
论文地址:https://ai.meta.com/research/publications/the-llama-3-herd-of-models/ 接下来,让我们看一下论文内容。
Llama3 论文亮点
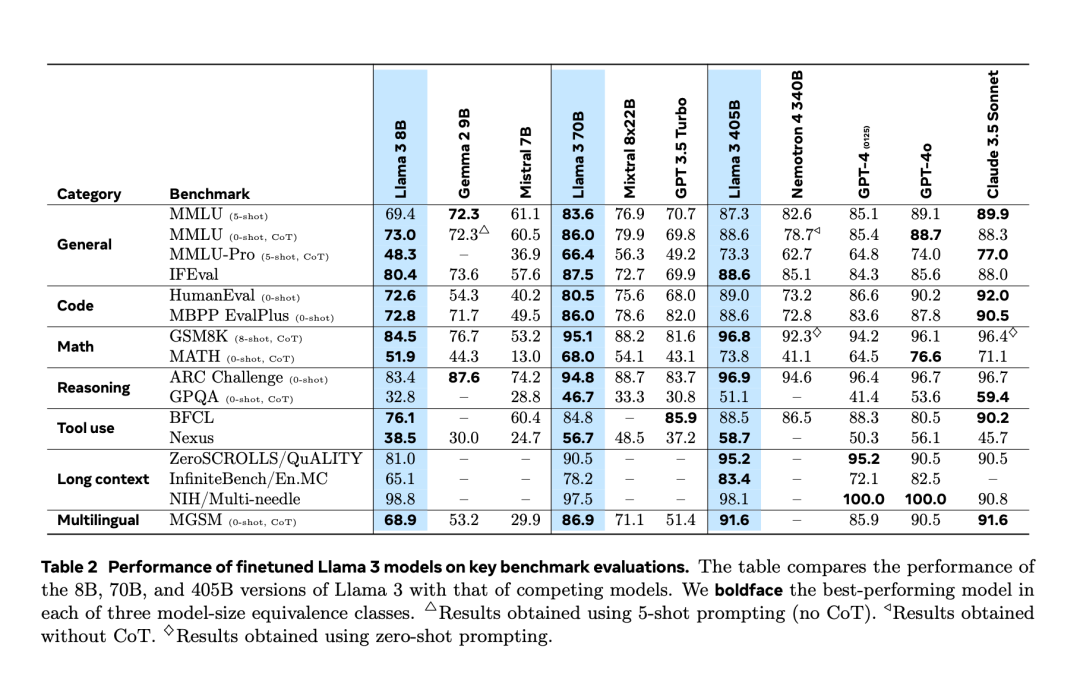
1、在使用 8K上下文长度进行预训练后,Llama 3.1 405B 使用 128K 上下文长度进行连续训练,且支持多语言和工具使用。 2、与以前的 Llama 模型相比,Meta 加强了预处理和预训练数据的 Curation pipelines,以及后训练数据的质量保证和过滤方法。Curation pipelines 是一系列自动化或半自动化的步骤,用于管理和改善数据集的质量。这些管道通常包括数据清洗、去重、标准化、验证和丰富等多个阶段,旨在确保数据集的准确性、一致性和可用性。Curation pipelines 对于机器学习和人工智能研究尤为重要,因为高质量的数据是构建有效模型的基础。Meta 认为,高质量基础模型的开发有三个关键杠杆:数据、规模和复杂性管理。 首先,与 Llama 的早期版本相比,Meta 在数量和质量两方面改进了用于预训练和后训练的数据。Meta 在大约 15 万亿的多语言 Token 语料库上对 Llama 3 进行了预训练,相比之下,Llama 2 只使用了 1.8 万亿 Token。 此次训练的模型规模远大于以前的 Llama 模型:旗舰语言模型使用了 3.8 × 10²⁵ 次浮点运算(FLOPs)进行预训练,超过 Llama 2 的最大版本近 50 倍。 基于 Scaling law,在 Meta 的训练预算下,当前的旗舰模型已是近似计算最优的规模,但 Meta 对较小模型进行的训练时间已经远超计算最优的时长。结果表明,这些较小模型在相同推理预算下的表现优于计算最优模型。在后训练阶段,Meta 使用了 405B 的旗舰模型进一步提高了 70B 和 8B 模型这些较小模型的质量。
先训练大模型,在用大模型训练小模型 Scaling Law 是人工智能领域中描述模型性能与其规模(包括模型大小、数据集大小、计算资源等)之间关系的定律。它表明,随着模型规模的增加,模型的性能通常会提高,这种关系在某些条件下可以近似为幂律关系。3、为了支持 405B 模型的大规模生产推理,Meta 将 16 位 (BF16) 量化为 8 位 (FP8),从而降低了计算要求,并使模型能够在单个服务器节点上运行。 4、在 15.6T token(3.8x10²⁵ FLOPs)上预训练 405B 是一项重大挑战,Meta 优化了整个训练堆栈,并使用了超过 16K H100 GPU。 正如 PyTorch 创始人、Meta 杰出工程师 Soumith Chintala 所说,Llama3 论文揭示了许多很酷的细节,其中之一就是基础设施的构建。
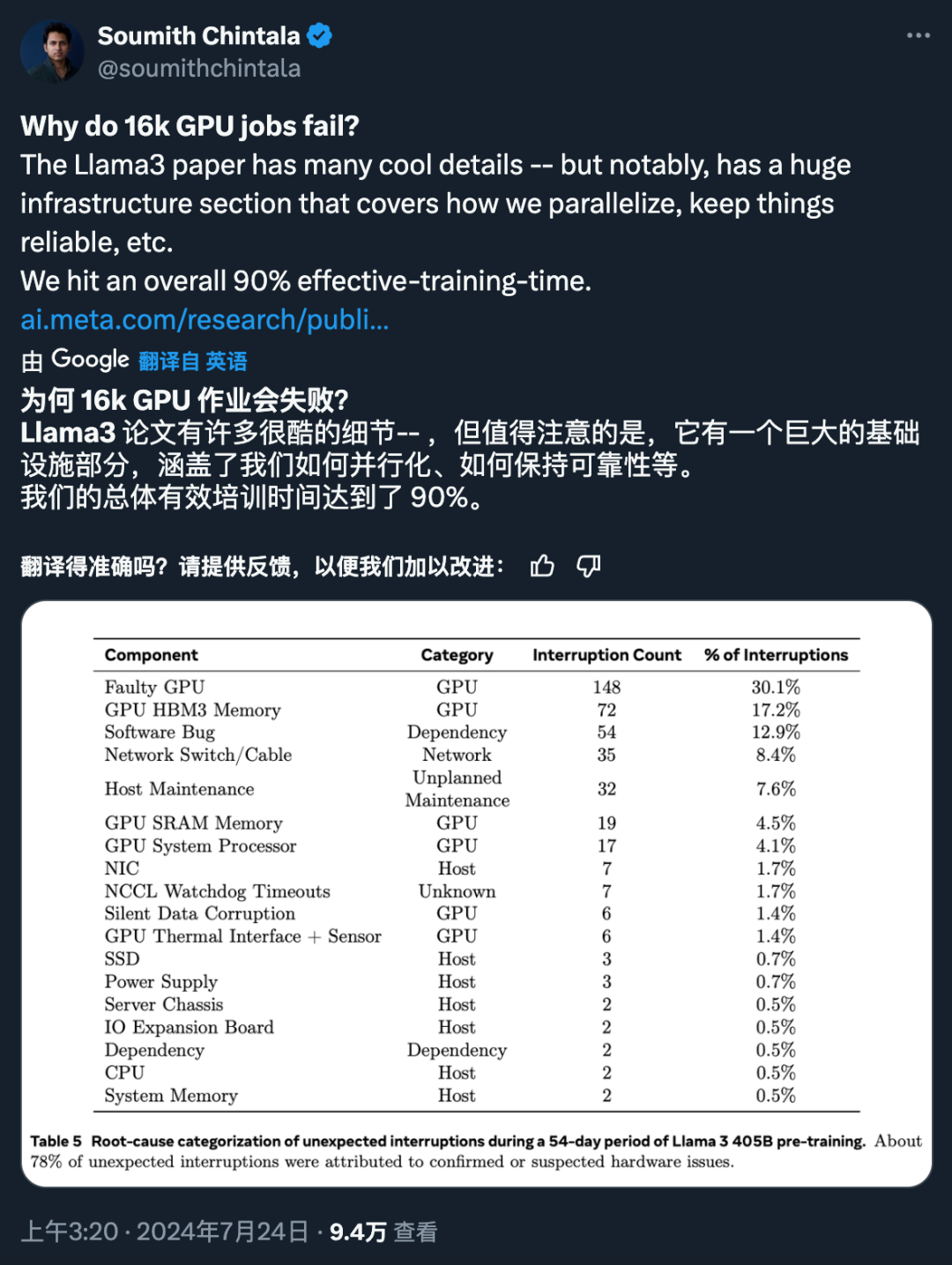


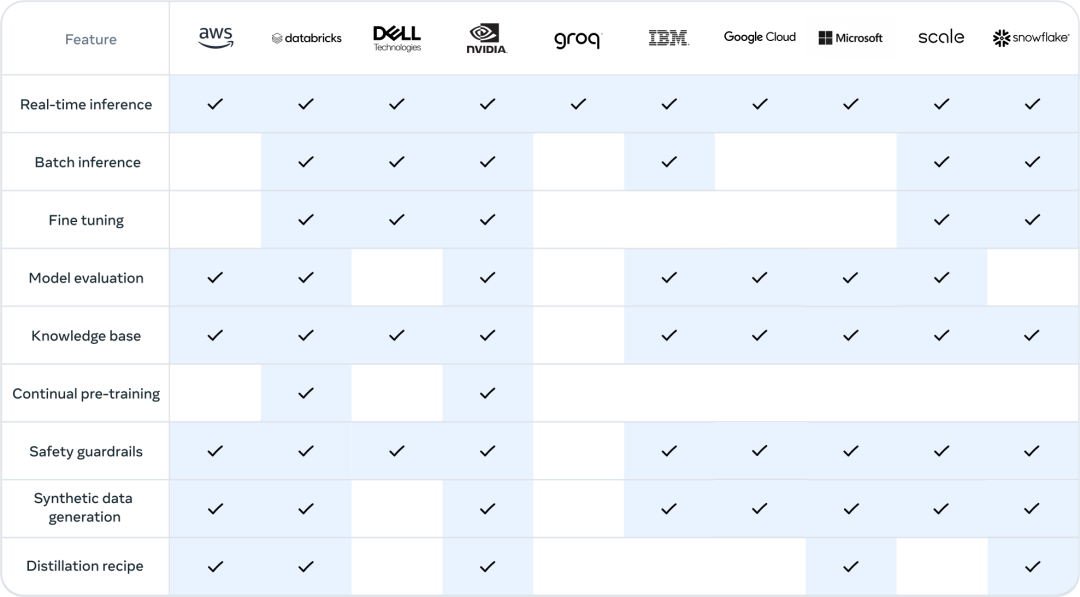
这一系列因素,最终造就了今天的 Llama 3 系列。 当然,对于普通开发者来说,如何利用 405B 规模的模型是一项挑战,需要大量的计算资源和专业知识。 发布之后,Llama 3.1 的生态系统已准备就绪,超过 25 个合作伙伴提供了可与最新模型搭配使用的服务,包括亚马逊云科技、NVIDIA、Databricks、Groq、Dell、Azure、Google Cloud 和 Snowflake 等。

若有收获,就点个赞吧
0 人点赞
