1
论文背景
在数据库管理系统中查找某些关键字会导致很大的磁盘I/O开销,针对这一问题,通常会使用一个内存开销小并且常驻内存的过滤器来检测该关键字是否存在。比如现在常用的bloom过滤器对判断某个key是否存在是非常高效的,其能用极少的空间(与key长度无关),极低的出错概率判断key的存在性。
现有的过滤器都仅仅支持point
query,例如现在RocksDB里面有一张学生表,现在要做查询,找出年龄等于18岁的学生,我们可以通过使用布隆过滤器减少磁盘IO,从而缩短查询时间。但是现在查询请求变成了学生表中是否含有年龄段在22到25之间的学生,这个时候布隆过滤器就没有办法工作了。
这篇论文的核心是提出了一种基于succinct data structure的trie树,同时对该树进行合理的编码,从而降低占用内存的大小,同时保留查询能力,既支持point query,也支持range quey存在性。这篇论文2018年发表在数据库顶级会议SIGMOD,并获选SIGMOD年度最佳论文。
2
论文主要工作
作者通过改进传统是LOUDS编码提出了FAST SUCCINCT TRIES的设计,然后基于FAST SUCCINCT
TRIES提出了SUCCINCT RANGE FILTERS,最后在RockDB上测试SUCCINCT RANGE FILTERS的性能并与布隆过滤器进行对比。
2.1 FAST SUCCINCT TRIES
FAST SUCCINCT
TRIES是作者基于LOUDS(Level-Ordered Unary Degree Sequence)提出来的一种对Trie树进行编码的方式,它可以减小该树在内存中空间,同时保留了查询的能力。
LOUDS编码的原理为:
1)从根节点开始,按广度优先的方式去遍历这棵树。
2)扫描到一个节点时,该节点有n个孩子,则用n个1和一个0对这个节点进行编码。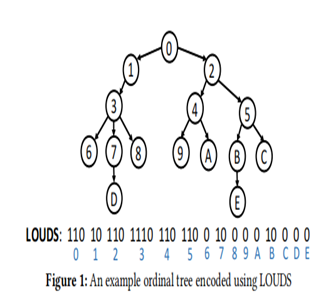
对这棵树编码完成后得到的是一组01字符串,现在根据这个字符串来访问树中的节点,可以总结成两个经典的操作:①通过父亲节点找孩子节点;②通过孩子节点找父亲节点。
为了能够实现上述两个操作从而实现访问树中的任意节点,根据该树的编码特点以及字符串的形式,定义了一些操作:
①
rank1(i) : 返回在 [0, i] 位置区间内 1 的个数;
②
select1(i) : 返回第i个1的位置(整个bit序列);
③
对应地,还有rank0(i)和select0(i)操作。
于是可以基于下面三个公式来访问整个树:
①
求层序遍历的第i个节点在比特序列中的位置:position(i-th node) = select0(i) +1
② 求在比特序列中起始位置为p的节点的孩子位置
first-child(i) = select0(rank1(p)) + 1
③ 求在比特序列中起始位置为p的节点的父亲位置
parent(i) = select1(rank0(p))
基于LOUDS编码,作者对整棵树设计了一种混合编码方法,称为LOUDS-DS编码,即上层节点通过Dense编码,下层节点通过Sparse编码,分界点是可以调整的,以适应不同的空间以及性能的权衡。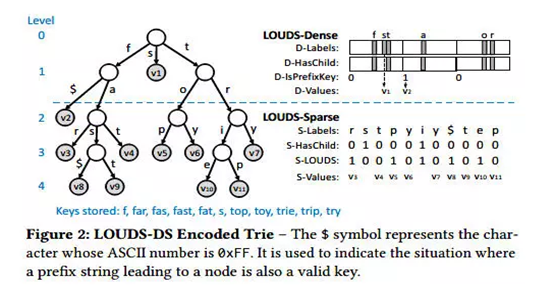
1)LOUDS-Dense编码
每个节点最多有256个子节点, 那么在LOUDS-Dense编码方式中, 每个节点使用3个256个bit的bit map和一个bit序列来保存信息. 它们分别是:
① D-Labels : 为节点中的每一个值做一个分支标记。例如根节点有以 f,s 和 t作为前缀的三个分支,那么会将这个大小为256的bit map的第 102(f),115(s) 和 116 (t)bit 位就会设置为 1,具体哪一个bit 位,就是
ASCII 码的值。
② D-HasChild : 标记对应的子节点是否是叶子节点还是中间节点。以根节点的三个分支为例,f 和 t 都有子节点,而 s 没有,所以 102 和 116 bit 都会设置为
1。
③ D-IsPrefixKey : 标记当前前缀是否是有效的key。
④ D-Values : 存储固定大小的
value
在LOUDS-Dense中的计算公式为:
①孩子节点:D-ChildNodePos(pos)=256×rank1(D-HasChild,
pos)
② 父亲节点: DParentNodePos(pos)=select1(D-HasChild,⌊pos/256⌋)
③ Value位置:D-ValuePos(pos)
= rank1(D-Labels, pos) - rank1(D-HashChild, pos) + rank1(D-IsPrefixKey, pos /
256) – 1
2)LOUDS-Dense编码
使用3个bit序列来对trie树进行编码, 在整个bit序列中, 每个节点的长度相同, 这三个bit序列分别是:
① S-Labels(bit-sequences)
: 直接存储节点中的值,按照 level order 的方式记录了所有 node 的 label,用0xFF($)标记该前缀也是key节点(作用相当于LOUDS-Dense中的D-IsPrefixKey )。
② S-HasChild(one
bit) : 记录每个节点中的label是否含有分支子节点, 有的话标记为1, 每个label使用一个bit。
③ S-LOUDS(one bit)
: 记录每个label是否是该节点的第一个label。譬如上图第三层,r,p 和 i 都是本节点的第一个label,那么对应的 S-LOUDS 就设置为 1 了。
④ S-Values : 存储的是固定大小的
value,在本文中,表示的是指向之前说过三种后缀(hashed, Real, Mixed)的指针。
在LOUDS-Sparse编码中的计算公式为:
①孩子节点:S-ChildNodePos(pos) =
select1(S-LOUDS,rank1(S-HasChild,pos) + 1)
②父亲节点:S-ParentNodePos(pos)=select1(SHasChild,rank1(S-LOUDS,pos)-1)
2.2 SUCCINCT RANGE FILTERS
一棵不做处理的Trie树可以实现精确查询,但是占用空间太大,为了使它变小,就要去截断一部分后缀,只会保存最短的前缀且这个前缀可以与集合中其他元素不同,这棵Trie树被称为Surf-Base。Surf-Base只存能够最小区分不同key的前缀,导致FPR(False Positive Rate)就会很高。为了降低FPR,作者对SuRF-Base结构做了改进,提出了SuRF-Hash、SuRF-Real以及SuRF-Mixed三种结构。
SuRF-Hash:在base的基础上额外将key的后n个位的哈希值保存到FST的value array里面,不仅要在Trie树上面查找,还要对比hash值。它的优点是有利于Point查询,且保存的hash值每多一位,做Point quey的FPR就会减少一半;它的缺点是对Range query没帮助,不能减少FPR。
SuRF-Real:在base的基础上额外将key的前缀之后的key的n位保存到value array里面,SuRF-Real将存储的hash值的n个bit换成了真实key(即value中存放着key),例如上图的右部分表示添加了8bit的suffixes。它的优点是同时增强了Point query和Range query;它的缺点是关键字的区分度还是不高,在point查询下, 它的FPR比SuRF-Hash要高。
SuRF-Mixed:为了同时享受Hash和Real两种方式的优点, 将两种方式混合使用,存储的value中有一部分是real key,另一部分是hashed key,混合的比例可以根据数据分布进行调节来获得最好的效果。
2.3 性能测试
作者使用了两组key的数据进行性能对比测试。
一组是由YCSB输出的64bit的整数, 另一组是由字符串组成的电子邮件地址,,其中整数的key有50M个,电子邮件地址组成的key有25M个。
首先对比了SuRF不同模式和布隆过滤器在FPR上的对比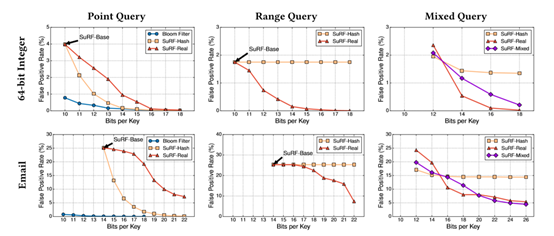
一般情况,在point
query下,SuRF比bloom filter稍差。随着SuRF-Hash的hash后缀的bit位数的增加,它对range query起不到任何作用。在Mixed query中,随着后缀的长度的增加,SuRF-Real对Point和Range
query都可以增强作用,所以它下降的最快,而 SuRF-Hash只对Point query起作用,所以它的后缀增加到一定后,只是将Point query的FPR降低了但是Range query的FPR不会变化,而在整数和Email的实验中SuRF-Real和SuRF-Mixed的变化趋势不同,是因为在整数中后缀添加一个bit,这个值变化很大,区分度高,但是相对于字符串,特别是邮箱,后缀添加一个bit,即便是一个字节,区分度可能不高。
作者又用SuRF的不同模式和bloom filter的做吞吐量对比,吞吐量实际上指的是查询速度。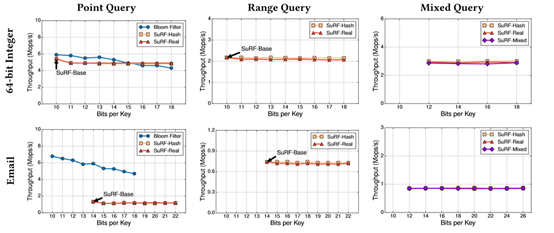
无论是Point,Range,还是Mixed Query下,SuRF的三种模式吞吐量差别不大,而且在做Point Query时,布隆过滤器的吞吐量还是相对高的。
作者又做了SuRF和布隆过滤器的点查询和范围查询性能对比,下图左侧表示的是Point query的性能对比,可以看出添加布隆过滤器后,查询时涉及的磁盘IO最少,它的吞吐量最大;图中右侧表示Range query的性能对比,此时SuRF的两种变体就有一些性能上的提升。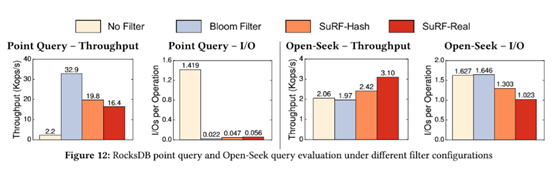
最后作者为了更大程度的显示SuRF的优势,于是做一组关于在range query时,故意设置一些查询语句返回为空时的性能对比试验,并逐渐增加这些查询语句在所有查询语句的比例,从图中可以看出随着查询中查询结果为空的比例不断增多,SuRF的性能就会不断的提升,而布隆过滤器的性能始终没有任何变化。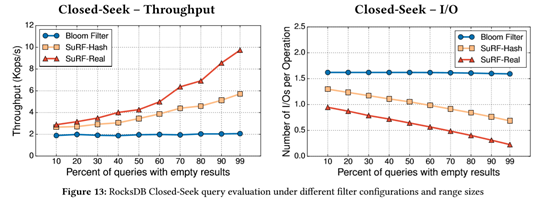
2.4 主要结论
FST的基本设计思想是基于一个树结构上层少部分节点拥有更多的访问次数而下层节点虽然多但是访问次数更少的现实,作者基于FST实现了SuRF,它既支持Point
query又支持Range query。SuRF是常驻内存的,而且很高效,它的FPR可以通过调整后缀的长度来降低。
在性能上,如果具体应用中针对Point query的FPR的要求很高,布隆过滤器则比SuRF更好。但是如果查询中出现empty result的情况很多的话,且关注性能的提升时,可以使用SuRF结构。
可以调节SuRF-Mixed中后缀部分hashed key和Real key的各自的长度,一般都是从SuRF-Real这种模式开始做调整,因为这种模式可以对Point query和Range query都很好,然后慢慢的逐步将Real 换成Hashed Suffixes。
3
心得体会
正所谓“尺有所短,寸有所长”,没有一种数据结构是完美的,但是每种数据结构都有自己的适用场景。每位作者在做实验时候都要体现出自己idea的优势,他做实验用的数据和场景可能更适合自己提出的东西。但是我们也不能认为被作者用来做对比的事物是一无是处的。在本文中,作者故意设置一些查询语句返回为空时的性能对比试验,来突出SuRF的优势。但是布隆过滤器依然是一种优秀的过滤器,应用范围还是更广些。
LOUDS编码已经提出很多很多年了,是比较老的一个东西,但是作者经过思考挖掘了它,新生的SuRF获评SIGMOD 2018最佳论文。可见虽然有很多人会研究经典的东西,论文也好,其他事物也好,但是总有人能发掘出新idea(难度另当别论),所以在科研的道路上,经典是会下金蛋的鸡,我们不要认为别人已经对它做了大量的研究,自己就不能提出新想法;也不要妄自菲薄,认真自己的idea没有价值,也许你认为的价值不大的东西会是后人重大发现的基础,这样的事在自然科学大厦建立的过程中并不罕见,开普勒提出的行星三大运动定律正是建立在第谷的记录之上的;瓦特蒸汽机也是对前人工作的改进。
最后,回到我们学科本身,在数据库领域,Succinct 是一个比较有趣的研究方向,也有很多数据库采用了 succinct 来保存数据,毕竟如果能用更少的空间存放数据,memory 能装的更多,cache 更友好,性能就更好。现在已经有不少精简数据结构提出来,但是真正能解决问题的不多,现在 succinct 还没有大规模的落地,可以看看后续的发展。

若有收获,就点个赞吧
0 人点赞
