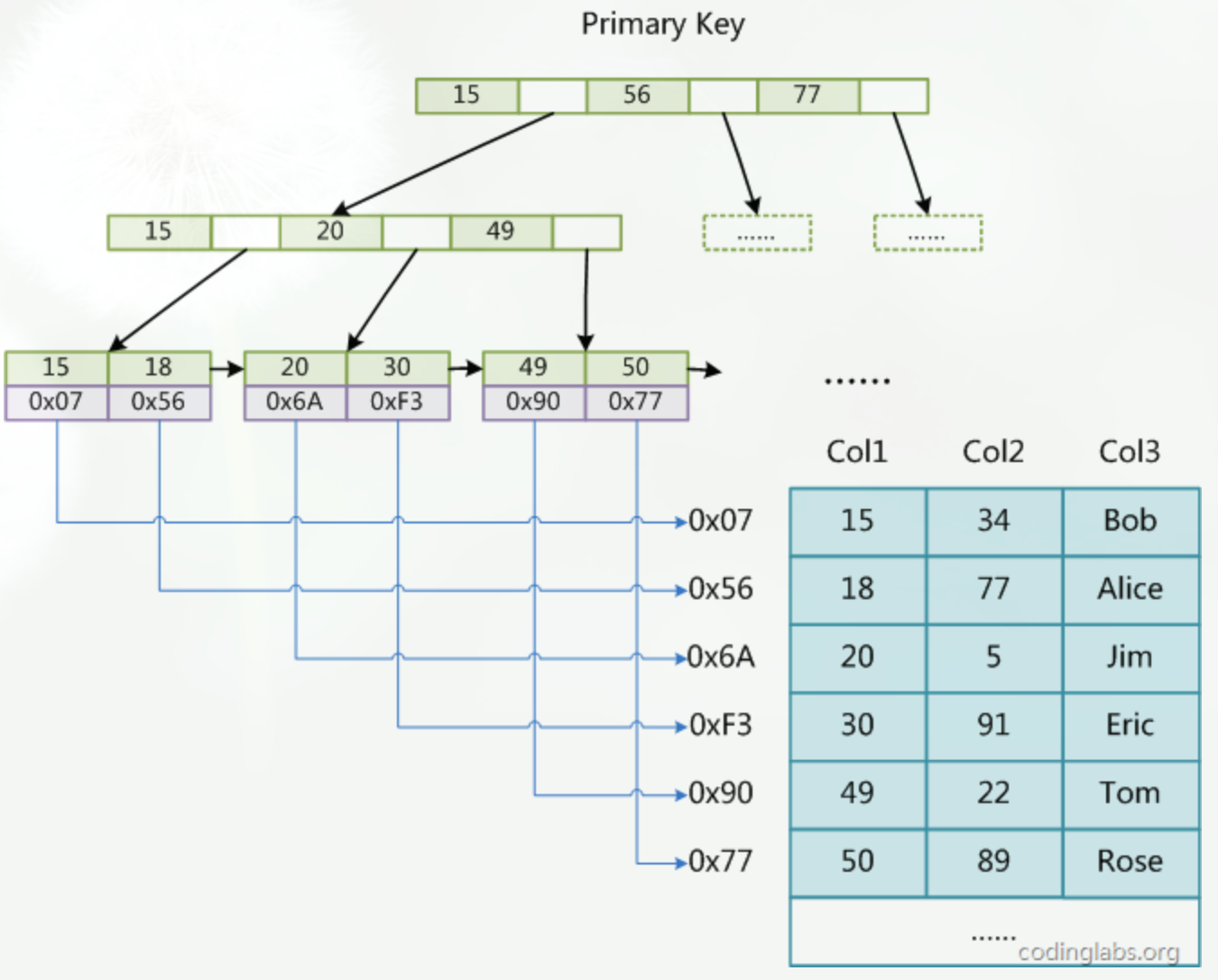
辅助索引的数据结构
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。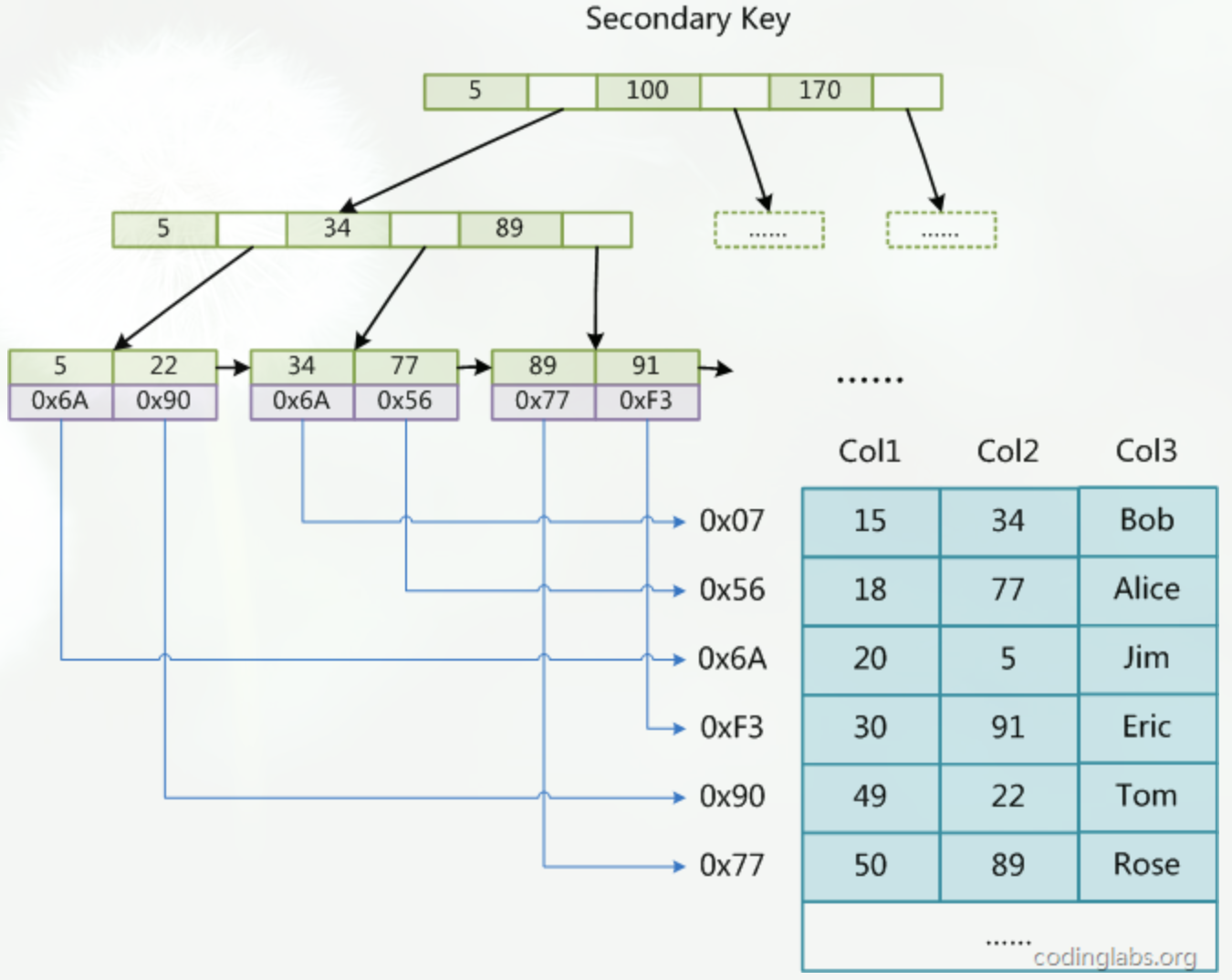
(2)InnoDB存储引擎的索引
相比于MyISAM,InnoDB存储引擎的叶子节点存储数据本身,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引,所以必须有主键,如果没有显示定义,自动为生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。而辅助索引的叶子节点存放了主键值,主键值越大索引就越大,在查询的时候需要先找到主键值在去主索引上去查找数据。
主键索引的结构
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
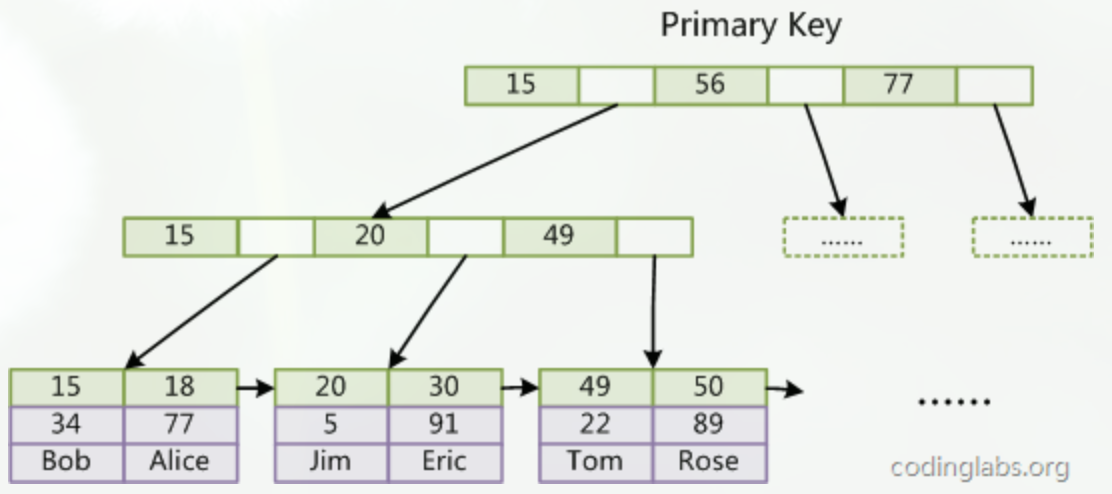
辅助索引的结构
InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引: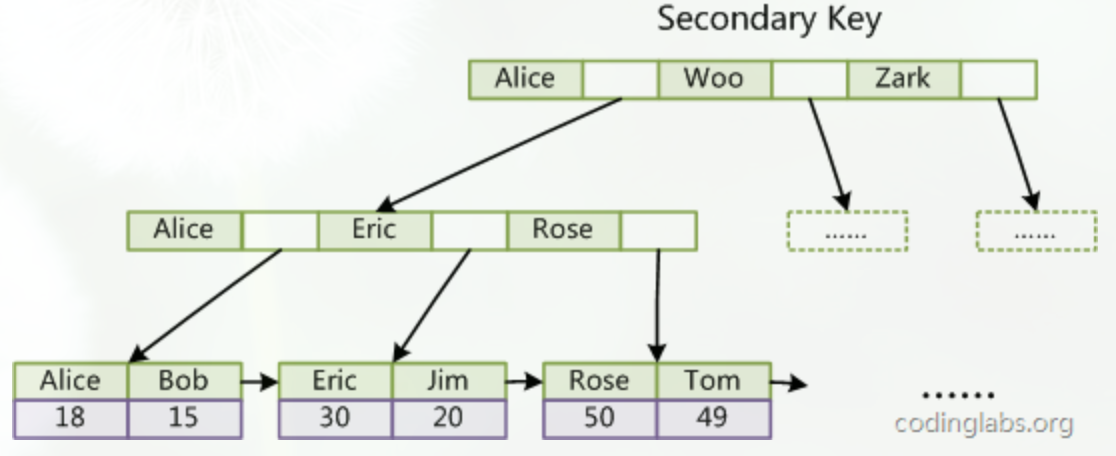
(3)MyISAM和InnoDB关于索引的区别
一是主索引的区别,InnoDB的数据文件本身就是索引文件。而MyISAM的索引和数据是分开的。
二是辅助索引的区别:InnoDB的辅助索引data域存储相应记录主键的值而不是地址。而MyISAM的辅助索引和主索引没有多大区别。因此MyISAM辅助索引没有回表操作。
3.2、其他的区别
MyISAM不是事务安全的,而且不支持外键。InnoDB:支持事务安全的引擎,支持外键、行锁、事务是他的最大特点。如果有大量的update和insert,建议使用InnoDB。由于锁的粒度小,写操作是不会锁定全表的,所以特别是针对多个并发和QPS较高的情况。
1、大容量的数据集时趋向于选择Innodb。因为它支持事务处理和故障的恢复。Innodb可以利用数据日志来进行数据的恢复。主键的查询在Innodb也是比较快的。
2、大批量的插入语句时(这里是INSERT语句)在MyIASM引擎中执行的比较的快,但是UPDATE语句在Innodb下执行的会比较的快,尤其是在并发量大的时候。
四、InnoDB的体系结构
(1)Innodb存储引擎主要包括内存池以及后台线程。
Innodb的数据以页的形式存储在磁盘,因此采用内存作为缓存页数据。
- 内存池:多个内存块组成一个内存池,主要维护进程/线程的内部数据、缓存磁盘数据,修改文件前先修改内存、redo log(重做日志)。
- 后台线程:刷新内存池中的数据(插入更新数据)到磁盘中。
- 缓冲池
- 读页数据时,先将磁盘上的页数据“FIX”到缓冲池,下次读即可直接从缓冲池中读。
- 修改数据时,先修改缓冲池中的页数据,然后刷新到磁盘,并不是每次都刷新而是通过Checkpoint机制刷新到磁盘。
- 数据页类型:索引页、数据页、undo页、插入缓冲(insert buffer)、自适应哈希索引、锁信息、数据字典信息等
- 缓存池通过LRU算法管理。
(2)redo log buffer(重做日志缓存)
redo log先都写入该buffer,而后按一定频率刷新到磁盘(1s/次),默认8M。其刷到磁盘主要一下几个情况:
- Master Thread每秒执行一次。
- 事物提交时。
- redo log buffer剩余空间小于1/2。
redo log 日志在数据库意外丢失数据时可以恢复数据。主要备份数据库的物理改变。
binlog日志(二进制日志)功能也可以进行数据恢复(定时全备份+binlog日志恢复增量数据部分),主要备份数据库的逻辑改变。
(3)线程
- Master Thread
负责将缓存池中的数据异步刷新到磁盘,包括脏页。合并插入缓存(INSERT BUFFER)、UNDO页的回收等。
- IO Thread
Innodb中大量使用AIO处理写请求,IO Thread则主要处理这些请求的回调,包括write、read、insert buffer和log IO Thread。
- Purge Thread
主要用来回收undo log(回滚日志),Innodb1.1之前由Master Thread负责。
- Page Cleaner Thread
清理已提交事物的UNDO log。
- Checkpoint
事务型数据库一般采用Write Ahead Log策略,当事物提交时先写redo log而后修改内存中的页。当数据库宕机对于还未写入磁盘的修改数据可以通过redo log恢复。Checkpoint作用在于保证该点之前的所有修改的页均已刷新到磁盘,这之前的redo log在恢复数据时可以不需要了。
- (4)Innodb关键特性
- 插入缓冲
- 当插入数据需要更新非聚集索引时,如果每次都更新则需要进行多次随机IO,因此将这些值写入缓冲对相同页的进行合并提高IO性能。
- 插入非聚集索引时,先判断该索引页是否在缓冲池中,在则直接插入。否则写入到Insert Buffer对象。
- 条件:二级索引,索引不能是unique(因为如果是unique则必须保证唯一性,此时得检查所有索引页,还是随机IO了)
- Change Buffer:包括Insert Buffer、Delete Buffer、Purge Buffer,update操作包括将记录标记为已删除和真正将记录删除两个过程,对应后两个Buffer。
- Insert Buffer内部是一颗B+树
- Merge Insert Buffer三种情况:
- 对应的索引页被读入缓冲池。
- 对应的索引页的可用空间小于1/32,则强制进行合并。
- Master Thread中的合并插入缓冲。
- 两次写
在对脏页刷新到磁盘时,如果某一页还没写完就宕机,此时该页数据已经混乱无法通过redo实现恢复。innodb提供了doublewrite机制,其刷新脏页步骤如下:
1. 先将脏页数据复制到doublewrite buffer中(2MB内存) 2. 将doublewrite buffer分两次,每次1MB写入到doublewrite磁盘(2MB)中。 3. 马上同步脏页数据到磁盘。对于数据混乱的页则可以从doublewrite中读取到,该页写到共享表空间。
- 自适应哈希索引
InnoDB存储引擎会监控对表上索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立哈希索引,所以称之为自适应(adaptive) 的。自适应哈希索引通过缓冲池的B+树构造而来,因此建立的速度很快。而且不需要将整个表都建哈希索引,InnoDB存储引擎会自动根据访问的频率和模式 来为某些页建立哈希索引。
B树和B+树的区别
众所周知,MySQL的索引使用了B+树的数据结构。那么为什么不用B树呢?
先看一下B树和B+树的区别。
1.B树
维基百科对B树的定义为“在计算机科学中,B树(B-tree)是一种树状数据结构,它能够存储数据、对其进行排序并允许以O(log n)的时间复杂度运行进行查找、顺序读取、插入和删除的数据结构。B树,概括来说是一个节点可以拥有多于2个子节点的二叉查找树。与自平衡二叉查找树不同,B-树为系统最优化大块数据的读和写操作。B-tree算法减少定位记录时所经历的中间过程,从而加快存取速度。普遍运用在数据库和文件系统。”
B 树可以看作是对2-3查找树的一种扩展,即他允许每个节点有M-1个子节点。
1.1定义
根节点至少有两个子节点
每个节点有M-1个key,并且以升序排列
位于M-1和M key的子节点的值位于M-1 和M key对应的Value之间
其它节点至少有M/2个子节点
下图是一个M=4 阶的B树:
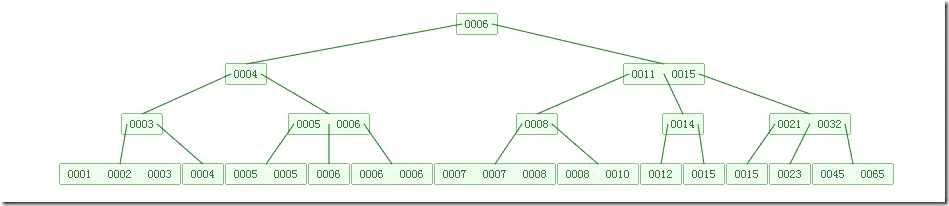
M=4的B树
可以看到B树是2-3树的一种扩展,他允许一个节点有多于2个的元素。
B树的插入及平衡化操作和2-3树很相似,这里就不介绍了。下面是往B树中依次插入
6 10 4 14 5 11 15 3 2 12 1 7 8 8 6 3 6 21 5 15 15 6 32 23 45 65 7 8 6 5 4 的演示动画:

btreebuild
2.B+树
B+树是对B树的一种变形树,它与B树的差异在于:
有k个子结点的结点必然有k个关键码。
非叶结点仅具有索引作用,跟记录有关的信息均存放在叶结点中。
树的所有叶结点构成一个有序链表,可以按照关键码排序的次序遍历全部记录。
如下图是一个B+树:
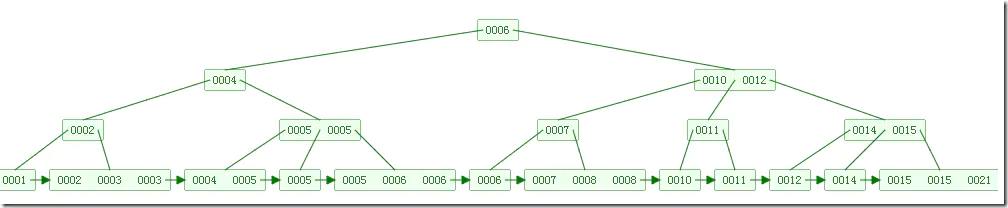
M=4的B+树
下图是B+树的建立过程:
Bplustreebuild.gif
B+树和B树的区别
B+树的非叶子结点只包含导航信息,不包含实际的值,所有的叶子结点和相连的节点使用链表相连,便于区间查找和遍历。
B+ 树的优点在于:
IO次数更少:由于B+树在内部节点上不包含数据信息,因此在内存页中能够存放更多的key。 数据存放的更加紧密,具有更好的空间局部性。因此访问叶子节点上关联的数据也具有更好的缓存命中率。
遍历更加方便:B+树的叶子结点都是相链的,因此对整棵树的遍历只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
但是B树也有优点,其优点在于,由于B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此访问也更迅速。下面是B 树和B+树的区别图:
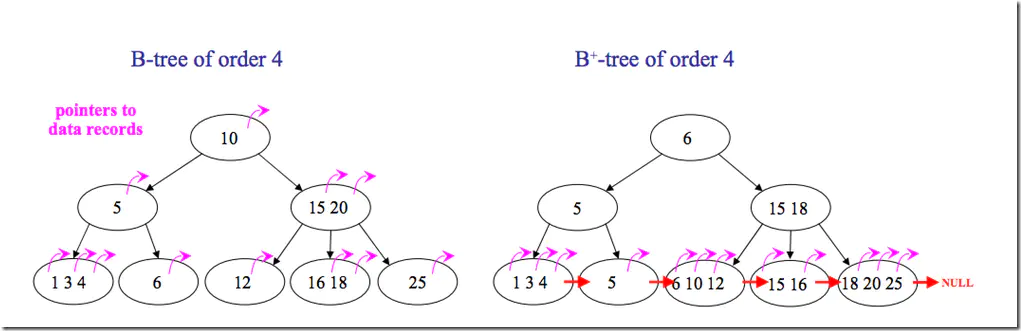
B树和B+树的区别图
为什么MySQL选择B+树做索引
1、 B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
2、B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3、B+树更便于遍历:由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。
4、B+树更适合基于范围的查询:B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。
————————————————
版权声明:本文为CSDN博主「小猫倩倩」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_29563497/article/details/113284907
什么是回表?如何避免回表?
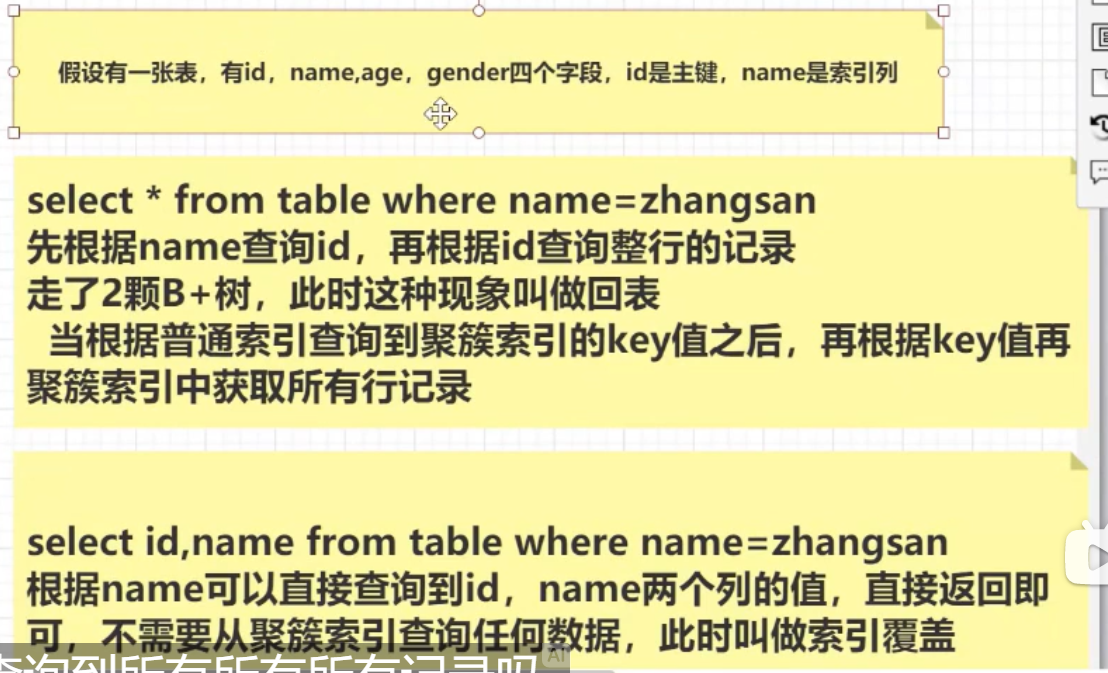
redo log和binlog区别
redo log是属于innoDB层面,binlog属于MySQL Server层面的,这样在数据库用别的存储引擎时可以达到一致性的要求。
redo log是物理日志,记录该数据页更新的内容;binlog是逻辑日志,记录的是这个更新语句的原始逻辑
redo log是循环写,日志空间大小固定;binlog是追加写,是指一份写到一定大小的时候会更换下一个文件,不会覆盖。
binlog可以作为恢复数据使用,主从复制搭建,redo log作为异常宕机或者介质故障后的数据恢复使用。
日志系统主要有redo log(重做日志)和binlog(归档日志)。redo log是InnoDB存储引擎层的日志,binlog是MySQL Server层记录的日志, 两者都是记录了某些操作的日志(不是所有)自然有些重复(但两者记录的格式不同)。
redo log是InnoDB存储引擎层的日志,又称重做日志文件,用于记录事务操作的变化,记录的是数据修改之后的值,不管事务是否提交都会记录下来。在实例和介质失败(media failure)时,redo log文件就能派上用场,如数据库掉电,InnoDB存储引擎会使用redo log恢复到掉电前的时刻,以此来保证数据的完整性。
在一条更新语句进行执行的时候,InnoDB引擎会把更新记录写到redo log日志中,然后更新内存,此时算是语句执行完了,然后在空闲的时候或者是按照设定的更新策略将redo log中的内容更新到磁盘中,这里涉及到WAL即Write Ahead logging技术,他的关键点是先写日志,再写磁盘。
有了redo log日志,那么在数据库进行异常重启的时候,可以根据redo log日志进行恢复,也就达到了crash-safe。
redo log日志的大小是固定的,即记录满了以后就从头循环写。
binlog日志模块
binlog是属于MySQL Server层面的,又称为归档日志,属于逻辑日志,是以二进制的形式记录的是这个语句的原始逻辑,依靠binlog是没有crash-safe能力的
redo log和binlog区别
- redo log是属于innoDB层面,binlog属于MySQL Server层面的,这样在数据库用别的存储引擎时可以达到一致性的要求。
- redo log是物理日志,记录该数据页更新的内容;binlog是逻辑日志,记录的是这个更新语句的原始逻辑
- redo log是循环写,日志空间大小固定;binlog是追加写,是指一份写到一定大小的时候会更换下一个文件,不会覆盖。
- binlog可以作为恢复数据使用,主从复制搭建,redo log作为异常宕机或者介质故障后的数据恢复使用。
一条更新语句执行的顺序
update T set c=c+1 where ID=2;
- 执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
这个update语句的执行流程图,图中浅色框表示是在 InnoDB 内部执行的,深色框表示是在执行器中执行的。
——————————————————————————
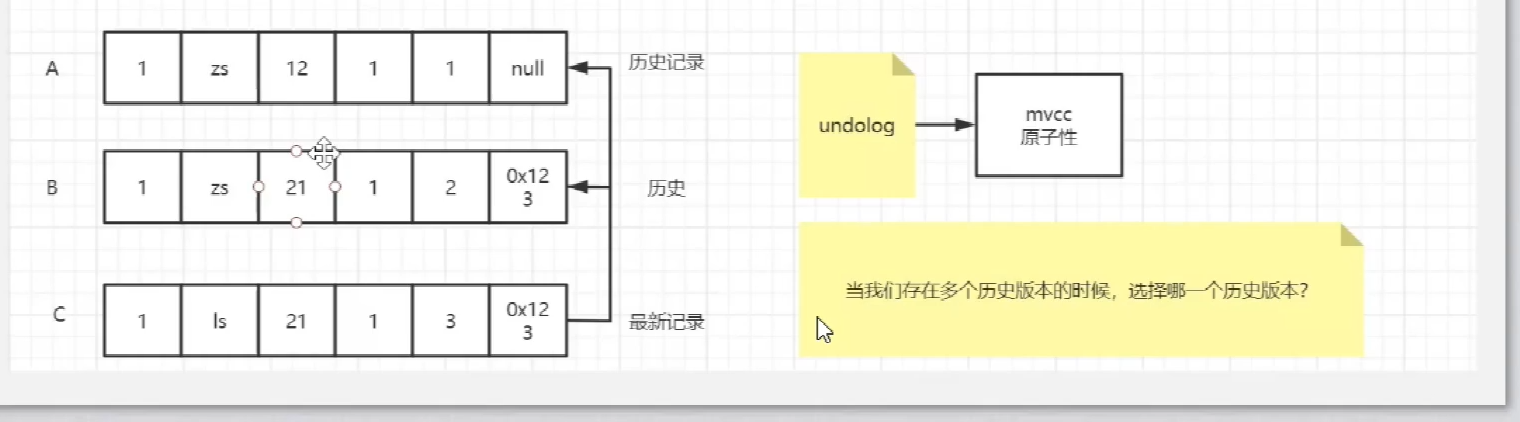
innodb事务日志包括redo log和undo log。redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作。
undo log不是redo log的逆向过程,其实它们都算是用来恢复的日志:
1.redo log通常是物理日志,记录的是数据页的物理修改,而不是某一行或某几行修改成怎样怎样,它用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置)。
2.undo用来回滚行记录到某个版本。undo log一般是逻辑日志,根据每行记录进行记录。
mysql索引失效情况

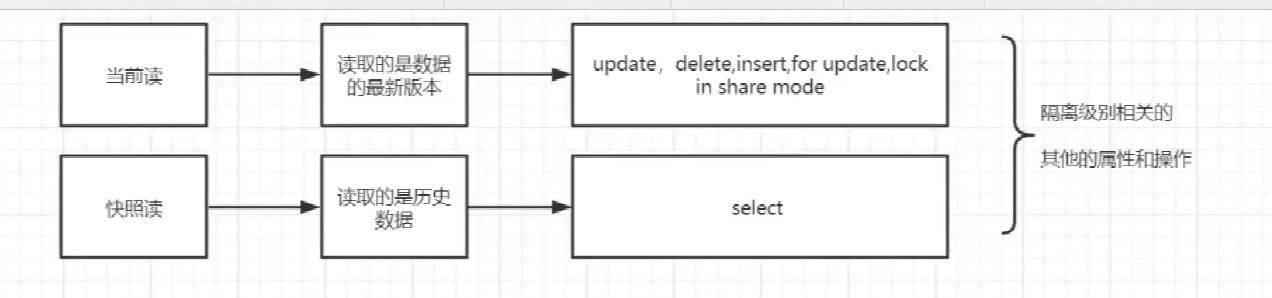
共享锁和排它锁
排他锁
(Exclusive Locks,简称 X 锁),又称为写锁或独占锁,是一种基本的锁类型。如果事务 T1对数据对象 O1加上了排他锁,那么在整个加锁期间,只允许事务 T1对 O1进行读取和更新操作,其他任何事务都不能再对这个数据对象进行任何类型的操作——直到T1释放了排他锁
共享锁
共享锁(Shared Locks,简称S锁),又称为读锁,同样是一种基本的锁类型。
如果事务T1对数据对象O1加上了共享锁,那么当前事务只能对O1进行读取操作,其他事务也只能对这个数据对象加共享锁——直到该数据对象上的所有共享锁都被释放。
共享锁和排他锁最根本的区别在于,加上排他锁后,数据对象只对一个事务可见,而加上共享锁后,数据对所有事务都可见。

若有收获,就点个赞吧
0 人点赞
