决策树是一个树结构,可以是二叉树或非二叉树。
训练数据举例:
| ID | 拥有房产(是/否) | 婚姻情况(单身,已婚,离婚) | 年收入(单位:千元) | 无法偿还债务(是/否) |
|---|---|---|---|---|
| 1 | 是 | 单身 | 125 | 否 |
| 2 | 否 | 已婚 | 100 | 否 |
| 3 | 否 | 单身 | 70 | 否 |
| 4 | 是 | 已婚 | 120 | 否 |
| 5 | 否 | 离婚 | 95 | 是 |
| 6 | 否 | 已婚 | 60 | 否 |
| 7 | 是 | 离婚 | 220 | 否 |
| 8 | 否 | 单身 | 85 | 是 |
| 9 | 否 | 已婚 | 75 | 否 |
| 10 | 否 | 单身 | 90 | 是 |
表中的前三列(ID不算)是数据样本的属性,最后一列是决策树需要做的分类结果。
通过该数据,构建的决策树如下:
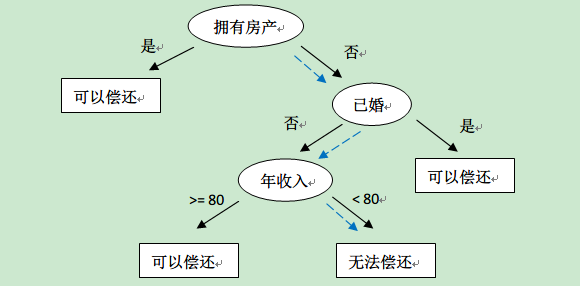
拿这棵树对新的用户数据进行「能否偿还」的预测。比如新来一个用户:无房产,单身,年收入55K,那么根据上面的决策树,可以预测他无法偿还债务(蓝色虚线路径)。从上面的决策树,还可以知道是否拥有房产可以很大的决定用户是否可以偿还债务,对借贷业务具有指导意义。
决策树的构造
决策树的构造就是进行属性选择度量确定各个特征属性之间的拓扑结构。
构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。分裂属性分为三种不同的情况:
- 属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
- 属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
- 属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
决策树ID3.5算法
决策树ID3.5算法是最基本的模型,简单实用,但是在某些场合下也有缺陷。
信息论中有熵(entropy)的概念,表示状态的混乱程度,熵越大越混乱。熵的变化可以看做是信息增益,决策树ID3算法的核心思想是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。
设D为用(输出)类别对训练元组进行的划分,则D的熵表示为: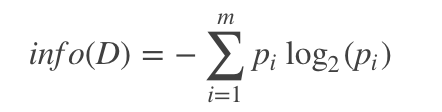
决策树C4.5算法

若有收获,就点个赞吧
0 人点赞
