入口:
Clifronted执行用户代码入口类Main方法之后,执行env.execute()
public JobExecutionResult execute(String jobName) throws Exception {Preconditions.checkNotNull(jobName, "Streaming Job name should not be null.");// 获取 StreamGraph 并继续执行return execute(getStreamGraph(jobName));}
SPI创建ExecutorFactory
往下获取executor进行execute 提交任务
public JobClient executeAsync(StreamGraph streamGraph) throws Exception {checkNotNull(streamGraph, "StreamGraph cannot be null.");checkNotNull(configuration.get(DeploymentOptions.TARGET),"No execution.target specified in your configuration file.");//SPI获取到Pipeline的执行器工厂final PipelineExecutorFactory executorFactory =executorServiceLoader.getExecutorFactory(configuration);//加载进行提交CompletableFuture<JobClient> jobClientFuture =executorFactory.getExecutor(configuration).execute(streamGraph, configuration, userClassloader);。。。。。}
SPI加载的Executor
flink-clients模块SPI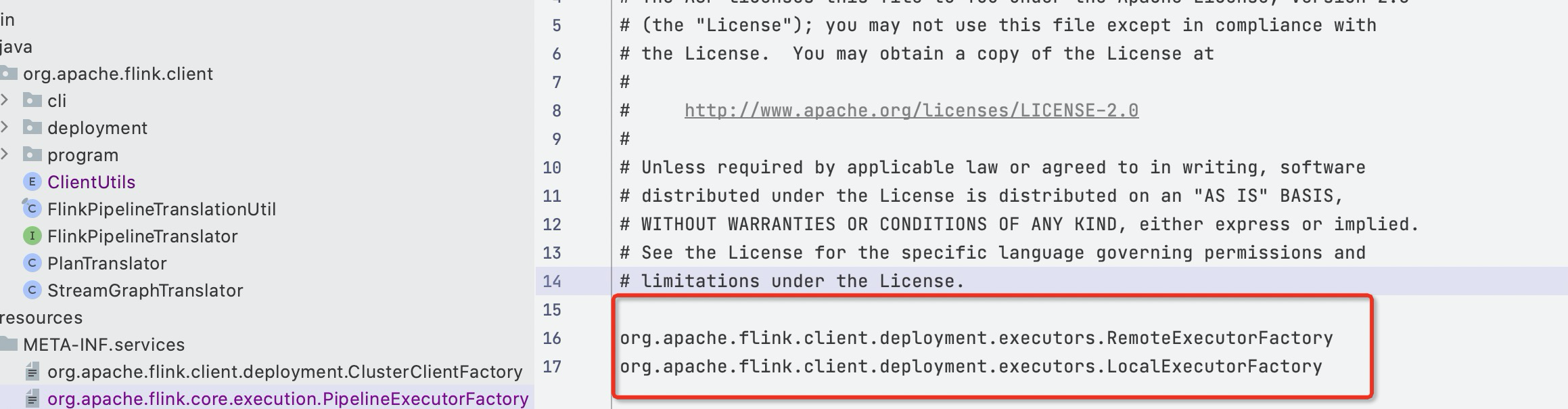
获取到Executor之后,RemoteExecutorFactory会创建RemoteExecutor进入其executor方法
standLone/Yarn-Session进入此方法org.apache.flink.client.deployment.executors.AbstractSessionClusterExecutor#execute
public CompletableFuture<JobClient> execute(@Nonnull final Pipeline pipeline,@Nonnull final Configuration configuration,@Nonnull final ClassLoader userCodeClassloader)throws Exception {final JobGraph jobGraph = PipelineExecutorUtils.getJobGraph(pipeline, configuration);try (final ClusterDescriptor<ClusterID> clusterDescriptor =clusterClientFactory.createClusterDescriptor(configuration)) {final ClusterID clusterID = clusterClientFactory.getClusterId(configuration);checkState(clusterID != null);final ClusterClientProvider<ClusterID> clusterClientProvider =clusterDescriptor.retrieve(clusterID);ClusterClient<ClusterID> clusterClient = clusterClientProvider.getClusterClient();return clusterClient.submitJob(jobGraph)}}
AbstractSessionClusterExecutor-StandLone/yarnSession入口
- 创建jobGraph
- 获取集群描述符ClusterDescriptor
- 获取client
submitJob提交任务
standLone获取RestClusterClient
- yarnSession获取
集群描述符ClusterDescriptor
standLone获取的Descriptor为StandLoneClusterDescriptor
Yarn获取的Descriptor为YarnClusterDescriptor
获取Client
clusterDescriptor.retrieve(clusterID).getClusterClient()
由ClusterDescriptor获取对应的Client,
standLone获取的Client为RestClusterClient
Yarn获取的Client为YarnClient
AbstractJobClusterExecutor-PerJob入口
@Overridepublic CompletableFuture<JobClient> execute(@Nonnull final Pipeline pipeline,@Nonnull final Configuration configuration,@Nonnull final ClassLoader userCodeClassloader)throws Exception {// streamGraph 转换为 jobGraphfinal JobGraph jobGraph = PipelineExecutorUtils.getJobGraph(pipeline, configuration);// 获取集群描述器 创建并启动了yarn的客户端,包含了一些yarn flink的配置和环境信息try (final ClusterDescriptor<ClusterID> clusterDescriptor =clusterClientFactory.createClusterDescriptor(configuration)) {final ExecutionConfigAccessor configAccessor =ExecutionConfigAccessor.fromConfiguration(configuration);//获取集群特有信息,资源配置 jobManager内存 taskManager内存 每个TM的slot数final ClusterSpecification clusterSpecification =clusterClientFactory.getClusterSpecification(configuration);final ClusterClientProvider<ClusterID> clusterClientProvider =//部署job集群clusterDescriptor.deployJobCluster(clusterSpecification, jobGraph, configAccessor.getDetachedMode());return CompletableFuture.completedFuture(new ClusterClientJobClientAdapter<>(clusterClientProvider, jobGraph.getJobID(), userCodeClassloader));}}

若有收获,就点个赞吧
0 人点赞
