redis的持久化机制
一、持久化流程
(1)客户端向服务端发送写操作(数据在客户端的内存中)。
(2)数据库服务端接收到写请求的数据(数据在服务端的内存中)。
(3)服务端调用write这个系统调用,将数据往磁盘上写(数据在系统内存的缓冲区中)。
(4)操作系统将缓冲区中的数据转移到磁盘控制器上(数据在磁盘缓存中)。
(5)磁盘控制器将数据写到磁盘的物理介质中(数据真正落到磁盘上)。
这5个过程是在理想条件下一个正常的保存流程,但是在大多数情况下,我们的机器等等都会有各种各样的故障,这里划分了两种情况:
(1)Redis数据库发生故障,只要在上面的第三步执行完毕,那么就可以持久化保存,剩下的两步由操作系统替我们完成。
(2)操作系统发生故障,必须上面5步都完成才可以。
在这里只考虑了保存的过程可能发生的故障,其实保存的数据也有可能发生损坏,需要一定的恢复机制,不过在这里就不再延伸了。现在主要考虑的是redis如何来实现上面5个保存磁盘的步骤。它提供了两种策略机制,也就是RDB和AOF。
二、RDB机制
RDB其实就是把数据以快照的形式保存在磁盘上。什么是快照呢,你可以理解成把当前时刻的数据拍成一张照片保存下来。
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。
在我们安装了redis之后,所有的配置都是在redis.conf文件中,里面保存了RDB和AOF两种持久化机制的各种配置。
既然RDB机制是通过把某个时刻的所有数据生成一个快照来保存,那么就应该有一种触发机制,是实现这个过程。对于RDB来说,提供了三种机制:save、bgsave、自动化。我们分别来看一下
1、save触发方式
该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。具体流程如下: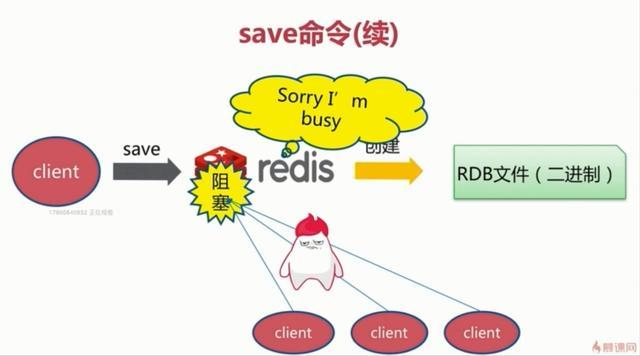
执行完成时候如果存在老的RDB文件,就把新的替代掉旧的。我们的客户端可能都是几万或者是几十万,这种方式显然不可取。
2、bgsave触发方式
执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。具体流程如下: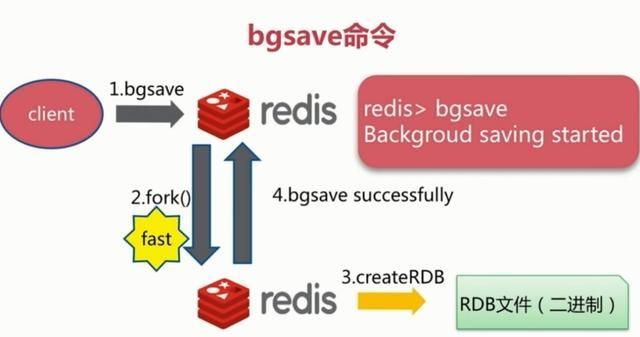
具体操作是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。
3、自动触发(配置文件才会触发,上面两种需要敲命令)
自动触发是由我们的配置文件来完成的。在redis.conf配置文件中,里面有如下配置,我们可以去设置:
①save:这里是用来配置触发 Redis的 RDB 持久化条件,也就是什么时候将内存中的数据保存到硬盘。比如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。
默认如下配置:
#表示900 秒内如果至少有 1 个 key 的值变化,则保存save 900 1#表示300 秒内如果至少有 10 个 key 的值变化,则保存save 300 10#表示60 秒内如果至少有 10000 个 key 的值变化,则保存save 60 10000
不需要持久化,那么你可以注释掉所有的 save 行来停用保存功能。
②stop-writes-on-bgsave-error :默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了
③rdbcompression ;默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。
④rdbchecksum :默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
⑤dbfilename :设置快照的文件名,默认是 dump.rdb
⑥dir:设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。
我们可以修改这些配置来实现我们想要的效果。因为第三种方式是配置的,所以我们对前两种进行一个对比: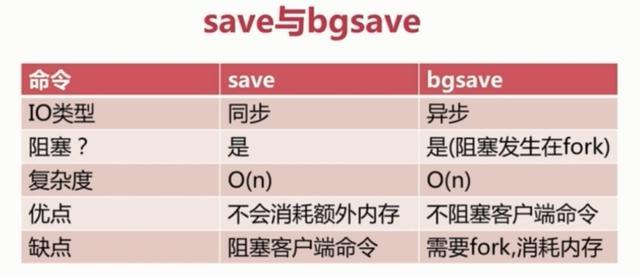
4、RDB 的优势和劣势
①、优势
(1)RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
(2)生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
(3)RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
②、劣势
RDB快照是一次全量备份,存储的是内存数据的二进制序列化形式,存储上非常紧凑。当进行快照持久化时,会开启一个子进程专门负责快照持久化,子进程会拥有父进程的内存数据,父进程修改内存子进程不会反应出来,所以在快照持久化期间修改的数据不会被保存,可能丢失数据。
三、AOF机制
全量备份总是耗时的,有时候我们提供一种更加高效的方式AOF,工作机制很简单,redis会将每一个收到的写命令都通过write函数追加到文件中。通俗的理解就是日志记录。
1、持久化原理
他的原理看下面这张图: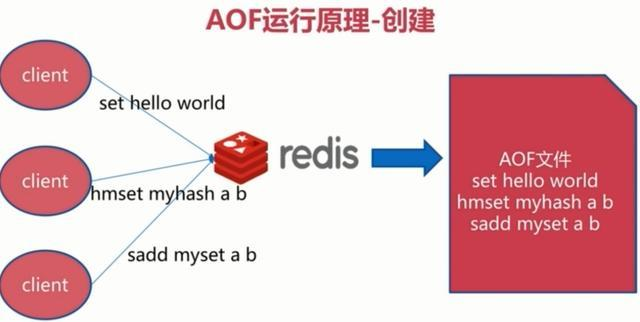
每当有一个写命令过来时,就直接保存在我们的AOF文件中。
2、文件重写原理
AOF的方式也同时带来了另一个问题。持久化文件会变的越来越大。为了压缩aof的持久化文件。redis提供了bgrewriteaof命令。将内存中的数据以命令的方式保存到临时文件中,同时会fork出一条新进程来将文件重写。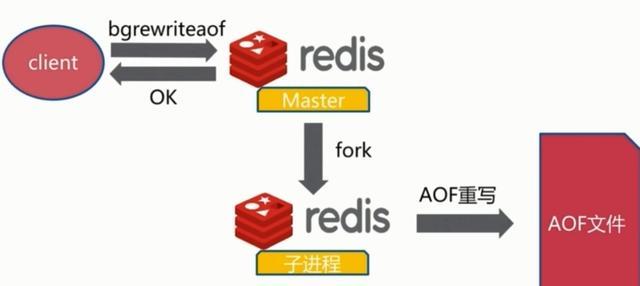
重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
3、AOF也有三种触发机制
(1)每修改同步always:同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
(2)每秒同步everysec:异步操作,每秒记录 如果一秒内宕机,有数据丢失
(3)不同no:从不同步
在配置文件里长啥样:
appendfsync always #每次有数据修改发生时都会写入AOF文件。appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。appendfsync no #从不同步。高效但是数据不会被持久化(数据不一致)。

4、优点
(1)AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。(2)AOF日志文件没有任何磁盘寻址的开销,写入性能非常高,文件不容易破损。
(3)AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。
(4)AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据
5、缺点
(1)对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
(2)AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的
(3)以前AOF发生过bug,就是通过AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。
四、RDB和AOF到底该如何选择
选择的话,两者加一起才更好。因为两个持久化机制你明白了,剩下的就是看自己的需求了,需求不同选择的也不一定,但是通常都是结合使用。有一张图可供总结: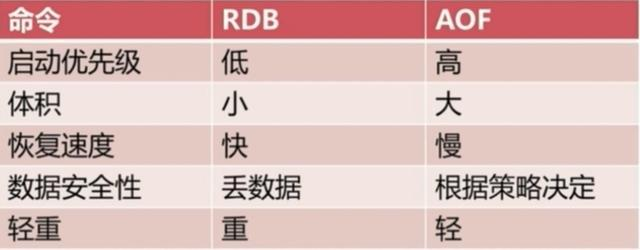
对比了这几个特性,剩下的就是看自己了。
redis五种数据类型
1.redis的5种数据类型:
string 字符串(可以为整形、浮点型和字符串,统称为元素)
list 列表(实现队列,元素不唯一,先入先出原则)
set 集合(各不相同的元素)
hash hash散列值(hash的key必须是唯一的)
sort set 有序集合
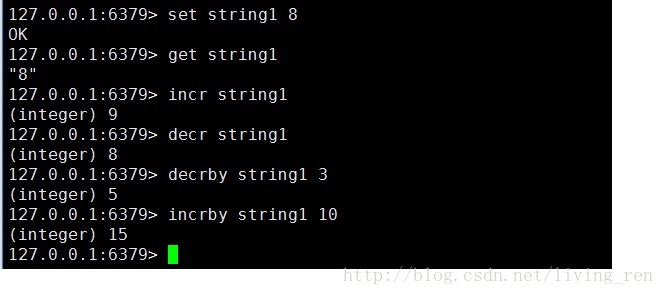
2.string类型的常用命令:
自加:incr
自减:decr
加: incrby
减: decrby
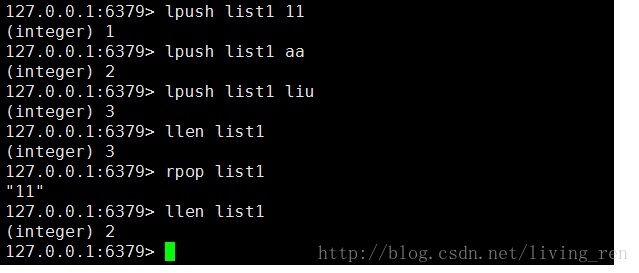
3.list类型支持的常用命令:
lpush:从左边推入
lpop:从右边弹出
rpush:从右变推入
rpop:从右边弹出
llen:查看某个list数据类型的长度
4.set类型支持的常用命令:
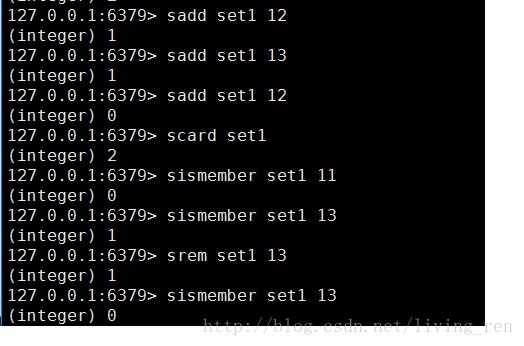
sadd:添加数据
scard:查看set数据中存在的元素个数
sismember:判断set数据中是否存在某个元素
srem:删除某个set数据中的元素
5.hash数据类型支持的常用命令:
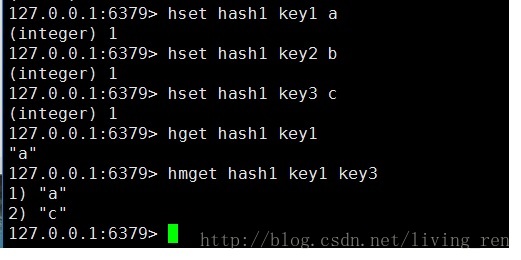
hset:添加hash数据
hget:获取hash数据
hmget:获取多个hash数据
6.sort set和hash很相似,也是映射形式的存储:
zadd:添加
zcard:查询
zrange:数据排序 数组下标 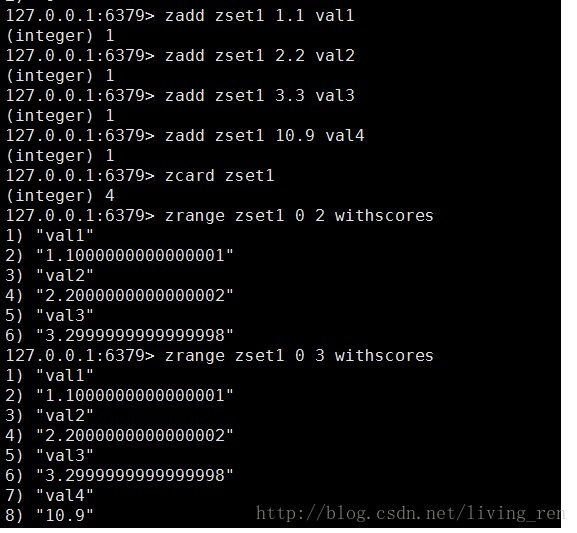
————————————————
版权声明:本文为CSDN博主「living_ren」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/living_ren/article/details/79166436
布隆过滤器原理
布隆过滤器是一个 bit 向量或者说 bit 数组,如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数(看你设置的误差率,误差率越小,hash函数越多,速度越慢)生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 把0改成1;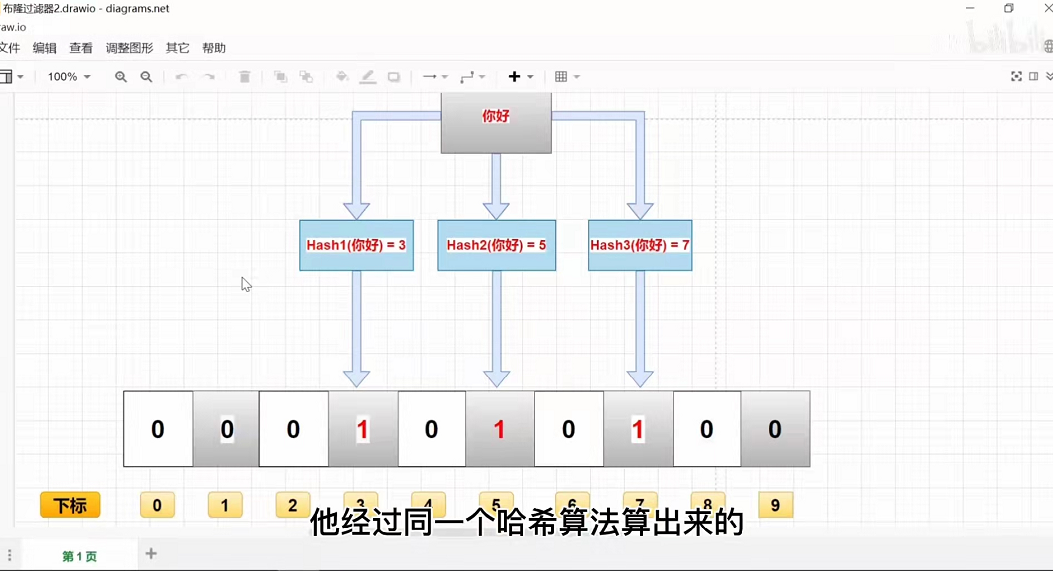
如果布隆过滤器告诉你存在,则可能不存在;如果告诉你不存在,则一定不存在;
以下是应用demo,redis给我们提供了封装类;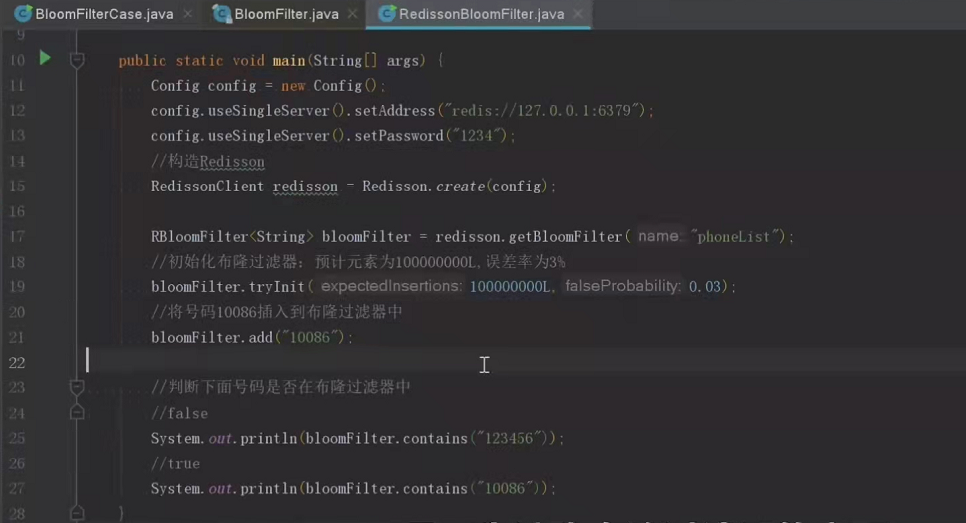
图片来自b站 :IT老哥
另外,较好文章 https://zhuanlan.zhihu.com/p/43263751
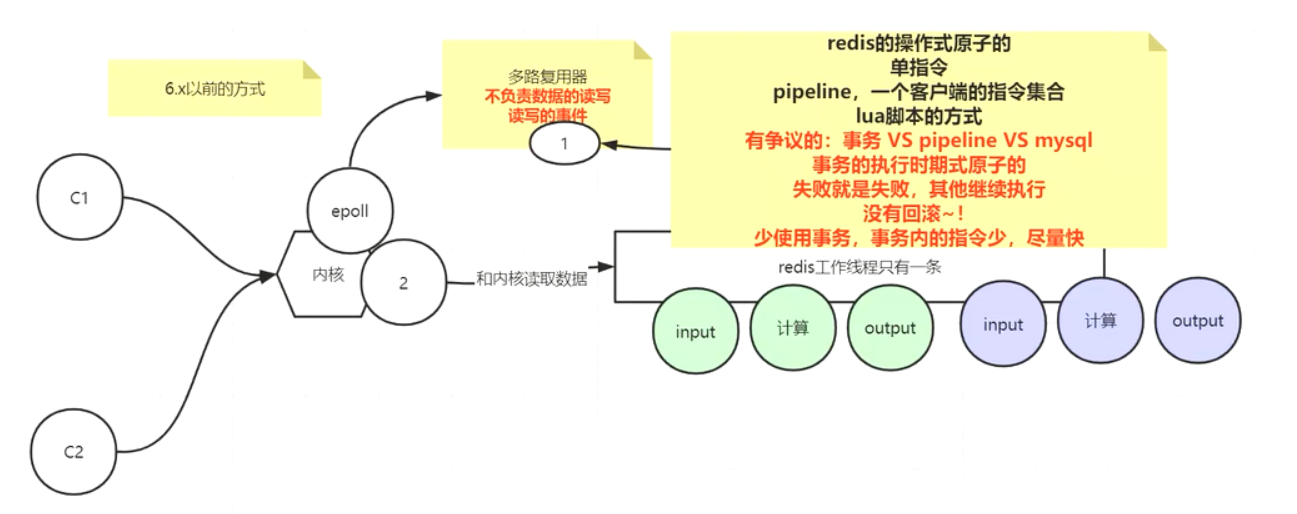
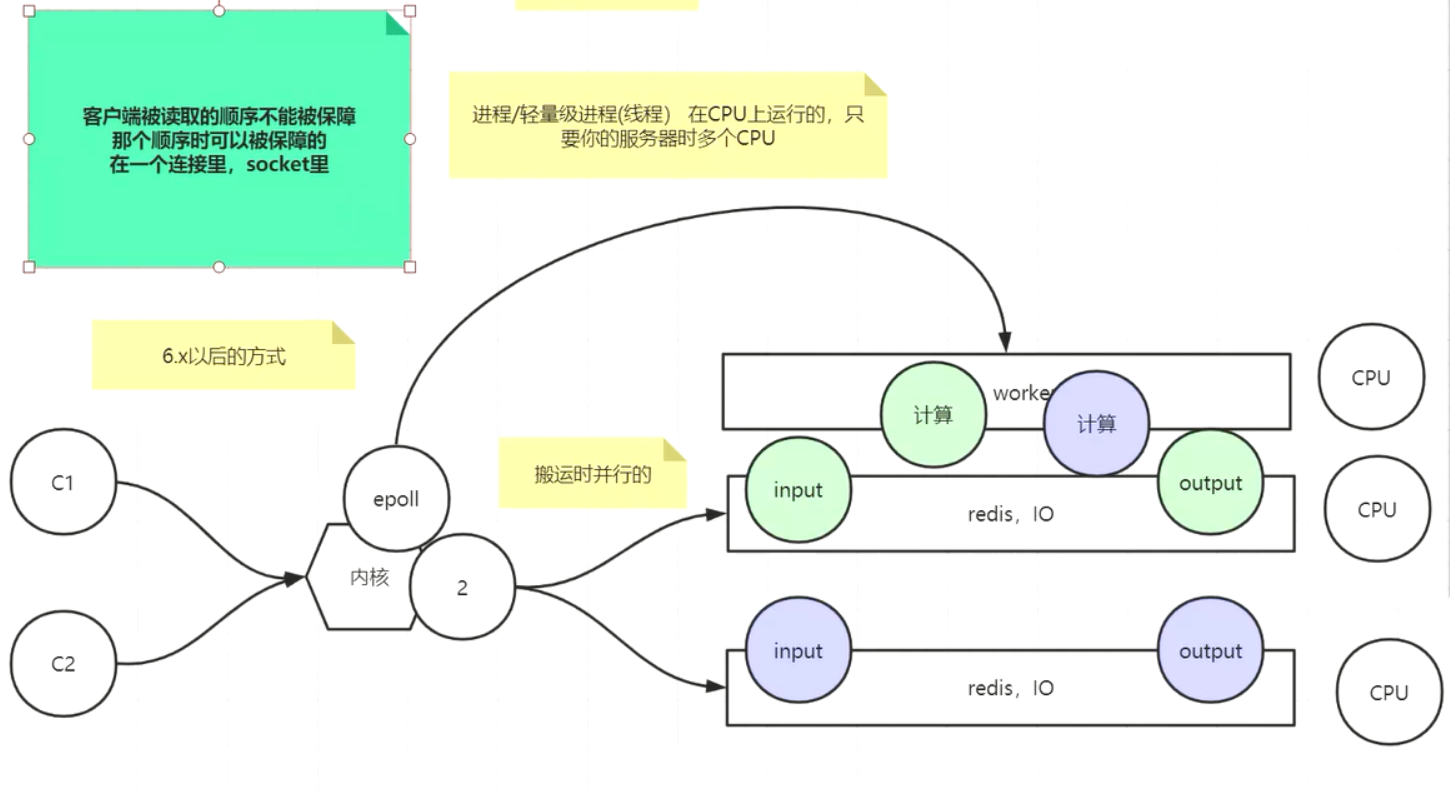
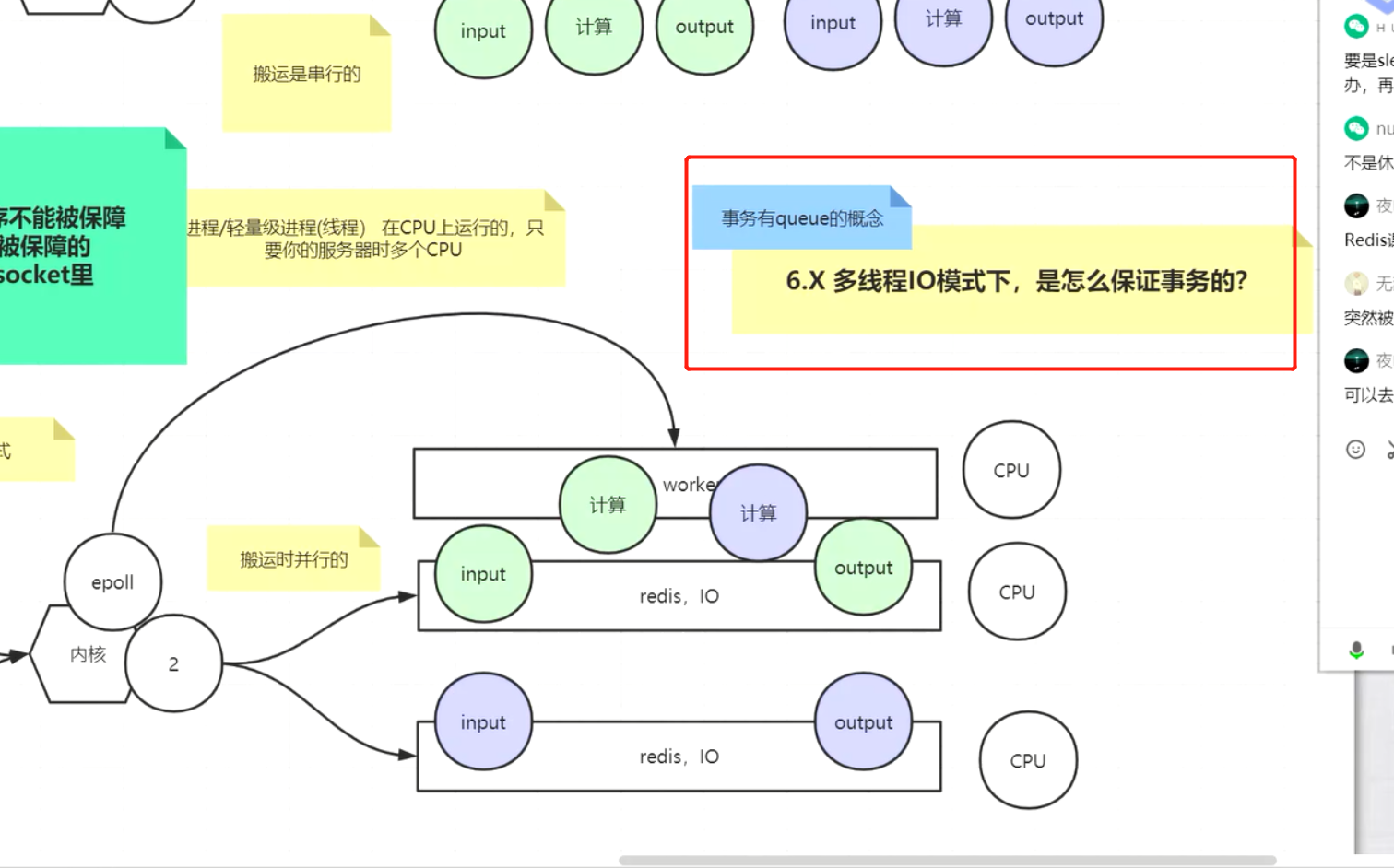
redis是单线程的吗?

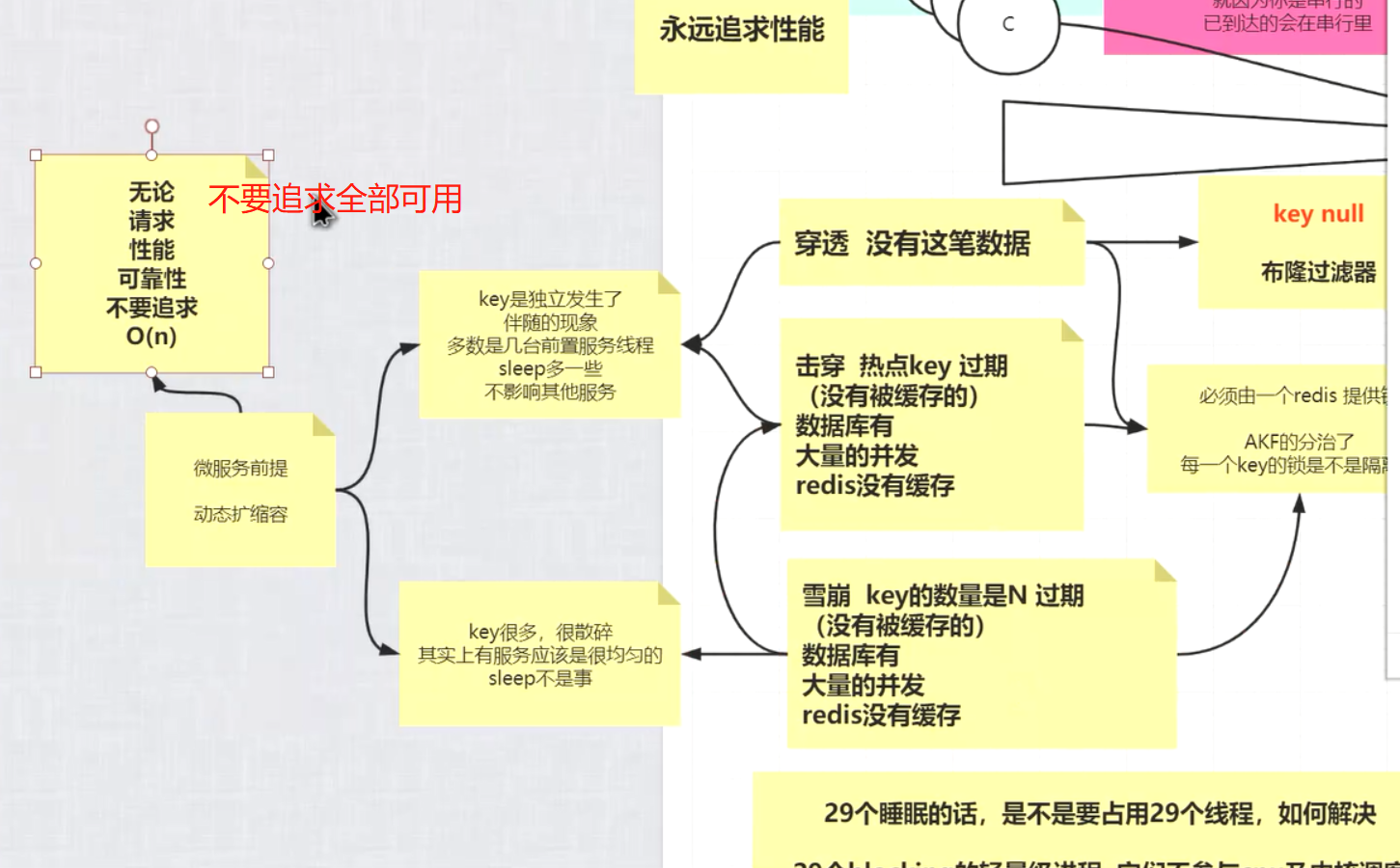
redis穿透,击穿,雪崩
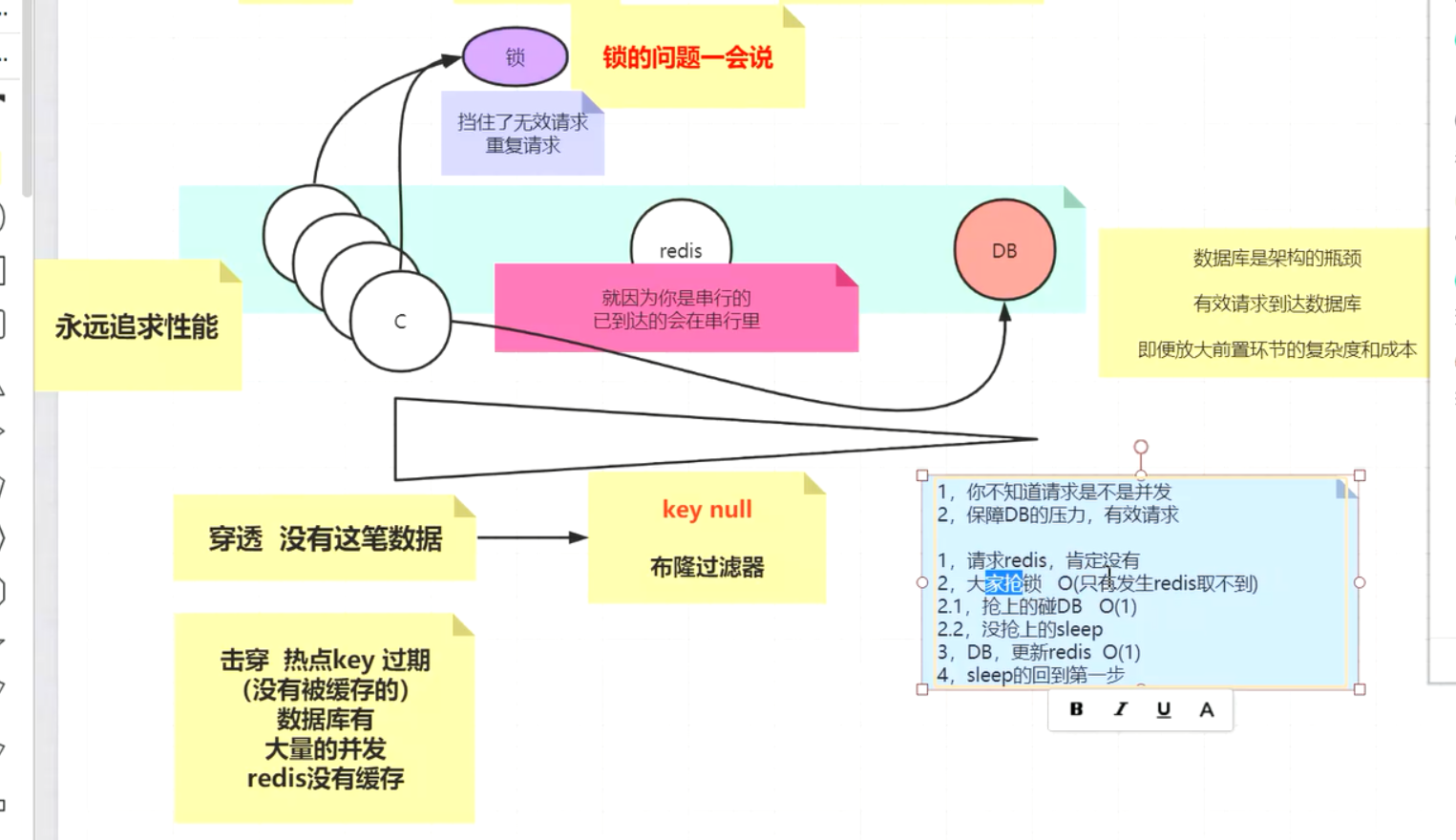
击穿是雪崩子集 雪崩是大面积key都没命中 击穿是局部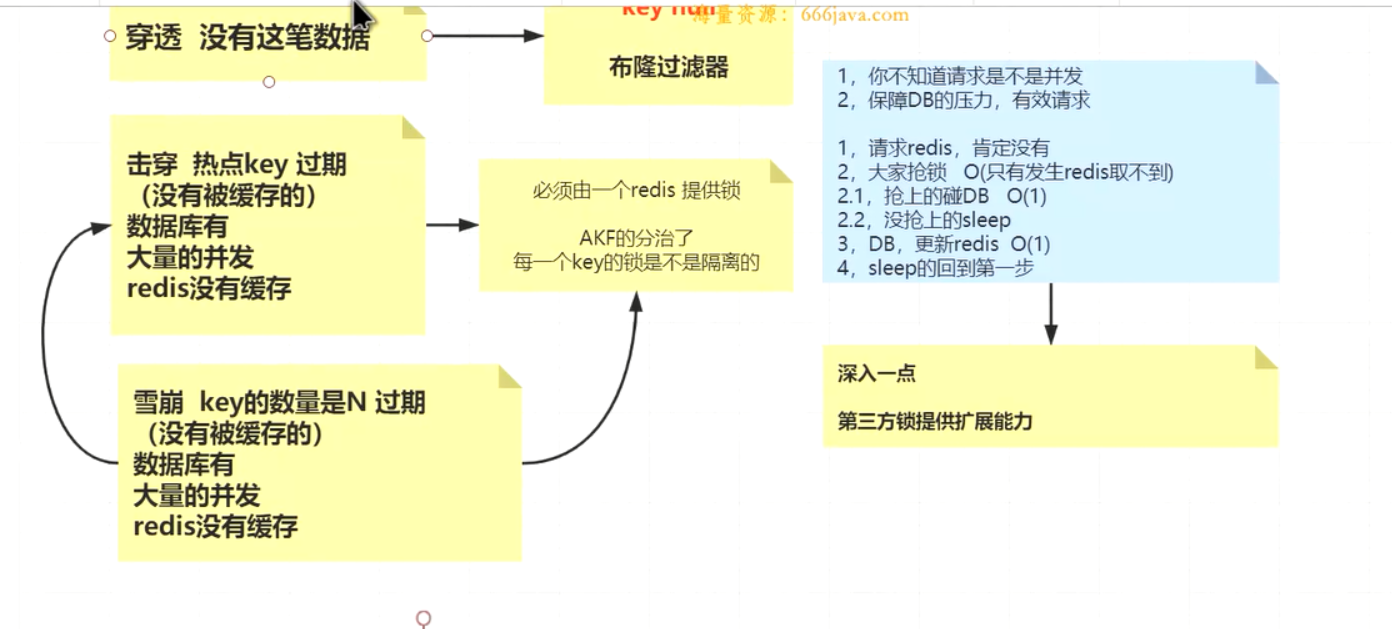

不仅是面试 面试中多周旋 体现出自己的架构设计思想
缓存如何回收的

缓存如何淘汰的

全空间:
redis.config文件里设置: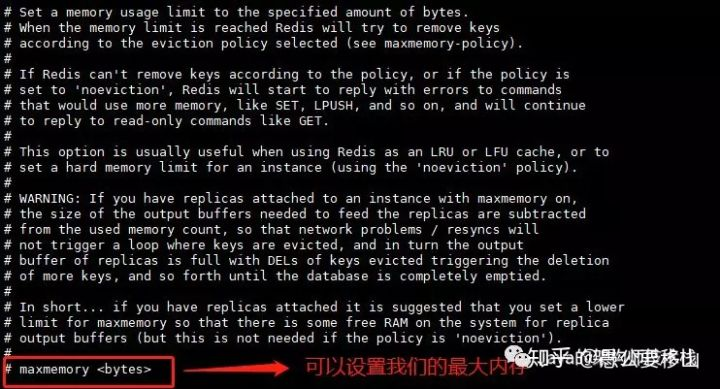
不同于之前的版本,redis5.0 为我们提供了八个不同的内存置换策略。很早之前提供了6种。
(1)volatile-lru:从已设置过期时间的数据集中挑选最近最少使用的数据淘汰。
(2)volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰。
(3)volatile-random :从已设置过期时间的数据集中任意选择数据淘汰。
(4)volatile-lfu :从已设置过期时间的数据集挑选使用频率最低的数据淘汰。
(5)allkeys-lru:从数据集中挑选最近最少使用的数据淘汰
(6)allkeys-lfu :从数据集中挑选使用频率最低的数据淘汰。
(7)allkeys-random :从数据集(server.db[i].dict)中任意选择数据淘汰
(8) no-enviction(驱逐):禁止驱逐数据,这也是默认策略。意思是当内存不足以容纳新入数据时, 新写入操作就会报错,请求可以继续进行,线上任务也不能持续进行,采用no-enviction策略可以保证数 据不被丢失。 这八种大体上可以分为4中,lru、lfu、random、ttl。
如何缓存预热

热数据:根据业务预测;根据日志预测;
如何保证缓存和数据库一致性
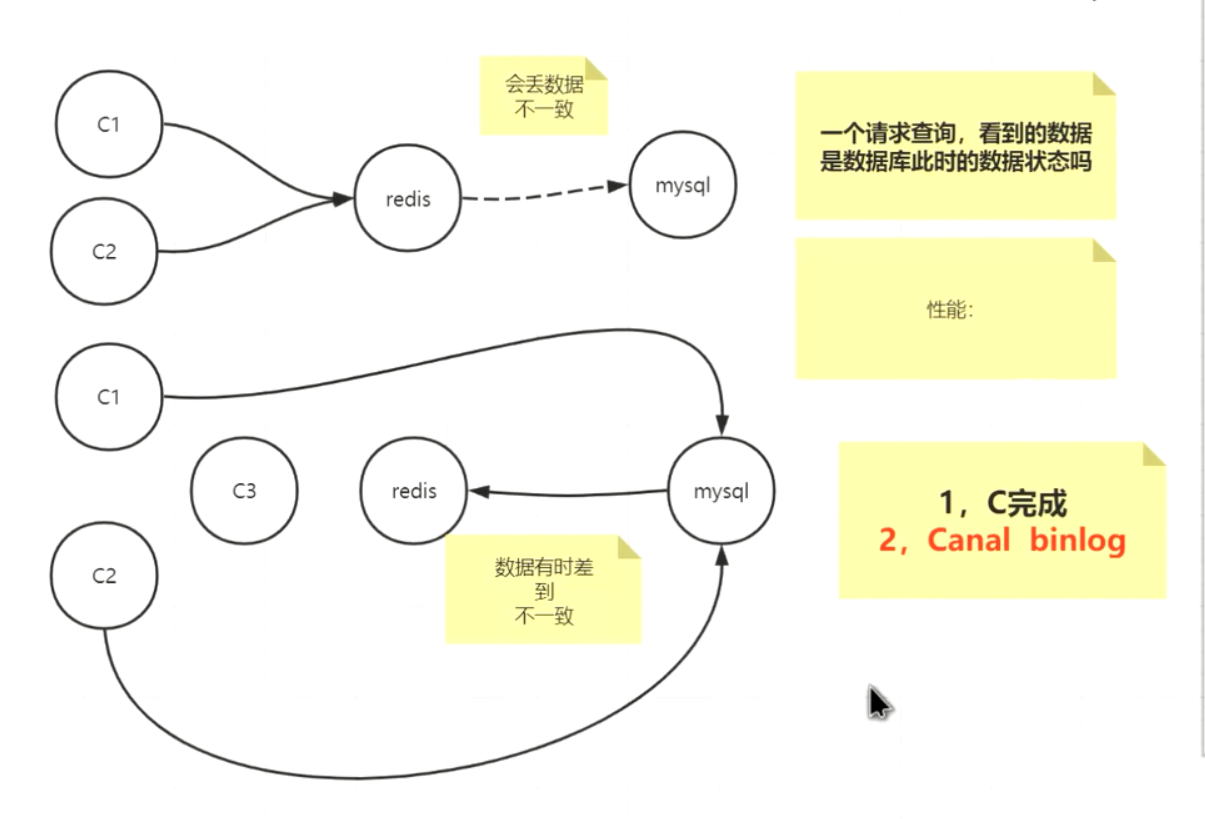
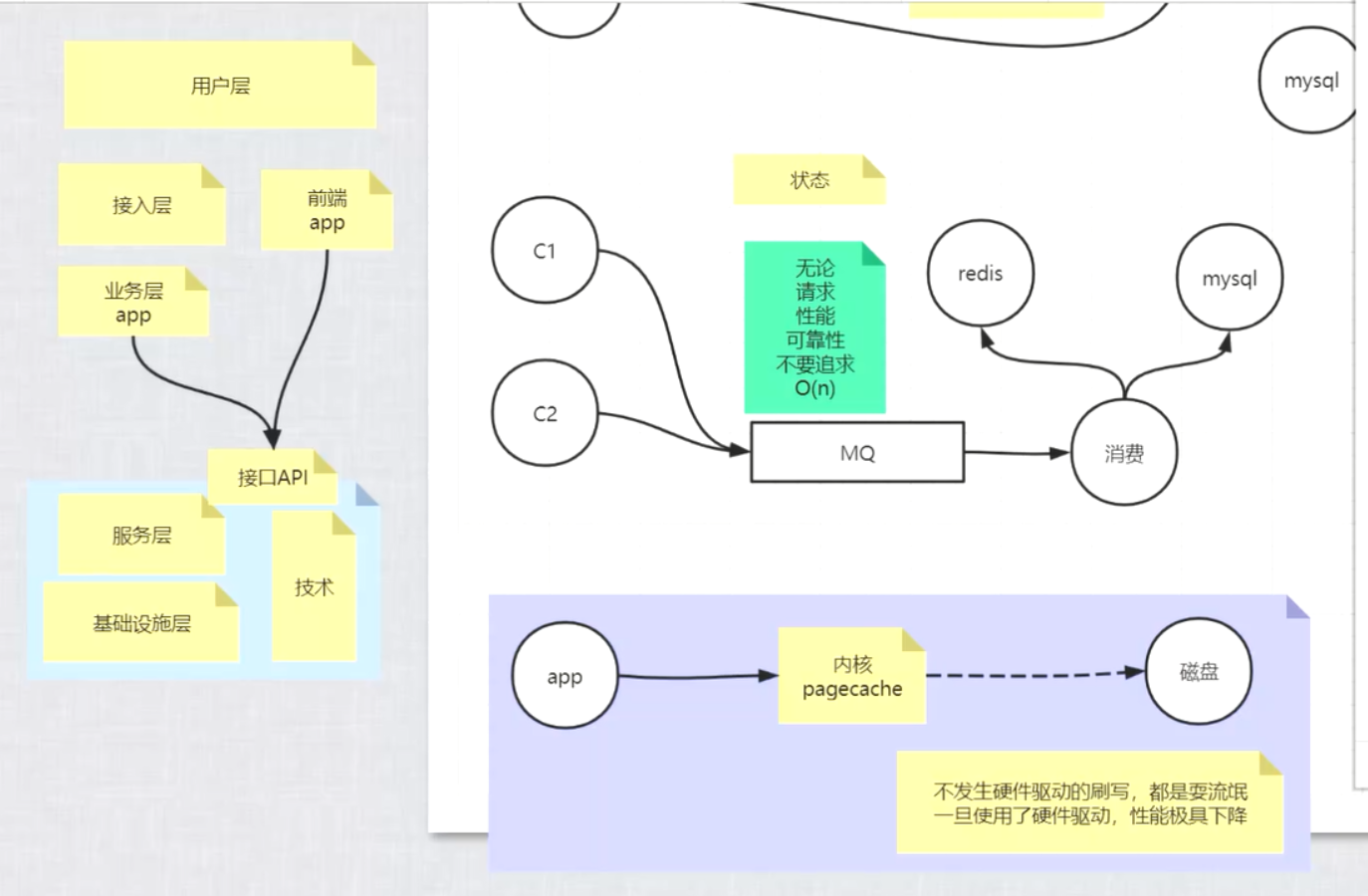

描述redis主从同步

redis持久化方式

redis持久化原理

fork+copy on write
详细见“redis的持久化机制”。
为什么使用setnx?

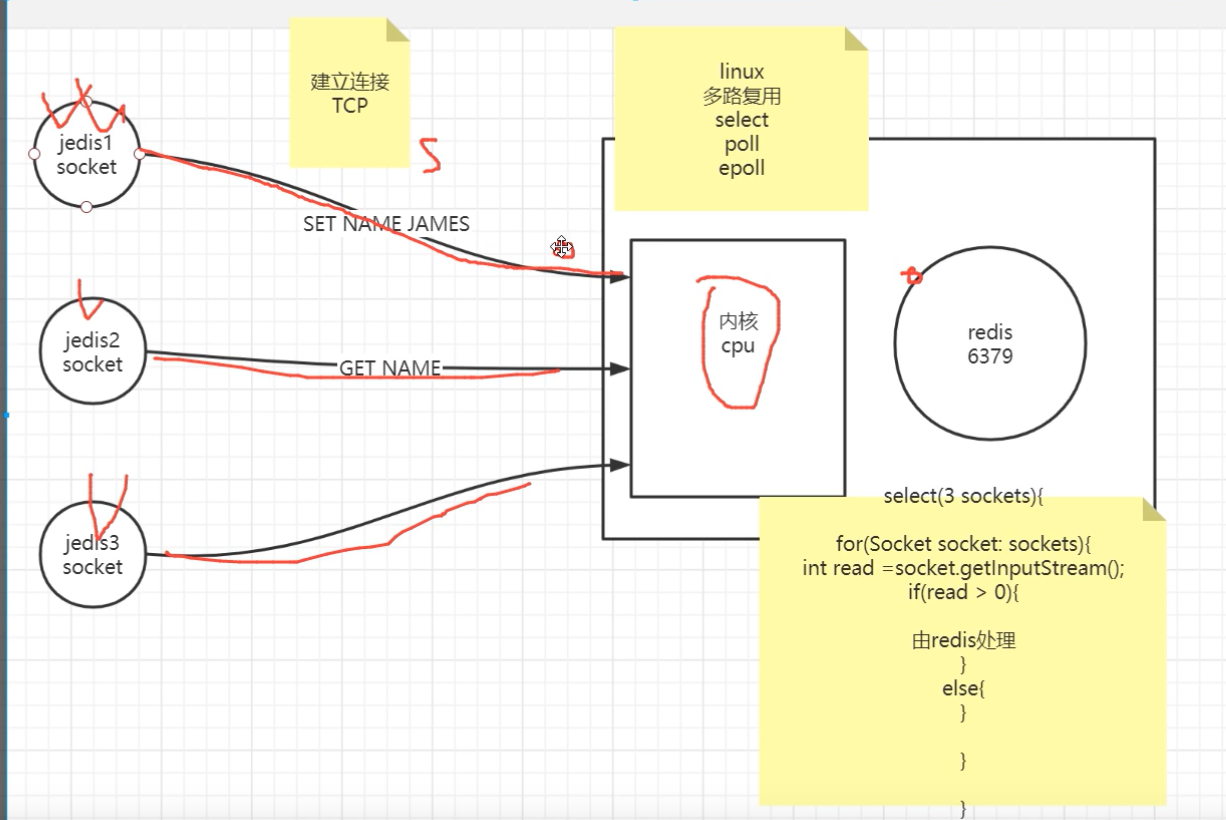
redis 多路复用
client1,2,3只是跟操作系统建立了连接,而redis只需要处理发数据的client;
实际上redis只处理client1,2,没有处理3,
那么,redis怎么知道client1,2来了数据,3没来数据呢?见下图;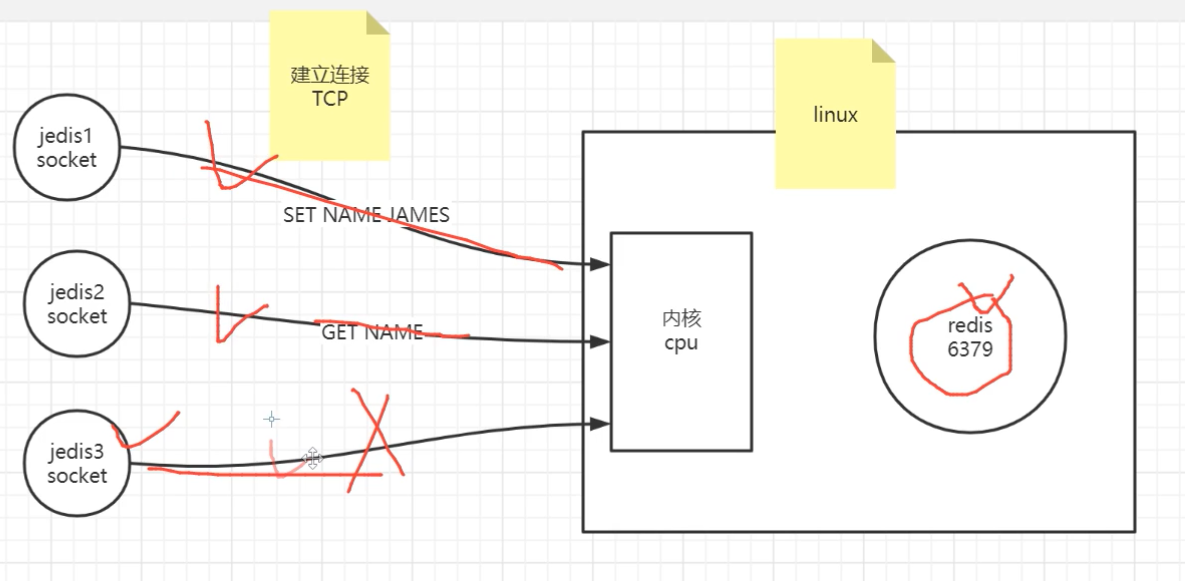
那么,redis怎么知道client1,2来了数据,3没来数据呢?—通过多路复用机制(包括select ,poll,epoll)解决
操作系统提供了三个函数:select ,poll,epoll
select函数拿到所有的soket连接遍历,有数据的通知redis处理,没有数据的不做处理;见下图;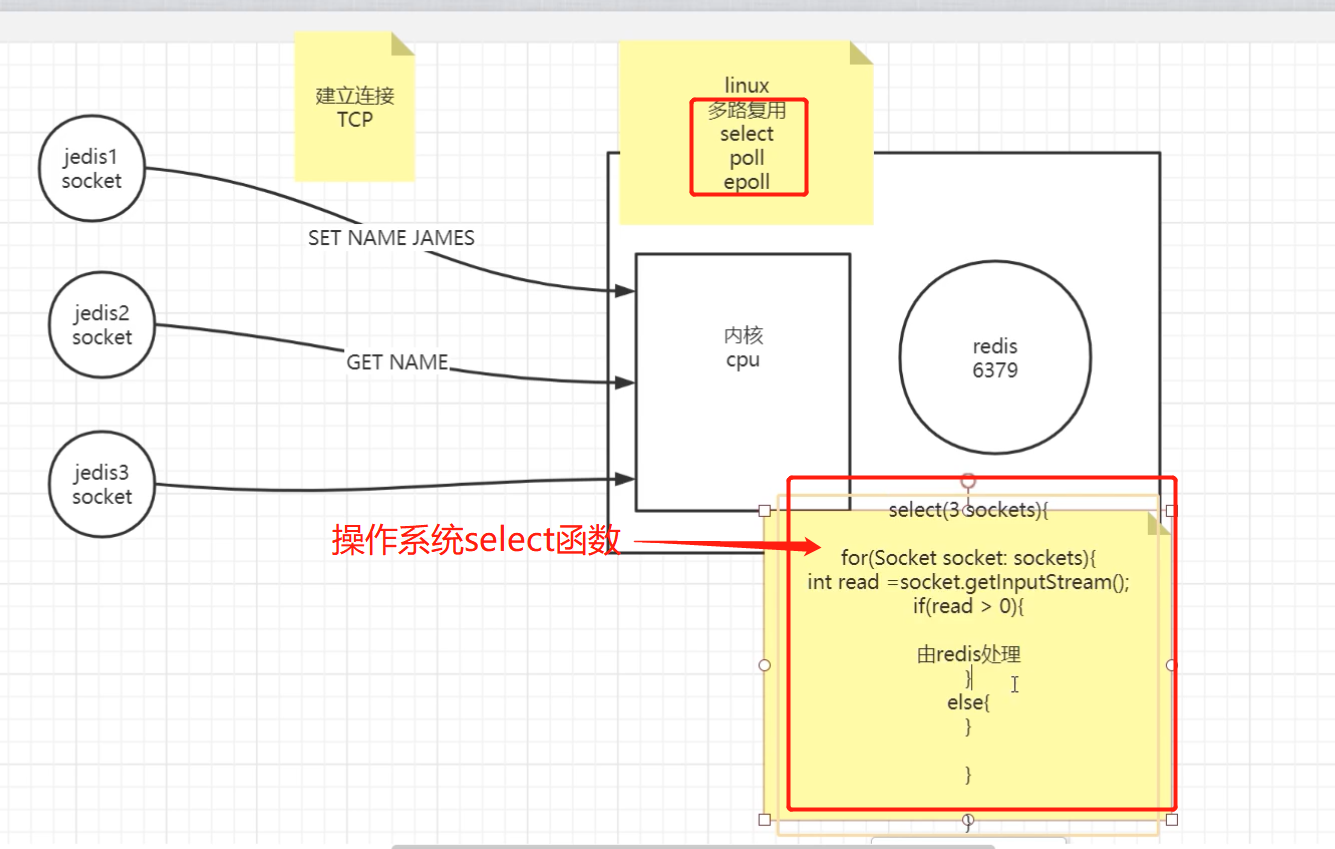
多路复用:(建立一个连接,可以多次发数据)每条路都是复用的,每个人都可以走这条路去城里赶集;见下图;

bio模式的redis服务端:accept()和read()方法都是同步阻塞的。见下图;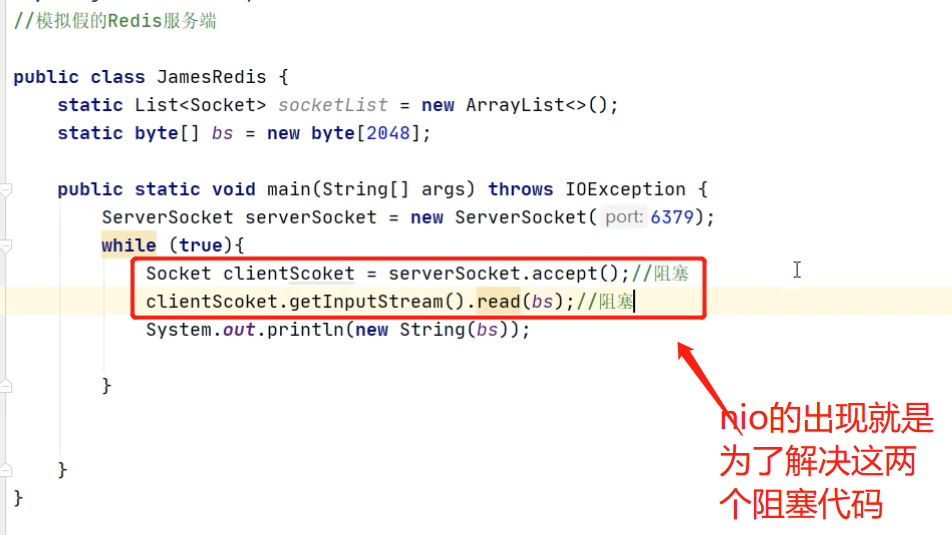
上图的代码 不支持并发,不支持多用户;原因如下图;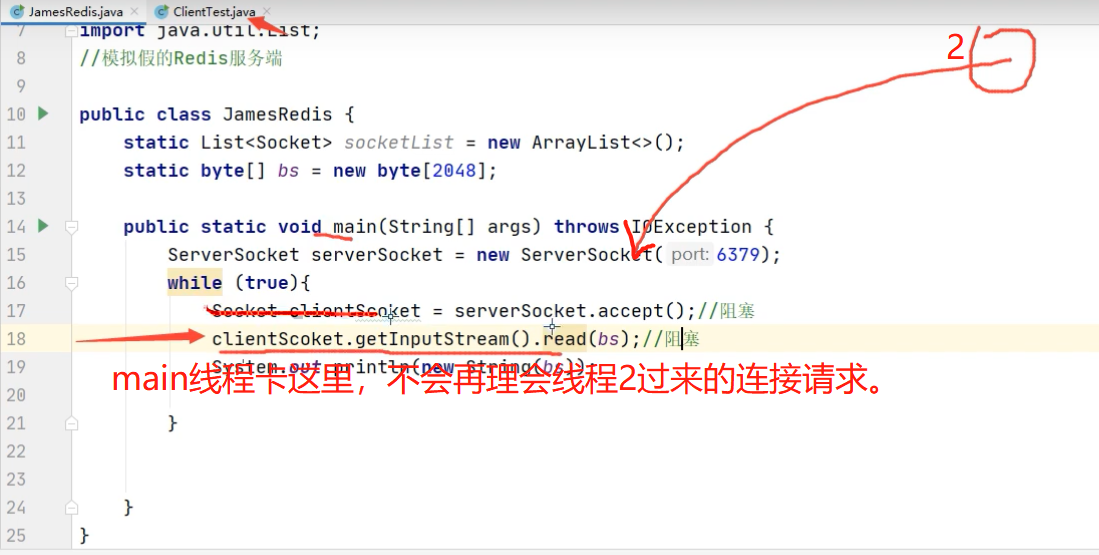
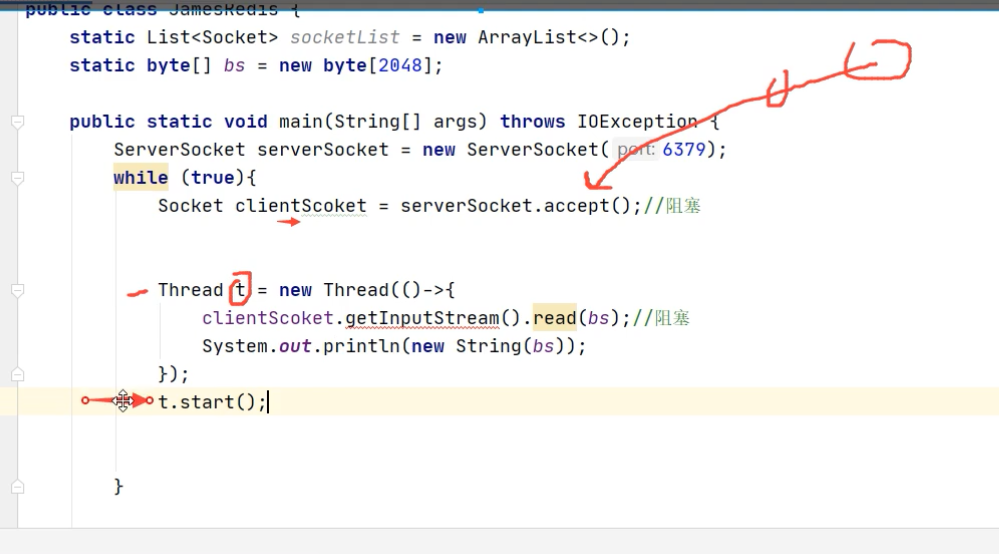
那如何解决呢?引入多线程,建立完连接后,开启子线程来给每个连接读取数据;如下图;这是bio的处理模式,tomcat6之前都是这么处理的 ,会浪费线程,很多线程在那里空等待;
解决办法:把阻塞变成非阻塞,如下图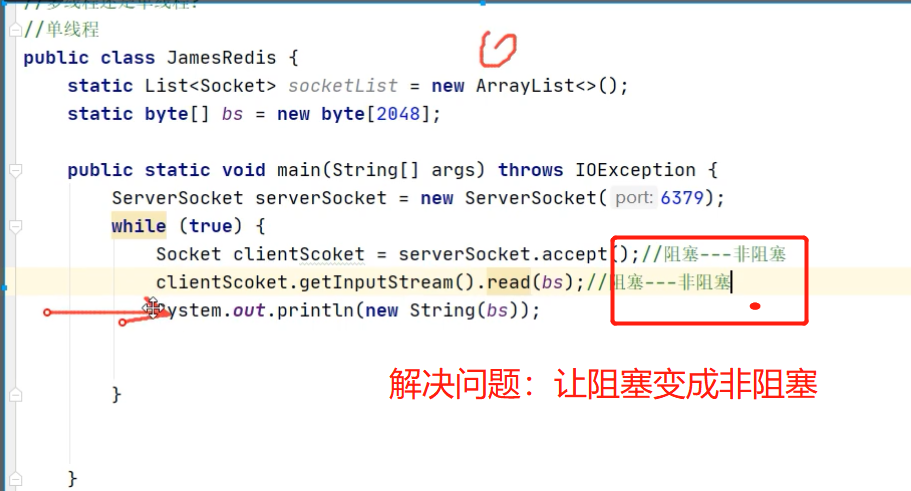
但是有新问题:如果有3个连接过来,第一二个连接会丢失,如下图
解决方法: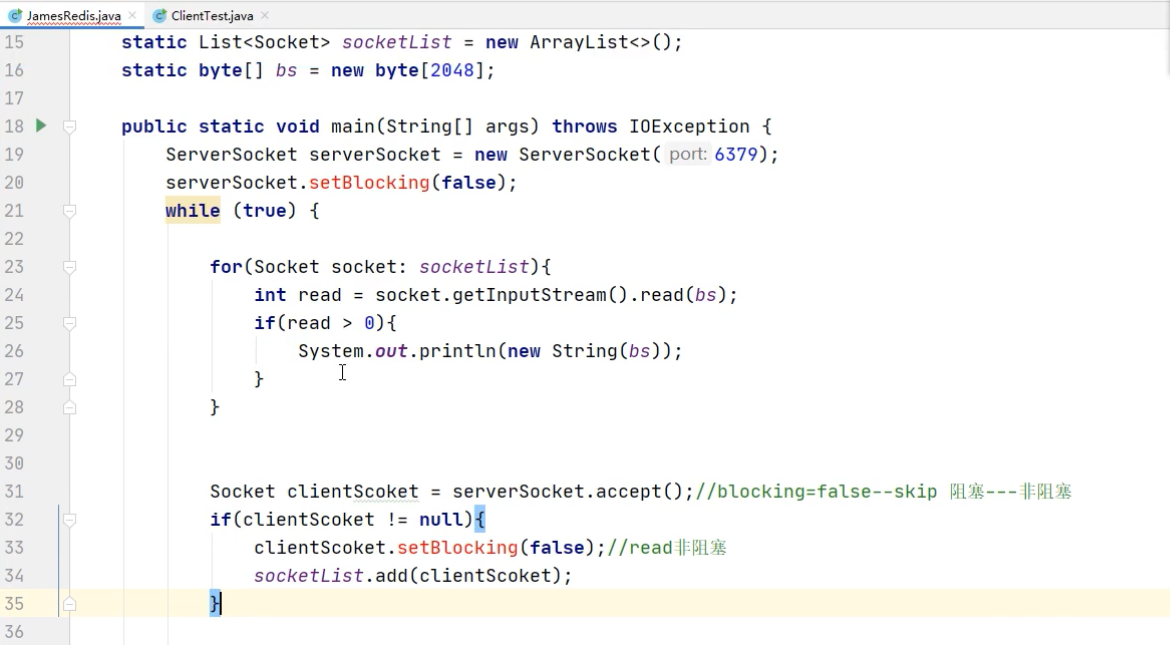
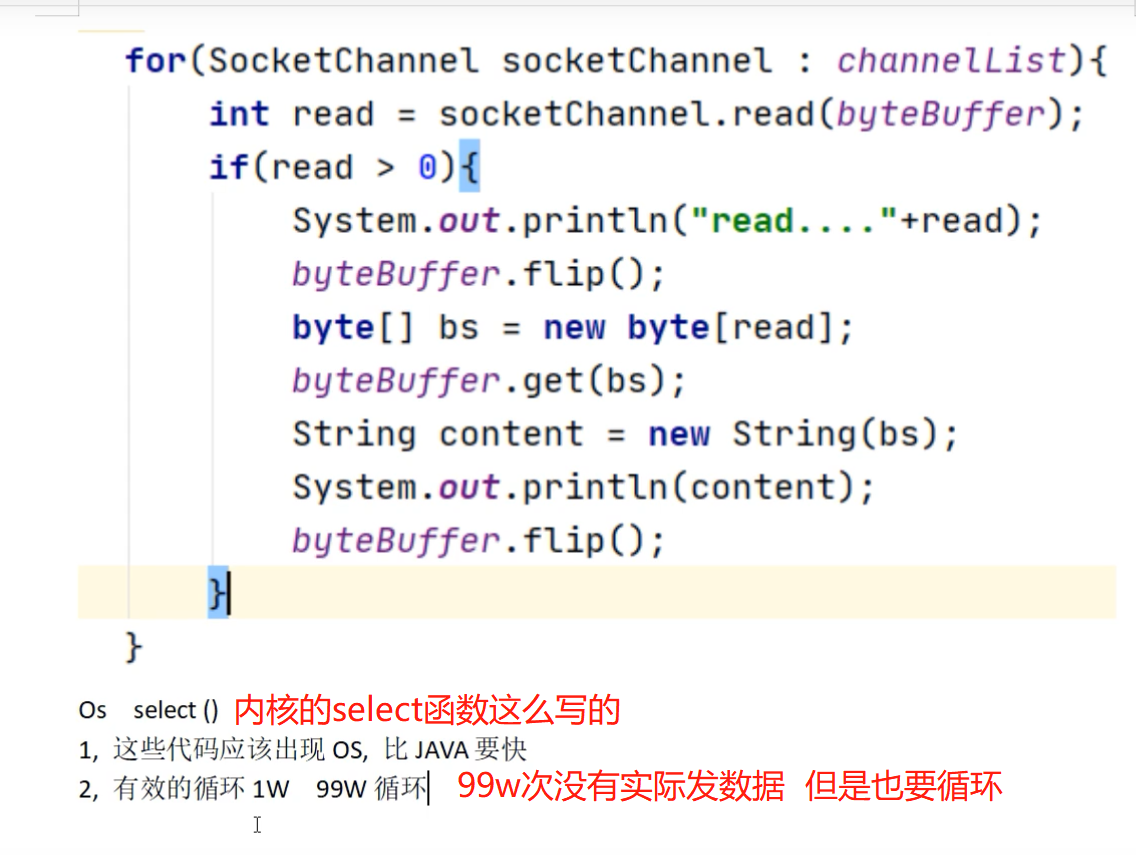
解决上图办法:用事件感知有实际发送数据的请求,解决空循环 无效循环问题
事件管理驱动:
服务端注册accept事件(监听有没有连接)到selector(多路复用器);
客户端的连接请求事件注册到selector,当客户端发送请求到服务端,由selector通知服务端处理客户端连接请求;
客户端的io事件(read write )注册到selector,当客户端向服务端发起write请求,由selector判断是否有数据,有数据则通知服务端(read请求估计是直接通知服务端响应客户端读请求)
代码示例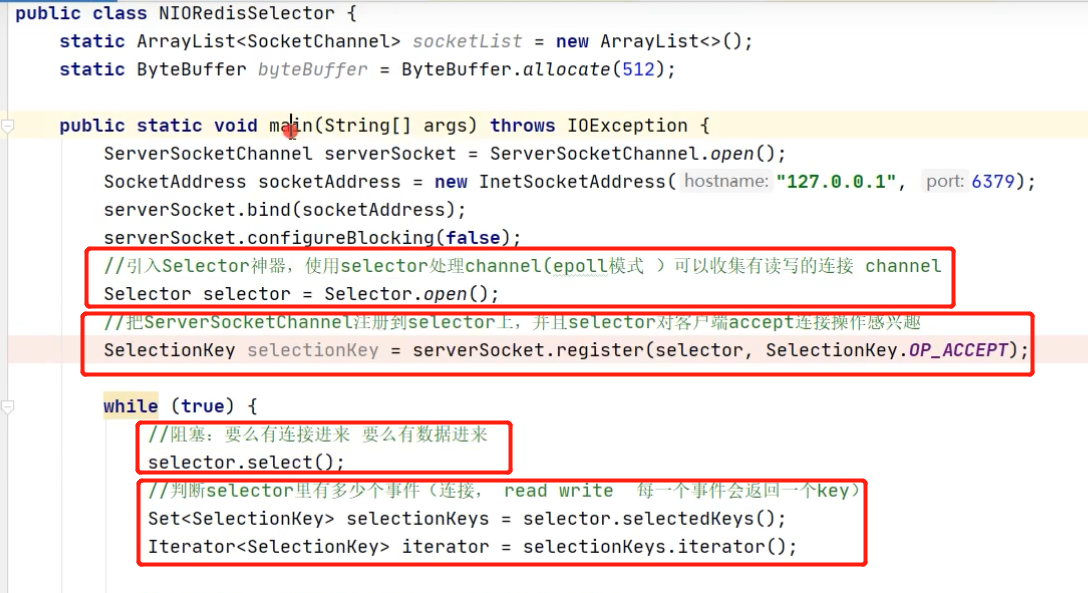
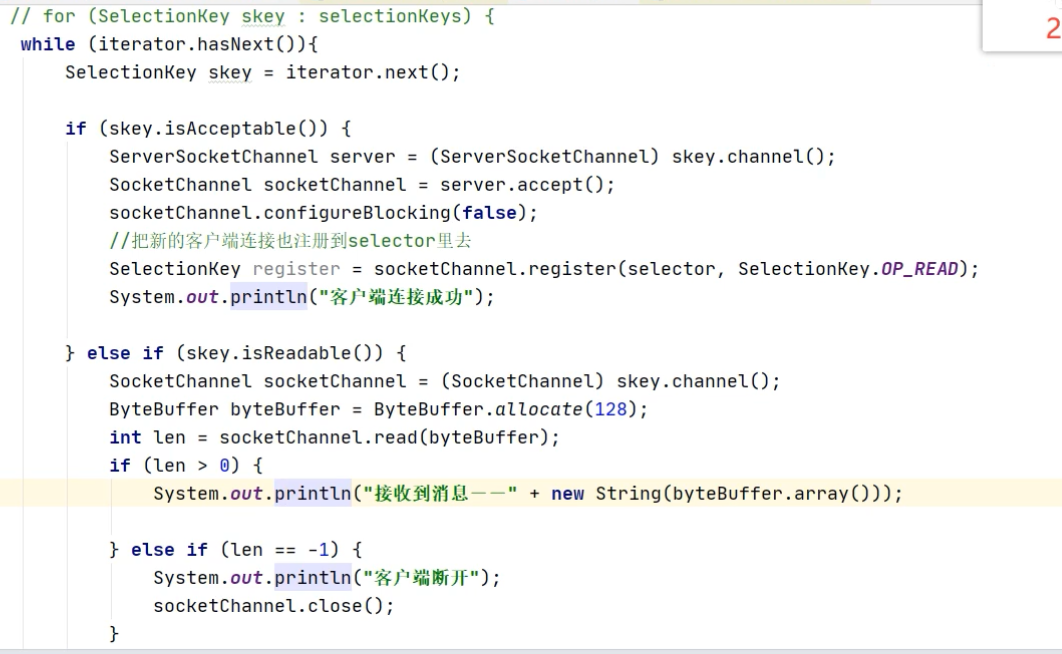
select
fd_set 使用数组实现
1.fd_size 有限制 1024 bitmap
fd【i】 = accept()
2.fdset不可重用,新的fd进来,重新创建
3.用户态和内核态拷贝产生开销
4.O(n)时间复杂度的轮询
成功调用返回结果大于 0,出错返回结果为 -1,超时返回结果为 0
具有超时时间
poll
基于结构体存储fd
struct pollfd{
int fd;
short events;
short revents; //可重用
}
解决了select的1,2两点缺点
epoll
解决select的1,2,3,4
不需要轮询,时间复杂度为O(1)
epoll_create 创建一个白板 存放fd_events
epoll_ctl 用于向内核注册新的描述符或者是改变某个文件描述符的状态。已注册的描述符在内核中会被维护在一棵红黑树上
epoll_wait 通过回调函数内核会将 I/O 准备好的描述符加入到一个链表中管理,进程调用 epoll_wait() 便可以得到事件完成的描述符
两种触发模式:
LT:水平触发
当 epoll_wait() 检测到描述符事件到达时,将此事件通知进程,进程可以不立即处理该事件,下次调用 epoll_wait() 会再次通知进程。是默认的一种模式,并且同时支持 Blocking 和 No-Blocking。
ET:边缘触发
和 LT 模式不同的是,通知之后进程必须立即处理事件。
下次再调用 epoll_wait() 时不会再得到事件到达的通知。很大程度上减少了 epoll 事件被重复触发的次数,
因此效率要比 LT 模式高。只支持 No-Blocking,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。
分布式锁用redis做,redis主从结构,主挂了,锁还没从主同步到从,此时从成为主,导致锁重复。有啥解决办法?
简单,写完之后去从库查一下,如果没查到就当没有获取锁[坏笑]
redis 不是 cp 的,所以不一致是可能的。如果需要强一致用 zk,牺牲性能
redis官方推荐redlock,不过部署麻烦,简单点就只用单台redis做分布式锁,要求高可用就换zk
红锁
用Redis中的多个master实例,来获取锁,只有大多数实例获取到了锁,才算是获取成功。具体的红锁算法分为以下五步:
获取当前的时间(单位是毫秒)。
使用相同的key和随机值在N个节点上请求锁。这里获取锁的尝试时间要远远小于锁的超时时间,防止某个masterDown了,我们还在不断的获取锁,而被阻塞过长的时间。
只有在大多数节点上获取到了锁,而且总的获取时间小于锁的超时时间的情况下,认为锁获取成功了。
如果锁获取成功了,锁的超时时间就是最初的锁超时时间进去获取锁的总耗时时间。
如果锁获取失败了,不管是因为获取成功的节点的数目没有过半,还是因为获取锁的耗时超过了锁的释放时间,都会将已经设置了key的master上的key删除。
————————————————
版权声明:本文为CSDN博主「姜秀丽」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/jiangxiulilinux/article/details/107015292

若有收获,就点个赞吧
0 人点赞
