你好,我是悦创。
我们先来看看今天要学习的内容:
- 列表、集合、元组、字典
- 链表
1. 你真的了解这四个数据类型吗?
- 可变与不可变
- 选择存储策略
事实上,由于列表是动态的,所以它需要存储指针,来指向对应的元素(上述例子中,对于 int 型,8 字节)。
另外,由于列表可变,所以需要额外存储已经分配的长度大小(8 字节),这样才可以实时追踪列表空间的使用情况,当空间不足时,及时分配额外空间。
对于静态大数据的存储,元组更加合适
l = []l.__sizeof__() // 空列表的存储空间为 40 字节40l.append(1)l.__sizeof__()72 // 加入了元素 1 之后,列表为其分配了可以存储 4 个元素的空间 (72 - 40)/8 = 4,可以存储 4 个 intl.append(2)l.__sizeof__()72 // 由于之前分配了空间,所以加入元素2,列表空间不变l.append(3)l.__sizeof__()72 // 同上l.append(4)l.__sizeof__()72 // 同上l.append(5)l.__sizeof__()104 // 加入元素5之后,列表的空间不足,所以又额外分配了可以存储 4 个元素的空间,也就是 72 + 4 * 8 = 104
上面的例子,大概描述了列表空间分配的过程。
我们可以看到,为了减小每次增加 / 删减操作时空间分配的开销,Python 每次分配空间时都会额外多分配一些,这样的机制(over-allocating)保证了其操作的高效性:增加 / 删除的时间复杂度均为 O(1)。
但是对于元组,情况就不同了。元组长度大小固定,元素不可变,所以存储空间固定。
看了前面的分析,你也许会觉得,这样的差异可以忽略不计。但是想象一下,如果列表和元组存储元素的个数是一亿,十亿甚至更大数量级时,你还能忽略这样的差异吗?
2. 列表和元组的性能
通过学习列表和元组存储方式的差异,我们可以得出结论:元组要比列表更加轻量级一些,所以总体上来说,元组的性能速度要略优于列表。
另外,Python 会在后台,对静态数据做一些资源缓存(resource caching)。通常来说,因为垃圾回收机制的存在,如果一些变量不被使用了,Python 就会回收它们所占用的内存,返还给操作系统,以便其他变量或其他应用使用。
但是对于一些静态变量,比如元组,如果它不被使用并且占用空间不大时,Python 会暂时缓存这部分内存。这样,下次我们再创建同样大小的元组时,Python 就可以不用再向操作系统发出请求,去寻找内存,而是可以直接分配之前缓存的内存空间,这样就能大大加快程序的运行速度。
下面的例子,是计算初始化一个相同元素的列表和元组分别所需的时间。我们可以看到,元组的初始化速度,要比列表快 5 倍。
python3 -m timeit 'x=(1,2,3,4,5,6)'20000000 loops, best of 5: 9.97 nsec per looppython3 -m timeit 'x=[1,2,3,4,5,6]'5000000 loops, best of 5: 50.1 nsec per loop
但如果是索引操作的话,两者的速度差别非常小,几乎可以忽略不计。
python3 -m timeit -s 'x=[1,2,3,4,5,6]' 'y=x[3]'10000000 loops, best of 5: 22.2 nsec per looppython3 -m timeit -s 'x=(1,2,3,4,5,6)' 'y=x[3]'10000000 loops, best of 5: 21.9 nsec per loop
当然,如果你想要增加、删减或者改变元素,那么列表显然更优。原因你现在肯定知道了,那就是对于元组,你必须得通过新建一个元组来完成。
3. 列表和元组的使用场景
那么列表和元组到底用哪一个呢?根据上面所说的特性,我们具体情况具体分析。
1. 如果存储的数据和数量不变,比如你有一个函数,需要返回的是一个地点的经纬度,然后直接传给前端渲染,那么肯定选用元组更合适。
def get_location():.....return (longitude, latitude)
2. 如果存储的数据或数量是可变的,比如社交平台上的一个日志功能,是统计一个用户在一周之内看了哪些用户的帖子,那么则用列表更合适。
viewer_owner_id_list = [] # 里面的每个元素记录了这个viewer一周内看过的所有owner的idrecords = queryDB(viewer_id) # 索引数据库,拿到某个viewer一周内的日志for record in records:viewer_owner_id_list.append(record.id)
4. 思考题
1. 想创建一个空的列表,我们可以用下面的 A、B 两种方式,请问它们在效率上有什么区别吗?我们应该优先考虑使用哪种呢?可以说说你的理由。
# 创建空列表# option Aempty_list = list()# option Bempty_list = []
密码:aiyc
1.2 字典 VS. 集合
- 字典:键对值
- 集合:值
2. 任务「统计一片文章词频」
目标文本:I_Have_a_Dream.txt/https://www.aiyc.top/1774.html
解决代码如下,不过代码主要为了解决问题,优化后的代码,也会提供。本任务主要是为了让你熟悉各个数据类型的用法。
# -*- coding: utf-8 -*-# @Time : 2021/5/11 9:42 下午# @Author : AI悦创# @FileName: words_count_main.py# @Software: PyCharm# @Blog :http://www.aiyc.top# @公众号 :AI悦创words = []def find_word_count(words):word_count = {}# 1.0# for word in set(words):# word_count[word] = 0# for word in words:# word_count[word] += 1for word in words:if word in word_count:word_count[word] += 1else:word_count[word] = 1return word_countwith open('I_Have_a_Dream.txt', mode='r', encoding='utf-8') as f:"""f.read() -> type: <class 'str'>f.readline() -> type: <class 'str'> -> Read a linef.readlines() -> type: <class 'list'> -> Read all"""lines = f.readlines()for line in lines:line = line.replace(',', '')line = line.replace(':', '')line = line.replace('?', '')line = line.replace('!', '')line = line.replace('"', '')line = line.replace('\n', '')line = line.replace('”', '')line = line.replace('.', '')line = line.replace(';', '')line = line.replace('“', '')for word in line.split(' '):if word: words.append(word)if __name__ == '__main__':print(len(words))print(len(set(words)))r = find_word_count(words)print(r)
补充:不推荐使用如下方式访问文件:
f = open("text.txt", "w")f.read()f.close()
3. 链表
在我们接触的 Python 中的列表,其实就是可以做成链表的形式使用的。
L = [3, 5, 6]L.append(7)
如何自己实现一个类似的结构呢?可以查询元素、添加元素、插入元素、删除元素
那我们先来简单的、系统的了解一下链表的定义。与数组相似,链表也是一种线性数据结构。这里有一个例子:
正如你所看到的,链表中的每个元素实际上是一个单独的对象,而所有对象都通过每个元素中的引用字段链接在一起。
链表有两种类型:单链表和双链表。上面给出的例子是一个单链表,这里有一个双链表的例子:
不过,我这里主要讲解当链表结构。链表是一种线性数据结构,它通过引用字段将所有分离的元素链接在一起。
其实,不就类似我们的铁链。
3.1 定义一个最简单的链表
class IntList(object):def __init__(self):"""first:存自己本身的数据rest:存下一个节点,也就下一个节点是谁"""self.first = Noneself.rest = None


l1 = IntList()l1.first = 5l2 = IntList()l2.first = 10l3 = IntList()l3.first = 15

上面代码其实就可以理解为,创建了每一节车厢,那我们该如何吧车厢链接起来呢?
l1.rest = l2l2.rest = l3# 正好使用两行代码连在一起了,也就是火车的两个铁链# PS: 如果你这么写的话:l1.rest = l2.first > 注意:这将不是链接一个车厢,而是连接一个 Value。# 所以:l1.rest = l2 才是连接车厢

但是,要是像下面代码这样写是不行的。这就好像,我们的火车一节连着一节,连的是一整个车厢不是就一部分。其中,lx.first 是一个值。
可以使用:http://pythontutor.com/ 来讲解
那我们如何输出数据呢?
print("第一节车厢:{}".format(l1.first))print("第二节车厢:{}".format(l1.rest.first))print("第三节车厢:{}".format(l1.rest.rest.first))
3.2 「改进」如何只用一个 l 来操作呢?
class IntList(object):def __init__(self):self.first = Noneself.rest = Nonel = IntList()l.first = 5l.rest = Nonel.rest = IntList()l.rest.first = 10l.rest.rest = Nonel.rest.rest = IntList()l.rest.rest.first = 15
class IntList(object):def __init__(self):self.first = Noneself.rest = Nonel = IntList()l.first = 5l.rest = IntList()l.rest.first = 10l.rest.rest = IntList()l.rest.rest.first = 15

3.3 问题
不知道,大家有没有发现,如果这么写的话。我们要写10节车厢或者以上的话不得写死了。
class IntList(object):def __init__(self):self.first = Noneself.rest = Nonel = IntList()l.first = 5l.rest = Nonel.rest = IntList()l.rest.first = 10l.rest.rest = Nonel.rest.rest = IntList()l.rest.rest.first = 15l.rest.rest.rest = IntList()l.rest.rest.rest.first = 20l.rest.rest.rest.rest = IntList()l.rest.rest.rest.rest.first = 25

所以,我们虽然实现了链表的结构,但是不完美。我们可以再进一步的去改进一下。
首先,我们肯定不希望之后还是要写一堆 rest 这样肯定是超级麻烦的。
3.4 改进代码
class IntList(object):def __init__(self, first, rest):self.first = firstself.rest = restl1 = IntList(5, None)l2 = IntList(10, l1)l3 = IntList(15, l2)

当然,我们也可以就用一个 l:
class IntList(object):def __init__(self, first, rest):self.first = firstself.rest = restl = IntList(5, None)l = IntList(10, l)l = IntList(15, l)

这样写,肯定比之前的书写要简洁。但是又出现问题了,就是我们每一个衔接的数据是显示出来了,但这个问题我们后面解决。接下来,我们先来添加个 size 函数。
3.5 添加一个 size() 方法,方便用户查询链表的大小
这个地方,需要递归作为前置知识:
01-Python 递归详解
def size(self):if self.rest is None:return 1else:return 1 + self.rest.size()
- 第一次: self.rest()

- 第二次:self.rest.size() —> self.rest.rest is None

- self.rest.rest.size() —> self.rest.rest.rest is None


3.6 不使用递归如何实现?
def get_length(self, linked):"""方法二"""length = 0while linked:length += 1linked = linked.restreturn length
不过上面写的虽然实现了,但是总体来说有点奇怪,在调用的时候:
print(l.get_length(l)) # 这样调用有点奇怪
所以,进行改进:
def iterative_size(self):# l == self 抽象理解p = selftotal_size = 0while p is not None:total_size += 1p = p.restreturn total_size
这样调用就很自然了:
print(l.iterative_size())
3.7 改进
添加一个 get() 方法,方便用户查询某个元素:
def get(self, index):if i == 0:return self.firstelse:return self.rest.get(index-1)
def get_index(self, index):'''第二种查询方法'''if index < 0:return -1node = self.firstfor _ in range(index+1):node = node.restreturn node.first
3.8 Question

现在的链表更像是一个“没穿衣服的”数据结构。
内部数据也是直接爆露出来的,
有些地方也是看起来很奇怪。
None 和 l 应该是内部的数据,不应该让外部的人看见的。
class IntNode(object):def __init__(self, item, next):self.item = itemself.next = nextclass SLList(object):def __init__(self, x):self.first = IntNode(x, None)
我们可以对比一下:
l = SLList(10)# l = IntList(5, None) 比之前的好
但是目前不能添加多个车厢(链表),添加多个链表的数据都会被覆盖:
l = SLList(5)l = SLList(10)l = SLList(15)
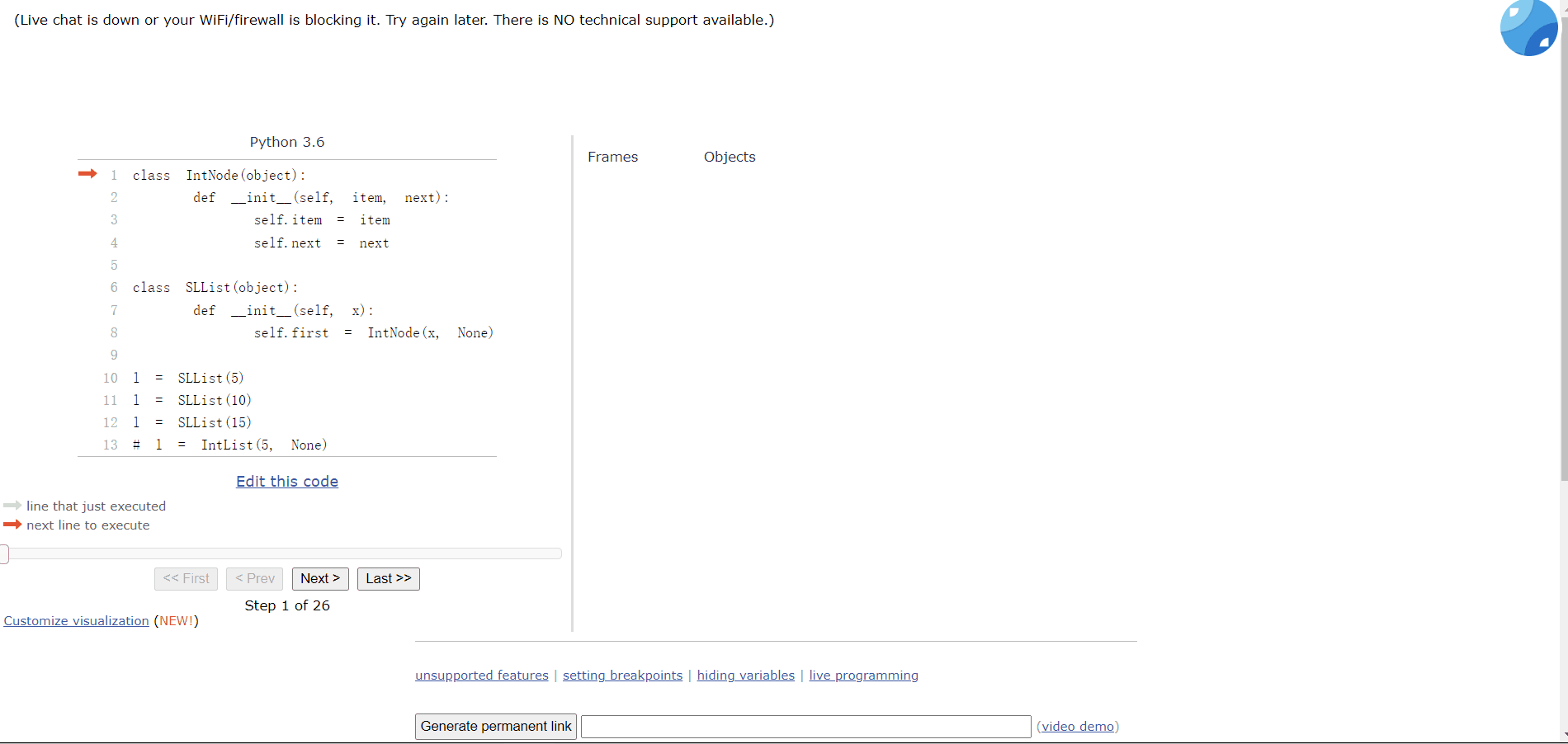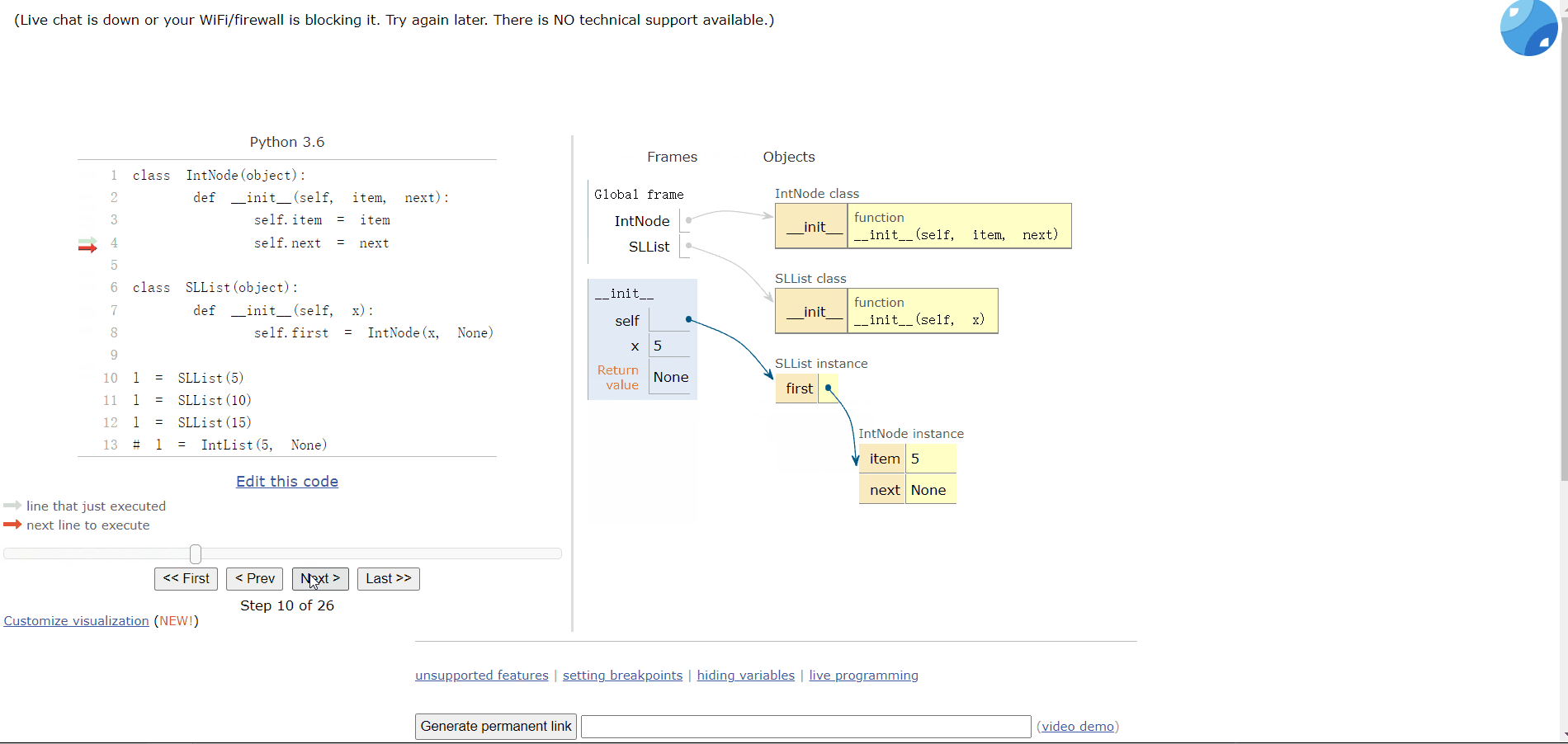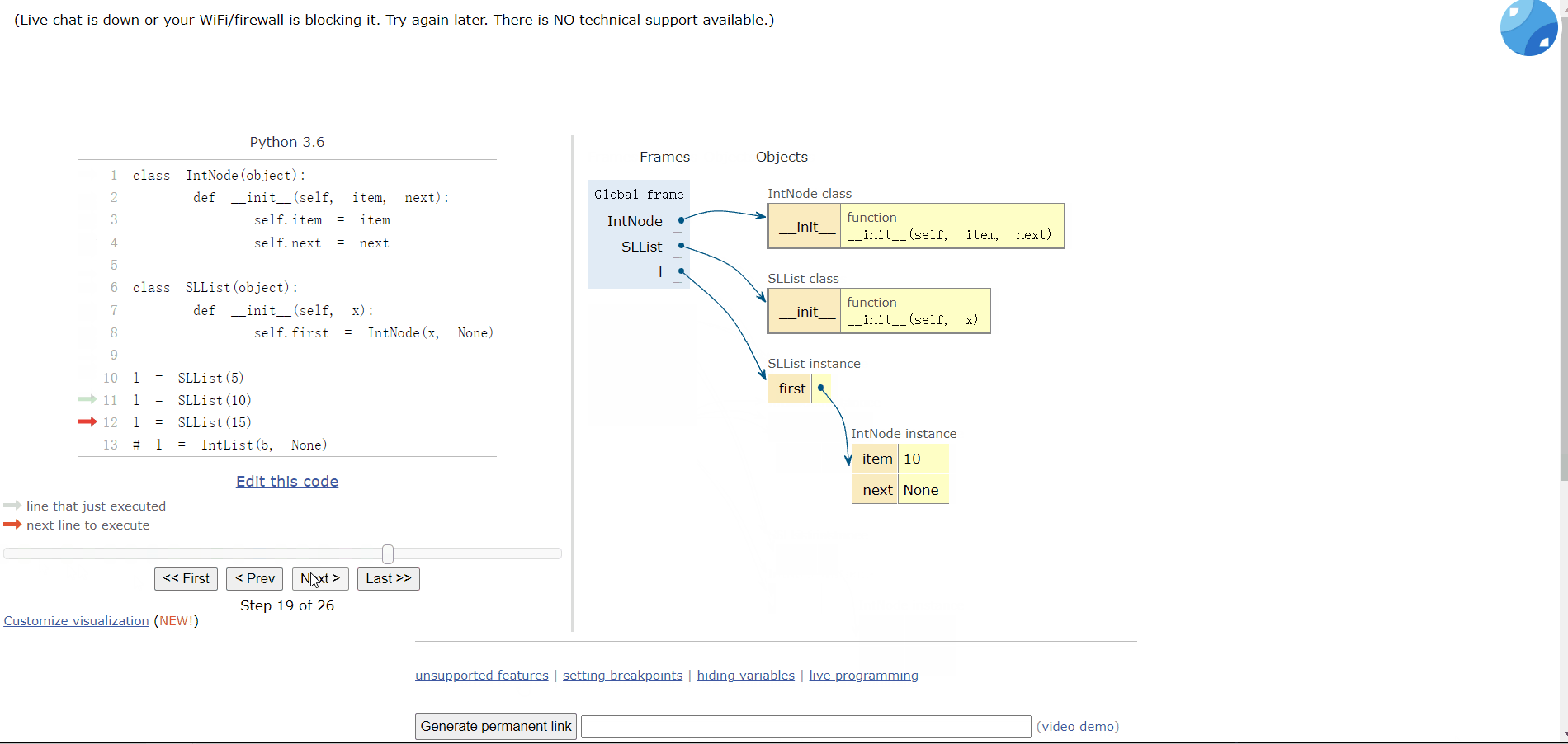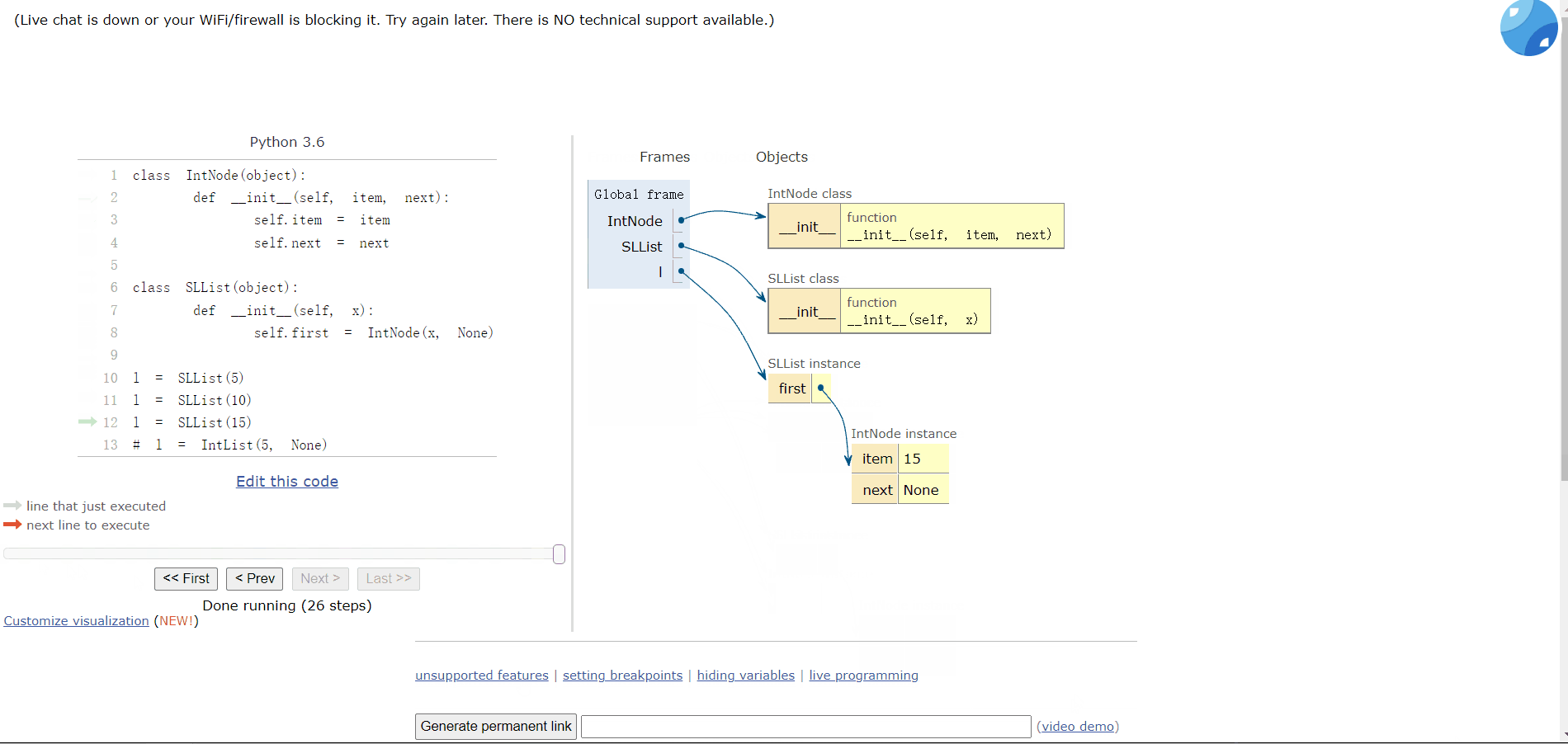
所以,我们需要添加一个函数来添加数据。
def add_first(self, x):self.first = IntNode(x, self.first)
这样,我们添加数据就是:
l = SLList(5)l.add_first(10)l.add_first(15)

SLList 新增加一个方法叫 get_first() ,用来让用户获取当前链表第一个元素:
def get_first(self):return self.first.item
3.9 比较一下

# filename: compare.pyclass IntList(object):def __init__(self, f, r):"""first:存自己本身的数据rest:存下一个节点,也就下一个节点是谁"""self.first = fself.rest = rdef size(self):"""方法一"""# l == self 抽象理解if self.rest is None:return 1else:return 1 + self.rest.size()def get_length(self, linked):"""方法二"""length = 0while linked:length += 1linked = linked.restreturn lengthdef iterative_size(self):# l == self 抽象理解p = selftotal_size = 0while p is not None:total_size += 1p = p.restreturn total_sizedef get(self, index):if i == 0:return self.firstelse:return self.rest.get(index-1)l1 = IntList(5, None)l2 = IntList(10, l1)l3 = IntList(15, l2)print(l1.first)print(l2.first)print(l3.first)


4.0 然而还是有点问题
如果,我破解出了 SLList 里面的变量的名称,一样可以修改,比如:
l.first.next.next = 8
4.1 改进
将 first 变量改为私有变量。
class IntNode(object):def __init__(self, item, next):self.item = itemself.next = nextclass SLList(object):def __init__(self, x):self.__first = IntNode(x, None)def add_first(self, x):self.__first = IntNode(x, self.__first)l = SLList(5)l.add_first(10)l.add_first(15)# print(l.get_first())
class 里的私有变量只能再 class 的内部访问:
print(l.__first)
AttributeError: 'SLList' object has no attribute '__first'
4.2 为什么要设计私有变量?
将类的内部细节隐藏起来
- 用户不需要了解太多类的细节
- 设计者可以拥有更为安全的对于程序的控制全
以汽车来类比
- 公共的方法或变量:油门、方向盘
- 私有的方法或变量:燃油管道、旋转阀
4.3 改进
SLList 新增加一个方法叫 add_last() ,用来让用户向链表末尾添加一个元素。
def add_last(self, x):
p = self.__first
while p.next is not None:
p = p.next
p.next = IntNode(x, None)
l.add_last(20)

4.4 改进
SLList 新增加一个方法叫 size() :
def __size(self, p):
if p.next is None:
return 1
else:
return 1 + self.__size(p.next)
def size(self):
return self.__size(self.__first)
每次查询 size() 都要把整个链表遍历一遍,是不是低效了?
# -*- coding: utf-8 -*-
# @Author: AI悦创
# @Date: 2021-10-15 14:50:07
# @Last Modified by: aiyc
# @Last Modified time: 2021-10-18 15:49:59
class IntNode(object):
def __init__(self, item, next):
self.item = item
self.next = next
class SLList(object):
def __init__(self, x):
self.__first = IntNode(x, None)
self.__size = 1
def add_first(self, x):
self.__first = IntNode(x, self.__first)
self.__size += 1
def get_first(self):
return self.first.item
def add_last(self, x):
p = self.__first
while p.next is not None:
p = p.next
p.next = IntNode(x, None)
self.__size += 1
def __size(self, p):
if p.next is None:
return 1
else:
return 1 + self.__size(p.next)
# def size(self):
# return self.__size(self.__first)
def size(self):
return self.__size
l = SLList(5)
l.add_first(10)
l.add_first(15)
l.add_last(20)
# print(l.__first)
4.5 改进
如果,我希望创建一个空链表呢?
# -*- coding: utf-8 -*-
# @Author: AI悦创
# @Date: 2021-10-18 15:53:48
# @Last Modified by: aiyc
# @Last Modified time: 2021-10-18 15:58:12
class IntNode(object):
def __init__(self, item, next):
self.item = item
self.next = next
class SLList(object):
def __init__(self, x=None):
self.__first = IntNode(x, None)
self.__size = 1
def add_first(self, x):
if self.__first.item is None:
self.__first.item = x
else:
self.__first = IntNode(x, self.__first)
self.__size += 1
def get_first(self):
return self.first.item
def add_last(self, x):
p = self.__first
while p.next is not None:
p = p.next
p.next = IntNode(x, None)
self.__size += 1
def __size(self, p):
if p.next is None:
return 1
else:
return 1 + self.__size(p.next)
# def size(self):
# return self.__size(self.__first)
def size(self):
return self.__size
l = SLList()
l.add_first(5)
l.add_first(10)
l.add_first(15)
l.add_last(20)
# print(l.__first)

若有收获,就点个赞吧
0 人点赞
