背景
对过去解决的问题进行一个总结,分析bug产生原因,环境问题是否可优化等,以减少相同bug重复出现。
bug分类
场景问题
http://zenpms.dtstack.cn/zentao/bug-view-50600.html
场景:元数据同步.开头表,部分数据为空,没同步到
原因:.开头的表需要转义
反思:场景需要丰富
http://zenpms.dtstack.cn/zentao/bug-view-51852.html
场景:数据源存在同名表导致元数据获取失败
原因:数据源存在同名表,获取元数据的时候没有加上schema区分
反思:没考虑过同名表?历史问题,但是同名表问题在其他数据源也出现过,主要原因在于:客户哪个数据源出现,就改哪个数据源插件,没改其他的是因为数据源太多,同步的数据源获取元数据信息的逻辑又不一样,一个一个的改没时间 ——》rdb很多共性问题改动成本太高,只能一个插件一个插件改造?
http://zenpms.dtstack.cn/zentao/bug-view-51439.html
场景:kerberos任务运行超过24小时报错
原因:kerberos超时没有重新验证
反思:kerberos场景不全,后续需要对此场景验证
doris通过restApi发送请求,发送的条件参数是通过字符串拼接的,字符串拼接时没考虑到特殊字符的场景导致doris解析失败
关联的问题:postgrelsql进行copy模式写入的时候,会有分隔符等配置,特殊字符也是要转义
反思:场景问题,开发的时候,还是要考虑到一些特殊场景,尤其是有一些分格符,字符串拼接
代码不熟悉
http://zenpms.dtstack.cn/zentao/bug-view-52006.html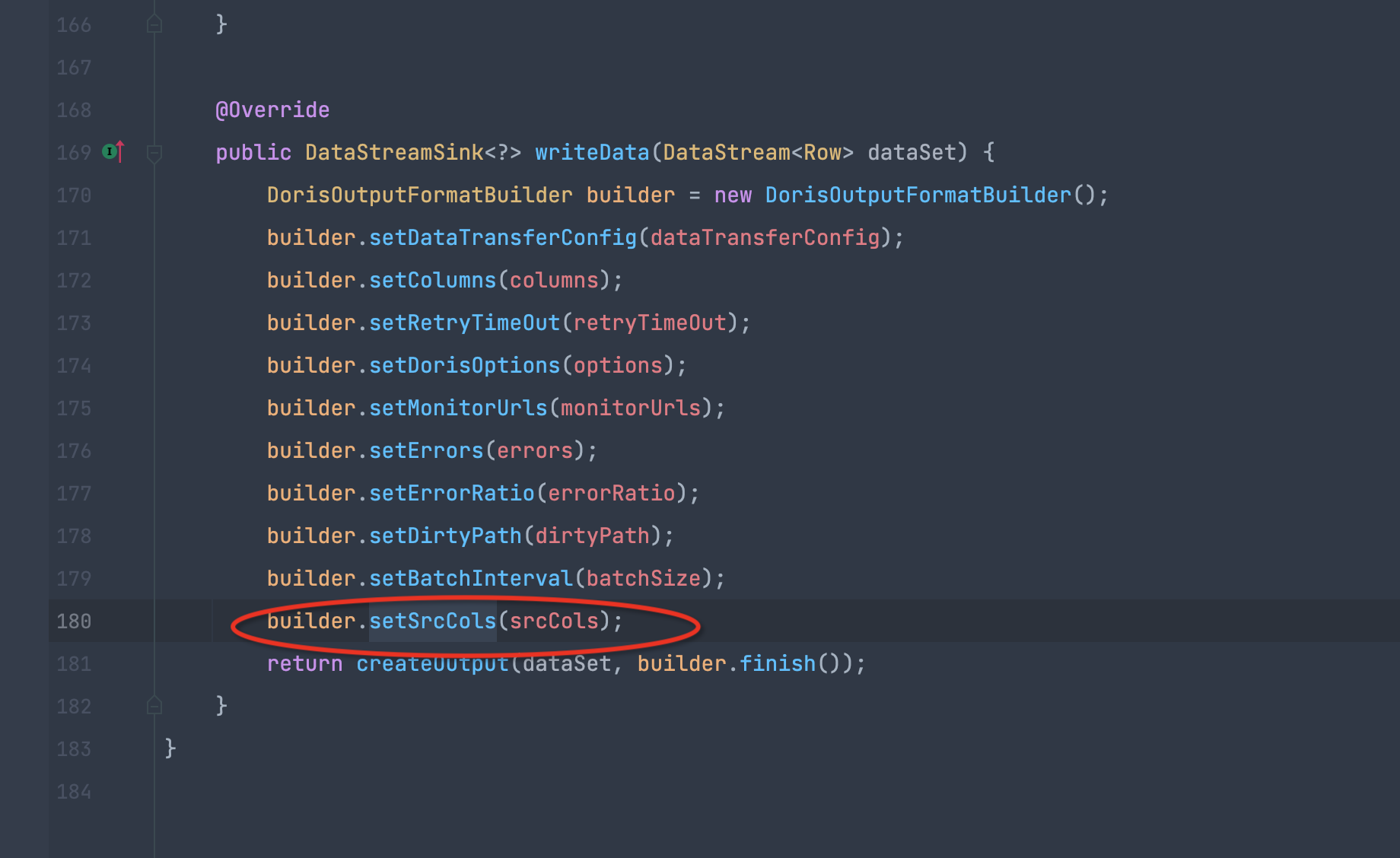
在构建formatBuilder时,没有设置源表字段值,导致如果配置了脏数据会报错
对于一些必要参数的设置,没有文档或者上层抽象一下,具体插件不应该关心一些其他参数的设置
http://zenpms.dtstack.cn/zentao/bug-view-48946.html
场景:1.12迁移后插件不支持历史脚本
原因:
1 1.12插件迁移得时候,可能部分同学不熟悉1.10的一些逻辑,导致不兼容
2 认为这个参数在1.10不合理,所以1.12不应该兼容
反思:这种1.10迁移1.12,计算引擎团队所有开发全部分几个插件,是否合理,最终还是导致flink团队在测试的时候擦屁股
思考不完善
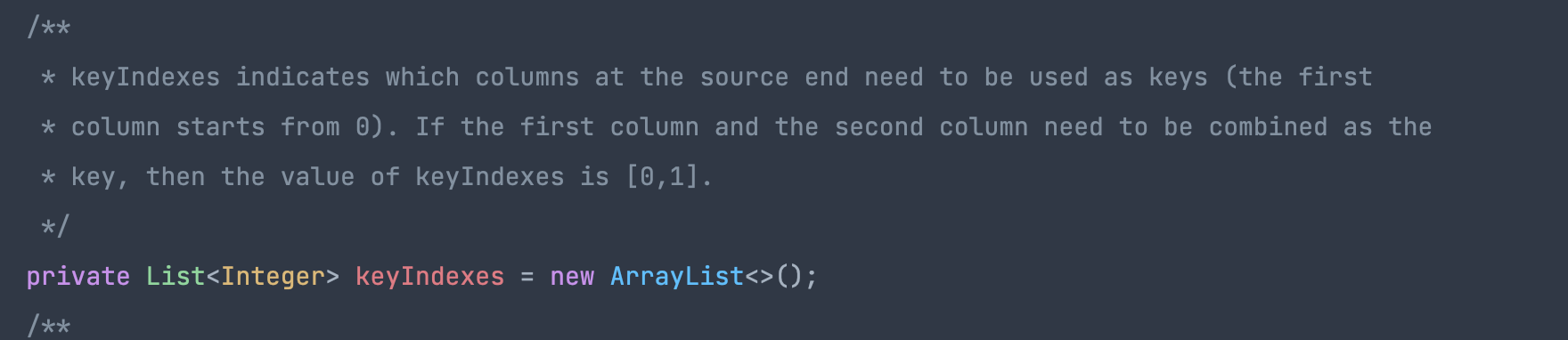
有时候参数值是没有默认值的,可能后面的人加上个默认值,但是是否判断过这个参数涉及到的一些判断逻辑
以前没有默认值,那么对象类型数据默认就是NULL,int这种自带默认值。可能一些判断逻辑是判断这个字段是否为null,如果修改为有默认值之后,就会导致这个逻辑永远走不进去,因为这个值不会为NULL了,所以修改的时候一定要知道自己影响的边界。
http://zenpms.dtstack.cn/zentao/bug-view-52650.html
场景:打包失败
原因:修改公共方法参数之后,inceptor模块调用地方没有修改,因为通过1.10_release_4.3的pom文件有profile,inceptor模块在tdh profile,默认不生效,所以idea通过显示调用的地方没有显示出来inceptor插件调用地方。
反思:这种问题很难解决,因为默认的profile缺失了很多插件,除非每次都记住要在所有pfofile生效下查看的代码才是最全的,但是这种靠人自觉记得很难保证。ci/cd是否能在提交代码后进行打包验证可避免,或者profile修改?
http://zenpms.dtstack.cn/zentao/bug-view-51977.html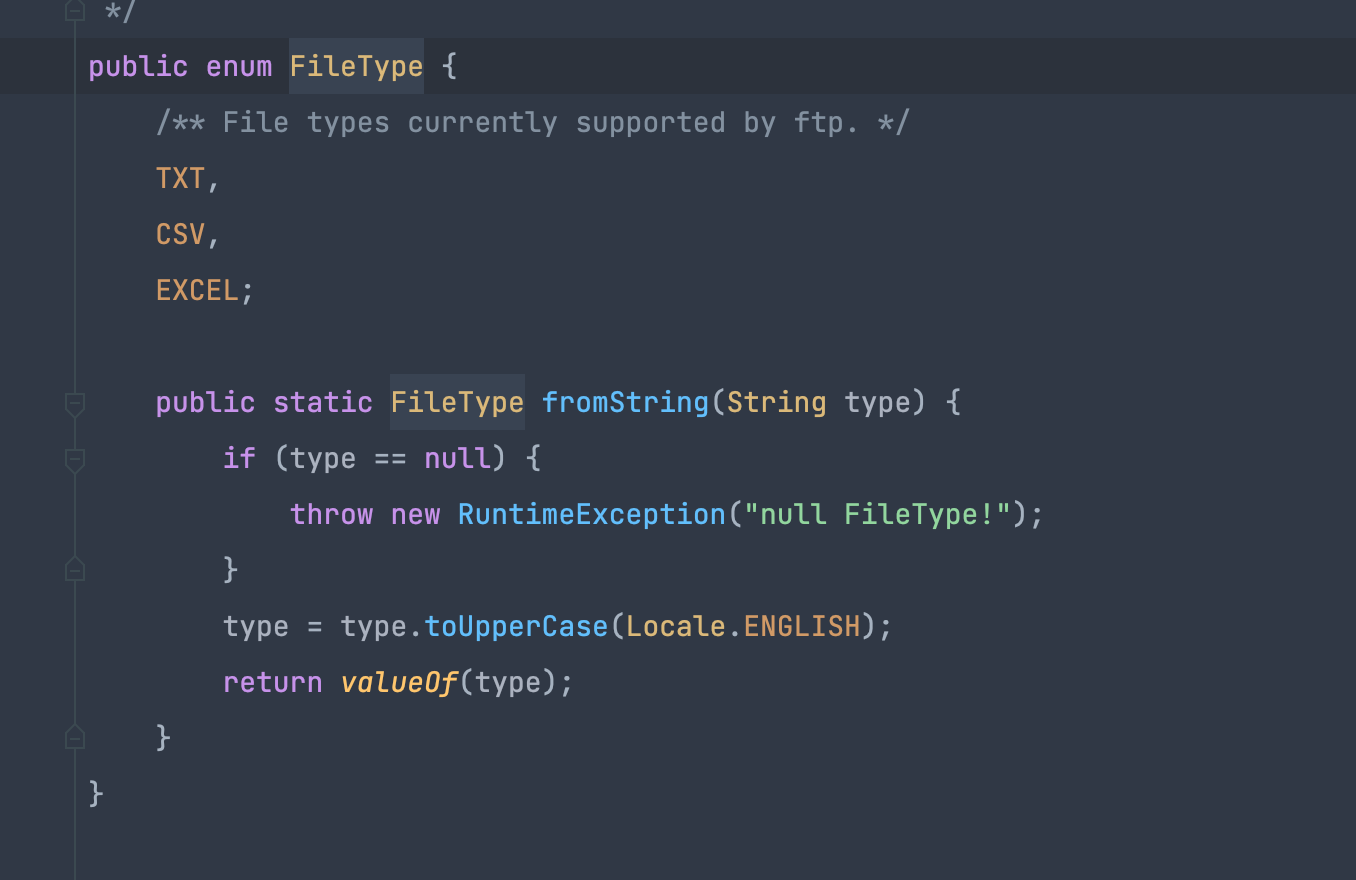
场景:ftp读取的目录下文件后缀存在非txt csv excel等格式就会报错
原因:根据后缀名获取对应的读取client,但是在判断的时候,根据枚举的valueOf获取会导致不存在这些枚举类型值时报错,以前是根据字符串比较的所以不会报错
反思:需要根据场景判断,比如这个参数就只能是这些枚举值,那可以通过valueOf进行判断,如果参数是可以任意的,不符合就有一个默认实现,那就不能通过枚举的valueOf判断
http://zenpms.dtstack.cn/zentao/bug-view-51625.html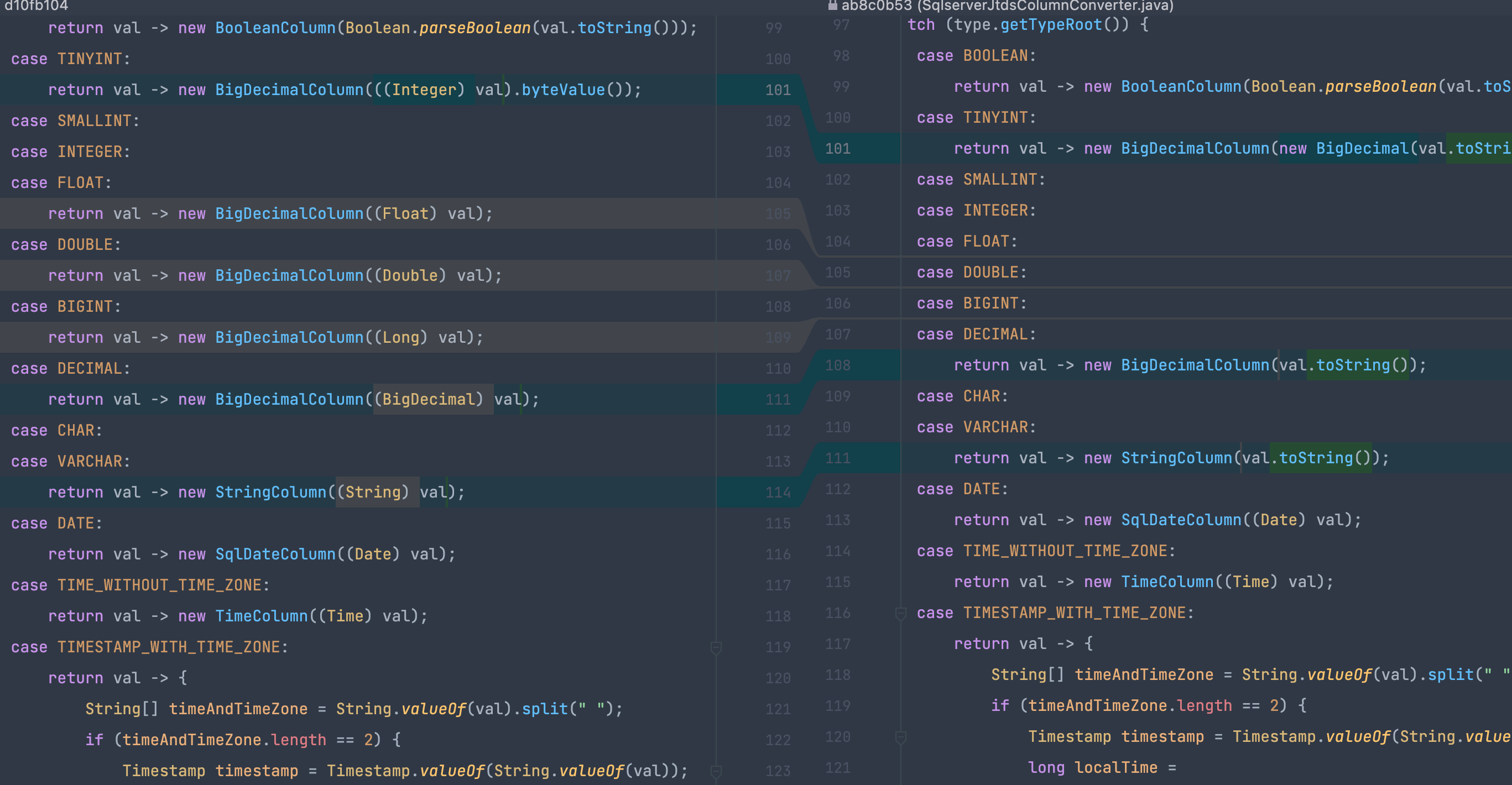
场景:类型转换异常
原因:convent设计不理解?没考虑过类型之间互相转换?
反思:验证的时候或者测试验证的时候 应该能直接发现的,但是为何没有发现?推测大概率是写的脚本是 int到int,double到doube,没有double-》float?测试场景需要添加
问题描述:1.12出现过numreader!=numwriter+errorcount
原因:很多地方有numwriter或者errorcount添加的地方,会出现重复累加的问题
反思:了解这个参数含义,知道这个应该在哪些地方,哪种场景下添加,不能这儿加一下 那儿加一下,要详细的了解业务场景。
业务对接问题
http://zenpms.dtstack.cn/zentao/bug-view-50421.html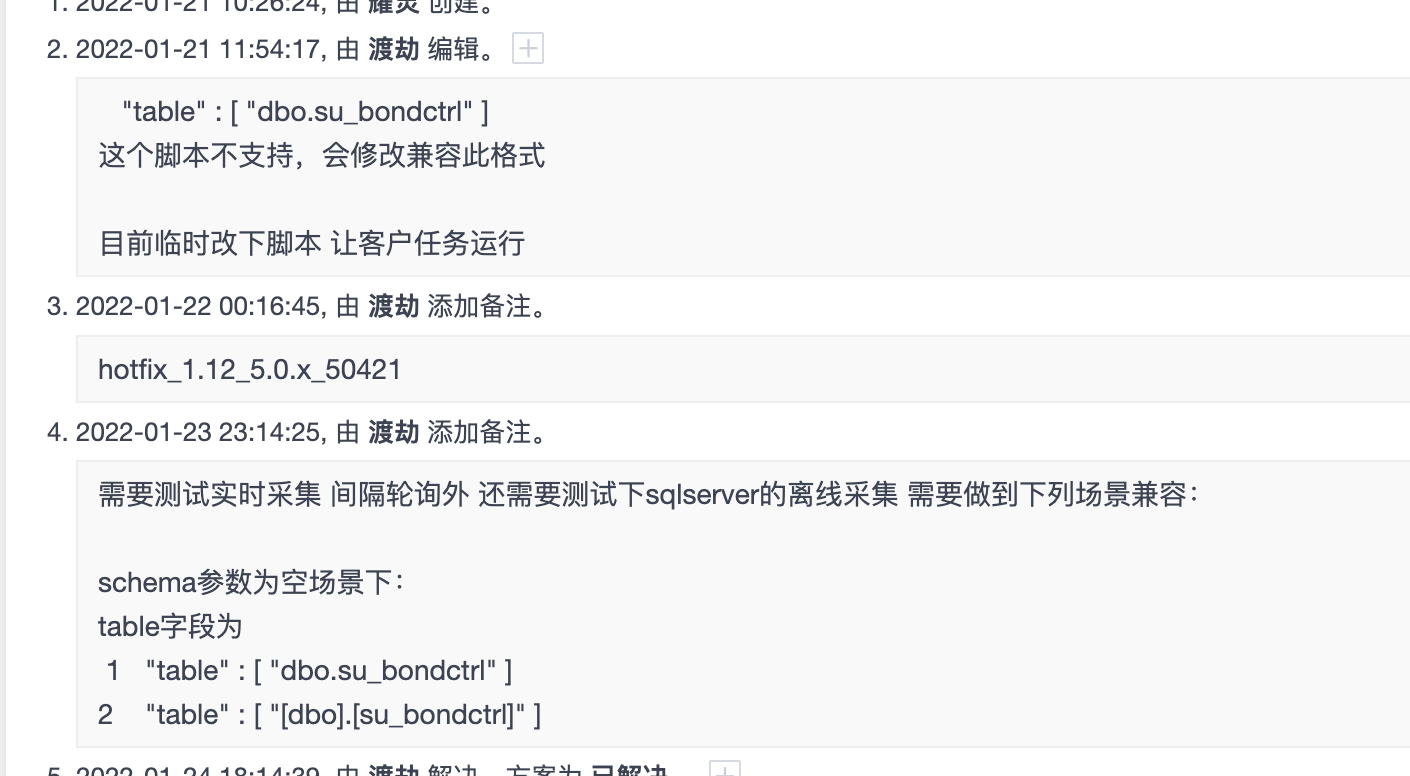
场景:实时任务表找不到
原因:传参格式不支持解析,离线支持,但是实时不支持
反思:以前和离线对过这种问题,兼容掉了,但是实时后面突然也换了,没有支持-》平台分为实时,离线,按产品对接就会出现这个问题,flink如何对接?如何判断?一直说flinkx独立产品,和业务侧如何对接呢?
http://zenpms.dtstack.cn/zentao/bug-view-51580.html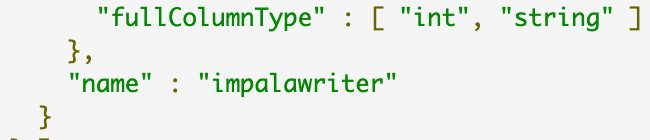
场景:自动化测试,impala插件写入失败
原因:没有impalawriter插件,对应的是kuduwriter 或者 hdfsWriter
反思:测试编写自动化脚本时应该知道这个逻辑,flink团队输出过
不该出现的问题
http://zenpms.dtstack.cn/zentao/bug-view-51464.html
场景:gbase类找不到
原因:gbase类是GBase,但是脚本是gbase找的类是Gbase所以报错
反思:百分百报错的问题,自测没发现?开发如何自测,测试如何测试?
http://zenpms.dtstack.cn/zentao/bug-view-52399.html
场景:打包失败
原因:代码没有格式化,但是注意得是这个是release分支打包失败
反思: 提交代码前执行 mvn spotless:apply 很难保证所有人每次提交前都会执行
git hook 的 pre-commit 也许可以解决https://blog.csdn.net/qq624202120/article/details/107443295
拖延症问题
http://zenpms.dtstack.cn/zentao/bug-view-49367.html
场景:hdfs不支持表字段类型是数组类型的
原因:以前把inceptor的校验去掉,hdfs没有去掉
反思:印象中是知道hdfs 和 inceptor都有这个问题,但是从逻辑上来说,测试只提了inceptor自然只改inceptor
http://zenpms.dtstack.cn/zentao/bug-view-51923.html
场景:kerberos多并行度下偶尔登录报错
原因:kerberos多并行度下存在一定kerberos文件覆盖问题,目前通过ftp下载kerberos文件到本地目录格式是通过jobId区分的,如果多并行度,则jobid相同导致会覆盖
反思:第一版改的时候考虑到jobmanager和taskmanager区分,由于时间关系临时只改了jobmanager区分,后续taskmanager区分的优化没及时解决掉。还是不能拖,该解决的时候就应该解决掉。
http://zenpms.dtstack.cn/zentao/bug-view-51408.html
场景:session任务运行hdfs orc任务失败
原因:inceptor类冲突,fliksql增加inceptor的支持,只测试了perjojb任务,没测试session
反思:inceptor大概率是会和hdfs出现类冲突,session应该跑一个hdfs的session任务,但是这个问题其实还是类加载问题
环境问题&优化
http://zenpms.dtstack.cn/zentao/bug-view-51927.html
场景:报错不规范
反思:对于参数校验报错,至少包含四要素:哪个参数报错,报错原因,正确的参数格式是什么,参数的原始值。这样报错才有意义,否则缺少关键字的报错,只能看代码看校验的逻辑才知道这个参数为什么报错。有效的参数校验或者一些逻辑报错应该是不知道代码的人能看出来为什么报错 应该怎么改。
http://zenpms.dtstack.cn/zentao/bug-view-52320.html
场景:zk验证失败
原因:flink高可用的zk没有开启kerberos,但是控制台配置了kerberos相关参数导致
反思:这种配置问题,能否加校验,数据源没有开启kerberos就不应该配置这个参数,如何判断数据源开启这个是一个问题
http://zenpms.dtstack.cn/zentao/bug-view-51933.html
这种环境问题其实第一时间就能判断出不是flinkx的问题,因为flinkx绝对不对多加字段,而且还是alibba数据源,不是通用的mysql。应该是二线团队过滤掉
http://zenpms.dtstack.cn/zentao/bug-view-51982.html
场景:读取客户的视图报错 单行返回多行
原因: 客户自己的视图数据有问题
反思:这种问题需要沉淀,技术支持应该要过滤掉(flinkx不会加上子查询即使有子查询也是客户自己写的customsql,那就是客户自己写的sql有问题)
http://zenpms.dtstack.cn/zentao/bug-view-50941.html
场景:任务运行失败
原因:flinkx的flink依赖1.12.5升级到1.12.7,但是测试不知道,flikjar还是1.12.5的
反思:基础依赖环境依赖改变,范围评审时需要通知到测试,运维,开发,但是我估计该出现这种问题还是会出现问题,测试很难定位到这种环境依赖jar包版本不对导致
拓展
场景问题需要开发在开发过程中意识到可能存在的一些特殊场景,第二测试也要想到一些特殊场景,而不是按照开发给出的场景测试,第三 测试对于线上出现的特殊场景需要总结,完善
很多参数配置都是看客户&技术支持了不了解,知道了就会填对,不知道到就可能该填的不填,不该填的填了,最终都是参数问题,但是排查很痛苦。能代码校验的就校验,不能校验的也应该有文档输出,参数含义要全。
很多必现的问题(可能在一定场景,但是也是比较正常的场景)到线上才发现,开发是否正确自测过,测试如何测试的
对于一些共性问题先按照当前客户场景解决,后续排期优化关联的其他类似插件是否有这个问题。应该让测试去测其他的插件看下是否有问题,有问题提禅道解决。
对于业务问题,比如和离线对了rdb的一些场景,实际上在实时中也有,但是实时的开发可能没和你对接,如何操作?一直埋头做插件相关在和各个平台之间对接会存在一定的局限问题
拖延症问题一般是解决了客户的问题,或者通过一个方法先绕过去,但是其实后面还是要优化或者调研解决,但是后续客户没问题了基本也就没管了。经常说的一句话是 最近很忙,没时间看。最近看到一本书里写的一句话总结的非常好 没时间看代表这件事情不重要。

若有收获,就点个赞吧
0 人点赞
