zk如何实现节点间同步?
在Leader 节点正常工作时,启动一台新的服务器加入到集群,那么这个服务器就会直接进入数据恢复模式,和Leader 节点进行数据同步。同步完成后即可正常对外提供非事务请求的处理。
需要注意的是:leader 节点可以处理事务请求和非事务请求,Follower 节点只能处理非事务请求,会把这个请求转发给Leader服务器
消息广播的实现原理
消息广播的过程实际上是一个简化版本的二阶段提交过程(可以去了解2PC和3PC协议)
流程如下:
1、leader 接受到消息请求后,将消息赋予给一个全局唯一的64位自增id,叫:zxid,通过zxid的代销比较即可以实现因果有序的这个特征
2、leader 为每个follower 准备了一个FIFO队列(通过TCP协议来实现,以实现了全局有序这个特点)将带有zxid的消息作为一个提案(proposal)分发给所有的follower
3、当follower接受到proposal,先把proposal写到磁盘,写入成功以后再向leader恢复一个ack
4、当leader 接受到合法数量(超过半数节点)的 ack,leader 就会向这些follower发送commit命令,同时会在本地执行该消息
5、当follower接受到消息的commit命令以后,就会提交该消息
————————————————
版权声明:本文为CSDN博主「菜鸟编程98K」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_39938758/article/details/105754198
zk的watch机制
客户端注册Watcher到服务端;
服务端发生数据变更;
服务端通知客户端数据变更;
客户端回调Watcher处理变更应对逻辑;
Client向ZK注册监听器。监听某个目录 可以监听下面的子节点, 也可以监听下面的数据。
- 客户端在向Zookeeper服务器注册的同时,会将Watcher对象存储在客户端的WatcherManager当中。用来对各种监听器进行管理。
- 当Zookeeper服务器触发Watcher事件后,会向客户端发送通知。如果监听的目录中的数据或节点发生了改变,ZK就会发送一个通知到Client。这里的流程是把Watcher对象发送到WatchManager里,则之前存储的watcher对象里面的内容就会被更新。更新之后,Client就会从WatchManager中再次获取到watcher对象,然后调用接收到通知之后的执行逻辑,比如是要把变化后的监听数据拿回来还是去做其他事情
Zookeeper Watcher的运行机制
1,Watch是轻量级的,其实就是本地JVM的Callback,服务器端只是存了是否有设置了Watcher的布尔类型。(源码见:org.apache.zookeeper.server.FinalRequestProcessor)
2,在服务端,在FinalRequestProcessor处理对应的Znode操作时,会根据客户端传递的watcher变量,添加到对应的ZKDatabase(org.apache.zookeeper.server.ZKDatabase)中进行持久化存储,同时将自己NIOServerCnxn做为一个Watcher callback,监听服务端事件变化
3,Leader通过投票通过了某次Znode变化的请求后,然后通知对应的Follower,Follower根据自己内存中的zkDataBase信息,发送notification信息给zookeeper客户端。
4,Zookeeper客户端接收到notification信息后,找到对应变化path的watcher列表,挨个进行触发回调。
流程图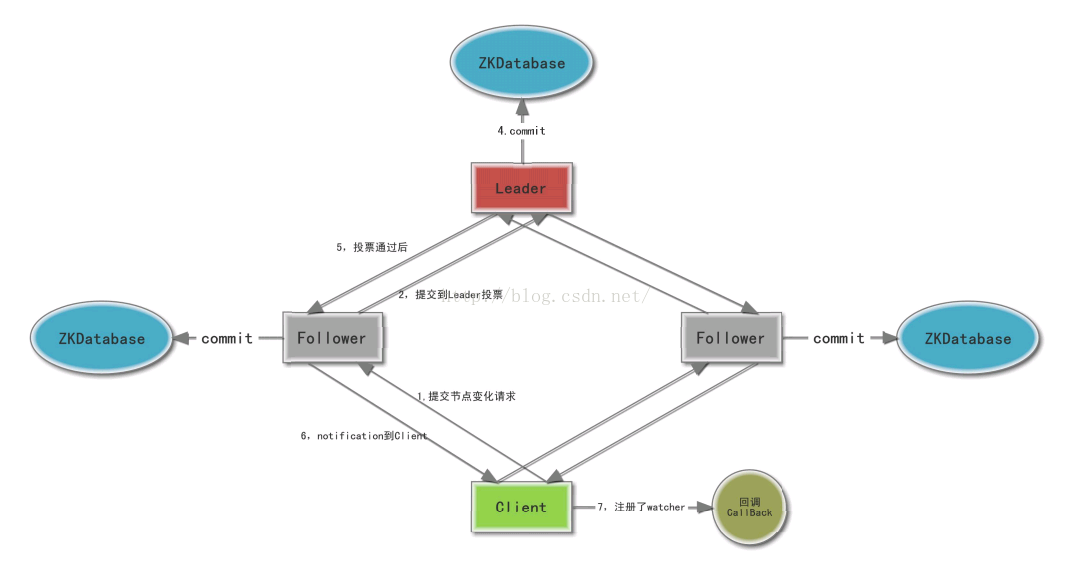
[
](https://blog.csdn.net/qq_39938758/article/details/105754198)

若有收获,就点个赞吧
0 人点赞
