你好,我是悦创。
从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事!故事是什么呢?『从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事!故事是什么呢?』……
这也许是最经典(口耳相传)的童谣了,充分展现了自然语言的魅力及其无限可能性,可以永远以这种递归的方式继续下去。。。

俄文艺理论家车尔尼雪夫斯基曾说过:
艺术来源于生活,却又高于生活!
生活如此,编程世界亦如此 - 没有生活原形或者现象,何来程序创作的源头和灵感?正因此,Python 中出现了这样一种函数 - 递归函数。
大多数情况下,我们见到的是一个函数调用其他函数。除此之外,函数还可以自我调用,这种类型的函数被称为递归函数。
1. 递归函数
递归的一个视觉效果呈现 - 捧着画框的蒙娜丽莎:
递归(Recursion),在数学与计算机科学中,是指在函数的定义中使用函数自身的方法。
在使用递归时,需要注意以下几点:
- 递归就是在过程或函数里调用自身
- 边界条件:必须有一个明确的递归结束条件,称为递归出口。(确定递归到何时终止,也称为递归出口。)
- 递归模式:大问题是如何分解为小问题的,也称为递归体。
递归函数只有具备了这两个要素,才能在有限次计算后得出结果。
注意: 切勿忘记递归出口,避免函数无限调用。
2. 典型的算法
2.1 阶乘
大多数学过数学、计算机科学或者读过编程相关书籍的人,想必都会遇到阶乘:
n! = 1 × 2 × 3 × … × n
也可以用递归方式定义:
n! = (n-1)! × n

其中,n >= 1,并且 0! = 1。
由于简单、清晰,因此其常被用作递归的示例。
PS: 除了阶乘以外,还有很多算法可以使用递归来处理,例如:斐波那契数列、汉诺塔等。
根据阶乘的递归定义,很容易就能写出求阶乘的递归算法。
1. 迭代实现
相比递归,阶乘的迭代实现更容易理解:
In [1]: def factorial(n):...: result = 1 # 对于 0! = 1, 所以一开始就为 1...: for i in range(2, n+1): # 1. 对于阶乘, 0 或 1 开始是没有意义的,因为如果 n 是这两个数字的话,可以不用操作...: result *= i # 2. 2 以前的数据是可以不用乘的(也就是 1)...: return result # 3. range 是左闭右开的,所以 n 需要 +1...:In [2]: factorial(0)Out[2]: 1In [3]: factorial(1)Out[3]: 1In [4]: factorial(2)Out[4]: 2In [5]: factorial(3)Out[5]: 6In [6]: factorial(4)Out[6]: 24In [7]: factorial(5)Out[7]: 120
开始时,result 为 1,进入 for 循环,对之前的结果累积乘以 i,直至 n。
2. 递归实现
现在,来使用递归来实现,和数学定义一样优雅。
In [4]: def factorial(n):...: if n == 0 or n == 1:...: return 1 # 递归结束...: else:...: return n * factorial(n - 1) # 问题规模减1,递归调用...:In [5]: factorial(0)Out[5]: 1In [6]: factorial(1)Out[6]: 1In [7]: factorial(2)Out[7]: 2In [8]: factorial(3)Out[8]: 6In [9]: factorial(4)Out[9]: 24In [10]: factorial(5)Out[10]: 120

当使用正整数调用 factorial() 时,会通过递减数字来递归地调用自己。
为了明确递归步骤,对 5! 进行过程分解:
factorial(5) # 第 1 次调用使用 55 * factorial(4) # 第 2 次调用使用 45 * (4 * factorial(3)) # 第 3 次调用使用 35 * (4 * (3 * factorial(2))) # 第 4 次调用使用 25 * (4 * (3 * (2 * factorial(1)))) # 第 5 次调用使用 15 * (4 * (3 * (2 * 1))) # 从第 5 次调用返回5 * (4 * (3 * 2)) # 从第 4 次调用返回5 * (4 * 6) # 从第 3次调用返回5 * 24 # 从第 2 次调用返回120 # 从第 1 次调用返回
当数字减少到 1 时,递归结束。
使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。可以试试 factorial(1000):
Traceback (most recent call last):File "D:/Windows_Code/Tester/Lesson01_wxl/lesson02.py", line 8, in <module>r = factorial(1000)File "D:/Windows_Code/Tester/Lesson01_wxl/lesson02.py", line 5, in factorialreturn n * factorial(n - 1) # 问题规模减1,递归调用File "D:/Windows_Code/Tester/Lesson01_wxl/lesson02.py", line 5, in factorialreturn n * factorial(n - 1) # 问题规模减1,递归调用File "D:/Windows_Code/Tester/Lesson01_wxl/lesson02.py", line 5, in factorialreturn n * factorial(n - 1) # 问题规模减1,递归调用[Previous line repeated 995 more times]File "D:/Windows_Code/Tester/Lesson01_wxl/lesson02.py", line 2, in factorialif n == 1 or n == 0:RecursionError: maximum recursion depth exceeded in comparison
3. 递归的优缺点:
从“编程之美”的角度来看,引用一句伟大的计算机编程名言:
To iterate is human,to recurse divine. 迭代者为人,递归者为神。 – L. Peter Deutsch
优点:
- 递归使代码看起来更加整洁、优雅
- 可以用递归将复杂任务分解成更简单的子问题
- 使用递归比使用一些嵌套迭代更容易
- 总之:递归函数的优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
缺点:
- 递归的逻辑很难调试、跟进
- 递归调用的代价高昂(效率低),因为占用了大量的内存和时间。
[
](https://blog.csdn.net/liang19890820/article/details/72850612)
2.2 高斯求和
典型的高斯求和问题,1+2+3+4+…+99+100,不使用递归的话,我们可以用循环,这么做:
In [19]: def sum_number(n):...: total = 0...: for i in range(1, n+1):...: total += i...: return total...:In [20]: sum_number(100)Out[20]: 5050
但如果使用递归函数来写,是这样的:
In [21]: def sum_number(n):...: if n <= 0:...: return 0...: return n + sum_number(n-1)...:In [22]: sum_number(100)Out[22]: 5050
分析一下代码:
- 当 n 小于等于 0 的时候,直接给出和值为 0,这句不能省。
- 当 n 大于 0 时,结果是 n 加上
sum_number(n-1)。这里的sum_number(n-1)又是一次sum_number函数的调用,不过参数的值变成了 n-1。 - 要得
sum_number(n)到的值就必须等待sum_number(n-1)的值被计算出来,同样要得到sum_number(n-1)的值必须等待sum_number(n-2)的值,如此一路推算下去,直到sum_number(0),因为 if 语句的存在,它不需要等待sum_number(-1)的计算了,而是直接给出结果 0。然后程序一路返回,直到回到最初的sum_number(n),并给出最终结果。
递归最核心的思想是:每一次递归,整体问题都要比原来减小,并且递归到一定层次时,要能直接给出结果!
每一个递归程序都遵循相同的基本步骤:
- 初始化算法。递归程序通常需要一个开始时使用的种子值(seed value)。可以向函数传递参数,或者提供一个入口函数,这个函数是非递归的,但可以为递归计算设置种子值。
- 检查要处理的当前值是否已经与基线条件相匹配(base case)。如果匹配,则进行处理并返回值。
- 使用更小的或更简单的子问题(或多个子问题)来重新定义答案。
- 对子问题运行算法。
- 将结果合并入答案的表达式。
- 返回结果。
递归函数的优点是定义简单,代码量少,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
可是,有同学会问,从上面的例子来看,我一点没觉得递归有多简单,反倒更难理解。那么请看下面的例子:
如果有这么一个树形结构的评论系统(博主的博客评论系统):
1--直接对文章的评论1.1--对评论1的回复1.1.1--对评论1.1的回复1.1.2--对评论1.1的回复1.1.3--对评论1.1的回复1.2 --对评论1的回复1.2.1--对评论1.2的回复1.3 --对评论1的回复2--直接对文章的评论2.1 --对评论2的回复2.1.1--对评论2.1的回复2.2 --对评论2的回复3--直接对文章的评论4--直接对文章的评论
请一定要注意,其中的 1.1.1 这种是方便大家理解评论层次,并不是真正的评论内容。每一个评论都有一个指向父评论的指针。
现在的要求是,将所有的评论,根据评论的关系,放入一个列表内,然后逐一打印出来。需求的关键是我们必须穷举每个评论的子评论。下面我们写一个用循环来实现的伪代码:
lis = []all_top_comments = ["顶级评论1","顶级评论2","顶级评论3","....."]for comment in all_top_comments:for child_comment in comment:for child_child_comment in child_comment:for child_child_child_comment in child_child_comment:# ....子评论的子评论的子评论的....# 很快你就没办法写下去了,这种代码必定会被老板“重视”
你知道评论嵌套层级会有几层?有 100 层你就写 100 个 for 循环?对于这种问题,循环的做法是不行的。但是用递归就很简单了。
lis = []all_top_comments = ["顶级评论1","顶级评论2","顶级评论3","....."]def get_comment(comments):for comment in comments:lis.append(comment)child_comments = comment.child() # 假设有一个child方法获取当前评论的所有子评论。if len(child_comments) > 0: # 如果有子评论的话,就递归查找下去,否则回退get_comment(child_comments)get_comment(all_top_comments)
本博客的评论系统就是这么写的。
使用递归函数需要注意防止递归深度溢出,在Python中,通常情况下,这个深度是1000层,超过将抛出异常。在计算机中,函数递归调用是通过栈(stack)这种数据结构实现的,每当进入一个递归时,栈就会加一层,每当函数返回一次,栈就会减一层。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。
2.3 斐波那契数列
斐波拉契数列,是这样的一个数列:0、1、1、2、3、5、8、13、21、……。
斐波拉契数列的核心思想是:从第三项起,每一项都等于前两项的和,即 F(N) = F(N - 1) + F(N - 2) (N >= 2)
并且规定 F(0) = 0,F(1) = 1
要求:利用递归算法获得指定项的斐波拉契数列。
In [2]: def recur_fibo(n):...: """递归函数输出斐波那契数列中指定位置 (n) 的 value"""...: if n <= 1:...: return n...: else:...: return (recur_fibo(n-1) + recur_fibo(n-2))...:In [3]: # 获取用户输入In [4]: nterms = int(input("您要输出几项? "))您要输出几项? 10In [5]: # 检查输入的数字是否正确In [6]: if nterms <= 0:...: print("输入正数")...: else:...: print("斐波那契数列:")...: for i in range(nterms):...: print(recur_fibo(i))...:斐波那契数列:0112358132134
2.4 汉诺塔
汉诺塔问题是递归函数的经典应用,它来自一个古老传说。
在世界刚被创建的时候有一座钻石宝塔 A,其上有 64 个金蝶。所有碟子按从大到小的次序从塔底堆放至塔顶。紧挨着这座塔有另外两个钻石宝塔 B 和 C。
从世界创始之日起,波罗门的牧师就一直在试图把塔 A 上的碟子移动到 C 上去,其间借助于塔 B 的帮助。
每次只能移动一个碟子,任何时候都不能把一个碟子放在比它小的碟子上面。当牧师们完成这个任务时,世界末日也就到了。
对于汉诺塔问题的求解,可以通过以下 3 步实现:
(1)将塔 A 上的 n-1 个碟子借助 C 塔先移动到 B 塔上;
(2)把塔 A 上剩下的一个碟子移动到塔 C 上;
(3)将 n-1 个碟子从 B 塔借助塔 A 移动到塔 C 上。
很显然,这是一个递归求解的过程,假设碟子数 n=3 时,汉诺塔问题的求解过程如下图所示:
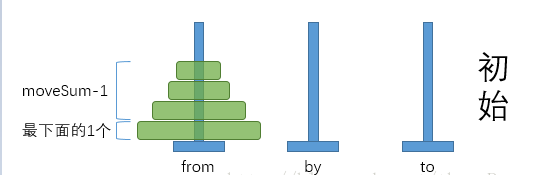
汉诺塔的递归算法(Python实现):
def Hanoi(n, A, B, C) :if (n == 1) :move(A, c) # 表示只有一个碟子时,直接从 A 塔移动到 C 塔else :Hanoi(n - 1, A, C, B) # 将剩下的 A 塔上的 n-1 借助 C 塔移动到 B 塔move(A, C) # 将 A 上最后一个直接移动到 C 塔上Hanoi(n - 1, B, A, C) #将 B 塔上的 n-1 个碟子借助 A 塔移动到 C 塔
递归函数的运行轨迹
借助汉诺塔这个实例,来讲解一下递归函数的运行轨迹。在递归函数中,调用函数和被调用函数都是同一个函数,需要注意的是函数的调用层次,如果把调用递归函数的主函数称为第0层,进入函数后,首次递归调用自身称为第1层调用;从第i层递归调用自身称为第i+1层。反之退出i+1层调用应该返回第i层。下图是n=3时汉诺塔算法的运行轨迹,有向弧上的数字表示递归调用和返回的执行顺序。

汉诺塔的递归算法代码实现:
#coding=utf-8i = 1def move(n, mfrom, mto) :global iprint "第%d步:将%d号盘子从%s -> %s" %(i, n, mfrom, mto)i += 1def hanoi(n, A, B, C) :if n == 1 :move(1, A, C)else :hanoi(n - 1, A, C, B)move(n, A, C)hanoi(n - 1, B, A, C)#********************程序入口**********************try :n = int(raw_input("please input a integer :"))print "移动步骤如下:"hanoi(n, 'A', 'B', 'C')except ValueError:print "please input a integer n(n > 0)!"
# -*- coding:utf-8-*-
# 将 10不断除以2,直至商为0,输出这个过程中每次得到的商的值。
def recursion(n):
v = n//2 # 地板除,保留整数
print(v) # 每次求商,输出商的值
if v==0:
''' 当商为0时,停止,返回Done'''
return 'Done'
v = recursion(v) # 递归调用,函数内自己调用自己
recursion(10) # 函数调用

若有收获,就点个赞吧
0 人点赞
