性能测试的目的:发现性能的瓶颈
负载测试
通过逐步加压的方法,达到既定的性能阀值的目标。阀值的设定应是小于等于某个值,如 CPU 的使用率小于等于 80%
压力测试
通过逐步加压的方法,使系统的某些资源达到饱和,甚至失效的状态(也就是说什么条件下可以把系统压崩溃)
并发测试
同一时间内,多个虚拟用户同时访问同一模块、同一功能。通常的测试方法是设置集合点。
容量测试
通常是指数据库层面的,目标是获取数据库最佳容量的能力,又称为容量预估。测试方法:在一定的并发用户,不同的基础数据量下,观察数据库的处理能力,即获取数据库的各项性能指标
可靠性测试(稳定性测试 / 疲劳测试)
系统在高压的情况下,长时间的运行系统是否稳定。如 CPU 使用率在 80% 以上,7 * 24 小时运行,系统是否稳定
异常测试(失败测试)
指系统架构方面的测试,如:在负载均衡架构中,要测试宕机(死机)、节点挂掉等情况下系统的反应。
性能测试指标定义
- 事务
从客户端发起的一个或多个请求(这些请求组成一个完整的操作),到客户端接收到从服务器返回的响应。
- TPS (Transactions Per Second)
每秒钟系统可以处理的事务数
- QPS:(Query per second )
一台查询服务器每秒处理的请求次数
- 请求响应时间
从客户端发起的一个请求开始,到客户端接收到从服务器返回的响应。整个过程所耗费的时间
- 事务响应时间
事务可能有一个或多个请求组成,事务的响应时间主要针对于用户的角度而言,如转账。
- 并发定义
没有严格意义上的并发,并发总有先后,无论是差距 1 毫秒或者是 1 微秒,总有一个时间差。所以并发讲的是一个时间范围内,比如 1S 内。
- 并发用户数
同一单位时间内,对系统发起请求的用户数量
- 吞吐量
一次性能测试过程中,网络上传输的数据量的总和
- 吞吐率
单位时间内网络上传输的数据量吞吐率 = 吞吐量 / 吞吐时间
- 点击率
每秒钟用户向服务器提交的请求数。Web 应用程序特有的指标,
- 资源使用率
对不同的系统资源的使用情况,如: CPU、内存、 IO
性能测试的监控指标
- 响应时间
反映完成某笔业务(事务)所需要的时间。在性能测试中通过事务函数来完成对响应时间的统计,事务是指做某件事的操作,事务函数会记录开始做这件事情和该事情完成之间的时间差(事务响应时间 Transaction Response Time)其他:1. 响应时间的2、5、8原则2. 80/20原则(又称帕累托效应,比如,某些系统一天中80%的访问量集中在20%的时间内)
- 吞吐量
反映单位时间内能够处理的事务数。在测试工具中,吞吐量也被称为TPS,单位时间内完成的事务数。TPS = 事务数 / 时间
- 服务器资源占用
服务器资源占用反映在负载下系统的资源利用率。资源的占用率越低,说明系统越优秀,资源是指系统运行的一切软硬件平台。在性能测试中,我们需要监控系统在负载下的硬件或者软件上的各种资源的使用情况,如:CPU的占用率、内存使用率、IO等(数据库中的查询Cache命中率)。对于终端用户来讲,其最关心的指标是响应时间。用户并不关心多少人使用,以及资源是否足够,所以性能测试必须保证在任意情况下终端用户使用的操作响应时间不大于5秒。
性能测试的原理
- 用户行为模拟
低成本且具有可行性,模拟大量用户操作的一种技术,凭借此项技术将被测系统在测试阶段运行起来,以检测系统工作是否正常。1. 通过参数化,实现不同用户使用不同数据1. 通过集合点模拟多用户并发操作2. 通过关联实现用户请求间的依赖关系3. 通过思考时间代替请求间的延时时间
- 性能指标监控
通过模拟用户行为,在系统运行中需要监控各项性能指标,并分析指标正确性1. 请求响应时间(通过事务实现 )2. 服务器处理能力监控(通过事务计算吞吐量)3. 服务器资源利用率监控(计数器接口)
- 性能调优
通过指标的监控发现系统存在的性能缺陷,利用分析工具定位并修正性能问题。
性能测试的工作流程
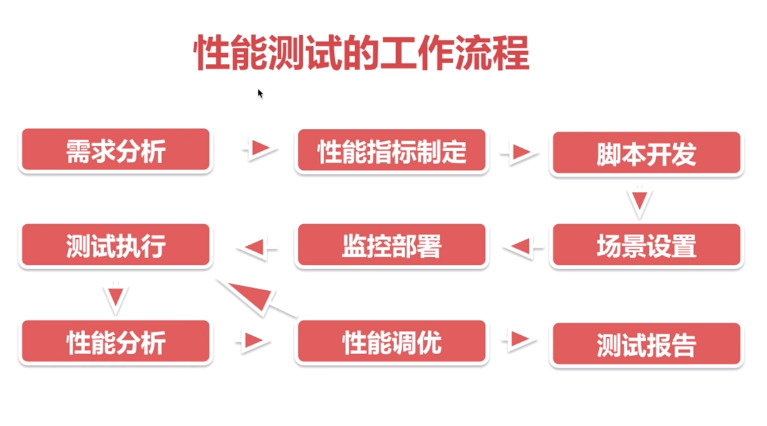
性能测试的需求分析
- 目的: 明确测试目标和测试场景
- 新系统
- 同行业比较
- 业务预期
- 老系统
- 对比以往用户的使用行为以及用户量
- 性能需求的的提取
1. 典型重要业务场景2. 高频使用场景3. 存在大量并发业务场景4. 容易出错的场景
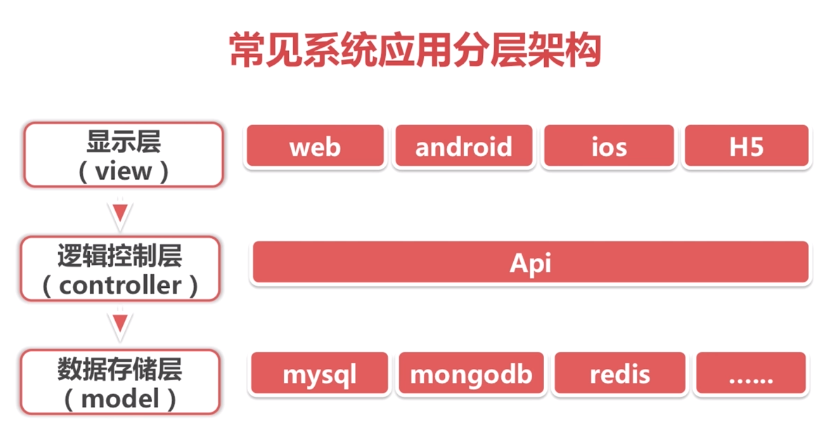
系统应用分层架构
JMeter 性能测试
JMeter 实现逻辑分支控制
- 逻辑控制器
- 用来控制测试脚本的逻辑判断,即控制脚本的运行(以下为常用控制器)
- 如果(if)控制器
- include Controller
- Runtime Controller
- Switch Controller
- While Controller
JMeter 实现配置管理
- 配置元件
JMeter 函数助手
- _CSVRead: 用于对脚本进行参数话,当脚本中不同变量需要不同参数值时
_CSVRead 函数参数说明:CSV file to get values from | *alias ==> 指${__CSVRead(,)}中()内的第一个参数,调用文件logins.txt的路径Column number of CSV file | next | *alias ==> 指${__CSVRead(,)}中()内的第二个参数,调用文件logins.txt中第几列的参数,注意第一列为0,第二列为1,依此类推。。。生成的函数字符串: ${__CSVRead(C:\Users\234652\Desktop\JMeter\log\01.txt,5)}[ 使用方法 ]: 配合 配置元件用户定义的变量使用
- _Random: 生成随机数
_Random 函数参数说明:The minimum value allowed for a range of values ==> 一个范围内允许的最小的值 1The maximum value allowed for a range of values ==> 一个范围内允许的最大的值 100Name of variable in which to store the result (optional) ==> 为生成随机数添加变量名称 id(可任意)生成的函数字符串:${__Random(2,100,)} ==> id = 55(随机数)
- _Log:
log 函数参数说明:String to be logged (and returned) ==> 日志输出的内容,可以引用变量名称Log level (default INFO) or OUT or ERR ==> 定义日志输出的级别,INFO、OUT、warnThrowable text (optional) ==> 抛出的异常信息
- _Split: 字符串分割函数
聚合报告
- Label:每个 JMeter 的 element(例如 HTTP Request)都有一个 Name 属性,这里显示的就是 Name 属性的值
Samples:请求数——表示这次测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里显示100
- Average:平均响应时间——默认情况下是单个 Request 的平均响应时间,当使用了 Transaction Controller 时,以 Transaction 为单位显示平均响应时间
- Median:中位数,也就是 50% 用户的响应时间
- 90% Line:90% 用户的响应时间
- Min:最小响应时间
- Max:最大响应时间
- Error%:错误率 —— 错误请求数 / 请求总数
- Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request per Second),当使用了 Transaction Controller 时,也可以表示类似 LoadRunner 的 Transaction per Second 数
- KB/Sec:每秒从服务器端接收到的数据量,相当于 LoadRunner 中的 Throughput / Sec
重点关注的数据:
- Samples: 请求数
- Average: 平均响应时间
- Min: 最小响应时间
- Max: 最大响应时间
- Error%: 错误率
- Throughput: 吞吐量
JMeter 扩展组件开发
$ Git 地址:
Linux 服务器监控性能测试
测试范围及性能指标
—— —— CPU 内存 磁盘 网络 版本
进程和线程
- 进程: 具有一定独立功能的程序关于某个数据集合上的一次运行活动,是系统进行资源分配和调度的一个独立单位。(进程是可以独立运行的)
- 线程: 是进程的一个实体,是 CPU 调度和分派的基本单位他是比进程更小的能够独立运行的基本单位,线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源。一个线程可以创建和撤销另一个线程
进程与线程的区别
- 一个线程只属于一个进程,一个进程中可以拥有多个线程,线程之间可以互相操作。
- 线程是进程工作的最小单位,
- 一个进程会分配一个地址空间,进程与进程之间不共享地址空间。即不共享内存。
- 同一个进程下的不同的多个线程,共享父进程的地址空间。
- 线程在执行过程中,需要协作同步,不同进程的线程之间要利用消息通信的办法实现同步。
- 线程作为调度和分派的基本单位,进程作为拥有资源的基本单位
进程的优缺点
[ 优点 ]
- 每个进程互相独立,不影响主程序的稳定性,子进程崩溃不影响其他进程
- 通过添加 CPU 可以扩充性能
- 可以尽量减少线程加锁和解锁的影响,极大地提高了性能
[ 缺点 ]
- 逻辑控制复杂,需要和主程序交互
- 多进程调度开销大
线程的优缺点
[ 优点 ]
- 程序的逻辑和控制方式简单
- 所有线程可以共享内存和变量等
- 线程方式消耗的总资源比进程方式少
[ 缺点 ]
- 线程与主程序共用地址空间,最大内存地址受限
- 线程之间的同步和加锁不易控制(同步锁)
- 一个线程的崩溃可能影响整个程序的稳定性
Linux 服务器监控命令
实时监控命令
- top (实时监控-综合)
- 作用: 实时监控系统的运行状态,并且可以按照 CPU 及内存进行排序
- top -h:帮助
- top -p: 监控指定进程,当监控多个进程是,进程 ID 以逗号分隔。语法:top -p PID
- top 任务区命令(top 进入任务区)
- M:按内存使用率排序
- P: 按 CPU 使用率排序
- z: 彩色 / 黑白显示
load average 说明:1. top 中的 load average 表示系统运行队列的平均利用率,也可以认为是可运行进程的平均数2. 三个值分别表示: 1 分钟、5 分钟、15 分钟的平均负载值3. 在单核 CPU 中 load average 的值为 1 时,表示满负荷状态。4. 同理,在多核 CPU 中满负载 load average 的值为 1 * CPU 核数。
- vmstat(实时监控 - 综合)
- 功能:可以监控操作系统的进程状态、内存、虚拟内存、磁盘 IO、CPU 的信息
- 选项:vmstat -S 使用指定单位显示,(k, K, m, M 分别代表 1000, 1024, 1000000, 1048576 字节,默认单位 K 1024)
- 语法:vmstat 2 5 (2 表示时间间隔; 5 表示 显示次数)
- free (实时监控-内存)
- 功能:监控系统内存的使用状态
- 语法:free -h
free - h 显示字段说明:1. total: 总物理内存的大小2. Used: 已经使用多大3. Free: 可用多少4. shared: 多个进程共享的内存总额5. buffers/cached: 磁盘缓存的大小
- mpstat(实时监控 - CPU)
- 功能:可以查看多核心 CPU 中每个计算核心的统计数据
- 参数:无参数时,显示系统启动以后所有信息的平均值,有 interval 时,第一行的信息自系统启动以来的平均信息,从第二行开始,输出为前一个 interval 时间段的平均信息
- 语法:mpstat [-P | ALL] [interval | count]
mpstat 语法使用说明1. -P: 表示监控那个 CPU ;在 [0, CPU 个数减一] 中取值使用方法:mpstat -P 0(实时监控第一个 CPU); mpstat -P 2(实时监控第三个 CPU);2. interval 相邻两次采样的间隔事件; count 采样的次数,count 只能和 delay 一起使用使用方法:mpstat 2 5 (2 表示时间间隔; 5 表示 显示次数)
- netstat (实时监控 - 网络) (netstat -ntlp 查看端口有没有被监听)
- netstat -n 拒绝显示别名,能显示数字的全部显示数字
- netstat -l 仅列出有在 Listen(监听)的服务状态
- netstat -p 显示建立相关链接的程序名
- netstat -t 显示 TCP 相关选项
- netstat -u 仅显示 UDP 相关选项
- netstat -i 显示自动匹配接口的信息 ==> 查看网络传输的大小以及有没有发生错误
- netstat -c 每隔一个固定时间,执行该 netstat 命令
- iostat (实时监控 - 磁盘)
- 作用: 显示磁盘读写操作的统计信息,同时给出 CPU 的使用情况
- iostat -x [设备名称] 1 2 输出指定要统计的磁盘设备名称,默认为所有磁盘设备(1,表示间隔时间,2 表示执行次数)
[root@dahuatech ~]# iostat -xLinux 2.6.32-573.el6.x86_64 (dahuatech) 07/28/2020 _x86_64_ (8 CPU)avg-cpu: %user %nice %system %iowait %steal %idle15.64 0.15 14.30 0.48 0.00 69.43Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %utilsda 0.60 241.21 0.68 14.04 64.67 2041.76 143.15 0.09 6.17 1.37 2.01dm-0 0.00 0.00 0.55 1.49 4.39 11.91 8.00 0.01 5.44 0.34 0.07dm-1 0.00 0.00 0.00 0.00 0.01 0.00 7.94 0.00 3.88 1.21 0.00dm-2 0.00 0.00 0.01 152.33 0.07 1218.60 8.00 1.56 10.24 0.03 0.39dm-3 0.00 0.00 0.17 0.00 27.40 0.00 159.85 0.00 1.91 1.45 0.02dm-4 0.00 0.00 0.16 97.30 9.72 778.39 8.09 0.26 2.69 0.08 0.77重点关注: r/s 、w/s、 %util(繁忙程度)>> 将命令结果以二进制格式存放在文件中
- sar 万能命令
- 功能:linux 全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告
- 监控范围: 文件读写情况、系统调用的使用情况、磁盘 I/O 、CPU 效率、内存使用情况、进程活动、IPC 有关的活动
- 语法:sar [options] [-O file] t n ==> (options: 命令行选项 t:表示采样间隔时间(必有);n:表示采样次数(可选,默认 1); -o file: 表示将命令结果以二进制格式存放在文件中,file 表示文件名)
options 选项:-A: 所有报告的总和;-u: CPU 利用率;-v: 进程、节点、文件和锁表的状态;-r:显示系统内存的使用情况-B: 内存分页情况-b: 缓冲区使用情况(8 份区域)
进程追踪命令
- strace
- 功能:集诊断、调试、统计于一体的工具,追踪进程的运行过程
- 选项 -p: 跟踪指定进程
- 选项 -f: 跟踪由 fork 子进程系统调用
- 选项 -c: 统计每一系统调用的所执行的时间,次数和出错的次数等
- 选项 -t: 在输出中的每一行前加上时间信息, -tt 时间确定到微秒级
- 选项 -e expr: 输出过滤器,通过表达式,可以过滤掉不想要的输出
- 选项 -o filename: 默认将结果输出到 stdout,通过 -o 输出到指定文件夹
监控工具 nmon
说明:下载:wget
数据驱动性能测试
定义:从数据文件中读取测试数据,驱动测试过程的一种测试方法(更高级的参数化)。特点:1. 测试数据与测试代码分离2. 数据控制过程3. 可以减少测试代码量4. 降低脚本开发和维护的成本5. 便于用例的修改和维护要求:1. 较强的代码能力2. 较强的分层架构设计思维3. 对开发框架有一定的了解使用场景:1. 复杂的业务流程2. 根据业务场景分流3. 符合条件的并发场景
数据库的架构设计
数据库性能测试
- 测试范围
1. SQL 语句 => 慢查询等2. 资源使用率3. 数据库架构的合理性4. 数据库的性能指标
数据库架构
- 一主多从
读写分离:master(主写,主库)==>复制 slave(从读,从库)==>复制 slave(从读,从库)缺点: 主从延迟
- 双机热备
KeepAlived==> VIP (虚拟 IP)==> master ==> 复制 ==> slave缺点:优点:
数据库主从同步的工作原理
1. master 将改变记录到二进制(binary log 文件)中2. slave 将 master 的 binary log events 拷贝到它的中继日志(relay log,转换日志)3. slave 重做中继日志中的事件,将改变反映他自己的数据
数据库分库分表的设计方法
分库分表原因:1. 单表或库数据量太大2. 硬件不能升级或无法升级方案:1. 业务拆分(用户、商品、订单、 ... ...)2. 垂直拆分(商品 ==> 电子商品、母婴商品、 ... ...)3. 水平拆分(一致性哈西算法)usreid ==> userid%3 == 1==> userid%3 == 2==> userid%3 == 3
数据库性能测试
MySQL
- MariaDB(主流分支)
- MySQL 之父 Widenius 创建,目标在于替换现有的 MySQL
- 兼容 MySQL, 对于开发者来说感知不到变化
- MariaDB is free and open source software
MySQL 数据库监控指标
- QPS(Queries per seconds)
- 每秒钟查询数量
- show global status like ‘Question%’;
- TPS (Transactions Per Second) TPS = Com_commit + Com_rollback) / seconds
- show global status like ‘Com_commit’;
- show global status like ‘Com_rollback’;
- 线程连接数
- show global status like ‘Max_used_connections’;(使用的最大连接数)
- show global status like ‘Max_connections’;(设置的最大连接数)
- show global status like ‘Threads%’;
- Query Cache
- 查询缓存,用于缓存 select 查询结果
- 当下次接收到相同查询请求时,不在执行实际查询处理而直接返回结果
- 适用于大量查询,很少改变表中的数据
- Query Cache 命中率(MySQL 特有)
- show global status like ‘Qcache%’;
- 命中率计算:Query_cache_hits = (Qcahce_hits/(Qcahce_hits + Qcahce_inserts)) * 100%
开启:1. 修改 my.cnf 文件2. 将 query_cache_size 设置为具体的大小(取决于查询的实际情况,最好设置为 1024 的倍数,参考值 32M)3. 增加一行: query_cache_type = 0/1/2=> 1 表示缓存所有结果,除非你的 select 语句使用 SQL_NO_CACHE 禁用了查询缓存=> 2 表示只缓存在 select 语句中通过 SQL_CACHE 指定需要缓存的查询
- 锁定状态
- show global status like ‘%lock’;
- table_locks_waited / table_lockks_immediate 值越大代表表锁造成的阻塞越严重
- innodb_row_lock_waits innodb 行锁,太大可能是间隙锁造成的
- 表锁、行锁、间隙锁
- 主从延时
- 查询主从延时时间: show slave status
MySQL 慢查询工作原理及操作
慢查询:1. 执行速度超过定义的时间的查询2. 不同系统定义不同的慢查询指标慢查询开启:1. 编辑 etc/my.cnf 在 [mysqlid] 域中添加:slow_query_log = 1 (开启慢查询)2. 设置慢查询日志路径:slow_query_log_file = /data/mysql/slow.log3. 设置慢查询的时长long_query_time = 14. 未使用索引的查询也被记录到慢查询日志中log_queries_not_using_indexes = 1
- 慢查询日志分析
- mysqldumpslow 命令
- -s : 表示按照何种方式排序
- -t : top n 的意思,即返回前面多少条数据
- -g : 后边可写正则匹配模式,大小写不敏感
- mysqldumpslow -s 的更多参数
- c 访问计数
- i 锁定时间
- r 返回记录
- t 查询时间
- al 平均锁定时间
- ar 平均返回记录数
- at 平均查询时间
使用:1. 得到返回记录集最多的 10 个 SQLmysqldumpslow -s r -t 10 slow.log2. 得到访问次数最多最多的 10 个 SQLmysqldumpslow -s c -t 10 slow.log3. 得到按照时间排序的前 10 条里面含有左连接的查询语句mysqldumpslow -s t -t 10 -g "left join" slow.log
- SQL 语句性能分析
- explain select 语句
explain 返回结果分析1. ID: select 识别符,代表语句的执行顺序,id 数字越大越先执行,如果一样大,从上往下执行2. select_type:3. table: 显示查询表名,<derived N> 临时表**4. type: **1) 依次从好到差:**system, const, eq_ref,** ref, fulltext, ref_or_null, unique_subquery, index_subquery, range, **index_merge, index, all**2) 除了 all, 其他 type 都可以使用到索引,除了 index_merge(表示查询使用两个以上的索引), 其他 type 只可以用到一个索引5. possible_keys: 可能使用的索引6. key: 真正使用到的索引7. key_len:8. ref:9. rows: 估算的扫描行数10. extra:
MySQL 索引的概念及作用
[ 索引类型 ]
- 主键索引(唯一索引,不允许有空值)
- 全文索引(fulltext, MyISAM 表特有)
- 唯一索引(值唯一,允许有空值)
- 组合索引(多列索引,多列同时创建索引)
- 普通索引(无限制)
[ 索引创建规则 ]
- 可以提高查询速度,但是减低插入和更新的速度,并占用磁盘空间
- 在插入与更新数据时,要重写索引文件
- 单张表索引数量最好不超过 5 个
- 单个索引中的字段数不超过 5 个(组合索引)
- 不适用索引的查询: like 模糊查询;反向查询,not in / not like
MySQL 存储引擎
- MyISAM(只支持表锁)
优点:1. 读取性能比 innoDB 高2. 索引与数据分离,使用压缩,从而提高了内存使用率缺点:1. 不支持事务2. 写入数据时,直接锁表(表锁)
- InnoDB
优点:1. 支持事务2. 支持外键3. 支持行锁缺点:1. 不支持 全文索引2. 行锁并不绝对,当不确定扫描范围时,锁全表3. 索引与数据捆绑,没有使用压缩,导致体积庞大
MySQL 实时监控
- orzdba(监控工具)
./orzdba 执行使用:
MySQL 集群监控方案 - 天兔 LEPUS
- 天兔 LEPUS 全部数据库实例监控
本地部署: 产品 > 文档中心 > 安装admin /Lepusadmin
MySQL 性能测试的用例准备
要点:使用 sql 模拟用户使用场景(增删改查语句)工具:JMeter步骤:1. JDBC Connection Configuration 配置 MySQLDatabase URL: jdbc:mysql://192.168.1.7:3306/testDriver class: com.mysql.cj.jdbc.DriverUsername:Password:2. JDBC Request 写 SQL 脚本select * fom user

若有收获,就点个赞吧
0 人点赞
