概要
刚才Meta如约发布了Llama3.1系列模型,其中就有大家翘首以盼的405B模型。 这是是全球最大、最有能力的可公开获取的基础模型,标志着开源大型语言模型进入了新时代。 该模型支持八种语言,上下文长度达到 128K,并且在多个基准数据集上进行了评估,表现出与 GPT-4 和其他高端模型相当的竞争力。 Meta 还提供了 Llama Guard 3 和 Prompt Guard 等安全工具,以及 Llama Stack API 的评论请求,旨在促进第三方项目更容易地利用 Llama 模型。 此外,Meta 还改进了模型的训练和微调流程,以及模型的推理和部署方式,以便更广泛地支持开发者和平台提供商。小扎声明
405B对Meta确实很重要,以至于小扎还发布了一个对应的声明来介绍Meta的开源优势。 他认为开源人工智能(如 Llama 3.1)是未来发展的正确道路,它能够促进 AI 技术的更广泛的应用和创新,同时也有助于 Meta 保持技术领先地位和商业模式的可持续性。 •对于 Meta 而言,开源 AI 有助于确保长期获取最佳技术,避免依赖竞争对手的封闭生态系统,并且与 Meta 的商业模式相符。•开源 AI 的安全性优于封闭模型,因为它更透明,可以被更多人审查和改进。•开源 AI 有助于平衡权力结构,使得更多人能够利用 AI 技术,而不是只有少数大公司和国家拥有。•开源 AI 的发展有助于美国和民主国家在技术竞争中保持优势,而不是通过封闭模型来限制对手的发展。模型评估
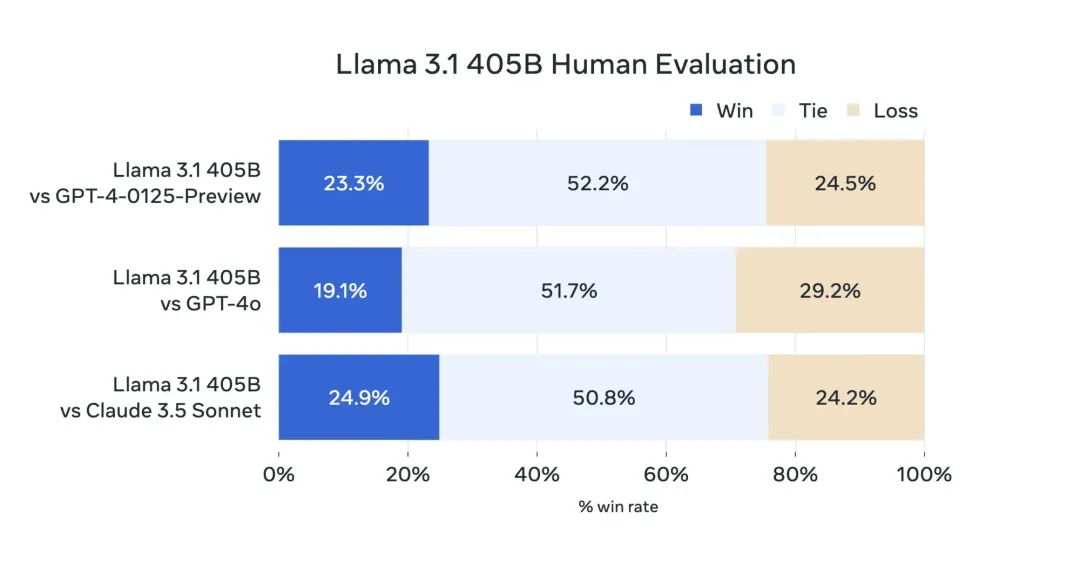
从评估结果来看405B模型确实超过了0314版本的GPT-4,但是405B相较于70B的提升有限,可能405B模型的训练对Llama来说也是个不小的挑战,剩下的工作就交给开源社区做了。 评估了涵盖多种语言的 150 多个基准数据集的性能。此外,进行了广泛的人类评估,与竞争模型在现实场景中进行比较。 实验评估表明,旗舰模型在包括 GPT-4、GPT-4o 和 Claude 3.5 Sonnet 在内的一系列任务上具有竞争力。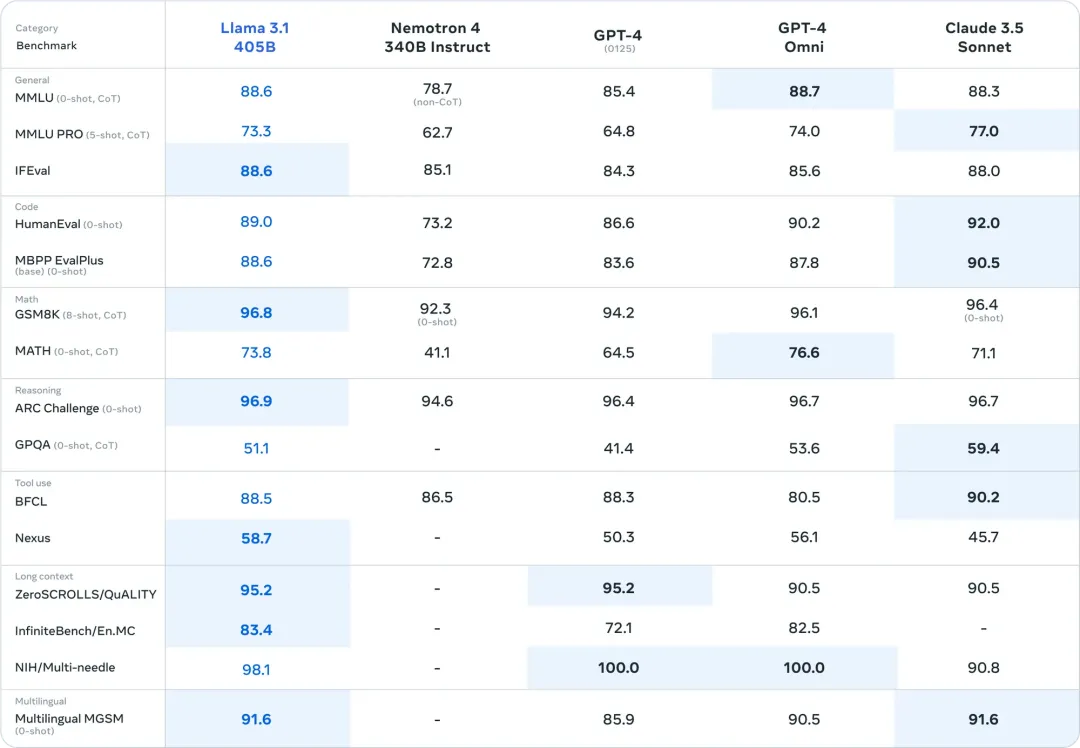
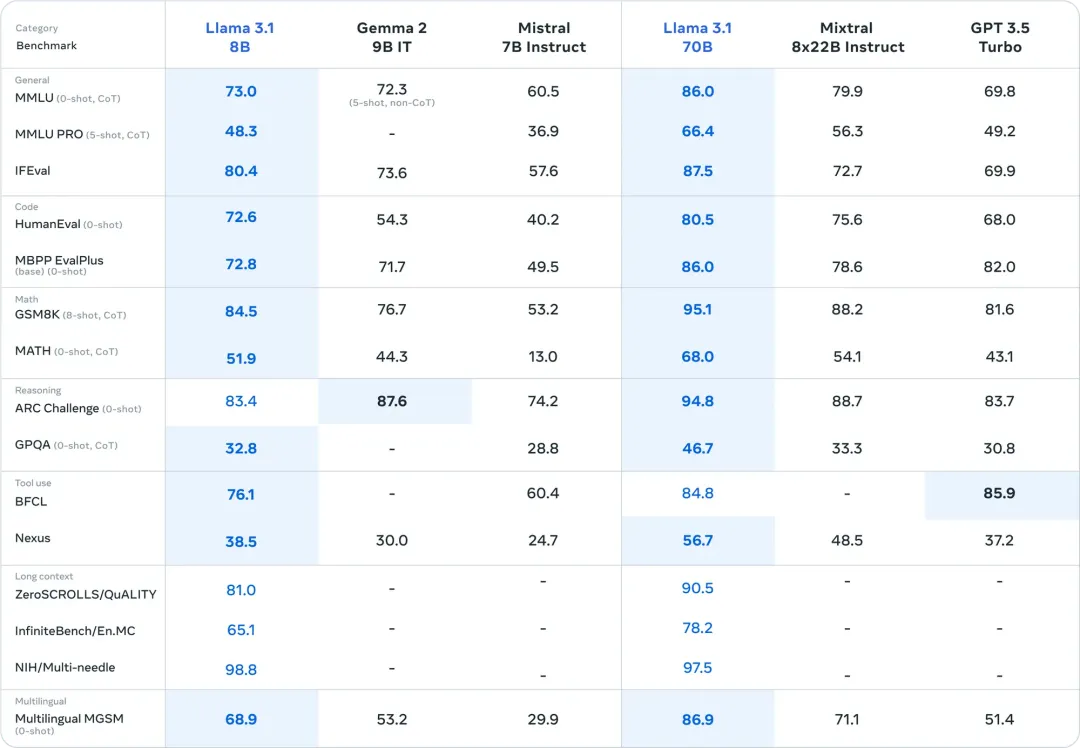
 ## 模型架构
由于Llama 3.1 405B的训练量超过了15 万亿个Token。总共使用了 16,000 个 H100 GPU 才完成,这个量级在国内几个大厂还是可以拿出来的。
## 模型架构
由于Llama 3.1 405B的训练量超过了15 万亿个Token。总共使用了 16,000 个 H100 GPU 才完成,这个量级在国内几个大厂还是可以拿出来的。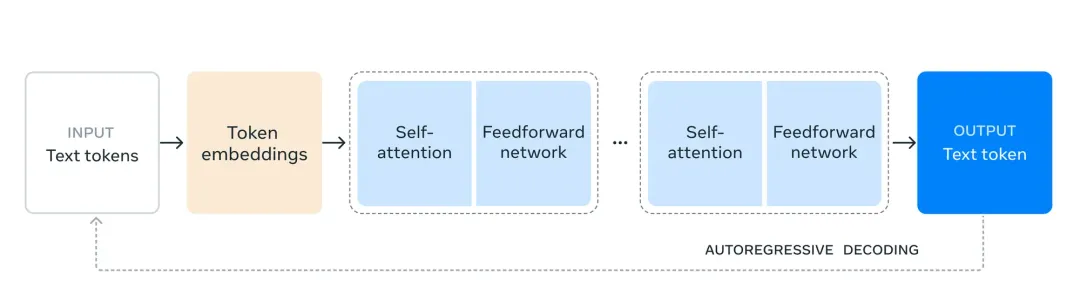 为了训练如此大的模型,他们对训练过程做了一些优化:
•选择了标准的解码器 Transformer 模型架构,并进行了少量改动,而没有采用专家混合模型,以确保训练的稳定性。•采用了一种迭代的后训练过程,每一轮都进行监督微调和直接偏好优化。这使我们能够在每一轮中生成最高质量的合成数据,并提升各项能力的性能。•相比之前的 Llama 版本,改进了预训练和后训练数据的数量和质量。这些改进包括更仔细的预处理和策划流程用于预训练数据,以及更严格的质量保证和过滤方法用于后训练数据。
根据语言模型的规模定律,新旗舰模型在使用相同程序训练的小模型上表现更为出色。还使用了 405B 模型来提升较小模型的后训练质量。
为了支持 405B 规模模型的大规模生产推理,将模型从 16 位 (BF16) 量化到 8 位 (FP8) 数值,从而有效降低了计算要求,使模型可以在单个服务器节点内运行。
为了训练如此大的模型,他们对训练过程做了一些优化:
•选择了标准的解码器 Transformer 模型架构,并进行了少量改动,而没有采用专家混合模型,以确保训练的稳定性。•采用了一种迭代的后训练过程,每一轮都进行监督微调和直接偏好优化。这使我们能够在每一轮中生成最高质量的合成数据,并提升各项能力的性能。•相比之前的 Llama 版本,改进了预训练和后训练数据的数量和质量。这些改进包括更仔细的预处理和策划流程用于预训练数据,以及更严格的质量保证和过滤方法用于后训练数据。
根据语言模型的规模定律,新旗舰模型在使用相同程序训练的小模型上表现更为出色。还使用了 405B 模型来提升较小模型的后训练质量。
为了支持 405B 规模模型的大规模生产推理,将模型从 16 位 (BF16) 量化到 8 位 (FP8) 数值,从而有效降低了计算要求,使模型可以在单个服务器节点内运行。
Instruction 和 chat fine-tuning
在后期训练中,通过在预训练模型基础上进行多轮对齐,最终生成聊天模型。每轮训练都包括监督微调(Supervised Fine-Tuning,SFT)、拒绝采样(Rejection Sampling,RS)和直接偏好优化(Direct Preference Optimization,DPO)。 主要依靠合成数据生成大量的SFT示例,并通过多次迭代提升合成数据的质量。 此外,还采用多种数据处理技术,以确保过滤出的合成数据达到最高质量。能够在各个功能上扩展微调数据量。Llama系统
之前的Llama整个系统比较分散有很多不同的标准。 这次他们在GitHub上发布了一份称为“Llama Stack”的意见征求书。 Llama Stack是一组标准化和有指导性的接口,用于构建规范的工具链组件(如微调、合成数据生成)和智能应用程序。如何使用Llama3.1构建产品
他们希望开发者可以利用405B进行更多的实践,包括: •实时和批量推理•监督微调•针对具体应用的模型评估•持续预训练•检索增强生成(RAG,Retrieval-Augmented Generation)•函数调用•合成数据生成从一开始,开发者就可以利用405B模型的所有高级功能,立即开始构建项目。开发者还可以探索高级工作流程,比如轻松进行合成数据生成,按照现成的模型蒸馏指南操作,并通过包括AWS、NVIDIA和Databricks在内的合作伙伴解决方案实现无缝的RAG。此外,Groq已为云端部署优化了低延迟推理,Dell也为本地系统实现了类似的优化。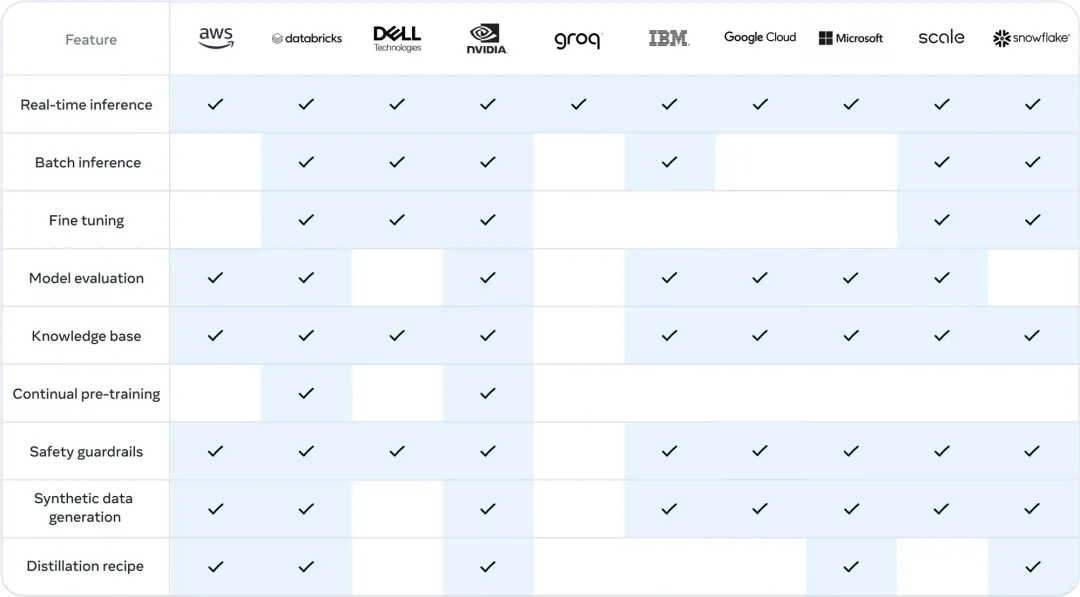
相关链接:
模型下载:https://llama.meta.com/[1]
扎克伯格声明:https://about.fb.com/news/2024/07/open-source-ai-is-the-path-forward/[2]
博客文章:https://ai.meta.com/blog/meta-llama-3-1/[3]
技术报告:https://ai.meta.com/research/publications/the-llama-3-herd-of-models/[4]
Llama Stack:https://github.com/meta-llama/llama-toolchain/issues[5]
GitHub项目:https://github.com/meta-llama/llama-models[6]
Huggingface:https://huggingface.co/meta-llama[7]
References
<font style="color:rgb(63, 63, 63);">[1]</font>: https://llama.meta.com/<font style="color:rgb(63, 63, 63);">[2]</font>: https://about.fb.com/news/2024/07/open-source-ai-is-the-path-forward/<font style="color:rgb(63, 63, 63);">[3]</font>: https://ai.meta.com/blog/meta-llama-3-1/<font style="color:rgb(63, 63, 63);">[4]</font>: https://ai.meta.com/research/publications/the-llama-3-herd-of-models/<font style="color:rgb(63, 63, 63);">[5]</font>: https://github.com/meta-llama/llama-toolchain/issues<font style="color:rgb(63, 63, 63);">[6]</font>: https://github.com/meta-llama/llama-models<font style="color:rgb(63, 63, 63);">[7]</font>: https://huggingface.co/meta-llama

若有收获,就点个赞吧
0 人点赞
