本课需要软件
Apache 清华镜像:https://mirrors.tuna.tsinghua.edu.cn/apache
Hadoop官网:https://hadoop.apache.org/releases.html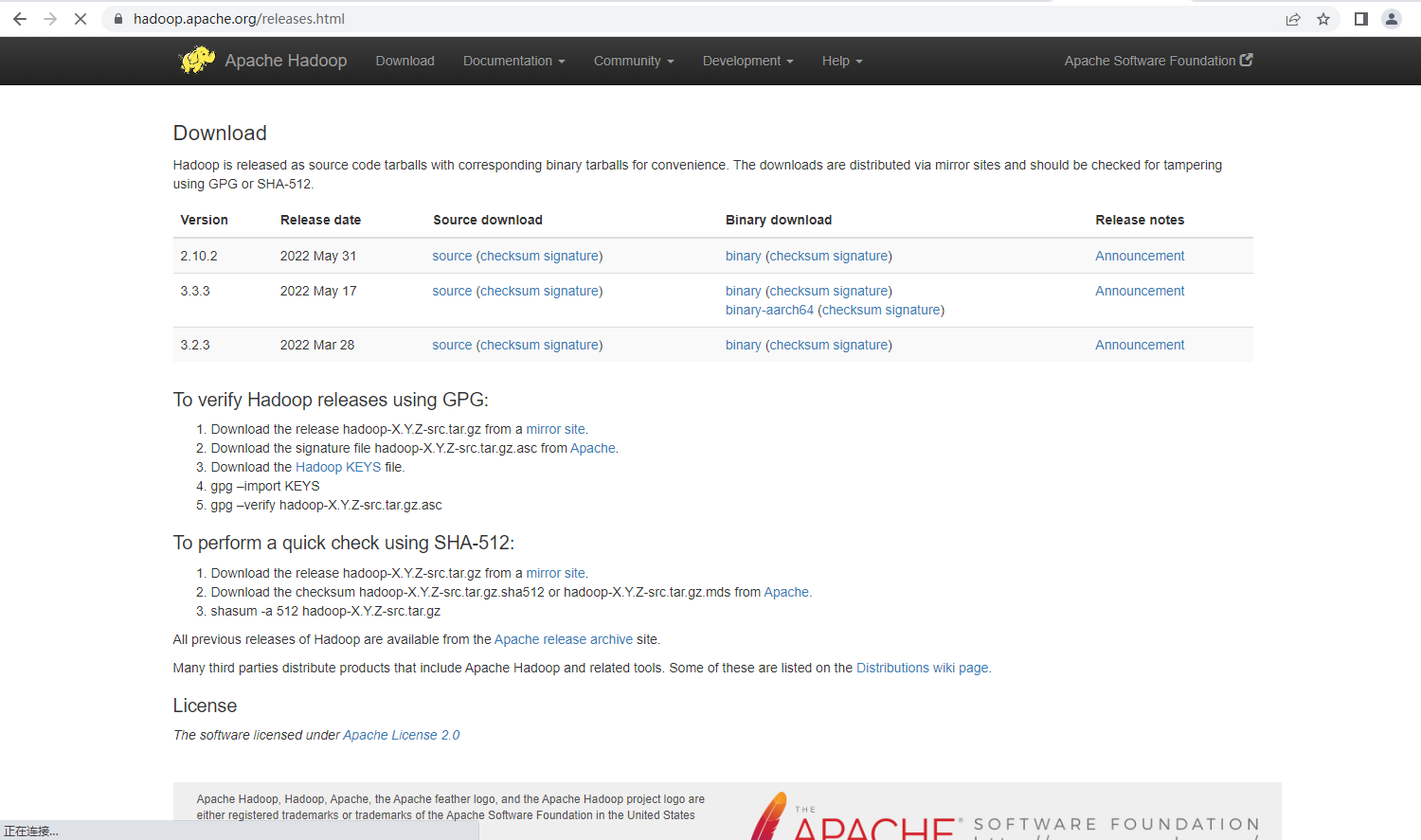
选择release
选择3.2.0版本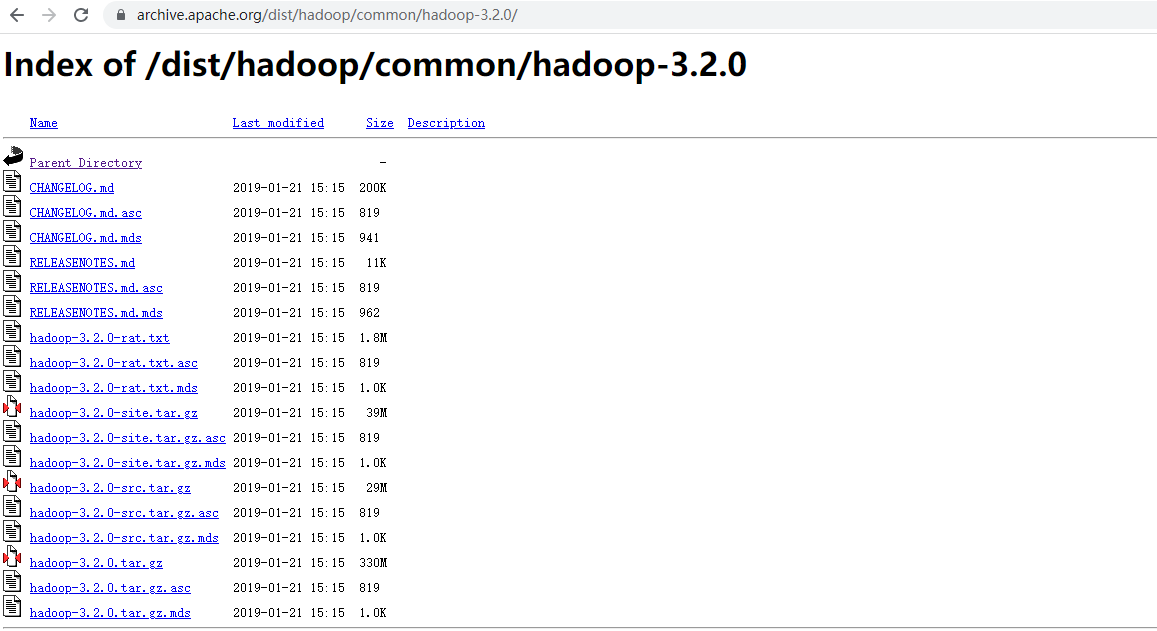
部署方式
部署方式用2种
一种单机的伪分布式集群:适合电脑性能差
一种分布式集群:适合电脑性能好
安装伪分布式集群
伪分布式集群图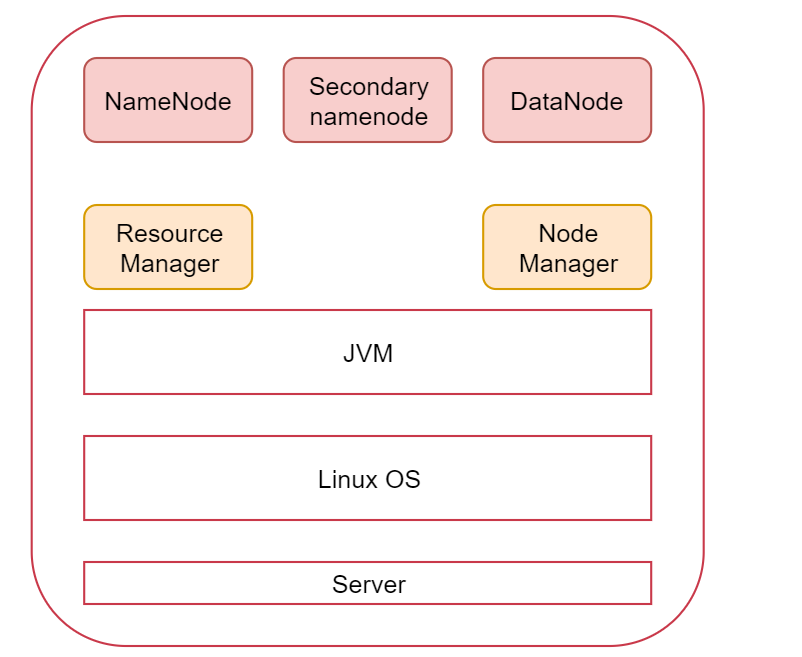
最上面的是Hadoop集群会启动的进程,其中NameNode、SecondaryNameNode、DataNode是HDFS服务的进程,ResourceManager、NodeManager是YARN服务的进程,MapRedcue在这里没有进程,因为它是一个计算框架,等Hadoop集群安装好了以后MapReduce程序可以在上面执行
基础配置:参考往期教程
配置静态Ip
关闭防火墙
设置主机名
免密登录
在这需要大致讲解一下ssh的含义,ssh 是secure shell,安全的shell,通过ssh可以远程登录到远程linux机器。
我们下面要讲的hadoop集群就会使用到ssh,我们在启动集群的时候只需要在一台机器上启动就行,然后hadoop会通过ssh连到其它机器,把其它机器上面对应的程序也启动起来。
但是现在有一个问题,就是我们使用ssh连接其它机器的时候会发现需要输入密码,所以现在需要实现ssh免密码登录。
非对称加密
非对称加密会产生秘钥,秘钥分为公钥和私钥,在这里公钥是对外公开的,私钥是自己持有的。
那么ssh通信的这个过程是,第一台机器会把自己的公钥给到第二台机器,
当第一台机器要给第二台机器通信的时候,
第一台机器会给第二台机器发送一个随机的字符串,第二台机器会使用公钥对这个字符串加密,
同时第一台机器会使用自己的私钥也对这个字符串进行加密,然后也传给第二台机器
这个时候,第二台机器就有了两份加密的内容,一份是自己使用公钥加密的,一份是第一台机器使用私钥加密传过来的,公钥和私钥是通过一定的算法计算出来的,这个时候,第二台机器就会对比这两份加密之后的内容是否匹配。如果匹配,第二台机器就会认为第一台机器是可信的,就允许登录。如果不相等 就认为是非法的机器。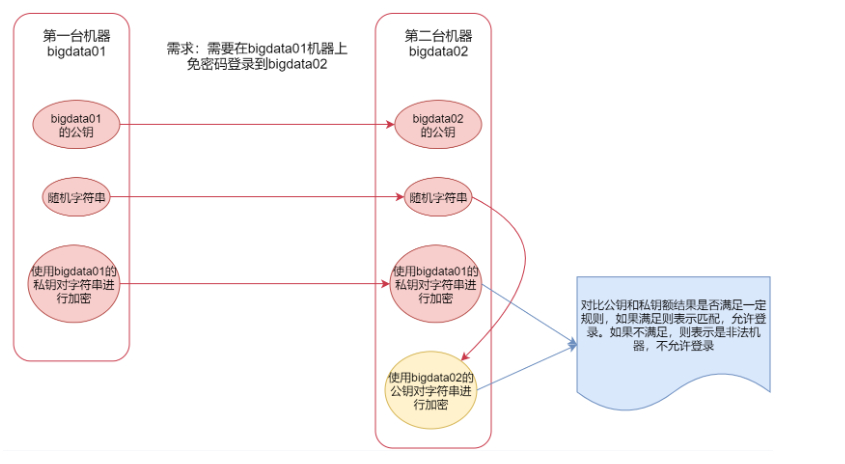
配置单机免密
ssh-keygen -t rsa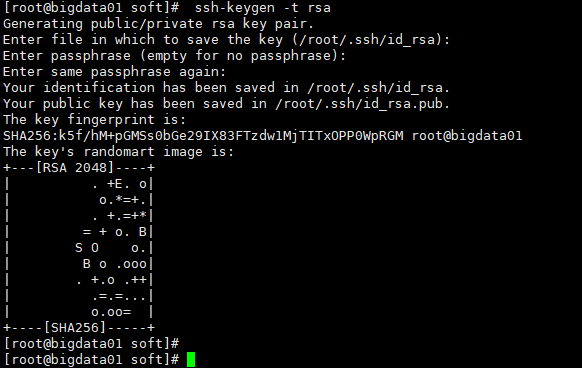
把公钥拷贝到需要免密码登录的机器上面
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
然后就可以通过ssh 免密码登录到bigdata01机器了
安装Hadoop
1:上传hadoop安装包
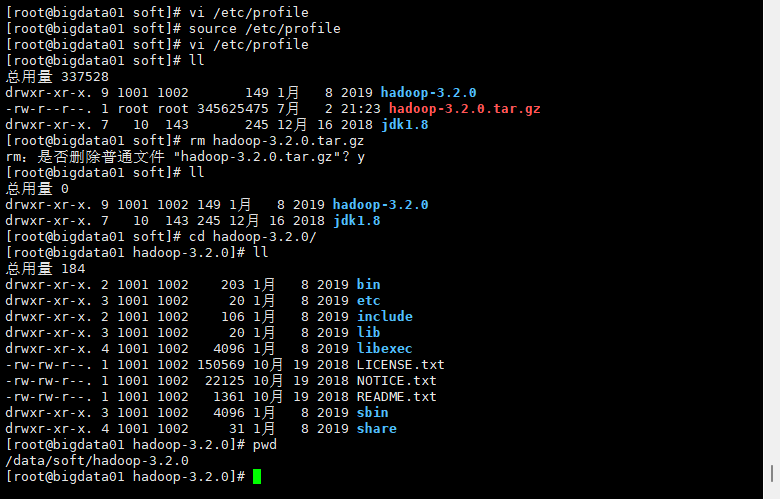
2:解压hadoop安装包
我们看一下bin目录,这里面有hdfs,yarn等脚本,这些脚本后期主要是为了操作hadoop集群中的hdfs和yarn组件的
再来看一下sbin目录,这里面有很多start stop开头的脚本,这些脚本是负责启动 或者停止集群中的组件的。
其实还有一个重要的目录是etc/hadoop目录,这个目录里面的文件主要是hadoop的一些配置文件,还是比较重要的。一会我们安装hadoop,主要就是需要修改这个目录下面的文件。
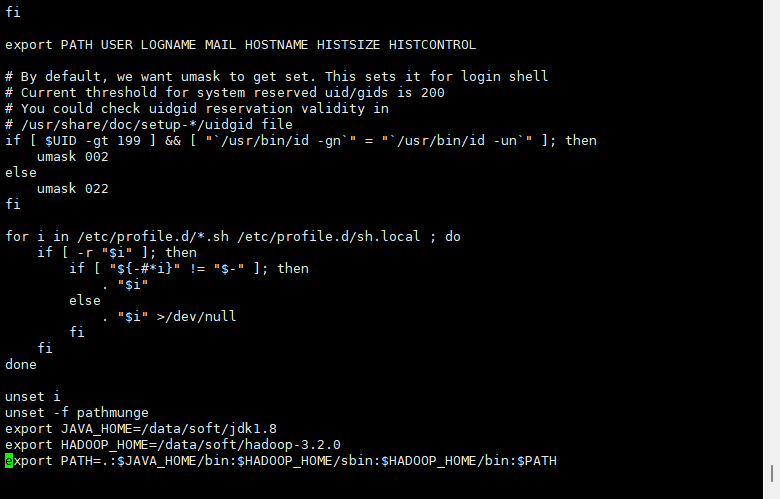
因为我们会用到bin目录和sbin目录下面的一些脚本,为了方便使用,我们需要配置一下环境变量。
3.修改环境变量
4.进入Hadoop目录
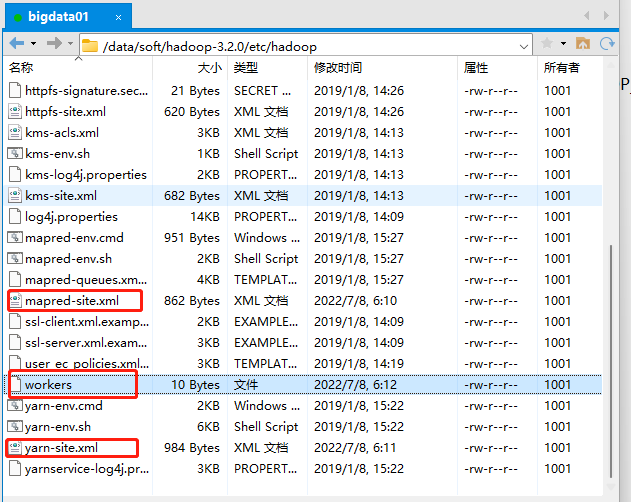
主要修改下面这几个文件:
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml workers
首先修改 hadoop-env.sh 文件,增加环境变量信息,添加到hadoop-env.sh 文件末尾即可。
JAVA_HOME:指定java的安装位置
HADOOP_LOG_DIR:hadoop的日志的存放目录
修改配置文件
切换至目录
/data/soft/hadoop-3.2.0/etc/hadoop
Hadoop-env.sh
JAVA_HOME:指定java的安装位置
HADOOP_LOG_DIR:hadoop的日志的存放目录
增加至文件末尾即可
core-site.xml

hdfs-site.xml
制定hdfs文件对应的副本数,由于是伪分布式配置,所以副本为1
mapred-site.xml

yarn-site.xml

workers
start-dfs.sh/stop-dfs.sh增加配置
切换至/data/soft/hadoop-3.2.0/sbin目录下
新增配置
start-yarn.sh/stop-yarn.sh增加配置

格式化HDFS

如果能看到successfully formatted这条信息就说明格式化成功了。
如果提示错误,一般都是因为配置文件的问题,当然需要根据具体的报错信息去分析问题。
启动伪分布式
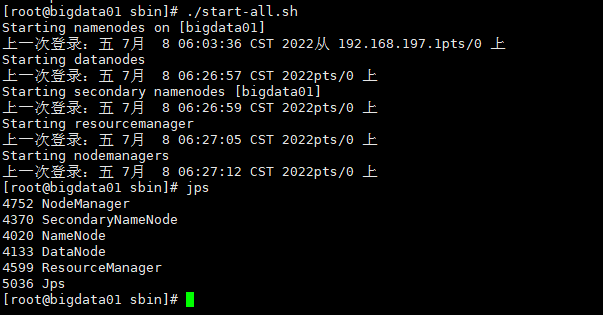
启动成功后
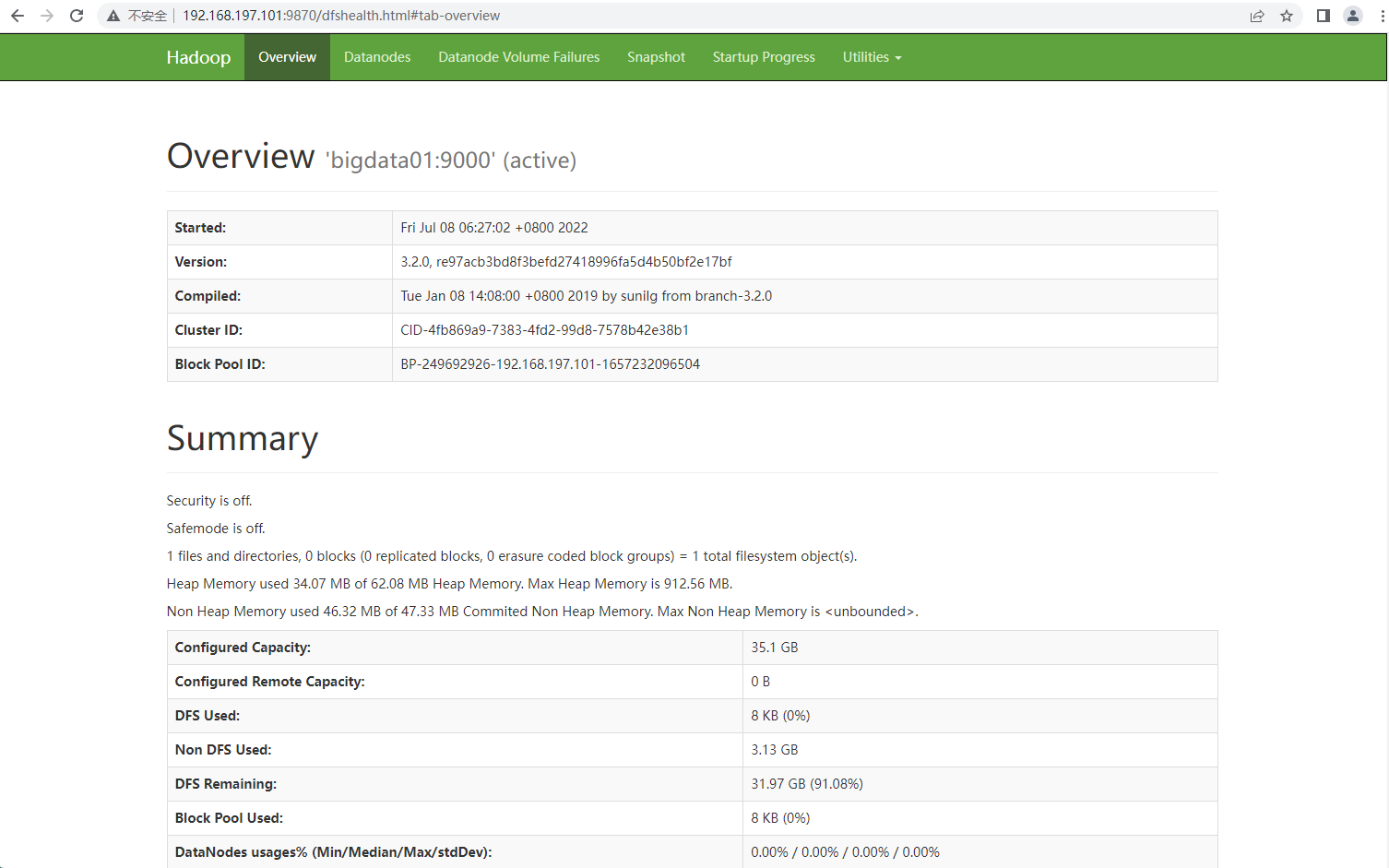
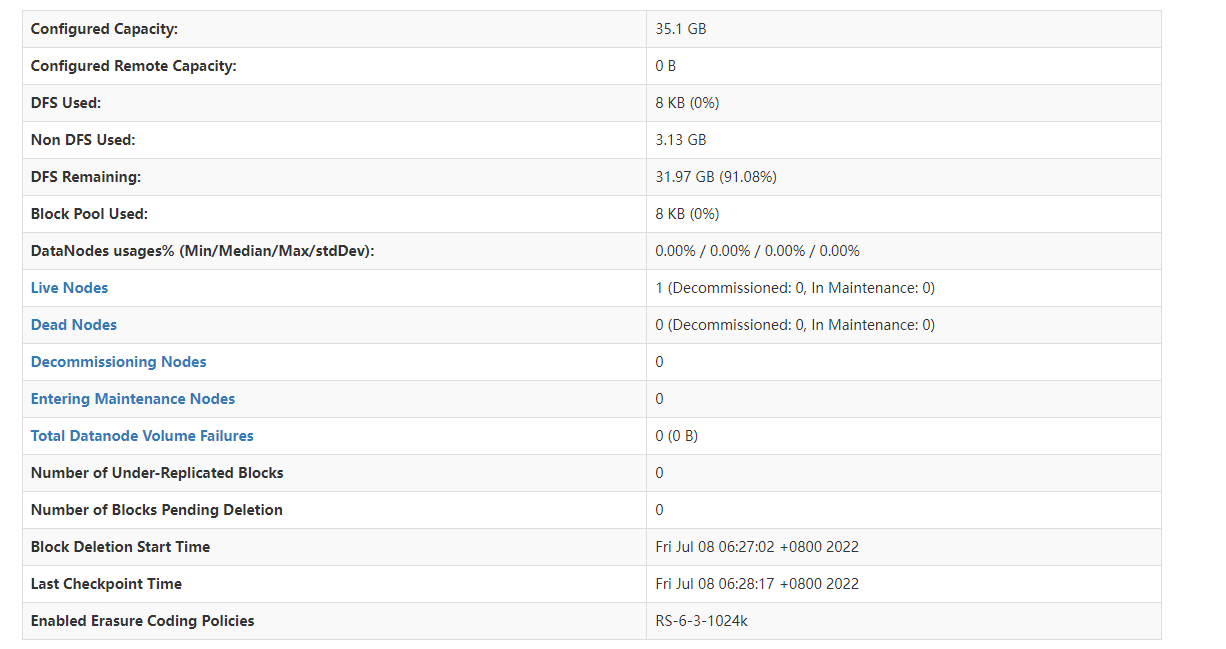
还可以通过webui界面来验证集群服务是否正常
- HDFS webui界面:http://192.168.197.101:9870
- YARN webui界面:http://192.168.197.101:8088
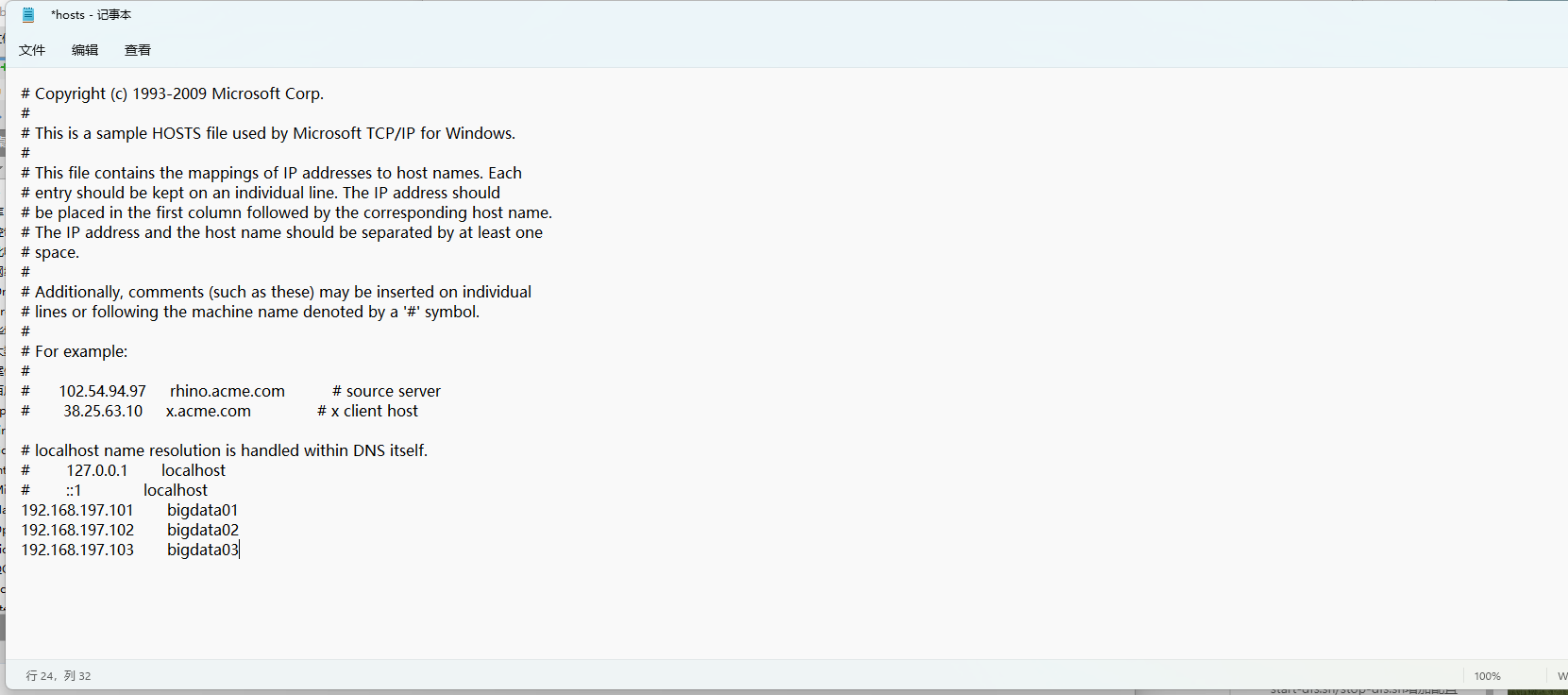
如果想通过主机名访问,则需要修改windows机器中的hosts文件
文件所在位置为:C:\Windows\System32\drivers\etc\HOSTS
在文件中增加下面内容,这个其实就是Linux虚拟机的ip和主机名,在这里做一个映射之后,就可以在Windows机器中通过主机名访问这个Linux虚拟机了。
192.168.197.100 bigdata01
注意:如果遇到这个文件无法修改,一般是由于权限问题,在打开的时候可以选择使用管理员模式打开。
Hdfs web UI
Yarn webUI
伪分布式环境需要的配置文件内容
链接:https://pan.baidu.com/s/1N-A1LyS17hWhaZzwIOiN1A?pwd=0n71
提取码:0n71
—来自百度网盘超级会员V7的分享

若有收获,就点个赞吧
0 人点赞
