数据库设计原则
范式 Normal Format
第一范式 1NF:字段的原子性
第二范式 2NF:消除对主键的部分依赖
第三范式 BCNF:消除对主键的传递依赖
事务 Transaction
事务特性
- 原子性 Atomicity
事务的操作要么全成功提交,要么全失败回滚;
依托于 undo log(回滚日志)保证;
- 一致性 Consistency
事务必须使数据库从一个一致性状态(事务提交前)转移到另一个一致性状态(事务提交后);
依托于 A+I+D 共同保证;
- 隔离性 Isolation
并发产生的事务之间不能相互干扰,无法感知其他并行事务的发生;
依托于 MVCC 或锁保证;
- 持久性 Durability
事务一旦提交,对数据库的改变就是永久性的,即使数据库产生故障也不会丢失事务操作;
依托于 redo log(重做日志)保证;
事务隔离级别
针对事务的隔离性,有着从低到高的4种隔离界别:
- Read Uncommitted
事务正在访问数据并产生修改,但还没提交到数据库中,若另一个事务也访问了该数据,这个数据就成为脏数据,即第二个事务发生了脏读;
- Read Committed(SQL Server和Oracle默认隔离界别)
事务只能读到其他事务已经提交的数据(解决了脏读),但如果在读的过程中,另一个事务将数据修改并提交,第一个事务再次读这个数据的时候就会发现不一致,即第一个事务发生了不可重复读;
- Repeatable Read(MySQL默认隔离级别)
事务进行中,其他事务不能修改第一个事务使用中的数据(解决了脏读和不可重复读),但如果第一个事务进行中,另一个事务新增/删除了一条数据,有可能会影响第一个事务的数据,即第一个数据发生了幻读;
幻读的实例: 先
select,发现没有已有数据后再insert,但发现插入失败 幻读的解决: 读数据分为”快照读”和”当前读”,单纯的SELECT属于前者,SELECT * FROM t LOCK IN SHARE MODE或SELECT * FROM t FOR UPDATE属于后者。 使用 next-key lock(行锁 + 间隙锁的组合)来锁住数据本身和行之间的间隙。重复读的解决: Multi-Version Concurrent Control,MVCC,多版本并发控制
- 事务提交之前的数据对其他用户不可见;
- 事务提交不会覆盖原数据,而是产生新版本数据,每个数据有多个历史版本,但同一时刻只有最新的版本有效(类似于CAS中的ABA问题);
- InnoDB中每一行数据有两个冗余字段:行创建版本、行删除版本,版本号随着事务的开启自增。
- Serializable
事务串行化按序执行(解决了脏读、不可重复读和幻读),但效率差开销高。
数据库的分布式锁
乐观锁
使用version字段进行版本控制,适用于小并发量,并发量过高会造成修改数据无效:
SELECT col, version as oldVersion FROM t WHERE id = <id>;-- <业务逻辑> --UPDATE t SET col = <new_col_data>, version = version + 1 WHERE id = <id> and version = oldVersion;
悲观锁
使用内置语法进行加锁行为,适用于高并发量,如果一直不commit其他请求的事务线程会一直处于阻塞,直到超时:
SELECT * FROM t WHERE id = 1 FOR UPDATE;-- <业务逻辑> --COMMIT;
多种加锁方式
一次性锁
一次性申请所有需要的锁,有一个锁不可用整个事务不执行,不会发生死锁,并发度较低。
二阶段锁
整个事务分为两段,前一个阶段只能加锁、操作数据,后一个阶段只能解锁、操作数据,可能发生死锁。
存储引擎
| InnoDB | MyISAM | |
|---|---|---|
| 适合场景 | 更新、删除频高 | 读写、插入为主 |
| 事务 | 支持 | 不支持 |
| 外键 | 支持 | 不支持 |
| 索引 | 聚簇索引,主索引与数据在一起 | 非聚簇索引,索引与数据分离 |
| 锁 | 行级锁(默认) + 表级锁 | 表级锁 |
| 文件存储方式 | .frm保存表,.ibd保存索引与数据 | .frm保存表,.myd保存数据,.myi保存索引 |
数据库中的锁
全局锁
- 使用方式
使用 flush tables with read lock 命令将整个数据库处于只读状态,使用 unlock tables 命令解锁。
- 应用场景
全库的逻辑备份,避免数据或表结构的更新造成问题(mysqldump 命令备份)。
表级锁
表锁
粒度较大,不推荐。
- 使用方式
行级锁
索引与优化
索引数据结构
B树
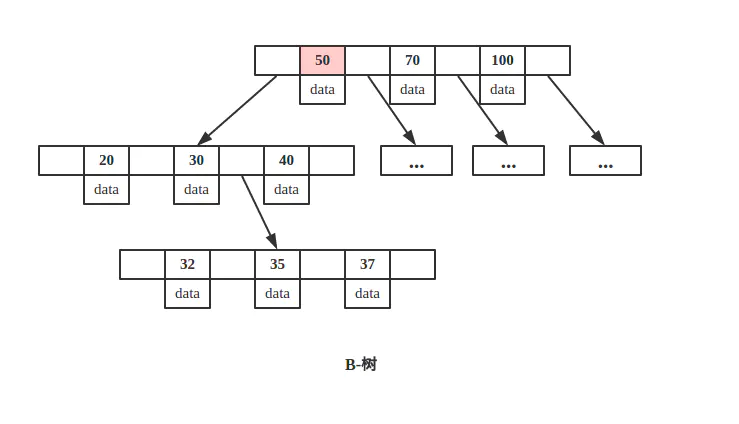
- 索引与数据存储在每个节点中;
-
B+树
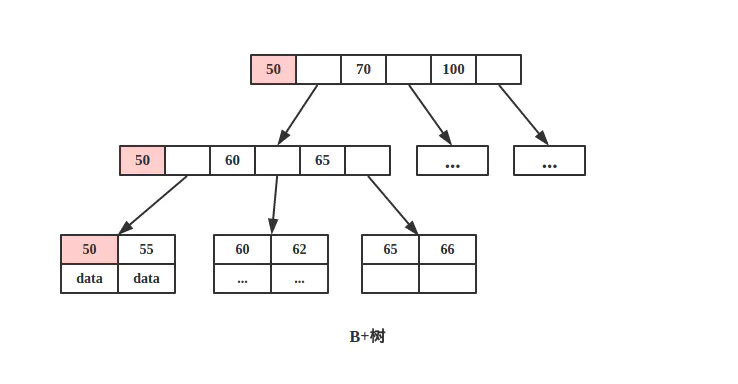
所有数据存储在叶子节点中;
- 所有叶子节点被双向链连接;
- 搜索过程固定时间复杂度(
 ),插入、删除时间复杂度为
),插入、删除时间复杂度为 ;
; -
Hash
对字符类数据适用;
- 不适合范围查找,需要避免哈希冲突;
-
跳表
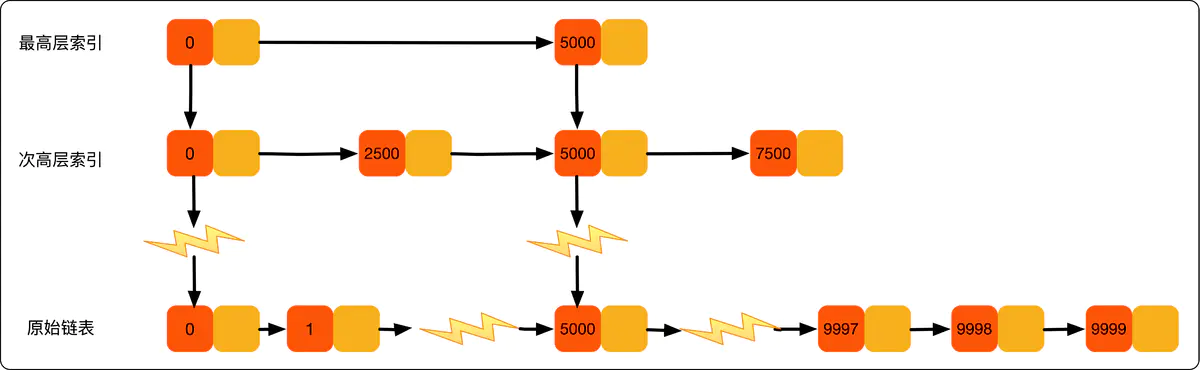
建立了多层索引的链表;
- 查找、插入、删除的时间复杂度都是
 ;
; - 插入删除需要维护索引:随机选
 个元素做为一级索引、随机选
个元素做为一级索引、随机选 个元素做为二级索引、随机选
个元素做为二级索引、随机选 个元素做为三级索引,以此类推到最顶层索引。
个元素做为三级索引,以此类推到最顶层索引。
索引分类
聚簇索引
索引与数据本身在一起(如主键索引所使用的B+树的叶子结点),一个表只能有一个聚簇索引;非聚簇索引
索引与数据分开,需要二次查找(B+树的叶子结点存储的不是数据本身,而是数据所在位置,通过二次IO查找到数据本身),一个表可以有多个非聚簇索引;联合索引
多个字段共同组成索引,使用索引需要满足最左索引(如index(A, B, C),可以支持以A/AB/ABC的索引查询方式,但不支持BC这种索引查询方式);
在底层数据结构上,B+树的非叶子结点存储的是A的索引,叶子结点按A、B、C的顺序对主索引进行排序。索引优化
索引建立准则
 )。
)。
 )。
)。
- 经常需要排序、分组、级联的字段(order by、group by、distinct、union等);
- 经常作为查询条件的字段(where);
-
索引失效场景
like左模糊查询;where进行了运算/函数;<>/!=/not in等范围查找;or查询索引列在非索引列后面。
索引失效实际举例:
对于创建了字段AB的联合索引,索引生效的场景:
SELECT * FROM t WHERE A = xxx/A <> xxx/A < xxx/A > xxx/;SELECT * FROM t WHERE A = xxx AND B = yyy;SELECT * FROM t WHERE B = yyy AND A = xxx;
索引失效的场景:
SELECT * FROM t where B = yyy/B <> yyy/B < yyy/B > yyy;
主索引使用自增整数的原因
- 存储空间小,比较速度快,一次性读入内存的索引量更多。
- 快速插入,直接插入到叶子结点末尾,一页写满自动开辟新页,避免了无序情况下随机申请内存,减少了碎片产生。
-
数据库日志
log分类
从一次SQL语句追溯不同log文件
执行语句
UPDATE table_name SET col_name = col_name + 1 WHERE ID = 1: 执行事务前将原数据记录到undo log;
- executor根据索引找到数据对应行,数据可能在内存中已有,也可能在磁盘上(需要读入内存);
- executor根据engine给的数据进行操作,得到新数据,并调用engine的接口写入新数据;
- engine将新数据更新到内存,同时记录更新操作到redo log(PREPARE状态);
- executor记录操作的bin log并写入磁盘;
- executor调用engine的事务提交接口,engine此时更新redo log状态(COMMITED)。
回滚日志undo log
- 记录修改前数据;
-
重做日志redo log
物理日志,提供给InnoDB引擎使用;
- 日志大小固定;
- 数据库异常重启时保证了crash-safe;
-
二进制日志bin log
逻辑日志,不区分引擎;
- 日志追加式添加;
- 不保证crash-safe;
-
容灾与备份
主从复制
主从复制延迟的解决
架构层面
分库分表,分散压力;
- 读写分离,一主多从,主写从读;
- 添加Redis等缓存层;
-
数据库层面
设置slave端的
sync_binlog = 0,停用slave的bin log的同步(或其他手段禁用slave的bin log)。分库分表
为何分库分表
IO瓶颈
- 磁盘IO瓶颈:原因是热点数据较多,数据库缓存放不下,降低查询速度,解决方案:分库/垂直分表;
-
CPU瓶颈
SQL语句瓶颈:SQL语句包含大量运算操作,解决方案:建立索引/业务侧提前计算;
- 单表查询瓶颈:单表数据量太大,查询时扫描的row太多,解决方案:水平分表。
分库分表的种类
水平拆分
将一个表(库)的数据拆分到其他表(库)中,表(库)的结构都是一样的,但数据完全不同,全部表(库)数据的并集才是全部数据。
- 水平分库:将一个库的数据拆分到多个库中,可以针对绝对并发量高且分表难以解决问题的情况。
水平分表:将一个表的数据拆分到多个表中,可以针对并发量不高但数据量很大,导致降低SQL效率的情况。
垂直拆分
将很多字段的表(很多表的库)拆分到不同的表(库)中,每个表(库)的结构不同且包含不同字段,将少数访问频率高的字段放到一个表中性能会更好。
垂直分库:将不同的表拆分到不同的库中,可以针对绝对并发量高的情况,需要根据业务进行拆分。
- 垂直分表:将表中的不同字段拆分到不同的表中,不同表以一个主键作为共享外键(不同表的交集),可以针对并发量不高但字段多且热点与非热点数据混杂,缓存不够用的情况。
⚠️查询不能用join,会增加CPU负担且将表耦合,数据的关联应该在业务侧service层进行。
分库分表的策略
- 按range分:按连续时间范围存
- 缺点:热点数据较多的情况下对新数据库的负荷很大;
- 优点:扩容简单,类似于尾部append。
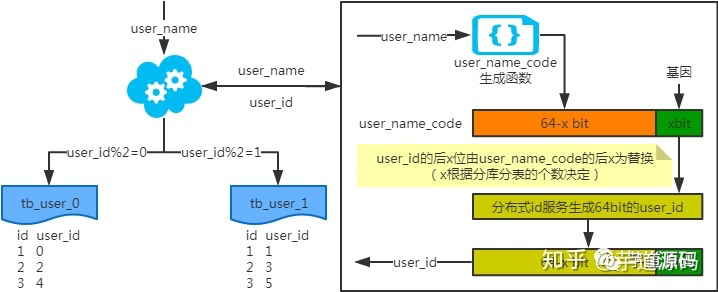
- 按hash分:将字段(一般是主键ID)进行hash分散到不同表(库)
映射法
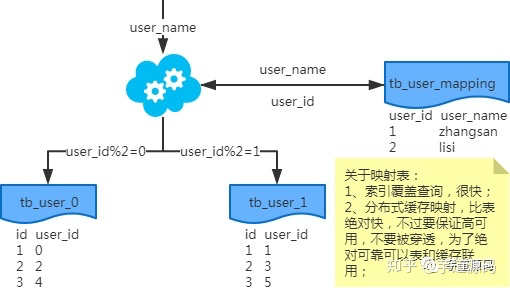
基因法

若有收获,就点个赞吧
0 人点赞
