摘要:
受提供关于轨迹数据全面知识的趋势的启发,我们研究了多属性轨迹,每个轨迹都包含一系列带时间戳的位置和一组特征属性。通过提供对运动对象的全面描述,可以丰富数据表示,从而可以对运动对象的轨迹进行新型查询。在本文中,我们考虑回答范围查询,这些查询返回的轨迹是(i)包含特定属性值,并且(ii)在查询时间内经过某个区域。我们将标准轨迹和属性集成到一个统一的框架中,并提出了一种索引结构以及查询算法。就处理多属性轨迹和标准轨迹而言,该结构是通用且灵活的,回答一系列查询并支持更新密集型应用程序。评估是在原型数据库系统中进行的,实验结果表明,在一百万条真实轨迹和综合属性值的数据集上,我们的方法比其他方法要好3-10倍。
1INTRODUCTION
TRAJECTORY数据库用于管理移动对象的历史数据,从而可以进行复杂的查询和过去的移动分析。尽管有大量关于建模和查询轨迹数据的文献,但是现有的研究工作主要集中在标准轨迹上,即一系列带有时间戳的位置。在现实世界中,除了位置和时间以外,诸如车辆和人员之类的典型移动物体还与描述性信息相关联。移动对象数据库应该扩展功能,使其具有完整的表示形式,可以处理标准轨迹和属性。这允许用户通过将属性集成到查询中来查询具有广泛知识的对象并找到特定的轨迹。因此,用户可以完全了解移动物体的行为,即,不仅知道何时何地,而且知道什么以及什么。多属性数据表示提供了现实世界对象不同方面的概述,并且最近涉及许多新应用程序[1]。
在本文中,我们关注于多属性轨迹,其中每个对象的内容均由带时间戳的位置和描述性属性组成。GPS数据包含位置和时间,但不足够。我们需要结合不同的数据源。随着允许用户包括时空参数和属性值以发现有趣的旅程,查询得到了扩展。考虑一个存储城市中车辆行驶的数据库。每个行程都包含一个标准轨迹和两个在域上的属性值:COLOR = {红色,银色,灰色}和BRAND
= {BENZ,BMW},如图1所示。我们回答包含一个属性值元组和一个时空框的查询,例如,“是否有任何银色宝马在[t1,t2]期间通过区域?”。我们研究布尔范围查询,该布尔范围查询将报告包含查询属性值并满足时空条件的对象。在示例中,返回o3。据我们所知,该问题尚未在文献中进行研究。
最近,研究人员已开始研究用语义数据注释的轨迹[2]。标签贴在地理位置上,以描述用户访问过或在其上进行过活动的地点。但是,当前的语义数据仅限于位置。这与我们考虑位置无关属性的工作正交。首先,多属性轨迹代表对象的不同方面,例如类别和角色,并将属性与标准轨迹组合在一起,以具有完整的运动对象图。这可以支持不同的(甚至更广泛的)应用范围。因为在旅行者的所有位置之间可能有语义上的偏僻,而属性却没有,所以语义上的稀疏定义很少。在[3]中研究的基于相似度的搜索通过结合空间相似度和关键词相似度来定义得分函数来排名对象。但是,这实际上是一个空间查询,没有考虑时间和语义也取决于位置。
其次,在设计索引时将执行不同的任务。语义轨迹的索引根据位置和语义对对象进行分组,但是多属性轨迹中的属性与位置无关。我们可以通过将属性附加到位置来使用语义轨迹索引,但这不适合仅涉及属性的查询,例如“找到所有SILVER BMWs”。要回答该查询,我们必须使用传统索引,例如B树。因此,语义轨迹索引主要用于回答涉及位置和语义的查询,但是它们的性能通常不是最佳的。
为了有效地处理多属性轨迹,本质上需要一个索引,因为对数据库进行顺序扫描对于大型数据集而言过于昂贵。一个人可以分别在标准轨迹和属性上使用两个单独的索引(例如3D R树和B树)。问题是,当查询在两个部分上评估选择谓词时,将对分别检索的两个候选集执行相交。面临的挑战是如何设计同时管理两个部分并允许评估AND谓词的集成结构。同时,该结构应通用且灵活,以支持对多属性轨迹和标准轨迹以及更新密集型应用程序的一系列查询。我们在本文中做出了以下贡献:
- (i)我们引入多属性轨迹,给出数据表示并定义一个新查询。
- (ii)我们提出了一种混合索引结构和一种有效的算法来回答对多属性轨迹的范围查询,以及一种针对该索引的有效更新方法。
- (iii)使用大型真实数据集,我们进行了广泛的实验研究,以证明我们的方法在效率和可扩展性方面优于五种替代方法。
本文的其余部分安排如下。第2节概述了相关工作。第3节定义了多属性轨迹和查询。第4节和第5节分别介绍了索引和查询算法。第6节提供了更新方法。第7节报告了实验评估,其次是第8节的结论。
2RELATED WORK
在文献中,许多研究都集中在查询标准轨迹上,例如最近邻,相似性查询和预测[4]。已经提出了许多指标[5],[6]。但是,这些技术仅处理没有属性的时空观点。多属性轨迹是在广泛的上下文中定义的,方法是使用领域特定的属性注释轨迹,以便用户可以发出结合移动对象不同方面的查询。现有方法无法直接应用,因为如果不评估属性将产生错误的结果,或者由于无法使用时空索引来评估属性而导致性能不佳。
2.1 Semantic Trajectories
最近,带有语义数据的轨迹越来越受到关注[7]。语义丰富的轨迹通常被定义为一系列带时间戳的地点,其中每个地点都由带有语义标签的位置(例如旅馆,饭店)表示。通过在空间,时间和语义方面对轨迹进行分组,可以发现频繁的模式。同样,活动轨迹被定义为与活动相关的一系列地理空间点。活动代表用户可以在某些地方进行的诸如体育,餐饮和娱乐之类的活动[2]。查询返回k条轨迹,其语义包含某些活动并且具有最短的匹配距离。在活动轨迹数据库上也研究了有效的相似性搜索[3]。在[8]中,跨越不同地理空间的轨迹包括带有时间戳的位置和一系列的运输模式,例如“室内!步行!汽车,并回答包含运输方式的查询。
这些作品使用补充信息处理轨迹,但是扩展的数据仅限于诸如景点和活动之类的位置。我们打算表示不能从几何轨迹和地理环境派生的与位置无关的属性。多属性轨迹将导致新的查询,这些查询将考虑属性匹配以及空间和时间参数上的相交条件。
在[9]中研究了异构k最近邻查询。运动对象由位置无关的属性和一组坐标表示。通过定义将距离成本和与位置无关的属性组合在一起的函数,查询将返回第k个最小值的对象。尽管该工作考虑了位置无关的属性,但仍存在三个主要差异。首先,数据表示的范围受到限制,因为每个移动对象仅与一个属性相关联。我们认为多个属性具有通用的解决方案。其次,他们基于距离和属性的排名函数评估对象,但是我们要求属性完全匹配。这导致不同的查询结果。第三,它们的距离函数与时间无关,但是我们处理时空查询。
提出了一个通用模型来捕获从标准轨迹(称为符号轨迹)中获得的广泛含义[10]。这样的轨迹由时间相关的标签表示。例如,标签可以是道路,模式和速度曲线的名称。然而,符号轨迹集中在语义标签上,而不考虑地理位置。
2.2空间关键词搜索
空间关键词查询(简称SKQ)已在文献中引起广泛关注[11]。典型的SKQ将地理位置和一组称为关键字的文本描述作为参数,并返回满足其他查询条件的对象。布尔kNN查询[12]返回靠近查询位置并包含查询关键字的对象。前k个NN查询[13]返回具有最高得分的对象,该得分由到查询位置的距离和与查询关键字的文本相关性的组合测得。为了有效地回答查询,将2D R-tree这样的空间索引和文本索引结构进行了组合。例如,IR树为R树的每个节点提供一个指向反向文件的指针,该文件包含对应子树中对象文本内容的摘要。在查询处理期间,组合的结构用于估计空间距离和文本相关性,并修剪对结果没有贡献的空间对象。
与研究地理位置和文本描述的SKQ相比,多属性轨迹在原则上是通过标准轨迹和属性的组合来定义的。这两个问题扩展了传统的空间和运动对象,以丰富数据表示。但是,存在一些显着差异。在数据表示方面,SKQ专注于静态地理位置和与位置有关的文本描述。另一方面,多属性轨迹处理具有位置无关属性的移动对象。文本描述和属性需要索引结构的不同设计。在SKQ中,索引根据空间距离和位置文本相关性对对象进行分组。在我们的问题中,属性不依赖于位置,而是与整个轨迹相关联。此外,布尔范围查询已经在空间关键词搜索中进行了研究[14],但没有针对多属性轨迹进行研究。
3问题定义
3.1标准轨迹
标准轨迹通常由从时间到2D空间的函数建模。在数据库系统中,实现了离散模型,并且连续变化的位置由时间的线性函数表示。我们通过一系列所谓的时间单位定义每个轨迹,如图2所示。每个单位记录一个时间间隔内的起点和终点位置,并且起点和终点之间的位置通过插值估算。为标准轨迹定义了称为mpoint的数据类型。轨迹的综合框架在[15]中提出。
3.2 Multi-Attribute Trajectories
多属性轨迹由一系列带时间戳的位置和一组属性组成,用o(Trip,Att)表示,其中Trip为标准轨迹,Att定义一组d属性。每个属性的域由dom(Ai)(i 2 [1,d])表示。我们定义多属性的数据类型如下: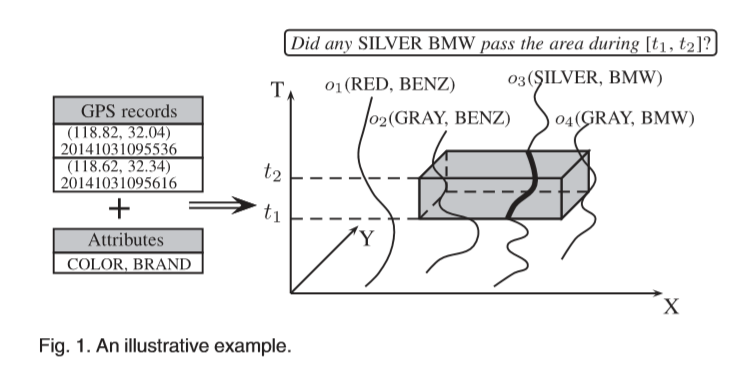
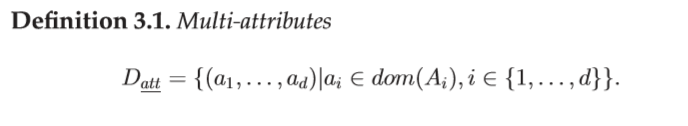
使用图1中的示例,我们有两个属性A1 =颜色和A2
=品牌,其域dom(A1)= {红色,银色,灰色},而dom(A2)= {BENZ,BMW}。我们使用关系接口将标准轨迹和属性集成到一个框架中。表1给出了图1中多属性四边形的表示。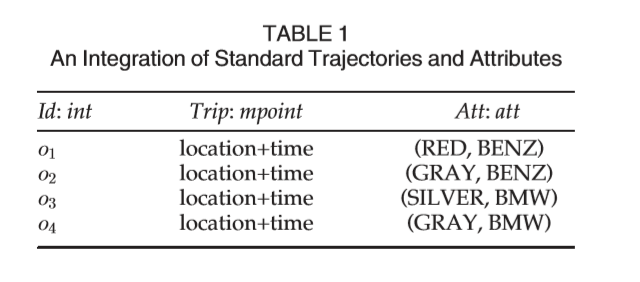
利用关系接口,多属性轨迹由包含mpoint和d值属性的元组表示。集成方法的优点是:(i)可以利用现有的轨迹运算符和关系运算符来制定查询,以及(ii)从多属性轨迹中提取标准轨迹,从而以一种灵活的方式来操纵数据。这有益于系统开发。
范围查询是轨迹数据库中基本操作的一个查询。我们将属性合并到查询中,并评估属性值的精确匹配。令O表示一组多属性轨迹。给定一个元组属性值Qa¼ða1;
…;adÞðai2domðAiÞ或ai¼?Þ和多属性轨迹o 2 O,我们定义了ato.AttcontainsQa if8ai 2Qa:ai 2o.Attorai =?。该查询称为RQMAT(RangeQueries关于多属性轨迹的定义如下。
定义3.2(RQMAT)。给定一个时空窗口Qbox和属性值Qa,该查询返回一组轨迹O0 O,使得8o2O0:ðiÞo:Att包含Qa;andðiiÞo.Trip与Qbox相交。
使用图1中的查询,属性值的格式为Qa =(SILVER,BMW)。我们可以使用类似SQL的语言来表达查询。
4 INDEX
标准轨迹索引无法管理属性,并且会抑制性能,因为此类索引不允许我们对属性值执行选择。另一种选择是建立一个单独的属性索引并首先评估属性条件,以获得包含查询属性值的轨迹。如果属性谓词是选择性的,则查询成本对于顺序扫描是可以接受的,因为仅处理少量数据集。如果属性谓词的选择性低,则将返回大量轨迹。顺序扫描和在线索引构建都需要很高的计算成本。
为了有效地回答RQMAT,我们开发了一种索引结构来管理多属性轨迹,如图3所示。其思想是让索引保留时空邻近性并保持属性值。该结构包括用于索引标准轨迹的3D R树和名为AttRec(属性和记录)的结构,用于维护R树节点中包含的属性值。AttRec包括用于存储属性值的关系和用于存储R树节点的一组记录。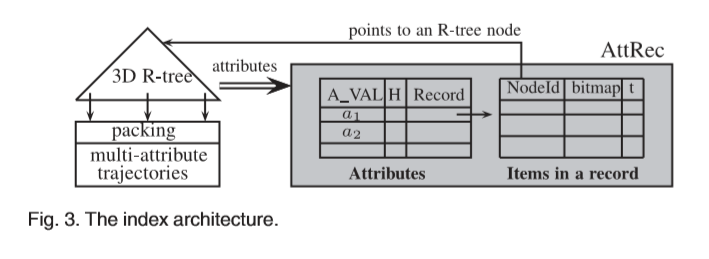
原始标准轨迹数据在短时间间隔或缓慢移动方面包含许多小的时间单位。我们通过打包小块动作来处理标准轨迹,以减少构建索引的对象数量。之后,我们通过在打包的轨迹上批量加载来构建3D R树。每条轨迹都由3D边界框近似。R树节点包含多个条目,每个条目都存储一个项对:一个边界框,该边界框是空间和时间数据的并集信息,以及指向子树或轨迹的指针。在R树的顶部创建了结构AttRec,以建立属性值和R树节点之间的连接。为了以统一的方式索引属性值,我们将每个值映射到一个整数,并且不同域之间没有重叠。这是通过对每个属性值使用二维点(x,y)(x,y2Zþ)来完成的,其中x是属性id,y是值。然后,我们对x和y的二进制表示进行交织以达到组合值。
令dom(Att)= S
di¼1domðAiÞ表示整个域。对于每个a2dom(Att),我们创建一个关系来记录在R树的每个级别上包含a的节点,其中A_VAL是属性,H是级别,Record是一个记录,其中存储了包含属性值的节点。在根级别,只有一个节点包含该值。在叶级别,大量节点可能包含该值。
每个记录都维护一个列表项:每个项定义一个位图,以标记节点中的条目,其中包含这些条目的属性值和联合时间。在查询处理期间,我们使用位图快速确定包含查询的条目(子树),而不是对所有条目执行顺序扫描。通常只有几个条目可以满足条件,特别是当遍历到达R树的低层时。该方法确保除根节点外,每个访问的节点都包含查询(属性值中的至少一个),并修剪子节点而不将其从磁盘加载到主内存中,从而降低了CPU和I / O成本。根据运行示例,结构AttRecin的一部分如图4所示。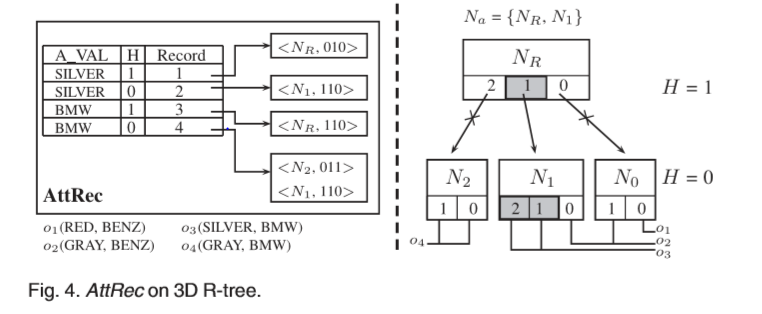
5 QUERY PROCESSING
查询处理分两个步骤运行。步骤1访问AttRec,以确定包含查询属性值且与查询时间重叠的R树节点。步骤2使用从步骤1返回的节点以及时空框对R树执行广度优先搜索,在此期间,将基于时空参数和属性值修剪搜索空间。图5概述了该过程。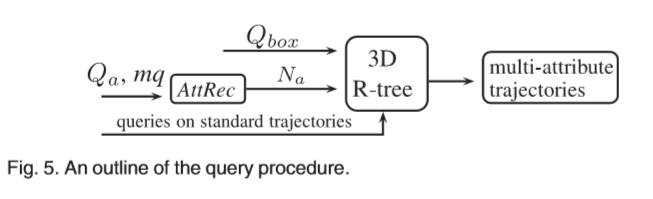
我们的方法结合了3D R-tree和AttRec,并且能够灵活地选择构建传统轨迹索引还是混合索引,具体取决于处理的是标准轨迹还是多属性轨迹。AttRec并未紧密集成到3D R树中,因此可以广泛地建立在许多其他轨迹索引上,例如TB树[5],SETI [16]。此外,AttRec仅用于属性评估,并且在访问轨迹索引时将评估时空参数。结果,使用所提出的结构也可以回答具有属性的最近邻居和相似性查询,从而使我们的方法具有通用性。
5.1 Select R-Tree Nodes
3D R树仅管理标准轨迹,而不知道属性值。为了确定包含查询值的对象,我们访问AttRec查找满足属性条件的节点。也就是说,我们搜索存在包含Qa的轨迹的节点。对于每个属性值,我们搜索AttRec以查找元组并获取记录。记录中的每一项都由(NodeId,b)表示,其中NodeId是节点ID,b是包含该值的位图标记条目。我们为每个属性值获得一个这样的项目,并在位图上执行交集以找到包含查询的条目。
令T为返回R树节点的定义时间和查询轨迹的函数。我们评估节点的时间维度,并检查在返回的节点集中是否存在项目(候选节点)(用Na表示)。如果不是,我们通过添加一个由1初始化的计数器来插入项目。如果是,我们通过执行AND操作来增加计数器并更新位图。最后,我们删除Na中对结果无用的项目。该算法在算法1中介绍。
证明。d.counter6¼jQaj:d.counter> jQaj是不可能的,因为要计数不同的属性值。如果d.counter 
基于图4,我们在图6中说明了Qa =(SILVER,BMW)的选择过程。我们首先找到包含SILVER的节点,然后评估它们是否包含BMW。N2将被删除,因为计数器仅为1。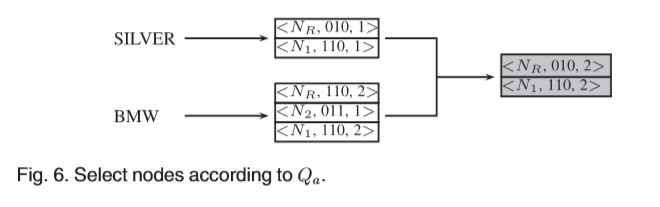
5.2 The Algorithm
我们以自上而下的方式遍历由R表示的R树,在此期间,我们从算法1评估节点上的时空条件。算法在算法2中给出。
图4举例说明了该过程。通过访问AttRec,我们找到NR和N1,然后逐级遍历R树。N2和N0被删除,因为它们不包含(SILVER,BMW)。我们访问节点N1,测试条目并报告o3。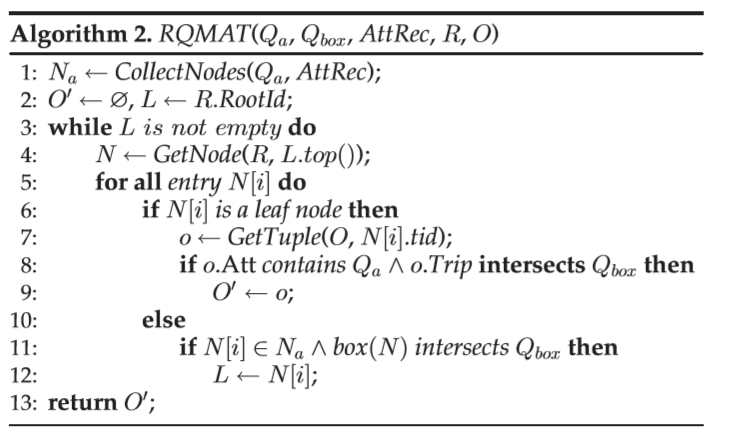
6UPDATE
更新密集型应用程序需要数据库系统有效地支持更新。一个重要的任务是同步索引结构。给定一组新的多属性轨迹,我们需要更新两个结构:(i)3D R树和(ii)AttRec。通常,将在新数据集Ou上创建一个名为Ru的新R树,并在Ru上构建AttRecu结构。然后,将Ru和AttRecu插入到现有的结构中,以使结构增长并与基础数据同步,如图7所示。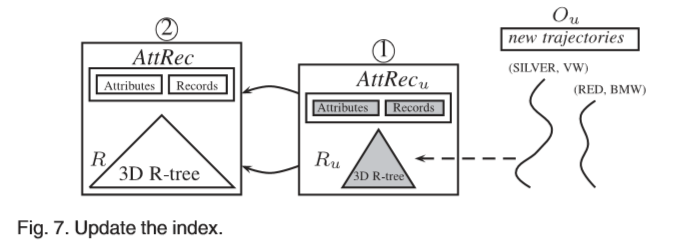
更新包括两个阶段:更新3D R-tree和AttRec。我们将重点放在第二阶段,因为第一阶段很简单。我们在Ru上创建AttRecu,并将Ru和AttRecu都插入到现有结构中。通过记录从根节点到Ru所在节点的路径Pu,将Ru插入R。从叶到根级别,节点的高度越来越多,从而确保R和Ru保持一致。通过附加元组将AttRecu插入到AttRec中。最后,我们为出现在Pu中的每个节点更新相应的记录。精确地,根据Ru中包含的属性值更新位图和时间间隔。更新算法在算法3中给出。
我们的方法具有低延迟,这对于在线应用程序很重要。当创建Ru和AttRecu但尚未将其插入R和AttRec时,可以执行评估。当系统检测到插入未完成时,我们可以分别搜索R,AttRec和Ru,AttRecu,然后对这两个部分执行联合以得到最终答案。
7EXPERIMENTAL EVALUATION
实验评估在可扩展的数据库系统SECONDO [17]中进行。该实现用C / C ++编程。使用运行Suse Linux 13.1(32位,kernelversion3.11.6)的标准PC(Intel®Core™i7-4770 CPU,3.4 GHz,4 GB内存,2 TB硬盘)。
我们使用北京的真实出租车轨迹,这些轨迹是从DataTang [18]公司购买的。图8a报告了标准轨迹的统计数据。由于缺乏实际属性,因此我们通过定义属性的数量和域来生成数据。每个属性的值都是从域中随机选择的。查询参数报告在图8b中。Qbox是随机生成的,其大小X
= DX的30%,Y = DY的30%,其中DX和DY分别是x和y维度的长度。时间间隔是总时间的40%。可以任意放大或缩小时空窗口。我们进行了一些初步测试,发现较小的窗户可能不会收到任何结果。我们专注于评估受属性影响的性能,因此保持Qbox的大小不变。查询属性jQaj2 [1,d]的数量有所变化,其中默认情况下我们设置jQaj = 3。图8c报告了属性的设置,其中索引存储成本包括3DR树和AttRec。
7.1 Alternative Methods for RQMAT
- (i)3D R树。该方法使用标准轨迹的索引来找到与Qbox相交的对象,然后顺序执行属性评估。
- (ii)3D R树+属性集(简称RAttSet)。这个想法类似于在空间关键字查询中使用的IR树[13],它用子树中空间对象的关键字摘要对每个R树节点进行论证。RAttSet将由轨迹定义的属性值集存储在子树中。我们以自上而下的方式遍历树。对于每个访问的节点,我们利用设置的属性值来修剪搜索空间。当属性值取决于位置时,该方法是有效的。可以根据位置和属性值将关闭的对象分组。但是,我们问题中的属性与位置无关,根据接近程度对d值属性进行分组并不是一件容易的事。此外,汇总信息能够判断特定值是否存在,但是不能确定哪些条目(子树)包含该值。将对所有条目执行顺序扫描,以将子节点加载到主内存中进行评估,这将导致CPU和I / O成本的增加。如果考虑多个值,则需要根据相交条件评估节点。但是,存储的摘要信息无法做出决定。
- (iii)4D R树。对于每个多属性轨迹,我们通过将(a1; …; ad)分解为d个单个值并将每个值与标准轨迹组合,将属性值(a1; …; ad)分布到d个轨迹。这导致d个轨迹,每个轨迹仅包含一个属性。例如,o1(RED,BENZ)将变为o0 1(RED)和o00 1(BENZ)。因此,我们将获得四个维度的数据:位置(x + y),时间和单个值属性。为了回答查询,人们将时空窗口和属性值结合在一起,形成一个高维查询框。令jQaj d为查询属性值的数量。我们需要jQaj查询框。仅当在d个轨迹中有jQaj个轨迹与查询框相交时,才返回该轨迹。该方法将数据集放大了d倍,并且在对较大d的对象进行分组时无法获得良好的局部性。
- (iv)IOC树。文献[19]提出了一种混合索引,该索引由称为八叉树的三维四叉树的反向索引和集合组成,以回答轨迹上的空间关键词范围查询。通过将属性定义为关键字来扩展该方法以解决我们的问题。开发了属性值的反向索引,其中每个值都与存储相关轨迹点的八叉树相关联。由于我们的属性与位置无关,因此轨迹的所有位置点都将放入八叉树。保持的轨迹点的显着增加会导致索引开销并降低查询性能。
- (v)HAGI。我们还实现了[9]中的分层聚合网格索引(简称HAGI)和相应的查询算法,以解决我们的纸张问题与最近的邻居查询有关的问题。HAGI中的每个节点都维护子树中存储的最小和最大属性值下降对象。
7.2 Performance
在评估中,将CPU时间和I / O访问用作性能指标,并将结果平均20次运行。
规模d。结果报告在图9中。我们的方法明显优于所有其他方法。当d> 1时,我们的解决方案始终比替代方法快至少8倍。实际上,由于属性谓词具有良好的选择性,当d变大时,性能会提高,从而导致较少的节点和轨迹可用于时空评估。
比例dom(Att),d =1。从图10可以看出,当jdom(Att)变大时,所有方法的性能通常都会提高。原因是,当jdom(Att)j增大时,每个属性值的轨迹数会减少,并且属性选择性会增加。除了在某些情况下IOC-Tree的I / O成本接近我们的方法外,我们的方法在所有情况下都大大优于其他方法。这是因为IOC树为每个属性值维护一个八叉树,并且当d = 1时,关键字优先修剪策略是有效的。
改变jQaj。此部分演示了jQaj对性能的影响。图11表明,在大多数情况下,我们的方法比其他方法快一个数量级。
更新性能。我们进行了两个实验:扩展jDuj并执行一系列更新。如图12所示,结果表明,缩放jDuj时,时间成本略有增加,除了从50,000到100,000的急剧曲线。为了评估连续更新的性能,我们为每个更新设置jDuj = 50,000,并连续执行10次更新。时间成本以累积方式报告。8CONCLUSIONS
我们提出一种有效的方法来回答多属性轨迹上的范围查询,并证明该方法相对于大型数据集上的替代方法的性能优势。

若有收获,就点个赞吧
0 人点赞
